
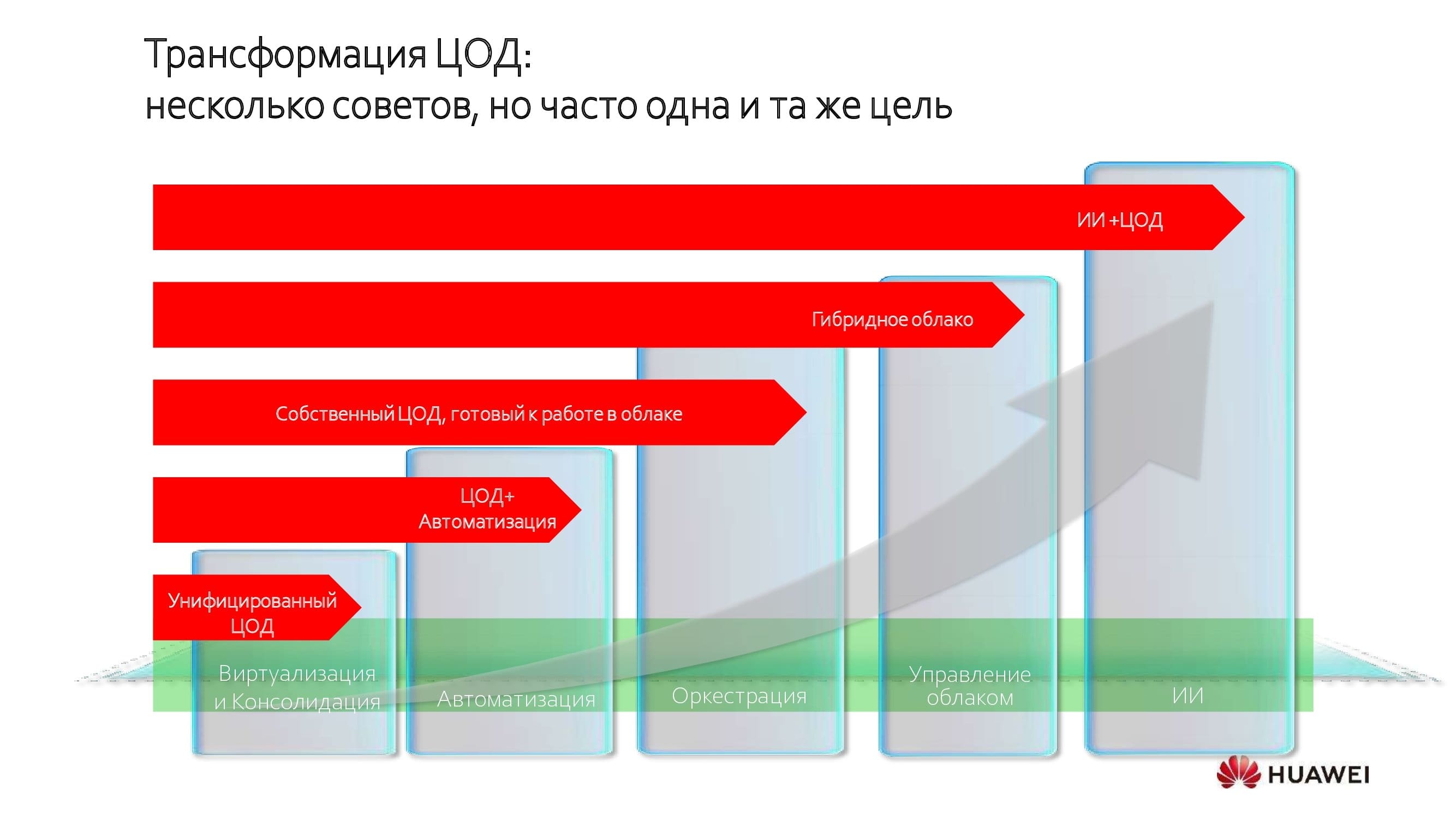
Transformation des Rechenzentrums
Rechenzentren ändern sich konzeptionell und dramatisch. Der Trend hat sich vor etwa zehn Jahren relativ verbreitet, aber beispielsweise im Bankensektor hat er viel früher begonnen. Unabhängig vom gewählten Weg sind die Ziele der Transformationen mehr oder weniger ähnlich - die Vereinheitlichung und Konsolidierung von Ressourcen.
Dies ist der erste Schritt, gefolgt von einer weiteren Verbesserung der Effizienz von Rechenzentren durch Automatisierung, Orchestrierung und Übergang zum Hybrid-Cloud-Modus. Und die am weitesten erreichbare Grenze der Transformation ist die Einführung künstlicher Intelligenzsysteme.
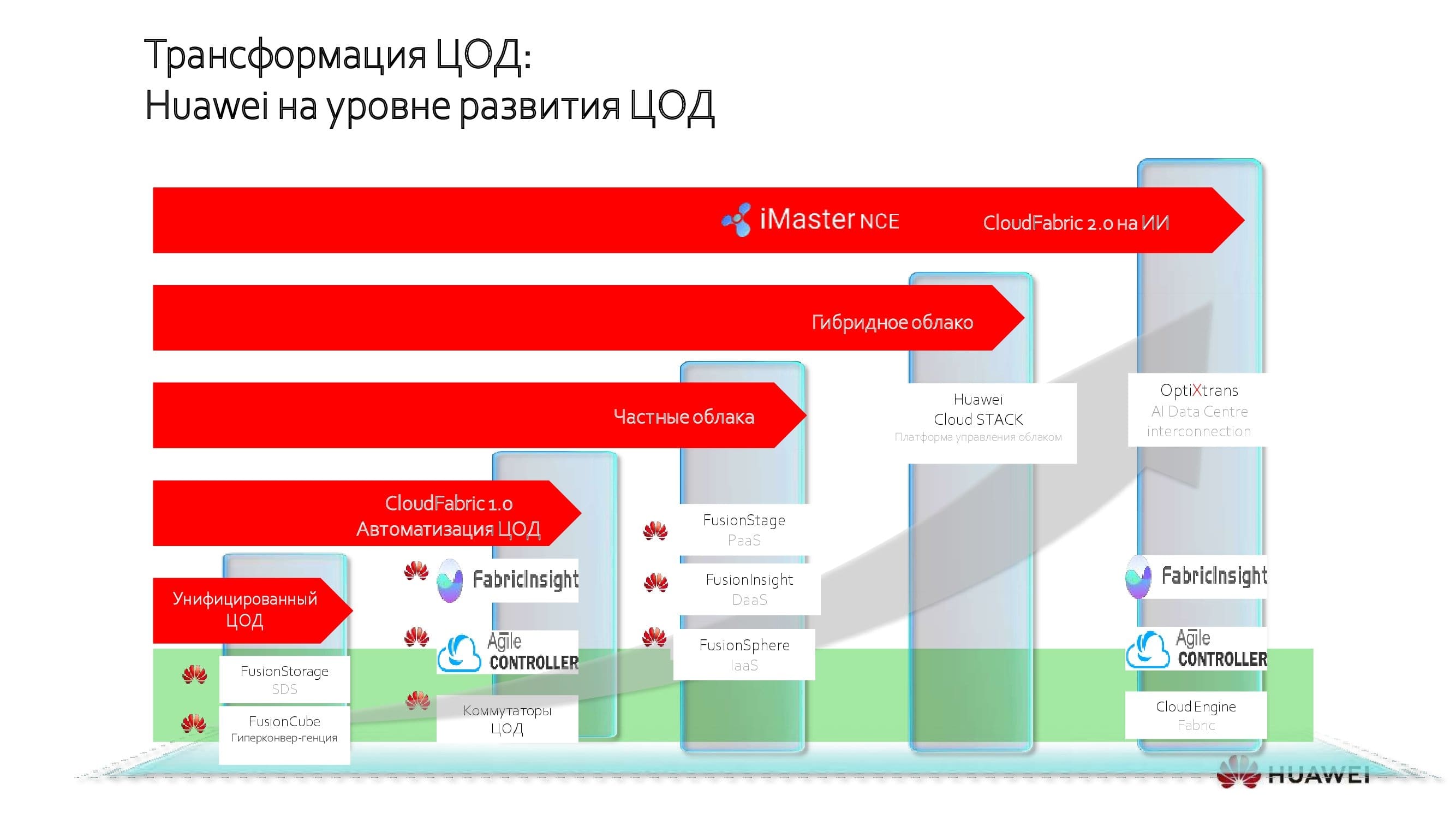
Huawei-Lösungen für jede Transformationsphase
In jeder Phase bietet Huawei abhängig von der "IT-Reife" des Kunden eigene Lösungen an, mit denen das beste Upgrade-Ergebnis ohne unnötige Kosten erzielt werden kann. Heute möchte ich ausführlicher auf das „i-Tüpfelchen“ eingehen - KI-Systeme in modernen Rechenzentren.

Um eine Analogie zum menschlichen Körper zu ziehen, fungieren Netzwerkschalter für Rechenzentren als Kreislaufsystem und stellen die Konnektivität zwischen verschiedenen Komponenten bereit: Rechenknoten, Datenspeichersysteme usw.
Noch vor wenigen Jahren war die SSD-Speichertechnologie weit verbreitet, und die CPU-Leistung wächst weiter. Damit sind Speicher- und Rechenknoten nicht mehr die Hauptursachen für Latenz. Das Rechenzentrumsnetzwerk ist jedoch seit langem als eine Art "kleiner Bruder" in der Struktur von Rechenzentren geblieben.
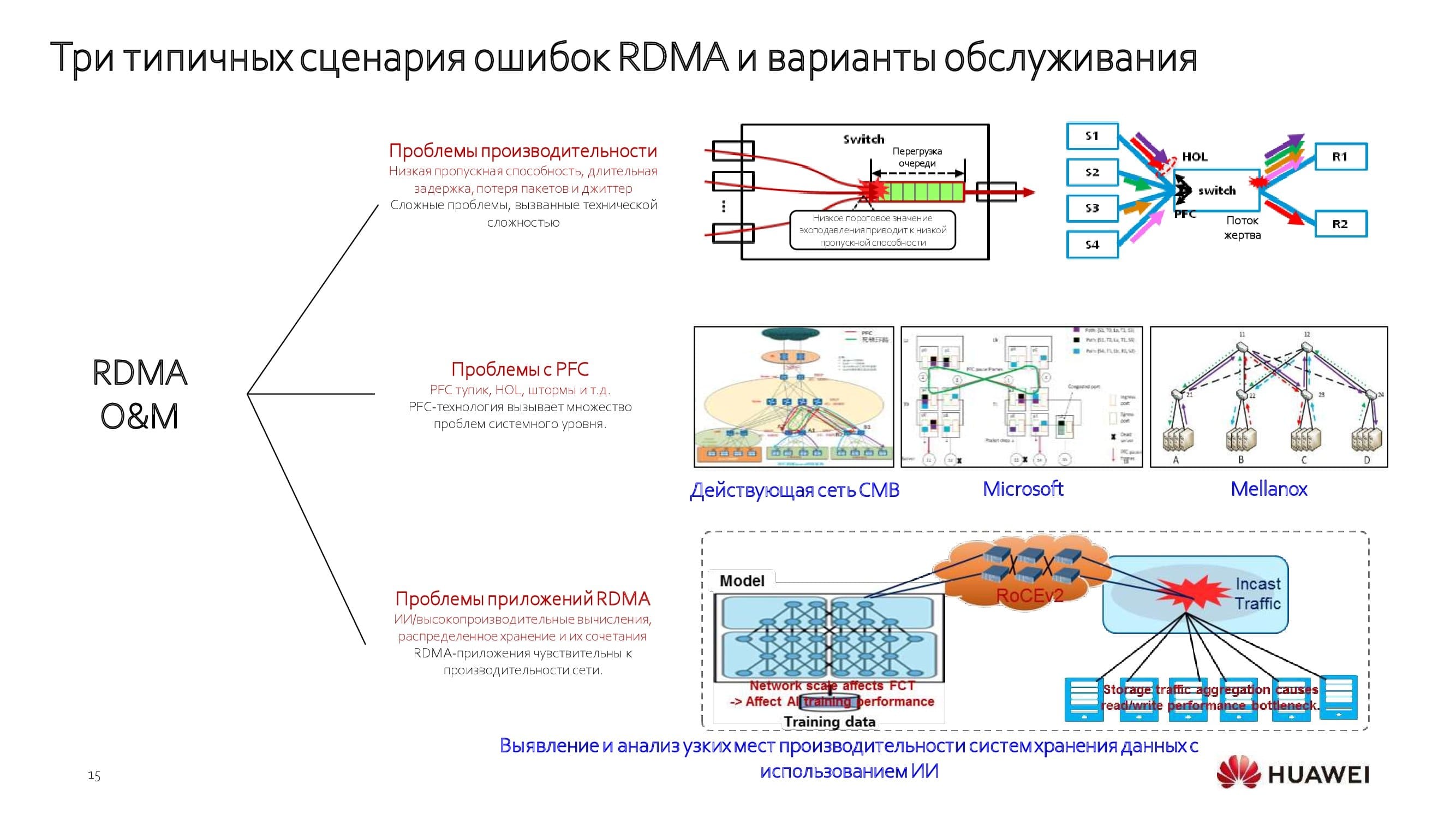
Die Hersteller haben versucht, das Problem auf verschiedene Weise zu lösen. Jemand entschied sich für lizenzierte InfiniBand (IB) -Technologien, um ein Netzwerk aufzubauen . Das Netzwerk erwies sich als spezialisiert und in der Lage, nur Aufgaben mit engem Profil zu lösen. Jemand zog es vor, Netzwerkfabriken mit Fibre Channel- Protokollen aufzubauen(FC). Beide Ansätze hatten ihre Grenzen: Entweder erwies sich die Netzwerkbandbreite als relativ gering, oder die Gesamtkosten der Lösung waren begrenzt, was durch die Abhängigkeit von einem Anbieter weiter verschärft wurde.
Unser Unternehmen setzte offene Technologien ein. Die Lösungen von Huawei basieren auf der zweiten Version von RoCE , deren Funktionen durch die Verwendung zusätzlicher lizenzierter Algorithmen in unseren Switches erweitert wurden. Dadurch konnten wir die Fähigkeiten der Netzwerke ernsthaft optimieren.
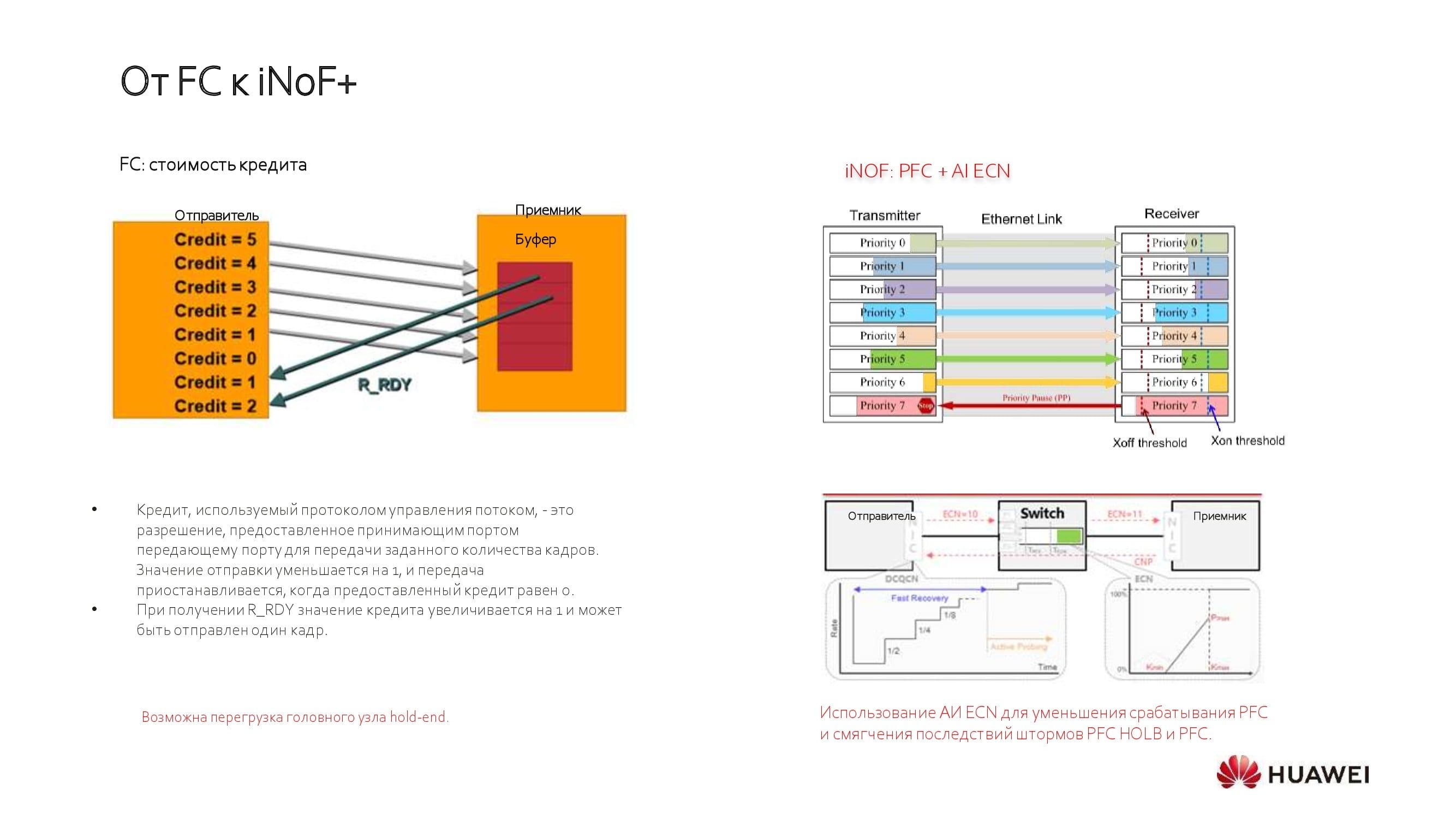
Warum sehen wir nicht die Zukunft hinter klassischen FC-Lösungen? Der Punkt ist, dass sie nach dem Prinzip der statischen Kreditvergabe arbeiten, bei dem die Netzwerkstruktur für einen begrenzten Zeitraum entsprechend den Anforderungen Ihrer Anwendungen konfiguriert werden muss.
Vor kurzem hat FC einen Schritt in Richtung eigenständiger Speichernetzwerke gemacht, weist jedoch weiterhin Leistungsbeschränkungen auf. Jetzt beginnt der Mainstream - die sechste Generation der Technologie, die einen Durchsatz von 32 Gbit / s und 64 Gbit / s ermöglicht, mit der Implementierung. Gleichzeitig können wir heute mithilfe von Ethernet mithilfe von Prioritätstabellen 100, 200 und sogar 400 Gbit / s auf den Server übertragen.
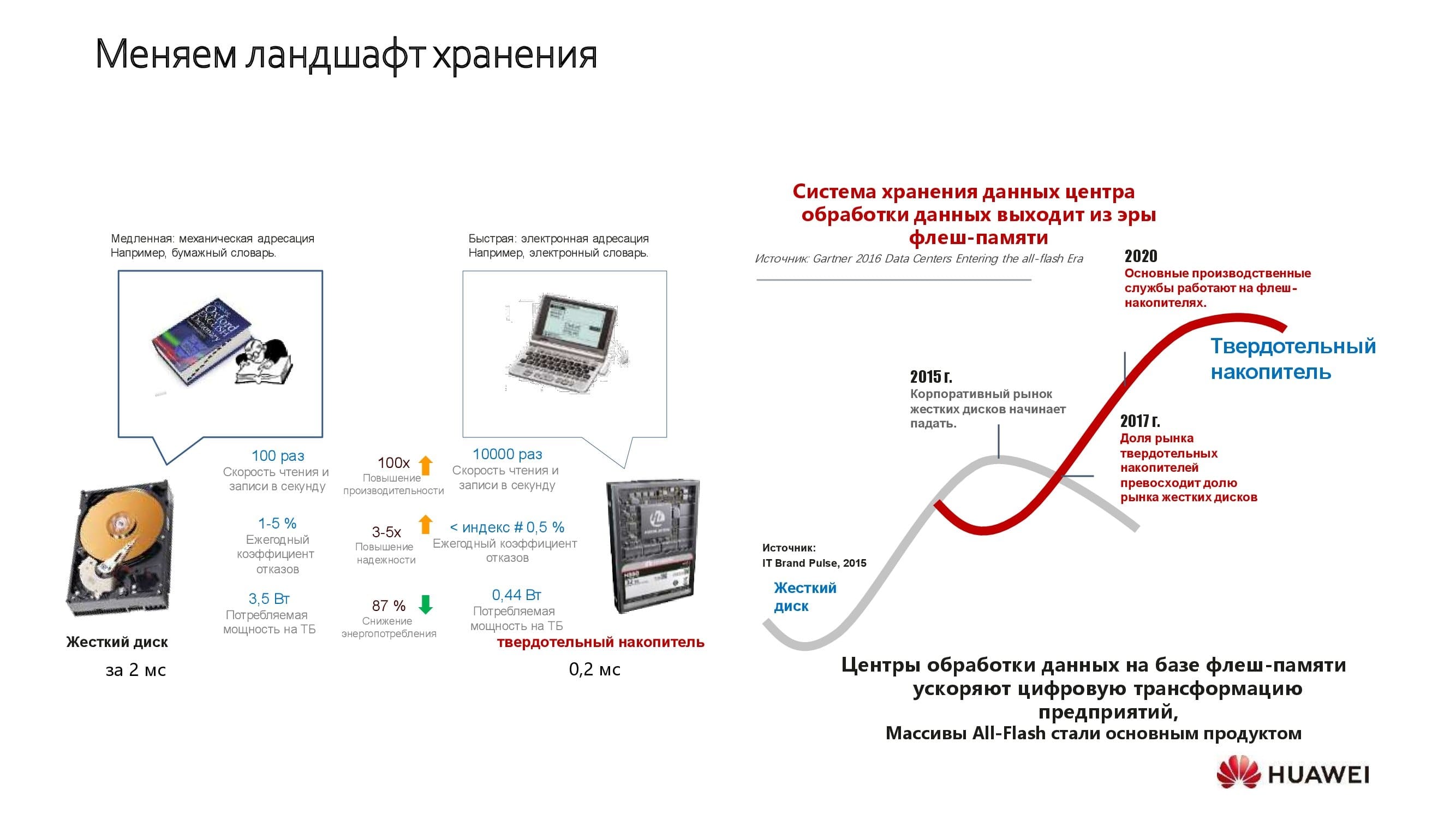
Der Mehrwert des Rechenzentrumsnetzwerks ist von besonderer Bedeutung in einer Welt, in der Solid-State-Laufwerke mit Hochgeschwindigkeitsschnittstellen mehr Marktanteile gewinnen und klassische Spindelantriebe verdrängen. Huawei setzt sich dafür ein, dass der SSD-Speicher sein volles Potenzial entfalten kann.
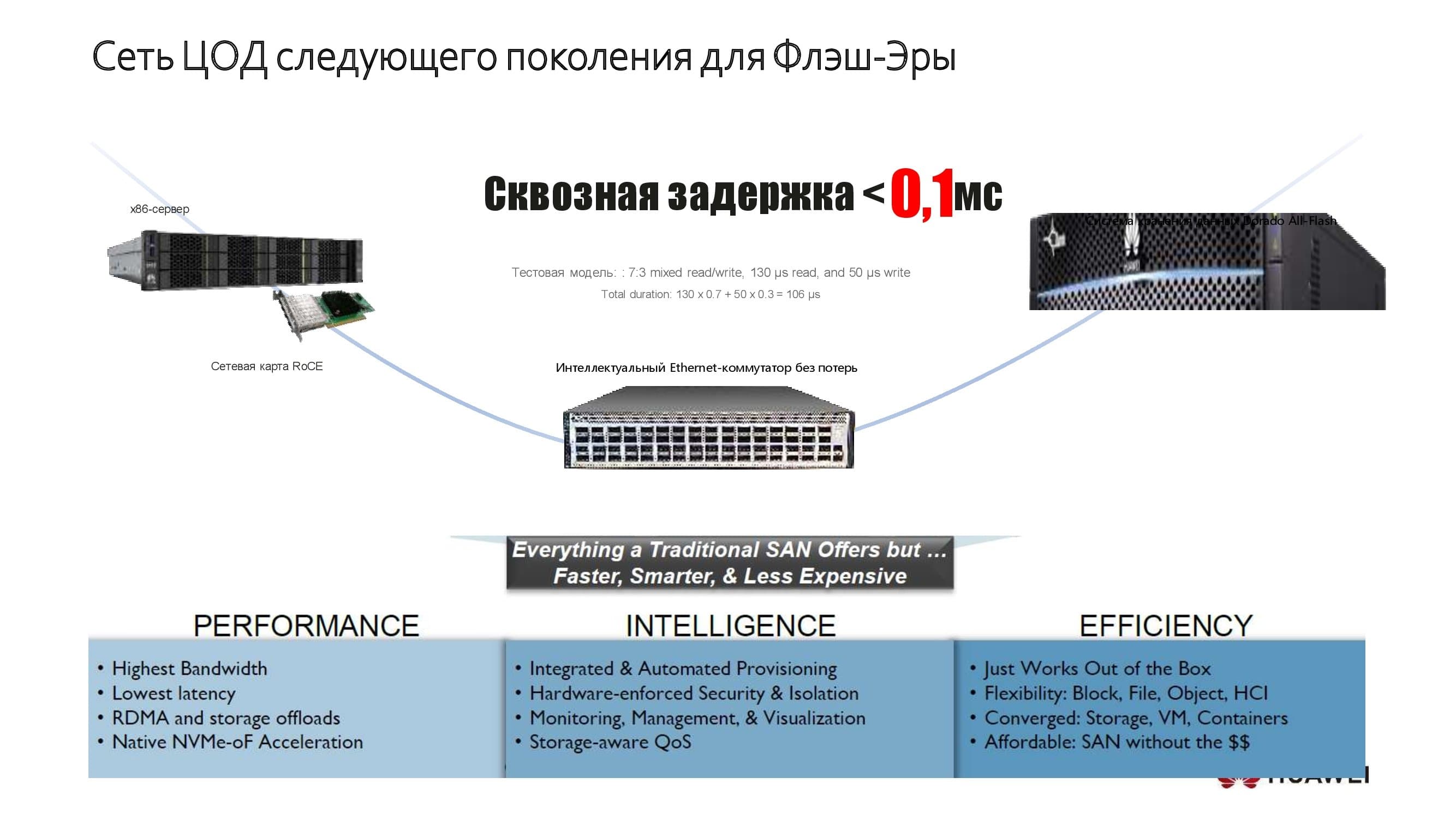
Rechenzentrumsnetzwerk der nächsten Generation
Ein kleines Beispiel dafür, wie wir es machen. Das Diagramm zeigt eines unserer Speichersysteme, das als das schnellste der Welt anerkannt ist. Hier sehen Sie unsere x86- oder ARM-basierten Server, die eine Leistung bieten, die die Erwartungen anspruchsvoller Kunden erfüllt. In Rechenzentren, die auf diesen Lösungen basieren, erreichen wir eine End- to- End-Latenz von nicht mehr als 0,1 ms. Der Einsatz neuer Anwendungstechnologien hilft uns, ein solches Ergebnis zu erzielen.
Die im Speicher verwendeten klassischen Technologien waren insbesondere durch die relativ hohen Latenzen begrenzt, die durch den SAS-Bus verursacht wurden. Durch die Umstellung auf neue Protokolle wie NVMe wurde dieser Parameter erheblich verbessert, und gleichzeitig wurde das Netzwerk selbst zu einem einschränkenden Leistungsfaktor.
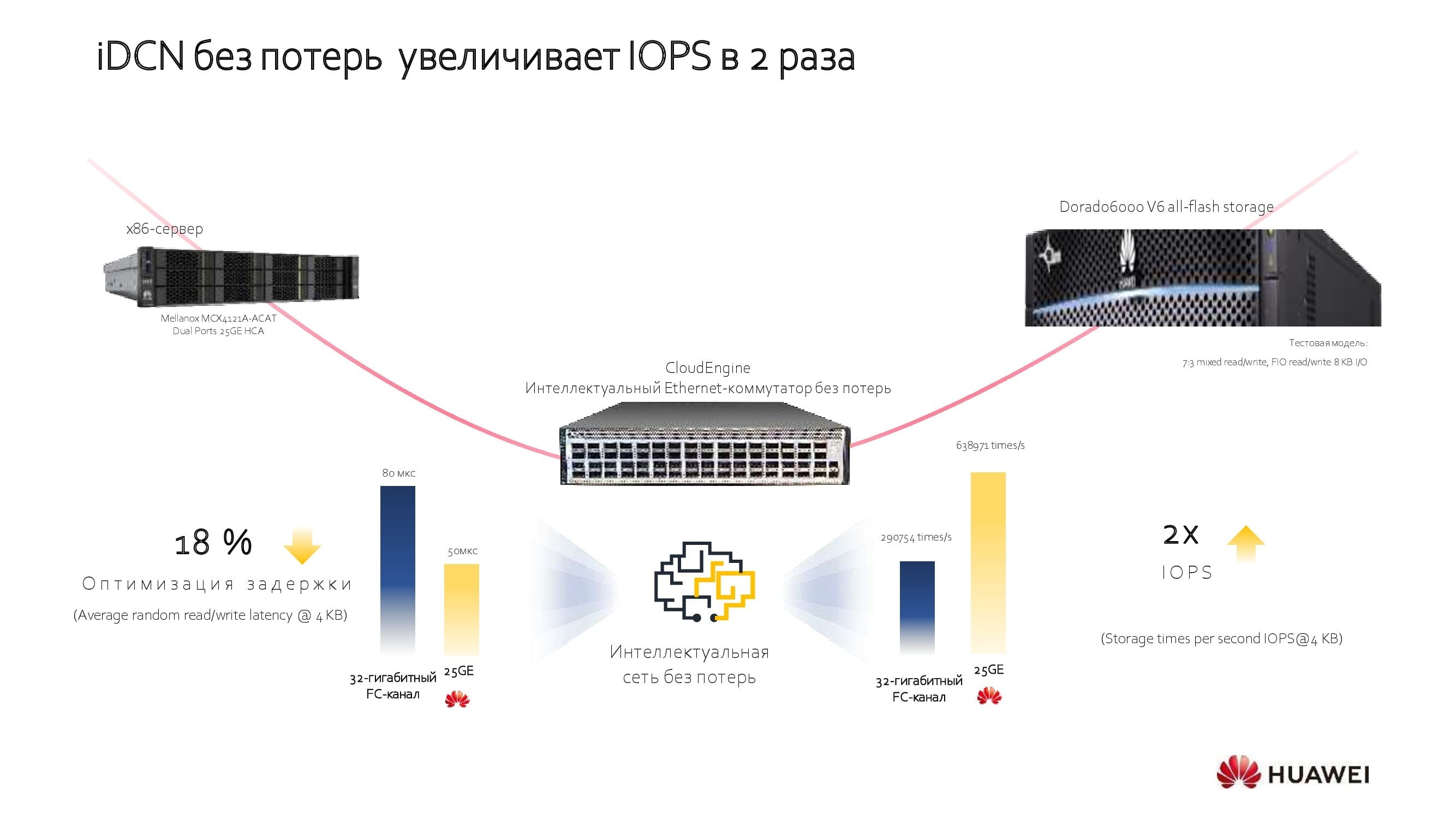
Betrachten Sie im selben Beispiel die Verwendung von Netzwerken mit zusätzlichen lizenzierten Algorithmen. Sie optimieren die End-to-End-Latenz, erhöhen den Netzwerkdurchsatz erheblich und erhöhen den E / A-Betrieb pro Zeiteinheit. Dieser Ansatz hilft, den "doppelten Kauf" zu vermeiden, der manchmal erforderlich ist, um die erforderlichen Leistungsparameter zu erreichen, und die Gesamteinsparungen (in Bezug auf die Gesamtbetriebskosten) bei der Einführung eines neuen Netzwerks erreichen 18-40%, abhängig von den verwendeten Gerätemodellen.
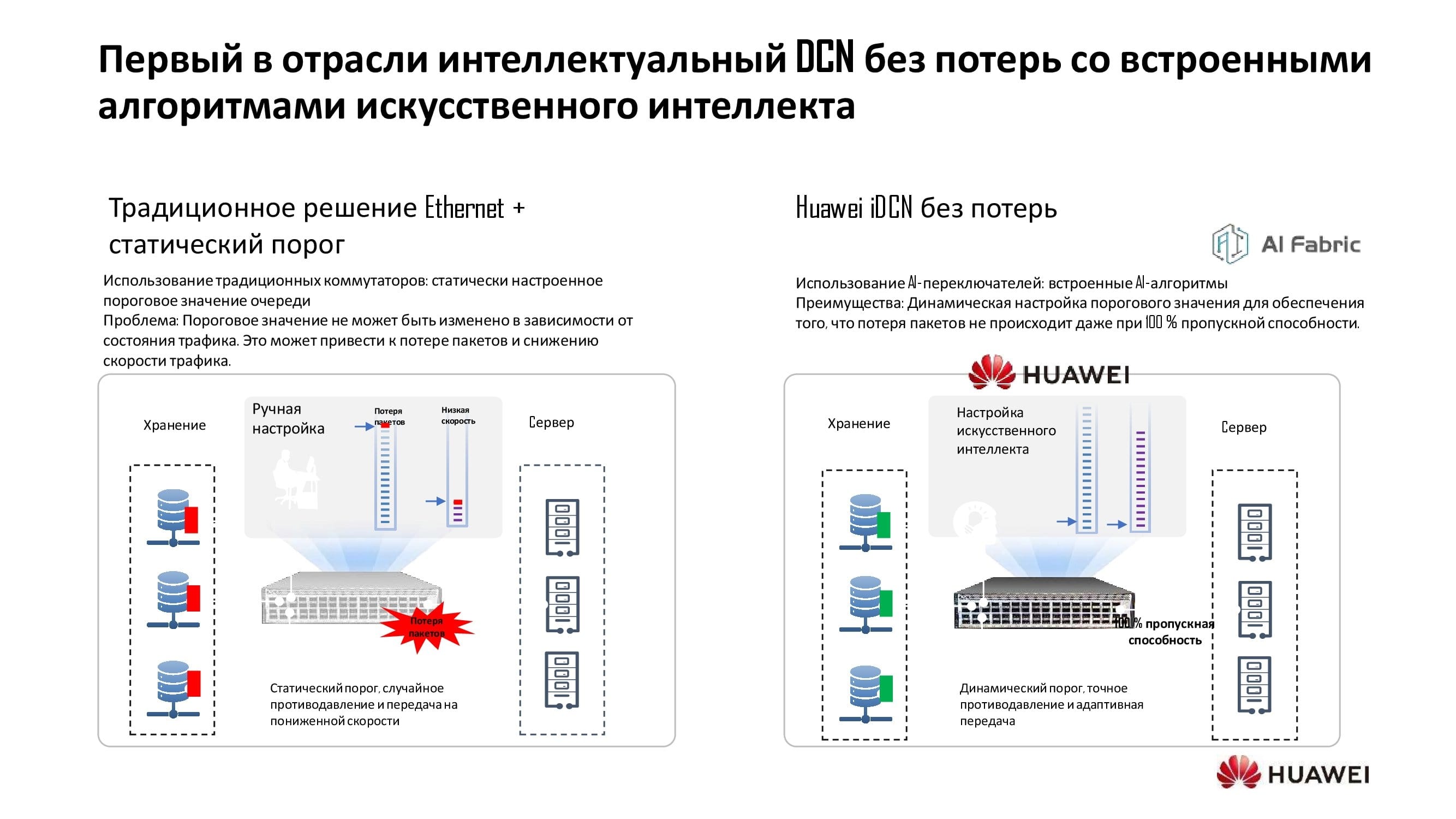
Was sind diese Wow-Algorithmen?
Herkömmliche Technologien brachten die üblichen Probleme mit sich, da sie mit statischen Schwellenwerten der Warteschlange arbeiteten. Dieser Schwellenwert bedeutete, dass für alle Anwendungen eine grundlegende Beziehung zwischen Geschwindigkeit und Latenz bestand. Der manuelle Steuermodus ermöglichte keine dynamische Anpassung der Netzwerkparameter.
Mithilfe zusätzlicher Chipsätze für maschinelles Lernen in den Switches haben wir dem Netzwerk beigebracht, in einem Modus zu arbeiten, der den Aufbau intelligenter Rechenzentrumsnetzwerke ohne Paketverlust ermöglicht (wir haben es iDCN genannt ).
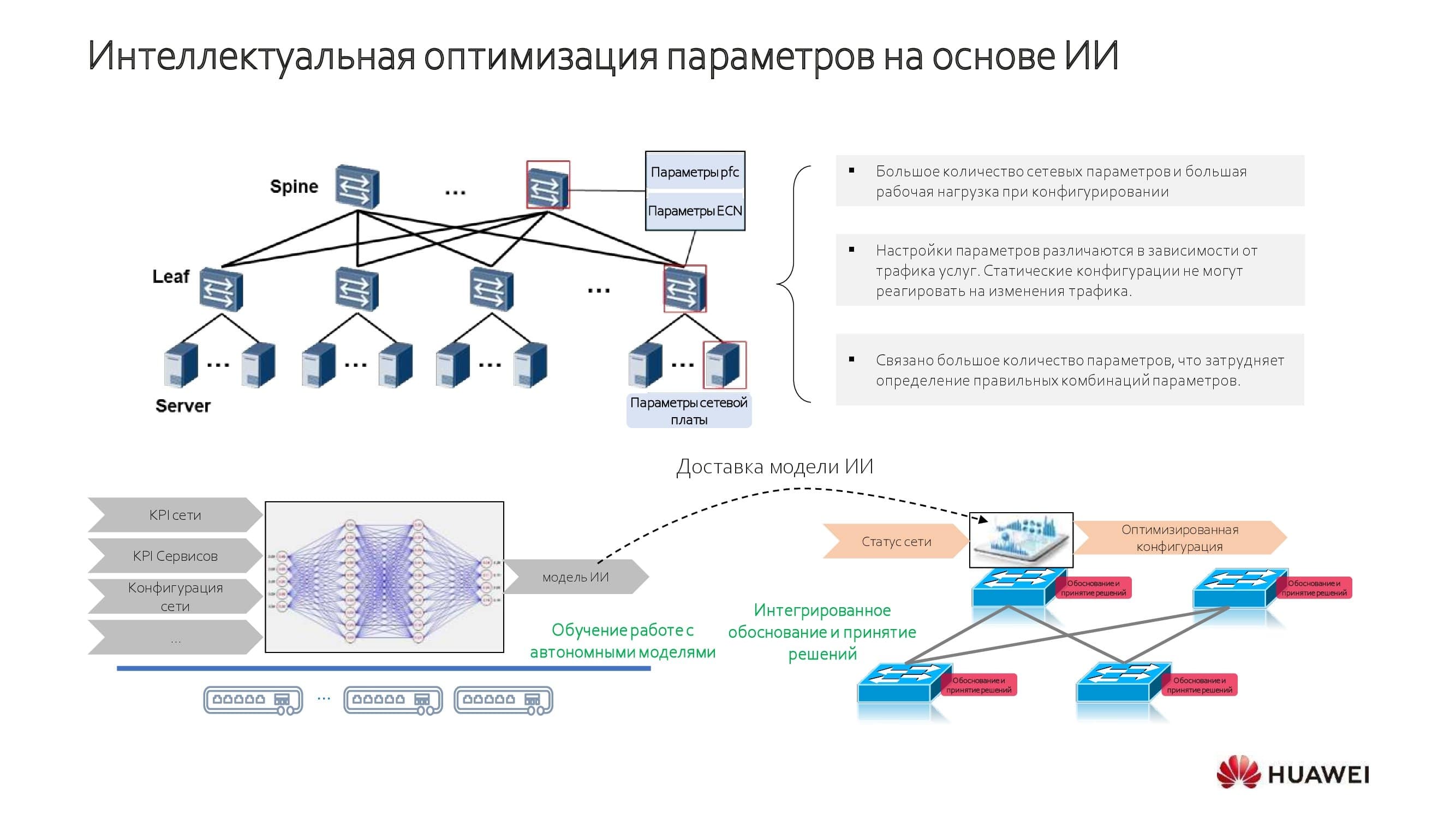
Wie wird eine intelligente Optimierung erreicht? Diejenigen, die sich mit neuronalen Netzen beschäftigen, finden im Diagramm leicht vertraute Elemente und Trainings- / Inferenzmechanismen. Unsere Lösungen kombinieren eingebettete Modelle mit der Fähigkeit, in einem bestimmten Netzwerk zu lernen.
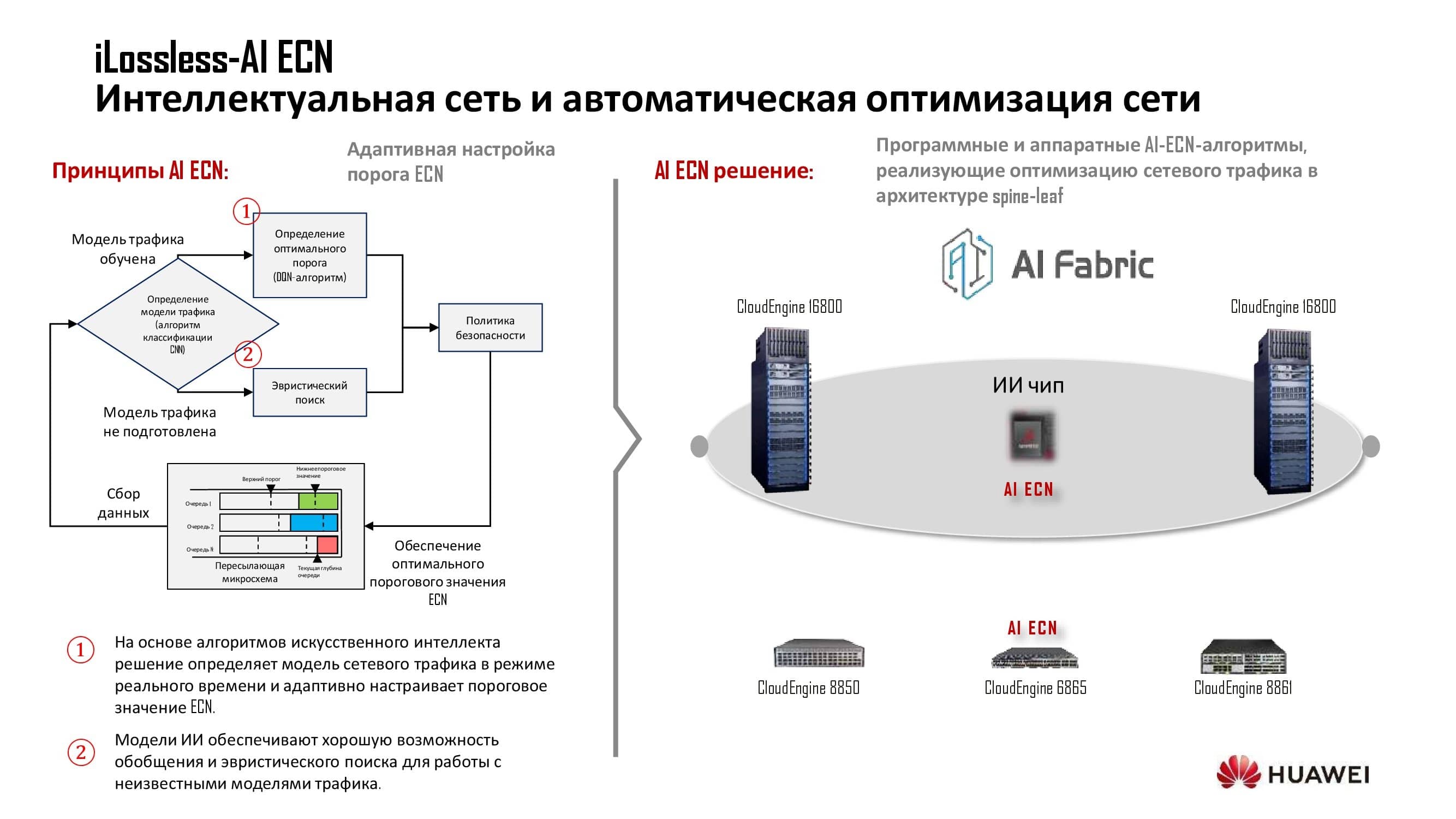
Das KI-System sammelt eine bestimmte Menge an Wissen über das Netzwerk, das dann angenähert und in der dynamischen Konfiguration des Netzwerks verwendet wird. Geräte, die auf unseren eigenen Hardwarelösungen basieren, verwenden einen speziellen AI-Chip. Modelle, die auf lizenzierten Chipsätzen amerikanischer Hersteller basieren, verwenden ein Zusatzmodul und einen Softwarebus.
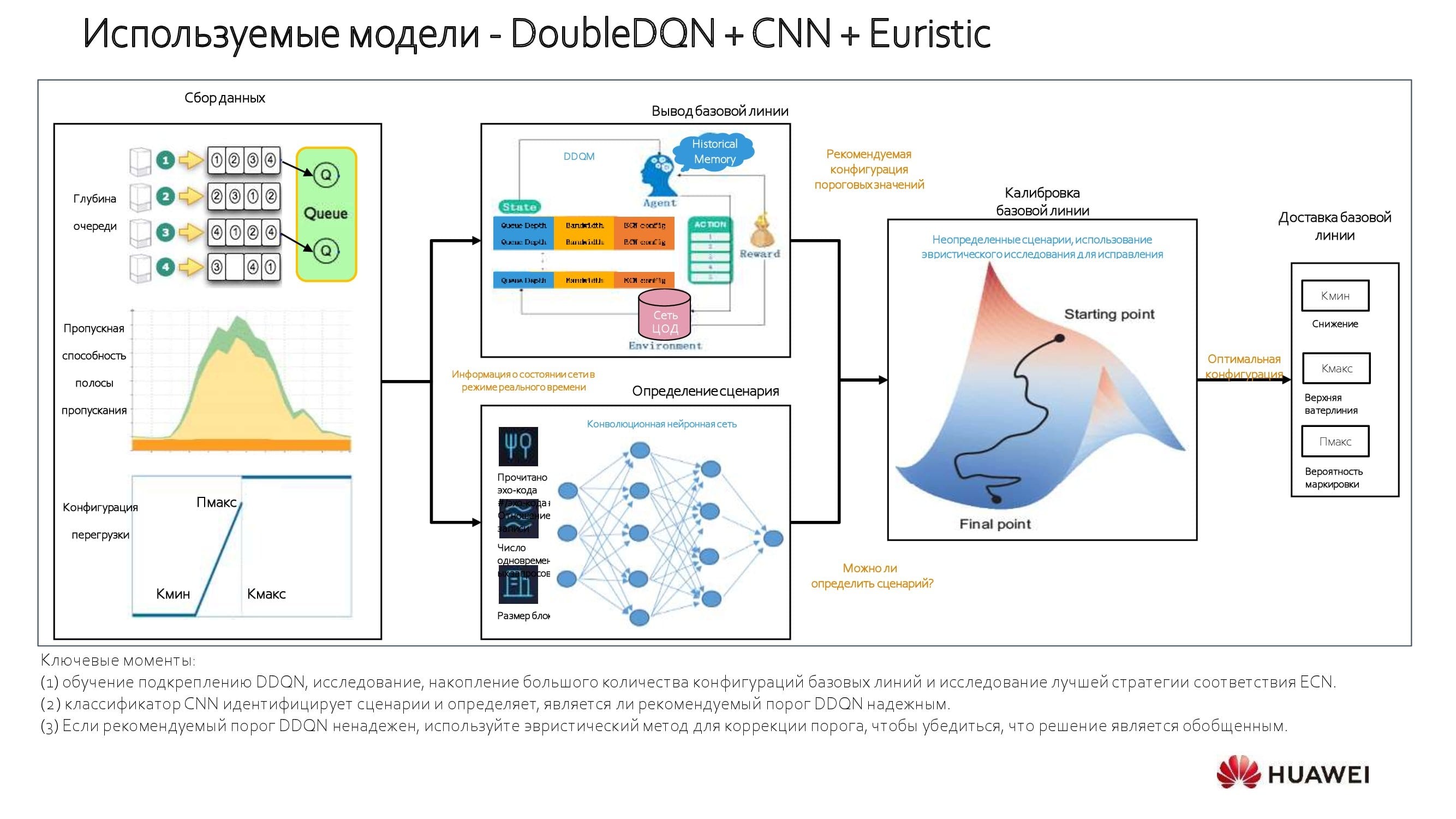
Über die angewandten Modelle. Wir verwenden einen Ansatz, der auf einem Modell des verstärkenden Lernens beruht. Das System analysiert 100% der Daten, die durch das Netzwerkgerät übertragen werden, und wählt die Basislinie aus. Wenn Sie beispielsweise die Bandbreite und die Verzögerungen kennen, die für eine bestimmte Anwendung kritisch sind, ist es nicht schwierig, die Basislinie zu bestimmen. Mit einer großen Anzahl von Anwendungen ist es möglich, „Median“ -Berechnungen durchzuführen und Anpassungen im automatischen Modus vorzunehmen, wodurch die Leistung erheblich gesteigert wird.

Das Diagramm zeigt den Vorgang detaillierter. Zu Beginn der Netzwerkoptimierung berechnen wir die minimalen und maximalen Schwellenwerte. Als nächstes kommt das Faltungsnetzwerk(CNN). Somit ist es möglich, die Bandbreiten- und Latenzraten für jede Anwendung auszugleichen und ihr Gesamtgewicht innerhalb der Netzwerkdienste zu bestimmen. Mit diesem geschichteten Ansatz erhalten wir einige wirklich interessante Einblicke.
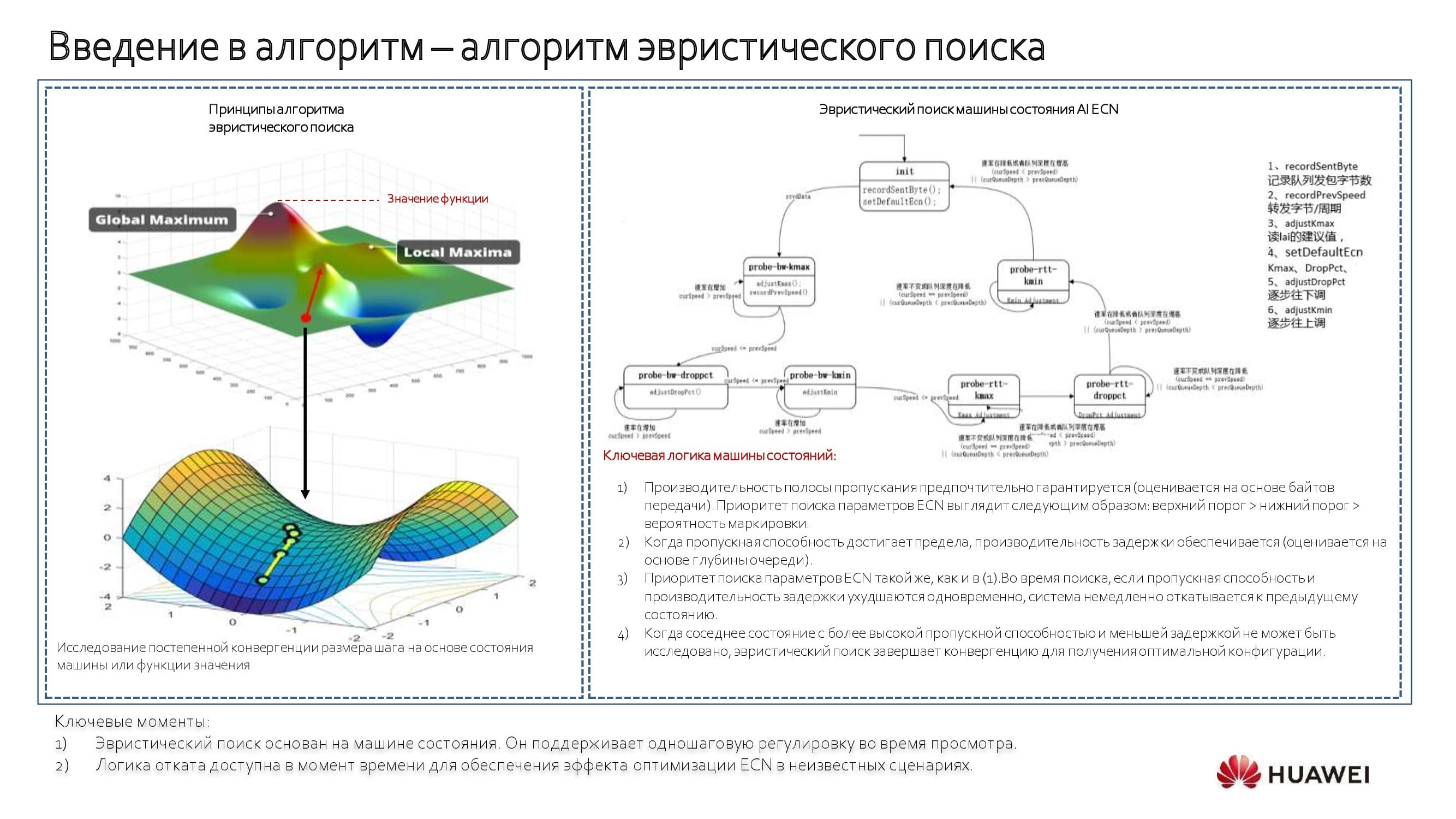
Wenn die Anwendung unbekannt ist, wird ein heuristischer Suchalgorithmus in Verbindung mit einer " Zustandsmaschine " verwendet. Mit seiner Hilfe beginnen wir, uns entlang des oben gezeigten Blockdiagramms gegen den Uhrzeigersinn zu bewegen, Schwellenwerte zu identifizieren und ein Modell zu erstellen. Es ist ein automatischer Prozess, der nach Bedarf bearbeitet werden kann. Wenn dies nicht erforderlich ist, ist es einfacher, sich auf den Switch und seine Dienste zu verlassen.
Von der Theorie zur Praxis
Indem wir solche Algorithmen anwenden und auf der Ebene des gesamten Netzwerks und nicht seiner einzelnen Schichten arbeiten, lösen wir alle Hauptleistungsprobleme. Es gibt bereits interessante Fälle für die Implementierung und den Einsatz solcher Technologien im Bankensektor. Diese Mechanismen sind auch in anderen Branchen gefragt, beispielsweise bei Telekommunikationsbetreibern.
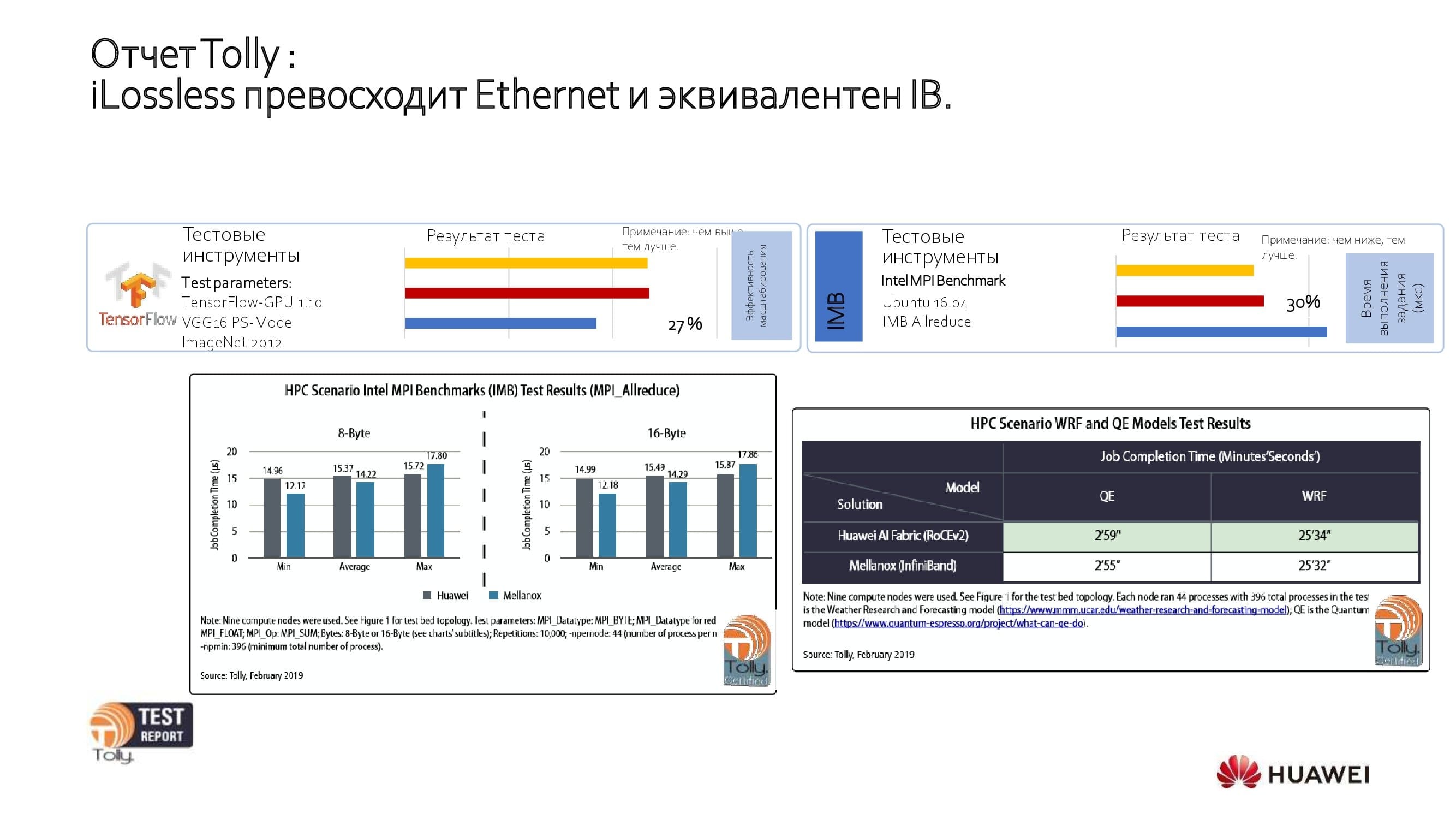
Schauen wir uns die Ergebnisse offener Tests an. Das unabhängige Labor der Tolly Group hat unsere Lösung getestet und mit Ethernet- und IB-Lösungen anderer Hersteller verglichen. Tests haben gezeigt, dass die Produktleistung von Huawei der von IB entspricht und 27% besser ist als bei anderen wichtigen Ethernet-Produkten.
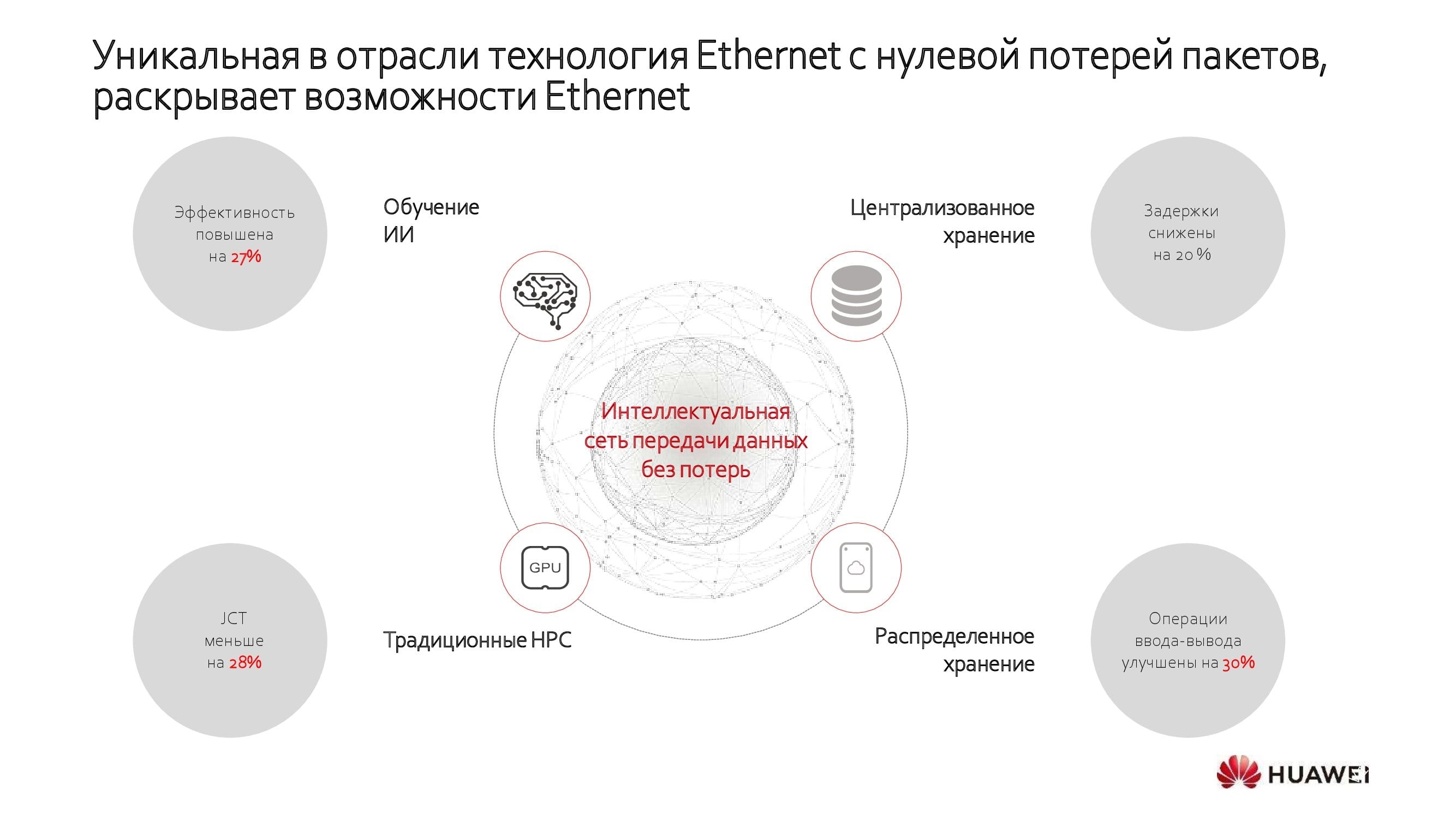
Das verlustfreie Rechenzentrumsnetzwerk zeigt maximale Effizienz in verschiedenen Szenarien, z. B.:
- KI-Training;
- zentraler Speicher;
- verteilter Speicher;
- Hochleistungs-GPU-Computing.

Abschließend betrachten wir eines der Szenarien für die Verwendung eines intelligenten Rechenzentrumsnetzwerks. Viele Kunden verwenden verteilte Speichersysteme (SDB). Durch die Integration von Softwarespeichersystemen verschiedener Hersteller in unsere Lösung können Sie eine um 40% höhere Leistung erzielen als ohne diese. Dies bedeutet, dass wenn Sie das erforderliche Leistungsniveau Ihres Sicherheitsdatenblatts kennen, es mit 40% weniger Servern erreicht werden kann.
***.
Vergessen Sie übrigens nicht unsere zahlreichen Webinare, die nicht nur im russischsprachigen, sondern auch auf globaler Ebene stattfinden. Die Liste der Webinare für Dezember finden Sie hier .