Noch niedrigere Ebene (avr-vusb)
USB-On-Register: Bulk-Endpunkt am Beispiel von Massenspeicher
USB-On-Register: Interrupt-Endpunkt am Beispiel von HID
USB-On-Registern: Isochroner Endpunkt am Beispiel eines Audiogeräts
Wir haben bereits Software-USB mit kennengelernt Am Beispiel von AVR ist es an der Zeit, schwerere Steine anzunehmen - stm32. Unsere Versuchspersonen werden der klassische STM32F103C8T6 sowie ein Vertreter der STM32L151RCT6-Serie mit geringem Stromverbrauch sein. Nach wie vor werden wir keine gekauften Debug-Boards und HAL verwenden und bevorzugen ein Fahrrad.
Da der Titel zwei Controller enthält, lohnt es sich, über die Hauptunterschiede zu sprechen. Zuallererst ist dies ein Pull-up-Widerstand, der dem USB-Host mitteilt, dass etwas darin stecken geblieben ist. In L151 ist es eingebaut und wird vom Bit SYSCFG_PMC_USB_PU gesteuert, in F103 jedoch nicht. Sie müssen es von außen an die Platine löten und entweder an VCC oder an den Controller-Zweig anschließen. In meinem Fall kam das PA10-Bein unter meinen Arm. An welchem UART1 hängt ... Und der andere Pin von UART1 widerspricht dem Knopf ... Ich habe ein wundervolles Board geworfen, findest du nicht? Der zweite Unterschied ist die Größe des Flash-Speichers: Beim F103 sind es 64 kB und beim L151 sogar 256 kB, die wir eines Tages beim Studium von Bulk-Endpunkten verwenden werden. Sie haben auch leicht unterschiedliche Uhreinstellungen und können mit Glühbirnen mit Knöpfen an verschiedenen Beinen hängen, aber das sind schon ziemlich Kleinigkeiten. Beispiel für F103ist im Repository verfügbar, so dass es nicht schwierig sein wird , den Rest der Experimente mit dem L151 dafür anzupassen . Quellcodes finden Sie hier: github.com/COKPOWEHEU/usb
Allgemeines Prinzip der Arbeit mit USB
Der Betrieb mit USB in diesem Controller wird über ein Hardwaremodul vorausgesetzt. Das heißt, wir sagen ihm, was zu tun ist, er tut es und am Ende zieht er die Unterbrechung „Ich bin bereit!“. Dementsprechend müssen wir fast nichts von der Hauptleitung aufrufen (obwohl ich für alle Fälle die Funktion usb_class_poll bereitgestellt habe). Der normale Arbeitszyklus beschränkt sich auf ein einziges Ereignis - den Datenaustausch. Der Rest - Zurücksetzen, Schlafen und andere - sind außergewöhnliche, einmalige Ereignisse.
Dieses Mal werde ich nicht auf die Details des Austauschs auf niedriger Ebene eingehen. Jeder Interessierte kann über vusb lesen. Aber ich möchte Sie daran erinnern, dass der Austausch gewöhnlicher Daten nicht durch ein Byte, sondern durch ein Paket erfolgt und die Übertragungsrichtung vom Host festgelegt wird. Und er diktiert auch die Namen dieser Richtungen: IN-Übertragung bedeutet, dass der Host Daten empfängt (und das Gerät sendet), und OUT bedeutet, dass der Host Daten sendet (und wir empfangen). Darüber hinaus hat jedes Paket eine eigene Adresse - die Nummer des Endpunkts, mit dem der Host kommunizieren möchte. Im Moment haben wir einen einzelnen Endpunkt 0, der für das gesamte Gerät verantwortlich ist (der Kürze halber werde ich es auch ep0 nennen). Wofür der Rest ist, werde ich Ihnen in anderen Artikeln sagen. Gemäß dem Standard beträgt die Größe von ep0 für Geräte mit niedriger Geschwindigkeit (zu denen derselbe Vusb gehört) streng 8 Byte und eine Auswahl von 8, 16, 32,64 Bytes für volle Geschwindigkeit wie bei uns.
Was ist, wenn die Daten zu klein sind und den Puffer nicht vollständig füllen? Hier ist alles einfach: Zusätzlich zu den Daten im Paket wird auch deren Größe übertragen (dies kann das wLength-Feld oder eine Kombination von SE0-Signalen auf niedriger Ebene sein, die das Ende der Übertragung anzeigt), also selbst wenn wir übertragen müssen drei Bytes bis ep0 von 64 Bytes, dann werden genau drei Bytes übertragen ... Infolgedessen verschwenden wir keine Bandbreite, indem wir unnötige Nullen ansteuern. Seien Sie also nicht zu klein: Wenn wir es uns leisten können, 64 Bytes auszugeben, geben wir ohne zu zögern aus. Dies reduziert unter anderem die Buslast etwas, da es einfacher ist, ein Stück von 64 Bytes (plus alle Header und Tails) gleichzeitig zu übertragen als jeweils 8 mal 8 Bytes (zu denen wiederum Header und Tails gehören) ).
Und wenn es im Gegenteil zu viele Daten gibt? Hier ist es komplizierter. Die Daten müssen nach der Größe des Endpunkts aufgeteilt und in Blöcken übertragen werden. Angenommen, die Größe von ep0 beträgt 8 Byte, und der Host versucht, 20 Byte zu übertragen. Beim ersten Interrupt kommen die Bytes 0-7 zu uns, beim zweiten 8-15, beim dritten 16-20. Das heißt, um das gesamte Paket zu sammeln, müssen Sie bis zu drei Interrupts empfangen. Dafür wurde in derselben HAL ein kniffliger Puffer erfunden, mit dem ich versuchte, es herauszufinden, aber nach der vierten Ebene der Übertragung derselben Sache zwischen Funktionen spuckte ich aus. Infolgedessen fällt in meiner Implementierung die Pufferung auf die Schultern des Programmierers.
Aber der Host sagt zumindest immer, wie viele Daten er zu übertragen versucht. Wenn wir Daten übertragen, müssen wir die Zustände der Beine auf niedriger Ebene irgendwie austricksen, um klar zu machen, dass die Daten vorbei sind. Genauer gesagt, um dem USB-Modul klar zu machen, dass die Daten vorbei sind und Sie die Beine ziehen müssen. Dies geschieht auf offensichtliche Weise - indem nur ein Teil des Puffers geschrieben wird. Wenn wir zum Beispiel 8 Bytes im Puffer haben und 4 geschrieben haben, dann haben wir offensichtlich nur 4 Bytes Daten, wonach das Modul die magische Kombination SE0 sendet und alle glücklich sind. Und wenn wir 8 Bytes geschrieben haben, bedeutet das, dass wir nur 8 Bytes haben oder dass dies nur ein Teil der Daten ist, die in den Puffer passen? Das USB-Modul glaubt, dass die. Wenn wir also die Übertragung stoppen möchten, müssen wir nach dem Schreiben des 8-Byte-Puffers den nächsten 0-Byte-Puffer schreiben. Dies wird als ZLP, Zero Length Packet bezeichnet. Wie es im Code aussieht,Ich werde es dir etwas später erzählen.
Organisation des Gedächtnisses
Gemäß dem Standard kann die Größe des Endpunkts 0 bis zu 64 Byte betragen. Jede andere Größe - bis zu 1024 Byte. Die Anzahl der Punkte kann auch von Gerät zu Gerät unterschiedlich sein. Der gleiche STM32L1 unterstützt bis zu 7 Punkte am Eingang und 7 am Ausgang (ohne ep0), dh bis zu 14 kB Puffer allein. Was in einem solchen Volumen höchstwahrscheinlich von niemandem benötigt wird. Inakzeptabler Speicherverbrauch! Stattdessen kaut das USB-Modul einen Teil des gemeinsam genutzten Kernelspeichers ab und verwendet ihn. Dieser Bereich heißt PMA (Packet Memory Area) und beginnt mit USB_PMAADDR. Und um anzuzeigen, wo sich die Puffer jedes Endpunkts darin befinden, wird zu Beginn ein Array von 8 Elementen mit jeweils der folgenden Struktur zugewiesen, und erst dann der tatsächliche Bereich für Daten:
typedef struct{
volatile uint32_t usb_tx_addr;
volatile uint32_t usb_tx_count;
volatile uint32_t usb_rx_addr;
volatile union{
uint32_t usb_rx_count;
struct{
uint32_t rx_count:10;
uint32_t rx_num_blocks:5;
uint32_t rx_blocksize:1;
};
};
}usb_epdata_t;
Hier legen Sie den Anfang des Sendepuffers, seine Größe, dann den Beginn des Empfangspuffers und seine Größe fest. Beachten Sie zunächst, dass usb_tx_count nicht die tatsächliche Puffergröße, sondern die zu übertragende Datenmenge festlegt. Das heißt, unser Code muss Daten an die Adresse usb_tx_addr schreiben, dann ihre Größe in usb_tx_count schreiben und erst dann das USB-Modulregister ziehen, in das die Daten geschrieben wurden, und sie übertragen. Achten Sie noch mehr auf das seltsame Format der Empfangspuffergröße: Es ist eine Struktur, in der 10 rx_count-Bits für die tatsächliche Menge der gelesenen Daten verantwortlich sind, während der Rest tatsächlich für die Puffergröße verantwortlich ist. Es ist notwendig, das Stück Eisen zu kennen, an das Sie schreiben können und an dem die Daten anderer Personen beginnen. Das Format dieser Einstellung ist ebenfalls sehr interessant: Das Flag rx_block_size gibt an, in welchen Einheiten die Größe festgelegt ist. Wenn es auf 0 zurückgesetzt wird,dann in 2-Byte-Wörtern beträgt die Puffergröße 2 * rx_num_blocks, dh von 0 bis 62. Wenn sie auf 1 gesetzt ist, ergibt sich in 32-Byte-Blöcken die Puffergröße als 32 * rx_num_blocks und liegt im Bereich von 32 bis 512 (ja, nicht bis 1024, dies ist die Einschränkung des Controllers).
Um Puffer in diesem Bereich zu platzieren, verwenden wir einen semidynamischen Ansatz. Das heißt, Speicher nach Bedarf zuweisen, aber nicht freigeben (malloc / free war noch nicht genug, um zu erfinden!). Auf den Anfang des nicht zugewiesenen Raums wird durch die Variable lastaddr hingewiesen, die anfänglich auf den Beginn der PMA abzüglich der oben diskutierten Strukturtabelle zeigt. Nun, jedes Mal, wenn die Funktion zum Konfigurieren des nächsten Endpunkts usb_ep_init () aufgerufen wird, wird sie um die dort angegebene Puffergröße verschoben. Und der gewünschte Wert wird natürlich in die entsprechende Zelle der Tabelle eingegeben. Der Wert dieser Variablen wird bei einem Rücksetzereignis zurückgesetzt, gefolgt von einem Aufruf von usb_class_init (), in dem die Punkte gemäß der Aufgabe des Benutzers neu konfiguriert werden.
Arbeiten mit Sende-Empfangs-Registern
Wie gerade gesagt, lesen wir beim Empfang, wie viele Daten tatsächlich empfangen wurden (das Feld usb_rx_count), lesen dann die Daten selbst und ziehen dann das USB-Modul, damit der Puffer frei ist. Sie können das nächste Paket empfangen. Umgekehrt zur Übertragung: Wir schreiben die Daten in den Puffer, legen dann fest, wie viel in usb_tx_count geschrieben wurde, und ziehen schließlich das Modul, damit der Puffer voll ist, und können es übertragen.
Der erste RechenBeginnen Sie mit der Arbeit mit dem Puffer selbst: Er ist nicht wie der Rest des Controllers in 32 Bit und nicht wie erwartet in 8 Bit organisiert. Und jeweils 16 Bit! Infolgedessen wird es in 2 Bytes geschrieben und gelesen, ausgerichtet auf 4 Bytes. Danke ST, dass du so eine Perversion gemacht hast! Wie langweilig wäre das Leben ohne es! Jetzt ist gewöhnliches memcpy unverzichtbar, Sie müssen spezielle Funktionen umzäunen. Übrigens, wenn jemand DMA liebt, dann scheint es in der Lage zu sein, eine solche Transformation selbst durchzuführen, obwohl ich sie nicht getestet habe.
Und dann der zweite Rechenmit Schreiben in die Register des Moduls. Tatsache ist, dass für die Konfiguration jedes Endpunkts - für seinen Typ (Steuerung, Bulk usw.) und Status - ein Register USB_EPnR verantwortlich ist, das heißt, Sie können nichts daran ändern, Sie müssen aufpassen um den Rest nicht zu verderben. Und zweitens gibt es in diesem Register bereits vier Arten von Bits! Einige sind nur zum Lesen verfügbar (das ist großartig), andere zum Lesen und Schreiben (auch normal), andere ignorieren Datensatz 0, aber wenn sie 1 schreiben, ändern sie den Zustand in das Gegenteil (Spaß beginnt) und der vierte auf dem Ignorieren Sie im Gegensatz dazu Datensatz 1, aber Datensatz 0 setzt sie auf 0 zurück. Sagen Sie mir, welcher Süchtige hat daran gedacht, Bits in einem Register zu erstellen, die 0 ignorieren und 1 ignorieren ?! Nein, ich bin bereit anzunehmen, dass dies getan wurde, um die Integrität des Registers zu erhalten, wenn sowohl über Code als auch über Hardware darauf zugegriffen wird. Aber was willst du,War es zu faul, den Wechselrichter so zu platzieren, dass die Bits durch Schreiben von 1 zurückgesetzt wurden? Oder ein Inverter, damit andere Bits durch Schreiben von 0 invertiert werden? Das Setzen von zwei Registerbits sieht daher folgendermaßen aus (nochmals vielen Dank an ST für eine solche Perversion):
#define ENDP_STAT_RX(num, stat) do{USB_EPx(num) = ((USB_EPx(num) & ~(USB_EP_DTOG_RX | USB_EP_DTOG_TX | USB_EPTX_STAT)) | USB_EP_CTR_RX | USB_EP_CTR_TX) ^ stat; }while(0)
Oh ja, ich hätte fast vergessen: Sie haben auch keinen Zugang zum Register nach Nummer. Das heißt, Makros USB_EP0R, USB_EP1R usw. sie haben, aber wenn die Zahl in einer Variablen kam, dann leider. Ich musste mein eigenes USB_EPx () erfinden - und was zu tun ist.
Um die Formalitäten zu erfüllen, möchte ich darauf hinweisen, dass das Bereitschaftsflag (dh, dass wir die vorherigen Daten bereits gelesen haben) von der Bitmaske USB_EP_RX_VALID gesetzt wird und zum Schreiben (dh wir haben die Daten eingeschrieben) voll und kann übertragen werden) - durch die Maske USB_EP_TX_VALID.
Verarbeitung von IN- und OUT-Anfragen
Das Auftreten eines USB-Interrupts kann verschiedene Dinge signalisieren, aber wir werden uns vorerst auf Kommunikationsanfragen konzentrieren. Das Flag für ein solches Ereignis ist das USB_ISTR_CTR-Bit. Wenn wir es gesehen haben, können wir herausfinden, mit welchem Punkt der Host kommunizieren möchte. Die Punktnummer ist unter der Bitmaske USB_ISTR_EP_ID und die Richtung IN oder OUT unter den Bits USB_EP_CTR_TX bzw. USB_EP_CTR_RX verborgen.
Da wir viele Punkte haben können und jeder seinen eigenen Verarbeitungsalgorithmus hat, werden wir für alle Rückruffunktionen erstellen, die bei den entsprechenden Ereignissen aufgerufen würden. Zum Beispiel hat der Host Daten an Endpoint3 gesendet, wir haben USB-> ISTR gelesen und von dort herausgezogen, dass die Anfrage OUT ist und dass die Punktnummer 3 ist. Also rufen wir epfunc_out [3] (3) auf. Die Punktnummer in Klammern wird übertragen, wenn der Benutzercode plötzlich einen Handler an mehreren Punkten aufhängen möchte. Oh ja, auch im USB-Standard ist es üblich, IN-Eingangspunkte mit einem gespannten 7. Bit zu markieren. Das heißt, Endpunkt3 am Ausgang hat die Nummer 0x03 und am Eingang - 0x83. Darüber hinaus sind dies verschiedene Punkte, sie können gleichzeitig verwendet werden, sie stören sich nicht gegenseitig. Na ja, fast: In stm32 haben sie eine Einstellung des Typs (Bulk, Interrupt, ...) für Empfang und Übertragung. Der gleiche 0x83. IN-Punkt stimmt also mit dem Rückruf überein. 'bei epfunc_in [3] (3 | 0x80).
Das gleiche Prinzip gilt für ep0. Der einzige Unterschied besteht darin, dass die Verarbeitung innerhalb der Bibliothek und nicht innerhalb des Benutzercodes erfolgt. Aber was ist, wenn Sie bestimmte Anfragen wie HID bearbeiten müssen - wählen Sie nicht den Bibliothekscode aus? Hierfür gibt es spezielle Rückrufe usb_class_ep0_out und usb_class_ep0_in, die an bestimmten Stellen aufgerufen werden und ein spezielles Format haben, über das ich näher am Ende sprechen werde.
Es ist erwähnenswert, dass ein weiterer nicht sehr offensichtlicher Punkt im Zusammenhang mit dem Auftreten von Paketverarbeitungsunterbrechungen steht. Bei OUT-Anfragen ist alles einfach: Die Daten kamen, hier sind sie. Der IN-Interrupt wird jedoch nicht generiert, wenn der Host eine IN-Anforderung gesendet hat, sondern wenn der Sendepuffer leer ist. Das heißt, dieser Interrupt ähnelt im Prinzip dem UART-Puffer-Unterlauf-Interrupt. Wenn wir also etwas auf den Host übertragen möchten, schreiben wir einfach die Daten in den Übertragungspuffer, warten auf den IN-Interrupt und fügen hinzu, was nicht passt (vergessen Sie nicht den ZLP). Und okay, selbst mit den "üblichen" Endpunkten werden sie vom Programmierer gesteuert. Sie können sie vorerst ignorieren. Aber durch ep0 geht der Austausch immer. Daher sollte die Arbeit damit in die Bibliothek integriert werden.
Infolgedessen wird der Beginn der Übertragung von der Funktion ep0_send ausgeführt, die die Adresse des Pufferanfangs und die zu übertragende Datenmenge in die globale Variable schreibt. Anschließend wird das IN-Ereignis selbst abgerufen Handler zum ersten Mal. In Zukunft wird dieser Handler bei Hardwareereignissen aufgerufen, Sie müssen jedoch noch einen Push ausführen.
Nun, der Handler selbst ist recht einfach: Er schreibt die nächsten Daten in den Übertragungspuffer, verschiebt die Adresse des Pufferanfangs und reduziert die Anzahl der für die Übertragung verbleibenden Bytes. Eine separate Krücke ist demselben ZLP zugeordnet und die Notwendigkeit, auf einige Anfragen mit einem leeren Paket zu antworten. In diesem Fall wird das Ende der Übertragung durch die Tatsache angezeigt, dass die Datenadresse NULL geworden ist. Und ein leeres Paket - dass es gleich der ZLPP-Konstante ist. Beide treten auf, wenn die Größe gleich Null ist, sodass keine tatsächliche Aufzeichnung erfolgt.
Ein ähnlicher Algorithmus muss implementiert werden, wenn mit anderen Endpunkten gearbeitet wird. Dies ist jedoch das Anliegen des Benutzers. Und die Logik ihrer Arbeit unterscheidet sich oft von der Arbeit mit ep0. In einigen Fällen ist diese Option daher bequemer als das Puffern auf Bibliotheksebene.
USB-Kommunikationslogik
Der Host bestimmt die Tatsache der Verbindung durch das Vorhandensein eines Pull-up-Widerstands zwischen einer Datenleitung und der Stromversorgung. Er setzt das Gerät zurück, weist ihm eine Adresse auf dem Bus zu und versucht festzustellen, was genau darin steckt. Zu diesem Zweck werden Geräte- und Konfigurationsdeskriptoren (und gegebenenfalls bestimmte) gelesen. Er kann auch die Zeichenfolgendeskriptoren lesen, um zu verstehen, wie sich das Gerät selbst nennt (obwohl er es vorziehen würde, die Zeilen aus seiner Datenbank zu ziehen, wenn ihm das Paar VID: PID bekannt ist). Danach kann der Host den entsprechenden Treiber laden und mit dem Gerät in einer Sprache arbeiten, die er versteht. Die Sprache, die es versteht, umfasst bestimmte Anforderungen und Aufrufe an bestimmte Schnittstellen und Endpunkte. Wir werden auch darauf zurückkommen, aber zuerst muss das Gerät mindestens im System angezeigt werden.
Verarbeitung von SETUP-Anforderungen: DeviceDescriptor
Eine Person, die zumindest ein wenig an USB herumgebastelt hat, sollte lange Zeit vorsichtig sein: COKPOWEHEU, Sie sprechen von IN- und OUT-Anfragen, aber SETUP ist auch im Standard festgelegt. Ja, aber es ist eher eine Art OUT-Anfrage, die speziell strukturiert ist und ausschließlich für Endpunkt 0 bestimmt ist. Lassen Sie uns über die Struktur und die Merkmale der Arbeit sprechen.
Die Struktur selbst sieht folgendermaßen aus:
typedef struct{
uint8_t bmRequestType;
uint8_t bRequest;
uint16_t wValue;
uint16_t wIndex;
uint16_t wLength;
}config_pack_t;
Die Felder dieser Struktur werden in vielen Quellen berücksichtigt, aber ich werde Sie trotzdem daran erinnern.
bmRequestType ist eine Bitmaske, deren Bits Folgendes bedeuten:
7: Übertragungsrichtung. 0 - von Host zu Gerät, 1 - von Gerät zu Host. Tatsächlich ist es der Typ der nächsten Übertragung, OUT oder IN.
6-5: Anforderungsklasse
0x00 (USB_REQ_STANDARD) - Standard (wir werden sie
vorerst nur verarbeiten) 0x20 (USB_REQ_CLASS) - klassenspezifisch (wir werden sie in den nächsten Artikeln behandeln)
0x40 (USB_REQ_VENDOR) - herstellerspezifisch ( Ich hoffe, wir müssen sie nicht berühren)
4-0: Gesprächspartner
0x00 (USB_REQ_DEVICE) - Gerät als Ganzes
0x01 (USB_REQ_INTERFACE) - separate Schnittstelle
0x02 (USB_REQ_ENDPOINT) -
bRequest-Endpunkt -
wValue- Anforderung selbst - kleines 16-Bit-Datenfeld. Bei einfachen Anfragen, um keine vollwertigen Transfers zu fahren.
wIndex ist die Nummer des Empfängers. Zum Beispiel die Schnittstelle, mit der der Host kommunizieren möchte.
wLength - Die Größe der zusätzlichen Daten, wenn 16 Bit wValue nicht ausreichen.
Beim Anschließen eines Geräts versucht der Host zunächst herauszufinden, was genau darin steckt. Zu diesem
Zweck wird eine Anforderung mit den folgenden Daten gesendet : bmRequestType = 0x80 (Leseanforderung) + USB_REQ_STANDARD (Standard) + USB_REQ_DEVICE (an das gesamte Gerät)
bRequest = 0x06 (GET_DESCRIPTOR) - Deskriptoranforderung
wValue = 0x0100 (DEVICE_DESCRIPTOR) - Gerätedeskriptor insgesamt
wIndex = 0 - nicht verwendet
wLength = 0 - keine zusätzlichen Daten
Dann sendet es eine IN-Anfrage, wo das Gerät die Antwort stellen soll. Wie wir uns erinnern, sind die IN-Anforderung vom Host und der Controller-Interrupt lose gekoppelt, sodass wir die Antwort sofort in den ep0-Senderpuffer schreiben. Theoretisch sind die Daten aus diesem und allen anderen Deskriptoren an ein bestimmtes Gerät gebunden, sodass es keinen Sinn macht, sie in den Kern der Bibliothek zu stellen. Die entsprechenden Anforderungen werden an die Funktion usb_class_get_std_descr übergeben, die einen Zeiger auf den Anfang der Daten und ihre Größe an den Kernel zurückgibt. Der Punkt ist, dass einige Deskriptoren eine variable Größe haben können. Aber DEVICE_DESCRIPTOR gehört nicht dazu. Seine Größe und Struktur sind standardisiert und sehen folgendermaßen aus:
uint8_t bLength; //
uint8_t bDescriptorType; // . USB_DESCR_DEVICE (0x01)
uint16_t bcdUSB; // 0x0110 usb-1.1, 0x0200 2.0.
uint8_t bDeviceClass; //
uint8_t bDeviceSubClass; //
uint8_t bDeviceProtocol; //
uint8_t bMaxPacketSize0; // ep0
uint16_t idVendor; // VID
uint16_t idProduct; // PID
uint16_t bcdDevice_Ver; // BCD-
uint8_t iManufacturer; //
uint8_t iProduct; //
uint8_t iSerialNumber; //
uint8_t bNumConfigurations; // ( 1)
Achten Sie zunächst auf die ersten beiden Felder - die Größe des Deskriptors und seinen Typ. Sie sind typisch für fast alle USB-Deskriptoren (außer vielleicht für HID). Wenn bDescriptorType eine Konstante ist, muss bLength für jeden Deskriptor fast manuell gezählt werden. Irgendwann wurde ich es leid und ein Makro wurde geschrieben
#define ARRLEN1(ign, x...) (1+sizeof((uint8_t[]){x})), x
Es berechnet die Größe der übergebenen Argumente und ersetzt sie anstelle der ersten. Tatsache ist, dass Deskriptoren manchmal verschachtelt sind, so dass beispielsweise eine Größe im ersten Byte, eine andere in 3 und 4 (16-Bit-Nummer) und die dritte in 6 und 7 (wiederum eine 16-Bit-Nummer) erforderlich ist. . Makros kümmern sich nicht um die genauen Werte der Argumente, aber zumindest sollte die Anzahl gleich sein. Eigentlich gibt es auch Makros für die Substitution in 1, in 3 und 4 sowie in 6 und 7 Bytes, aber ich werde ihre Anwendung anhand eines typischeren Beispiels zeigen.
Schauen wir uns zunächst 16-Bit-Felder wie VID und PID an. Es ist klar, dass das Mischen von 8-Bit- und 16-Bit-Konstanten in einem Array nicht funktioniert, plus Endiannes ... im Allgemeinen helfen Makros wieder: USB_U16 (x).
In Bezug auf die VID-Auswahl: PID ist eine schwierige Frage. Wenn Sie vorhaben, Massenprodukte herzustellen, lohnt es sich dennoch, ein persönliches Paar zu kaufen. Für den persönlichen Gebrauch können Sie die Daten anderer Personen von einem ähnlichen Gerät abholen. Angenommen, ich habe in meinen Beispielen Paare von AVR LUFA und STM. Auf jeden Fall ermittelt der Host bestimmte Implementierungsfehler und nicht die Zuweisung aus diesem Paar. Denn der Zweck des Gerätes wird in einem speziellen Deskriptor ausführlich beschrieben.
Achtung, Rechen!Wie sich herausstellte, bindet Windows Treiber an dieses Paar, dh Sie haben beispielsweise das HID-Gerät zusammengebaut, das System gezeigt und die Treiber installiert. Und dann haben wir das Gerät unter MSD (Flash-Laufwerk) erneut geflasht, ohne die VID: PID zu ändern. Dann bleiben die Treiber alt und das Gerät funktioniert natürlich nicht. Wir müssen in die "Hardwareverwaltung" gehen, Treiber entfernen und das System zwingen, neue zu finden. Ich denke, es wird niemanden überraschen, dass Linux dieses Problem nicht hat: Die Geräte werden einfach angeschlossen und funktionieren.
StringDescriptor
Ein weiteres interessantes Merkmal von USB-Deskriptoren ist die Liebe zu Strings. In der Deskriptorvorlage werden sie mit dem Präfix i gekennzeichnet, z. B. iSerialNumber
Achtung, Rechen! Egal wie groß die Versuchung ist, nur einen String in iSerialNumber zu stecken, sogar einen String mit einer ehrlichen Version wie u``1.2.3 '' - tu es nicht! Einige Betriebssysteme glauben, dass es nur hexadezimale Ziffern geben sollte, dh '0' - '9', 'A' - 'Z' und das war's. Sie können nicht einmal Punkte. Wahrscheinlich zählen sie irgendwie den Hash von dieser "Nummer", um ihn beim erneuten Verbinden zu identifizieren, ich weiß es nicht. Beim Testen auf einer virtuellen Maschine mit Windows 7 bemerkte ich jedoch ein solches Problem. Sie betrachtete das Gerät als defekt. Interessanterweise haben Windows XP und 10 das Problem nicht bemerkt.
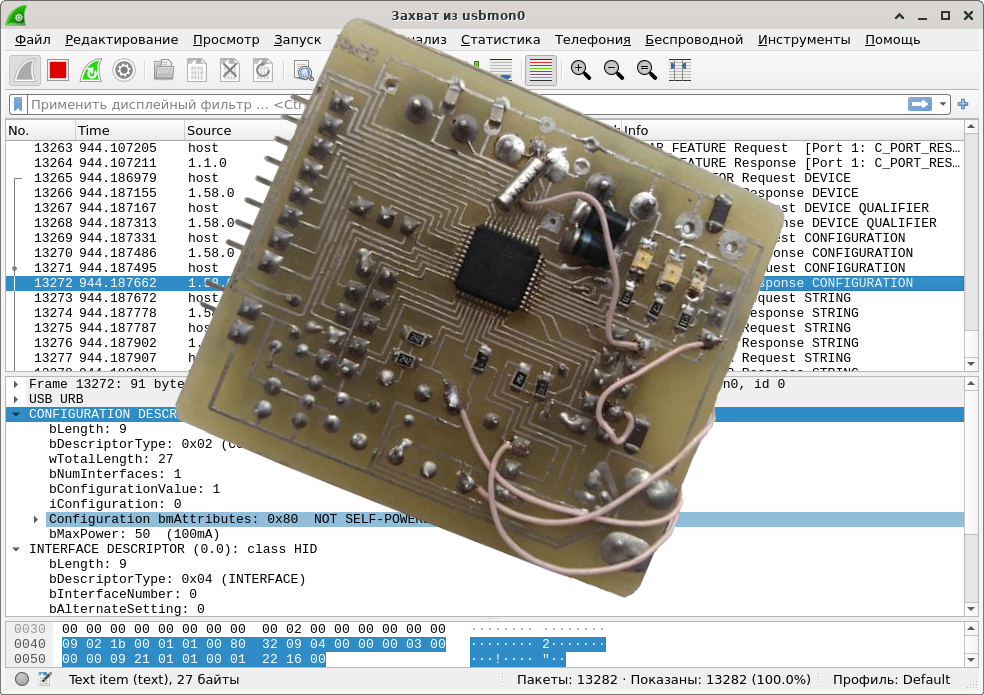
Konfigurationsdeskriptor
Aus Sicht des Hosts stellt das Gerät eine Reihe separater Schnittstellen dar, von denen jede zur Lösung eines Problems ausgelegt ist. Ein Schnittstellendeskriptor beschreibt das Gerät und die zugehörigen Endpunkte. Ja, Endpunkte werden nicht selbst beschrieben, sondern nur als Teil der Schnittstelle. In der Regel werden Schnittstellen mit einer komplexen Architektur durch SETUP-Anforderungen (dh bis ep0) gesteuert, in denen das Feld wIndex der Schnittstellennummer entspricht. Das Maximum darf den Endpunkt für Interrupts einstecken. Von den Datenschnittstellen benötigt der Host nur Beschreibungen der Endpunkte, und der Austausch wird diese durchlaufen.
Es können viele und sehr unterschiedliche Schnittstellen in einem Gerät vorhanden sein. Um nicht zu verwechseln, wo eine Schnittstelle endet und eine andere beginnt, gibt der Deskriptor daher nicht nur die Größe des "Headers" an, sondern auch separat (normalerweise 3-4 Bytes) die volle Größe der Schnittstelle. Somit faltet sich die Benutzeroberfläche wie eine Schachtelpuppe: In einem gemeinsamen Container (in dem die Größe des "Titels", des bDescriptorType und die volle Größe des Inhalts einschließlich des Titels gespeichert sind) können einige kleinere Container vorhanden sein, die jedoch in angeordnet sind in der gleichen Weise. Und drinnen immer mehr. Hier ist ein Beispiel für einen Deskriptor für ein primitives HID-Gerät:
static const uint8_t USB_ConfigDescriptor[] = {
ARRLEN34(
ARRLEN1(
bLENGTH, // bLength: Configuration Descriptor size
USB_DESCR_CONFIG, //bDescriptorType: Configuration
wTOTALLENGTH, //wTotalLength
1, // bNumInterfaces
1, // bConfigurationValue: Configuration value
0, // iConfiguration: Index of string descriptor describing the configuration
0x80, // bmAttributes: bus powered
0x32, // MaxPower 100 mA
)
ARRLEN1(
bLENGTH, //bLength
USB_DESCR_INTERFACE, //bDescriptorType
0, //bInterfaceNumber
0, // bAlternateSetting
0, // bNumEndpoints
HIDCLASS_HID, // bInterfaceClass:
HIDSUBCLASS_NONE, // bInterfaceSubClass:
HIDPROTOCOL_NONE, // bInterfaceProtocol:
0x00, // iInterface
)
ARRLEN1(
bLENGTH, //bLength
USB_DESCR_HID, //bDescriptorType
USB_U16(0x0101), //bcdHID
0, //bCountryCode
1, //bNumDescriptors
USB_DESCR_HID_REPORT, //bDescriptorType
USB_U16( sizeof(USB_HIDDescriptor) ), //wDescriptorLength
)
)
};
Hier ist die Verschachtelungsebene klein und es wird kein einziger Endpunkt beschrieben - also habe ich versucht, ein einfacheres Gerät auszuwählen. Einige Verwirrung kann hier durch die Konstanten bLENGTH und wTOTALLENGTH verursacht werden, die acht- und sechzehn-Bit-Nullen entsprechen. Da in diesem Fall Makros zur Berechnung der Größe verwendet werden, wäre es seltsam, ihre Arbeit zu duplizieren und Bytes von Hand zu zählen. Wie seltsam es ist, Nullen zu schreiben. Und Konstanten sind eine bemerkenswerte Sache, die zur Klarheit des Codes beiträgt.
Wie Sie sehen können, besteht dieser Deskriptor aus dem USB_DESCR_CONFIG- "Header" (der die gesamte Größe des Inhalts einschließlich sich selbst speichert!), Der USB_DESCR_INTERFACE-Schnittstelle (die die Details des Geräts beschreibt) und USB_DESCR_HID, die im Allgemeinen angeben, welche Art von HID wir rendern. Und genau das im Allgemeinen: Eine bestimmte HID-Struktur wird in einem speziellen Deskriptor HID_REPORT_DESCRIPTOR beschrieben, den ich hier nicht berücksichtigen werde, einfach weil ich es zu schlecht kenne. Wir beschränken uns daher auf das Kopieren und Einfügen aus einem Beispiel .
Kehren wir zu den Schnittstellen zurück. Angesichts der Tatsache, dass sie Nummern haben, ist es logisch anzunehmen, dass ein Gerät viele Schnittstellen enthalten kann. Darüber hinaus können sie sowohl für eine gemeinsame Aufgabe (z. B. die USB-CDC-Steuerschnittstelle und die Datenschnittstelle) als auch für grundsätzlich nicht zusammenhängende Aufgaben verantwortlich sein. Angenommen, nichts hindert uns (außer dem bisherigen Mangel an Wissen) daran, auf einem Controller zwei USB-CDC-Adapter sowie ein USB-Flash-Laufwerk und beispielsweise eine Tastatur zu implementieren. Offensichtlich kennt die Schnittstelle des Flash-Laufwerks den COM-Anschluss nicht. Hier gibt es jedoch Fallstricke, die wir hoffentlich eines Tages in Betracht ziehen werden. Es ist auch erwähnenswert, dass eine Schnittstelle mehrere alternative Konfigurationen (bAlternateSetting) haben kann, die sich beispielsweise in der Anzahl der Endpunkte oder der Häufigkeit ihrer Abfrage unterscheiden. Eigentlich wurde es deshalb so gemacht: Wenn der Host der Meinung ist, dass es besser ist, die Bandbreite zu sparen,Er kann die Benutzeroberfläche auf einen alternativen Modus umschalten, den er am liebsten mag.
Kommunikation mit HID
Im Allgemeinen simulieren HID-Geräte Objekte der realen Welt, die weniger Daten als eine Reihe bestimmter Parameter enthalten, die gemessen oder eingestellt werden können (SET_REPORT / GET_REPORT-Anforderungen) und die den Host über ein plötzliches externes Ereignis benachrichtigen können (INTERRUPT). Tatsächlich sind diese Geräte also nicht für den Datenaustausch gedacht ... aber wer hat sie wann gestoppt?
Wir werden Interrupts vorerst nicht ansprechen, da sie einen speziellen Endpunkt benötigen. Wir werden jedoch das Lesen und Einstellen von Parametern in Betracht ziehen. In diesem Fall gibt es nur einen Parameter, nämlich eine Struktur aus zwei Bytes, die konstruktionsbedingt für zwei LEDs oder für eine Taste und einen Zähler verantwortlich sind.
Beginnen wir mit einem einfacheren - Lesen auf Anfrage HIDREQ_GET_REPORT. Tatsächlich ist dies dieselbe Anforderung wie bei jedem DEVICE_DESCRIPTOR, nur spezifisch für die HID. Außerdem richtet sich diese Anforderung nicht an das gesamte Gerät, sondern an die Schnittstelle. Das heißt, wenn wir mehrere unabhängige HID-Geräte in einem Gerät implementiert haben, können diese durch das wIndex-Feld der Anforderung unterschieden werden. Dies ist zwar nicht der beste Ansatz speziell für HID: Es ist einfacher, den Deskriptor selbst zusammenzusetzen. In jedem Fall sind wir weit von solchen Perversionen entfernt, sodass wir nicht einmal analysieren werden, was und wohin der Host zu senden versucht hat: Bei jeder Anforderung an die Schnittstelle und mit dem Feld bRequest gleich HIDREQ_GET_REPORT geben wir die tatsächlichen Daten zurück. Theoretisch soll dieser Ansatz Deskriptoren (mit allen bLength- und bDescriptorType-Werten) zurückgeben. Im Fall von HID haben die Entwickler jedoch beschlossen, alles zu vereinfachen und nur Daten auszutauschen.Wir geben also einen Zeiger auf unsere Struktur und ihre Größe zurück. Nun, ein wenig zusätzliche Logik wie Verarbeitungsschaltflächen und ein Anforderungszähler.
Ein komplexerer Fall ist eine Schreibanforderung. Dies ist das erste Mal, dass wir in einer SETUP-Anforderung auf zusätzliche Daten stoßen. Das heißt, der Kern unserer Bibliothek muss zuerst die Anforderung selbst und erst dann die Daten lesen. Und übertragen Sie sie auf die Benutzerfunktion. Und ich erinnere Sie daran, dass wir keinen Puffer haben. Als Ergebnis einer Magie auf niedriger Ebene wurde der folgende Algorithmus entwickelt. Rückruf wird immer aufgerufen, aber wir werden ihm mitteilen, von welchem Byte sich die Daten jetzt im Endpunkt-Empfangspuffer befinden (Offset) und wie groß diese Daten sind (Größe). Das heißt, wenn die Anforderung selbst empfangen wird, sind die Offset- und Größenwerte Null (es gibt keine Daten). Wenn das erste Paket empfangen wird, ist der Versatz immer noch Null und die Größe ist die Größe der empfangenen Daten. Zum zweiten entspricht der Versatz der Größe von ep0 (denn wenn die Daten aufgeteilt werden mussten, erfolgt dies entsprechend der Größe des Endpunkts), und die Größe entspricht der Größe der empfangenen Daten.Usw. Wichtig! Wenn die Daten akzeptiert werden, müssen sie gelesen werden. Dies kann entweder durch den Handler erfolgen, indem er usb_ep_read () aufruft und 1 zurückgibt (sie sagen "Ich dachte selbst, mach dir keine Sorgen") oder einfach 0 zurückgibt ("Ich brauche diese Daten nicht"), ohne zu lesen - dann kümmert sich der Bibliothekskern um die Reinigung. Die Funktion basiert auf diesem Prinzip: Sie prüft, ob die Daten verfügbar sind, liest sie gegebenenfalls und leuchtet auf.
Datenaustausch-Software
Hier habe ich das Rad nicht neu erfunden, sondern ein fertiges Programm aus dem vorherigen Artikel übernommen .
Fazit
Das ist in der Tat alles. Ich habe die Grundlagen der Arbeit mit USB mit einem Hardwaremodul in STM32 erklärt und auch einen Rechen berührt. Angesichts der viel geringeren Menge an Code als des Horrors, den STMCube erzeugt, wird es einfacher sein, dies herauszufinden. Tatsächlich habe ich es bei Würfelnudeln immer noch nicht herausgefunden, es gibt zu viele Aufrufe derselben Sache in verschiedenen Kombinationen. Viel besser, um die Option von EddyEm zu verstehen , von der ich ausgegangen bin. Natürlich gibt es nicht ohne Pfosten, aber zumindest ist es zum Verständnis geeignet. Ich rühme mich auch, dass die Größe meiner Version fast fünfmal kleiner ist als die von ST (~ 2,7 kB gegenüber 14) - trotz der Tatsache, dass ich nicht an der Optimierung beteiligt war und Sie sie natürlich immer noch verkleinern können.
Ich möchte auch auf den Unterschied im Verhalten verschiedener Betriebssysteme beim Anschließen fragwürdiger Geräte hinweisen. Linux funktioniert auch dann, wenn die Deskriptoren fehlerhaft sind. Windows XP, 7, 10, beim geringsten Fehler schwören sie, dass "das Gerät kaputt ist, ich weigere mich, damit zu arbeiten." Und XP fiel manchmal sogar in BSOD aus Empörung. Oh ja, sie zeigen auch ständig an "das Gerät kann schneller arbeiten", ich weiß nicht, was ich dagegen tun soll. Unabhängig davon, wie gut Linux für die Entwicklung ist, verzeiht es im Allgemeinen zu viel. Es ist notwendig, auf weniger benutzerfreundlichen Systemen zu testen.
Weitere Pläne: Andere Arten von Endpunkten berücksichtigen (bisher gab es nur ein Beispiel mit Control). Betrachten Sie andere Controller (sagen wir, ich habe noch at90usb162 (AVR) und gd32vf103 (RISC_V) herumliegen), aber dies sind sehr weit entfernte Pläne. Es wäre auch schön, einzelne USB-Geräte wie die gleichen HIDs genauer zu betrachten, aber auch keine vorrangige Aufgabe.