(unter der Annahme einer Normalverteilung)
Das Problem der Bestimmung der Mittelgleichheit unter der Bedingung gleicher Varianzen ist ein klassisches Problem der mathematischen Statistik, das an technischen Schulen und Universitäten gelöst wird. MS als Wissenschaft ist jedoch einem Sumpf sehr ähnlich - wenn Sie versuchen, von einer Beule eines klassisch gelösten Problems zur Seite zu springen, können Sie festsitzen oder ganz ertrinken.
Das betrachtete Problem ist eines davon. In der Tat haben fürsorgliche Mathematiker bereits etwa zwei Dutzend verschiedene statistische Tests zur Lösung dieser Art von Problemen entwickelt, was die Frage aus der Kategorie "welches zu verwenden ist" aufwirft.
Eine vorläufige Studie (der Text der Studie ist auf GitHub verfügbar ) hat gezeigt, dass in Abhängigkeit von der spezifischen Kombination von Mittelwerten, Varianz und den Besonderheiten der Problemstellung fast alle im Artikel "Cavus, M. , Yazici, B. Prüfung der Gleichheit von normalverteilten und unabhängigen Gruppenmitteln unter ungleichen Abweichungen durch das Doex-Paket / The R Journal. 2020. Nr. 2 (12). S. 134-155 " .
Um dieses Problem zu lösen, wurde ein Verfahren entwickelt, mit dem der beste statistische Test für jeden speziellen Fall ermittelt werden kann. Dies wird am Beispiel der GrowthDJ-Datenbank demonstriert, die Daten zum Wirtschaftswachstum enthält. Testen wir die Annahme über die Gleichheit der Durchschnittswerte des Wirtschaftswachstums (variables BIP-Wachstum) in Abhängigkeit von der Verfügbarkeit qualitativ hochwertiger Daten in Ländern (Variable Inter ).
Die ersten Phasen der Studie bestehen darin, die Normalität der Verteilungen zu überprüfen und deskriptive Statistiken zu finden:
library("tibble")
library("AER")
library("WRS2")
library("doex")
data("GrowthDJ")
XX<-na.omit(GrowthDJ)
library("psych")
describeBy(XX$gdpgrowth, XX$inter)
shapiro.test(XX[XX$inter=='yes',6])
shapiro.test(XX[XX$inter=='no',6])
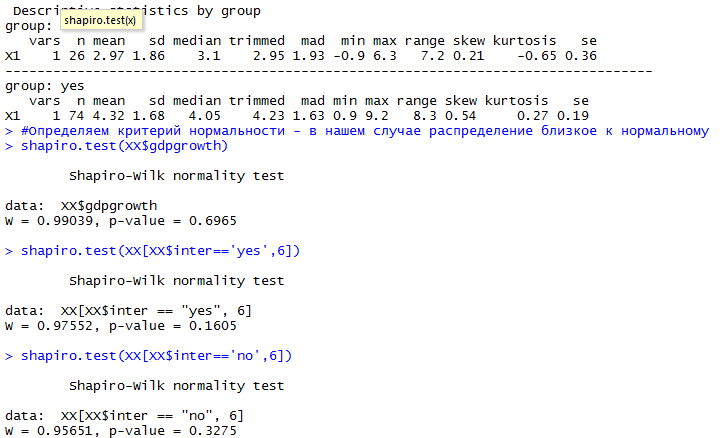
Wir erhalten, dass unsere Daten normal verteilt sind, was bedeutet, dass die Tests angewendet werden können
Verifikationsverfahren
Legen Sie zwei Mittelwerte und zwei Varianzwerte fest (basierend auf den verfügbaren Daten nach Gruppen).
( 70 ). – № 1 № 1, – № 1 № 2, – № 2 № 2.
0.01. p- 0.01, , 0.01 – . . p- 0.01, , 0.01 – . 100 , .
( , ):
accuracy ( );
selectivity ( , );
precision ( );
recall ( , );
FOR ( );
F- ( precision recall, ).
( .R )
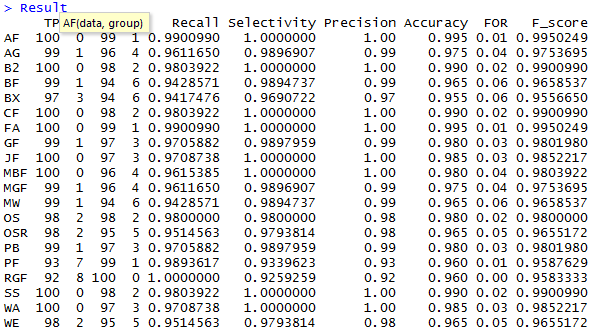
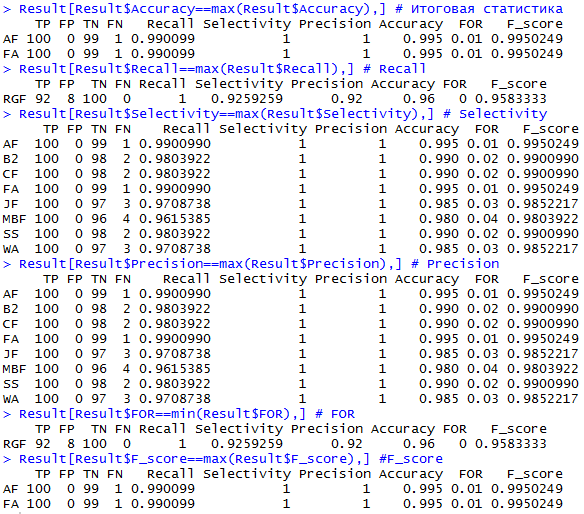
, :
, AF FA- ( , F-score
- (.. ), RGF-
- (.. ), 8 (AF,BA,CF,FA,JF,MBF,SS,WA)
, 8
, RGF-
- AF- (Approximate F-test)

0.0003 -