* Dieser Artikel wurde basierend auf dem offenen Workshop REBRAIN & Yandex.Cloud verfasst. Wenn Sie das Video gerne ansehen, finden Sie es unter folgendem Link: https://youtu.be/cZLezUm0ekE
Vor kurzem hatten wir die Gelegenheit, Yandex.Cloud live zu berühren. Da wir es lange und fest spüren wollten, haben wir die Idee, einen einfachen WordPress-Blog mit Cloud-Basis zu starten, sofort aufgegeben - es ist zu langweilig. Nach einigen Überlegungen haben wir uns entschlossen, etwas Ähnliches wie die Produktionsarchitektur eines Dienstes für den Empfang und die Analyse von Ereignissen im Echtzeitmodus bereitzustellen.
Ich bin absolut sicher, dass die überwiegende Mehrheit der Online-Unternehmen (und nicht nur) auf die eine oder andere Weise einen Berg von Informationen über ihre Benutzer und ihre Aktionen sammelt. Dies ist zumindest erforderlich, um bestimmte Entscheidungen zu treffen. Wenn Sie beispielsweise ein Online-Spiel verwalten, können Sie Statistiken anzeigen, auf welcher Ebene Benutzer am wahrscheinlichsten stecken bleiben und Ihr Spielzeug löschen. Oder warum Benutzer Ihre Website verlassen, ohne etwas zu kaufen (Hallo, Yandex.Metrica).
Unsere Geschichte: Wie wir eine Anwendung in Golang geschrieben, Kafka gegen Rabbitmq gegen Yqs getestet, Daten-Streaming in einen Clickhouse-Cluster geschrieben und Daten mithilfe von Yandex-Daten visualisiert haben. All dies wurde natürlich mit Infrastrukturfreuden in Form von Docker, Terraform, Gitlab Ci und natürlich Prometheus gewürzt. Lass uns gehen!
Ich möchte sofort reservieren, dass wir nicht alles in einer Sitzung konfigurieren können - dafür benötigen wir mehrere Artikel in der Reihe. Ein wenig über die Struktur:
Teil 1 (Sie lesen es). Wir werden die technischen Spezifikationen und die Architektur der Lösung definieren und auch eine Anwendung in Golang schreiben.
Teil 2. Wir geben unsere Anwendung für die Produktion frei, machen sie skalierbar und testen die Last.
Teil 3. Versuchen wir herauszufinden, warum wir Nachrichten in einem Puffer und nicht in Dateien speichern müssen, und vergleichen wir auch den Warteschlangendienst kafka, rabbitmq und yandex untereinander.
Teil 4. Wir werden den Clickhouse-Cluster bereitstellen, Streaming schreiben, um Daten aus dem dortigen Puffer zu übertragen, und die Visualisierung in Daten einrichten.
Teil 5. Lassen Sie uns die gesamte Infrastruktur in den richtigen Zustand bringen - konfigurieren Sie ci / cd mit gitlab ci, verbinden Sie Überwachung und Serviceerkennung mit prometheus und consul.
TK
Zunächst formulieren wir die Leistungsbeschreibung - was genau wir am Ausgang erhalten wollen.
- Wir möchten einen Endpunkt der Form events.kis.im (kis.im ist die Testdomäne, die wir in allen Artikeln verwenden), der Ereignisse mit HTTPS akzeptieren sollte.
- Ereignisse sind ein einfaches json der Form: {"event": "view", "os": "linux", "browser": "chrome"}. In der letzten Phase werden wir etwas mehr Felder hinzufügen, aber dies wird keine große Rolle spielen. Wenn Sie möchten, können Sie zu protobuf wechseln.
- Der Dienst sollte 10.000 Ereignisse pro Sekunde verarbeiten können.
- Es sollte horizontal skalierbar sein, indem einfach neue Instanzen zu unserer Lösung hinzugefügt werden. Und es wäre schön, wenn wir das Front-End auf verschiedene Geolocations verschieben könnten, um die Latenz für Client-Anfragen zu verringern.
- Fehlertoleranz. Die Lösung muss stabil genug sein und überleben können, wenn Teile herunterfallen (natürlich bis zu einer bestimmten Menge).
Die Architektur
Im Allgemeinen wurden für diese Art von Aufgaben seit langem klassische Architekturen erfunden, mit denen Sie effektiv skalieren können. Die Abbildung zeigt ein Beispiel unserer Lösung.

Also, was wir haben:
1. Auf der linken Seite werden unsere Geräte angezeigt, die verschiedene Ereignisse erzeugen, unabhängig davon, ob sie die Anzahl der Spieler in einem Spielzeug auf einem Smartphone überschreiten oder eine Bestellung in einem Online-Shop über einen normalen Browser erstellen. Das Ereignis, wie im TOR angegeben, ist ein einfacher JSON, der an unseren Endpunkt - events.kis.im - gesendet wird.
2. Die ersten beiden Server sind einfache Balancer. Ihre Hauptaufgaben sind:
- . , , keepalived, IP .
- TLS. , TLS . -, , -, , backend .
- backend . — . , , load balancer’ .
3. Hinter den Balancern haben wir Anwendungsserver, auf denen eine ziemlich einfache Anwendung ausgeführt wird. Es sollte in der Lage sein, eingehende HTTP-Anforderungen zu akzeptieren, den gesendeten JSON zu validieren und die Daten in einem Puffer zu speichern.
4. Das Diagramm zeigt Kafka als Puffer, obwohl natürlich auch andere ähnliche Dienste auf dieser Ebene verwendet werden können. Wir werden Kafka, rabbitmq und yqs im dritten Artikel vergleichen.
5. Der vorletzte Punkt unserer Architektur ist Clickhouse - eine Säulendatenbank, mit der Sie eine große Datenmenge speichern und verarbeiten können. Auf dieser Ebene müssen wir Daten vom Puffer zum Speichersystem übertragen (mehr dazu in Artikel 4).
Diese Anordnung ermöglicht es uns, jede Schicht unabhängig horizontal zu skalieren. Backend-Server kommen nicht zurecht - fügen wir noch mehr hinzu -, da es sich um zustandslose Anwendungen handelt. Dies kann daher auch im automatischen Modus erfolgen. Es wird kein Puffer in Form einer Kafka gezogen - wir werden weitere Server hinzufügen und einige der Partitionen unseres Themas auf diese übertragen. Das Clickhouse schlägt fehl - es ist unmöglich :) Tatsächlich werden wir auch die Server löschen und die Daten teilen.
Übrigens, wenn Sie den optionalen Teil unserer technischen Spezifikation implementieren und die Skalierung in verschiedenen Geolokalisierungen vornehmen möchten, gibt es nichts Einfacheres:
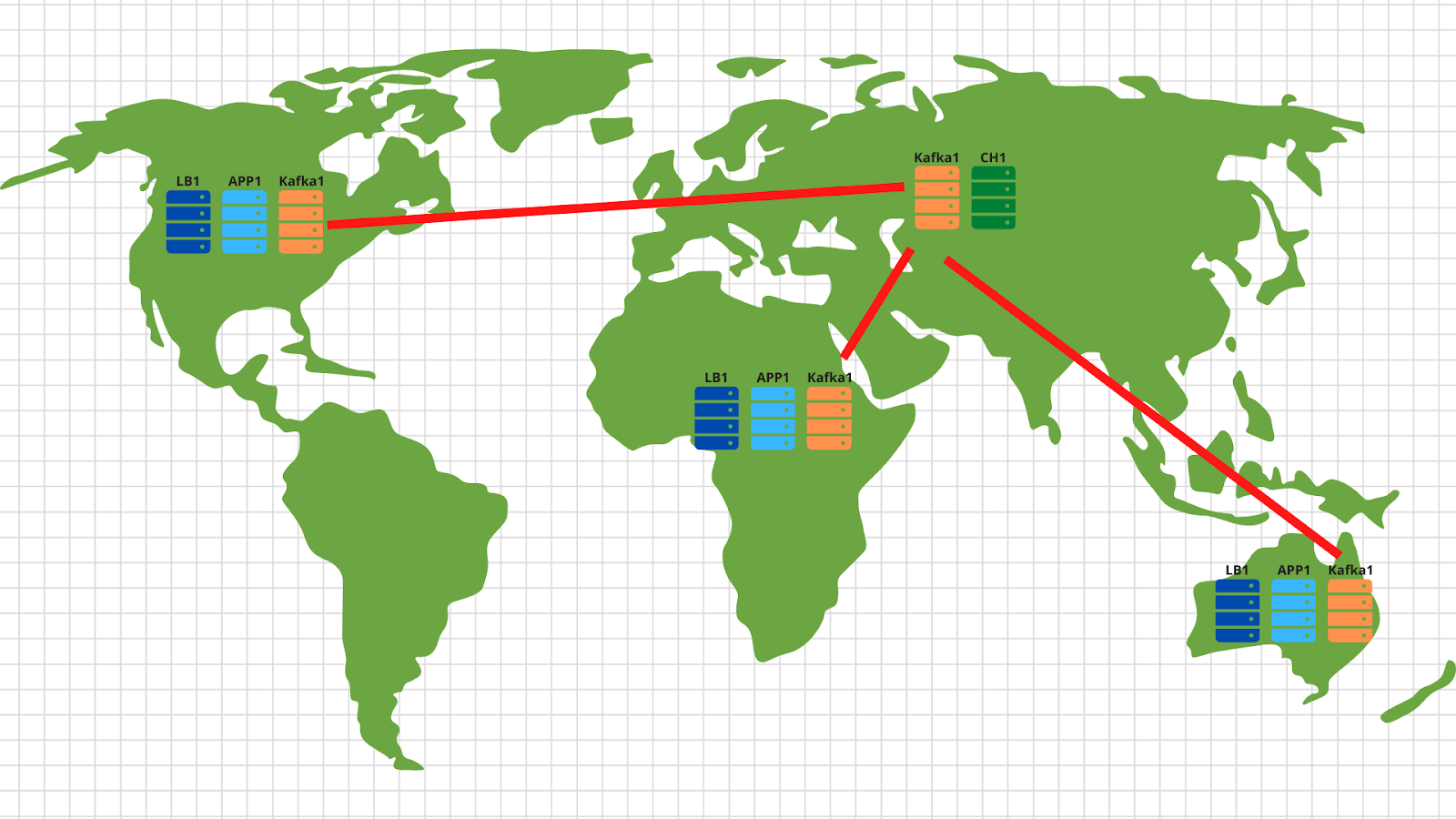
In jeder Geolocation stellen wir einen Load Balancer mit Anwendung und Kafka bereit. Im Allgemeinen reichen 2 Anwendungsserver, 3 Kafka-Knoten und ein Cloud-Balancer, z. B. Cloudflare, aus, um die Verfügbarkeit von Anwendungsknoten zu überprüfen und Anforderungen nach Geolokalisierung basierend auf der ursprünglichen IP-Adresse des Clients auszugleichen. Somit landen die vom amerikanischen Client gesendeten Daten auf den amerikanischen Servern. Und die Daten aus Afrika - über den Afrikaner.
Dann ist alles ganz einfach: Wir verwenden das Spiegelwerkzeug aus dem Kafka-Set und kopieren alle Daten von allen Standorten in unser zentrales Rechenzentrum in Russland. Im Inneren analysieren wir die Daten und schreiben sie zur anschließenden Visualisierung in Clickhouse.
Also haben wir die Architektur herausgefunden - fangen wir an, Yandex.Cloud zu schütteln!
Eine Bewerbung schreiben
Vor der Cloud müssen Sie noch ein wenig aushalten und einen ziemlich einfachen Dienst für die Verarbeitung eingehender Ereignisse schreiben. Wir werden Golang verwenden, da es sich als Sprache zum Schreiben von Netzwerkanwendungen sehr gut bewährt hat.
Nach einer Stunde (vielleicht ein paar Stunden) erhalten wir ungefähr Folgendes: https://github.com/RebrainMe/yandex-cloud-events/blob/master/app/main.go .
Was sind die wichtigsten Punkte hier, die ich beachten möchte:
1. Beim Starten der Anwendung können Sie zwei Flags angeben. Einer ist verantwortlich für den Port, an dem wir auf eingehende http-Anfragen (-addr) warten. Die zweite ist für die Adresse des Kafka-Servers, auf dem wir unsere Ereignisse aufzeichnen (-kafka):
addr = flag.String("addr", ":8080", "TCP address to listen to")
kafka = flag.String("kafka", "127.0.0.1:9092", "Kafka endpoints”)2. Die Anwendung verwendet die Sarama-Bibliothek ( [] github.com/Shopify/sarama ), um Nachrichten an den Kafka-Cluster zu senden. Wir stellen die Einstellungen sofort auf die maximale Verarbeitungsgeschwindigkeit ein:
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForLocal
config.Producer.Compression = sarama.CompressionSnappy
config.Producer.Return.Successes = true3. Außerdem verfügt unsere Anwendung über einen integrierten Prometheus-Client, der verschiedene Metriken erfasst, z.
- die Anzahl der Anfragen an unsere Bewerbung;
- die Anzahl der Fehler bei der Ausführung der Anfrage (es ist unmöglich, die Post-Anfrage zu lesen, defekt json, es ist unmöglich, in die Kafka zu schreiben);
- Verarbeitungszeit einer Anfrage von einem Client, einschließlich der Zeit zum Schreiben einer Nachricht an kafka.
4. Drei Endpunkte, die unsere Bewerbung verarbeitet:
- / status - kehre einfach in Ordnung zurück, um zu zeigen, dass wir am Leben sind. Sie können zwar einige Überprüfungen hinzufügen, z. B. die Verfügbarkeit des Kafka-Clusters.
- /metrics - Gemäß dieser URL gibt der Prometheus-Client die gesammelten Metriken zurück.
- /post — endpoint, POST json . json — -.
Ich werde reservieren, dass der Code nicht perfekt ist - er kann (und sollte!) Fertig sein. Sie können beispielsweise die Verwendung des integrierten Netzes / http beenden und zu schnellerem fasthttp wechseln. Oder Sie können Verarbeitungszeit und CPU-Ressourcen gewinnen, indem Sie die Überprüfung der JSON-Validierung auf einen späteren Zeitpunkt verschieben - wenn die Daten vom Puffer zum Clickhouse-Cluster übertragen werden.
Zusätzlich zur Entwicklungsseite des Problems haben wir sofort über unsere zukünftige Infrastruktur nachgedacht und beschlossen, unsere Anwendung über Docker bereitzustellen. Die endgültige Docker-Datei zum Erstellen der Anwendung lautet https://github.com/RebrainMe/yandex-cloud-events/blob/master/app/Dockerfile . Im Allgemeinen ist es ganz einfach. Der einzige Punkt, auf den ich aufmerksam machen möchte, ist die mehrstufige Baugruppe, mit der wir das endgültige Bild unseres Containers reduzieren können.
Erste Schritte in der Cloud
Zunächst registrieren wir uns unter cloud.yandex.ru . Nachdem Sie alle erforderlichen Felder ausgefüllt haben, erstellen wir ein Konto und gewähren einen Zuschuss für einen bestimmten Geldbetrag, der zum Testen von Cloud-Diensten verwendet werden kann. Wenn Sie alle Schritte aus unserem Artikel wiederholen möchten, sollte dieser Zuschuss für Sie ausreichen.
Nach der Registrierung werden eine separate Cloud und ein Standardverzeichnis für Sie erstellt, in denen Sie mit der Erstellung von Cloud-Ressourcen beginnen können. In Yandex.Cloud lautet die Beziehung zwischen Ressourcen im Allgemeinen wie folgt:

Sie können mehrere Clouds für ein Konto erstellen. Erstellen Sie in der Cloud verschiedene Verzeichnisse für verschiedene Unternehmensprojekte. Weitere Informationen hierzu finden Sie in der Dokumentation unter https://cloud.yandex.ru/docs/resource-manager/concepts/resources-hierarchy... Übrigens werde ich weiter unten im Text oft darauf verweisen. Als ich die gesamte Infrastruktur von Grund auf neu eingerichtet habe, hat mir die Dokumentation mehr als einmal geholfen. Ich rate Ihnen daher, zu studieren.
Zum Verwalten der Cloud können Sie sowohl die Weboberfläche als auch das Konsolendienstprogramm yc verwenden. Die Installation erfolgt mit einem Befehl (für Linux- und Mac-Betriebssysteme):
curl https://storage.yandexcloud.net/yandexcloud-yc/install.sh | bashWenn ein interner Sicherheitsbeamter über das Ausführen von Skripten aus dem Internet wütete, können Sie zum einen das Skript öffnen und lesen, und zum anderen führen wir es unter unserem Benutzer aus - ohne Root-Rechte.
Wenn Sie den Client für Windows installieren möchten, können Sie die Anweisungen hier verwenden und dann folgen,
yc initum ihn vollständig zu konfigurieren:
vozerov@mba:~ $ yc init
Welcome! This command will take you through the configuration process.
Please go to https://oauth.yandex.ru/authorize?response_type=token&client_id= in order to obtain OAuth token.
Please enter OAuth token:
Please select cloud to use:
[1] cloud-b1gv67ihgfu3bp (id = b1gv67ihgfu3bpt24o0q)
[2] fevlake-cloud (id = b1g6bvup3toribomnh30)
Please enter your numeric choice: 2
Your current cloud has been set to 'fevlake-cloud' (id = b1g6bvup3toribomnh30).
Please choose folder to use:
[1] default (id = b1g5r6h11knotfr8vjp7)
[2] Create a new folder
Please enter your numeric choice: 1
Your current folder has been set to 'default' (id = b1g5r6h11knotfr8vjp7).
Do you want to configure a default Compute zone? [Y/n]
Which zone do you want to use as a profile default?
[1] ru-central1-a
[2] ru-central1-b
[3] ru-central1-c
[4] Don't set default zone
Please enter your numeric choice: 1
Your profile default Compute zone has been set to 'ru-central1-a'.
vozerov@mba:~ $Im Prinzip ist der Vorgang einfach: Zuerst müssen Sie das oauth-Token für das Cloud-Management abrufen, die Cloud und den Ordner auswählen, den Sie verwenden möchten.
Wenn Sie mehrere Konten oder Ordner in derselben Cloud haben, können Sie zusätzliche Profile mit separaten Einstellungen über yc config profile create erstellen und zwischen diesen wechseln.
Zusätzlich zu den oben genannten Methoden hat das Yandex.Cloud-Team ein sehr gutes Terraform-Plugin für die Verwaltung von Cloud-Ressourcen geschrieben. Ich für meinen Teil habe ein Git-Repository vorbereitet, in dem ich alle Ressourcen beschrieben habe, die im Rahmen des Artikels erstellt werden - https://github.com/rebrainme/yandex-cloud-events/ . Wir interessieren uns für den Master-Zweig, klonen wir ihn lokal:
vozerov@mba:~ $ git clone https://github.com/rebrainme/yandex-cloud-events/ events
Cloning into 'events'...
remote: Enumerating objects: 100, done.
remote: Counting objects: 100% (100/100), done.
remote: Compressing objects: 100% (68/68), done.
remote: Total 100 (delta 37), reused 89 (delta 26), pack-reused 0
Receiving objects: 100% (100/100), 25.65 KiB | 168.00 KiB/s, done.
Resolving deltas: 100% (37/37), done.
vozerov@mba:~ $ cd events/terraform/Alle in terraform verwendeten Hauptvariablen werden in die Datei main.tf geschrieben. Erstellen Sie zunächst eine Datei private.auto.tfvars im Ordner terraform mit folgendem Inhalt:
# Yandex Cloud Oauth token
yc_token = ""
# Yandex Cloud ID
yc_cloud_id = ""
# Yandex Cloud folder ID
yc_folder_id = ""
# Default Yandex Cloud Region
yc_region = "ru-central1-a"
# Cloudflare email
cf_email = ""
# Cloudflare token
cf_token = ""
# Cloudflare zone id
cf_zone_id = ""Alle Variablen können aus der yc-Konfigurationsliste entnommen werden, da wir das Konsolendienstprogramm bereits konfiguriert haben. Ich empfehle Ihnen, private.auto.tfvars sofort zu .gitignore hinzuzufügen, um nicht versehentlich private Daten zu veröffentlichen.
In private.auto.tfvars haben wir auch Daten aus Cloudflare angegeben - zum Erstellen von DNS-Datensätzen und zum Proxying der Hauptdomäne events.kis.im auf unsere Server. Wenn Sie Cloudflare nicht verwenden möchten, entfernen Sie die Initialisierung des Cloudflare-Anbieters in main.tf und der Datei dns.tf, die für die Erstellung der erforderlichen DNS-Datensätze verantwortlich ist.
In unserer Arbeit werden wir alle drei Methoden kombinieren - das Webinterface, das Konsolendienstprogramm und Terraform.
Virtuelle Netzwerke
Ehrlich gesagt könnte dieser Schritt übersprungen werden, da Sie beim Erstellen einer neuen Cloud automatisch ein separates Netzwerk und 3 Subnetze haben - eines für jede Verfügbarkeitszone. Dennoch möchte ich für unser Projekt ein separates Netzwerk mit eigener Adressierung einrichten. Das allgemeine Schema des Netzwerks in Yandex.Cloud ist in der folgenden Abbildung dargestellt (ehrlich gesagt aus https://cloud.yandex.ru/docs/vpc/concepts/ ).
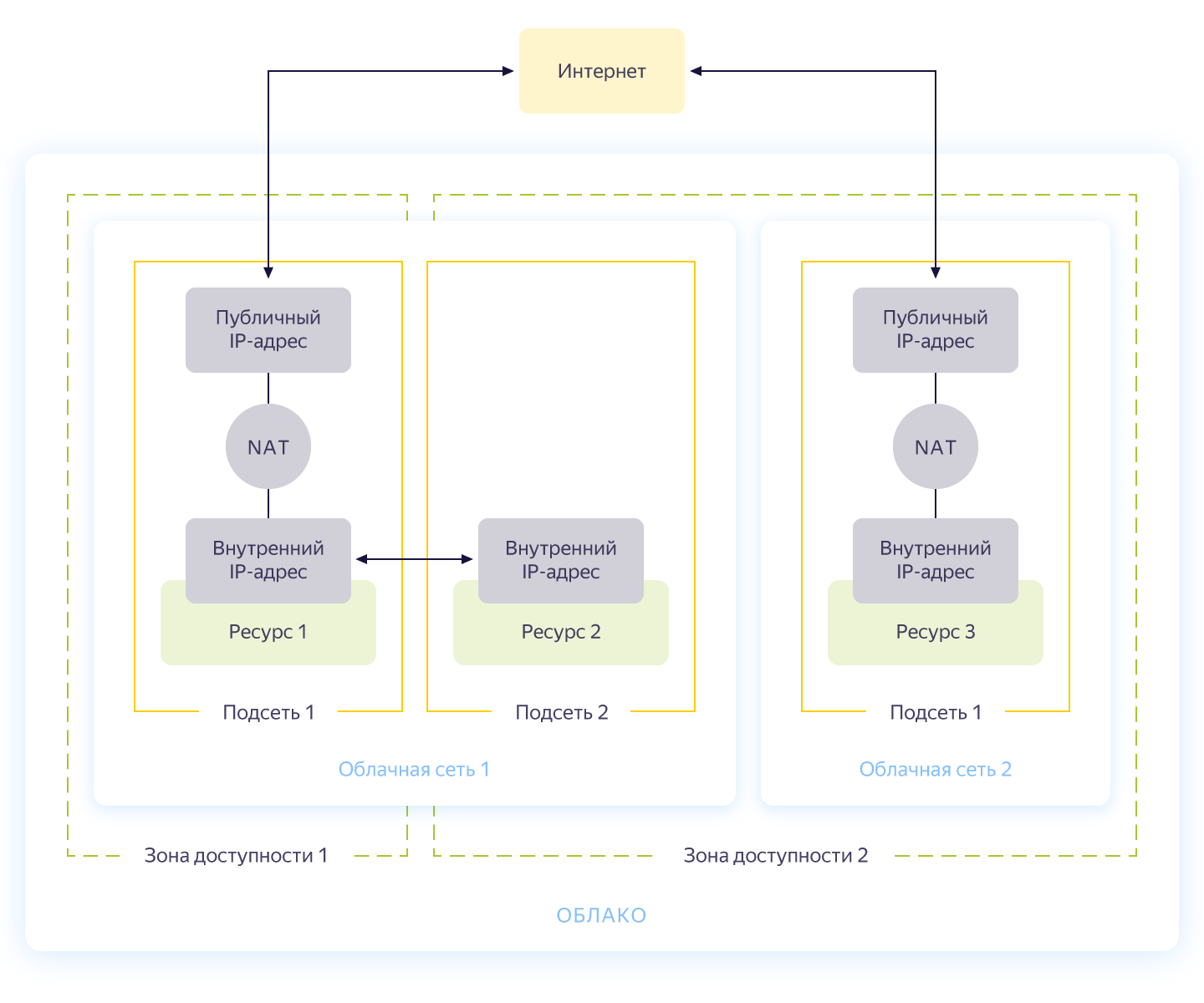
Sie erstellen also ein gemeinsames Netzwerk, in dem Ressourcen miteinander kommunizieren können. Für jede Verfügbarkeitszone wird ein Subnetz mit eigener Adressierung erstellt und mit dem öffentlichen Netzwerk verbunden. Infolgedessen können alle darin enthaltenen Cloud-Ressourcen kommunizieren, selbst wenn sie sich in unterschiedlichen Verfügbarkeitszonen befinden. Ressourcen, die mit verschiedenen Cloud-Netzwerken verbunden sind, können sich nur über externe Adressen sehen. Übrigens, wie diese Magie im Inneren funktioniert, wurde auf Habré gut beschrieben .
Die Netzwerkerstellung wird in der Datei network.tf aus dem Repository beschrieben. Dort erstellen wir ein gemeinsames privates Netzwerk intern und verbinden drei Subnetze in verschiedenen Verfügbarkeitszonen damit - intern-a (172.16.1.0/24), intern-b (172.16.2.0/24), intern-c (172.16.3.0/24) ).
Wir initialisieren Terraform und erstellen Netzwerke:
vozerov@mba:~/events/terraform (master) $ terraform init
... skipped ..
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_vpc_subnet.internal-a -target yandex_vpc_subnet.internal-b -target yandex_vpc_subnet.internal-c
... skipped ...
Plan: 4 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
yandex_vpc_network.internal: Creating...
yandex_vpc_network.internal: Creation complete after 3s [id=enp2g2rhile7gbqlbrkr]
yandex_vpc_subnet.internal-a: Creating...
yandex_vpc_subnet.internal-b: Creating...
yandex_vpc_subnet.internal-c: Creating...
yandex_vpc_subnet.internal-a: Creation complete after 6s [id=e9b1dad6mgoj2v4funog]
yandex_vpc_subnet.internal-b: Creation complete after 7s [id=e2liv5i4amu52p64ac9p]
yandex_vpc_subnet.internal-c: Still creating... [10s elapsed]
yandex_vpc_subnet.internal-c: Creation complete after 10s [id=b0c2qhsj2vranoc9vhcq]
Apply complete! Resources: 4 added, 0 changed, 0 destroyed.Ausgezeichnet! Wir haben unser Netzwerk aufgebaut und sind nun bereit, unsere internen Services zu erstellen.
Virtuelle Maschinen erstellen
Um die Anwendung zu testen, reicht es aus, zwei virtuelle Maschinen zu erstellen - wir benötigen die erste zum Erstellen und Ausführen der Anwendung, die zweite -, um kafka auszuführen, mit dem wir eingehende Nachrichten speichern. Und wir werden eine weitere Maschine erstellen, auf der wir prometheus für die Überwachung der Anwendung konfigurieren.
Virtuelle Maschinen werden mit ansible konfiguriert. Stellen Sie daher vor dem Starten von terraform sicher, dass Sie über eine der neuesten ansible-Versionen verfügen. Und installieren Sie die erforderlichen Rollen mit ansible galaxy:
vozerov@mba:~/events/terraform (master) $ cd ../ansible/
vozerov@mba:~/events/ansible (master) $ ansible-galaxy install -r requirements.yml
- cloudalchemy-prometheus (master) is already installed, skipping.
- cloudalchemy-grafana (master) is already installed, skipping.
- sansible.kafka (master) is already installed, skipping.
- sansible.zookeeper (master) is already installed, skipping.
- geerlingguy.docker (master) is already installed, skipping.
vozerov@mba:~/events/ansible (master) $Im ansible-Ordner befindet sich eine Beispielkonfigurationsdatei .ansible.cfg, die ich verwende. Vielleicht nützlich.
Stellen Sie vor dem Erstellen virtueller Maschinen sicher, dass ssh-agent ausgeführt und ein ssh-Schlüssel hinzugefügt wurde. Andernfalls kann terraform keine Verbindung zu den erstellten Maschinen herstellen. Ich bin natürlich auf einen Fehler in OS X gestoßen: https://github.com/ansible/ansible/issues/32499#issuecomment-341578864 . Um zu vermeiden, dass diese Geschichte wiederholt wird, fügen Sie env eine kleine Variable hinzu, bevor Sie Terraform starten:
vozerov@mba:~/events/terraform (master) $ export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YESErstellen Sie die erforderlichen Ressourcen im Terraform-Ordner:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_compute_instance.build -target yandex_compute_instance.monitoring -target yandex_compute_instance.kafka
yandex_vpc_network.internal: Refreshing state... [id=enp2g2rhile7gbqlbrkr]
data.yandex_compute_image.ubuntu_image: Refreshing state...
yandex_vpc_subnet.internal-a: Refreshing state... [id=e9b1dad6mgoj2v4funog]
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
... skipped ...
Plan: 3 to add, 0 to change, 0 to destroy.
... skipped ...Wenn alles gut endete (und es sollte sein), werden wir drei virtuelle Maschinen haben:
- build - eine Maschine zum Testen und Erstellen einer Anwendung. Docker wurde automatisch von ansible installiert.
- Überwachung - Maschine zur Überwachung - Prometheus & Grafana ist darauf installiert. Login / Passwort ist Standard: admin / admin
- kafka ist ein kleines Auto mit installiertem kafka, das an Port 9092 erhältlich ist.
Stellen wir sicher, dass alle vorhanden sind:
vozerov@mba:~/events (master) $ yc compute instance list
+----------------------+------------+---------------+---------+---------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+------------+---------------+---------+---------------+-------------+
| fhm081u8bkbqf1pa5kgj | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.35 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+------------+---------------+---------+---------------+-------------+Die Ressourcen sind vorhanden, und von hier aus können wir ihre IP-Adressen abrufen. Überall unten werde ich IP-Adressen verwenden, um eine Verbindung über ssh herzustellen und die Anwendung zu testen. Wenn Sie ein Cloudflare-Konto mit Terraform verbunden haben, können Sie die neu erstellten DNS-Namen verwenden.
Übrigens werden beim Erstellen einer virtuellen Maschine eine interne IP-Adresse und ein interner DNS-Name ausgegeben, sodass Sie nach Namen auf Server im Netzwerk verweisen können:
ubuntu@build:~$ ping kafka.ru-central1.internal
PING kafka.ru-central1.internal (172.16.1.31) 56(84) bytes of data.
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=1 ttl=63 time=1.23 ms
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=2 ttl=63 time=0.625 ms
^C
--- kafka.ru-central1.internal ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.625/0.931/1.238/0.308 msDies ist nützlich, um der Anwendung einen Endpunkt mit kafk anzuzeigen.
Antrag zusammenstellen
Großartig, es gibt Server, es gibt eine Anwendung - alles, was bleibt, ist, sie zu sammeln und zu veröffentlichen. Für die Assembly verwenden wir den üblichen Docker-Build, aber als Image-Speicher übernehmen wir den Service von Yandex - der Container-Registrierung. Aber das Wichtigste zuerst.
Kopieren Sie die Anwendung auf den Buildcomputer, gehen Sie zu ssh und sammeln Sie das Image:
vozerov@mba:~/events/terraform (master) $ cd ..
vozerov@mba:~/events (master) $ rsync -av app/ ubuntu@84.201.132.3:app/
... skipped ...
sent 3849 bytes received 70 bytes 7838.00 bytes/sec
total size is 3644 speedup is 0.93
vozerov@mba:~/events (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cd app
ubuntu@build:~/app$ sudo docker build -t app .
Sending build context to Docker daemon 6.144kB
Step 1/9 : FROM golang:latest AS build
... skipped ...
Successfully built 9760afd8ef65
Successfully tagged app:latestDie halbe Miete ist geschafft - jetzt können wir die Funktionalität unserer Anwendung überprüfen, indem wir sie ausführen und auf kafka verweisen:
ubuntu@build:~/app$ sudo docker run --name app -d -p 8080:8080 app /app/app -kafka=kafka.ru-central1.internal:9092</code>
event :
<code>vozerov@mba:~/events (master) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://84.201.132.3:8080/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 13:53:54 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":0}
vozerov@mba:~/events (master) $Die Anwendung antwortete mit dem Erfolg der Aufzeichnung und gab die ID der Partition und den Offset an, in die die Nachricht fiel. Das einzige, was Sie tun müssen, ist, eine Registrierung in Yandex.Cloud zu erstellen und dort unser Bild hochzuladen (wie dies in drei Zeilen geschieht, wird in der Datei registry.tf beschrieben). Wir erstellen ein Repository:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_container_registry.events
... skipped ...
Plan: 1 to add, 0 to change, 0 to destroy.
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Es gibt verschiedene Möglichkeiten, sich in der Containerregistrierung zu authentifizieren - mit oauth-Token, iam-Token oder Dienstkontoschlüssel. Weitere Informationen zu diesen Methoden finden Sie in der Dokumentation https://cloud.yandex.ru/docs/container-registry/operations/authentication . Wir werden den Dienstkontoschlüssel verwenden, also erstellen wir ein Konto:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_iam_service_account.docker -target yandex_resourcemanager_folder_iam_binding.puller -target yandex_resourcemanager_folder_iam_binding.pusher
... skipped ...
Apply complete! Resources: 3 added, 0 changed, 0 destroyed.Jetzt bleibt ihm ein Schlüssel zu machen:
vozerov@mba:~/events/terraform (master) $ yc iam key create --service-account-name docker -o key.json
id: ajej8a06kdfbehbrh91p
service_account_id: ajep6d38k895srp9osij
created_at: "2020-04-13T14:00:30Z"
key_algorithm: RSA_2048Wir erhalten Informationen über die ID unseres Speichers, drehen den Schlüssel um und melden uns an:
vozerov@mba:~/events/terraform (master) $ scp key.json ubuntu@84.201.132.3:
key.json 100% 2392 215.1KB/s 00:00
vozerov@mba:~/events/terraform (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cat key.json | sudo docker login --username json_key --password-stdin cr.yandex
WARNING! Your password will be stored unencrypted in /home/ubuntu/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
ubuntu@build:~$Um das Bild in die Registrierung zu laden, benötigen wir die ID-Container-Registrierung, die wir dem Dienstprogramm yc entnehmen:
vozerov@mba:~ $ yc container registry get events
id: crpdgj6c9umdhgaqjfmm
folder_id:
name: events
status: ACTIVE
created_at: "2020-04-13T13:56:41.914Z"Danach kennzeichnen wir unser Bild mit einem neuen Namen und laden:
ubuntu@build:~$ sudo docker tag app cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
ubuntu@build:~$ sudo docker push cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
The push refers to repository [cr.yandex/crpdgj6c9umdhgaqjfmm/events]
8c286e154c6e: Pushed
477c318b05cb: Pushed
beee9f30bc1f: Pushed
v1: digest: sha256:1dd5aaa9dbdde2f60d833be0bed1c352724be3ea3158bcac3cdee41d47c5e380 size: 946Wir können sicherstellen, dass das Image erfolgreich gestartet wurde:
vozerov@mba:~/events/terraform (master) $ yc container repository list
+----------------------+-----------------------------+
| ID | NAME |
+----------------------+-----------------------------+
| crpe8mqtrgmuq07accvn | crpdgj6c9umdhgaqjfmm/events |
+----------------------+-----------------------------+Übrigens, wenn Sie das Dienstprogramm yc auf einem Linux-Computer installieren, können Sie den Befehl verwenden
yc container registry configure-dockerfür Docker-Setup.
Fazit
Wir haben einen tollen und schwierigen Job gemacht und als Ergebnis:
- .
- golang, -.
- container registry.
Im nächsten Teil werden wir zum interessanten Teil übergehen - wir werden unsere Anwendung in die Produktion einfließen lassen und schließlich die Last darauf starten. Nicht wechseln!
Dieses Material befindet sich im Video des offenen Workshops REBRAIN & Yandex.Cloud: Wir akzeptieren 10.000 Anfragen pro Sekunde in der Yandex Cloud - https://youtu.be/cZLezUm0ekE
Wenn Sie daran interessiert sind, an solchen Veranstaltungen online teilzunehmen und Fragen in Echtzeit zu stellen, stellen Sie eine Verbindung zum Kanal her DevOps von REBRAIN .
Wir möchten uns ganz besonders bei Yandex.Cloud für die Gelegenheit bedanken, eine solche Veranstaltung abzuhalten. Ein Link zu ihnen lautet https://cloud.yandex.ru/prices.
Wenn Sie in die Cloud wechseln oder Fragen zu Ihrer Infrastruktur haben, können Sie gerne eine Anfrage hinterlassen .
P.S. 2 , , .