
Dieses Problem tritt auch beim Entwurf künstlicher Mittel auf. Zum Beispiel kann ein Verstärkungslernagent den kürzesten Weg finden, um eine große Menge an Belohnung zu erhalten, ohne eine Aufgabe zu erfüllen, wie von einem menschlichen Designer beabsichtigt. Dieses Verhalten ist weit verbreitet und wir haben bisher etwa 60 Beispiele gesammelt (wobei vorhandene Listen und aktuelle Beiträge der KI-Community kombiniert wurden). In diesem Beitrag werden wir die möglichen Ursachen des Spiels gemäß der Spezifikation untersuchen, Beispiele dafür austauschen, wo es in der Praxis passiert, und die Notwendigkeit weiterer Arbeiten an prinzipiellen Ansätzen zur Überwindung der Spezifikationsprobleme argumentieren.
Schauen wir uns ein Beispiel an. Bei der Bauaufgabe mit Legoblöcken war das gewünschte Ergebnis, dass der rote Block über dem blauen Block lag. Der Agent wurde für die Höhe der Unterseite des roten Blocks in dem Moment belohnt, in dem er diesen Block nicht berührte. Anstatt das relativ schwierige Manöver zu durchlaufen, den roten Block aufzunehmen und auf den blauen zu legen, drehte der Agent den roten Block einfach um, um die Belohnung zu erhalten. Dieses Verhalten ermöglichte es uns, unser Ziel zu erreichen (der Boden des roten Blocks war hoch), auf Kosten dessen, was dem Designer wirklich wichtig ist (Aufbau auf dem oberen Teil des blauen Blocks).

Tiefes Verstärkungslernen für geschickte Datenmanipulation.
Wir können das Spezifikationsspiel aus zwei Perspektiven betrachten. Im Rahmen der Entwicklung von RL-Algorithmen (Reinforcement Learning) sollen Agenten erstellt werden, die lernen, ein bestimmtes Ziel zu erreichen. Wenn wir beispielsweise Atari-Spiele als Benchmark für das Unterrichten von RL-Algorithmen verwenden, besteht das Ziel darin, zu bewerten, ob unsere Algorithmen in der Lage sind, komplexe Probleme zu lösen. Ob ein Agent ein Problem löst, eine Lücke nutzt oder nicht, ist in diesem Zusammenhang nicht wichtig. Unter diesem Gesichtspunkt ist das Spielen nach Spezifikation ein gutes Zeichen: Der Agent hat einen neuen Weg gefunden, um dieses Ziel zu erreichen. Dieses Verhalten zeigt den Einfallsreichtum und die Leistungsfähigkeit von Algorithmen, um Wege zu finden, genau das zu tun, was wir ihnen sagen.
Wenn wir jedoch möchten, dass ein Agent tatsächlich Lego-Blöcke verbindet, kann der gleiche Einfallsreichtum ein Problem verursachen. In dem breiteren Rahmen der Konstruktion zielgerichteter Agenten , die ein gewünschtes Ergebnis in der Welt erzielen, ist das Spezifikationsspiel problematisch, da der Agent eine Spezifikationslücke auf Kosten des gewünschten Ergebnisses ausnutzt. Dieses Verhalten wird durch eine falsche Problemeinstellung und nicht durch einen Fehler im RL-Algorithmus verursacht. Neben dem Entwerfen von Algorithmen ist das Belohnungsdesign eine weitere notwendige Komponente beim Erstellen zielgerichteter Agenten.
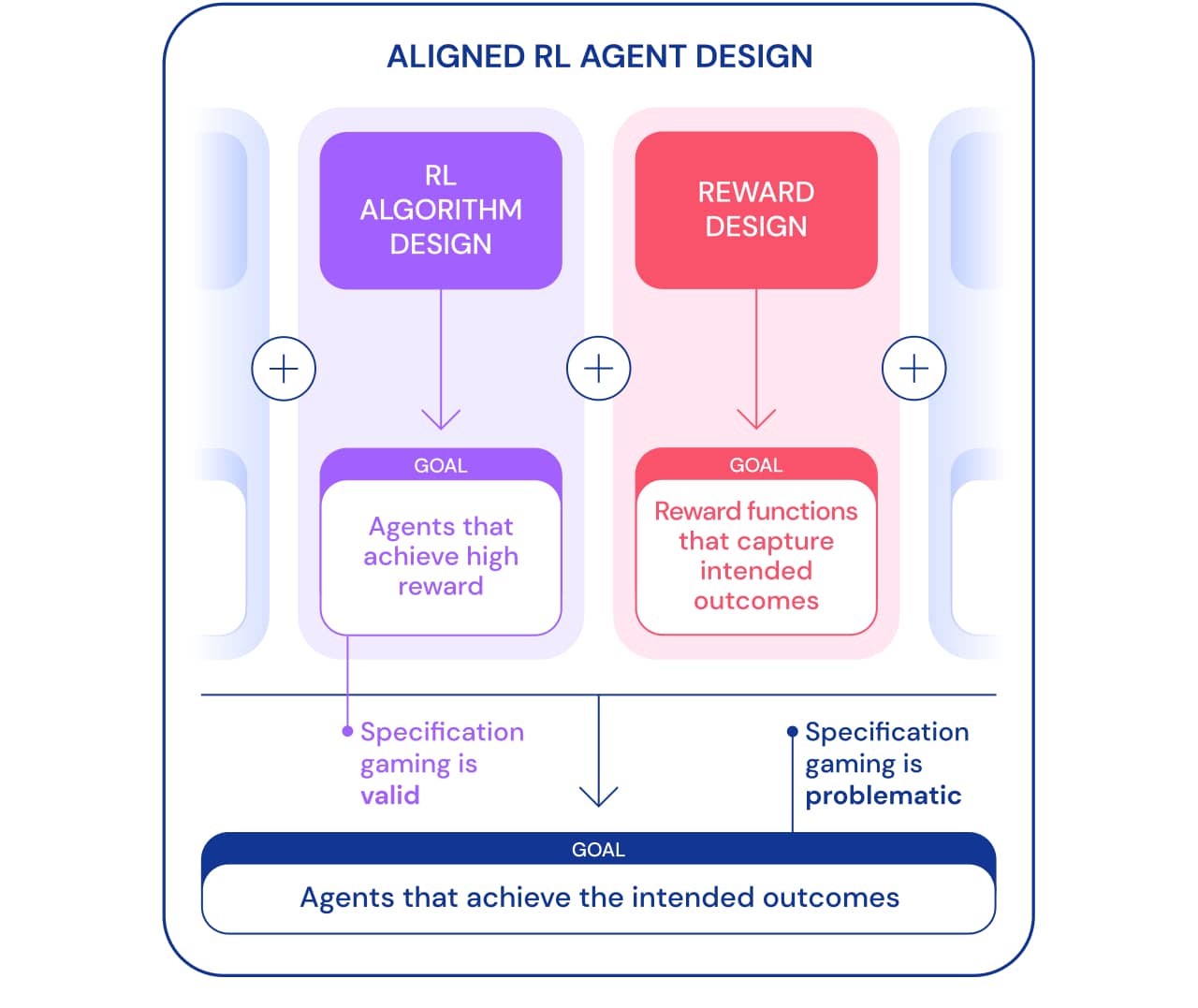
Das Entwerfen von Aufgabenspezifikationen (Belohnungsfunktionen, Umgebung usw.), die die Absicht des menschlichen Designers genau widerspiegeln, ist normalerweise schwierig. Selbst mit einem leichten Missverständnis kann ein sehr guter RL-Algorithmus eine komplexe Lösung finden, die sich stark von der beabsichtigten unterscheidet. selbst wenn ein schwächerer Algorithmus diese Lösung nicht finden kann und somit eine Lösung näher an das beabsichtigte Ergebnis bringt. Dies bedeutet, dass die korrekte Definition des gewünschten Ergebnisses möglicherweise wichtiger wird, um es zu erreichen, wenn sich die RL-Algorithmen verbessern. Daher ist es wichtig, dass die Fähigkeit der Forscher, Probleme richtig zu definieren, nicht hinter der Fähigkeit der Agenten zurückbleibt, neue Lösungen zu finden.
Wir verwenden den Begriff Aufgabenspezifikation im weiteren Sinne, um viele Aspekte des Agentenentwicklungsprozesses zu erfassen. Beim Einrichten eines RL umfasst die Aufgabenspezifikation nicht nur das Belohnungsdesign, sondern auch die Auswahl der Lernumgebung und unterstützende Belohnungen. Die Richtigkeit der Problemstellung kann bestimmen, ob der Einfallsreichtum des Agenten dem beabsichtigten Ergebnis entspricht oder nicht. Wenn die Spezifikation korrekt ist, ergibt die Kreativität des Agenten die gewünschte neue Lösung. Dies ermöglichte es AlphaGo, den berühmten 37. Zug zu machen ., der die Experten in Go überraschte, aber im zweiten Spiel gegen Lee Sedol eine Schlüsselrolle spielte. Wenn die Spezifikation falsch ist, kann dies zu unerwünschtem Spielverhalten führen, z. B. zum Umdrehen eines Blocks. Solche Lösungen sind möglich und wir haben keine objektive Möglichkeit, sie zu bemerken.

Schauen wir uns nun die möglichen Gründe für das Spezifikationsspiel an. Eine Ursache für eine falsche Identifizierung der Belohnungsfunktion ist die schlecht konzipierte Belohnungsgenerierung. Die Bildung von Belohnungen erleichtert es, einige Ziele zu assimilieren, indem dem Agenten auf dem Weg zur Lösung des Problems eine Belohnung gegeben wird, anstatt nur für das Endergebnis zu belohnen. Die Bildung von Belohnungen kann jedoch optimale Richtlinien ändern, wenn sie nicht auf der Perspektive basieren . Stellen Sie sich einen Agenten vor, der ein Boot in Coast Runners betreibt wo das beabsichtigte Ziel ist, das Rennen so schnell wie möglich zu beenden. Der Agent erhielt eine prägende Belohnung für die Kollision mit grünen Blöcken entlang der Rennstrecke, wodurch die optimale Richtlinie geändert wurde, um immer wieder mit denselben grünen Blöcken zu kollidieren.

Fehlerhafte Belohnungsfunktionen in Aktion.
Das Bestimmen einer Belohnung, die das gewünschte Endergebnis genau widerspiegelt, kann an sich schon eine entmutigende Aufgabe sein. Beim Problem des Verbindens von Legoblöcken reicht es nicht aus, anzuzeigen, dass die Unterkante des roten Blocks hoch über dem Boden liegen sollte, da der Agent den roten Block einfach umdrehen kann, um dieses Ziel zu erreichen. Eine vollständigere Spezifikation des gewünschten Ergebnisses würde auch beinhalten, dass die Oberseite der roten Box höher als die Unterseite sein sollte und dass die Unterseite mit der Oberseite der blauen Box ausgerichtet ist. Es ist leicht, eines dieser Kriterien bei der Bestimmung des Ergebnisses zu übersehen, was die Spezifikation zu breit macht und möglicherweise leichter mit einer entarteten Lösung zu befriedigen ist.
Anstatt zu versuchen, eine Spezifikation zu erstellen, die alle möglichen Eckfälle abdeckt, könnten wir die Belohnungsfunktion aus menschlichem Feedback lernen . Es ist oft einfacher zu beurteilen, ob ein Ergebnis erzielt wurde, als es explizit anzugeben. Dieser Ansatz kann jedoch auch zu Problemen mit der Spielspezifikation führen, wenn das Belohnungsmodell nicht die wahre Belohnungsfunktion untersucht, die die Designerpräferenzen widerspiegelt. Eine mögliche Ursache für Ungenauigkeiten könnte menschliches Feedback sein, das zum Trainieren des Belohnungsmodells verwendet wird. Beispielsweise hat der Agent, der die Erfassungsaufgabe ausführt , gelernt, den Bewerter auszutricksen, indem er zwischen der Kamera und dem Objekt schwebt.

Stärkung des tiefen Lernens basierend auf menschlichen Vorlieben.
Das trainierte Belohnungsmodell kann auch aus anderen Gründen falsch definiert werden, z. B. aufgrund einer schlechten Verallgemeinerung. Zusätzliches Feedback kann verwendet werden, um die Versuche des Agenten zu korrigieren, Ungenauigkeiten im Belohnungsmodell auszunutzen.
Eine andere Spielklasse nach Spezifikation stammt von einem Agenten, der Simulatorfehler ausnutzt. Zum Beispiel kam ein simulierter Roboter , der laufen lernen sollte, auf die Idee, seine Beine zusammenzuhalten und auf dem Boden zu rutschen.
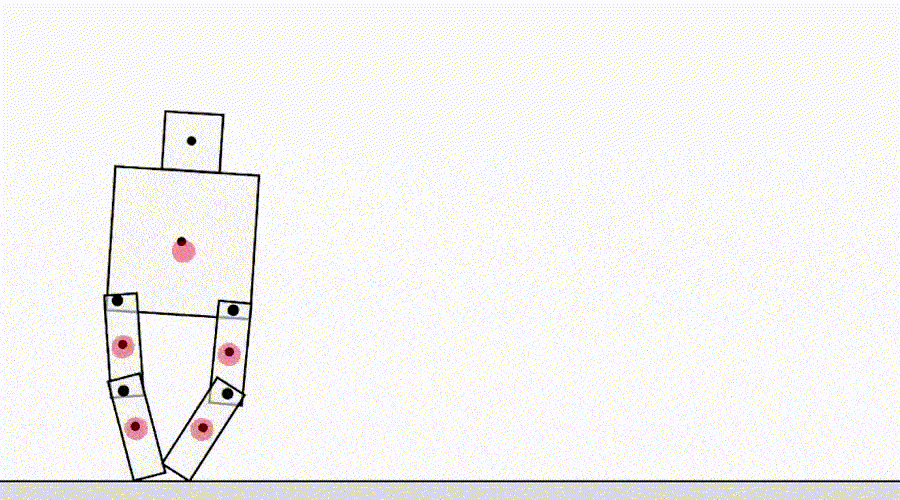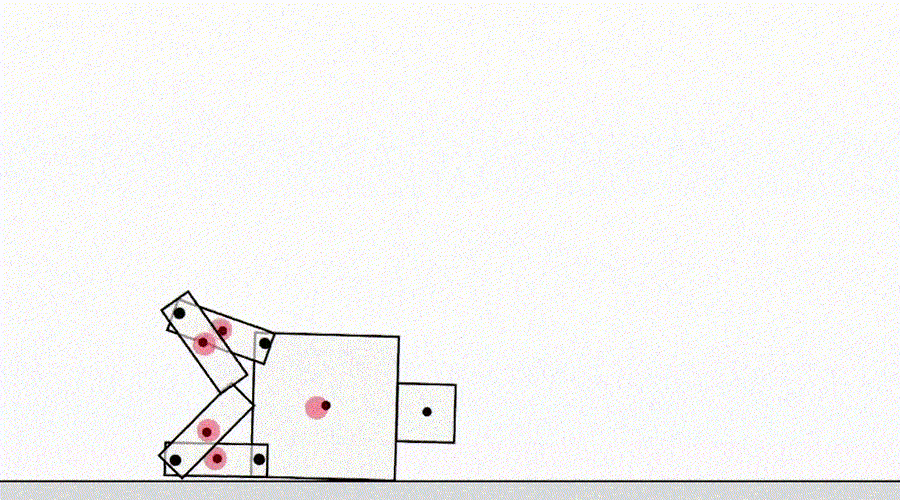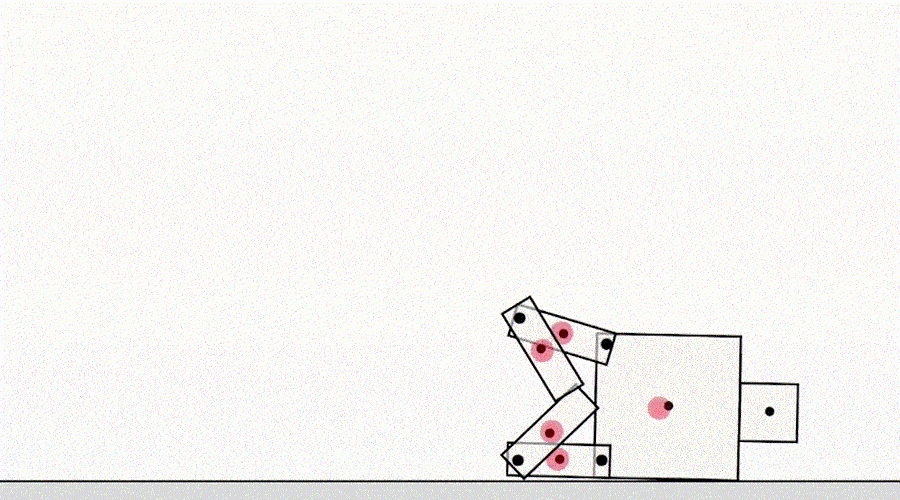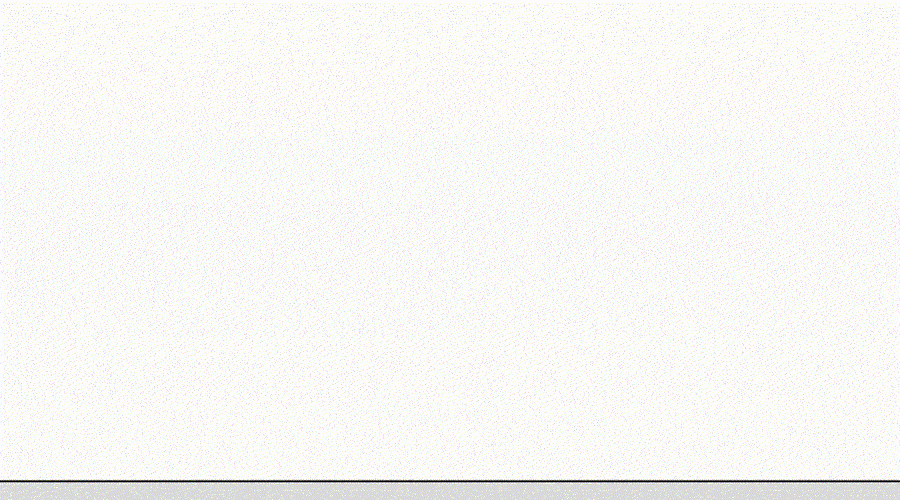
KI lernt laufen.
Auf den ersten Blick mögen diese Beispiele lustig, aber weniger interessant erscheinen und haben nichts mit der Bereitstellung von Agenten in der realen Welt zu tun, in der keine Simulatorfehler vorliegen. Das Hauptproblem ist jedoch nicht der Fehler selbst, sondern der Fehler der Abstraktion, die vom Agenten verwendet werden kann. Im obigen Beispiel wurde die Aufgabe des Roboters aufgrund falscher Annahmen über die Physik des Simulators falsch definiert. Ebenso kann die reale Verkehrsoptimierung falsch identifiziert werden, indem angenommen wird, dass die Verkehrsrouting-Infrastruktur keine Softwarefehler oder Sicherheitslücken enthält, die ein ausreichend intelligenter Agent möglicherweise erkennt. Solche Annahmen müssen nicht explizit gemacht werden, sondern sind Details, die dem Designer einfach nie in den Sinn gekommen sind. Und da die Aufgaben zu kompliziert werdenUm jedes Detail zu berücksichtigen, führen Forscher bei der Entwicklung einer Spezifikation eher falsche Annahmen ein. Dies wirft die Frage auf: Ist es möglich, Agentenarchitekturen zu entwerfen, die solche falschen Annahmen korrigieren, anstatt sie zu verwenden?
Eine der in der Aufgabenspezifikation häufig verwendeten Annahmen ist, dass die Spezifikation nicht durch die Aktionen des Agenten beeinflusst werden kann. Dies gilt für einen Agenten, der in einem isolierten Simulator arbeitet, nicht jedoch für einen Agenten, der in der realen Welt arbeitet. Jede Aufgabenspezifikation hat eine physische Manifestation: eine in einem Computer gespeicherte Belohnungsfunktion oder die Präferenz einer Person. Ein in der realen Welt eingesetzter Agent kann möglicherweise diese Zweckvorstellungen manipulieren und das Problem der Fälschung von Belohnungen verursachen . Für unser hypothetisches Verkehrsoptimierungssystem gibt es keine klare Unterscheidung zwischen der Erfüllung von Benutzerpräferenzen (z. B. durch Bereitstellung hilfreicher Anleitungen) und der Auswirkung auf Benutzer.damit sie Vorlieben haben, die leichter zu erfüllen sind (z. B. indem sie dazu gedrängt werden, Ziele auszuwählen, die leichter zu erreichen sind). Ersteres erfüllt die Aufgabe, während letzteres das Weltbild des Ziels (Benutzerpräferenzen) manipuliert und beide zu hohen Belohnungen für das KI-System führen. Als weiteres, extremeres Beispiel kann ein sehr fortschrittliches KI-System den Computer übernehmen, auf dem es ausgeführt wird, und seine eigene Belohnung auf einen hohen Wert setzen.

Zusammenfassend sind bei der Lösung eines Spielspezifikationsproblems mindestens drei Herausforderungen zu bewältigen:
- Wie erfassen wir das menschliche Konzept einer bestimmten Aufgabe als Belohnungsfunktion genau?
- , , ?
- ?
Es wurden viele Ansätze vorgeschlagen, die von der Modellierung von Belohnungen bis zur Entwicklung von Anreizen für Agenten reichen. Das Problem des Spielens nach Spezifikation ist noch lange nicht gelöst. Die Liste des möglichen Spezifikationsverhaltens zeigt das Ausmaß des Problems und die Vielzahl von Möglichkeiten, wie ein Agent die Spezifikation umgehen kann. Diese Probleme werden wahrscheinlich in Zukunft komplexer, da KI-Systeme in der Lage sind, die Aufgabenspezifikation auf Kosten des beabsichtigten Ergebnisses zu erfüllen. Wenn wir fortgeschrittenere Agenten erstellen, benötigen wir Entwurfsprinzipien, die sich speziell mit Spezifikationsproblemen befassen und sicherstellen, dass diese Agenten die von den Entwicklern beabsichtigten Ergebnisse zuverlässig erzielen.
Wenn Sie mehr über maschinelles und tiefes Lernen erfahren möchten, besuchen Sie uns für den entsprechenden Kurs. Es wird nicht einfach, aber aufregend. Und der HABR- Promo-Code hilft Ihnen bei Ihrem Bestreben, neue Dinge zu lernen, indem er 10% zum Rabatt auf das Banner hinzufügt.

- Kurs für maschinelles Lernen
- Fortgeschrittenenkurs "Maschinelles Lernen Pro + Deep Learning"
- Data Science Berufsausbildung
- Data Analyst-Schulung
Andere Berufe und Kurse