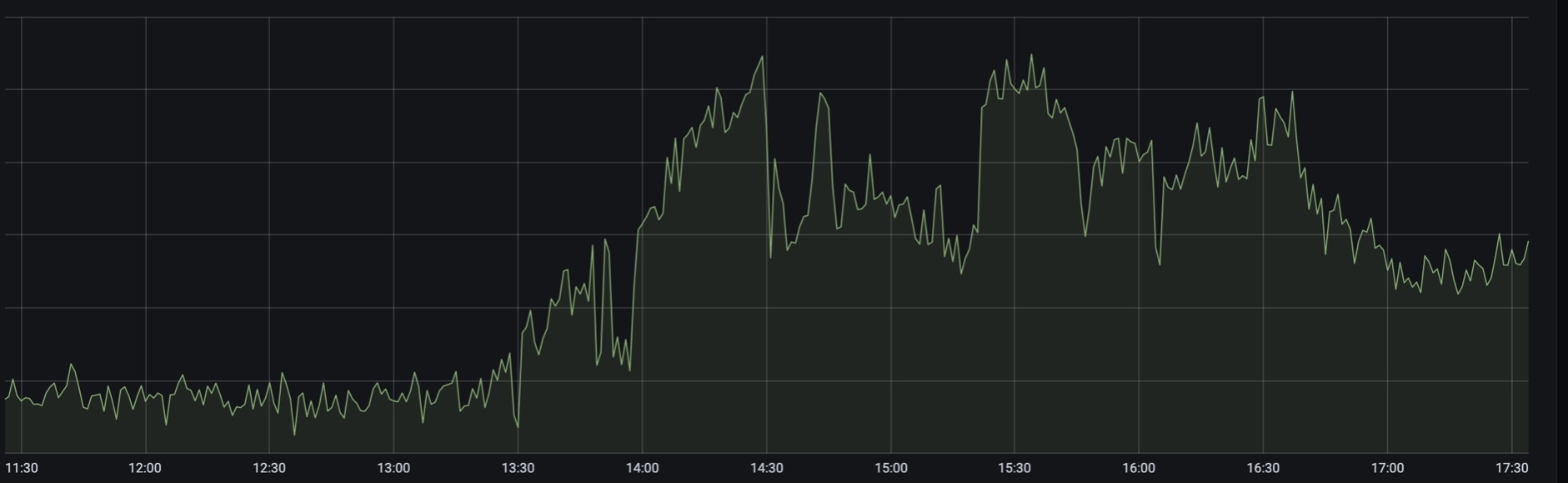
Gegen 13:30 Uhr nahm die Belastung für die Suche nach Luftfahrt und nach Bahntickets stark zu. Irgendwann in diesem Moment meldete die Russische Eisenbahn Unterbrechungen der Website und der Anwendung, und wir begannen dringend, zusätzliche Instanzen von Backends in alle Rechenzentren zu schütten.
Tatsächlich begannen die Probleme jedoch früher. Gegen 8 Uhr morgens schickte die Überwachung eine Warnung darüber, dass wir auf einem der Datenbankreplikate verdächtig viele langlebige Prozesse haben. Aber wir haben es verpasst, weil es nicht sehr wichtig war.
Einleitend
Unsere Infrastruktur ist in fast zwanzig Jahren Entwicklungszeit erheblich gewachsen. Anwendungen leben auf drei Plattformen - der alte PHP-Code in einem Monolithen , die erste Version von Microservices befindet sich auf einer Plattform mit selbst erstellter Orchestrierung, die zweite, strategisch korrekte, ist OKD, wo gehen, PHP- und NodeJS-Dienste leben. Um all dies herum gibt es Dutzende von MySQL-Basen mit einer Bindung für HA - die Haupt- "Girlande", die dem Monolithen dient, und viele Master-Hotstandby-Paare für Microservices. Darüber hinaus sind Memkesh, Kafkas, Mongas, Radieschen und Gummibänder weit von einer einzigen Kopie entfernt. Nginx und Gesandter als Frontproxy . Das Ganze lebt an drei Netzwerkstandorten und wir gehen davon aus, dass der Verlust eines dieser Standorte keine Auswirkungen auf die Benutzer hat.
-: mysql
Wir haben drei geladene Produkte. Der Fahrplan der Züge, in denen nur viel Verkehr herrscht. Der Eisenbahnfahrplan für Fernzüge und der Kauf und die Buchung von Bahntickets - es gibt viel Verkehr und die Suche ist schwieriger. Luftfahrt mit sehr schwierigen Suchvorgängen, mehrstufigem Cache, vielen Optionen aufgrund von Übertragungen und Gabeln "plus oder minus 3 Tage". Vor langer Zeit lebten alle drei Produkte nur in einem Monolithen, und dann begannen wir, einzelne Teile langsam in Microservices zu verschieben. Die ersten, die abgebaut wurden, waren die elektrischen Züge, und trotz der Tatsache, dass normalerweise der Höhepunkt im Mai auf sie fällt, ist die neue Architektur sehr praktisch und lässt sich leicht auf das Wachstum der Last skalieren. Im Falle der Luftfahrt wurde der größte Teil des Monolithen gestohlen, und genau zum Zeitpunkt des Tages P wurden seit einer Woche A / B-Tests der geografisch klügsten durchgeführt. Wir haben zwei Versionen der Implementierung verglichen - eine neue,auf elasticsearch und das alte mysql. Zum Zeitpunkt des Starts, am 15. April, hatten sie bereits eine Reihe von Problemen festgestellt, aber dann wurden sie schnell konzipiert, korrigierten den Code und beschlossen, dass er nicht erneut ausgelöst werden würde.
Schuss. Es sollte beachtet werden, dass die alte Version eine eigene Implementierung der Volltextsuche und des Rankings auf MySQL ist. Nicht die beste Lösung, aber erprobt und meistens funktionsfähig. Probleme beginnen, wenn eine der Tabellen stark fragmentiert ist, dann verlangsamen sich alle Abfragen mit ihrer Beteiligung und laden das System stark. Und natürlich haben wir um 8 Uhr morgens diese Fragmentierungsschwelle überschritten, die von der Warnung gemeldet wurde. Die Standardreaktion auf eine so seltene, aber immer noch erwartete Situation besteht darin, ein langweiliges Replikat aus der Last zu nehmen (mit unserer Proxy-Schicht von proxysql ist dies einfach), dann optimieren + analysieren und dann zurückgeben. Unter Berücksichtigung der Gangreserve während normaler Zeiten unter normaler Last führt dies zu keinen Problemen. Aber hier, in einer ruhigen Zeit, haben wir diese Warnung nicht verarbeitet.
13:20
Um diese Zeit klingen die Nachrichten über die Mai-Feiertage und arbeitsfreien Tage.
Spitzenverkehr gegen 13:30 Uhr
Wie wir später herausfanden, begann der Verkehr nur wenige Minuten nach der Ankündigung des zusätzlichen Wochenendes (das kein Wochenende, sondern ein „Wochenende“ ist) zu wachsen. Die Ladung ging abrupt. Auf dem Höhepunkt war es 2,5 - 3 Mal von der Norm entfernt, und dies dauerte mehrere Stunden.
Wir wurden fast sofort mit „Notfallwarnungen“ bombardiert - Warnungen der Kritikalitätsstufe „Aufwachen und Beheben“. Zunächst war es eine Warnung über das Wachstum von 50 * -Fehlern, die wir von unserem Frontproxy an Kunden senden. Auf einer niedrigeren Ebene wurde eine Warnung für Datenbankverbindungsfehler ausgelöst, und in den Protokollen wurde Folgendes angezeigt: "DB: Maximales Verbindungszeitlimit beim Erreichen der Hostgruppe 102 nach 3162 ms erreicht". Plus Warnungen über den Kapazitätsmangel auf den drei Gruppen von Anwendungsservern der alten monolithischen Plattform. Alarmsturm in seiner reinsten Form.
Die Idee der Gründe kam fast augenblicklich, noch bevor der Zeitplan mit eingehenden Anfragen eingegeben wurde - die Nachrichten über den "Urlaub" waren bereits in der internen Korrespondenz in den Chats geflasht.
Nachdem sie in einer fast vollständigen Achtung-Situation ein wenig zur Besinnung gekommen waren, begannen sie zu reagieren. Skalieren Sie Anwendungsserver und behandeln Sie Fehler an der Schnittstelle zwischen Anwendung und Basis. Wir erinnerten uns schnell an die Warnung, die am Morgen „gebrannt“ hatte, und fanden unsere alten Bekannten aus dem geografischen Traurigen in der Prozessliste der kranken Bemerkung. Wir haben das Avia-Team kontaktiert und sie haben bestätigt, dass das Verkehrswachstum in den letzten April-Tagen, das in den letzten 15 Jahren nicht einmal annähernd erreicht wurde, real ist. Und dies ist kein Angriff, kein Ausgleichsproblem, sondern ein natürlicher Live-Benutzer. Und unter ihren lebhaften Anfragen wurde unser bereits überladenes Replikat völlig unwohl.
Alexey, unser DBA, nahm das Replikat aus der Last, nagelte langlebige Prozesse und folgte dem Standardverfahren zur Tabellenoptimierung. Das ist alles schnell, ein paar Minuten, aber während dieser Zeit wurden die verbleibenden Repliken unter diesem Verkehr noch schlimmer. Wir haben das verstanden, aber wir haben es als das geringste Übel gewählt.
Fast parallel dazu, gegen 13:40 Uhr, wurden neue Anwendungsserver ausgeschüttet, wobei erkannt wurde, dass diese Last nicht von selbst schnell verschwindet, sondern wachsen kann und der Prozess selbst für den monolithischen Teil nicht sehr schnell.
Basismanipulation half für eine Weile. Von ca. 13:50 bis 14:30 Uhr war alles ruhig.
Zweiter Gipfel - gegen 14:30 Uhr
In diesem Moment teilte uns die Überwachung mit, dass die Website der Russischen Eisenbahn nicht erreichbar war. Nun, das heißt, er sagte, dass die Zug-Backends schlechter wurden, und wir erfuhren später von Russian Railways, als die Nachricht herauskam . In Echtzeit sah es für uns so aus.

Die Belastung scheint mit Unterbrechungen auf der Website der Russischen Eisenbahn zu zusammenhängen
. Leider leben die Züge meist noch in einem Monolithen und können nur auf Anwendungsebene durch Hinzufügen neuer Backends skaliert werden. Und dies ist, wie ich oben schrieb, ein langsamer Vorgang und schwer zu beschleunigen. Daher musste nur noch gewartet werden, bis die bereits gestartete Automatik funktionierte. In Microservices ist natürlich alles viel einfacher, aber der Umzug selbst ... obwohl das eine andere Geschichte ist.
Das Warten war nicht langweilig. In ungefähr 5 Minuten "drückte" der Engpass des Systems auf eine noch nicht ganz klare Weise von der Anwendungsschicht auf die Datenbankschicht, entweder auf die Basis selbst oder auf proxysql. Und um 14:40 Uhr hatten wir das Schreiben in den Haupt-MySQL-Cluster vollständig eingestellt. Was genau dort passiert ist, haben wir noch nicht herausgefunden, aber der Wechsel des Masters in die Hotstandby-Reserve hat geholfen. Und nach 10 Minuten gaben wir die Aufzeichnung zurück. Etwa zur gleichen Zeit beschlossen sie, die gesamte Ladung gewaltsam vom Sadget auf das Gummiband zu übertragen, um die Ergebnisse der AB-Kampagne zu opfern. Wie sehr es half, wurde ihnen auch nicht klar, aber es wurde sicherlich nicht schlimmer.
15:00
Die Aufnahme wurde zum Leben erweckt, es scheint, dass alles in Ordnung sein sollte, und die Belastung der Replikate und des Proxysql vor ihnen ist normal. Aus irgendeinem Grund werden Fehler bei Leseanforderungen von der Anwendung an die Datenbank nicht beendet. In etwa 15 bis 20 Minuten, in denen wir uns an Diagramme auf verschiedenen Ebenen gehalten und nach mindestens einigen Mustern gesucht haben, haben wir festgestellt, dass Fehler nur von einem Proxy-SQL stammen. Starten Sie es neu und die Fehler waren weg. Die Grundursache wurde viel später mit einer detaillierten Analyse des Fehlers ausgegraben. Es stellte sich heraus, dass während des letzten Notfalls, eine Woche zuvor, zu Beginn der AB-Kampagne über Sagest, Proxysql die Verbindungen zu einer der Repliken der Girlande, die dann manipuliert wurde, nicht korrekt geschlossen hat. Und auf dieser Instanz von proxysql sind wir dumm auf einen Mangel an Ports für ausgehenden Verkehr gestoßen. Diese Metrik wird es natürlich tun, aber es ist uns nie in den Sinn gekommen, eine Warnung darauf zu legen. Jetzt ist es schon da.
15:20
Alle Produkte außer Zügen wurden restauriert.
15:50
Die letzten Zug-Backends wurden erweitert. Normalerweise dauert es nicht zwei Stunden, sondern eine Stunde, aber hier haben sie selbst in einer stressigen Situation ein wenig durcheinander gebracht.
Wie so oft wurde es an einer Stelle repariert, an einer anderen kaputt. Backends akzeptierten mehr Verbindungen, Front-Proxys löschten Client-Anfragen aufgrund des Überlaufs von Upstreams weniger, wodurch der interne dienstübergreifende Verkehr zunahm. Und es gab einen Autorisierungsdienst. Dies ist ein Microservice, jedoch nicht in OKD, sondern auf einer alten Plattform. Dort ist die Skalierung einfacher als bei Monolithen, aber schlechter als bei OKD. Wir haben es für ungefähr 15 Minuten angehoben, die Parameter mehrmals gedreht und Kapazitäten hinzugefügt, aber am Ende hat es auch funktioniert.
16:10
Hurra, alles funktioniert, du kannst zum Mittagessen gehen.
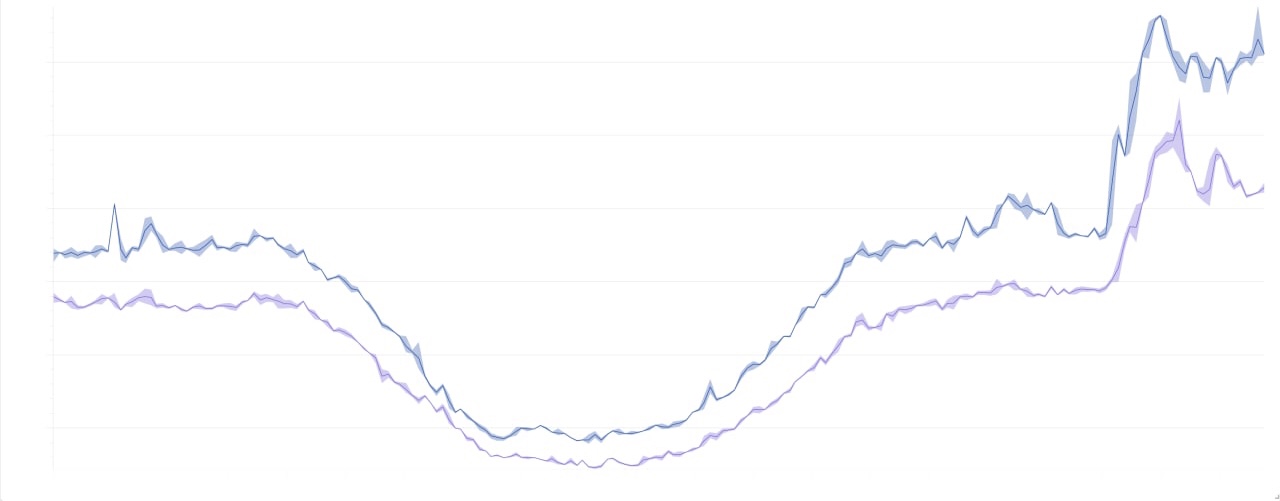
Schöne Bilder
Sie sind wunderschön, weil sie nicht vollständig informativ sind, aber die Achsen wurden vom Sicherheitsrat nicht getestet.
Grafik der 500er:

Das allgemeine Bild der Ladung für 2 Tage:
Schlussfolgerungen des Kapitäns
- Danke, dass du heute Nacht nicht bist.
- Sie müssen etwas gegen Warnungen unternehmen. Es gibt bereits viele von ihnen, aber einerseits ist es manchmal immer noch nicht genug, und andererseits sind einige ausverkauft, auch wegen der Menge. Und die Supportkosten steigen mit jeder neuen Warnung. Im Allgemeinen gibt es immer noch ein Verständnis für das Problem, aber es gibt keine strategische Lösung. Es versteckt sich irgendwo an der Schnittstelle von Prozessen und Werkzeugen, die wir suchen. Aber wir haben bereits einige Warnungen taktisch angegangen.
- . , - proxysql , . , .
- , OKD . .
- . , , , .