
Wir werden die Skripte aus Anhang B - Griechisches Mythologie-Diagramm-Beispiel der SAP-HANA-Diagrammreferenzdokumentation für die übliche SAP-HANA-Plattform übernehmen, die lokal im Rechenzentrum bereitgestellt wird. Der Hauptzweck dieses Beispiels besteht darin, die Analysefunktionen von SAP HANA zu zeigen und zu zeigen, wie Sie die Beziehung von Objekten und Ereignissen mithilfe von Diagrammalgorithmen analysieren können. Wir werden nicht im Detail auf diese Technologie eingehen, die Hauptidee wird aus der weiteren Diskussion klar. Jeder Interessierte kann es selbst herausfinden, indem er die Funktionen der SAP HANA Express Edition testet oder einen kostenlosen Kurs zur Analyse verbundener Daten mit SAP HANA Graph belegt .
Lassen Sie uns die Daten in die relationale Cloud der SAP HANA Cloud stellen und die Möglichkeiten zur Analyse der familiären Bindungen griechischer Helden sehen. Denken Sie daran, dass es in "Mythen und Legenden des antiken Griechenland" viele Charaktere gab und Sie sich in der Mitte nicht mehr daran erinnern, wer der Sohn und der Bruder von wem war? Hier werden wir uns ein Memo machen und es nie vergessen.
Erstellen Sie zunächst eine Instanz der SAP HANA Cloud. Dies ist ganz einfach. Sie müssen die Parameter des zukünftigen Systems eingeben und einige Minuten warten, bis die Instanz für Sie bereitgestellt wurde (Abb. 1).

Abbildung 1
Klicken Sie also auf die Schaltfläche Instanz erstellen. Daraufhin wird die erste Seite des Erstellungsassistenten angezeigt, auf der Sie den Kurznamen der Instanz angeben, das Kennwort festlegen und eine Beschreibung geben müssen ( Abbildung 2 ).
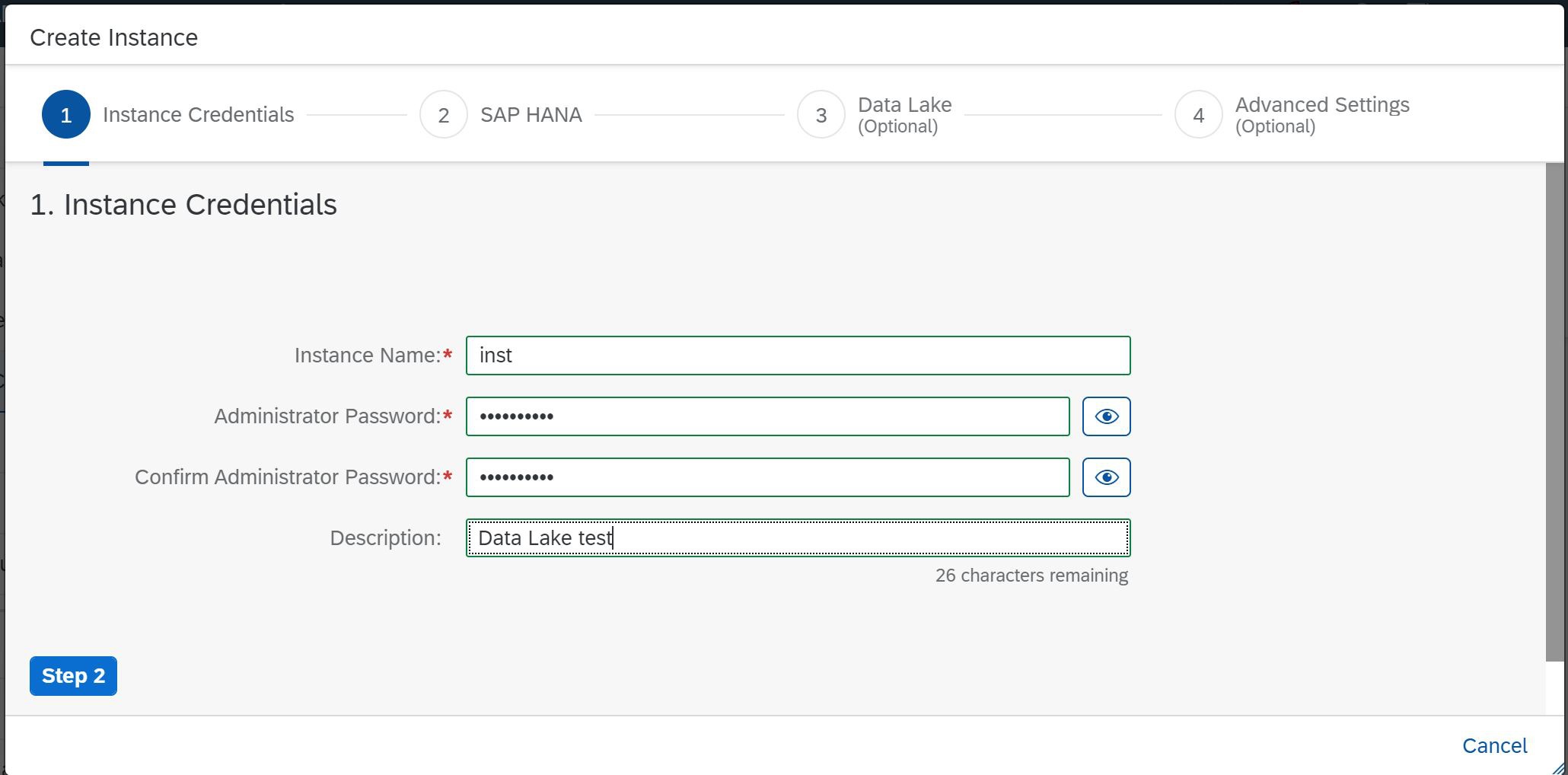
Abbildung 2
Klicken Sie auf die Schaltfläche Schritt 2. Jetzt müssen Sie die Parameter der zukünftigen SAP-HANA-Instanz angeben. Hier können Sie nur die Größe des RAM des zukünftigen Systems einstellen, alle anderen Parameter werden automatisch ermittelt (Abb. 3).

Abbildung 3
Wir sehen, dass wir jetzt die Möglichkeit haben, den Mindestwert von 30 GB und den Höchstwert von 900 GB zu wählen. Wir wählen 30 GB aus und es wird automatisch festgestellt, dass bei dieser Speichermenge zwei virtuelle Prozessoren zur Unterstützung von Berechnungen und 120 GB zum Speichern von Daten auf der Festplatte benötigt werden. Hier wird mehr Speicherplatz zugewiesen, da wir die NSE-Technologie (Native Storage Extension) von SAP HANA verwenden können. Wenn Sie einen größeren Speicher wählen, z. B. 255 GB, benötigen Sie 17 virtuelle Prozessoren und 720 GB Festplattenspeicher (Abb. 4).
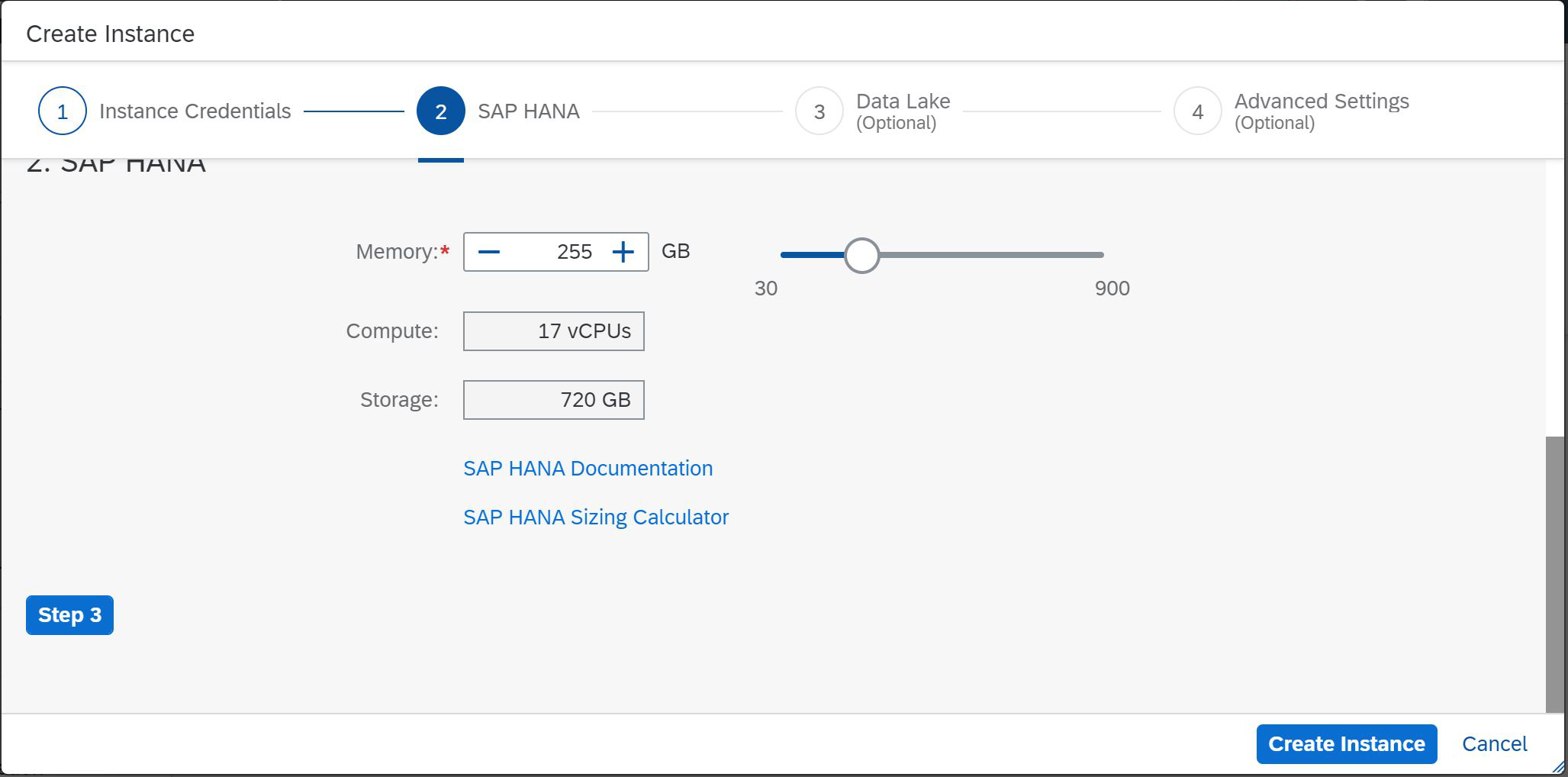
Figur 4
Aber wir brauchen nicht so viel Speicher für das Beispiel. Wir setzen die Parameter auf ihre ursprünglichen Werte zurück und klicken auf Schritt 3. Nun müssen wir auswählen, ob der Datensee verwendet werden soll. Die Antwort liegt auf der Hand. Natürlich werden wir. Wir wollen auch ein solches Experiment durchführen (Abb. 5).

Abbildung 5
In diesem Schritt haben wir viel mehr Möglichkeiten und Freiheiten, eine Instanz des Datensees zu erstellen. Sie können die Größe der erforderlichen Computerressourcen und des Festplattenspeichers auswählen. Die Parameter der verwendeten Komponenten / Knoten werden automatisch ausgewählt. Das System selbst ermittelt die erforderlichen Rechenressourcen für die Knoten "Koordinator" und "Arbeit". Wenn Sie mehr über diese Komponenten erfahren möchten, wenden Sie sich besser an die SAP IQ- Ressourcen und den SAP HANA Cloud Data Lake.. Klicken Sie anschließend auf Schritt 4.
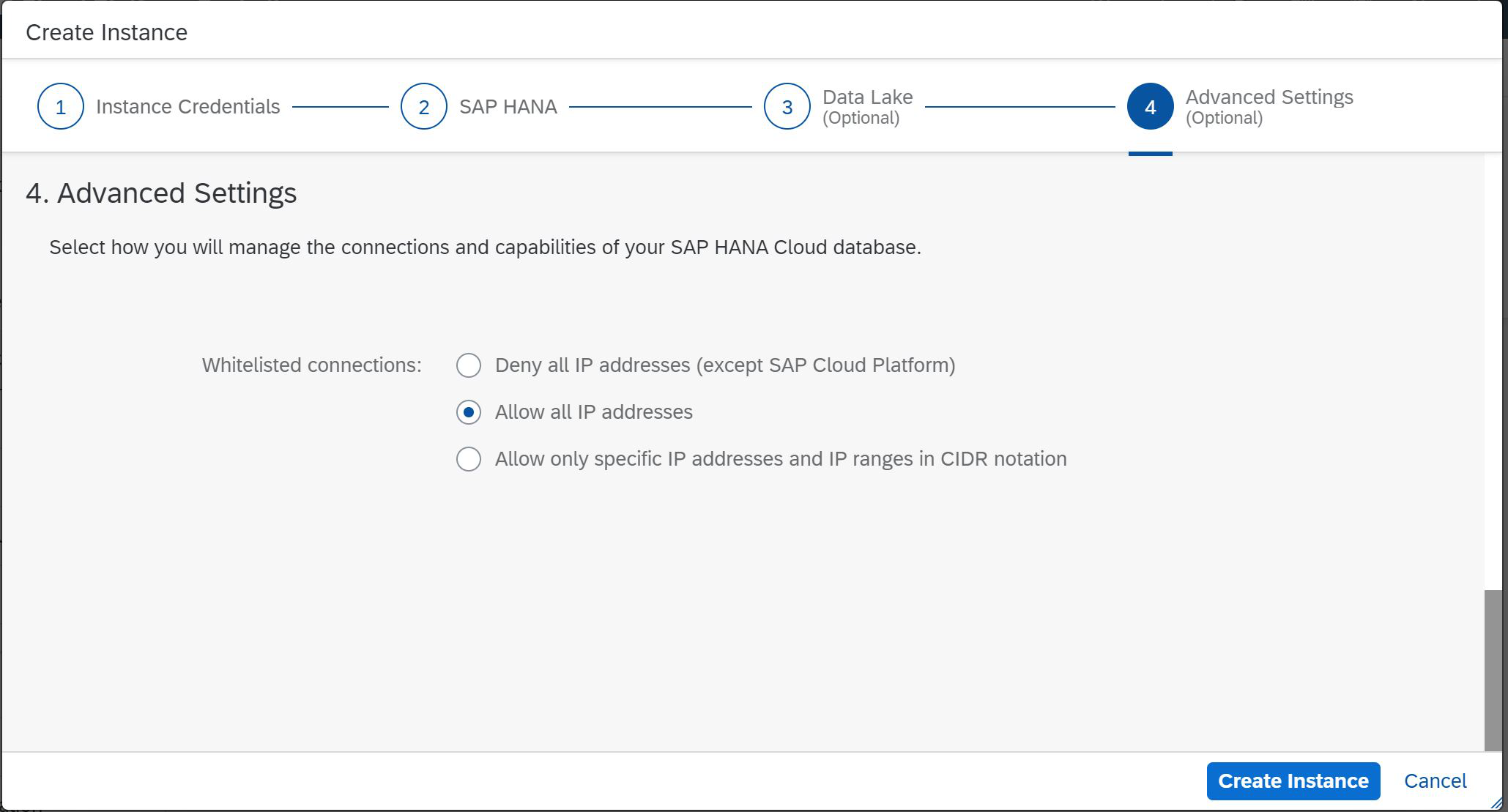
Abbildung 6
In diesem Schritt bestimmen oder beschränken wir die IP-Adressen, die auf die zukünftige Instanz von SAP HANA zugreifen können. Wie Sie sehen, ist dies der letzte Schritt unseres Assistenten (Abb. 6). Sie müssen nur noch auf Instanz erstellen klicken und sich Kaffee einschenken.

Abbildung 7
Der Prozess hat begonnen (Abbildung 7) und es wird nicht lange dauern. Wir hatten trotz der späten Nacht nur Zeit, starken Kaffee zu trinken. Und wann sonst können Sie ruhig mit dem System experimentieren und verschiedene Chips anschrauben? So entsteht unser System (Abb. 8).

Abbildung 8
Wir haben zwei Möglichkeiten: Öffnen Sie das SAP HANA Cockpit oder den SAP HANA Database Explorer. Wir wissen, dass das zweite Produkt vom Cockpit aus gestartet werden kann. Deshalb öffnen wir gleichzeitig das SAP HANA Cockpit und sehen, was da ist. Zunächst müssen Sie jedoch einen Benutzer und sein Kennwort angeben. Bitte beachten Sie, dass der SYSTEM-Benutzer Ihnen nicht zur Verfügung steht. Sie müssen DBADMIN verwenden. Geben Sie in diesem Fall das Kennwort an, das Sie beim Erstellen der Instanz festgelegt haben (siehe Abb. 9).
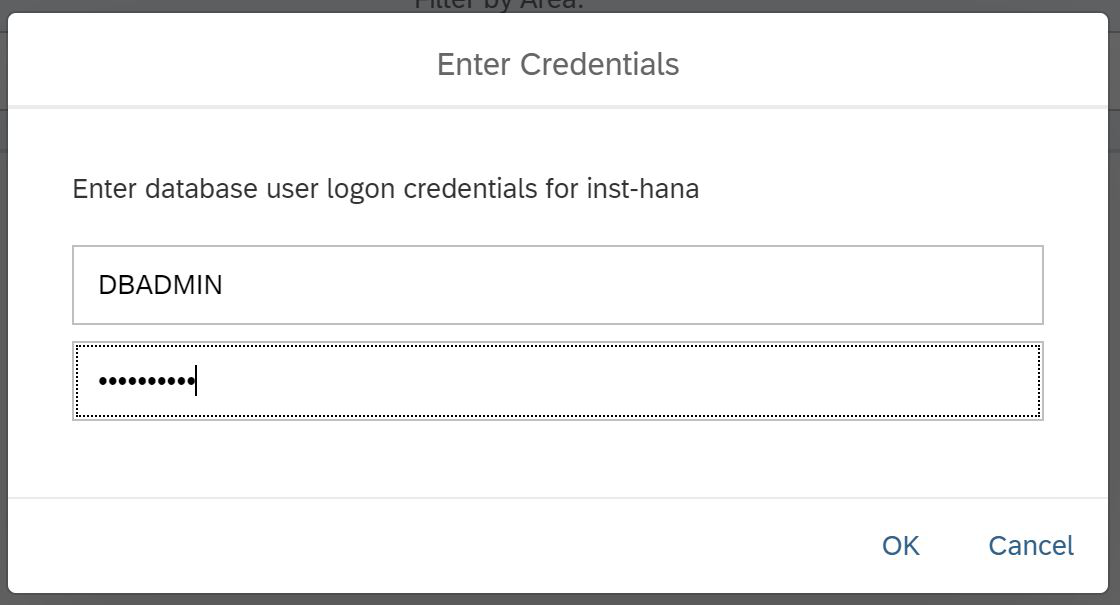
Abbildung 9
Wir gingen ins Cockpit und sahen die traditionelle SAP-Oberfläche in Form von Kacheln, wenn jede von ihnen für ihre Aufgabe verantwortlich ist. In der oberen rechten Ecke sehen wir einen Link zur SQL-Konsole (Abb. 10).
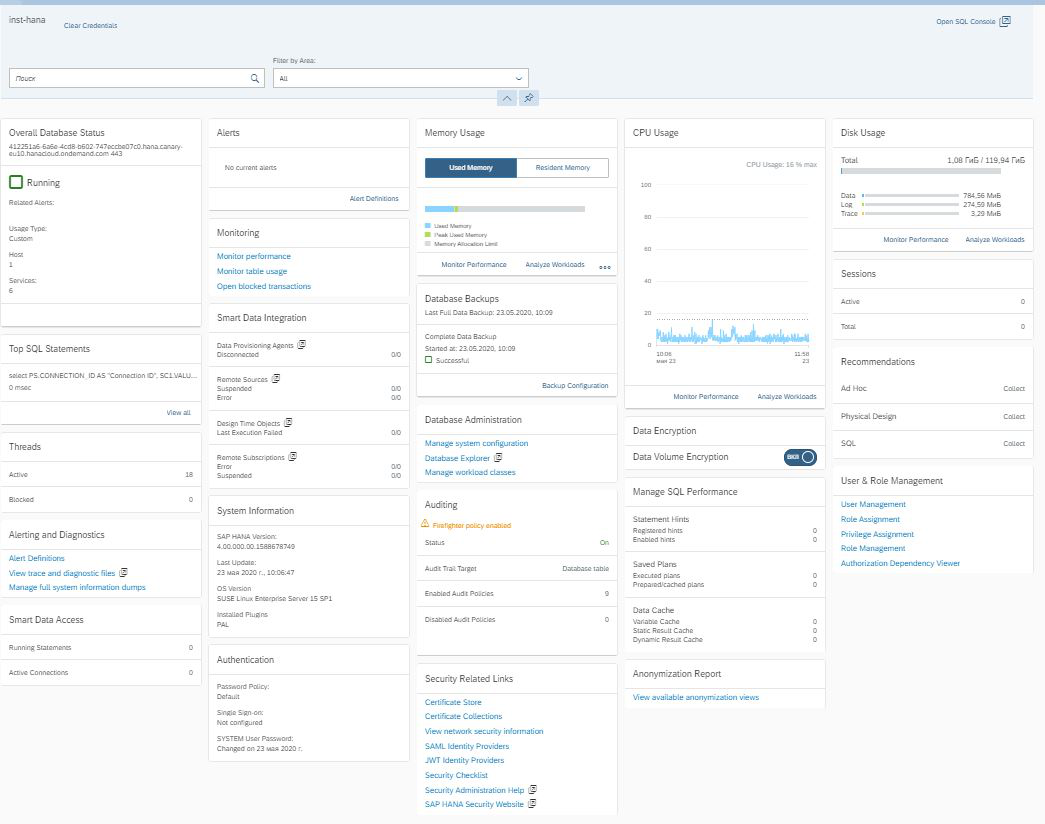
Abbildung 10
Sie ermöglicht es uns, zum SAP HANA Database Explorer zu wechseln.
Die Oberfläche dieses Tools ähnelt der SAP Web IDE, ist jedoch nur für die Arbeit mit Datenbankobjekten vorgesehen. Zunächst sind wir natürlich daran interessiert, wie wir in den Datensee gelangen. Immerhin haben wir jetzt ein Tool für die Arbeit mit HANA geöffnet. Gehen wir zum Element Remote Source im Navigator und sehen einen Link zum See (SYSRDL, RDL - Relation Data Lake). Hier ist es der gewünschte Zugang (Abb. 11).

Abbildung 11
Fahren wir fort, wir sollten nicht unter dem Administrator arbeiten. Wir müssen einen Testbenutzer erstellen, unter dem wir mit der HANA-Graph-Engine experimentieren, aber die Daten in einem relationalen Datensee platzieren.
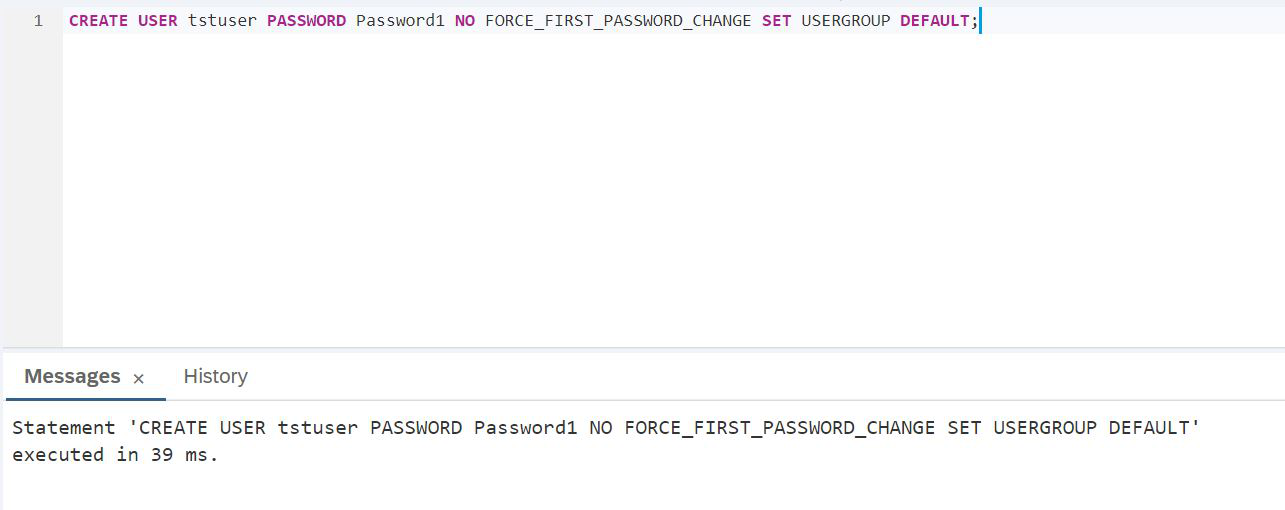
SKRIPT:
CREATE USER tstuser PASSWORD Password1 NO FORCE_FIRST_PASSWORD_CHANGE SET USERGROUP DEFAULT;Wir planen, mit einem Datensee zu arbeiten, daher müssen Sie auf jeden Fall Rechte erteilen, z. B. HANA_SYSRDL # CG_ADMIN_ROLE, damit Sie frei Objekte erstellen und tun können, was Sie wollen.
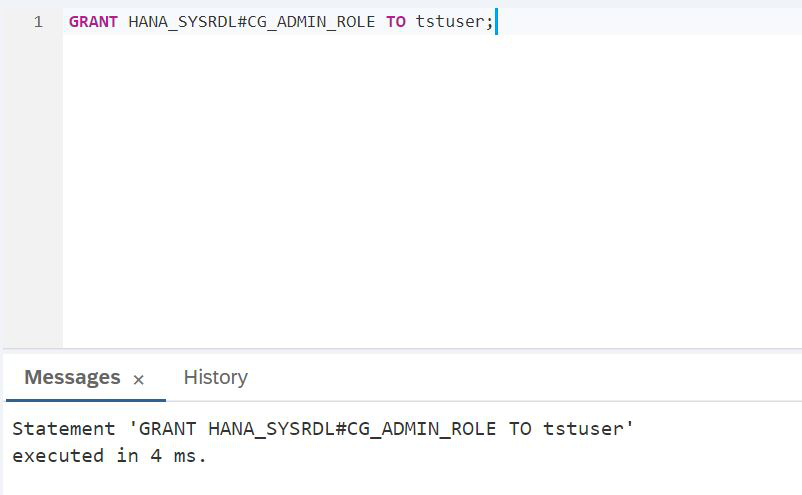
SKRIPT:
GRANT HANA_SYSRDL#CG_ADMIN_ROLE TO tstuser;Nachdem die Arbeit unter dem SAP-HANA-Administrator abgeschlossen ist, kann der SAP-HANA-Datenbank-Explorer geschlossen werden und wir müssen uns unter dem neu erstellten Benutzer tstuser anmelden. Kehren wir der Einfachheit halber zum SAP HANA Cockpit zurück und beenden Sie die Administrationssitzung. Zu diesem Zweck befindet sich in der oberen linken Ecke ein solcher Link Anmeldeinformationen löschen (Abb. 12).

Abbildung 12
Nachdem wir darauf geklickt haben, müssen wir uns erneut anmelden, jetzt jedoch unter dem Benutzer tstuser (Abbildung 13).
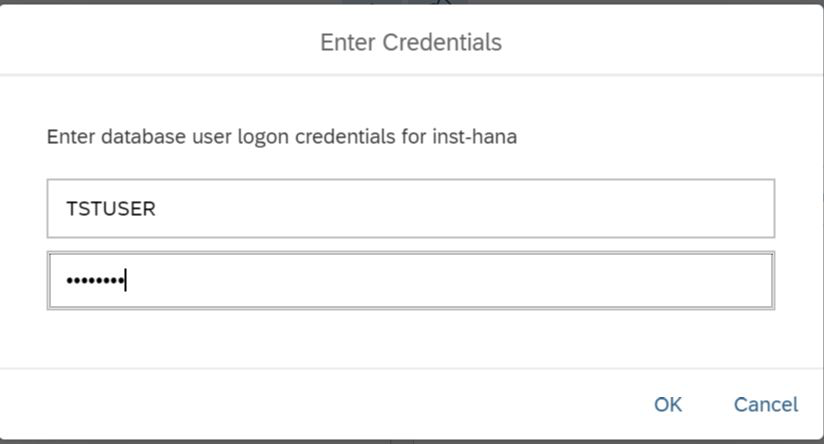
Abbildung 13
Und wir können die SQL-Konsole erneut öffnen, um zum SAP HANA Database Explorer zurückzukehren, jedoch unter einem neuen Benutzer (Abbildung 14).

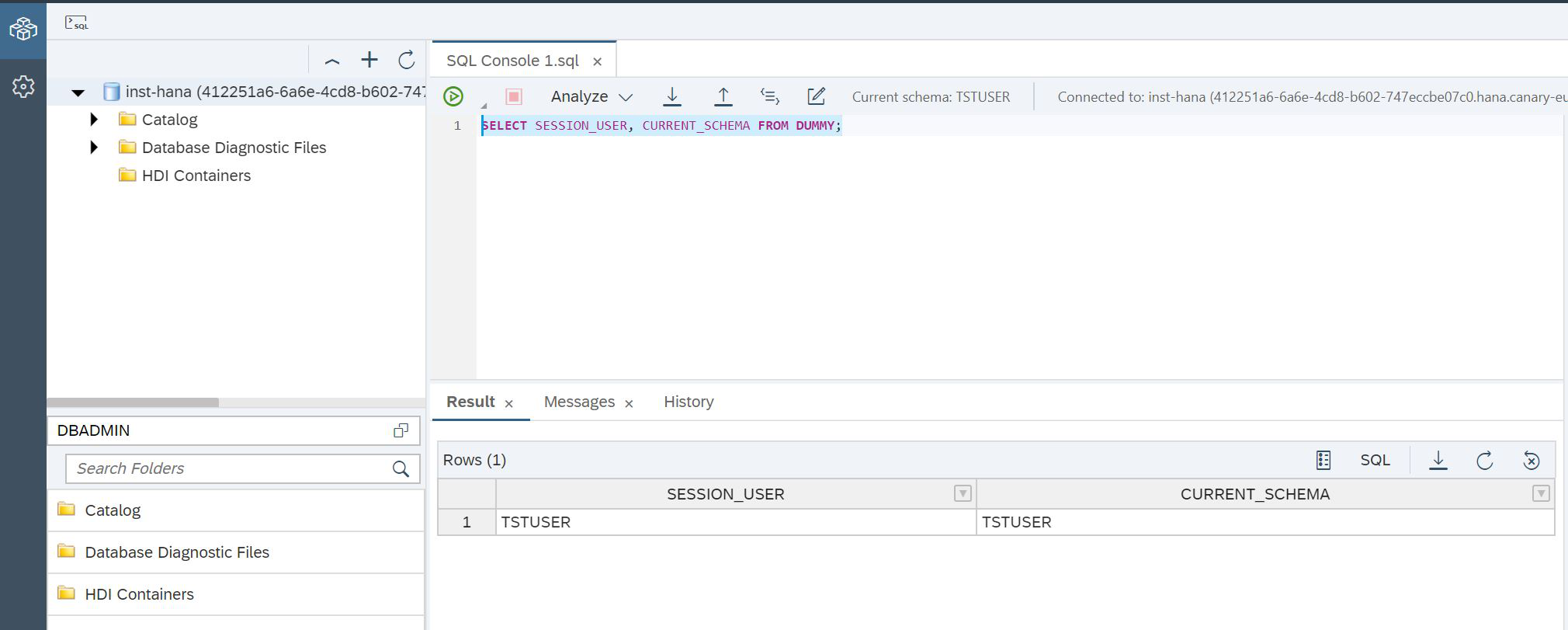
Abbildung 14
SCRIPT:
SELECT SESSION_USER, CURRENT_SCHEMA FROM DUMMY;Das war's, jetzt sind wir sicher, dass wir mit HANA unter dem richtigen Benutzer arbeiten. Es ist Zeit, Tabellen im Datensee zu erstellen. Dazu gibt es eine spezielle Prozedur SYSRDL # CG.REMOTE_EXECUTE, in die Sie einen Parameter übergeben müssen - einen Befehl line =. Mit dieser Funktion erstellen wir eine Tabelle im Datensee (Abb. 15), in der alle unsere Charaktere gespeichert werden: Helden, griechische Götter und Titanen.

Abbildung 15
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
CREATE TABLE "MEMBERS" (
"NAME" VARCHAR(100) PRIMARY KEY,
"TYPE" VARCHAR(100),
"RESIDENCE" VARCHAR(100)
);
END');Und dann erstellen wir eine Tabelle, in der wir die familiären Bindungen dieser Charaktere behalten (Abb. 16).

Abbildung 16
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
CREATE TABLE "RELATIONSHIPS" (
"KEY" INTEGER UNIQUE NOT NULL,
"SOURCE" VARCHAR(100) NOT NULL,
"TARGET" VARCHAR(100) NOT NULL,
"TYPE" VARCHAR(100),
FOREIGN KEY RELATION_SOURCE ("SOURCE") references "MEMBERS"("NAME") ON UPDATE RESTRICT ON DELETE RESTRICT,
FOREIGN KEY RELATION_TARGET ("TARGET") references "MEMBERS"("NAME") ON UPDATE RESTRICT ON DELETE RESTRICT
);
END');Wir werden uns jetzt nicht mit Integrationsproblemen befassen, dies ist eine separate Geschichte. Im ursprünglichen Beispiel gibt es INSERT-Befehle zum Erstellen der griechischen Götter und ihrer Verwandtschaft. Wir verwenden diese Befehle. Wir müssen uns nur daran erinnern, dass wir den Befehl über eine Prozedur an den Datensee übergeben, also müssen wir die Anführungszeichen verdoppeln, wie in Abb. 17 gezeigt.

Abbildung 17
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
INSERT INTO "MEMBERS"("NAME", "TYPE")
VALUES (''Chaos'', ''primordial deity'');
INSERT INTO "MEMBERS"("NAME", "TYPE")
VALUES (''Gaia'', ''primordial deity'');
INSERT INTO "MEMBERS"("NAME", "TYPE")
VALUES (''Uranus'', ''primordial deity'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Rhea'', ''titan'', ''Tartarus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Cronus'', ''titan'', ''Tartarus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Zeus'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Poseidon'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Hades'', ''god'', ''Underworld'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Hera'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Demeter'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Athena'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Ares'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Aphrodite'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Hephaestus'', ''god'', ''Olympus'');
INSERT INTO "MEMBERS"("NAME", "TYPE", "RESIDENCE")
VALUES (''Persephone'', ''god'', ''Underworld'');
END');Und die zweite Tabelle (Abb. 18)
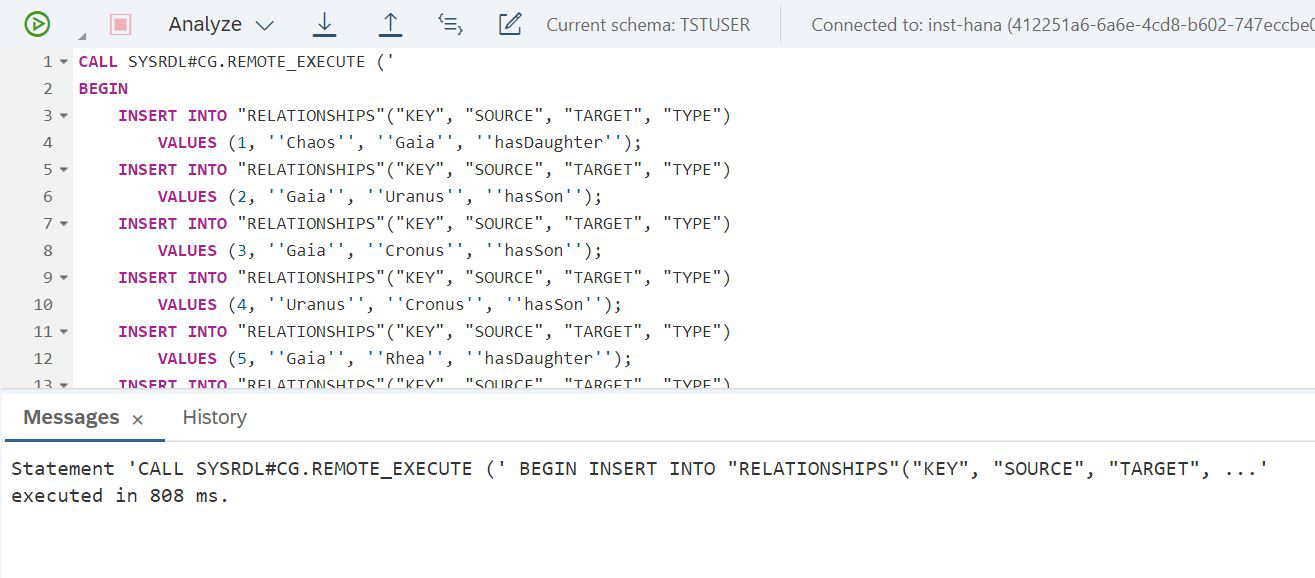
Abbildung 18
SCRIPT:
CALL SYSRDL#CG.REMOTE_EXECUTE ('
BEGIN
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (1, ''Chaos'', ''Gaia'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (2, ''Gaia'', ''Uranus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (3, ''Gaia'', ''Cronus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (4, ''Uranus'', ''Cronus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (5, ''Gaia'', ''Rhea'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (6, ''Uranus'', ''Rhea'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (7, ''Cronus'', ''Zeus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (8, ''Rhea'', ''Zeus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (9, ''Cronus'', ''Hera'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (10, ''Rhea'', ''Hera'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (11, ''Cronus'', ''Demeter'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (12, ''Rhea'', ''Demeter'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (13, ''Cronus'', ''Poseidon'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (14, ''Rhea'', ''Poseidon'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (15, ''Cronus'', ''Hades'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (16, ''Rhea'', ''Hades'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (17, ''Zeus'', ''Athena'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (18, ''Zeus'', ''Ares'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (19, ''Hera'', ''Ares'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (20, ''Uranus'', ''Aphrodite'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (21, ''Zeus'', ''Hephaestus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (22, ''Hera'', ''Hephaestus'', ''hasSon'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (23, ''Zeus'', ''Persephone'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (24, ''Demeter'', ''Persephone'', ''hasDaughter'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (25, ''Zeus'', ''Hera'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (26, ''Hera'', ''Zeus'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (27, ''Hades'', ''Persephone'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (28, ''Persephone'', ''Hades'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (29, ''Aphrodite'', ''Hephaestus'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (30, ''Hephaestus'', ''Aphrodite'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (31, ''Cronus'', ''Rhea'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (32, ''Rhea'', ''Cronus'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (33, ''Uranus'', ''Gaia'', ''marriedTo'');
INSERT INTO "RELATIONSHIPS"("KEY", "SOURCE", "TARGET", "TYPE")
VALUES (34, ''Gaia'', ''Uranus'', ''marriedTo'');
END');Öffnen wir nun Remote Source erneut. Wir müssen virtuelle Tabellen in HANA basierend auf der Beschreibung der Tabellen im Datensee erstellen (Abb. 19).
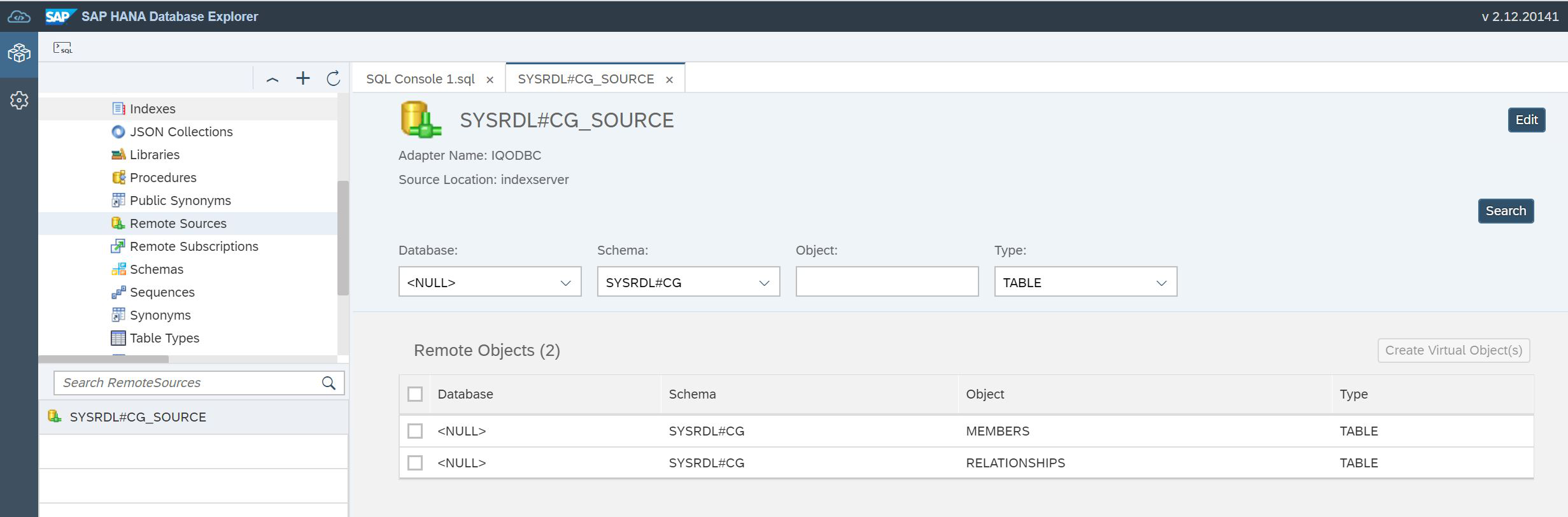
Abbildung 19
Suchen Sie beide Tabellen, aktivieren Sie die Kontrollkästchen vor den Tabellen und klicken Sie auf die Schaltfläche Virtuelle Objekte erstellen (siehe Abbildung 20).
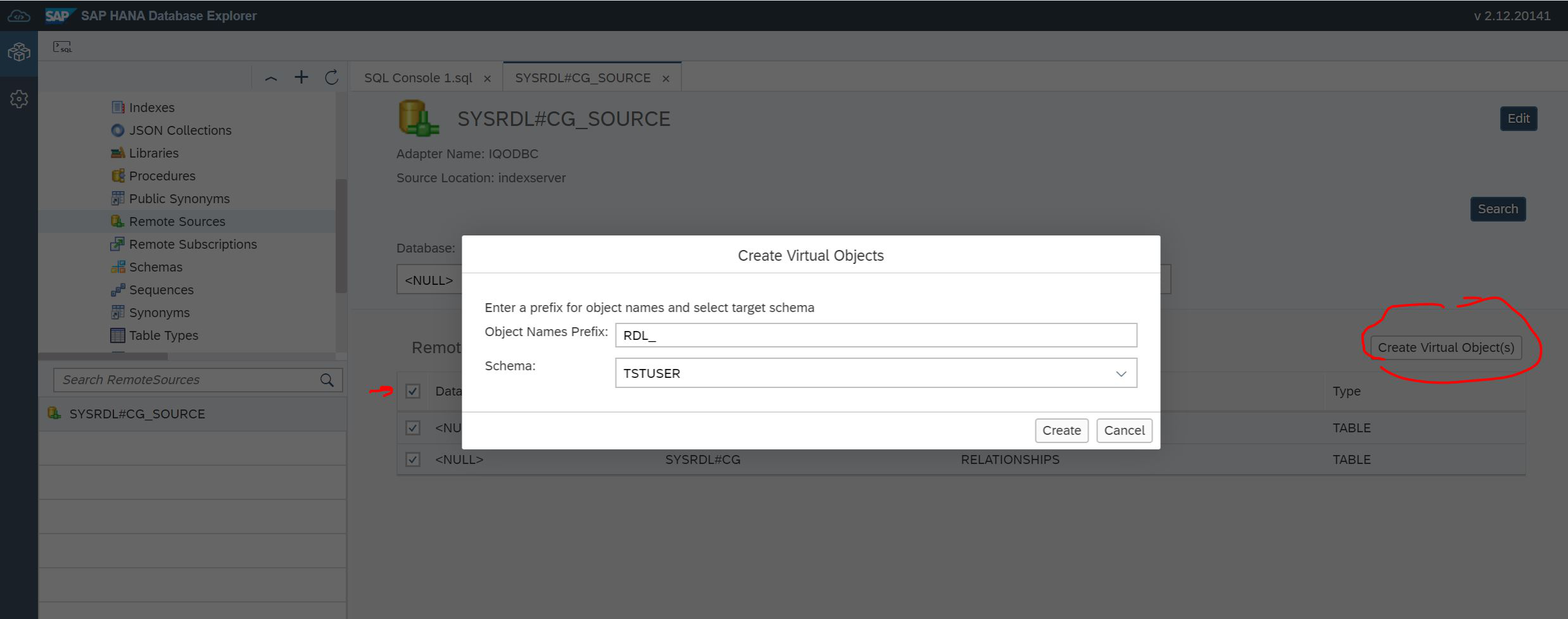
Abbildung 20
Wir haben die Möglichkeit, das Schema anzugeben, in dem virtuelle Tabellen erstellt werden. Und dort müssen Sie ein Präfix angeben, damit diese Tabellen leichter zu finden sind. Danach können wir im Navigator Tabelle auswählen, unsere Tabellen anzeigen und die Daten anzeigen (Abb. 21).

Abbildung 21
In diesem Schritt ist es wichtig, auf den Filter unten links zu achten. Es sollte unseren Benutzernamen oder unser TSTUSER-Schema geben.
Du bist fast fertig. Wir haben Tabellen im See erstellt und Daten in sie geladen. Um von der HANA-Ebene aus darauf zugreifen zu können, haben wir virtuelle Tabellen. Wir sind bereit, ein neues Objekt zu erstellen - ein Diagramm (Abb. 22).
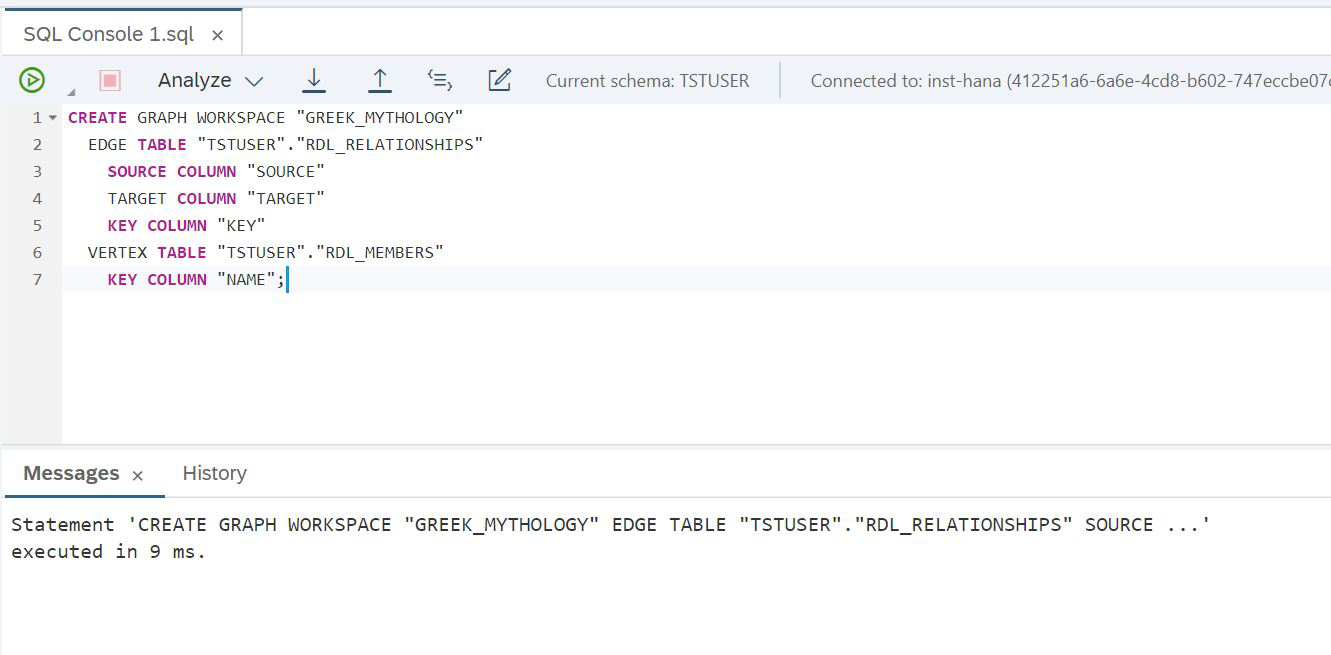
Abbildung 22
SCRIPT:
CREATE GRAPH WORKSPACE "GREEK_MYTHOLOGY"
EDGE TABLE "TSTUSER"."RDL_RELATIONSHIPS"
SOURCE COLUMN "SOURCE"
TARGET COLUMN "TARGET"
KEY COLUMN "KEY"
VERTEX TABLE "TSTUSER"."RDL_MEMBERS"
KEY COLUMN "NAME";Alles hat funktioniert, die Zählung ist fertig. Und Sie können sofort versuchen, eine einfache Abfrage der Diagrammdaten vorzunehmen, um beispielsweise alle Töchter des Chaos und alle Töchter dieser Töchter zu finden. Dafür wird uns Cypher helfen - eine Sprache für die Graphanalyse. Es wurde speziell für die Arbeit mit Grafiken entwickelt, ist praktisch, einfach und hilft bei der Lösung komplexer Probleme. Wir müssen uns nur daran erinnern, dass das Cypher-Skript mithilfe einer Tabellenfunktion in eine SQL-Abfrage eingeschlossen werden muss. Sehen Sie, wie unsere Aufgabe in dieser Sprache gelöst wird (Abb. 23).

Abbildung 23
SCRIPT:
SELECT * FROM OPENCYPHER_TABLE( GRAPH WORKSPACE "GREEK_MYTHOLOGY" QUERY
'
MATCH p = (a)-[*1..2]->(b)
WHERE a.NAME = ''Chaos'' AND ALL(e IN RELATIONSHIPS(p) WHERE e.TYPE=''hasDaughter'')
RETURN b.NAME AS Name
ORDER BY b.NAME
'
)Lassen Sie uns sehen, wie das visuelle Diagrammanalysetool von SAP HANA funktioniert. Wählen Sie dazu im Navigator Graph Workspace aus (Abb. 24).
Abbildung 24
Und jetzt sehen Sie unsere Grafik (Abb. 25).
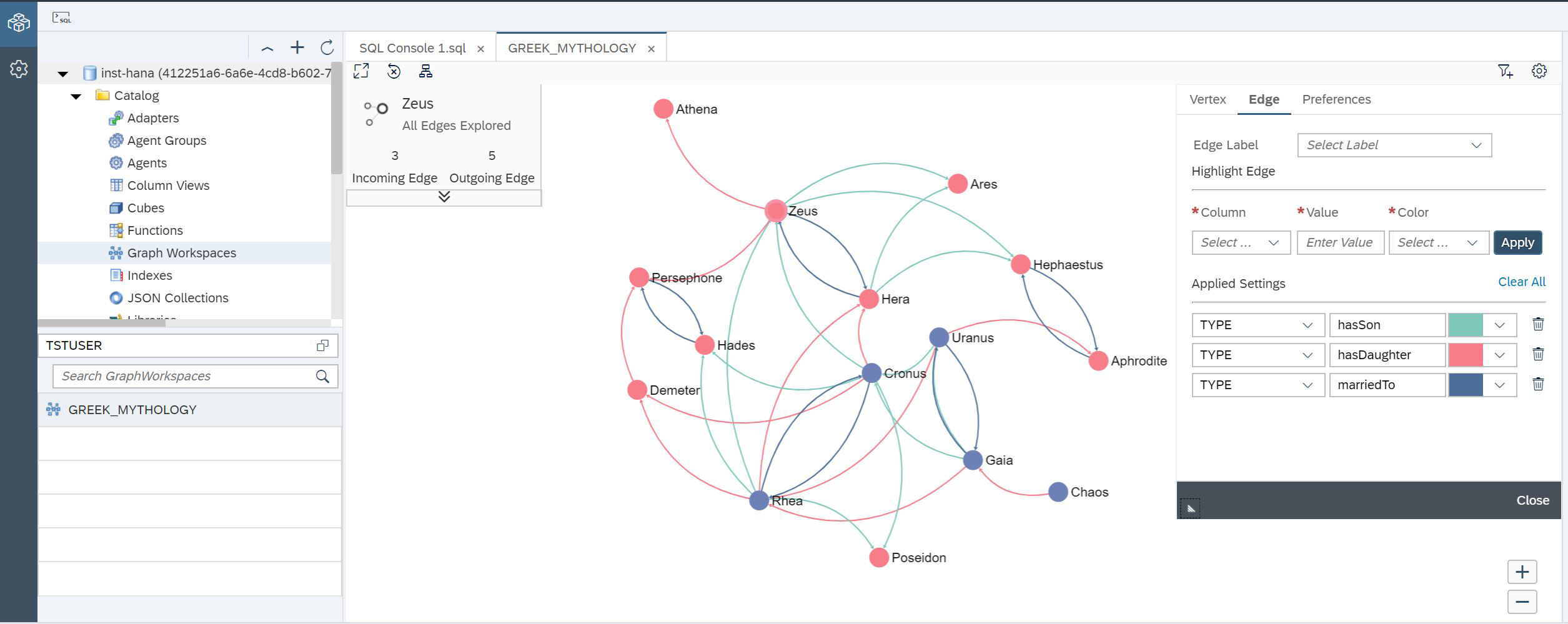
Abbildung 25
Sie sehen ein Diagramm, das bereits gefärbt wurde. Wir haben dies mit den Einstellungen auf der rechten Seite des Bildschirms getan. In der oberen linken Ecke werden detaillierte Informationen zu dem aktuell ausgewählten Knoten angezeigt.
Nun ... wir haben es geschafft. Die Daten befinden sich im Datensee und werden mit Tools in SAP HANA analysiert. Eine Technologie berechnet die Daten und die andere ist für deren Speicherung verantwortlich. Wenn die Diagrammdaten verarbeitet werden, werden sie vom Datensee angefordert und an SAP HANA übertragen. Können wir unsere Anfragen beschleunigen? Wie kann sichergestellt werden, dass die Daten im RAM gespeichert und nicht aus dem Datensee geladen werden? Es gibt eine einfache, aber nicht sehr schöne Möglichkeit: Erstellen Sie eine Tabelle, in die der Inhalt der Data Lake-Tabelle geladen werden kann (Abb. 26).

Abbildung 26
SCRIPT:
CREATE COLUMN TABLE MEMBERS AS (SELECT * FROM "TSTUSER"."RDL_MEMBERS")Es gibt aber noch einen anderen Weg - dies ist die Verwendung der Datenreplikation im SAP-HANA-RAM. Dies bietet eine bessere Leistung für SQL-Abfragen als der Zugriff auf Daten, die in einem Datensee gespeichert sind, mithilfe einer virtuellen Tabelle. Sie können zwischen virtuellen und Replikationstabellen wechseln. Fügen Sie dazu die Replikattabelle zur virtuellen Tabelle hinzu. Dies kann mit der Anweisung ALTER VIRTUAL TABLE erfolgen. Danach greift eine Abfrage mit einer virtuellen Tabelle automatisch auf die Replikattabelle zu, die sich im SAP-HANA-RAM befindet. Mal sehen, wie das geht, lass uns ein Experiment durchführen. Führen wir eine solche Anfrage aus (Abb. 27).
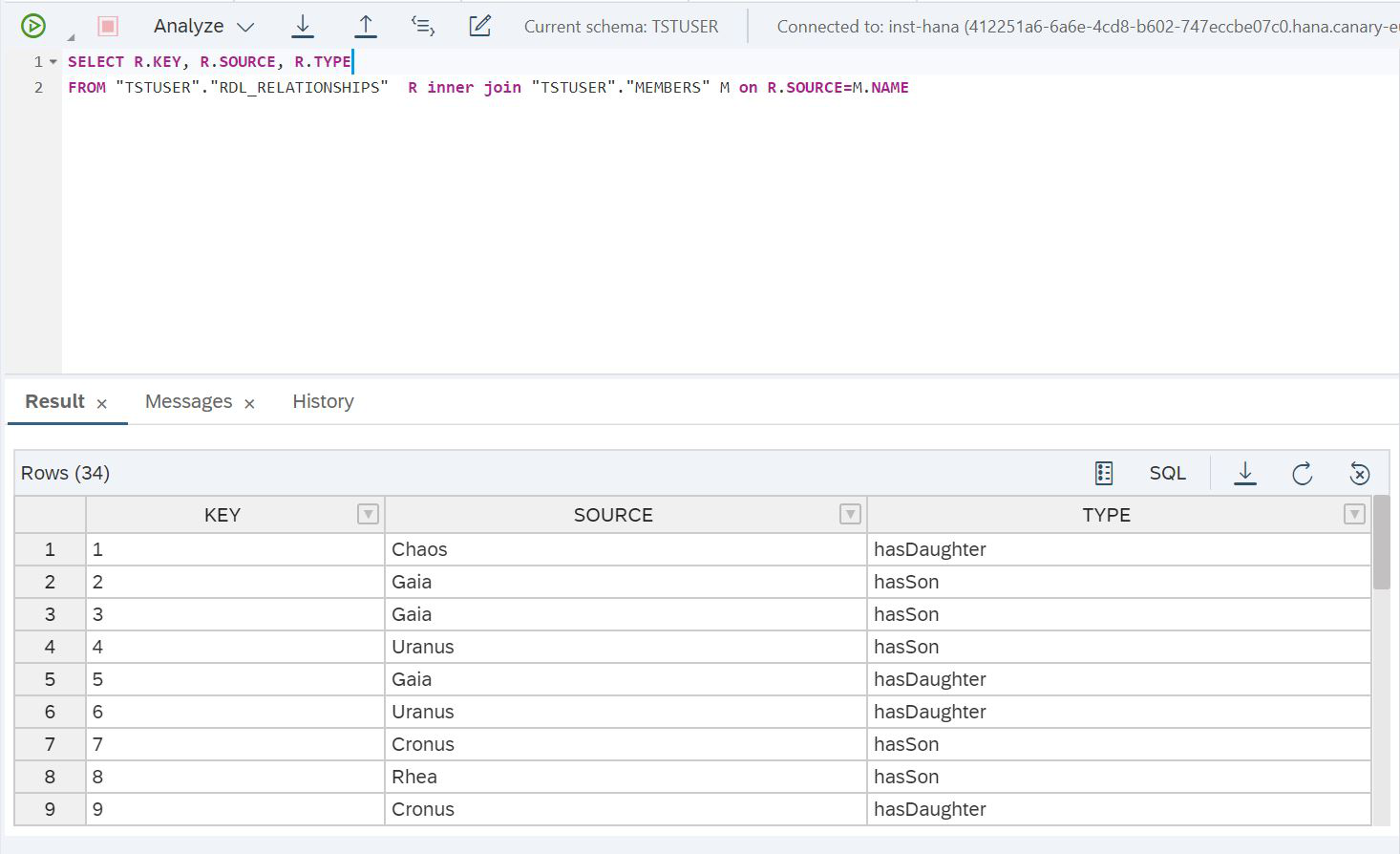
Abbildung 27
SCRIPT:
SELECT R.KEY, R.SOURCE, R.TYPE
FROM "TSTUSER"."RDL_RELATIONSHIPS" R inner join "TSTUSER"."MEMBERS" M on R.SOURCE=M.NAMEUnd mal sehen, wie lange es gedauert hat, diese Anfrage zu erfüllen (Abb. 28).
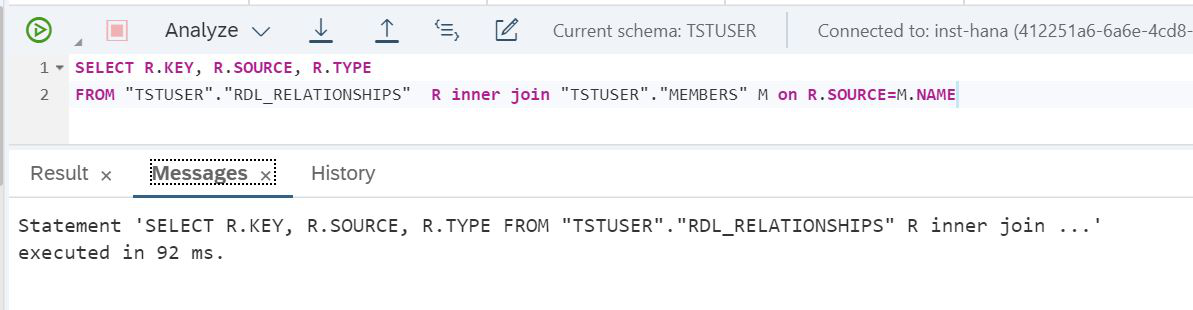
Abbildung 28
Wir können sehen, dass es 92 Millisekunden gedauert hat. Lassen Sie uns den Replikationsmechanismus aktivieren. Erstellen Sie dazu eine ALTER VIRTUAL TABLE der virtuellen Tabelle. Anschließend werden die Lake-Daten in den SAP HANA RAM repliziert.
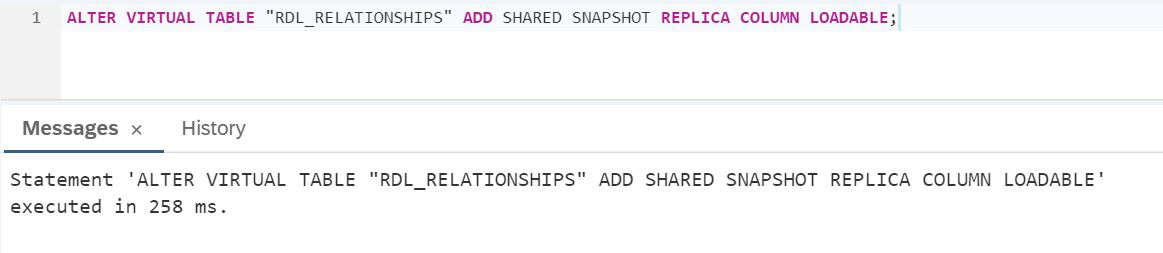
SKRIPT:
ALTER VIRTUAL TABLE "RDL_RELATIONSHIPS" ADD SHARED SNAPSHOT REPLICA COLUMN LOADABLE;Überprüfen wir die Ausführungszeit wie in Abbildung 29.

Abbildung 29
Wir haben 7 Millisekunden. Das ist ein tolles Ergebnis! Mit minimalem Aufwand haben wir die Daten in den RAM verschoben. Wenn Sie die Analyse abgeschlossen haben und mit der Leistung zufrieden sind, können Sie die Replikation erneut deaktivieren (Abb. 30).

Abbildung 30
SCRIPT:
ALTER VIRTUAL TABLE "RDL_RELATIONSHIPS" DROP REPLICA;Jetzt werden die Daten nur noch bei Bedarf wieder aus dem See geladen und der SAP-HANA-RAM ist frei für neue Aufgaben. Heute haben wir meiner Meinung nach eine interessante Arbeit geleistet und die SAP HANA Cloud auf die schnelle und einfache Organisation eines einzelnen Zugriffspunkts auf Daten getestet. Das Produkt wird sich entwickeln, und wir gehen davon aus, dass in naher Zukunft eine direkte Verbindung zum Datensee hergestellt werden kann. Die neue Funktion bietet eine schnellere Download-Geschwindigkeit für große Informationsmengen, die Ablehnung unnötiger Servicedaten und die Steigerung der Produktivität von Vorgängen, die für den Datensee spezifisch sind. Wir werden gespeicherte Prozeduren direkt in der Datenwolke mithilfe der SAP IQ-Technologie erstellen und ausführen, dh wir können die Verarbeitungs- und Geschäftslogik dort anwenden, wo sich die Daten selbst befinden.
Alexander Tarasov, Senior Business Architect SAP CIS