Betrugsbekämpfungskopf Andrey Popov Nox_andryhielt einen Vortrag darüber, wie wir all diese widersprüchlichen Anforderungen erfüllen konnten. Das zentrale Thema des Berichts ist ein Modell zur Berechnung komplexer Faktoren in einem Datenstrom und zur Gewährleistung der Systemfehlertoleranz. Andrey hat auch kurz die nächste, noch schnellere Iteration von Betrugsbekämpfung beschrieben, die wir derzeit entwickeln.
Das Betrugsbekämpfungsteam löst im Wesentlichen das Problem der binären Klassifizierung. Daher kann der Bericht nicht nur für Betrugsbekämpfungsspezialisten von Interesse sein, sondern auch für diejenigen, die verschiedene Systeme herstellen, die schnelle, zuverlässige und flexible Faktoren für große Datenmengen benötigen.
- Hallo, ich heiße Andrey. Ich arbeite bei Yandex und bin verantwortlich für die Entwicklung von Betrugsbekämpfung. Mir wurde gesagt, dass die Leute das Wort "Funktionen" bevorzugen, daher werde ich es während des gesamten Vortrags erwähnen, aber der Titel und die Einleitung blieben mit dem Wort "Faktoren" gleich.
Was ist Betrugsbekämpfung?
Was ist überhaupt Betrugsbekämpfung? Es ist ein System, das Benutzer vor negativen Auswirkungen auf den Dienst schützt. Mit negativem Einfluss meine ich absichtliche Handlungen, die die Qualität des Dienstes beeinträchtigen und dementsprechend die Benutzererfahrung verschlechtern können. Dies können relativ einfache Parser und Roboter sein, die unsere Statistiken verschlechtern, oder absichtlich komplexe betrügerische Aktivitäten. Die zweite ist natürlich schwieriger und interessanter zu definieren.
Gegen was bekämpft Betrugsbekämpfung? Ein paar Beispiele.
Zum Beispiel Nachahmung von Benutzeraktionen. Dies tun die Leute, die wir "Black SEO" nennen - diejenigen, die die Qualität der Website und den Inhalt der Website nicht verbessern wollen. Stattdessen schreiben sie Roboter, die zur Yandex-Suche gehen, und klicken auf ihre Site. Sie erwarten, dass ihre Website auf diese Weise höher steigt. Nur für den Fall, ich erinnere Sie daran, dass solche Handlungen der Benutzervereinbarung widersprechen und zu schwerwiegenden Sanktionen von Yandex führen können.

Oder zum Beispiel Bewertungen betrügen. Eine solche Überprüfung kann von der Organisation auf Karten gesehen werden, die Plastikfenster setzt. Sie selbst hat für diese Bewertung bezahlt.
Die Betrugsbekämpfungsarchitektur der obersten Ebene sieht folgendermaßen aus: Eine bestimmte Reihe von Rohereignissen fällt wie eine Black Box in das Betrugsbekämpfungssystem. Am Ausgang werden markierte Ereignisse generiert.
Yandex hat viele Dienstleistungen. Alle, besonders große, sind auf die eine oder andere Weise unterschiedlichen Arten von Betrug ausgesetzt. Suche, Markt, Karten und Dutzende anderer.
Wo waren wir vor zwei oder drei Jahren? Jedes Team überlebte unter dem Ansturm des Betrugs so gut es ging. Sie stellte ihre Betrugsbekämpfungsteams zusammen. Ihre Systeme, die nicht immer gut funktionierten, waren für die Interaktion mit Analysten nicht sehr praktisch. Und vor allem waren sie schlecht miteinander integriert.
Ich möchte Ihnen sagen, wie wir dies durch die Schaffung einer einzigen Plattform gelöst haben.

Warum brauchen wir eine einzige Plattform? Wiederverwendung von Erfahrungen und Daten. Durch die Zentralisierung von Erfahrung und Daten an einem Ort können Sie schneller und besser auf große Angriffe reagieren - diese sind normalerweise dienstübergreifend.
Unified Toolkit. Die Menschen haben die Werkzeuge, an die sie gewöhnt sind. Und natürlich die Verbindungsgeschwindigkeit. Wenn wir einen neuen Dienst gestartet haben, der derzeit aktiv angegriffen wird, müssen wir schnell einen hochwertigen Betrugsbekämpfungsdienst daran anschließen.
Wir können sagen, dass wir in dieser Hinsicht nicht einzigartig sind. Alle großen Unternehmen stehen vor ähnlichen Problemen. Und jeder, mit dem wir kommunizieren, schafft seine einzige Plattform.
Ich erzähle Ihnen ein wenig darüber, wie wir Betrugsbekämpfung klassifizieren.
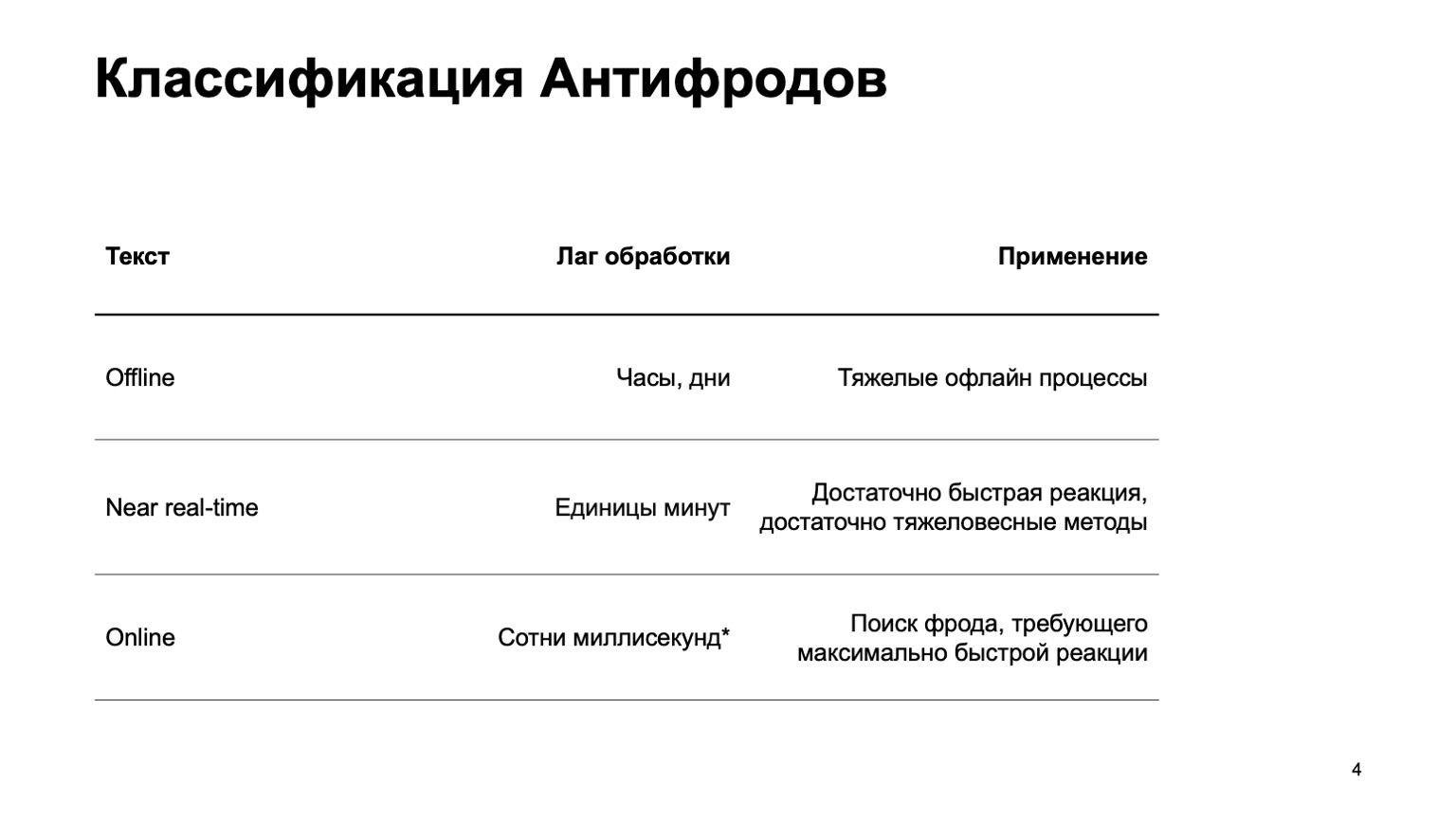
Dies kann ein Offline-System sein, das Stunden, Tage und schwere Offline-Prozesse zählt: zum Beispiel komplexes Clustering oder komplexes Retraining. Ich werde diesen Teil des Berichts praktisch nicht ansprechen. Es gibt einen Echtzeit-Teil, der in wenigen Minuten funktioniert. Dies ist eine Art goldener Mittelwert, sie hat schnelle Reaktionen und schwere Methoden. Zunächst werde ich mich auf sie konzentrieren. Es ist jedoch ebenso wichtig zu sagen, dass wir zu diesem Zeitpunkt Daten aus der obigen Phase verwenden.
Es gibt auch Online-Teile, die an Stellen benötigt werden, an denen eine schnelle Reaktion erforderlich ist, und es ist wichtig, Betrug auszumerzen, noch bevor wir das Ereignis erhalten und an den Benutzer weitergegeben haben. Hier verwenden wir wieder Daten und Algorithmen für maschinelles Lernen, die auf höheren Ebenen berechnet wurden.
Ich werde darüber sprechen, wie diese einheitliche Plattform funktioniert, über die Sprache zur Beschreibung von Funktionen und zur Interaktion mit dem System, über unseren Weg zur Geschwindigkeitssteigerung, dh über den Übergang von der zweiten zur dritten Stufe.
Ich werde die ML-Methoden selbst kaum ansprechen. Grundsätzlich werde ich über Plattformen sprechen, die Funktionen erstellen, die wir dann im Training verwenden.
Wer könnte daran interessiert sein? Offensichtlich für diejenigen, die Betrugsbekämpfung schreiben oder Betrüger bekämpfen. Aber auch für diejenigen, die nur den Datenstrom starten und die Funktionen lesen, erwägt ML. Da wir ein ziemlich allgemeines System erstellt haben, werden Sie vielleicht an einigen davon interessiert sein.
Was sind die Systemanforderungen? Es gibt einige von ihnen, hier sind einige von ihnen:
- Großer Datenstrom. Wir verarbeiten Hunderte Millionen Ereignisse in fünf Minuten.
- Vollständig konfigurierbare Funktionen.
- .
- , - exactly-once- , . — , , , , .
- , , .
Weiter werde ich Ihnen über jeden dieser Punkte separat berichten.
Da ich aus Sicherheitsgründen nicht über echte Services sprechen kann, stellen wir einen neuen Yandex-Service vor. Nein, vergessen Sie, dies ist ein fiktiver Dienst, den ich mir ausgedacht habe, um Beispiele zu zeigen. Es sei ein Dienst, bei dem die Leute eine Datenbank aller vorhandenen Bücher haben. Sie gehen hinein, geben Bewertungen von eins bis zehn und die Angreifer wollen die endgültige Bewertung beeinflussen, damit ihre Bücher gekauft werden.
Alle Zufälle mit realen Dienstleistungen sind natürlich zufällig. Betrachten wir zunächst die Echtzeit-Version, da Online hier in erster Näherung nicht speziell benötigt wird.
Große Daten
Yandex bietet eine klassische Methode zur Lösung von Big-Data-Problemen: Verwenden Sie MapReduce. Wir verwenden unsere eigene MapReduce-Implementierung namens YT . Übrigens hat Maxim Akhmedov heute Abend eine Geschichte über sie. Sie können Ihre Implementierung oder eine Open Source-Implementierung wie Hadoop verwenden.
Warum nutzen wir die Online-Version nicht sofort? Es wird nicht immer benötigt, es kann Neuberechnungen in die Vergangenheit erschweren. Wenn wir einen neuen Algorithmus und neue Funktionen hinzugefügt haben, möchten wir die Daten in der Vergangenheit häufig neu berechnen, um die Urteile darüber zu ändern. Es ist schwieriger, Schwergewichtsmethoden anzuwenden - ich denke, es ist klar, warum. Und die Online-Version kann aus mehreren Gründen ressourcenintensiver sein.
Wenn wir MapReduce verwenden, erhalten wir so etwas. Wir verwenden eine Art Mini-Batching, dh wir teilen die Charge in die kleinstmöglichen Teile. In diesem Fall ist es eine Minute. Aber diejenigen, die mit MapReduce arbeiten, wissen, dass weniger als diese Größe wahrscheinlich bereits zu große Gemeinkosten des Systems selbst hat - Gemeinkosten. Herkömmlicherweise wird es nicht in der Lage sein, die Verarbeitung in einer Minute zu bewältigen.
Als Nächstes führen wir den Reduce-Satz für diesen Satz von Stapeln aus und erhalten einen markierten Stapel.

Bei unseren Aufgaben ist es häufig erforderlich, den genauen Wert von Features zu berechnen. Wenn wir beispielsweise die genaue Anzahl der Bücher berechnen möchten, die der Benutzer im letzten Monat gelesen hat, berechnen wir diesen Wert für jede Charge und müssen alle gesammelten Statistiken an einem einzigen Ort speichern. Entfernen Sie dann alte Werte und fügen Sie neue hinzu.
Warum nicht grobe Zählmethoden anwenden? Kurze Antwort: Wir verwenden sie auch, aber manchmal ist es bei Betrugsbekämpfungsproblemen wichtig, für einige Intervalle genau den genauen Wert zu haben. Beispielsweise kann der Unterschied zwischen zwei und drei gelesenen Büchern für bestimmte Methoden erheblich sein.
Infolgedessen benötigen wir einen großen Datenverlauf, in dem wir diese Statistiken speichern.
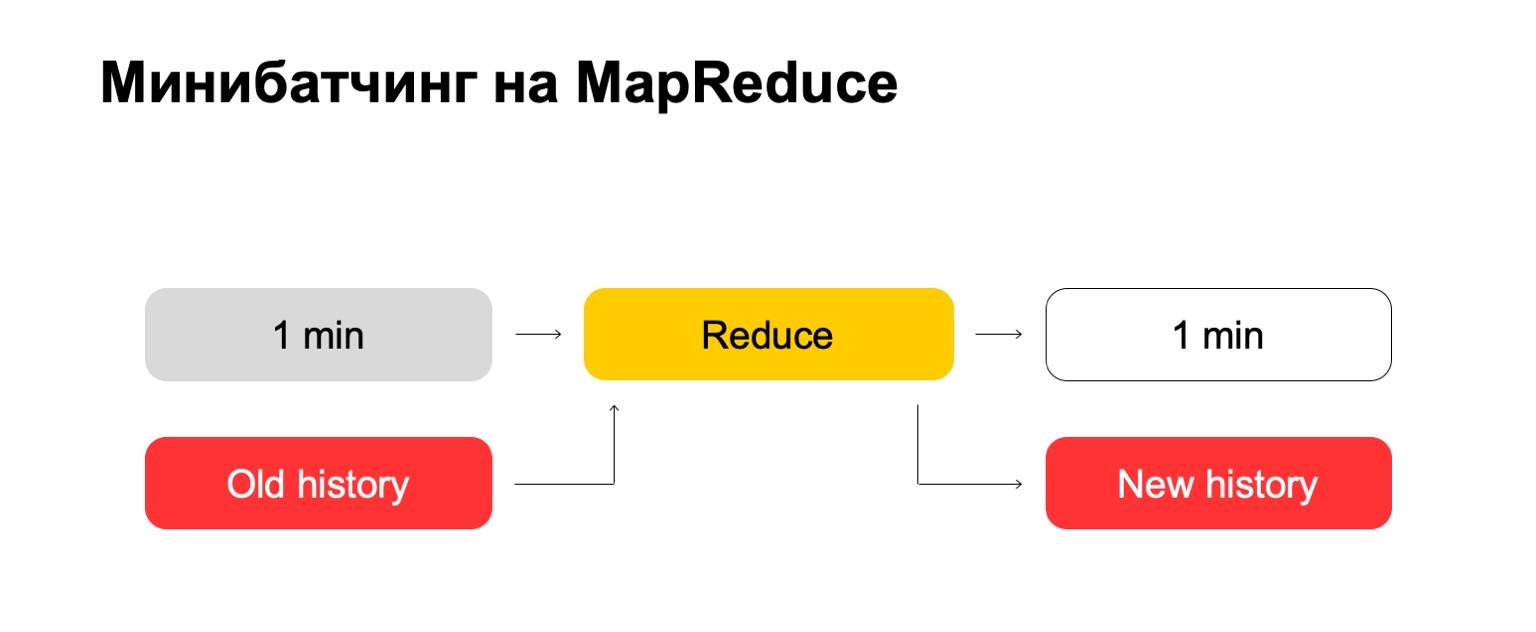
Versuchen wir es "frontal". Wir haben eine Minute und eine große alte Geschichte. Wir setzen es in die Eingaben reduzieren und geben einen aktualisierten Verlauf und ein markiertes Protokoll, Daten, aus.
Für diejenigen unter Ihnen, die mit MapReduce gearbeitet haben, wissen Sie wahrscheinlich, dass dies ziemlich schlecht funktionieren kann. Wenn der Verlauf hunderte oder sogar tausende, zehntausende Male größer sein kann als der Stapel selbst, kann eine solche Verarbeitung proportional zur Größe des Verlaufs und nicht zur Größe des Stapels funktionieren.
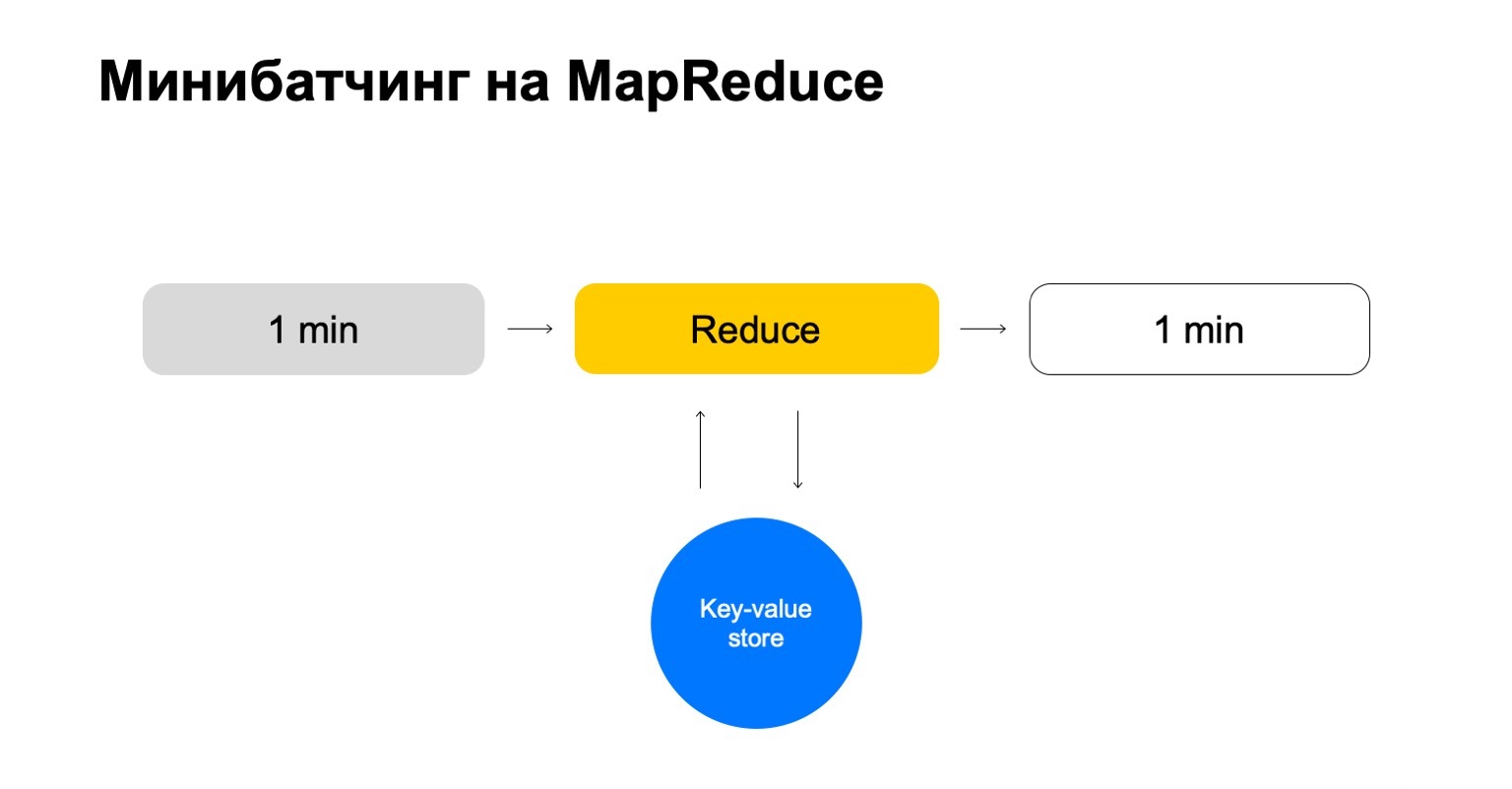
Ersetzen wir dies durch einen Schlüsselwertspeicher. Dies ist wieder unsere eigene Implementierung, die Speicherung von Schlüsselwerten, aber sie speichert Daten im Speicher. Das wahrscheinlich nächste Analogon ist eine Art Redis. Hier haben wir jedoch einen kleinen Vorteil: Unsere Implementierung des Schlüsselwertspeichers ist sehr eng in MapReduce und den MapReduce-Cluster integriert, auf dem er ausgeführt wird. Es stellt sich heraus, eine bequeme Transaktionalität, bequeme Datenübertragung zwischen ihnen.
Das allgemeine Schema ist jedoch, dass wir in jedem Job dieses Reduzierens zu diesem Schlüsselwertspeicher gehen, die Daten aktualisieren und sie zurückschreiben, nachdem wir ein Urteil darüber gebildet haben.
Am Ende haben wir eine Geschichte, die nur die Schlüssel handhabt, die wir brauchen, und die sich leicht skalieren lässt.
Konfigurierbare Funktionen
Ein wenig darüber, wie wir Funktionen konfigurieren. Einfache Zähler reichen oft nicht aus. Um nach Betrügern zu suchen, benötigen Sie eine Vielzahl von Funktionen und ein intelligentes und praktisches System zur Konfiguration.
Lassen Sie es uns in drei Schritte aufteilen:
- Extrahieren, wo wir Daten für den angegebenen Schlüssel und aus dem Protokoll extrahieren.
- Zusammenführen, wo wir diese Daten mit den Statistiken zusammenführen, die sich im Verlauf befinden.
- Erstellen Sie, wo wir den endgültigen Wert des Features bilden.
Berechnen wir beispielsweise den Prozentsatz der von einem Benutzer gelesenen Detektivgeschichten.
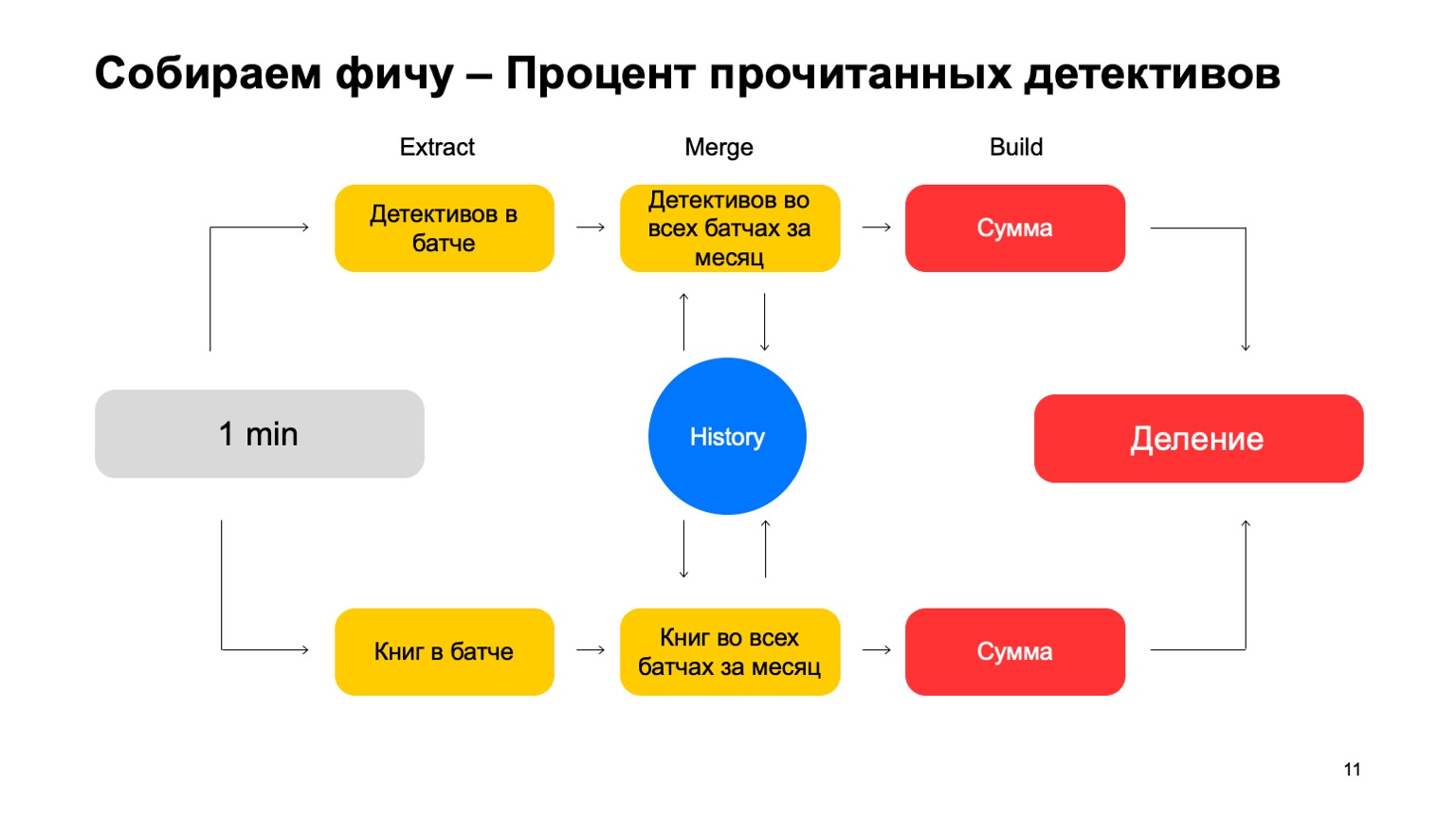
Wenn der Benutzer zu viele Detektivgeschichten liest, ist er zu misstrauisch. Es ist nie klar, was von ihm zu erwarten ist. Dann ist Extrahieren das Entfernen der Anzahl von Detectives, die der Benutzer in diesem Stapel gelesen hat. Zusammenführen - alle Detectives, alle diese Daten aus Chargen für einen Monat. Und Build ist eine Menge.
Dann tun wir dasselbe für den Wert aller Bücher, die er gelesen hat, und am Ende teilen wir uns.
Was ist, wenn wir verschiedene Werte zählen möchten, zum Beispiel die Anzahl der verschiedenen Autoren, die ein Benutzer liest?
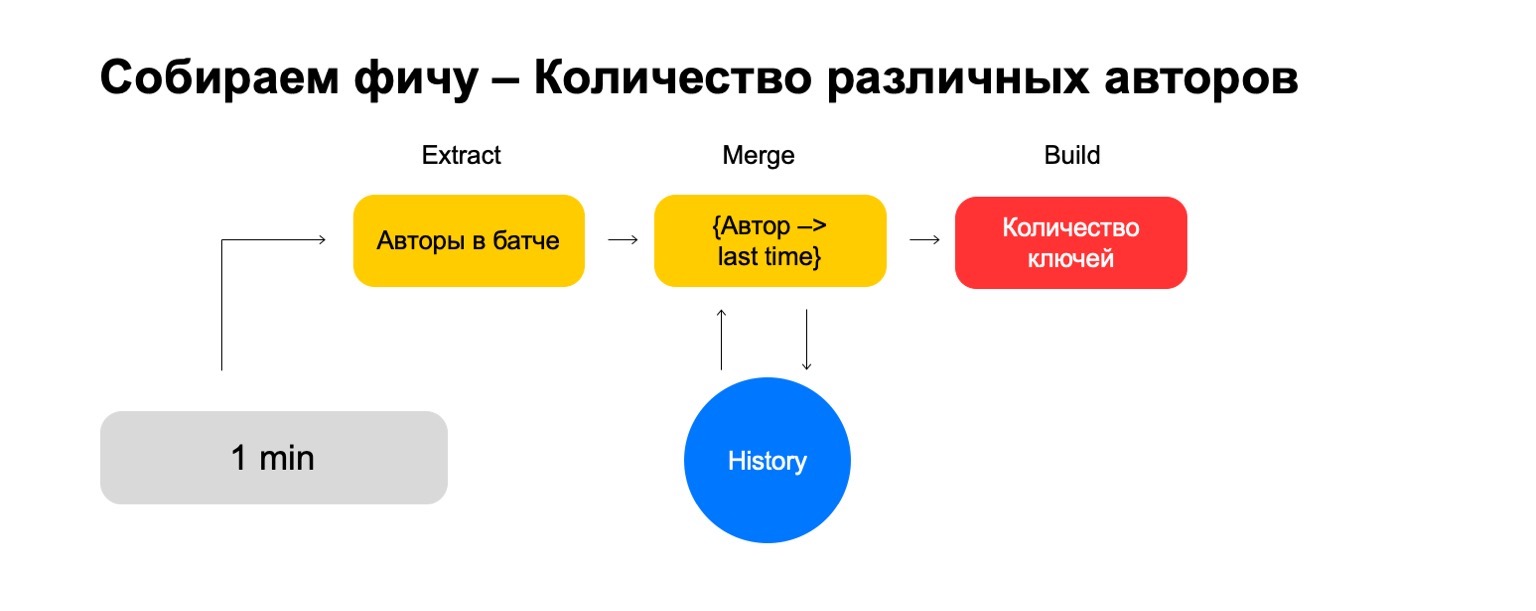
Dann können wir die Anzahl der verschiedenen Autoren nehmen, die der Benutzer in diesem Stapel gelesen hat. Speichern Sie außerdem eine Struktur, in der wir kürzlich eine Assoziation von Autoren herstellen, wenn der Benutzer sie liest. Wenn wir diesen Autor also wieder beim Benutzer treffen, aktualisieren wir diesmal. Wenn wir alte Ereignisse löschen müssen, wissen wir, was zu löschen ist. Um das endgültige Merkmal zu berechnen, zählen wir einfach die Anzahl der darin enthaltenen Schlüssel.

Bei einem verrauschten Signal reichen solche Merkmale jedoch nicht für einen Schnitt aus. Wir benötigen ein System zum Verkleben ihrer Verbindungen, bei dem diese Merkmale aus verschiedenen Schnitten geklebt werden.
Lassen Sie uns zum Beispiel solche Schnitte einführen - Benutzer, Autor und Genre.

Berechnen wir etwas Schwieriges. Zum Beispiel durchschnittliche Autorentreue. Mit Loyalität meine ich, dass Benutzer, die den Autor lesen, ihn fast nur lesen. Darüber hinaus ist dieser Durchschnittswert für die durchschnittliche Anzahl von Autoren, die von Benutzern gelesen wurden, die ihn lesen, ziemlich niedrig.
Dies könnte ein potenzielles Signal sein. Er kann natürlich bedeuten, dass der Autor einfach so ist: Es gibt nur Fans um ihn herum, jeder, der ihn liest, liest nur ihn. Es kann aber auch bedeuten, dass der Autor selbst versucht, das System zu betrügen und diese gefälschten Benutzer zu erstellen, die es angeblich lesen.
Versuchen wir es zu berechnen. Zählen wir eine Funktion, die die Anzahl der verschiedenen Autoren über einen langen Zeitraum zählt. Zum Beispiel scheinen uns hier der zweite und dritte Wert verdächtig, es gibt zu wenige davon.
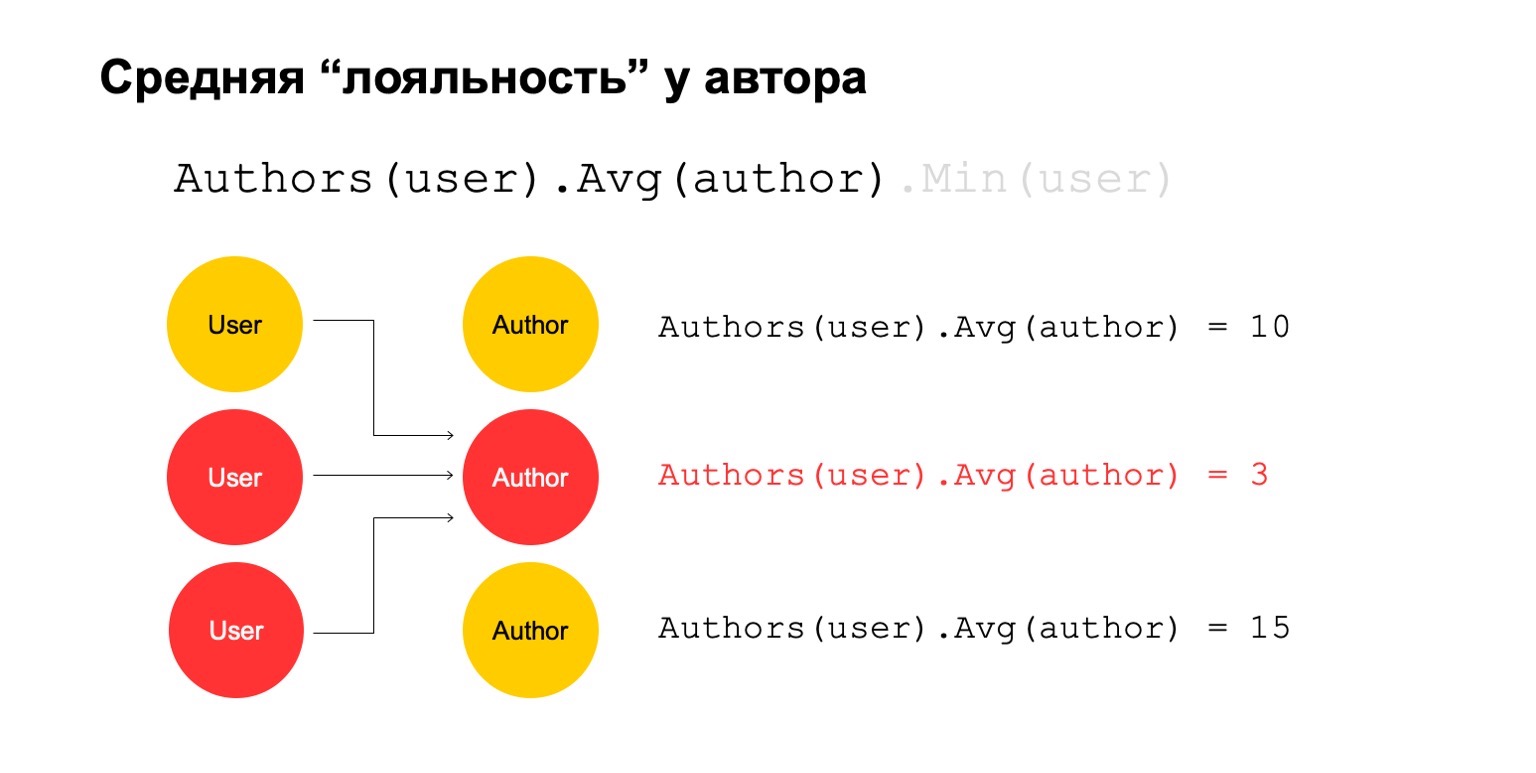
Berechnen wir dann den Durchschnittswert für die Autoren, die über ein großes Intervall verwandt sind. Und hier ist der Durchschnittswert wieder recht niedrig: 3. Aus irgendeinem Grund scheint uns dieser Autor misstrauisch.
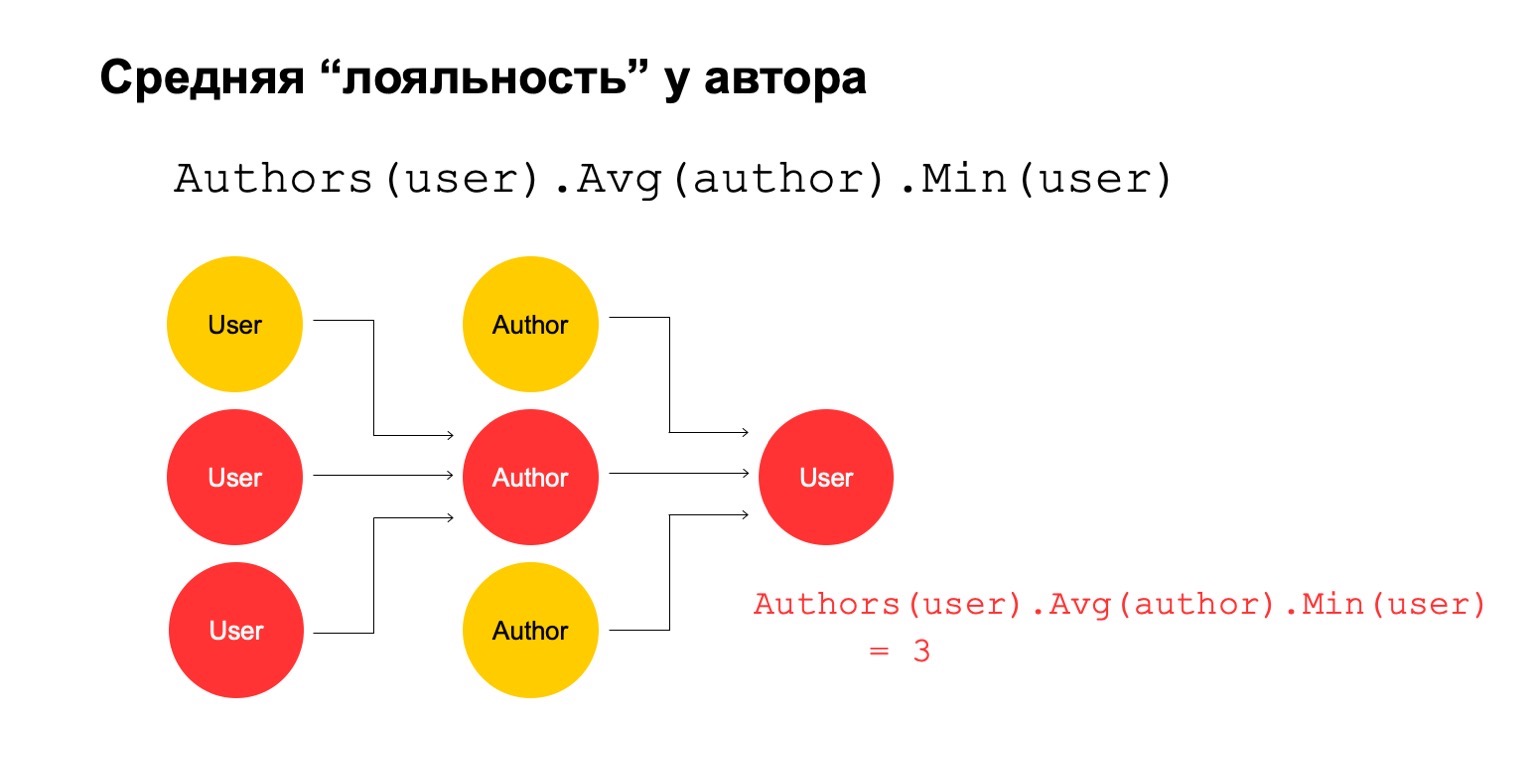
Und wir können es an den Benutzer zurückgeben, um zu verstehen, dass dieser bestimmte Benutzer eine Verbindung zum Autor hat, die uns verdächtig erscheint.
Es ist klar, dass dies an sich kein explizites Kriterium sein kann, dass der Benutzer gefiltert werden soll oder so etwas. Dies könnte jedoch eines der Signale sein, die wir verwenden können.
Wie geht das im MapReduce-Paradigma? Nehmen wir mehrere aufeinanderfolgende Reduzierungen und die Abhängigkeiten zwischen ihnen vor.

Wir erhalten eine grafische Darstellung der Reduzierungen. Es beeinflusst, welche Slices wir Features zählen, welche Joins im Allgemeinen zulässig sind, und wie viel Ressourcen verbraucht werden: Je mehr Reduzierungen, desto mehr Ressourcen. Und Latenz, Durchsatz.
Lassen Sie uns zum Beispiel einen solchen Graphen konstruieren.
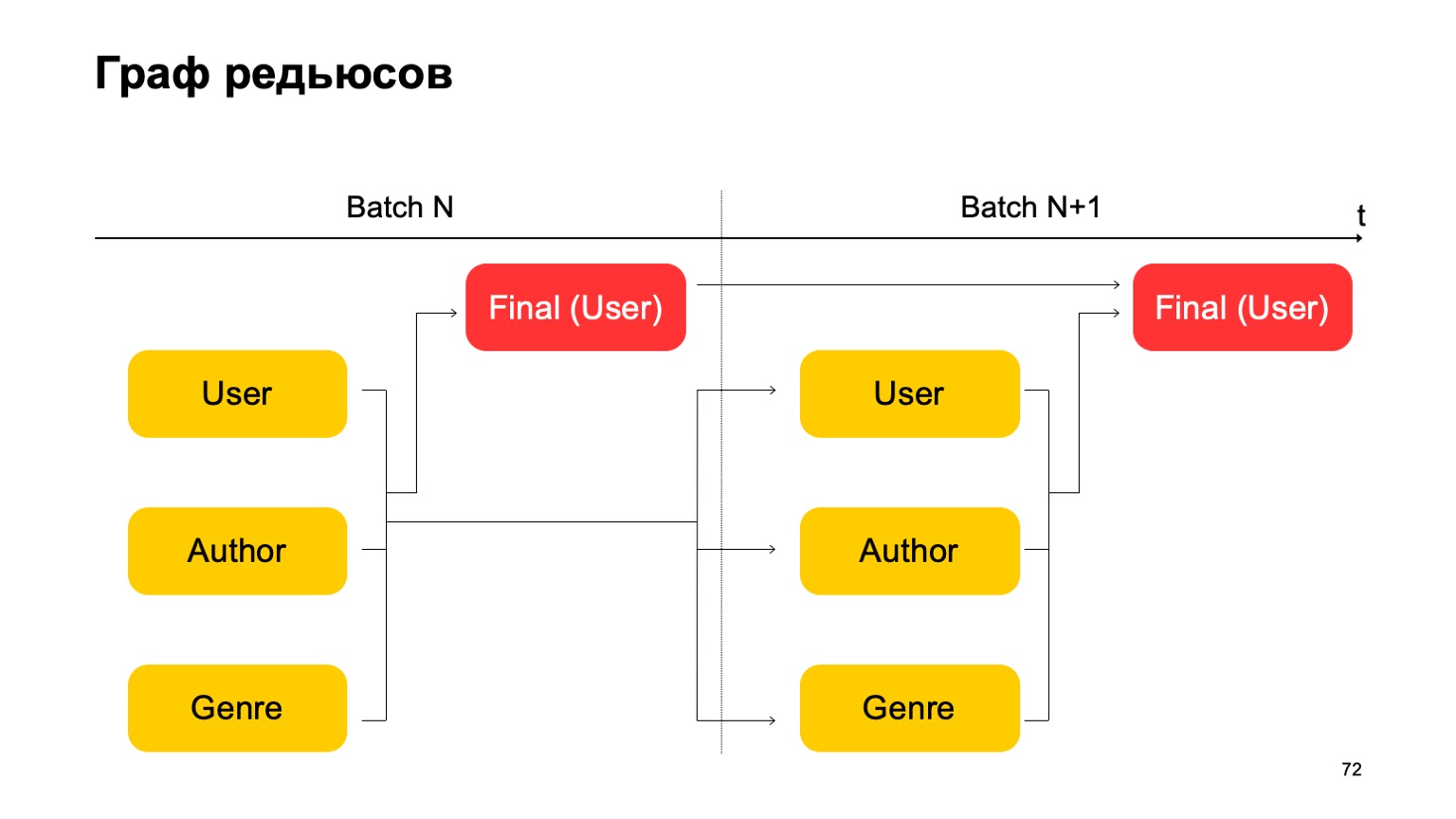
Das heißt, wir werden die Reduzierungen, die wir haben, in zwei Stufen aufteilen. In der ersten Phase werden wir verschiedene Reduzierungen parallel für verschiedene Abschnitte berechnen - unsere Benutzer, Autoren und das Genre. Und wir brauchen eine Art zweite Stufe, in der wir Merkmale aus diesen verschiedenen Reduzierungen sammeln und das endgültige Urteil akzeptieren.
Für die nächste Charge machen wir dasselbe. Darüber hinaus haben wir eine Abhängigkeit der ersten Stufe jeder Charge von der ersten Stufe der Vergangenheit und der zweiten Stufe von der zweiten Stufe der Vergangenheit.
Hier ist es wichtig, dass wir keine solche Abhängigkeit haben:
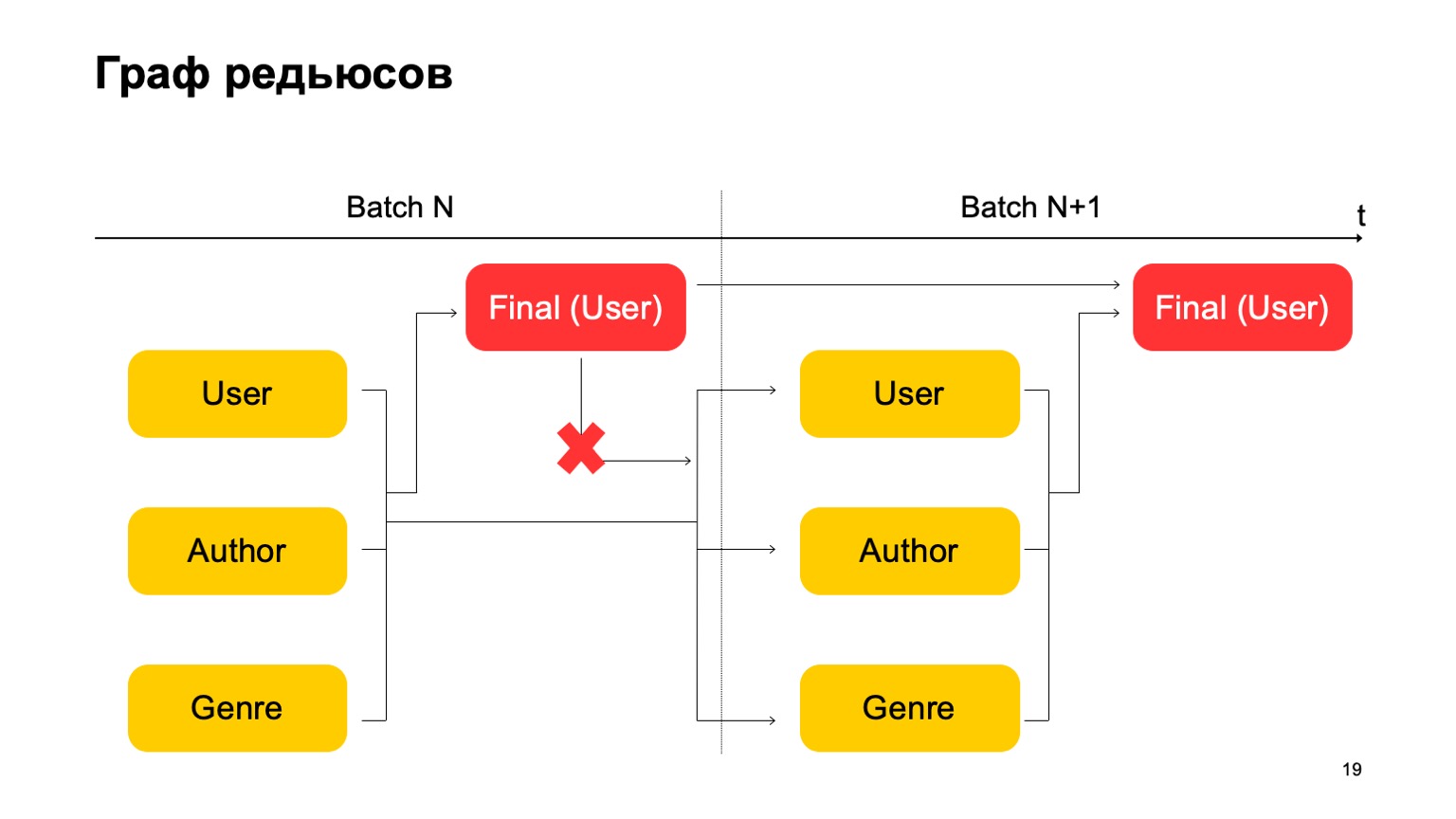
Das heißt, wir bekommen tatsächlich ein Förderband. Das heißt, die erste Stufe der nächsten Charge kann parallel zur zweiten Stufe der ersten Charge arbeiten.
Wie können wir die dreistufige Statistik, die ich oben angegeben habe, erstellen, wenn wir nur zwei Stufen haben? Sehr einfach. Wir können den ersten Wert in der ersten Stufe der Charge N lesen.
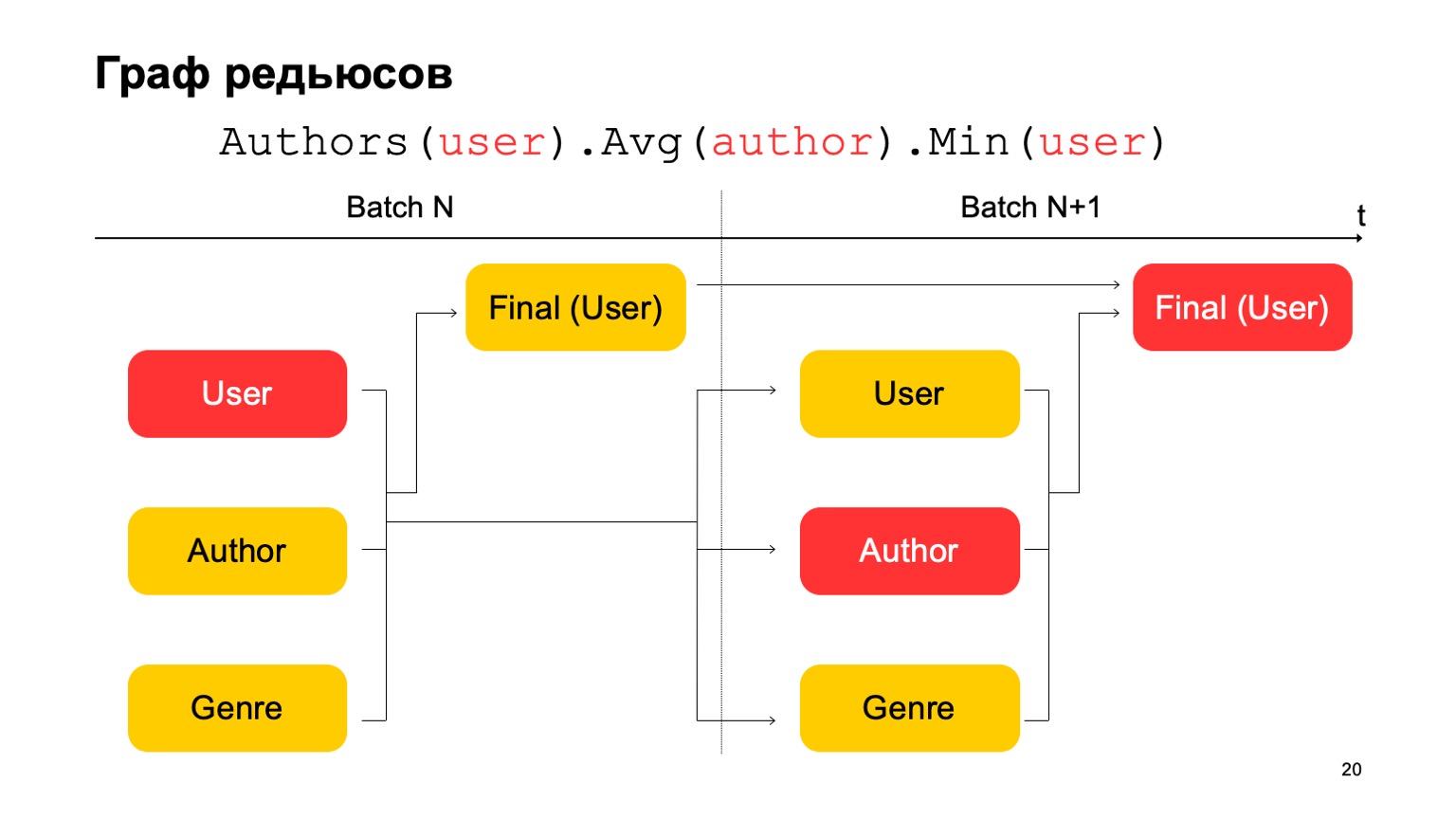
Der zweite Wert in der ersten Stufe der Charge ist N + 1, und der Endwert muss in der zweiten Stufe der Charge N + 1 gelesen werden. Während des Übergangs zwischen der ersten und der zweiten Stufe wird es daher möglicherweise keine ganz genauen Statistiken für die N + 1-Charge geben. In der Regel reicht dies jedoch für solche Berechnungen aus.

Mit all diesen Dingen können Sie komplexere Funktionen aus Cubes erstellen. Zum Beispiel die Abweichung der aktuellen Bewertung des Buches von der durchschnittlichen Bewertung des Benutzers. Oder der Anteil der Benutzer, die ein Buch sehr positiv oder sehr negativ bewerten. Auch verdächtig. Oder die durchschnittliche Buchbewertung von Benutzern, die mehr als N Bewertungen für verschiedene Bücher haben. Dies ist unter bestimmten Gesichtspunkten möglicherweise eine genauere und gerechtere Einschätzung.

Hinzu kommt die Beziehung zwischen Ereignissen. Oft erscheinen Duplikate in den Protokollen oder in den Daten, die an uns gesendet werden. Dies können entweder technische Ereignisse oder Roboterverhalten sein. Wir finden auch solche Duplikate. Oder zum Beispiel einige verwandte Ereignisse. Angenommen, Ihr System zeigt Buchempfehlungen an, und Benutzer klicken auf diese Empfehlungen. Damit die endgültigen Statistiken, die sich auf das Ranking auswirken, nicht beeinträchtigt werden, müssen wir sicherstellen, dass wir, wenn wir den Eindruck filtern, auch den Klick auf die aktuelle Empfehlung filtern müssen.
Da unser Fluss jedoch ungleichmäßig sein kann, müssen wir ihn zunächst mit einem Klick verschieben, bis wir die Show sehen und ein darauf basierendes Urteil akzeptieren.
Funktionsbeschreibungssprache
Ich werde Ihnen ein wenig über die Sprache erzählen, in der all dies beschrieben wird.

Sie müssen es nicht lesen, das ist zum Beispiel. Wir haben mit drei Hauptkomponenten begonnen. Die erste ist eine Beschreibung von Dateneinheiten in der Geschichte, im Allgemeinen eines beliebigen Typs.

Dies ist eine Art Feature, eine nullbare Zahl.

Und eine Art Regel. Wie nennen wir eine Regel? Dies ist eine Reihe von Bedingungen für diese Funktionen und etwas anderes. Wir hatten drei separate Dateien.
Das Problem ist, dass hier eine Aktionskette auf verschiedene Dateien verteilt ist. Eine große Anzahl von Analysten muss mit unserem System arbeiten. Sie fühlten sich unwohl.
Die Sprache erweist sich als zwingend: Wir beschreiben, wie die Daten berechnet werden, und nicht deklarativ, wenn wir beschreiben, was wir berechnen müssen. Dies ist auch nicht sehr praktisch, es ist leicht genug, einen Fehler und eine hohe Eintrittsschwelle zu machen. Neue Leute kommen, aber sie verstehen überhaupt nicht, wie sie damit arbeiten sollen.
Lösung - Lassen Sie uns unser eigenes DSL erstellen. Es beschreibt unser Szenario klarer, es ist einfacher für neue Leute, es ist höherrangig. Wir haben uns von SQLAlchemy, C # Linq und dergleichen inspirieren lassen.
Ich werde ein paar Beispiele geben, die denen ähnlich sind, die ich oben gegeben habe.

Prozentsatz der gelesenen Detektivgeschichten. Wir zählen die Anzahl der gelesenen Bücher, dh wir gruppieren nach Benutzern. Wir fügen dieser Bedingung eine Filterung hinzu, und wenn wir den endgültigen Prozentsatz berechnen möchten, berechnen wir nur die Bewertung. Alles ist einfach, klar und intuitiv.

Wenn wir die Anzahl der verschiedenen Autoren zählen, gruppieren wir nach Benutzer und legen unterschiedliche Autoren fest. Dazu können wir einige Bedingungen hinzufügen, z. B. ein Berechnungsfenster oder eine Begrenzung der Anzahl der Werte, die wir aufgrund von Speicherbeschränkungen speichern. Als Ergebnis zählen wir count, die Anzahl der Schlüssel darin.

Oder die durchschnittliche Loyalität, über die ich gesprochen habe. Das heißt, wir haben wieder eine Art Ausdruck, der von oben berechnet wird. Wir gruppieren nach Autor und setzen einen Durchschnittswert unter diesen Ausdrücken. Dann beschränken wir uns auf den Benutzer.

Dazu können wir dann eine Filterbedingung hinzufügen. Das heißt, unser Filter kann beispielsweise Folgendes sein: Die Loyalität ist nicht zu hoch und der Prozentsatz der Detectives liegt zwischen 80 von 100.
Was verwenden wir dafür unter der Haube?
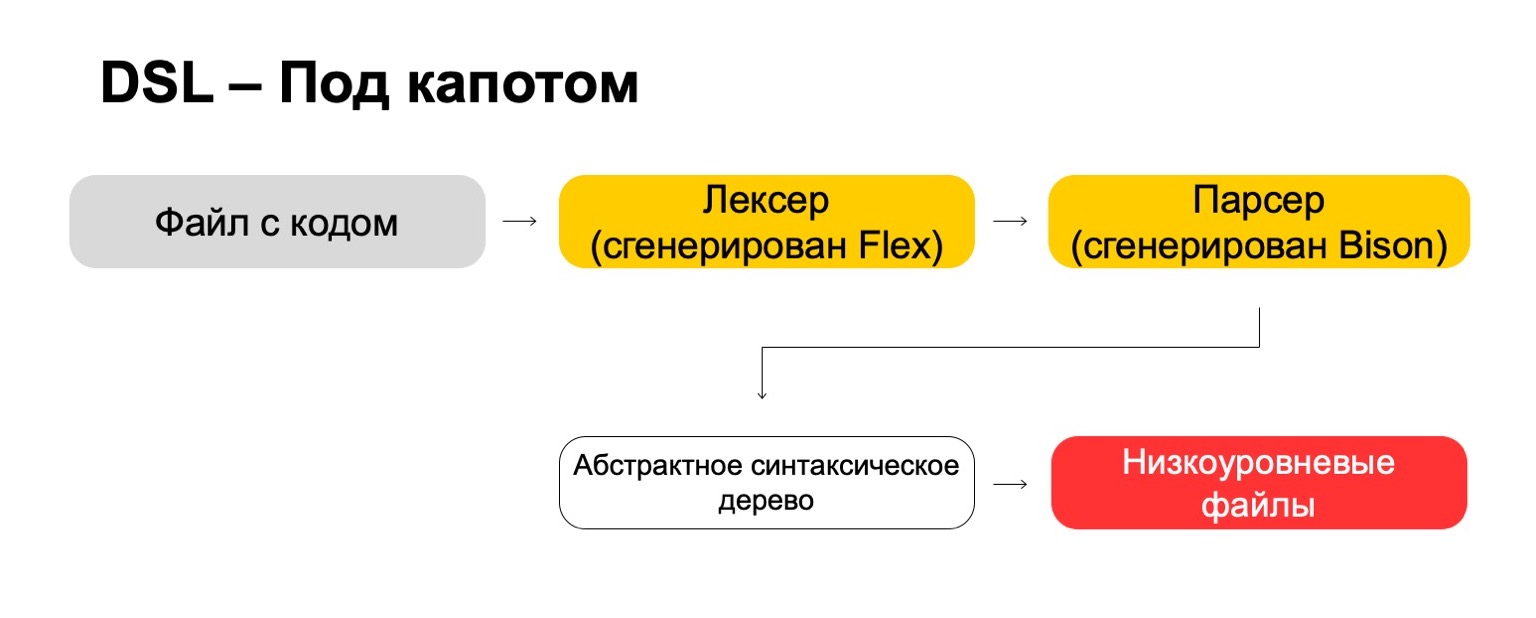
Unter der Haube verwenden wir die modernsten Technologien direkt aus den 70er Jahren wie Flex, Bison. Vielleicht hast du es gehört. Sie generieren Code. Unsere Codedatei durchläuft unseren Lexer, der in Flex generiert wird, und den Parser, der in Bison generiert wird. Der Lexer generiert Terminalsymbole oder Wörter in der Sprache, der Parser generiert Syntaxausdrücke.
Daraus erhalten wir einen abstrakten Syntaxbaum, mit dem wir bereits Transformationen durchführen können. Und am Ende verwandeln wir es in Dateien auf niedriger Ebene, die das System versteht.
Was ist das Ergebnis? Dies ist komplizierter, als es auf den ersten Blick erscheinen mag. Es erfordert eine Menge Ressourcen, um die kleinen Dinge wie Prioritäten für Operationen, Randfälle und dergleichen zu durchdenken. Sie müssen seltene Technologien erlernen, die für Sie im wirklichen Leben wahrscheinlich nicht nützlich sind, es sei denn, Sie schreiben natürlich Compiler. Aber am Ende lohnt es sich. Das heißt, wenn Sie wie wir eine große Anzahl von Analysten haben, die häufig aus anderen Teams stammen, bietet dies letztendlich einen erheblichen Vorteil, da sie leichter arbeiten können.
Verlässlichkeit
Einige Dienste erfordern Fehlertoleranz: Cross-DC und genau einmalige Verarbeitung. Ein Verstoß kann zu Diskrepanzen in Statistiken und Verlusten führen, einschließlich monetärer Verluste. Unsere Lösung für MapReduce besteht darin, dass wir die Daten jeweils nur in einem Cluster lesen und im zweiten synchronisieren.
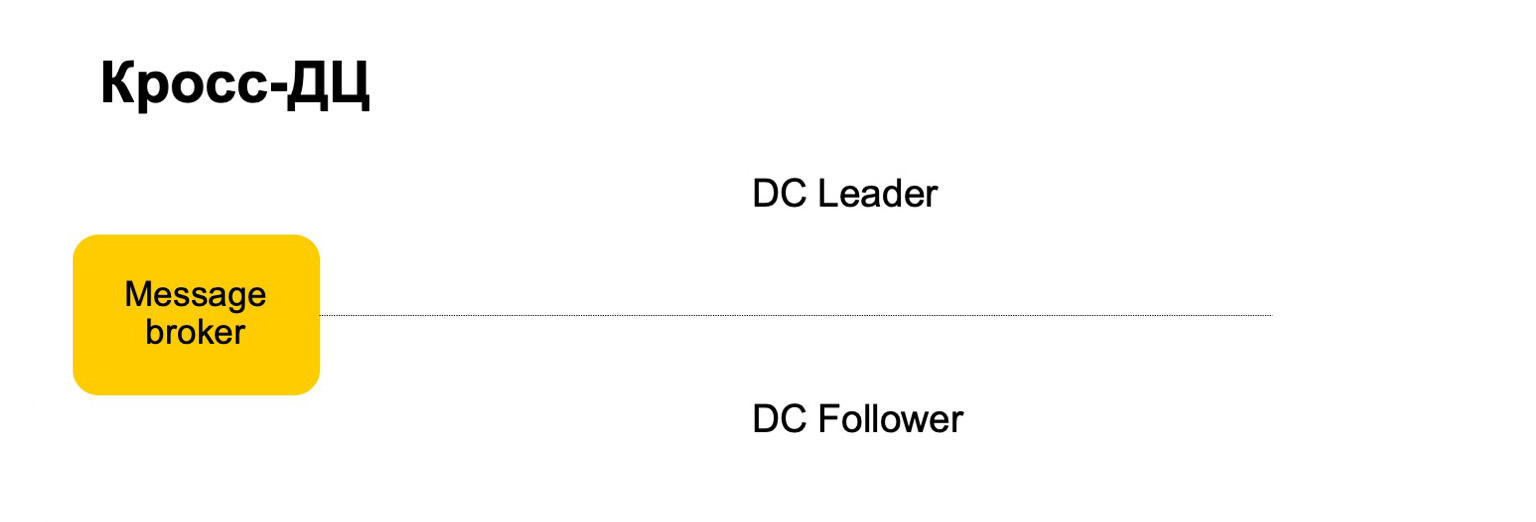
Wie würden wir uns zum Beispiel hier verhalten? Es gibt einen Leader, Follower und Message Broker. Es kann davon ausgegangen werden, dass dies eine bedingte Kafka ist, obwohl hier natürlich eine eigene Implementierung.
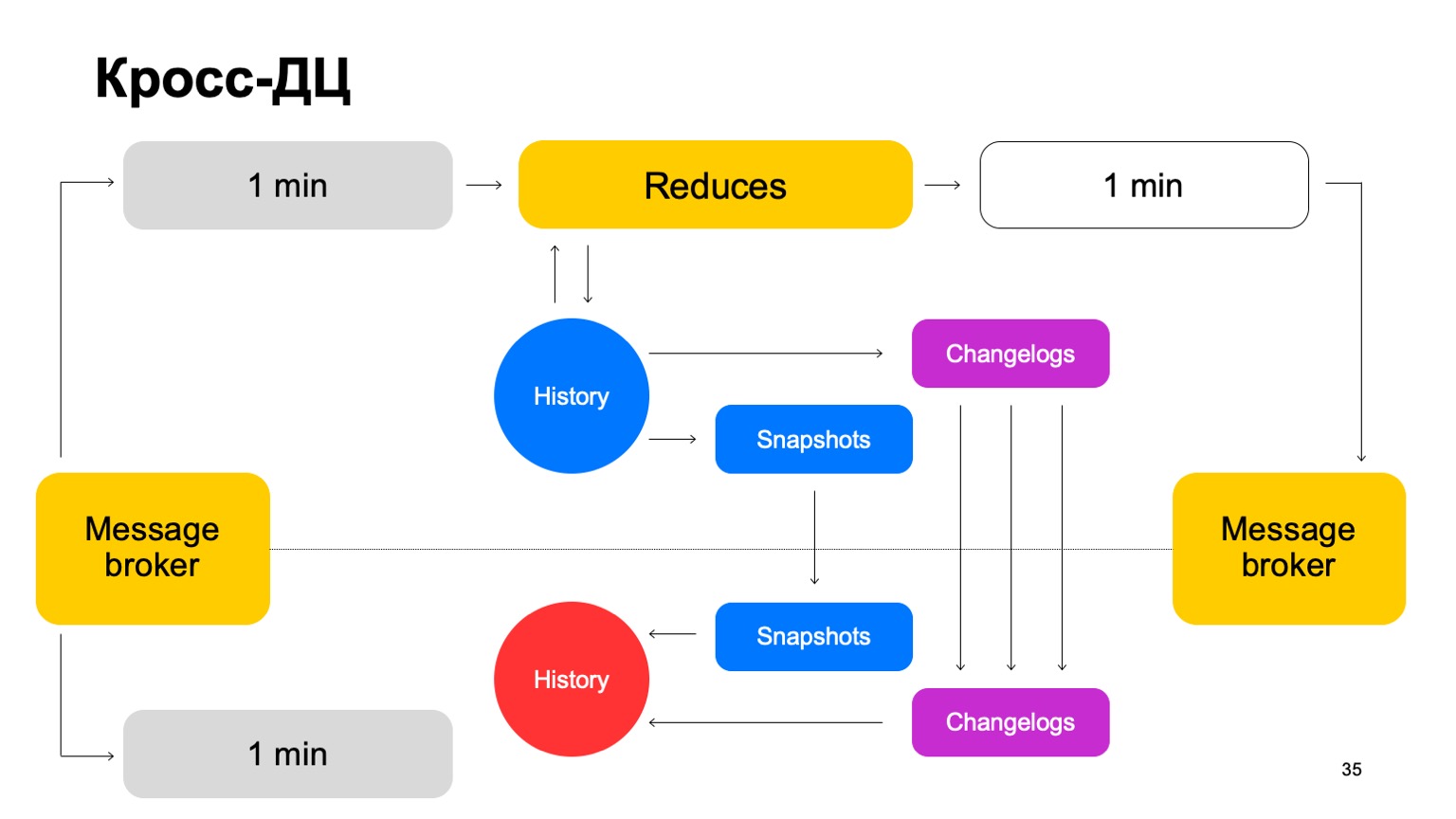
Wir liefern unsere Chargen an beide Cluster, führen eine Reihe von Reduzierungen für denselben Marktführer durch, akzeptieren die endgültigen Urteile, aktualisieren den Verlauf und senden die Ergebnisse an den Dienst an den Nachrichtenbroker zurück.
Hin und wieder müssen wir natürlich replizieren. Das heißt, wir sammeln Schnappschüsse, sammeln Änderungen - Änderungen für jeden Stapel. Wir synchronisieren beide mit dem zweiten Cluster-Follower. Und auch eine Geschichte aufgreifen, die so heiß ist. Ich möchte Sie daran erinnern, dass hier die Geschichte in Erinnerung bleibt.
Wenn also ein DC aus irgendeinem Grund nicht mehr verfügbar ist, können wir schnell genug mit minimaler Verzögerung zum zweiten Cluster wechseln.
Warum nicht überhaupt auf zwei Cluster gleichzeitig zählen? Externe Daten können sich in zwei Clustern unterscheiden und von externen Diensten bereitgestellt werden. Was sind externe Daten überhaupt? Dies ist etwas, das von dieser höheren Ebene aufsteigt. Das heißt, komplexes Clustering und dergleichen. Oder nur Datenhilfsmittel für Berechnungen.
Wir brauchen eine vereinbarte Lösung. Wenn wir Urteile mit unterschiedlichen Daten parallel zählen und regelmäßig zwischen Ergebnissen aus zwei verschiedenen Clustern wechseln, sinkt die Konsistenz zwischen ihnen dramatisch. Und natürlich Ressourcen sparen. Da wir CPU-Ressourcen jeweils nur in einem Cluster verwenden.
Was ist mit dem zweiten Cluster? Wenn wir arbeiten, ist er praktisch untätig. Lassen Sie uns seine Ressourcen für eine vollwertige Vorproduktion nutzen. Mit vollwertiger Vorproduktion meine ich eine vollwertige Installation, die denselben Datenstrom akzeptiert, mit denselben Datenmengen arbeitet usw.

Wenn der Cluster nicht verfügbar ist, ändern wir diese Installationen vom Verkauf in die Vorproduktion. Wir haben also seit einiger Zeit ein Preprod, aber es ist okay.
Der Vorteil ist, dass wir mehr Funktionen für den Vorprozess zählen können. Warum ist das überhaupt notwendig? Da es klar ist, dass wir, wenn wir eine große Anzahl von Funktionen zählen möchten, häufig nicht alle im Verkauf befindlichen Funktionen zählen müssen. Dort zählen wir nur, was nötig ist, um endgültige Urteile zu erhalten.
(00:25:12)
Gleichzeitig haben wir im Vorprozess eine Art heißen Cache, groß, mit einer Vielzahl von Funktionen. Im Falle eines Angriffs können wir damit das Problem schließen und diese Funktionen in die Produktion übertragen.
Hinzu kommen die Vorteile von B2B-Tests. Das heißt, wir alle rollen natürlich zuerst für den Vorverkauf aus. Wir vergleichen alle Unterschiede vollständig und werden uns daher nicht irren. Wir minimieren die Wahrscheinlichkeit, dass wir bei der Einführung zum Verkauf einen Fehler machen können.
Ein wenig über den Scheduler. Es ist klar, dass wir eine Art von Maschinen haben, die die Aufgabe in MapReduce ausführen. Dies sind eine Art Arbeiter. Sie synchronisieren ihre Daten regelmäßig mit der Cross-DC-Datenbank. Dies ist nur der Zustand dessen, was sie im Moment berechnet haben.
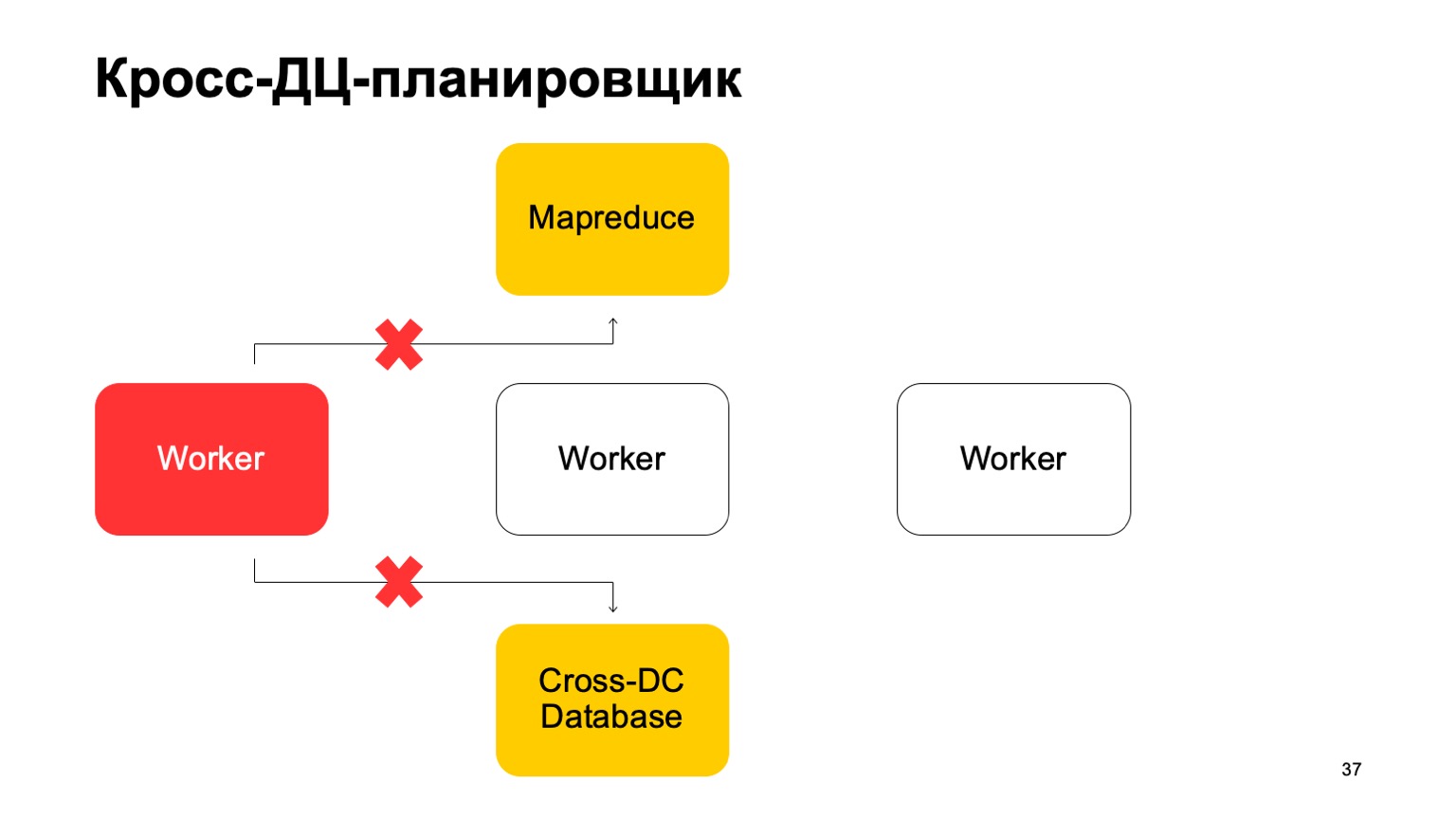
Wenn ein Mitarbeiter nicht mehr verfügbar ist, versucht ein anderer Mitarbeiter, das Protokoll zu erfassen und den Status zu übernehmen.
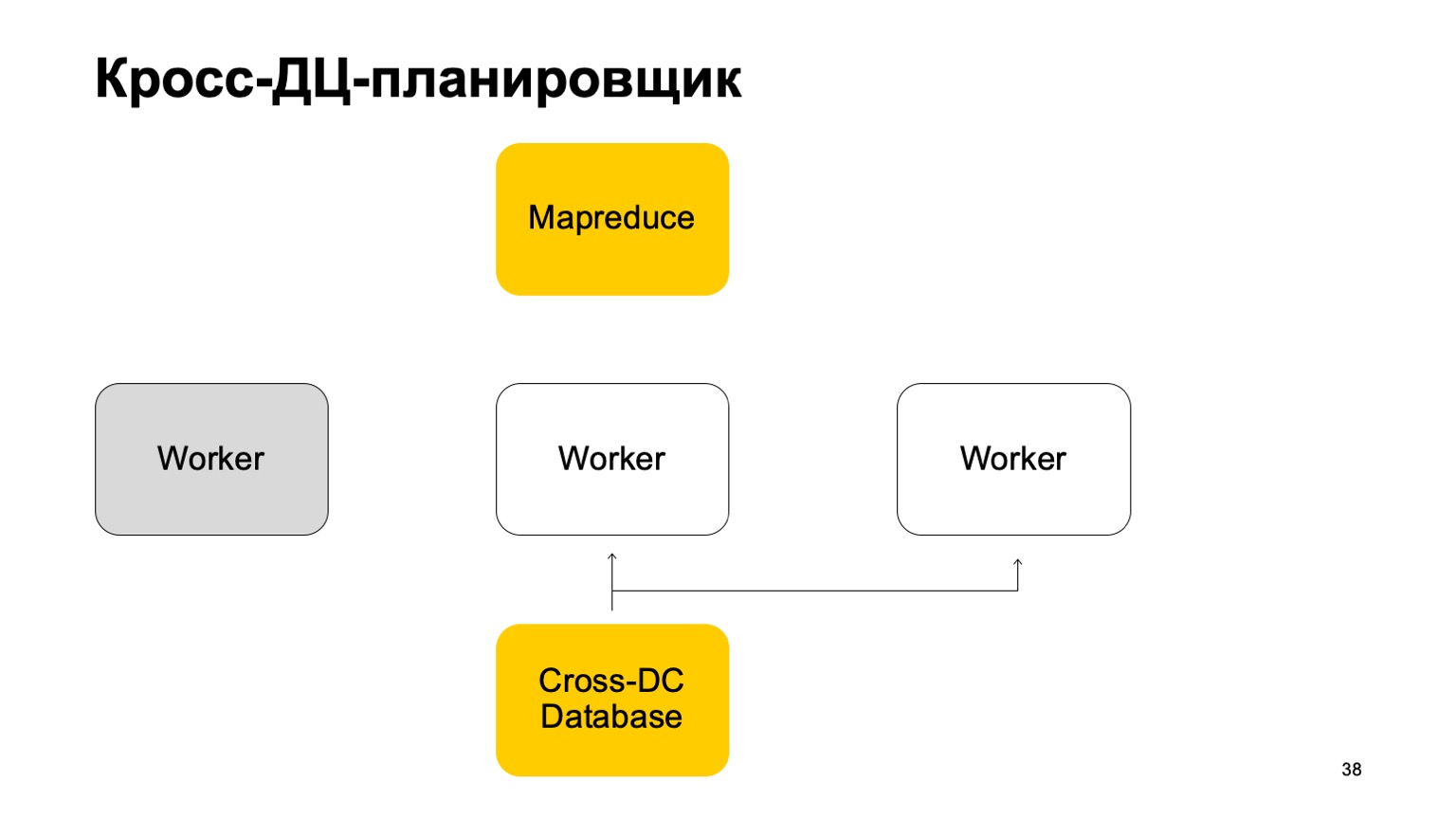
Steh auf und arbeite weiter. Setzen Sie das Festlegen von Aufgaben in diesem MapReduce fort.
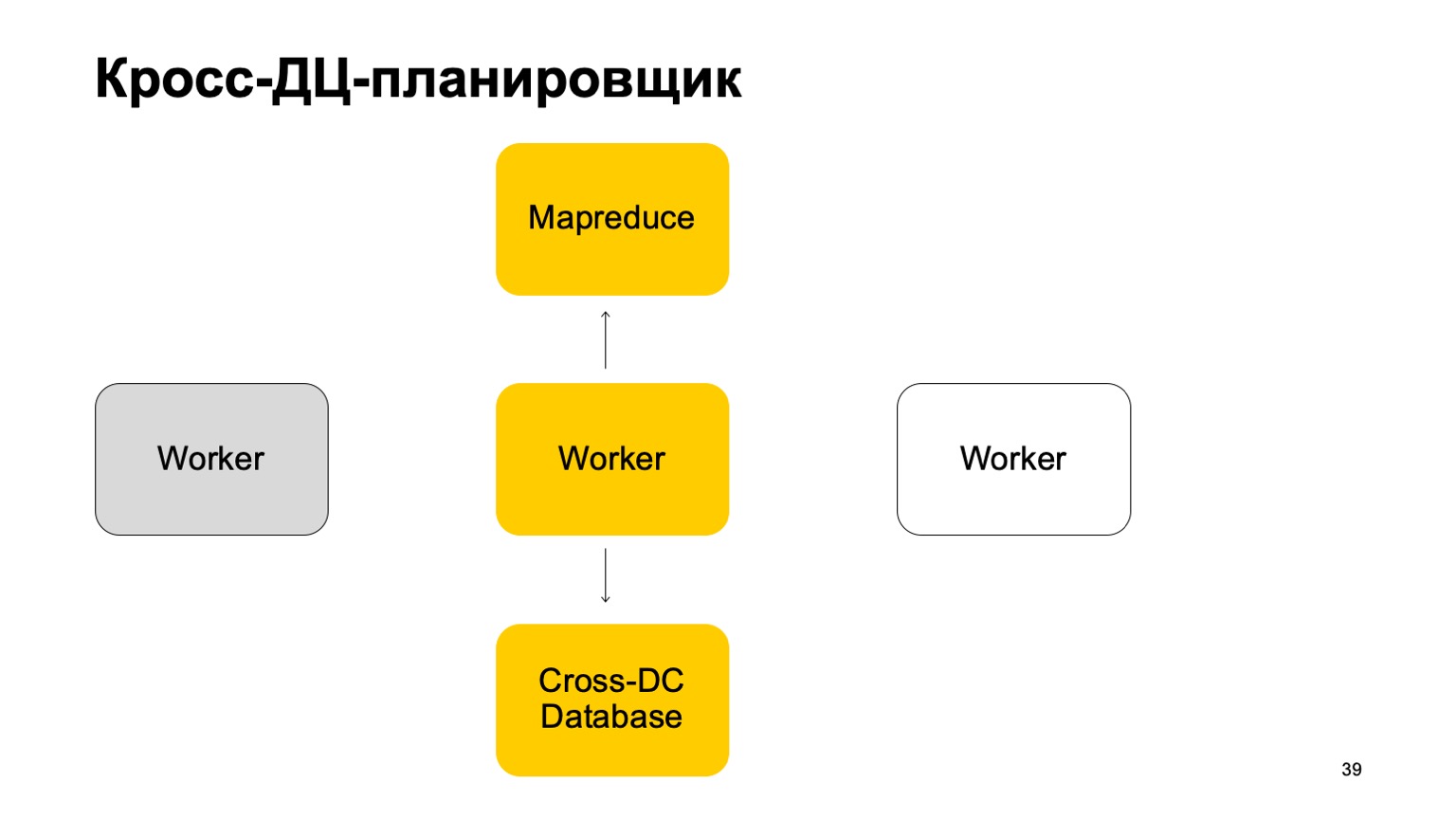
Es ist klar, dass im Falle des Überschreibens dieser Aufgaben einige von ihnen neu gestartet werden können. Daher gibt es hier eine sehr wichtige Eigenschaft für uns: Idempotenz, die Fähigkeit, jede Operation ohne Konsequenzen neu zu starten.
Das heißt, der gesamte Code muss so geschrieben sein, dass dies einwandfrei funktioniert.

Ich werde Ihnen genau einmal ein wenig darüber erzählen. Wir kommen gemeinsam zu einem Urteil, das ist sehr wichtig. Wir verwenden Technologien, die uns solche Garantien geben, und natürlich überwachen wir alle Unstimmigkeiten und reduzieren sie auf Null. Auch wenn es den Anschein hat, dass dies bereits reduziert wurde, tritt von Zeit zu Zeit ein sehr heikles Problem auf, das wir nicht berücksichtigt haben.
Instrumente
Sehr kurz über die Werkzeuge, die wir verwenden. Die Aufrechterhaltung mehrerer Betrugsbekämpfungsmittel für verschiedene Systeme ist eine schwierige Aufgabe. Wir haben buchstäblich Dutzende verschiedener Dienste, wir brauchen einen einzigen Ort, an dem Sie den Stand ihrer Arbeit im Moment sehen können.
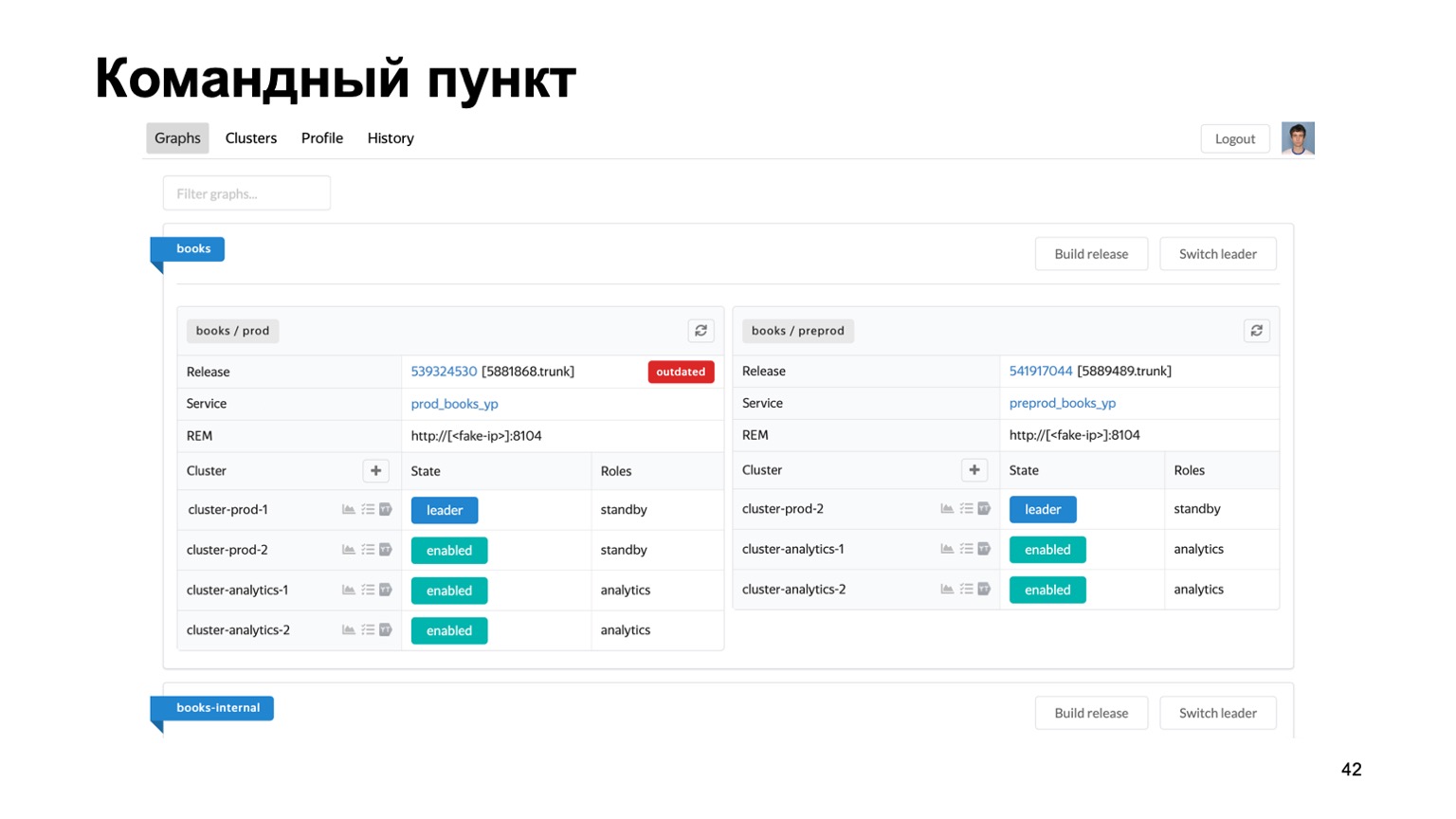
Hier ist unser Kommandoposten, in dem Sie den Status der Cluster sehen können, mit denen wir gerade arbeiten. Sie können sie untereinander austauschen, eine Version
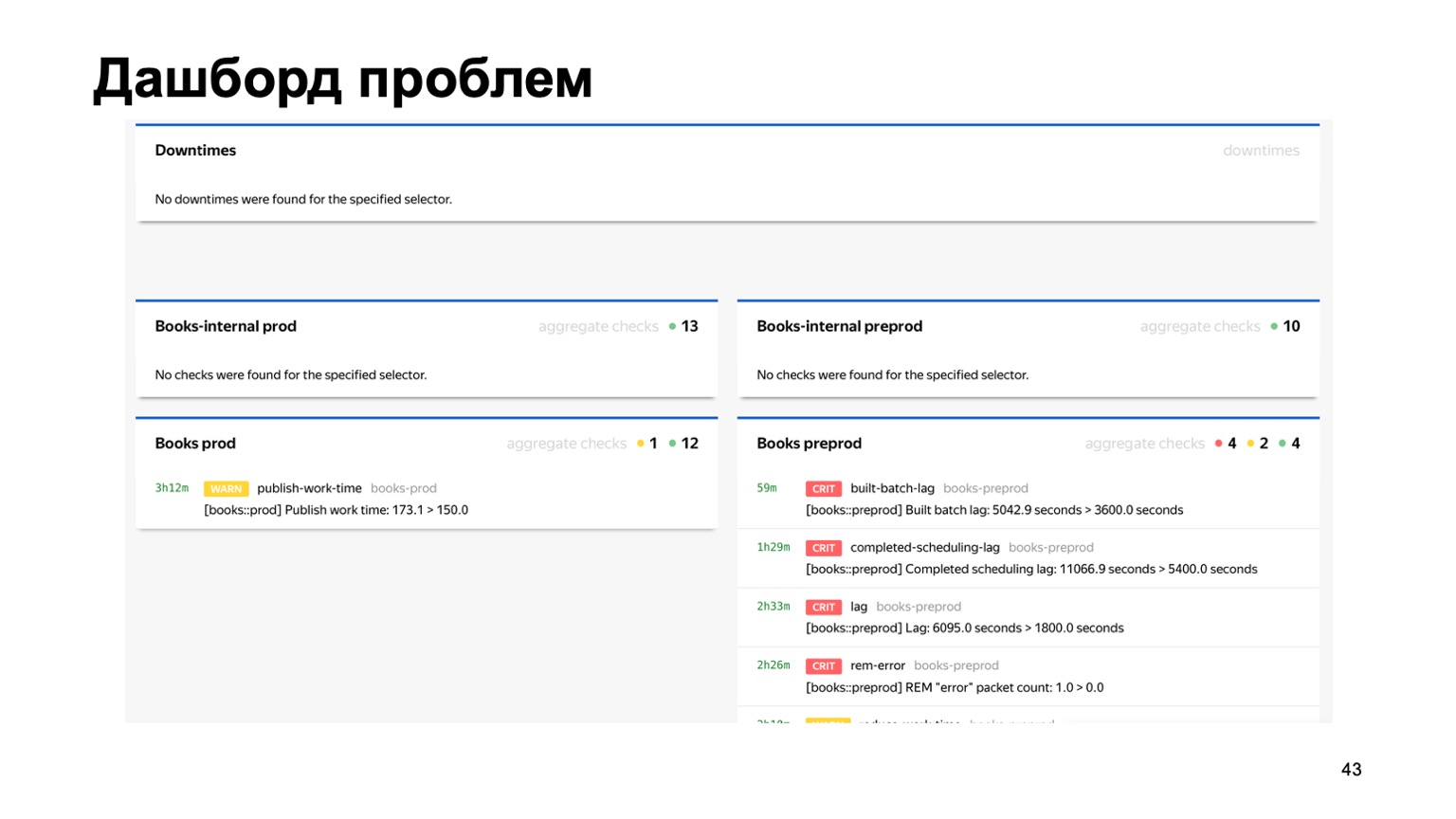
bereitstellen usw. Oder beispielsweise ein Dashboard mit Problemen, in dem auf einer Seite sofort alle Probleme aller Betrugsbekämpfung verschiedener Dienste angezeigt werden, die mit uns verbunden sind. Hier können Sie sehen, dass im Moment mit unserem Buchservice eindeutig etwas nicht stimmt. Aber die Überwachung wird funktionieren, und die diensthabende Person wird sie prüfen.
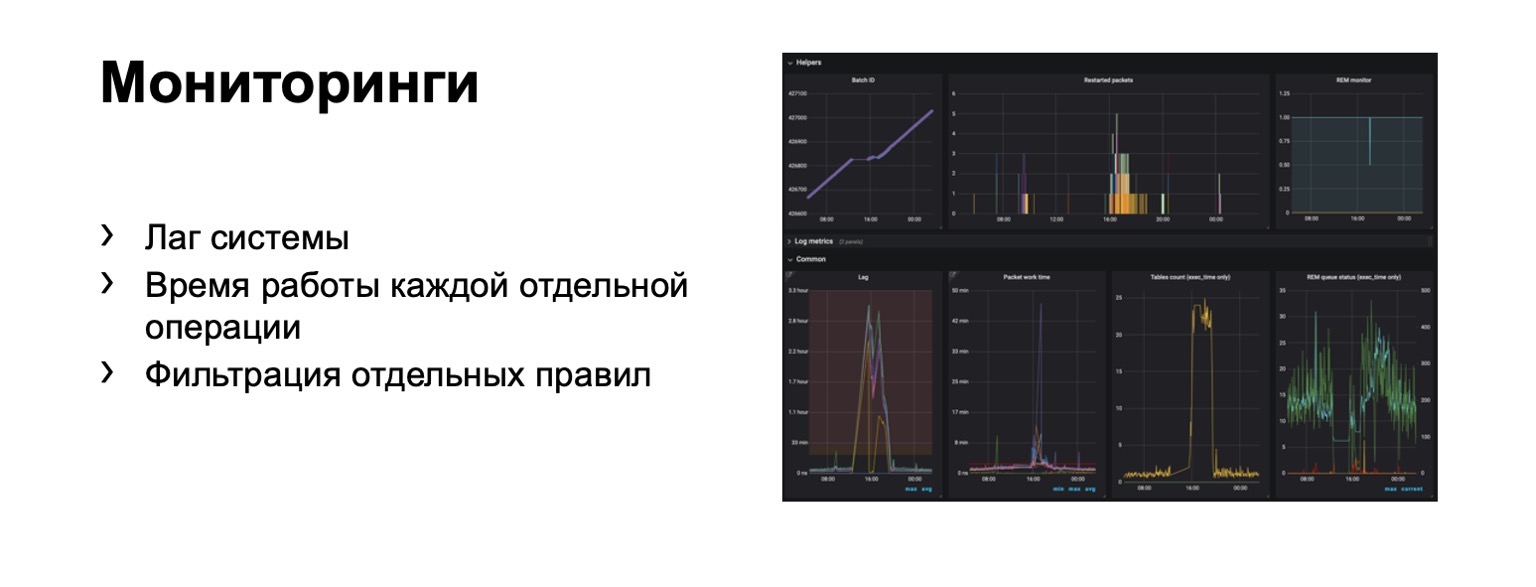
Was überwachen wir überhaupt? Offensichtlich ist die Systemverzögerung äußerst wichtig. Natürlich die Laufzeit jeder einzelnen Stufe und natürlich das Filtern einzelner Regeln. Dies ist eine Geschäftsanforderung.
Hunderte von Grafiken und Dashboards werden angezeigt. In diesem Dashboard können Sie beispielsweise sehen, dass die Kontur jetzt schlecht genug war, da wir eine erhebliche Verzögerung hatten.
Geschwindigkeit
Ich erzähle Ihnen vom Übergang zum Online-Teil. Das Problem hierbei ist, dass die Verzögerung in einem vollen Kreislauf einige Minuten erreichen kann. Es ist in der Gliederung auf MapReduce. In einigen Fällen müssen wir Betrüger verbieten und schneller aufdecken.
Was könnte es sein? Zum Beispiel kann unser Service jetzt Bücher kaufen. Gleichzeitig ist eine neue Art von Zahlungsbetrug aufgetreten. Sie müssen schneller darauf reagieren. Es stellt sich die Frage, wie dieses gesamte Schema übertragen werden kann, wobei die den Analysten vertraute Interaktionssprache im Idealfall so weit wie möglich erhalten bleibt. Versuchen wir es "auf die Stirn" zu übertragen.
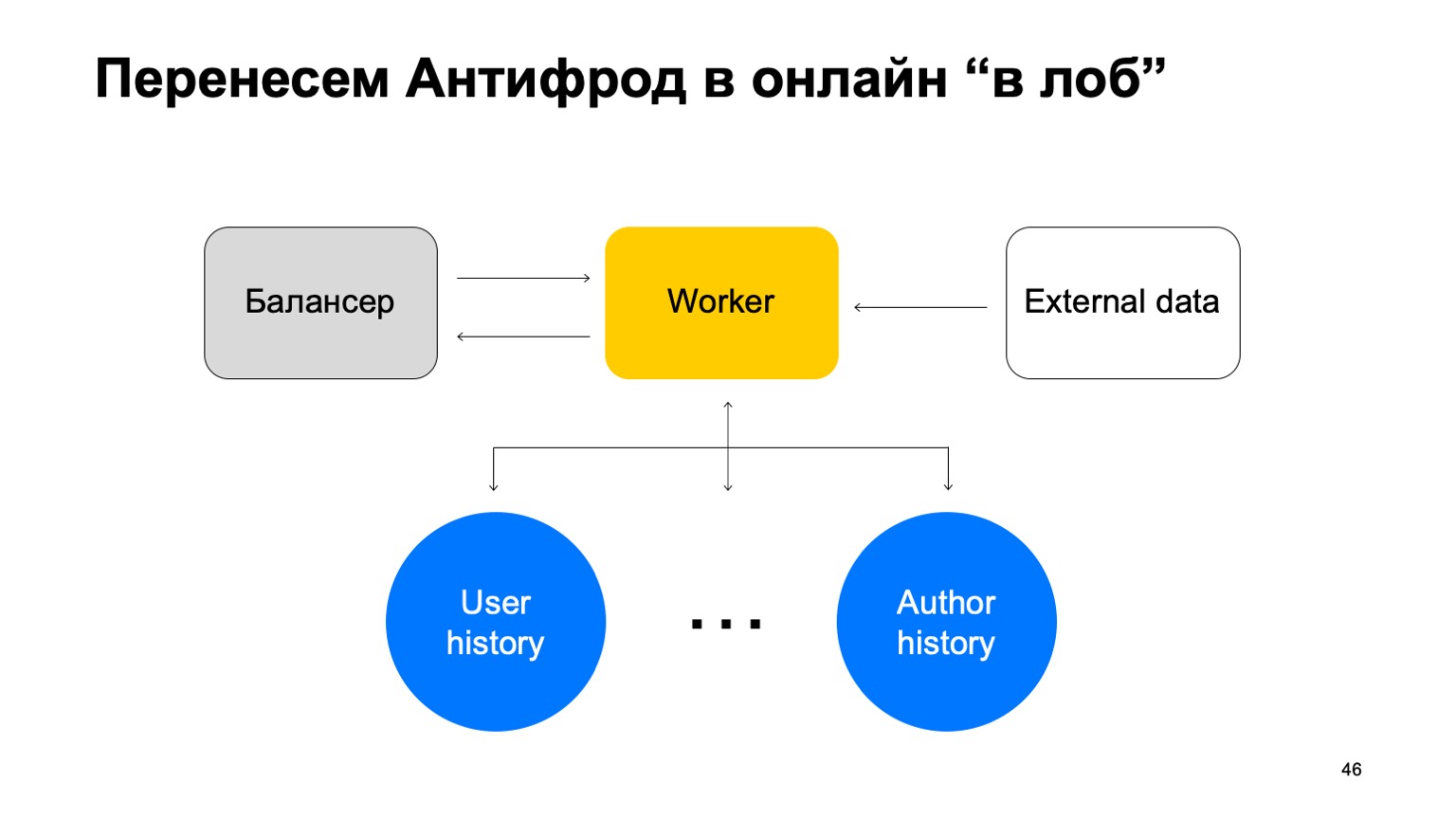
Angenommen, wir haben einen Balancer mit Daten aus dem Dienst und eine bestimmte Anzahl von Mitarbeitern, an die wir Daten aus dem Balancer weiterleiten. Es gibt externe Daten, die wir hier verwenden, sie sind sehr wichtig und eine Reihe dieser Geschichten. Ich möchte Sie daran erinnern, dass jede solche Geschichte für unterschiedliche Reduzierungen unterschiedlich ist, weil sie unterschiedliche Schlüssel hat.
In einem solchen Schema kann das folgende Problem auftreten.
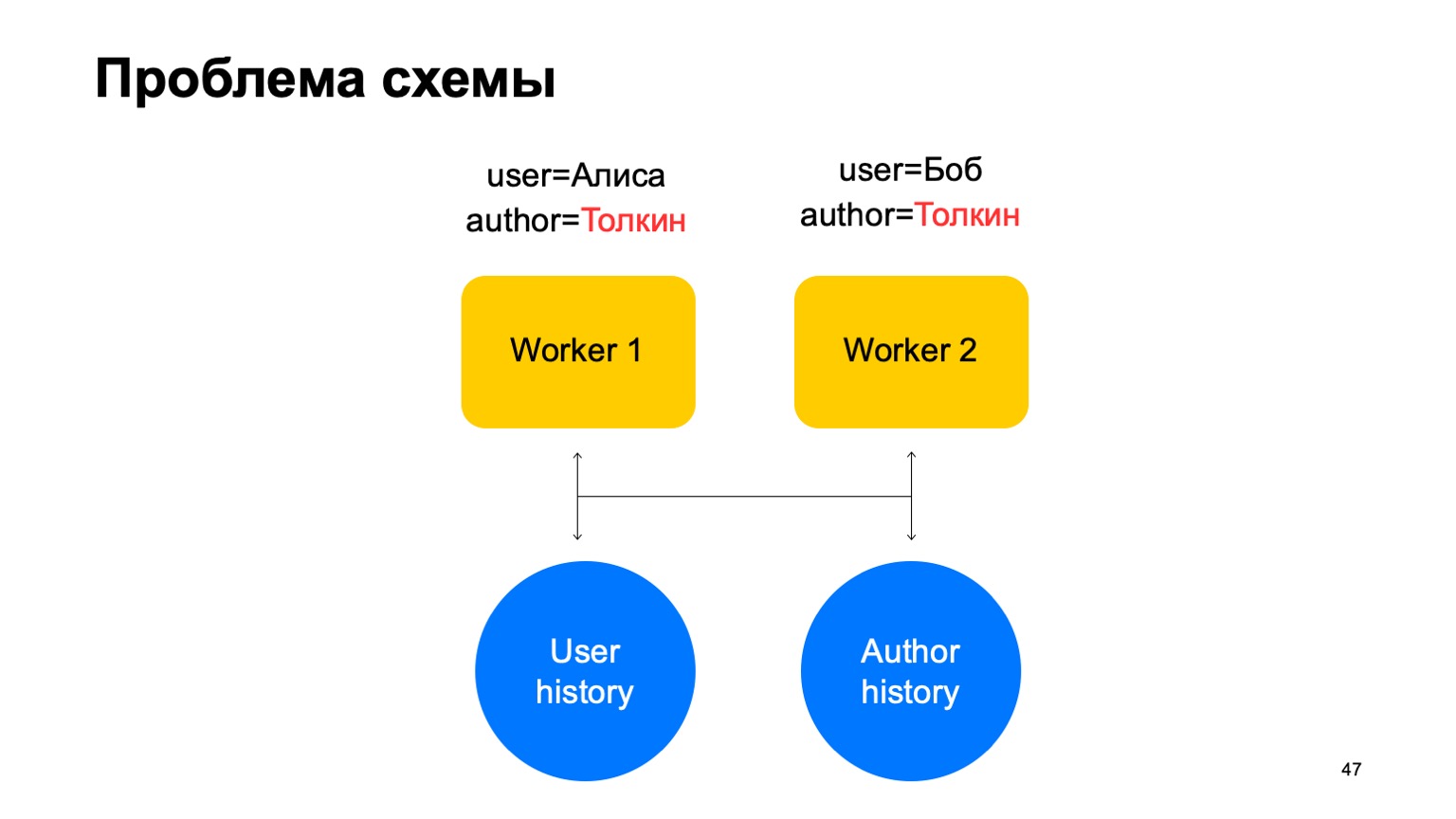
Nehmen wir an, wir haben zwei Ereignisse mit unserem Arbeiter. In diesem Fall kann es bei jeder Scherbe dieser Arbeiter zu einer Situation kommen, in der ein Schlüssel zu verschiedenen Arbeitern gelangt. In diesem Fall ist dies der Autor Tolkien, der in zwei Arbeiter geraten ist.
Dann lesen wir beiden Mitarbeitern aus der Geschichte Daten aus diesem Schlüsselwertspeicher vor, aktualisieren sie auf unterschiedliche Weise und es kommt zu einem Wettlauf, wenn wir versuchen, zurückzuschreiben.
Lösung: Nehmen wir an, dass Lesen und Schreiben getrennt werden können und dass das Schreiben mit einer leichten Verzögerung erfolgen kann. Dies ist normalerweise nicht sehr wichtig. Mit einer kleinen Verzögerung meine ich hier Einheiten von Sekunden. Dies ist insbesondere deshalb wichtig, weil unsere Implementierung dieses Schlüsselwertspeichers länger dauert, um Daten zu schreiben als zu lesen.
Wir werden die Statistiken mit einer Verzögerung aktualisieren. Im Durchschnitt funktioniert dies mehr oder weniger gut, da wir den zwischengespeicherten Status auf den Maschinen beibehalten.
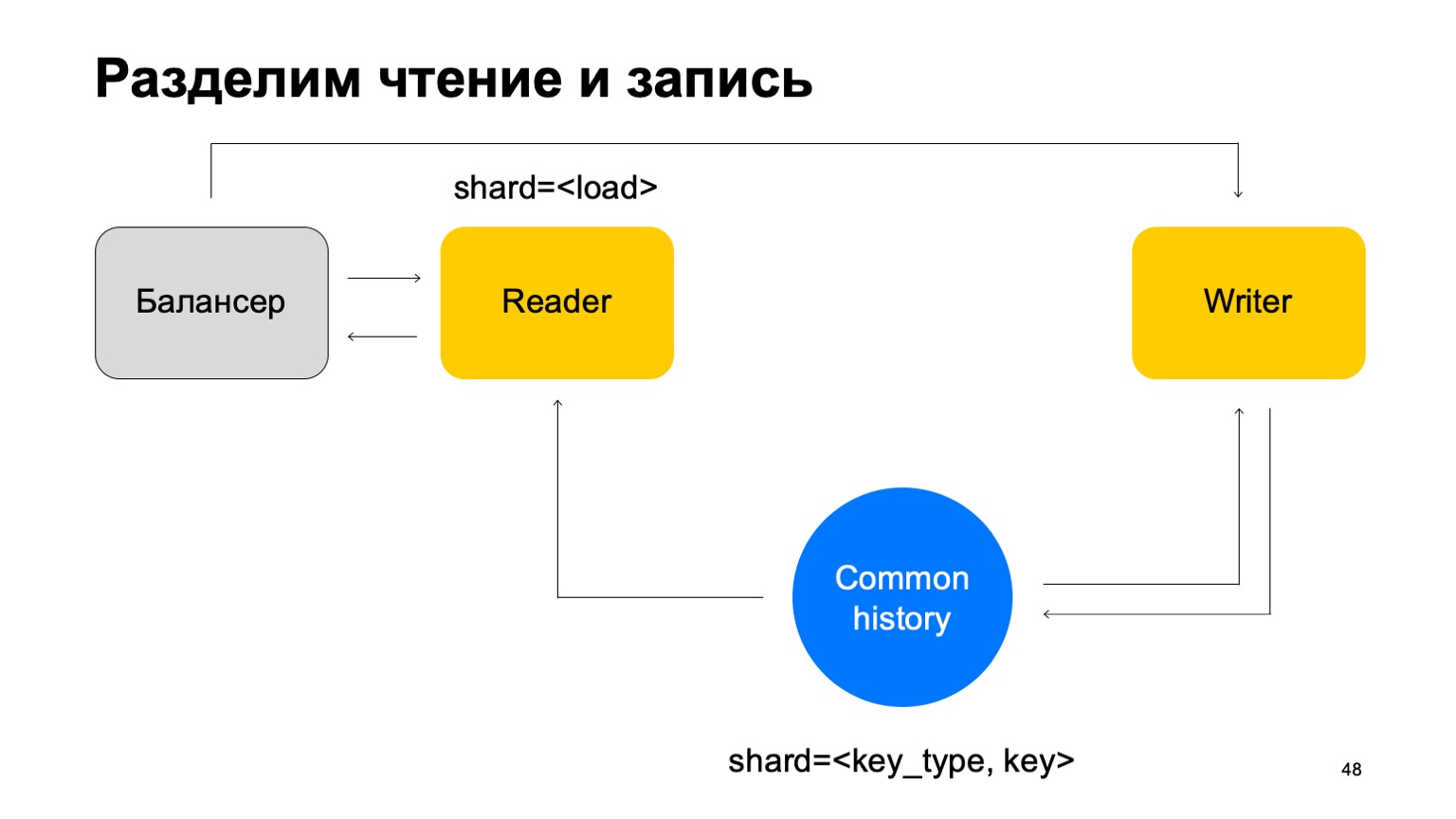
Und außerdem. Lassen Sie uns der Einfachheit halber diese Geschichten zu einer zusammenführen und sie nach Art und Tonart des Schnitts notieren. Wir haben eine gemeinsame Geschichte.
Dann fügen wir den Balancer erneut hinzu und fügen die Lesegeräte hinzu, die auf beliebige Weise gespalten werden können - zum Beispiel einfach durch Laden. Sie lesen diese Daten einfach, akzeptieren die endgültigen Urteile und senden sie an den Balancer zurück.
In diesem Fall benötigen wir eine Reihe von Schreibmaschinen, an die diese Daten direkt gesendet werden. Die Autoren werden die Geschichte entsprechend aktualisieren. Aber hier tritt immer noch das Problem auf, über das ich oben geschrieben habe. Lassen Sie uns dann die Struktur des Schriftstellers ein wenig ändern.
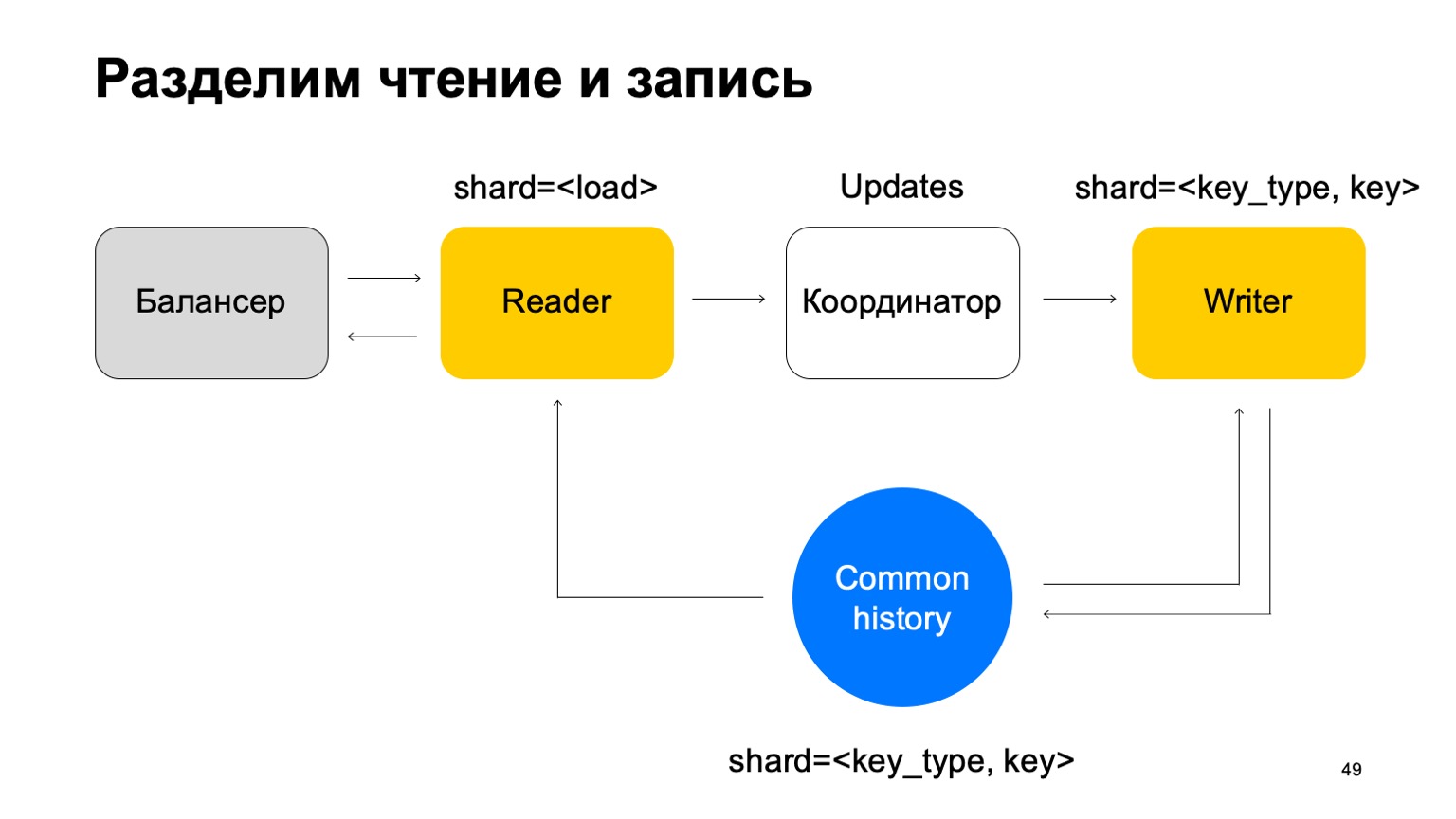
Wir werden es so gestalten, dass es auf die gleiche Weise wie die Historie gespalten wird - nach Art und Wert des Schlüssels. In diesem Fall haben wir nicht das oben erwähnte Problem, wenn das Sharding mit dem Verlauf identisch ist.
Hier ändert sich seine Mission. Er akzeptiert keine Urteile mehr. Stattdessen werden nur Aktualisierungen vom Reader akzeptiert, gemischt und korrekt auf den Verlauf angewendet.
Es ist klar, dass hier eine Komponente benötigt wird, ein Koordinator, der diese Aktualisierungen zwischen Lesern und Schreibern verteilt.
Hinzu kommt natürlich die Tatsache, dass der Worker einen aktuellen Cache verwalten muss. Infolgedessen stellt sich heraus, dass wir für Hunderte von Millisekunden verantwortlich sind, manchmal weniger, und wir aktualisieren die Statistiken in einer Sekunde. Im Allgemeinen funktioniert es gut, für Dienstleistungen ist es genug.

Was haben wir überhaupt bekommen? Analysten begannen, ihre Arbeit für alle Services schneller und auf die gleiche Weise zu erledigen. Dies hat die Qualität und Konnektivität aller Systeme verbessert. Sie können Daten zwischen Betrugsbekämpfung verschiedener Dienste wiederverwenden, und neue Dienste erhalten schnell eine qualitativ hochwertige Betrugsbekämpfung.

Ein paar Gedanken am Ende. Wenn Sie so etwas schreiben, denken Sie sofort an die Bequemlichkeit der Analysten hinsichtlich der Unterstützung und Erweiterbarkeit dieser Systeme. Machen Sie alles konfigurierbar, Sie brauchen es. Manchmal sind die Cross-DC- und genau einmaligen Eigenschaften schwer zu erreichen, aber sie können. Wenn Sie glauben, dass Sie es bereits erreicht haben, überprüfen Sie es noch einmal. Vielen Dank für Ihre Aufmerksamkeit.