Es ist unpraktisch, die erhaltenen Informationen im Cache zu speichern, und es ist erforderlich, eine Datenbank zu verwenden.
In dem Artikel werde ich berücksichtigen:
- Erstellen einer einfachen SQLite-Datenbank;
- Schreiben von Informationen mit Python;
- Lesen von Daten und Konvertieren in das DataFrame-Format;
- Analyse-Update basierend auf Datenbankdaten.

Datenbankanforderungen
Die Hauptanforderung für eine Projektdatenbank besteht darin, Daten zu speichern und sie schnell abrufen zu können.
Unsere Datenbank wird nicht benötigt:
- den Zugang zu Systemen einschränken, da Nur der Benutzer hat Zugriff durch Parsen.
- Zugang rund um die Uhr behalten, weil Die Datenextraktion ist nach Bedarf für die Analyse akzeptabel.
- Schaffung von Verfahren, da Alle Berechnungen werden in Python durchgeführt.
Daher ist es für ein Projekt möglich, eine einfache Datenbank in SQLite zu verwenden. Sie können es als Datei entweder auf Ihrer Festplatte, auf einem USB-Flash-Laufwerk oder auf einem Cloud-Laufwerk speichern, um von anderen Geräten aus darauf zuzugreifen.
Funktionen für die Arbeit mit SQLite über Python
Um mit SQLite über Python zu arbeiten, verwenden wir die sqlite3- Bibliothek .
Wir verbinden uns mit der Datenbank mit einem einfachen Befehl:
sqlite3.connect( )Wenn die Datei fehlt, wird eine neue Datenbank erstellt.
Datenbankabfragen werden wie folgt ausgeführt:
conn = sqlite3.connect( )
cur = conn.cursor()
cur.execute()
df = cur.fetchall()
cur.fetchall () wird ausgeführt, wenn wir als Ergebnis der Anforderung Daten aus der Datenbank abrufen möchten.
Vergessen Sie am Ende des Schreibens von Daten in die Datenbank nicht, die Transaktion zu beenden:
conn.commit()
Vergessen Sie am Ende der Arbeit mit der Datenbank nicht, sie zu schließen:
conn.close()
Andernfalls wird die Basis zum Schreiben oder Öffnen verriegelt.
Das Erstellen von Tabellen ist Standard:
CREATE TABLE t1 (1 , 2 ...)
oder eine vielseitigere Option, mit der eine Tabelle erstellt wird, wenn sie fehlt:
CREATE TABLE IF NOT EXISTS t1 (1 , 2 ...)Wir schreiben Daten in die Tabelle, um Wiederholungen zu vermeiden:
INSERT OR IGNORE INTO t1 (1, 2, ...) VALUES(1, 2, ...)Aktualisieren der Daten:
UPDATE t1 SET 1 = 1 WHERE 2 = 2Für eine bequemere Arbeit mit SQLite können Sie SQLite Manager oder DB Browser für SQLite verwenden .
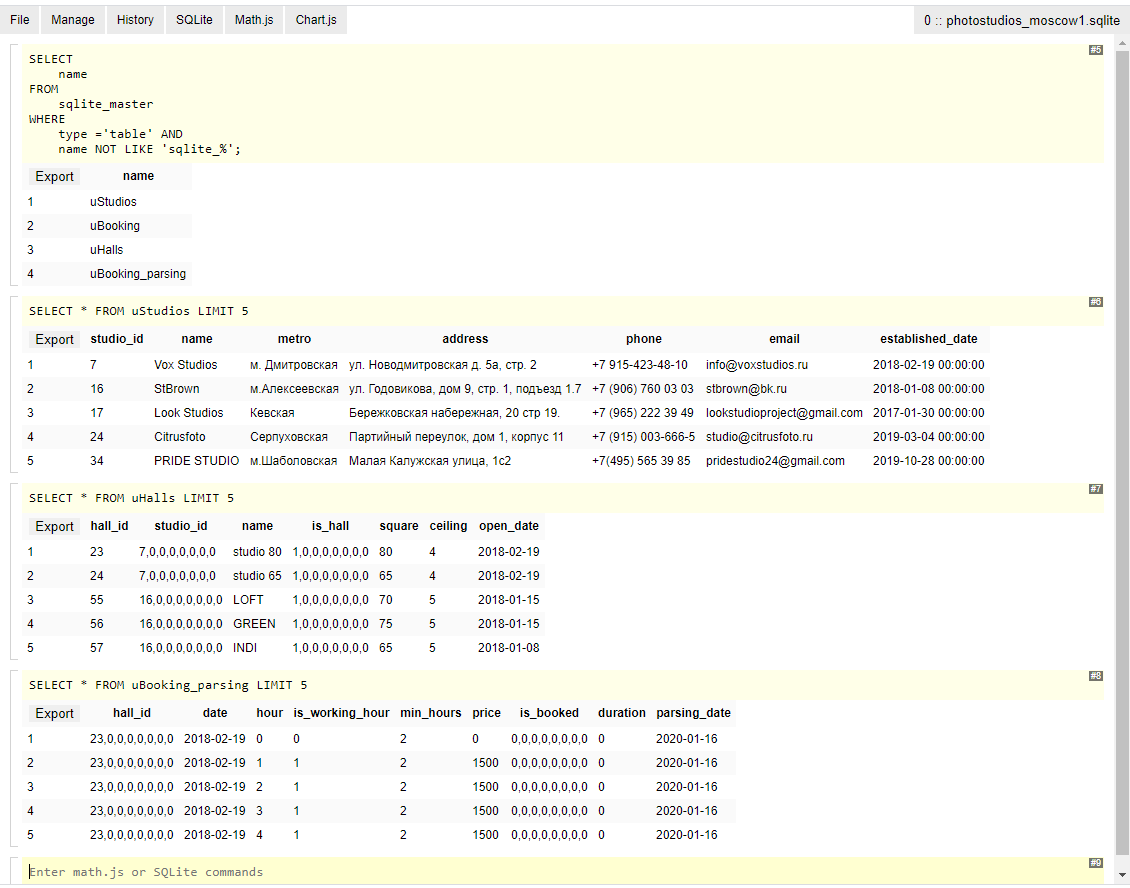
Das erste Programm ist eine Browser-Erweiterung und sieht aus wie eine Abwechslung einer Anforderungszeile und eines Antwortblocks:
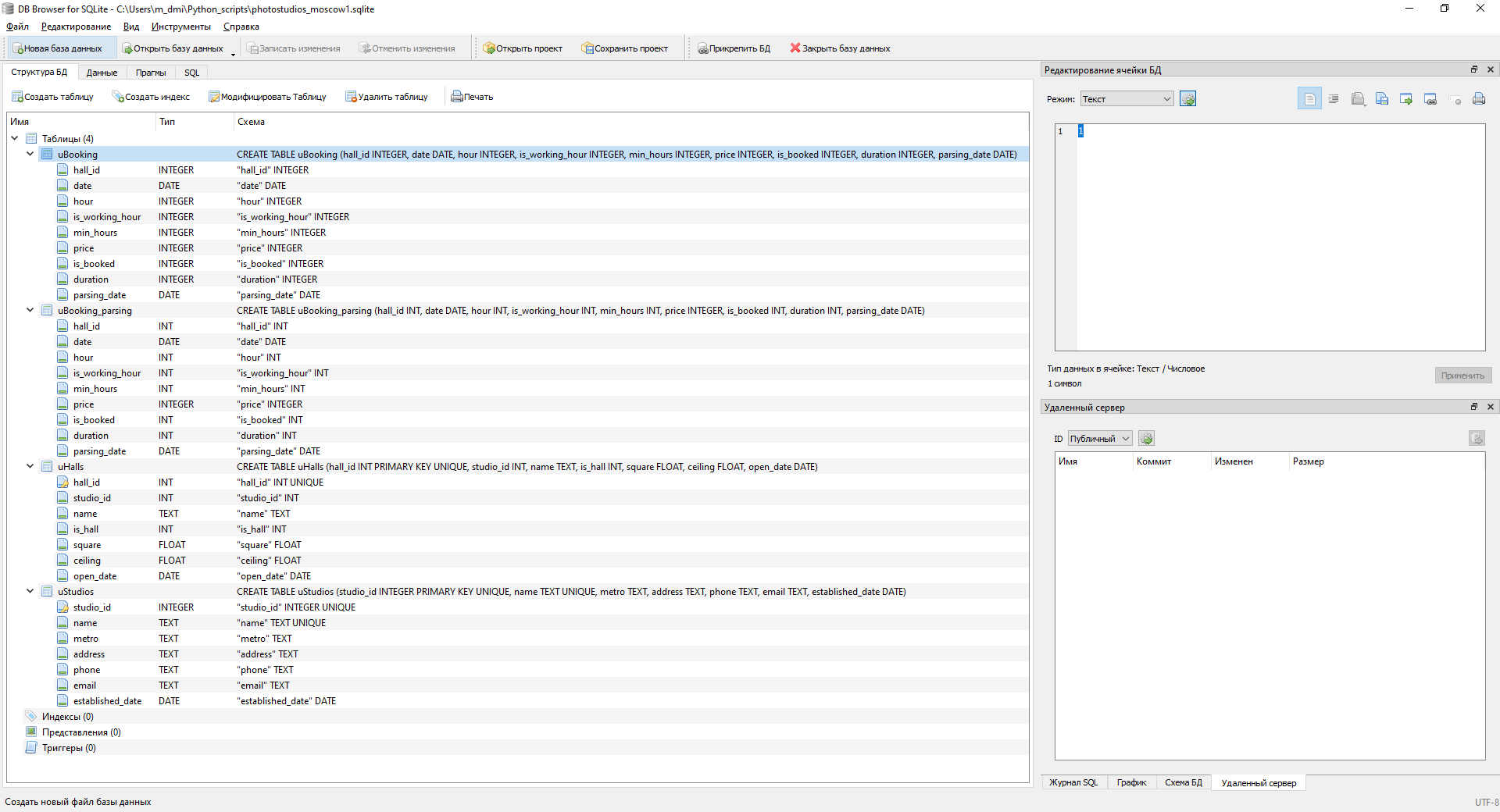
Das zweite Programm ist eine vollwertige Desktop-Anwendung:
Datenbankstruktur
Die Datenbank besteht aus 4 Tischen: Studios, Hallen, 2 Buchungstische.
Die hochgeladenen Buchungsdaten enthalten Informationen zu zukünftigen Perioden, die sich bei neuer Analyse ändern können. Es ist unerwünscht, die Daten zu überschreiben (sie können beispielsweise verwendet werden, um den Tag / die Stunde zu berechnen, an dem die Reservierung vorgenommen wurde). Daher wird eine Buchungstabelle für die Parsing-Rohdaten benötigt, die zweite für die neuesten relevanten Daten.
Wir erstellen Tabellen:
def create_tables(conn, table = 'all'):
cur = conn.cursor()
if (table == 'all') or (table == 'uStudios'):
cur.execute('''
CREATE TABLE IF NOT EXISTS uStudios
(studio_id INT PRIMARY KEY UNIQUE,
name TEXT UNIQUE,
metro TEXT,
address TEXT,
phone TEXT,
email TEXT,
established_date DATE)
''')
print('Table uStudios is created.')
if (table == 'all') or (table == 'uHalls'):
cur.execute('''
CREATE TABLE IF NOT EXISTS uHalls
(hall_id INT PRIMARY KEY UNIQUE,
studio_id INT,
name TEXT,
is_hall INT,
square FLOAT,
ceiling FLOAT,
open_date DATE)
''')
print('Table uHalls is created.')
if (table == 'all') or (table == 'uBooking_parsing'):
cur.execute('''
CREATE TABLE IF NOT EXISTS uBooking_parsing
(hall_id INT,
date DATE,
hour INT,
is_working_hour INT,
min_hours INT,
price INTEGER,
is_booked INT,
duration INT,
parsing_date DATE)
''')
print ('Table uBooking_parsing is created.')
if (table == 'all') or (table == 'uBooking'):
cur.execute('''
CREATE TABLE IF NOT EXISTS uBooking
(hall_id INT,
date DATE,
hour INT,
is_working_hour INT,
min_hours INT,
price INTEGER,
is_booked INT,
duration INT,
parsing_date DATE)
''')
print ('Table uBooking is created.')
Der Tabellenparameter legt den Namen der zu erstellenden Tabelle fest. Erstellt standardmäßig alles.
In den Feldern der Tabellen sehen Sie Daten, die nicht analysiert wurden (Datum der Studioeröffnung, Datum der Eröffnung der Halle). Ich werde die Berechnung dieser Felder später beschreiben.
Interaktion mit der Datenbank
Erstellen wir 6 Prozeduren für die Interaktion mit der Datenbank:
- Schreiben einer Liste von Fotostudios in die Datenbank;
- Hochladen einer Liste von Fotostudios aus der Datenbank;
- Aufzeichnen einer Liste von Hallen;
- Entladen der Hallenliste;
- Buchungsdaten hochladen;
- Aufzeichnung von Buchungsdaten.
1. Schreiben einer Liste von Fotostudios in die Datenbank
Am Eingang der Prozedur übergeben wir die Parameter für die Verbindung mit der Datenbank und der Tabelle in Form eines DataFrame. Wir schreiben die Daten zeilenweise und iterieren über alle Zeilen in einer Schleife. Eine nützliche Eigenschaft von Zeichenfolgendaten in Python für diese Operation ist das "?" die Elemente des nach angegebenen Tupels.
Das Verfahren zum Aufzeichnen einer Liste von Fotostudios ist wie folgt:
def studios_to_db(conn, studio_list):
cur = conn.cursor()
for i in studio_list.index:
cur.execute('INSERT OR IGNORE INTO uStudios (studio_id, name, metro, address, phone, email) VALUES(?, ?, ?, ?, ?, ?)',
(i,
studio_list.loc[i, 'name'],
studio_list.loc[i, 'metro'],
studio_list.loc[i, 'address'],
studio_list.loc[i, 'phone'],
studio_list.loc[i, 'email']))2. Laden Sie die Liste der Fotostudios aus der Datenbank hoch
Wir übergeben die Datenbankverbindungsparameter an den Eintrag in die Prozedur. Wir führen die Auswahlabfrage aus, fangen die entladenen Daten ab und schreiben sie in den DataFrame. Wir übersetzen das Gründungsdatum des Fotostudios in das Datumsformat.
Das gesamte Verfahren ist wie folgt:
def db_to_studios(conn):
cur = conn.cursor()
cur.execute('SELECT * FROM uStudios')
studios = pd.DataFrame(cur.fetchall()
, columns=['studio_id', 'name', 'metro', 'address', 'phone', 'email', 'established_date']
).set_index('studio_id')
studios['established_date'] = pd.to_datetime(studios['established_date'])
return studios3. Schreiben Sie die Liste der Hallen in die Datenbank
Das Verfahren ähnelt dem Aufzeichnen einer Liste von Fotostudios: Wir übertragen Verbindungsparameter und eine Tabelle mit Hallen und schreiben die Daten zeilenweise in die Datenbank.
Das Verfahren zum Aufzeichnen der Liste der Hallen in der Datenbank
def halls_to_db(conn, halls):
cur = conn.cursor()
for i in halls.index:
cur.execute('INSERT OR IGNORE INTO uHalls (hall_id, studio_id, name, is_hall, square, ceiling) VALUES(?, ?, ?, ?, ?, ?)',
(i,
halls.loc[i, 'studio_id'],
halls.loc[i, 'name'],
halls.loc[i, 'is_hall'],
halls.loc[i, 'square'],
halls.loc[i, 'ceiling']))4. Entladen der Hallenliste aus der Datenbank
Das Verfahren ähnelt dem Entladen einer Liste von Fotostudios: Übertragen von Verbindungsparametern, Auswahlanforderung, Abfangen, Schreiben in einen DataFrame, Konvertieren des Eröffnungsdatums der Halle in das Datumsformat.
Der einzige Unterschied: Studio-ID und Hallenschild wurden in Byte-Form aufgezeichnet. Wir geben den Wert durch die Funktion zurück:
int.from_bytes(, 'little')
Das Verfahren zum Entladen der Hallenliste ist wie folgt:
def db_to_halls(conn):
cur = conn.cursor()
cur.execute('SELECT * FROM uHalls')
halls = pd.DataFrame(cur.fetchall(), columns=['hall_id', 'studio_id', 'name', 'is_hall', 'square', 'ceiling', 'open_date']).set_index('hall_id')
for i in halls.index:
halls.loc[i, 'studio_id'] = int.from_bytes(halls.loc[i, 'studio_id'], 'little')
halls.loc[i, 'is_hall'] = int.from_bytes(halls.loc[i, 'is_hall'], 'little')
halls['open_date'] = pd.to_datetime(halls['open_date'])
return halls5. Hochladen von Buchungsinformationen aus der Datenbank
Wir übergeben die Datenbankverbindungsparameter und den Parsing-Parameter an die Prozedur und zeigen an, von welcher Buchungstabelle wir Informationen anfordern: 0 - von der tatsächlichen (standardmäßig), 1 - von der Parsing-Tabelle. Als nächstes führen wir eine Auswahlanforderung aus, fangen sie ab und übertragen sie an einen DataFrame. Daten werden in das Datumsformat konvertiert, Zahlen vom Byteformat in das Zahlenformat.
Verfahren zum Hochladen von Buchungsinformationen:
def db_to_booking(conn, parsing = 0):
cur = conn.cursor()
if parsing == 1:
cur.execute('SELECT * FROM uBooking_parsing')
else:
cur.execute('SELECT * FROM uBooking')
booking = pd.DataFrame(cur.fetchall(), columns=['hall_id',
'date', 'hour',
'is_working_hour',
'min_hours',
'price',
'is_booked',
'duration',
'parsing_date'])
booking['hall_id'] = [int.from_bytes(x, 'little') if not isinstance(x, int) else x for x in booking['hall_id']]
booking['is_booked'] = [int.from_bytes(x, 'little') if not isinstance(x, int) else x for x in booking['is_booked']]
booking['date'] = pd.DataFrame(booking['date'])
booking['parsing_date'] = pd.DataFrame(booking['parsing_date'])
return booking6. Buchungsinformationen in die Datenbank schreiben
Die komplexeste Funktion der Interaktion mit der Datenbank seit es initiiert das Parsen der Buchungsdaten. Am Eingang übergeben wir der Prozedur die Parameter für die Verbindung zur Datenbank und die Liste der Hallen-IDs, die aktualisiert werden müssen.
Um das neueste Datum der aktuellen Daten zu ermitteln,
Fordern Sie aus der Datenbank das späteste Analysedatum für jede Hallen-ID an:
parsing_date = db_to_booking(conn, parsing = 1).groupby('hall_id').agg(np.max)['parsing_date']Wir durchlaufen jede Hallen-ID mit einer Schleife.
In jeder Hallen-ID definieren wir zuerst
Anzahl der Wochen, die in der Vergangenheit analysiert wurden:
try:
last_day_str = parsing_date[id]
last_day = datetime.datetime.strptime(last_day_str, '%Y-%m-%d')
delta_days = (datetime.datetime.now() - last_day).days
weeks_ago = delta_days // 7
except:
last_day_str = '2010-01-01'
last_day = datetime.datetime.strptime(last_day_str, '%Y-%m-%d')
weeks_ago = 500Befindet sich die Hallen-ID in der Datenbank, berechnen wir. Wenn nicht, analysieren wir 500 Wochen in der Vergangenheit oder hören auf, wenn 2 Monate lang keine Reservierung stattgefunden hat (die Einschränkung ist im vorherigen Artikel beschrieben ).
Dann führen wir die Parsing-Prozeduren durch:
d = get_past_booking(id, weeks_ago = weeks_ago)
d.update(get_future_booking(id))
book = hall_booking(d)Zuerst analysieren wir Buchungsinformationen aus der Vergangenheit zu den tatsächlichen Daten, dann aus der Zukunft (bis zu 2 Monate, wenn keine Datensätze vorhanden waren) und übertragen am Ende die Daten aus dem JSON-Format in DataFrame.
In der letzten Phase schreiben wir die Daten bei der Buchung der Halle in die Datenbank und schließen die Transaktion ab.
Das Verfahren zum Aufzeichnen von Buchungsinformationen in der Datenbank ist wie folgt:
def booking_to_db(conn, halls_id):
cur = conn.cursor()
cur_date = pd.Timestamp(datetime.date.today())
parsing_date = db_to_booking(conn, parsing = 1).groupby('hall_id').agg(np.max)['parsing_date']
for id in halls_id:
#download last parsing_date from DataBase
try:
last_day_str = parsing_date[id]
last_day = datetime.datetime.strptime(last_day_str, '%Y-%m-%d')
delta_days = (datetime.datetime.now() - last_day).days
weeks_ago = delta_days // 7
except:
last_day_str = '2010-01-01'
last_day = datetime.datetime.strptime(last_day_str, '%Y-%m-%d')
weeks_ago = 500
d = get_past_booking(id, weeks_ago = weeks_ago)
d.update(get_future_booking(id))
book = hall_booking(d)
for i in list(range(len(book))):#book.index:
cur.execute('INSERT OR IGNORE INTO uBooking_parsing (hall_id, date, hour, is_working_hour, min_hours, price, is_booked, duration, parsing_date) VALUES(?,?,?,?,?,?,?,?,?)',
(book.iloc[i]['hall_id'],
book.iloc[i]['date'].date().isoformat(),
book.iloc[i]['hour'],
book.iloc[i]['is_working_hour'],
book.iloc[i]['min_hours'],
book.iloc[i]['price'],
book.iloc[i]['is_booked'],
book.iloc[i]['duration'],
cur_date.date().isoformat()))
conn.commit()
print('hall_id ' + str(id) + ' added. ' + str(list(halls_id).index(id) + 1) + ' from ' + str(len(halls_id)))Aktualisierung der Eröffnungstage des Studios und der Hallen
Das Eröffnungsdatum der Lounge ist das früheste Buchungsdatum für die Lounge.
Der Eröffnungstermin des Fotostudios ist der früheste Termin für die Eröffnung der Atelierhalle.
Basierend auf dieser Logik,
Wir entladen die frühesten Buchungstermine für jedes Zimmer aus der Datenbank
halls = db_to_booking(conn).groupby('hall_id').agg(min)['date']
Dann aktualisieren wir die Eröffnungsdaten Zeile für Zeile:
for i in list(range(len(halls))):
cur.execute('''UPDATE uHalls SET open_date = '{1}' WHERE hall_id = {0}'''
.format(halls.index[i], str(halls.iloc[i])))Wir aktualisieren die Öffnungsdaten des Fotostudios auf die gleiche Weise: Wir laden die Daten zu den Eröffnungsdaten der Hallen aus der Datenbank herunter, berechnen das kleinste Datum für jedes Studio und schreiben das Eröffnungsdatum des Fotostudios neu.
Verfahren zum Aktualisieren der Öffnungszeiten:
def update_open_dates(conn):
cur = conn.cursor()
#update open date in uHalls
halls = db_to_booking(conn).groupby('hall_id').agg(min)['date']
for i in list(range(len(halls))):
cur.execute('''UPDATE uHalls SET open_date = '{1}' WHERE hall_id = {0}'''
.format(halls.index[i], str(halls.iloc[i])))
#update open date in uStudios
studios = db_to_halls(conn)
studios['open_date'] = pd.to_datetime(studios['open_date'])
studios = studios.groupby('studio_id').agg(min)['open_date']
for i in list(range(len(studios))):
cur.execute('''UPDATE uStudios SET established_date = '{1}' WHERE studio_id = {0}'''
.format(studios.index[i], str(studios.iloc[i])))
conn.commit()Parsing-Update
Wir werden alle Verfahren in diesem und dem vorherigen Artikel in diesem Verfahren kombinieren. Es kann sowohl beim ersten Parsen als auch beim Aktualisieren von Daten gestartet werden.
Das Verfahren sieht folgendermaßen aus:
def update_parsing(directory = './/', is_manual = 0):
start_time = time.time()
#is DataBase exists?
if not os.path.exists(directory + 'photostudios_moscow1.sqlite'):
if is_manual == 1:
print('Data base is not exists. Do you want to create DataBase (y/n)? ')
answer = input().lower()
else:
answer == 'y'
if answer == 'y':
conn = sqlite3.connect(directory + 'photostudios_moscow1.sqlite')
conn.close()
print('DataBase is created')
elif answer != 'n':
print('Error in input!')
return list()
print('DataBase is exists')
print("--- %s seconds ---" % (time.time() - start_time))
start_time = time.time()
#connect to DataBase
conn = sqlite3.connect(directory + 'photostudios_moscow1.sqlite')
cur = conn.cursor()
#has DataBase 4 tables?
tables = [x[0] for x in list(cur.execute('SELECT name FROM sqlite_master WHERE type="table"'))]
if not ('uStudios' in tables) & ('uHalls' in tables) & ('uBooking_parsing' in tables) & ('uBooking' in tables):
if is_manual == 1:
print('Do you want to create missing tables (y/n)? ')
answer = input().lower()
else:
answer = 'y'
if anwer == 'y':
if not ('uStudios' in tables):
create_tables(conn, table = 'uStudios')
if not ('uHalls' in tables):
create_tables(conn, table = 'uHalls')
if not ('uBooking_parsing' in tables):
create_tables(conn, table = 'uBooking_parsing')
if not ('uBooking' in tables):
create_tables(conn, table = 'uBooking')
elif answer != 'n':
print('Error in input!')
return list()
conn.commit()
print(str(tables) + ' are exist in DataBase')
print("--- %s seconds ---" % (time.time() - start_time))
start_time = time.time()
#update uStudios
studios = studio_list()
new_studios = studios[[x not in list(db_to_studios(conn).index) for x in list(studios.index)]]
if len(new_studios) > 0:
print(str(len(new_studios)) + ' new studios detected: \n' + str(list(new_studios['name'])))
studios_to_db(conn, new_studios)
conn.commit()
print('Studio list update was successful')
print("--- %s seconds ---" % (time.time() - start_time))
start_time = time.time()
#update uHalls
halls = hall_list(list(studios.index)).sort_index()
new_halls = halls[[x not in list(db_to_halls(conn).index) for x in list(halls.index)]]
if len(new_halls) > 0:
halls_to_db(conn, new_halls)
conn.commit()
print('Halls list update was successful')
print("--- %s seconds ---" % (time.time() - start_time))
start_time = time.time()
#update uBooking_parsing
booking_to_db(conn, halls.index)
conn.commit()
print('Booking_parsing update was successful')
print("--- %s seconds ---" % (time.time() - start_time))
start_time = time.time()
#update uBooking from uBooking_parsing
cur.execute('DELETE FROM uBooking')
cur.execute('''
insert into uBooking (hall_id, date, hour, is_working_hour, min_hours, price, is_booked, duration, parsing_date)
select hall_id, date, hour, is_working_hour, min_hours, price, is_booked, duration, parsing_date
from
(
select *, row_number() over(partition by hall_id, date, hour order by parsing_date desc) rn
from uBooking_parsing
) t
where rn = 1
''')
conn.commit()
print('Booking update was successful')
print("--- %s seconds ---" % (time.time() - start_time))
start_time = time.time()
update_open_dates(conn)
conn.commit()
print('Open date update was successful')
print("--- %s seconds ---" % (time.time() - start_time))
conn.close()
Lassen Sie uns ihre Arbeit der Reihe nach analysieren.
Am Eingang der Prozedur übergeben wir zwei Parameter: die Adresse des Ordners, aus dem die Datenbank abgerufen oder installiert werden soll (standardmäßig wird der Ordner mit Python-Dokumenten verwendet), und den optionalen Parameter is_manual, der Sie auf "1" auffordert, eine Datenbank oder Tabellen zu erstellen in ihrer Abwesenheit.
. , :
if not os.path.exists(directory + 'photostudios_moscow1.sqlite'):
if is_manual == 1:
print('Data base is not exists. Do you want to create DataBase (y/n)? ')
answer = input().lower()
else:
answer == 'y'
if answer == 'y':
conn = sqlite3.connect(directory + 'photostudios_moscow1.sqlite')
conn.close()
print('DataBase is created')
elif answer != 'n':
print('Error in input!')
return list()
:
conn = sqlite3.connect(directory + 'photostudios_moscow1.sqlite')
cur = conn.cursor()
, . , . :
tables = [x[0] for x in list(cur.execute('SELECT name FROM sqlite_master WHERE type="table"'))]
if not ('uStudios' in tables) & ('uHalls' in tables) & ('uBooking_parsing' in tables) & ('uBooking' in tables):
if is_manual == 1:
print('Do you want to create missing tables (y/n)? ')
answer = input().lower()
else:
answer = 'y'
if anwer == 'y':
if not ('uStudios' in tables):
create_tables(conn, table = 'uStudios')
if not ('uHalls' in tables):
create_tables(conn, table = 'uHalls')
if not ('uBooking_parsing' in tables):
create_tables(conn, table = 'uBooking_parsing')
if not ('uBooking' in tables):
create_tables(conn, table = 'uBooking')
elif answer != 'n':
print('Error in input!')
return list()
conn.commit()
. :
conn.commit()
studios = studio_list()
new_studios = studios[[x not in list(db_to_studios(conn).index) for x in list(studios.index)]]
if len(new_studios) > 0:
print(str(len(new_studios)) + ' new studios detected: \n' + str(list(new_studios['name'])))
studios_to_db(conn, new_studios)conn.commit()
:
halls = hall_list(list(studios.index)).sort_index()
new_halls = halls[[x not in list(db_to_halls(conn).index) for x in list(halls.index)]]
if len(new_halls) > 0:
halls_to_db(conn, new_halls)
conn.commit()
uBooking_parsing. , .. booking_to_db
booking_to_db(conn, halls.index)
conn.commit()
uBooking. uBooking uBooking_parsing ( , ) :
cur.execute('DELETE FROM uBooking')
cur.execute('''
insert into uBooking (hall_id, date, hour, is_working_hour, min_hours, price, is_booked, duration, parsing_date)
select hall_id, date, hour, is_working_hour, min_hours, price, is_booked, duration, parsing_date
from
(
select *, row_number() over(partition by hall_id, date, hour order by parsing_date desc) rn
from uBooking_parsing
) t
where rn = 1
''')
conn.commit()
:
update_open_dates(conn)
conn.commit() conn.close()Das Parsen mit dem Speichern von Daten in der Datenbank wurde erfolgreich konfiguriert!
Wir starten das Parsen / Aktualisieren mit dem folgenden Verfahren:
update_parsing()Ergebnis
In diesem und dem vorherigen Artikel haben wir den Algorithmus zum Parsen offener Informationen für Fotostudios untersucht. Die erhaltenen Daten wurden in einer Datenbank gesammelt.
Im nächsten Artikel werden Beispiele für die Analyse der erhaltenen Daten betrachtet.
Das fertige Projekt finden Sie auf meiner Github- Seite .