Aber da die Leute keine Computer sind, suchen sie nach etwas wie "so etwas war von Ivanov oder von Ivanovsky ... nein, nicht das, früher, noch früher ... hier ist es! "
Dies droht dem Entwickler jedoch mit schrecklichen Problemen - schließlich werden für die FTS-Suche in PostgreSQL die "räumlichen" Typen von GIN- und GiST-Indizes verwendet , die außer einem Textvektor keinen "Schlupf" zusätzlicher Daten vorsehen.
Es bleibt nur, leider alle Datensätze nach Präfixübereinstimmung zu lesen (es gibt Tausende von ihnen!) Und nach Datumsindex und Filter zu sortieren oder umgekehrt zu gehenAlle gefundenen Einträge für das Präfix stimmen überein, bis wir geeignete gefunden haben (wie schnell wird es "Kauderwelsch" geben? ..).
Beide sind für die Abfrageleistung nicht sehr angenehm. Oder fällt Ihnen noch etwas für eine schnelle Suche ein?
Lassen Sie uns zunächst unsere "aktuellen Texte" generieren:
CREATE TABLE corpus AS
SELECT
id
, dt
, str
FROM
(
SELECT
id::integer
, now()::date - (random() * 1e3)::integer dt -- - 3
, (random() * 1e2 + 1)::integer len -- "" 100
FROM
generate_series(1, 1e6) id -- 1M
) X
, LATERAL(
SELECT
string_agg(
CASE
WHEN random() < 1e-1 THEN ' ' -- 10%
ELSE chr((random() * 25 + ascii('a'))::integer)
END
, '') str
FROM
generate_series(1, len)
) Y;
Naiver Ansatz Nr. 1: Kern + Baum
Versuchen wir, den Index sowohl für FTS als auch für die Sortierung nach Datum zu rollen - was ist, wenn sie helfen:
CREATE INDEX ON corpus(dt);
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str));
Wir werden nach allen Dokumenten suchen, die Wörter enthalten, die mit beginnen
'abc...'
. Lassen Sie uns zunächst überprüfen, ob es nicht viele solcher Dokumente gibt und der FTS-Index normalerweise verwendet wird:
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*');
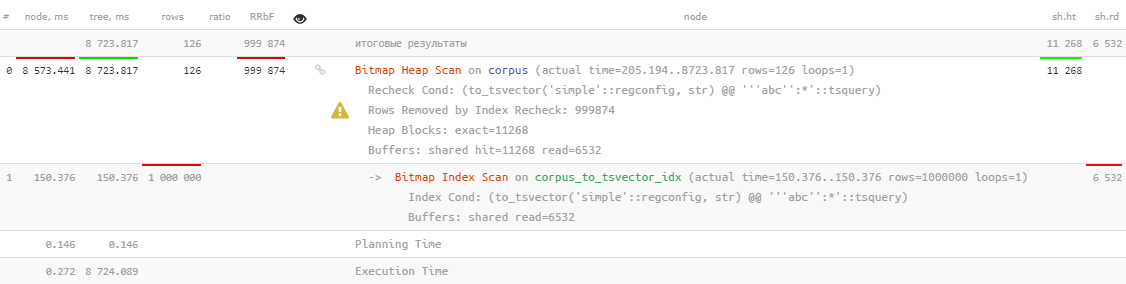
Nun ... es wird natürlich verwendet, aber es dauert mehr als 8 Sekunden , was eindeutig nicht das ist, was wir für die Suche nach 126 Datensätzen ausgeben möchten.
Vielleicht wird es besser, wenn Sie die Sortierung nach Datum hinzufügen und nur die letzten 10 Datensätze durchsuchen ?
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt DESC
LIMIT 10;

Aber nein, oben wurde nur sortiert.
Naiver Ansatz # 2: btree_gist
Es gibt jedoch eine hervorragende Erweiterung
btree_gist
, mit der Sie einen Skalarwert in einen GiST-Index "einfügen" können, sodass wir die Indexsortierung sofort mit dem Entfernungsoperator
<->
verwenden können, der für kNN-Suchen verwendet werden kann :
CREATE EXTENSION btree_gist;
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str), dt);
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt <-> '2100-01-01'::date DESC -- ""
LIMIT 10;
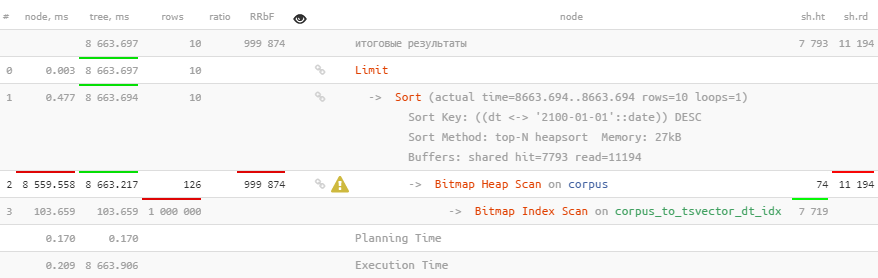
Leider hilft das überhaupt nicht.
Geometrie zur Rettung!
Aber es ist zu früh, um zu verzweifeln! Schauen wir uns die Liste der integrierten GiST-Operatorklassen an - der Distanzoperator
<->
ist nur für "geometrisch"
circle_ops, point_ops, poly_ops
und seit PostgreSQL 13 verfügbar - für
box_ops
.
Versuchen wir also , unser Problem "in die Ebene" zu übersetzen - wir weisen unseren Paaren,
(, )
die für die Suche verwendet werden , die Koordinaten einiger Punkte zu, damit die "Präfix" -Wörter und nicht weit entfernten Daten so nah wie möglich sind:

Wir brechen den Text in Worte
Natürlich wird unsere Suche nicht vollständig im Volltext durchgeführt, da Sie nicht für mehrere Wörter gleichzeitig eine Bedingung festlegen können. Aber es wird definitiv ein Präfix sein!
Bilden wir eine Hilfswörterbuchtabelle:
CREATE TABLE corpus_kw AS
SELECT
id
, dt
, kw
FROM
corpus
, LATERAL (
SELECT
kw
FROM
regexp_split_to_table(lower(str), E'[^\\-a-z-0-9]+', 'i') kw
WHERE
length(kw) > 1
) T;
In unserem Beispiel gab es 4,8 Millionen "Wörter" pro 1 Million "Texte".
Die Worte niederschreiben
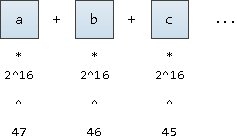
Um ein Wort in seine "Koordinate" zu übersetzen, stellen wir uns vor, dass dies eine Zahl ist, die in Basisnotation geschrieben ist
2^16
(schließlich möchten wir auch UNICODE-Zeichen unterstützen). Wir werden es nur ab der festen 47. Position aufschreiben:
Es wäre möglich, von der 63. Position aus zu beginnen. Dies gibt uns Werte, die etwas unter den
1E+308
Grenzwerten für liegen
double precision
, aber dann tritt beim Erstellen des Index ein Überlauf auf.
Es stellt sich heraus, dass auf der Koordinatenachse alle Wörter sortiert werden:

ALTER TABLE corpus_kw ADD COLUMN p point;
UPDATE
corpus_kw
SET
p = point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
);
CREATE INDEX ON corpus_kw USING gist(p);
Wir bilden eine Suchanfrage
WITH src AS (
SELECT
point(
( --
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
SELECT
*
, src.ps <-> kw.p d
FROM
corpus_kw kw
, src
ORDER BY
d
LIMIT 10;

Jetzt haben wir die
id
Dokumente, nach denen wir gesucht haben, in der richtigen Reihenfolge sortiert - und es dauerte weniger als 2 ms, 4000-mal schneller !
Eine kleine Fliege in der Salbe
Der Bediener
<->
weiß nichts über unsere Bestellung entlang zweier Achsen, daher befinden sich unsere erforderlichen Daten je nach erforderlicher Sortierung nach Datum nur in einem der richtigen Viertel:

Nun, wir wollten immer noch die Textdokumente selbst auswählen und nicht ihre Schlüsselwörter. Also brauchen wir einen längst vergessenen Index:
CREATE UNIQUE INDEX ON corpus(id);
Lassen Sie uns die Anfrage abschließen:
WITH src AS (
SELECT
point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
, dc AS (
SELECT
(
SELECT
dc
FROM
corpus dc
WHERE
id = kw.id
)
FROM
corpus_kw kw
, src
WHERE
p[0] >= ps[0] AND -- kw >= ...
p[1] <= ps[1] -- dt DESC
ORDER BY
src.ps <-> kw.p
LIMIT 10
)
SELECT
(dc).*
FROM
dc;

Sie haben uns
InitPlan
mit der Berechnung der Konstanten x / y ein wenig hinzugefügt , aber wir haben uns trotzdem innerhalb der gleichen 2 ms gehalten !
Fliege in die Salbe # 2
Nichts ist umsonst:
SELECT relname, pg_size_pretty(pg_total_relation_size(oid)) FROM pg_class WHERE relname LIKE 'corpus%';
corpus | 242 MB -- corpus_id_idx | 21 MB -- PK corpus_kw | 705 MB -- corpus_kw_p_idx | 403 MB -- GiST-
Aus 242 MB "Texten" wurden 1,1 GB "Suchindex".
Aber schließlich
corpus_kw
liegen das Datum und das Wort selbst darin , was wir bei der Suche nicht verwendet haben - also lassen Sie uns sie löschen:
ALTER TABLE corpus_kw
DROP COLUMN kw
, DROP COLUMN dt;
VACUUM FULL corpus_kw;
corpus_kw | 641 MB -- id point
Eine Kleinigkeit - aber schön. Es hat nicht allzu viel geholfen, aber dennoch wurden 10% des Volumens zurückgewonnen.