Einführung
Bei der Bearbeitung von Problemen mit maschinellem Lernen mit Online-Daten müssen verschiedene Einheiten zur weiteren Analyse und Bewertung zu einer Einheit zusammengefasst werden. Der Erfassungsprozess sollte bequem und schnell sein. Es sollte auch häufig einen nahtlosen Übergang von der Entwicklung zur industriellen Nutzung ohne zusätzlichen Aufwand und Routinearbeiten ermöglichen. Sie können den Feature Store-Ansatz verwenden, um dieses Problem zu beheben. Dieser Ansatz wird hier ausführlich beschrieben : Lernen Sie Michelangelo kennen: Ubers Plattform für maschinelles Lernen . Dieser Artikel beschreibt, wie die angegebene Feature-Management-Lösung als Prototyp interpretiert wird.
Feature Store für Online-Streaming
Der Feature Store kann als Dienst angesehen werden, der seine Funktionen streng gemäß seiner Spezifikation ausführen muss. Vor dem Definieren dieser Spezifikation sollte ein einfaches Beispiel zerlegt werden.
Beispiel
Lassen Sie die folgenden Entitäten angegeben werden.
Ein Film mit einer ID und einem Titel.
Filmbewertung, die auch eine eigene Kennung, Filmkennung und einen eigenen Bewertungswert hat. Die Bewertung ändert sich im Laufe der Zeit.
Bewertungsquelle, die auch eine eigene Bewertung hat. Und es ändert sich im Laufe der Zeit.
Und Sie müssen diese Entitäten zu einer kombinieren.
Folgendes passiert:
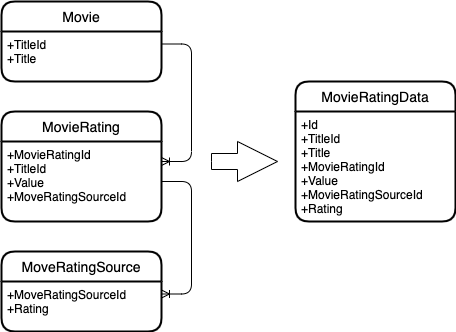
Entitätsdiagramm
Wie Sie sehen können, basiert die Zusammenführung auf Entitätsschlüsseln. Jene. Alle Filmbewertungen werden nach einem Film durchsucht und alle Quellenbewertungen nach einer Filmbewertung.
Verallgemeinerung des Beispiels
, .
kafka-, : A, B… NN.
: AB, BCD… NM.
: Feature Stream Engine.
Feature Stream Engine kafka-, Feature Stream Store Feature Stream Center, .
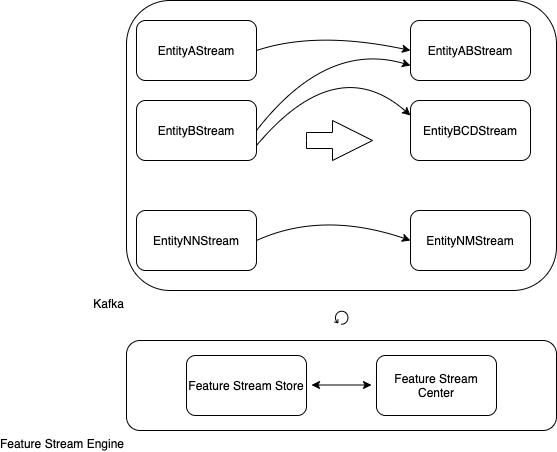
Feature Stream Engine
Feature Stream Store
, .
– (feature).
, , .
.
Feature Stream Center
, , .
Feature Stream Engine
Feature Stream Engine , .
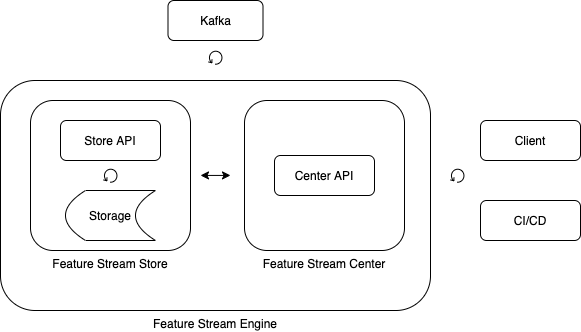
Feature Stream Engine
Feature Stream Engine
Feature Stream Engine , .
Feature Stream Engine .
.
kafka.
.
( ).
, .
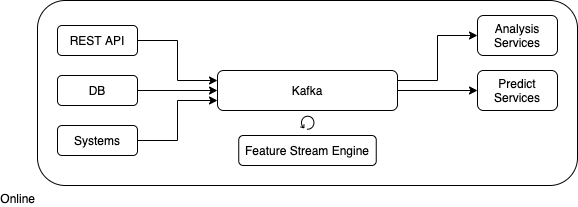
Feature Stream Engine
.
.
, ("configration.properties").
.
topic- kafka. “,”.
. “,”.
topic-.
, .
public static FeaturesDescriptor createFromProperties(Properties properties) {
String sources = properties.getProperty(FEATURES_DESCRIPTOR_FEATURE_DESCRIPTORS_SOURCES);
String keys = properties.getProperty(FEATURES_DESCRIPTOR_FEATURE_DESCRIPTORS_KEYS);
String sinkSource = properties.getProperty(FEATURES_DESCRIPTOR_SINK_SOURCE);
String[] sourcesArray = sources.split(",");
String[] keysArray = keys.split(",");
List<FeatureDescriptor> featureDescriptors = new ArrayList<>();
for (int i = 0; i < sourcesArray.length; i++) {
FeatureDescriptor featureDescriptor =
new FeatureDescriptor(sourcesArray[i], keysArray[i]);
featureDescriptors.add(featureDescriptor);
}
return new FeaturesDescriptor(featureDescriptors, sinkSource);
}
public static class FeatureDescriptor {
public final String source;
public final String key;
public FeatureDescriptor(String source, String key) {
this.source = source;
this.key = key;
}
}
public static class FeaturesDescriptor {
public final List<FeatureDescriptor> featureDescriptors;
public final String sinkSource;
public FeaturesDescriptor(List<FeatureDescriptor> featureDescriptors, String sinkSource) {
this.featureDescriptors = featureDescriptors;
this.sinkSource = sinkSource;
}
}
.
void buildStreams(StreamsBuilder builder)
topic-, , , .
Serde<String> stringSerde = Serdes.String();
List<KStream<String, String>> streams = new ArrayList<>();
for (FeatureDescriptor featureDescriptor : featuresDescriptor.featureDescriptors) {
KStream<String, String> stream =
builder.stream(featureDescriptor.source, Consumed.with(stringSerde, stringSerde))
.map(new KeyValueMapperSimple(featureDescriptor.key));
streams.add(stream);
}
.
KStream<String, String> pref = streams.get(0);
for (int i = 1; i < streams.size(); i++) {
KStream<String, String> cur = streams.get(i);
pref = pref.leftJoin(cur,
new ValueJoinerSimple(),
JoinWindows.of(Duration.ofSeconds(1)),
StreamJoined.with(
Serdes.String(),
Serdes.String(),
Serdes.String())
);
}
topic.
pref.to(featuresDescriptor.sinkSource);
.
public void buildStreams(StreamsBuilder builder) {
Serde<String> stringSerde = Serdes.String();
List<KStream<String, String>> streams = new ArrayList<>();
for (FeatureDescriptor featureDescriptor : featuresDescriptor.featureDescriptors) {
KStream<String, String> stream =
builder.stream(featureDescriptor.source, Consumed.with(stringSerde, stringSerde))
.map(new KeyValueMapperSimple(featureDescriptor.key));
streams.add(stream);
}
if (streams.size() > 0) {
if (streams.size() == 1) {
KStream<String, String> stream = streams.get(0);
stream.to(featuresDescriptor.sinkSource);
} else {
KStream<String, String> pref = streams.get(0);
for (int i = 1; i < streams.size(); i++) {
KStream<String, String> cur = streams.get(i);
pref = pref.leftJoin(cur,
new ValueJoinerSimple(),
JoinWindows.of(Duration.ofSeconds(1)),
StreamJoined.with(
Serdes.String(),
Serdes.String(),
Serdes.String())
);
}
pref.to(featuresDescriptor.sinkSource);
}
}
}
.
void run(Properties config)
( ).
FeaturesStream featuresStream = new FeaturesStream(config);
kafka.
StreamsBuilder builder = new StreamsBuilder();
featuresStream.buildStreams(builder);
Topology topology = builder.build();
KafkaStreams streams = new KafkaStreams(topology, featuresStream.buildStreamsProperties());
.
streams.start();
.
public static void run(Properties config) {
StreamsBuilder builder = new StreamsBuilder();
FeaturesStream featuresStream = new FeaturesStream(config);
featuresStream.buildStreams(builder);
Topology topology = builder.build();
KafkaStreams streams = new KafkaStreams(topology, featuresStream.buildStreamsProperties());
CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
streams.close();
latch.countDown();
}));
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
}
.
java -jar features-stream-1.0.0.jar -c plain.properties
: Java 1.8.
: kafka 2.6.0, jsoup 1.13.1.
. .
Erstens: Ermöglicht das schnelle Erstellen eines Themas zur Vereinigung.
Zweitens: Ermöglicht das schnelle Starten der Zusammenführung in verschiedenen Umgebungen.
Es ist anzumerken, dass die Lösung die Struktur der Eingabedaten einschränkt. Das Thema - und muss nämlich eine tabellarische Struktur haben. Um diese Einschränkung zu überwinden, können Sie eine zusätzliche Ebene einführen, mit der Sie verschiedene Strukturen auf eine tabellarische reduzieren können.
Für die industrielle Implementierung der vollen Funktionalität sollten Sie auf eine sehr leistungsfähige und vor allem flexible Funktionalität achten : KSQL .
Links und Ressourcen
Quellcode ;
Lernen Sie Michelangelo kennen: Ubers Plattform für maschinelles Lernen .