
Es gibt viele Ansätze zum Erstellen von Anwendungscode, um zu verhindern, dass die Projektkomplexität im Laufe der Zeit zunimmt. Der objektorientierte Ansatz und viele angehängte Muster ermöglichen es beispielsweise, die Komplexität des Projekts nicht auf dem gleichen Niveau zu halten, es zumindest während der Entwicklung unter Kontrolle zu halten und den Code dem neuen Programmierer im Team zur Verfügung zu stellen.
Wie können Sie die Komplexität eines ETL-Transformationsprojekts auf Spark verwalten?
Es ist nicht so einfach.
Wie sieht es im wirklichen Leben aus? Der Kunde bietet an, eine Anwendung zu erstellen, die eine Storefront sammelt. Es scheint notwendig zu sein, den Code über Spark SQL auszuführen und das Ergebnis zu speichern. Während der Entwicklung stellt sich heraus, dass für die Erstellung dieses Marts 20 Datenquellen erforderlich sind, von denen 15 ähnlich sind, der Rest jedoch nicht. Diese Quellen müssen kombiniert werden. Außerdem stellt sich heraus, dass Sie für die Hälfte von ihnen Ihre eigenen Montage-, Reinigungs- und Normalisierungsverfahren schreiben müssen.
Und ein einfaches Schaufenster sieht nach einer detaillierten Beschreibung ungefähr so aus:
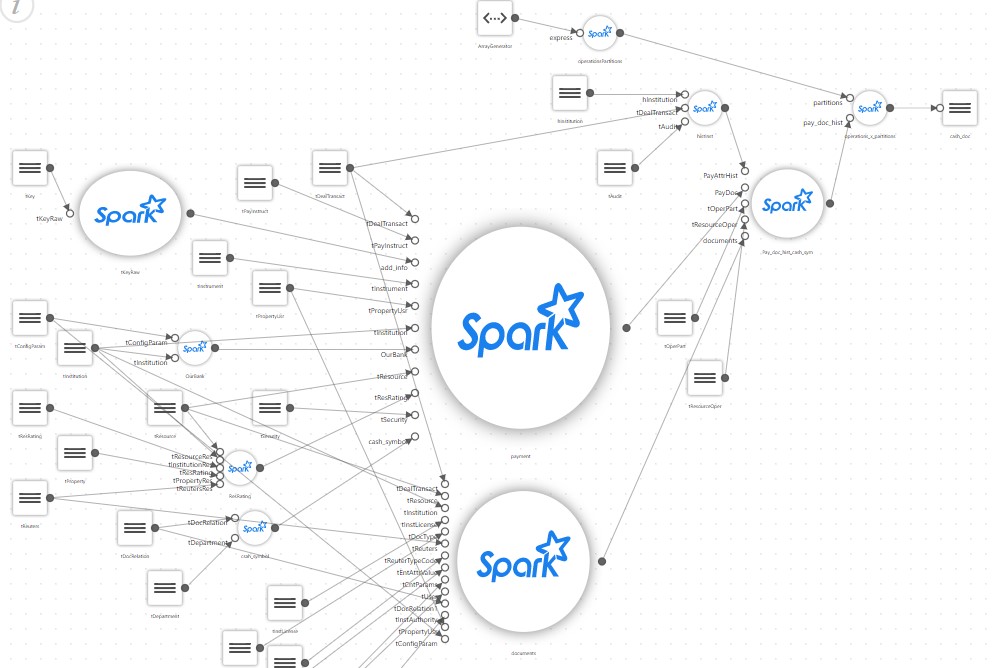
Als Ergebnis erhält ein einfaches Projekt, das nur ein SQL-Skript ausführen sollte, das das Schaufenster auf Spark sammelt, einen eigenen Konfigurator, einen Block zum Lesen einer großen Anzahl von Konfigurationsdateien, einen eigenen Zuordnungszweig und Übersetzer einiger Sonderregeln usw.
In der Mitte des Projekts stellt sich heraus, dass nur der Autor den resultierenden Code unterstützen kann. Und er verbringt die meiste Zeit in Gedanken. In der Zwischenzeit bittet der Kunde, ein paar weitere Vitrinen zu sammeln, die wiederum auf Hunderten von Quellen basieren. Gleichzeitig müssen wir uns daran erinnern, dass Spark im Allgemeinen nicht sehr gut zum Erstellen eigener Frameworks geeignet ist.
Zum Beispiel ist Spark so konzipiert, dass der Code ungefähr so aussieht (Pseudocode):
park.sql(“select table1.field1 from table1, table2 where table1.id = table2.id”).write(...pathToDestTable)
Stattdessen müssen Sie so etwas tun:
var Source1 = readSourceProps(“source1”) var sql = readSQL(“destTable”) writeSparkData(source1, sql)
Nehmen Sie also Codeblöcke in separate Prozeduren heraus und versuchen Sie, etwas Eigenes, Universelles zu schreiben, das durch Einstellungen angepasst werden kann.
Gleichzeitig bleibt die Komplexität des Projekts natürlich auf dem gleichen Niveau, jedoch nur für den Autor des Projekts und nur für kurze Zeit. Jeder eingeladene Programmierer wird lange brauchen, um es zu beherrschen, und die Hauptsache ist, dass es nicht funktioniert, Leute, die nur SQL kennen, für das Projekt zu gewinnen.
Dies ist bedauerlich, da Spark selbst eine großartige Möglichkeit ist, ETL-Anwendungen für diejenigen zu entwickeln, die nur SQL kennen.
Und im Verlauf der Projektentwicklung stellte sich heraus, dass aus einer einfachen Sache eine komplexe wurde.
Stellen Sie sich nun ein reales Projekt vor, in dem es Dutzende oder sogar Hunderte solcher Schaufenster wie auf dem Bild gibt und die unterschiedliche Technologien verwenden. Einige davon können beispielsweise auf dem Parsen von XML-Daten und andere auf Streaming-Daten basieren.
Ich möchte die Komplexität des Projekts irgendwie auf einem akzeptablen Niveau halten. Wie kann das gemacht werden?
Die Lösung kann darin bestehen, einen Tool- und Low-Code-Ansatz zu verwenden, wenn die Entwicklungsumgebung für Sie entscheidet, was die gesamte Komplexität in Anspruch nimmt und einen praktischen Ansatz bietet, wie er beispielsweise in diesem Artikel beschrieben wird .
Dieser Artikel beschreibt die Ansätze und Vorteile der Verwendung des Tools zur Lösung dieser Art von Problemen. Insbesondere bietet Neoflex eine eigene Lösung Neoflex Datagram an, die von verschiedenen Kunden erfolgreich eingesetzt wird.
Es ist jedoch nicht immer möglich, eine solche Anwendung zu verwenden.
Was ist zu tun?
In diesem Fall verwenden wir einen Ansatz, der üblicherweise Orc - Object Spark oder Orka genannt wird, wie Sie möchten.
Die anfänglichen Daten lauten wie folgt:
Es gibt einen Kunden, der einen Arbeitsplatz mit einem Standardsatz von Tools bereitstellt, nämlich: Farbton für die Entwicklung von Python- oder Scala-Code, Farbtoneditoren für das SQL-Debugging über Hive oder Impala und Oozie-Workflow-Editor. Dies ist nicht viel, aber völlig ausreichend, um Probleme zu lösen. Es ist aus verschiedenen Gründen unmöglich, der Umgebung etwas hinzuzufügen, es ist unmöglich, neue Tools zu installieren.
Wie entwickeln Sie ETL-Anwendungen, die wie üblich zu einem großen Projekt werden, an dem Hunderte von Datenquellentabellen und Dutzende von Ziel-Marts beteiligt sind, ohne an Komplexität zu ertrinken und nicht zu viel zu schreiben?
Eine Reihe von Bestimmungen wird verwendet, um das Problem zu lösen. Sie sind keine eigene Erfindung, sondern basieren vollständig auf der Architektur von Spark.
- Alle komplexen Verknüpfungen, Berechnungen und Transformationen werden über Spark SQL ausgeführt. Der Spark SQL-Optimierer verbessert sich mit jeder Version und funktioniert sehr gut. Daher geben wir dem Optimierer die gesamte Arbeit zur Berechnung von Spark SQL. Das heißt, unser Code basiert auf der SQL-Kette, in der Schritt 1 die Daten vorbereitet, Schritt 2 beitritt, Schritt 3 berechnet und so weiter.
- Spark, Spark SQL. (DataFrame) Spark SQL.
- Spark Directed Acicled Graph, , , , , 2, 2.
- Spark lazy, , , .
Dadurch kann die gesamte Anwendung sehr einfach gestaltet werden.
Es reicht aus, eine Konfigurationsdatei zu erstellen, in der eine einstufige Liste von Datenquellen definiert wird. Diese sequentielle Liste von Datenquellen ist das Objekt, das die Logik der gesamten Anwendung beschreibt.
Jede Datenquelle enthält einen Link zu SQL. In SQL können Sie für die aktuelle Quelle eine Quelle verwenden, die sich nicht in Hive befindet, sondern in der Konfigurationsdatei über der aktuellen beschrieben ist.
Zum Beispiel sieht Quelle 2, wenn sie in Spark-Code übersetzt wird, ungefähr so aus (Pseudocode):
var df = spark.sql(“select * from t1”); df.saveAsTempTable(“source2”);
Und Quelle 3 könnte bereits so aussehen:
var df = spark.sql(“select count(*) from source2”) df.saveAsTempTable(“source3”);
Das heißt, Quelle 3 sieht alles, was zuvor berechnet wurde.
Für Quellen, bei denen es sich um Zielvitrinen handelt, müssen Sie die Parameter zum Speichern dieser Zielvitrine angeben.
Infolgedessen sieht die Anwendungskonfigurationsdatei folgendermaßen aus:
[{name: “source1”, sql: “select * from t1”}, {name: “source2”, sql: “select count(*) from source1”}, ... {name: “targetShowCase1”, sql: “...”, target: True, format: “PARQET”, path: “...”}]
Und der Anwendungscode sieht ungefähr so aus:
List = readCfg(...) For each source in List: df = spark.sql(source.sql).saveAsTempTable(source.name) If(source.target == true) { df.write(“format”, source.format).save(source.path) }
Dies ist in der Tat die gesamte Anwendung. Außer einem Moment ist nichts anderes erforderlich.
Wie kann man das alles debuggen?
Immerhin ist der Code selbst in diesem Fall sehr einfach, was zum Debuggen da ist, aber die Logik dessen, was getan wird, wäre schön zu überprüfen. Das Debuggen ist sehr einfach - Sie müssen alle Anwendungen bis zur überprüften Quelle durchgehen. Dazu müssen Sie dem Oozie-Workflow einen Parameter hinzufügen, mit dem Sie die Anwendung an der erforderlichen Datenquelle stoppen können, indem Sie das Schema und den Inhalt in das Protokoll drucken.
Wir haben diesen Ansatz Object Spark in dem Sinne genannt, dass die gesamte Anwendungslogik vom Spark-Code entkoppelt und in einer einzigen, ziemlich einfachen Konfigurationsdatei gespeichert ist, bei der es sich um das Anwendungsbeschreibungsobjekt handelt.
Der Code bleibt einfach und nach seiner Erstellung können auch komplexe Storefronts mit Programmierern entwickelt werden, die nur SQL kennen.
Der Entwicklungsprozess ist sehr einfach. Zu Beginn ist ein erfahrener Spark-Programmierer beteiligt, der universellen Code erstellt. Anschließend wird die Anwendungskonfigurationsdatei bearbeitet, indem dort neue Quellen hinzugefügt werden.
Was dieser Ansatz bietet:
- Sie können SQL-Programmierer in die Entwicklung einbeziehen.
- Unter Berücksichtigung des Parameters in Oozie wird das Debuggen einer solchen Anwendung einfach und unkompliziert. Dies ist das Debuggen eines Zwischenschritts. Die Anwendung arbeitet alles bis zur gewünschten Quelle, berechnet es und stoppt;
- ( … ), , , , , . , Object Spark;
- , . . , , , XML JSON, -. , ;
- . , , , , .