Wir machen Sie auf eine Übersetzung einer interessanten Studie der Firma Crowdstrike aufmerksam. Das Material widmet sich der Verwendung der Rust-Sprache im Bereich Data Science (in Bezug auf Malware-Analyse) und zeigt, wie Rust in einem solchen Bereich auch mit NumPy und SciPy konkurrieren kann, ganz zu schweigen von reinem Python .

Viel Spaß beim Lesen!
Python ist aus gutem Grund eine der beliebtesten datenwissenschaftlichen Programmiersprachen. Der Python Package Index (PyPI) enthält eine Vielzahl beeindruckender datenwissenschaftlicher Bibliotheken wie NumPy, SciPy, Natural Language Toolkit, Pandas und Matplotlib. Mit einer Fülle hochwertiger Analysebibliotheken und einer umfangreichen Entwicklergemeinschaft ist Python für viele Datenwissenschaftler die offensichtliche Wahl.
Viele dieser Bibliotheken sind aus Leistungsgründen in C und C ++ implementiert, bieten jedoch externe Funktionsschnittstellen (FFIs) oder Python-Bindungen, damit Funktionen von Python aus aufgerufen werden können. Diese untergeordneten Sprachimplementierungen sollen einige der sichtbarsten Mängel von Python mindern, insbesondere in Bezug auf Ausführungszeit und Speicherverbrauch. Wenn Sie die Ausführungszeit und den Speicherverbrauch begrenzen können, wird die Skalierbarkeit erheblich vereinfacht, was für die Kostensenkung von entscheidender Bedeutung ist. Wenn wir Hochleistungscode schreiben können, der datenwissenschaftliche Probleme löst, ist die Integration dieses Codes in Python ein wesentlicher Vorteil.
Bei der Arbeit an der Schnittstelle von Data Science und Malware-AnalyseEs ist nicht nur eine schnelle Ausführung erforderlich, sondern auch eine effiziente Nutzung gemeinsam genutzter Ressourcen für die Skalierung. Die Skalierung ist eines der Hauptprobleme bei Big Data, z. B. die effiziente Verarbeitung von Millionen ausführbarer Dateien auf mehreren Plattformen. Um auf modernen Prozessoren eine gute Leistung zu erzielen, ist Parallelität erforderlich, die normalerweise mithilfe von Multithreading implementiert wird. Es ist jedoch auch notwendig, die Effizienz der Codeausführung und den Speicherverbrauch zu verbessern. Bei der Lösung solcher Probleme kann es schwierig sein, die Ressourcen des lokalen Systems auszugleichen, und es ist noch schwieriger, Multithread-Systeme korrekt zu implementieren. Das Wesentliche von C und C ++ ist, dass keine Thread-Sicherheit bereitgestellt wird. Ja, es gibt externe plattformspezifische Bibliotheken, aber die Gewährleistung der Thread-Sicherheit ist offensichtlich Aufgabe des Entwicklers.
Das Parsen von Malware ist von Natur aus gefährlich. Schädliche Software manipuliert häufig Datenstrukturen im Dateiformat auf unbeabsichtigte Weise und lähmt so die Analysedienstprogramme. Eine relativ häufige Gefahr, die uns in Python erwartet, ist der Mangel an guter Typensicherheit. Python, das großzügig Werte akzeptiert,
Nonewenn dies an seiner Stelle erwartet wird bytearray, kann in ein völliges Chaos geraten, das nur vermieden werden kann, indem der Code mit Überprüfungen gefüllt wird None. Solche "Ententypisierung" -Annahmen führen oft zu Abstürzen.
Aber da ist Rust. Rust ist in vielerlei Hinsicht die ideale Lösung für alle oben beschriebenen potenziellen Probleme: Laufzeit und Speicherverbrauch sind mit C und C ++ vergleichbar, und es wird umfassende Typensicherheit geboten. Rust bietet außerdem zusätzliche Annehmlichkeiten wie starke Garantien für die Speichersicherheit und keinen Laufzeitaufwand. Da es keinen solchen Overhead gibt, ist es einfacher, Rust-Code in Code aus anderen Sprachen, insbesondere Python, zu integrieren. In diesem Artikel machen wir eine kurze Tour durch Rust, um zu sehen, ob sich der damit verbundene Hype lohnt.
Beispielanwendung für Data Science
Data Science ist ein sehr breites Fachgebiet mit vielen angewandten Aspekten, und es ist unmöglich, alle in einem Artikel zu diskutieren. Eine einfache Aufgabe für die Datenwissenschaft ist die Berechnung der Informationsentropie für Byte-Sequenzen. Eine allgemeine Formel für die Berechnung der Entropie in Bits an bestimmte Wikipedia :
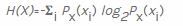
die Entropie für eine Zufallsvariable berechnen
Xwir zuerst zählen , wie oft jeder möglicher Byte - Wert tritt 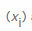 , und dann durch die Gesamtzahl der Elemente , die Anzahl unterteilt angetroffen die Wahrscheinlichkeit, auf einen bestimmten Wert zu berechnen
, und dann durch die Gesamtzahl der Elemente , die Anzahl unterteilt angetroffen die Wahrscheinlichkeit, auf einen bestimmten Wert zu berechnen 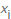 , jeweils
, jeweils 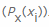 . Dann zählen wir den negativen Wert aus der gewichteten Summe der Wahrscheinlichkeiten eines bestimmten Wertes xi sowie der sogenannten eigenen Information
. Dann zählen wir den negativen Wert aus der gewichteten Summe der Wahrscheinlichkeiten eines bestimmten Wertes xi sowie der sogenannten eigenen Information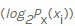 . Da wir die Entropie in Bits berechnen, wird sie hier verwendet
. Da wir die Entropie in Bits berechnen, wird sie hier verwendet 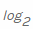 (beachten Sie Radix 2 für Bits).
(beachten Sie Radix 2 für Bits).
Lassen Sie uns Rust ausprobieren und sehen, wie es mit Entropieberechnung im Vergleich zu reinem Python umgeht, sowie mit einigen der oben erwähnten beliebten Python-Bibliotheken. Dies ist eine vereinfachte Schätzung der potenziellen datenwissenschaftlichen Leistung von Rust. Dieses Experiment ist keine Kritik an Python oder den darin enthaltenen hervorragenden Bibliotheken. In diesen Beispielen generieren wir unsere eigene C-Bibliothek aus Rust-Code, den wir aus Python importieren können. Alle Tests wurden unter Ubuntu 18.04 ausgeführt.
Reines Python
Beginnen wir mit einer einfachen reinen Python-Funktion (c
entropy.py) zur Berechnung der Entropie bytearray, wobei nur das Mathematikmodul aus der Standardbibliothek verwendet wird. Diese Funktion ist nicht optimiert. Nehmen wir sie als Ausgangspunkt für Änderungen und Leistungsmessungen.
import math
def compute_entropy_pure_python(data):
"""Compute entropy on bytearray `data`."""
counts = [0] * 256
entropy = 0.0
length = len(data)
for byte in data:
counts[byte] += 1
for count in counts:
if count != 0:
probability = float(count) / length
entropy -= probability * math.log(probability, 2)
return entropy
Python mit NumPy und SciPy
Es überrascht nicht, dass SciPy eine Funktion zur Berechnung der Entropie bietet. Aber zuerst verwenden wir eine Funktion
unique()von NumPy, um die Bytefrequenzen zu berechnen. Der Vergleich der Leistung der SciPy-Entropiefunktion mit anderen Implementierungen ist etwas unfair, da die SciPy-Implementierung zusätzliche Funktionen zur Berechnung der relativen Entropie (Kullback-Leibler-Abstand) bietet. Wieder werden wir eine (hoffentlich nicht zu langsame) Probefahrt machen, um zu sehen, wie die Leistung der aus Python importierten kompilierten Rust-Bibliotheken sein wird. Wir bleiben bei der in unserem Skript enthaltenen SciPy-Implementierung entropy.py.
import numpy as np
from scipy.stats import entropy as scipy_entropy
def compute_entropy_scipy_numpy(data):
""" bytearray `data` SciPy NumPy."""
counts = np.bincount(bytearray(data), minlength=256)
return scipy_entropy(counts, base=2)Python mit Rost
Als nächstes werden wir unsere Rust-Implementierung im Vergleich zu früheren Implementierungen etwas genauer untersuchen, um solide und solide zu sein. Beginnen wir mit dem mit Cargo generierten Standardbibliothekspaket. Die folgenden Abschnitte zeigen, wie wir das Rust-Paket geändert haben.
cargo new --lib rust_entropy
Cargo.tomlWir beginnen mit einer obligatorischen Manifestdatei
Cargo.toml, die das Frachtpaket definiert und einen Bibliotheksnamen angibt rust_entropy_lib. Wir verwenden den öffentlichen cpython-Container (v0.4.1), der von crates.io in der Rust Package Registry verfügbar ist. Für diesen Artikel verwenden wir Rust v1.42.0, die neueste stabile Version, die zum Zeitpunkt des Schreibens verfügbar war.
[package] name = "rust-entropy"
version = "0.1.0"
authors = ["Nobody <nobody@nowhere.com>"] edition = "2018"
[lib] name = "rust_entropy_lib"
crate-type = ["dylib"]
[dependencies.cpython] version = "0.4.1"
features = ["extension-module"]lib.rs
Die Implementierung der Rust-Bibliothek ist ziemlich einfach. Wie bei unserer reinen Python-Implementierung initialisieren wir das Zählarray für jeden möglichen Bytewert und durchlaufen die Daten, um die Zählungen zu füllen. Um die Operation abzuschließen, berechnen Sie die negative Summe der Wahrscheinlichkeiten multipliziert mit den
Wahrscheinlichkeiten und geben Sie sie zurück.
use cpython::{py_fn, py_module_initializer, PyResult, Python};
///
fn compute_entropy_pure_rust(data: &[u8]) -> f64 {
let mut counts = [0; 256];
let mut entropy = 0_f64;
let length = data.len() as f64;
// collect byte counts
for &byte in data.iter() {
counts[usize::from(byte)] += 1;
}
//
for &count in counts.iter() {
if count != 0 {
let probability = f64::from(count) / length;
entropy -= probability * probability.log2();
}
}
entropy
}
Wir haben nur noch
lib.rseinen Mechanismus, um eine reine Rust-Funktion aus Python aufzurufen. Wir integrieren lib.rseine CPython-optimierte (compute_entropy_cpython())Funktion, um unsere "reine" Rust-Funktion aufzurufen (compute_entropy_pure_rust()). Auf diese Weise profitieren wir nur von der Aufrechterhaltung einer einzigen reinen Rust-Implementierung und der Bereitstellung eines CPython-freundlichen Wrappers.
/// Rust CPython
fn compute_entropy_cpython(_: Python, data: &[u8]) -> PyResult<f64> {
let _gil = Python::acquire_gil();
let entropy = compute_entropy_pure_rust(data);
Ok(entropy)
}
// Python Rust CPython
py_module_initializer!(
librust_entropy_lib,
initlibrust_entropy_lib,
PyInit_rust_entropy_lib,
|py, m | {
m.add(py, "__doc__", "Entropy module implemented in Rust")?;
m.add(
py,
"compute_entropy_cpython",
py_fn!(py, compute_entropy_cpython(data: &[u8])
)
)?;
Ok(())
}
);Rust Code von Python aus aufrufen
Schließlich rufen wir die Rust-Implementierung von Python aus (wieder von
entropy.py). Dazu importieren wir zunächst unsere eigene dynamische Systembibliothek, die aus Rust kompiliert wurde. Dann rufen wir einfach die bereitgestellte Bibliotheksfunktion auf, die wir zuvor beim Initialisieren des Python-Moduls mithilfe eines Makros py_module_initializer!in unserem Rust-Code angegeben haben. Derzeit haben wir nur ein Python ( entropy.py) -Modul , das Funktionen zum Aufrufen aller Implementierungen der Entropieberechnung enthält.
import rust_entropy_lib
def compute_entropy_rust_from_python(data):
"" bytearray `data` Rust."""
return rust_entropy_lib.compute_entropy_cpython(data)Wir erstellen das obige Rust-Bibliothekspaket unter Ubuntu 18.04 mit Cargo. (Dieser Link kann für OS X-Benutzer nützlich sein.)
cargo build --releaseWenn Sie mit der Assembly fertig sind, benennen wir die resultierende Bibliothek um und kopieren sie in das Verzeichnis, in dem sich unsere Python-Module befinden, damit sie aus Skripten importiert werden kann. Die Bibliothek, die Sie mit Cargo erstellt haben, heißt
librust_entropy_lib.so, Sie müssen sie jedoch umbenennen, um im rust_entropy_lib.soRahmen dieser Tests erfolgreich importieren zu können.
Leistungsprüfung: Ergebnisse
Wir haben die Leistung jeder Funktionsimplementierung anhand von Pytest-Haltepunkten gemessen und die Entropie für über 1 Million zufällige Bytes berechnet. Alle Implementierungen werden mit denselben Daten angezeigt. Die Benchmarks (auch in entropy.py enthalten) sind unten aufgeführt.
# ### ###
# w/ NumPy
NUM = 1000000
VAL = np.random.randint(0, 256, size=(NUM, ), dtype=np.uint8)
def test_pure_python(benchmark):
""" Python."""
benchmark(compute_entropy_pure_python, VAL)
def test_python_scipy_numpy(benchmark):
""" Python SciPy."""
benchmark(compute_entropy_scipy_numpy, VAL)
def test_rust(benchmark):
""" Rust, Python."""
benchmark(compute_entropy_rust_from_python, VAL)Schließlich erstellen wir separate einfache Treiberskripte für jede Methode, die zur Berechnung der Entropie benötigt wird. Als nächstes folgt ein repräsentatives Treiberskript zum Testen der reinen Python-Implementierung. Die Datei enthält
testdata.bin1.000.000 zufällige Bytes, die zum Testen aller Methoden verwendet werden. Jede Methode wiederholt die Berechnung 100 Mal, um die Erfassung von Speichernutzungsdaten zu vereinfachen.
import entropy
with open('testdata.bin', 'rb') as f:
DATA = f.read()
for _ in range(100):
entropy.compute_entropy_pure_python(DATA)Implementierungen für SciPy / NumPy und Rust haben eine gute Leistung gezeigt und die nicht optimierte reine Python-Implementierung um mehr als das 100-fache übertroffen. Die Rust-Version schnitt nur geringfügig besser ab als die SciPy / NumPy-Version, aber die Ergebnisse bestätigten unsere Erwartungen: Reines Python ist viel langsamer als kompilierte Sprachen, und in Rust geschriebene Erweiterungen können recht erfolgreich mit ihren C-Gegenstücken konkurrieren (sie sogar in solchen schlagen) Mikrotests).
Es gibt auch andere Methoden zur Verbesserung der Produktivität. Wir könnten Module verwenden
ctypesoder cffi. Sie können Typhinweise hinzufügen und mit Cython eine Bibliothek generieren, die Sie aus Python importieren können. Alle diese Optionen erfordern die Berücksichtigung lösungsspezifischer Kompromisse.

Wir haben auch die Speichernutzung für jede Feature-Implementierung mithilfe der GNU-Anwendung gemessen
time(nicht zu verwechseln mit dem integrierten Shell-Befehl time). Insbesondere haben wir die maximale Größe des residenten Sets gemessen.
Während in reinen Python- und Rust-Implementierungen die maximalen Größen für diesen Teil ziemlich ähnlich sind, verbraucht die SciPy / NumPy-Implementierung erheblich mehr Speicher für diesen Benchmark. Dies ist vermutlich auf zusätzliche Funktionen zurückzuführen, die beim Import in den Speicher geladen werden. Wie dem auch sei, das Aufrufen von Rust-Code aus Python scheint keinen signifikanten Speicheraufwand zu verursachen.

Ergebnis
Wir sind sehr beeindruckt von der Leistung, die wir erhalten, wenn wir Rust von Python aus aufrufen. In unserer ehrlich gesagt kurzen Bewertung konnte die Rust-Implementierung in der Leistung mit der Basis-C-Implementierung aus den Paketen SciPy und NumPy konkurrieren. Rost scheint für eine effiziente Verarbeitung in großem Maßstab großartig zu sein.
Rust hat nicht nur hervorragende Ausführungszeiten gezeigt; Es ist zu beachten, dass der Speicheraufwand bei diesen Tests ebenfalls minimal war. Diese Laufzeit- und Speichernutzungsmerkmale scheinen aus Gründen der Skalierbarkeit ideal zu sein. Die Leistung von SciPy- und NumPy-C-FFI-Implementierungen ist definitiv vergleichbar, aber mit Rust erhalten wir zusätzliche Vorteile, die C und C ++ uns nicht bieten. Speichersicherheit und Thread-Sicherheitsgarantien sind ein sehr attraktiver Vorteil.
Während C eine vergleichbare Laufzeit wie Rust bietet, bietet C selbst keine Thread-Sicherheit. Es gibt externe Bibliotheken, die diese Funktionalität für C bereitstellen. Es liegt jedoch in der Verantwortung des Entwicklers, sicherzustellen, dass sie ordnungsgemäß verwendet werden. Rust-Monitore auf Thread-Sicherheitsprobleme wie Rennen während der Kompilierung - dank des Besitzmodells - und die Standardbibliothek bietet eine Reihe von Parallelitätsmechanismen wie Pipes, Sperren und referenzgezählte Smart Pointer.
Wir empfehlen nicht, SciPy oder NumPy nach Rust zu portieren, da diese Python-Bibliotheken bereits gut optimiert sind und von coolen Entwicklergemeinschaften unterstützt werden. Auf der anderen Seite empfehlen wir dringend, Code von reinem Python nach Rust zu portieren, der nicht in Hochleistungsbibliotheken enthalten ist. Im Kontext von Data Science-Anwendungen, die für die Sicherheitsanalyse verwendet werden, scheint Rust aufgrund seiner Geschwindigkeits- und Sicherheitsgarantien eine wettbewerbsfähige Alternative zu Python zu sein.