Während des Studiums des Kurses Algorithmen auf Strings stand ich vor dem Problem, einen Suffixbaum zu erstellen . Dem Link für zusätzliche Materialien folgend , stieß ich auf eine Empfehlung, "diesen wunderbaren Kommentar zu Stack Overflow anzuzeigen ". Nachdem Ukkonens Algorithmus gemäß der angegebenen freien Beschreibung studiert und implementiert hatte , entschied er sich, die Übersetzung zu teilen.
Das Folgende ist ein Versuch, den Ukkonen-Algorithmus zu beschreiben; Zeigen Sie zunächst, wie es mit einer einfachen Zeichenfolge funktioniert (d. h. die Zeichenfolge enthält keine doppelten Zeichen), und erweitern Sie sie schrittweise auf den vollständigen Algorithmus.
Einige vorläufige Aussagen:
Was wir bauen, ist im Grunde ein Präfixbaum . Dies ist der Wurzelscheitelpunkt, dessen Kanten zu neuen Scheitelpunkten führen und nachfolgende Kanten aus diesen herausgehen, und so weiter.
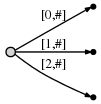
Aber , im Gegensatz zu einem Präfix - Baum, Kanten Etiketten sind nicht Einzelzeichen, für jede Kante ist die Markierung ein Paar von Nummern [von, bis] - Zeiger auf Stellen in dem Text. In diesem Fall enthält jede Kante eine Zeichenfolge beliebiger Länge, benötigt jedoch nur O (1) Speicher (zwei Zeiger).
Grundprinzip
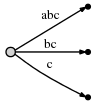
Zunächst möchte der Autor zeigen, wie ein Suffixbaum aus einer extrem einfachen Zeichenfolge erstellt wird, Zeichenfolgen ohne doppelte Zeichen:
abc
Der Algorithmus arbeitet schrittweise von links nach rechts . Ein Schritt pro Zeilenzeichen . Jeder Schritt kann mehr als eine einzelne Operation umfassen, aber wir werden sehen (siehe abschließende Beobachtungen am Ende), dass die Gesamtzahl der Operationen O (n) ist.
a
, [0, #]
- 0 . #
, , 1 ( a
).
, :
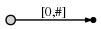
:

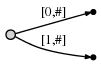
2 ( b
). : . :
a
-ab
b
:
:
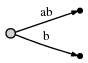
:
ab
, :[0, #]
. ,#
1 2.
O(1) , , , .
c
c
.
:
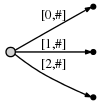
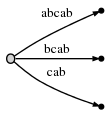
:
:
,
O(n),
#
, O(1). n, O(n)
:
, , . :
abcabxabcd
abc
, , ab
x
, abc
d
.
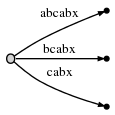
1 3: 3 :
4: #
4. :

a
.
, ( #
), , , , :
(_, _, _)
,
, :
abc
(, '\0x', 0)
, .._
,_
'0\x',_
. , , , .
1 . , , , 1 ( )
. a
, a
, : abca
. :
[3, #]
. ,a
. , - . , .
(, 'a', 1)
. , -a
, , 1 . ,a
. , ( , , ).
, 2
Spoiler
[4, #]
, , a
3
: , , , (
). , ( a
). , ( , O(1)), .
5: #
5. :
,
2, : ab
b
. - , :
a
. , ,
ab
.
b
.
, ( a
, abcab
), b
. : , b
.
, . :
(, 'a', 2)
( , ,b
)
3, , .
: ab
b
, ab
, b
. ? , ab
, ( b
) . , , , - , .
6, #
. :
3, abx
, bx
x
. , ab
, x
. , x
, abcabx
:

- , O(1).
, abx
2. bx
. , . , , 1, , _
( 3 ).
1, :
-
_
-
_
, , ..b
-
_
1
C, (, 'b', 1)
, bcabx
, 1 , b
. O(1) , x
. , . x
, , :
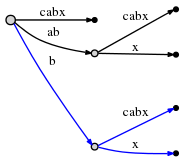
O(1),
1, (, 'x', 0)
, 1.
-. 2:
, , , , .
Spoiler
1 2
, , , , .
, . ( ):

, x
. _
0, . x
, :
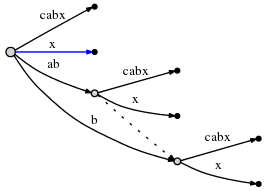
Spoiler
, .
7, #
= 7, , , a
. () , . , , (, 'a', 1)
.
Spoiler
#
, , #
8, #
= 8, b
, , , , (, 'a', 2)
, , b
. ( O(1)), . (1, '\0x', 0)
. 1
, ab
.
, #
= 9 'c', :
:
, #
c
, , , 'c'. , 'c' , (1, 'c', 1)
,
.
#
= 10
4, abcd
( 3 ), d
.
d
O(1):

_
, , .
3
_
, , , ,_
, . ,_
._
_
.
(2, 'c', 1)
, 2 :
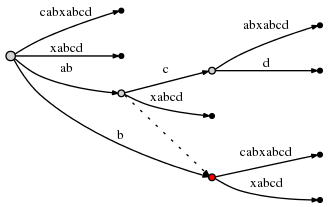
abcd
,
3 : bcd
. 3 , bcd
, d
.
, - 2 :
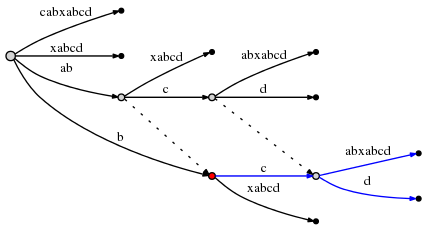
: , O(1). , , ab
b
( ), abc
bc
.
.
2, 3, . _
( ) , . (, 'c', 1)
.
, , c
: cabxabcd
, , c
. :
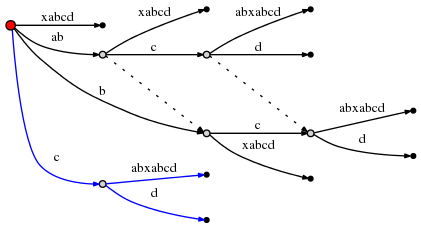
, 2 :
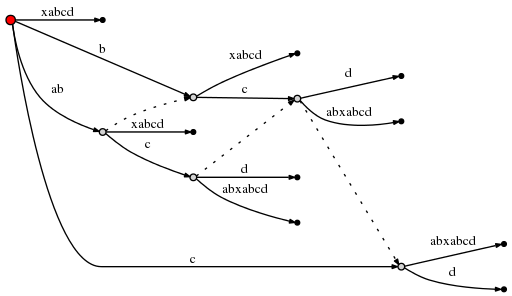
( Graphviz Dot . , , , , - )
1, _
, 1 (root, 'd', 0)
. , d
:
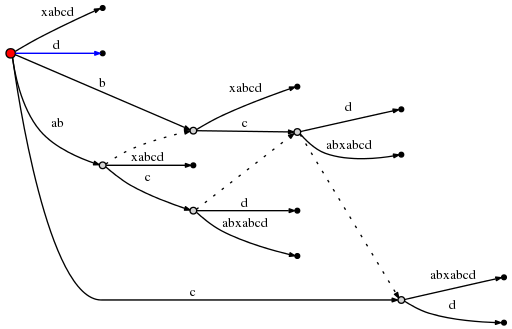
Spoiler
, . :
#
1 . O(1).
:
,
.
, . , #
. . : O(1), , , . ? ( , ).
, , , , ,
> 0. , , . , . ,
> 0, , .
Spoiler
,
> 0? , - , - . , . $
. ? → , , . , , .
- , , , . , , , .
? n , , n ( n + 1, ). ( ),
, O(1) .
, , , , , -, n ( n + 1). , O(n).
, : , , , , _
_
. , :
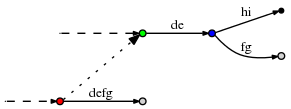
( . )
, (, 'd', 3)
, f
defg
. , , 3. (, 'd', 3)
. d
-, - de
, 2 . , , , (, 'f', 1)
.
_
,
, n. , , , , , n . , O(n2),
O(n), - _
O(n)?
. , (, , ), , , _
. , , , _
, , , , _
. _
,
,
O(n) , , -
O(n), O(n).
Anmerkungen des Übersetzers
Im Allgemeinen wird der Algorithmus in einer einfachen und verständlichen Sprache beschrieben. Nach der Beschreibung ist es möglich, sie zu implementieren, und natürliche Optimierungen werden im laufenden Betrieb durchgeführt. Ich habe die Stellen hervorgehoben, die mir mit Spoilern Schwierigkeiten bereiteten.
In meiner Implementierung wird das ACGT-Alphabet verwendet, da es das Ziel verfolgt, Tests für ein Problem innerhalb eines Kurses zu bestehen.