
Heute werden wir über ein scheinbar einfaches Thema wie relationale und verwandte Daten sprechen.
Trotz all seiner Einfachheit stelle ich fest, dass die Leute manchmal wirklich verwirrt sind - ich habe beschlossen, dies zu beheben, indem ich eine kurze und informelle Erklärung darüber schreibe, was sie sind und warum sie gebraucht werden.
Wir werden das relationale Modell und die damit verbundene SQL- und relationale Algebra diskutieren. Kommen wir dann zu Beispielen verwandter Daten aus Wikidat und dann zu RDF, SPARQL und einem kleinen Vortrag über Datalog und logische Datendarstellung. Am Ende die Schlussfolgerungen - wann das relationale Modell anzuwenden ist und wann das vernetzte logische Modell.
Der Hauptzweck des Beitrags ist es zu beschreiben, wann und warum es sinnvoll ist, sich zu bewerben. Da es viele schwierige Konzepte gibt, die an einem Ort zusammengekommen sind, wäre es natürlich möglich, für jedes ein Buch zu schreiben - aber unsere heutige Aufgabe ist es, eine Vorstellung von dem Thema zu geben, und wir werden es informell anhand einfacher Beispiele analysieren.
Wenn Sie Zweifel haben, wie sich eine von der zweiten unterscheidet und warum Sie überhaupt verknüpfte Daten (LinkedData) benötigen, dann begrüßen Sie unter cat.

Relationale Daten
Beginnen wir mit einer Standarddefinition. Eine
relationale Datenbank ist eine Sammlung von Daten mit vordefinierten Beziehungen zwischen ihnen. Diese Daten sind als eine Reihe von Tabellen organisiert, die aus Spalten und Zeilen bestehen. In den Tabellen werden Informationen zu den in der Datenbank dargestellten Objekten gespeichert.
Bei Anwendung:
- Feste Domänenmodellierung
- Das Datenschema ändert sich entweder nur geringfügig oder die Änderungen wirken sich sofort auf eine signifikante Gruppe von Datensätzen aus
- Grundlegende Abfragen - Filtern von Kategorien nach Schlüsselfeldern von Datensätzen, Aggregation, Generieren von Berichten und Analysen basierend auf statistischen Indikatoren usw.
In dieser Situation ist die Modellierungseinheit die Tabelle und die Beziehungen zwischen den Tabellen (z. B. Fremdschlüssel). Tatsächlich ist eine Tabelle ein Prädikat mit festen Attributen, d.h. Wir kennen immer die Arität eines tabellarischen Prädikats.
Nehmen wir einen Fremdschlüssel als Beispiel für Einschränkungsbeziehungen: den Schlüssel „p (_, X, _) → q (_, Y, _)“, der Einschränkungen in der Form X \ Teilmenge Y festlegt, wobei X ein Attribut der p-Beziehung ist, und Y. Beziehungsattribut q.

Noch wichtiger ist, dass wir in der Welt der relationalen Daten alles in einer Tabelle haben! Und Operationen nehmen eine Tabelle als Eingabe und geben eine Tabelle zurück, zum Beispiel:

Relationale Datensprache: SQL und relationale Algebra
Relationale Algebra (Codd-Algebra) ist im Wesentlichen eine Reihe von Operationen für Tabellen, die Tabellen zurückgeben. Das heißt, für Sie ist das zentrale Element der Modellierung genau die festen Tabellen und ihre Transformationen.
Die SQL-Sprache ist eine deklarative Überstruktur und eine konkrete Umsetzung der Ideen der relationalen Algebra.
Ein Beispiel für eine einfache Abfrage und die entsprechenden Vergleichsoperatoren aus der Algebra.

Bisher haben wir nur die klassischen Dinge behandelt, die wir aus jedem Datenbankkurs kennen.
Verknüpfte Daten und Wissensgraphen
Stellen wir uns vor, was passiert, wenn wir neue Eigenschaften haben und dies möglicherweise in Echtzeit geschieht. Das heißt, die Domain ist nicht fixiert - sondern flexibel und erweiterbar ?
In einer solchen Situation können wir Tabellen natürlich Tabellen und Spalten hinzufügen, indem wir NULL- oder Standardwerte einfügen. Es ist nicht nur technisch unpraktisch, sondern auch aus modelltechnischer Sicht ein ungeeignetes Werkzeug.
Stellen Sie sich vor, Sie modellieren das Leben von Menschen in all seinen möglichen Aspekten. Sogar zwei verschiedene Personen haben ziemlich unterschiedliche Schlüsseleigenschaften, und das ist absolut normal!
Sie haben keine feste Liste, wie ein bestimmter Charakter beschrieben wird. Der Autor und der Fußballspieler sind zwei Personen, die viele wichtige, aber dennoch unterschiedliche Eigenschaften haben.
Beginnen wir hier mit dem Autor Douglas Adams - die Top-Eigenschaften sind für jeden ziemlich typisch - und außerdem verwenden wir Wikidata als Beispiel für LinkedData.
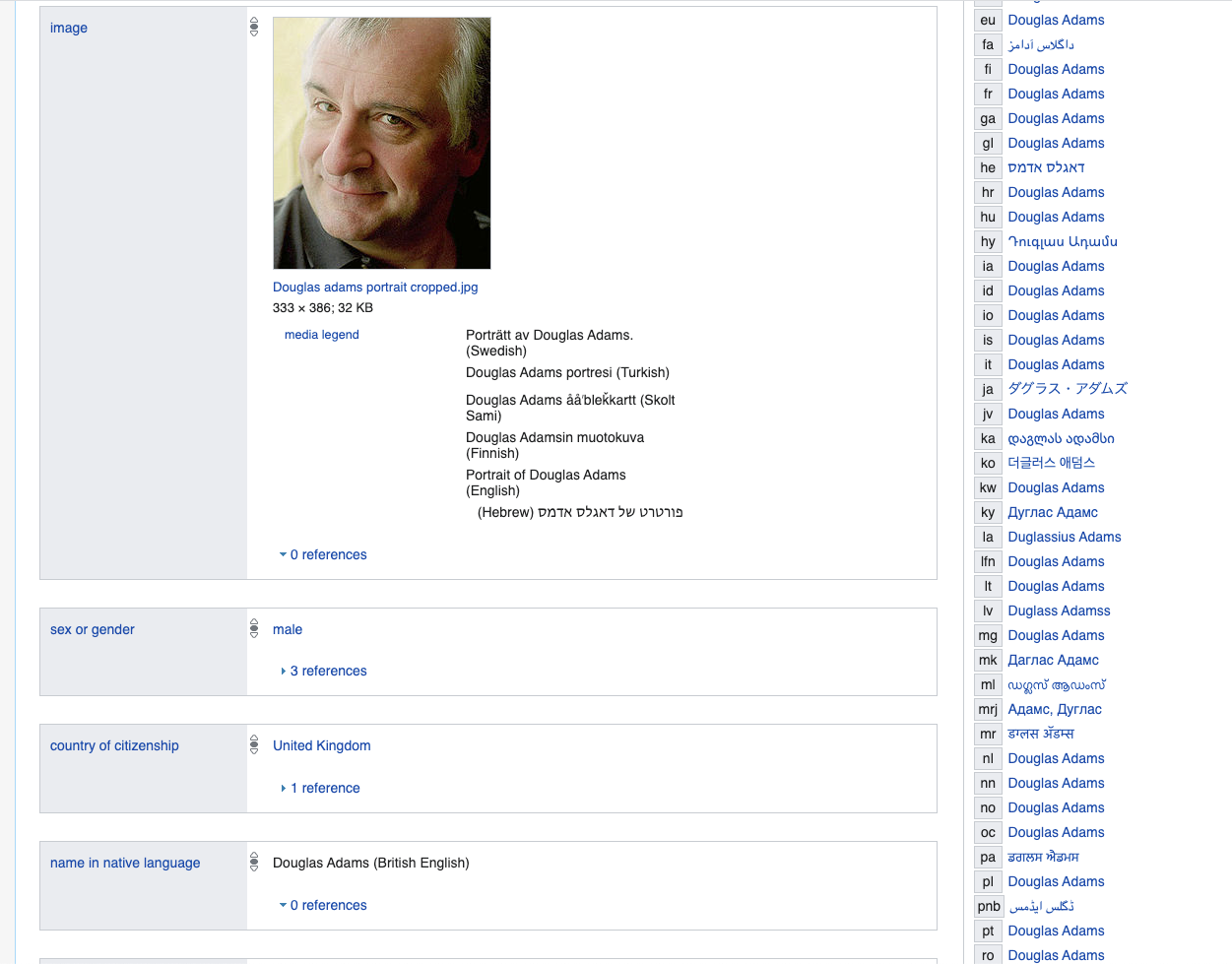
www.wikidata.org/wiki/Q42
Aber lassen Sie uns etwas tiefer gehen und
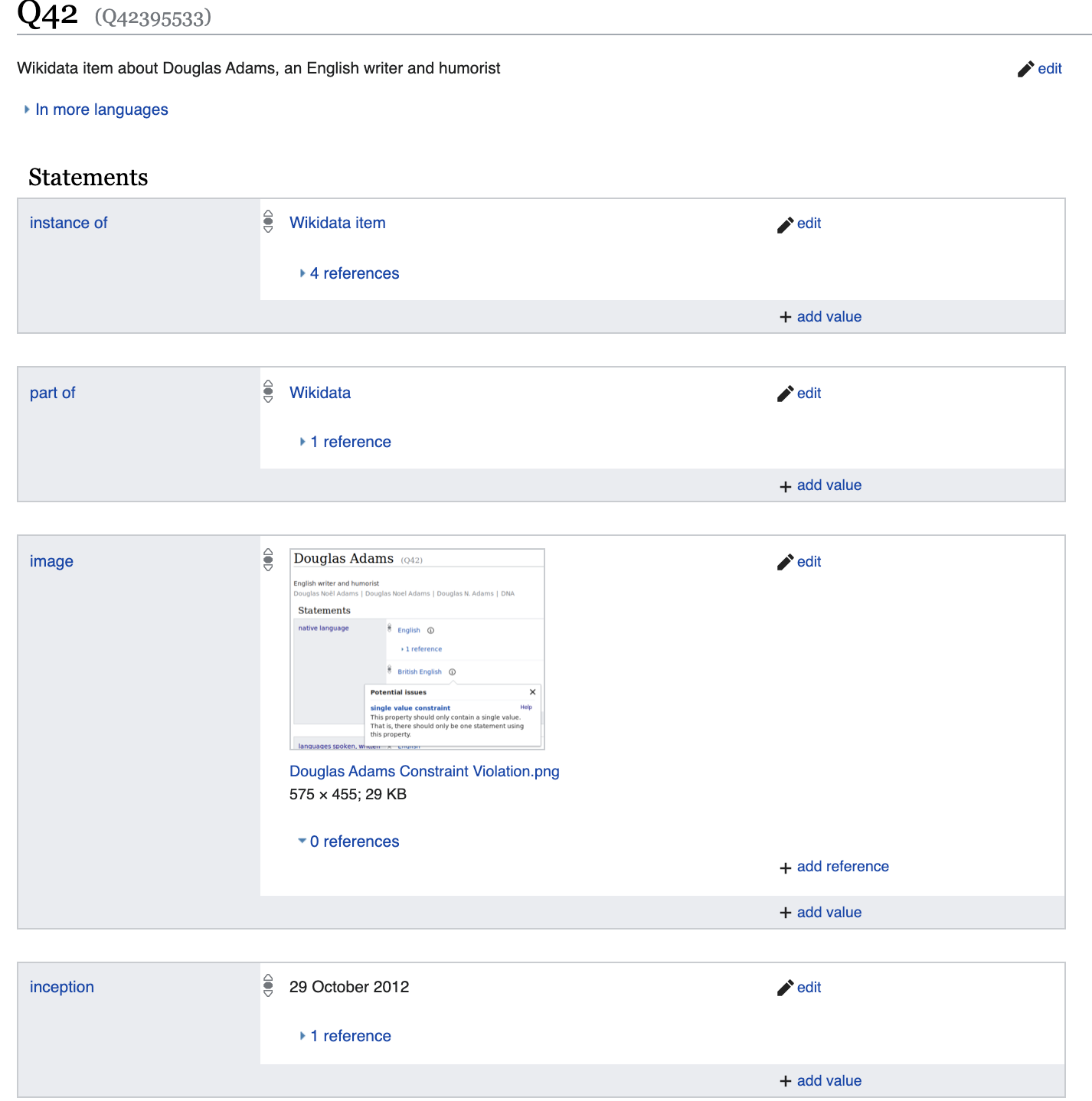
eine Reihe von Eigenschaften sehen, die sich erheblich von beispielsweise Diego Maradonna unterscheiden.
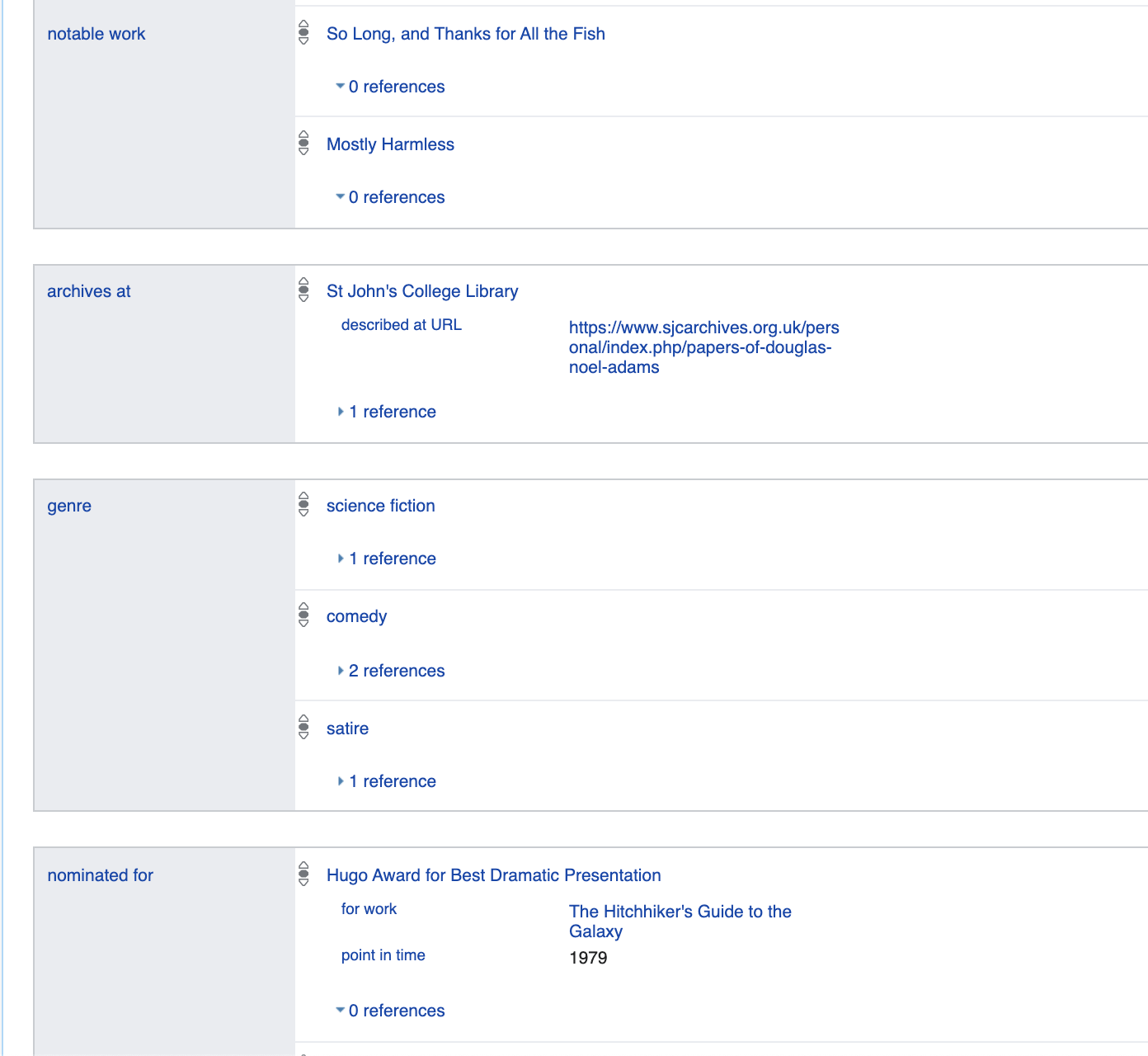
Lassen Sie uns etwas mehr über die hier angegebenen Eigenschaften sprechen. Zum Beispiel

spiegelt Geschlecht: Mann im Wesentlichen die logische Tatsache wider: p21 (Q42, Q6581097).
Wobei p21 → dies gender_identity / 2 ist - ein binäres Prädikat
Q42 → Douglas Adams
Q6581097 → männlich
Somit werden alle Daten entweder als unäre Prädikate dargestellt, zum Beispiel is_dead (Q42) oder als binäres p21 (Q42, Q6581097).
Tatsächlich ist dies ein weiteres Paradigmenparadigma der Modellierung - Logik erster Ordnung, jedoch auf unären und binären Prädikaten.
Und hier ist es sehr einfach, neue Daten hinzuzufügen: Alles, was nicht in Form eines Prädikats über Objekten angezeigt wird, ist falsch, in der Literatur wird dies als Annahme der geschlossenen Welt bezeichnet .
Darüber hinaus ermöglicht dieses Format eine absolut natürliche Metamodellierung
https://www.wikidata.org/wiki/Q42395533
Es gibt verschiedene grundlegende Speicher- und Schreibabfragen für solche Daten - schauen wir uns die beliebten Optionen an.
RDF und die SPARQL-Abfragesprache
RDF ist eine formale Sprache zur Beschreibung verwandter Daten für die nachfolgende Abfrageverarbeitung, dh ein maschinenlesbares Format.
Tatsächlich ist für ihn der Schlüssel das Konzept eines Tripletts:

Und hier ist ein Beispiel für die Datenaufzeichnung in diesem Modell (Präfixe bestimmen, wo die „Beschreibungen“ dieser Prädikate liegen).

Dieses Aufzeichnungsformat ermöglicht es Ihnen, Daten über Objekte grafisch darzustellen - zum Beispiel können Sie Informationen über die Stadt Berlin schreiben.

Für das RDF-Format haben sie die SPARQL-Abfragesprache erstellt: Diese beschreibt im Wesentlichen die Einschränkungen für logische Prädikate und gibt an, welche Variable aus dem logischen Ausdruck extrahiert werden soll:

Was wir eigentlich finden wollen, ist der Wert der Variablen? Land, so dass member_of wahr ist, dass member_of (? Country, q458) und q458 die EU-ID ist.
Im realen Code könnte dies folgendermaßen aussehen:
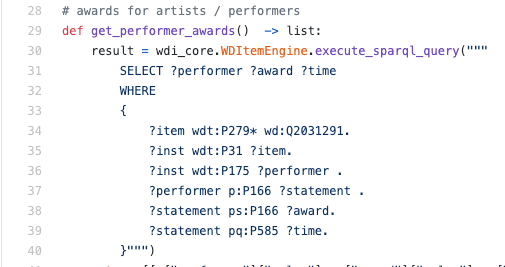
Total: RDF ist ein Format zur Darstellung von Daten in Form von Tripeln (binären Prädikaten) und SPARQL ist eine logikbasierte Abfragesprache für Tripel.
Datalog-Abfragesprache und Derivate
Um Abfragen an RDF zu schreiben (und nicht nur daran, dazu später mehr), können Sie auch Datalog verwenden - eine deklarative (häufig) Sprache, die syntaktisch eine Teilmenge von Prolog darstellt (meistens).
Abfragen sehen darin folgendermaßen aus: Die
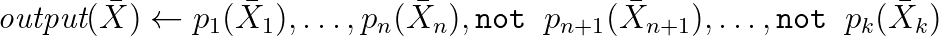
Syntax wird häufig um Aggregationen und andere praktisch wichtige Dinge erweitert. Tatsächlich handelt es sich hierbei um Inferenzregeln aus der Logik. Mit ihrer Hilfe können Sie die Inferenz neuer Eigenschaften modellieren und Abfragen in RDF schreiben. Das Folgende ist ein reales Beispiel für die Arbeit mit WikiData basierend auf einem der Dialekte

Ein weiterer wichtiger Vorteil von Datalog-basierten logischen Abfragesprachen besteht darin, dass RDF für sie einfach ein Format zum Aufzeichnen von Fakten (Anweisungen) der binären Logik ist. Sie können genauso gut mit jeder anderen logischen Behauptung umgehen - nicht unbedingt binär.
Schlussfolgerungen
Erstens eignen sich relationale Daten gut zur Modellierung fester Domänen, bei denen sich das Schema entweder selten ändert oder Änderungen nicht nur einzelne Datensätze, sondern ganze Segmente betreffen.
Zweitens eignen sich relationale Sprachen gut für Modellierungsaufgaben, bei denen Sie Untertabellen extrahieren, vorhandene transformieren und kombinieren müssen. Dies ist kein ideales Werkzeug, wenn ein wesentlicher Teil der Arbeit auf der Ebene der Änderung und / oder Inferenz eines bestimmten Datensatzes liegt.
Drittens sind kohärente Daten gut geeignet, wenn die Modellierungsdomäne ein allumfassender Bereich ist und sich sogar ändert, in dem selbst die Datensätze derselben Klasse auffallend unterschiedlich sind.
Viertens ist die Standarddarstellung RDF und es ist sinnvoll, es zuerst zu versuchen. Durch Verschrauben der erforderlichen Datenbanken und Verwendung von SPARQ-ähnlichen Sprachen können Sie die erforderlichen Daten extrahieren.
Fünftens können Sie die logische Darstellung der Daten und des Datenprotokolls als Abfragesprache betrachten, wenn das Modellieren mit Triplets umständlich und unpraktisch wird.

