Am Ende des Artikels werden wir Ihnen eine Liste der interessantesten Materialien zu diesem Thema mitteilen.

Neuer Ansatz
Verstärktes Lernen mit mehreren Agenten ist ein wachsendes und reichhaltiges Forschungsgebiet. Die ständige Verwendung von Single-Agent-Algorithmen in Multi-Agent-Kontexten bringt uns jedoch in eine schwierige Position. Das Lernen ist aus vielen Gründen kompliziert, insbesondere aufgrund von:
- Nichtstationarität zwischen unabhängigen Agenten;
- Exponentielles Wachstum von Aktions- und Zustandsräumen.
Forscher haben viele Möglichkeiten gefunden, um die Auswirkungen dieser Faktoren zu verringern. Die meisten dieser Methoden fallen unter den Begriff "zentralisierte Planung mit dezentraler Ausführung".
Zentrale Planung
Jeder Agent hat direkten Zugriff auf lokale Beobachtungen. Diese Beobachtungen können sehr unterschiedlich sein: Bilder der Umgebung, Position relativ zu bestimmten Orientierungspunkten oder sogar Position relativ zu anderen Agenten. Darüber hinaus werden während des Trainings alle Agenten von einer zentralen Einheit oder einem Kritiker kontrolliert.
Trotz der Tatsache, dass jeder Schulungsagent nur über lokale Informationen und lokale Richtlinien verfügt, gibt es eine Entität, die das gesamte Agentensystem überwacht und ihnen mitteilt, wie Richtlinien aktualisiert werden sollen. Dadurch wird der Effekt der Nichtstationarität verringert. Alle Agenten werden mithilfe eines Moduls mit globalen Informationen geschult.
Dezentrale Ausführung
Während des Tests wird das zentrale Modul entfernt, die Agenten mit ihren Richtlinien und lokalen Daten bleiben jedoch erhalten. Dies reduziert den Schaden, der durch die Vergrößerung von Aktions- und Zustandsräumen verursacht wird, da aggregierte Richtlinien niemals untersucht werden. Stattdessen hoffen wir, dass das zentrale Modul über genügend Informationen verfügt, um die lokale Lernrichtlinie so zu verwalten, dass sie für das gesamte System optimal ist, sobald die Zeit für die Durchführung von Tests gekommen ist.
OpenAI
Forscher von OpenAI, UC Berkeley und der McGill University haben einen neuen Ansatz für Multi-Agent-Einstellungen unter Verwendung des Multi-Agent Deep Deterministic Policy Gradient vorgestellt . Dieser Ansatz, der von seinem Einzelagenten-Gegenstück DDPG inspiriert wurde, verwendet eine Schulung von Schauspieler zu Kritiker und hat vielversprechende Ergebnisse gezeigt.
Die Architektur
In diesem Artikel wird davon ausgegangen, dass Sie mit der Einzelagentenversion von MADDPG: Deep Deterministic Policy Gradients oder DDPG vertraut sind. Um Ihr Gedächtnis aufzufrischen, können Sie den wunderbaren Artikel von Chris Yoon lesen .
Jeder Agent hat einen Beobachtungsraum und einen kontinuierlichen Aktionsraum. Außerdem besteht jeder Agent aus drei Komponenten:
- , ;
- ;
- , - Q-.
Wenn der Kritiker im Laufe der Zeit die gemeinsamen Q-Werte einer Funktion lernt, sendet er dem Schauspieler die entsprechenden Annäherungen der Q-Werte, um ihn beim Lernen zu unterstützen. Im nächsten Abschnitt werden wir diese Interaktion genauer untersuchen.
Denken Sie daran, dass der Kritiker ein gemeinsames Netzwerk zwischen allen N Agenten sein kann. Mit anderen Worten, anstatt N Netzwerke zu trainieren, die denselben Wert bewerten, trainieren Sie einfach ein Netzwerk und verwenden Sie es, um alle anderen Agenten zu trainieren. Gleiches gilt für Netzwerke von Akteuren, wenn die Agenten homogen sind.
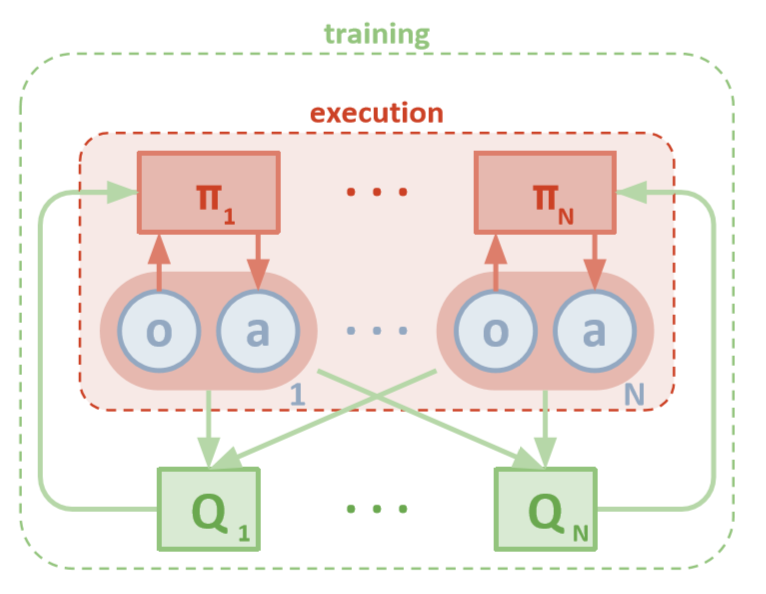
MADDPG-Architektur (Lowe, 2018)
Ausbildung
Erstens verwendet MADDPG die Wiedergabe von Erfahrungen für effektives Lernen außerhalb der Richtlinien . In jedem Zeitintervall speichert der Agent den folgenden Übergang:
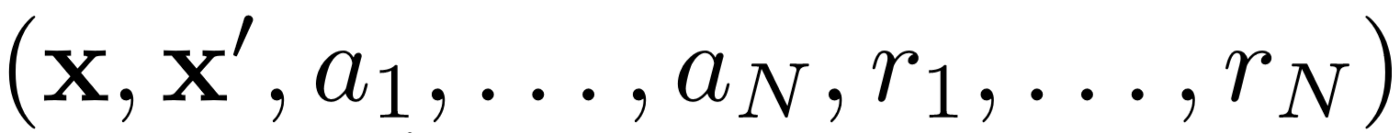
Wo wir den gemeinsamen Status, den nächsten gemeinsamen Status, die gemeinsame Aktion und jede der vom Agenten erhaltenen Belohnungen speichern. Dann nehmen wir eine Reihe solcher Übergänge von der Erfahrungswiederholung , um unseren Agenten zu schulen.
Kritische Updates
Um den zentralen Kritiker des Agenten zu aktualisieren, verwenden wir einen Lookahead-TD-Fehler:
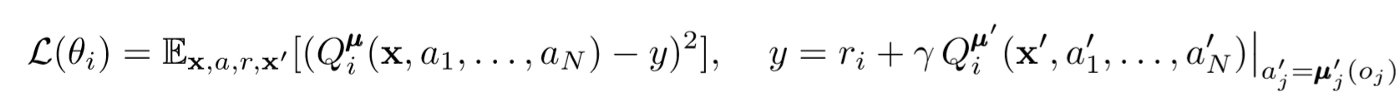
Wobei μ ein Akteur ist. Denken Sie daran, dass dies ein zentraler Kritiker ist, was bedeutet, dass er allgemeine Informationen verwendet, um seine Parameter zu aktualisieren. Die Grundidee ist, dass die Umgebung stationär ist, wenn Sie die Aktionen kennen, die alle Agenten ausführen, selbst wenn sich die Richtlinie ändert.
Achten Sie bei der Berechnung des Q-Wertes auf die rechte Seite des Ausdrucks. Während wir niemals unsere nächste Synergie speichern, verwenden wir jeden Zielakteur des Agenten, um die nächste Aktion während des Updates zu berechnen, um das Lernen stabiler zu machen. Die Parameter des Zielakteurs werden regelmäßig aktualisiert, um mit denen des Akteurs des Agenten übereinzustimmen.
Schauspieler-Updates
Ähnlich wie bei DDPG für einzelne Agenten verwenden wir einen deterministischen Richtliniengradienten , um jeden Parameter eines Agentenakteurs zu aktualisieren.
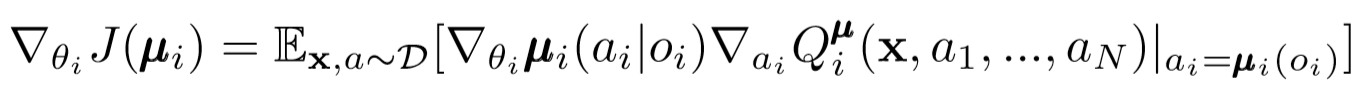
Wobei μ der Akteur des Agenten ist.
Lassen Sie uns diesen Update-Ausdruck etwas genauer betrachten. Wir nehmen den Gradienten relativ zu den Parametern des Schauspielers unter Verwendung des Zentralkritikers. Das Wichtigste, worauf Sie achten sollten, ist, dass wir während des Trainings einen zentralen Kritiker einsetzen, um Informationen über die Optimalität seiner Handlungen innerhalb des Gesamtsystems zu erhalten, selbst wenn der Schauspieler nur lokale Beobachtungen und Aktionen hat. Dadurch wird der Effekt der Nichtstationarität verringert und die Lernpolitik bleibt in einem niedrigeren Staatenraum!
Schlussfolgerungen von Politikern und Ensembles von Politikern
In der Frage der Dezentralisierung können wir noch einen Schritt weiter gehen. In früheren Updates haben wir angenommen, dass jeder Agent die Aktionen anderer Agenten automatisch erkennt. MADDPG schlägt jedoch vor, Schlussfolgerungen aus den Richtlinien anderer Akteure zu ziehen, um das Lernen noch unabhängiger zu machen. Tatsächlich fügt jeder Agent N-1-Netzwerke hinzu, um die Gültigkeit der Richtlinien aller anderen Agenten zu bewerten. Wir verwenden ein probabilistisches Netzwerk, um die logarithmische Wahrscheinlichkeit zu maximieren, auf die beobachtete Wirkung eines anderen Agenten zu schließen.
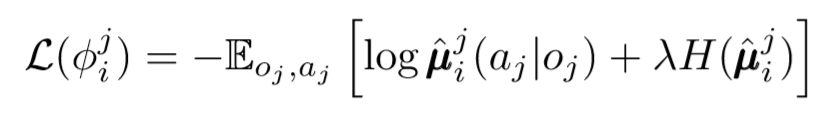
Wo wir die Verlustfunktion für den i-ten Agenten sehen, bewerten wir die Richtlinien des j-ten Agenten unter Verwendung des Entropie-Regularisierers. Infolgedessen ändert sich unser Q-Zielwert geringfügig, wenn wir die Aktionen des Agenten durch unsere vorhersehbaren Aktionen ersetzen!
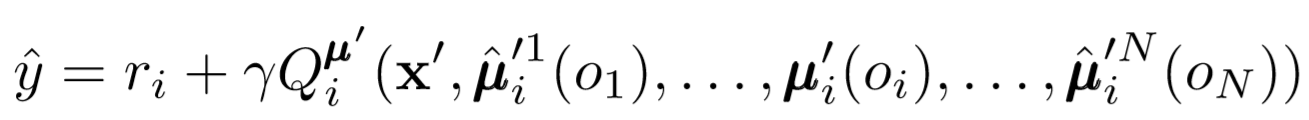
Also, mit was bist du gelandet? Wir haben die Annahme entfernt, dass Agenten die Richtlinien des anderen kennen. Stattdessen versuchen wir, Agenten zu schulen, um die Richtlinien anderer Agenten anhand einer Reihe von Beobachtungen vorherzusagen. Tatsächlich lernt jeder Agent unabhängig und empfängt globale Informationen aus der Umgebung, anstatt sie standardmäßig zur Hand zu haben.
Politische Ensembles
Es gibt ein großes Problem mit dem obigen Ansatz. In vielen Einstellungen für mehrere Agenten, insbesondere in wettbewerbsorientierten Einstellungen, können Agenten Richtlinien erstellen, die das Verhalten anderer Agenten neu trainieren. Dies macht die Richtlinie fragil, instabil und im Allgemeinen nicht optimal. Um diesen Mangel auszugleichen, trainiert MADDPG eine Sammlung von K Unterrichtlinien für jeden Agenten. Bei jedem Zeitschritt wählt der Agent zufällig eine der Unterrichtlinien aus, um die Aktion auszuwählen. Und dann macht er es.
Das Gefälle der Politik ändert sich leicht. Wir nehmen den Durchschnitt über die K-Subpolitik, verwenden die Warte-Linearität und verbreiten Aktualisierungen mithilfe der Q-Wert-Funktion.
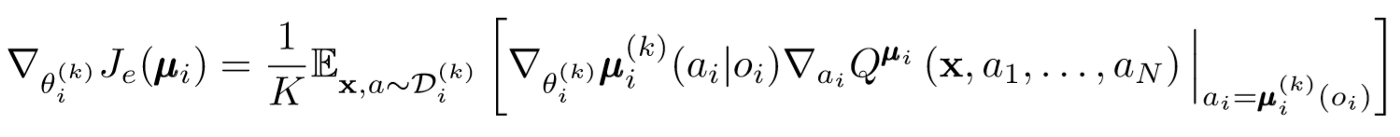
Machen wir einen Schritt zurück
So sieht der gesamte Algorithmus allgemein aus. Jetzt müssen wir zurückgehen und erkennen, was genau wir getan haben, und intuitiv verstehen, warum es funktioniert. Grundsätzlich haben wir folgendes gemacht:
- Definierte Akteure für Agenten, die nur lokale Beobachtungen verwenden. Auf diese Weise kann man den negativen Effekt exponentiell zunehmender Zustands- und Aktionsräume kontrollieren.
- Identifizierte einen zentralen Kritiker für jeden Agenten, der gemeinsam genutzte Informationen verwendet. So konnten wir den Effekt der Nichtstationarität reduzieren und dem Akteur helfen, für das globale System optimal zu werden.
- Definierte Richtlinieninferenznetzwerke zur Bewertung der Richtlinien anderer Agenten. So konnten wir die gegenseitige Abhängigkeit von Agenten begrenzen und die Notwendigkeit beseitigen, dass Agenten perfekte Informationen haben.
- Die Ensembles von Richtlinien wurden identifiziert, um die Auswirkungen und die Möglichkeit einer Umschulung der Richtlinien anderer Agenten zu verringern.
Jede Komponente des Algorithmus dient einem bestimmten, unterschiedlichen Zweck. Der MADDPG-Algorithmus ist aus folgenden Gründen leistungsstark: Seine Komponenten wurden speziell entwickelt, um die schwerwiegenden Hindernisse zu überwinden, mit denen Multi-Agent-Systeme normalerweise konfrontiert sind. Als nächstes werden wir über die Leistung des Algorithmus sprechen.
Ergebnisse
MADDPG wurde in vielen Umgebungen getestet. Eine vollständige Übersicht über seine Arbeit findet sich im Artikel [1]. Hier werden wir nur über das Problem der kooperativen Kommunikation sprechen.
Umgebungsübersicht
Es gibt zwei Agenten: den Sprecher und den Zuhörer. Bei jeder Iteration erhält der Hörer einen farbigen Punkt auf der Karte, zu dem Sie sich bewegen möchten, und eine Belohnung, die proportional zur Entfernung zu diesem Punkt ist. Aber hier ist der Haken: Der Hörer kennt nur seine Position und die Farbe der Endpunkte. Er weiß nicht, zu welchem Punkt er gehen soll. Der Sprecher kennt jedoch die Farbe des richtigen Punkts für die aktuelle Iteration. Infolgedessen müssen zwei Agenten interagieren, um dieses Problem zu lösen.
Vergleich
Um dieses Problem zu lösen, werden in dem Artikel MADDPG und moderne Einzelagentenmethoden gegenübergestellt. Bei der Verwendung von MADDPG werden signifikante Verbesserungen festgestellt.
Es wurde auch gezeigt, dass Schlussfolgerungen aus der Politik, selbst wenn die Politiker nicht ideal ausgebildet waren, dieselben Ergebnisse erzielten, die mit echter Beobachtung erzielt werden können. Darüber hinaus gab es keine signifikante Verlangsamung der Konvergenz.
Schließlich haben Ensembles von Politikern sehr vielversprechende Ergebnisse gezeigt. In Artikel [1] werden die Auswirkungen von Ensembles in einem Wettbewerbsumfeld untersucht und signifikante Leistungsverbesserungen gegenüber Agenten mit nur einer Richtlinie aufgezeigt.
Fazit
Das ist alles. Hier haben wir uns einen neuen Ansatz zur Stärkung des Multi-Agent-Lernens angesehen. Natürlich gibt es unendlich viele Methoden im Zusammenhang mit MARL, aber MADDPG bietet eine solide Grundlage für Methoden, die die globalsten Probleme von Multiagentensystemen lösen.
Quellen
[1] R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, I. Mordatch, Multi-Agent-Schauspieler-Kritiker für gemischte kooperativ-wettbewerbsorientierte Umgebungen (2018).
Liste nützlicher Artikel
- 3 Fallstricke für angehende Data Scientists
- AdaBoost-Algorithmus
- Wie war 2019 im Bereich Mathematik und Informatik?
- Maschinelles Lernen stand vor einem ungelösten mathematischen Problem
- Den Satz von Bayes verstehen
- Finden von Gesichtskonturen in einer Millisekunde mithilfe eines Ensembles von Regressionsbäumen
, , , . .