Sie können dies manuell tun, aber es gibt auch Frameworks und Bibliotheken dafür, die diesen Prozess schneller und einfacher machen. Heute werden wir
über eines davon sprechen , featuretools , sowie über die praktischen Erfahrungen bei der Verwendung.

Die modischste Pipeline
Hallo! Ich bin Alexander Loskutov, arbeite bei Leroy Merlin als Datenanalyst oder, wie es heute üblich ist, als Datenwissenschaftler. Zu meinen Aufgaben gehört es, mit Daten zu arbeiten, mit analytischen Abfragen zu beginnen und zu entladen, das Modell zu trainieren, es beispielsweise in einen Dienst zu verpacken, die Bereitstellung und Bereitstellung des Codes einzurichten und seine Arbeit zu überwachen.
Die Vorhersage rückgängig machen ist eines der Produkte, an denen ich arbeite.
Produktziel: Vorhersage der Wahrscheinlichkeit, dass ein Kunde eine Online-Bestellung storniert. Mit Hilfe einer solchen Vorhersage können wir bestimmen, welcher der Kunden, die eine Bestellung aufgegeben haben, zuerst angerufen werden soll, um die Bestätigung der Bestellung zu erhalten, und wer möglicherweise überhaupt nicht angerufen wird. Erstens verringert die Tatsache eines Anrufs und der Bestätigung einer Bestellung von einem Kunden per Telefon die Wahrscheinlichkeit einer Stornierung, und zweitens können wir Ressourcen sparen, wenn wir anrufen und die Person sich weigert. Den Mitarbeitern wird mehr Zeit zur Verfügung gestellt, die sie für die Abholung der Bestellung aufgewendet hätten. Außerdem bleibt das Produkt auf diese Weise im Regal, und wenn der Kunde im Geschäft es zu diesem Zeitpunkt benötigt, kann er es kaufen. Dies reduziert die Anzahl der Waren, die bei später stornierten Bestellungen abgeholt wurden und nicht in den Regalen vorhanden waren.
Vorläufer
Für den Produktpiloten nehmen wir nur Postpaid-Bestellungen zur Abholung in mehreren Filialen entgegen.
Eine vorgefertigte Lösung funktioniert folgendermaßen: Eine Bestellung kommt zu uns. Mit Hilfe von Apache NiFi bereichern wir Informationen darüber - zum Beispiel indem wir Daten zu Waren abrufen. All dies wird dann über den Apache Kafka-Nachrichtenbroker an den in Python geschriebenen Dienst übertragen. Der Service berechnet die Merkmale für die Bestellung, und dann wird ein Modell für maschinelles Lernen für sie erstellt, das die Wahrscheinlichkeit einer Stornierung angibt. Danach bereiten wir gemäß der Geschäftslogik eine Antwort vor, ob wir den Kunden jetzt anrufen müssen oder nicht (wenn beispielsweise die Bestellung mit Hilfe eines Mitarbeiters im Geschäft oder nachts getätigt wurde, sollten Sie nicht anrufen).
Es scheint, was hindert Sie daran, alle hintereinander anzurufen? Tatsache ist, dass wir nur eine begrenzte Anzahl von Ressourcen für Anrufe haben. Daher ist es wichtig zu verstehen, wer auf jeden Fall anrufen sollte und wer seine Bestellung definitiv abholen wird, ohne anzurufen.
Modellentwicklung
Ich war mit dem Service, dem Modell und dementsprechend der Berechnung der Merkmale für das Modell beschäftigt, auf die weiter eingegangen wird.
Bei der Berechnung von Funktionen während des Trainings verwenden wir drei Datenquellen.
- Schild mit Bestell-Metainformationen: Bestellnummer, Zeitstempel, Kundengerät, Versandart, Zahlungsmethode.
- Platte mit Positionen in Quittungen: Bestellnummer, Artikel, Preis, Menge, Menge der auf Lager befindlichen Waren. Jede Position wird in einer separaten Zeile angezeigt.
- Tabelle - ein Nachschlagewerk: Artikel, mehrere Felder mit einer Warengruppe, Maßeinheiten, Beschreibung.
Mit den Standard-Python-Methoden und der Pandas-Bibliothek können Sie alle Tabellen einfach zu einer großen zusammenfassen. Anschließend können Sie mit groupby alle Arten von Attributen wie Aggregate nach Reihenfolge, Verlauf nach Produkt, Produktkategorie usw. berechnen. Hier gibt es jedoch mehrere Probleme.
- Parallelität der Berechnungen. Die Standardgruppe arbeitet in einem Thread, und bei Big Data (bis zu 10 Millionen Zeilen) werden hundert Features als unannehmbar lang angesehen, während die Kapazität der verbleibenden Kerne im Leerlauf ist.
- Die Menge an Code: Jede solche Anfrage muss separat geschrieben, auf Richtigkeit überprüft und dann müssen noch alle Ergebnisse gesammelt werden. Dies nimmt Zeit in Anspruch, insbesondere angesichts der Komplexität einiger Berechnungen - beispielsweise der Berechnung des neuesten Verlaufs für einen Artikel in einer Quittung und der Zusammenfassung dieser Merkmale für eine Bestellung.
- Sie können Fehler machen, wenn Sie alles von Hand codieren.
Der Vorteil des Ansatzes "Wir schreiben alles von Hand" ist natürlich die völlige Handlungsfreiheit. Sie können Ihrer Fantasie freien Lauf lassen.
Es stellt sich die Frage: Wie kann dieser Teil der Arbeit optimiert werden? Eine Lösung besteht darin, die featuretools- Bibliothek zu verwenden .
Hier kommen wir bereits zum Kern dieses Artikels, nämlich der Bibliothek selbst und der Praxis ihrer Verwendung.
Warum featuretools?
Betrachten wir verschiedene Rahmen für maschinelles Lernen in Form einer Platte (das Bild selbst ist ehrlich gestohlen von hier , und wahrscheinlich nicht alle sind dort angegeben ist , aber immer noch):
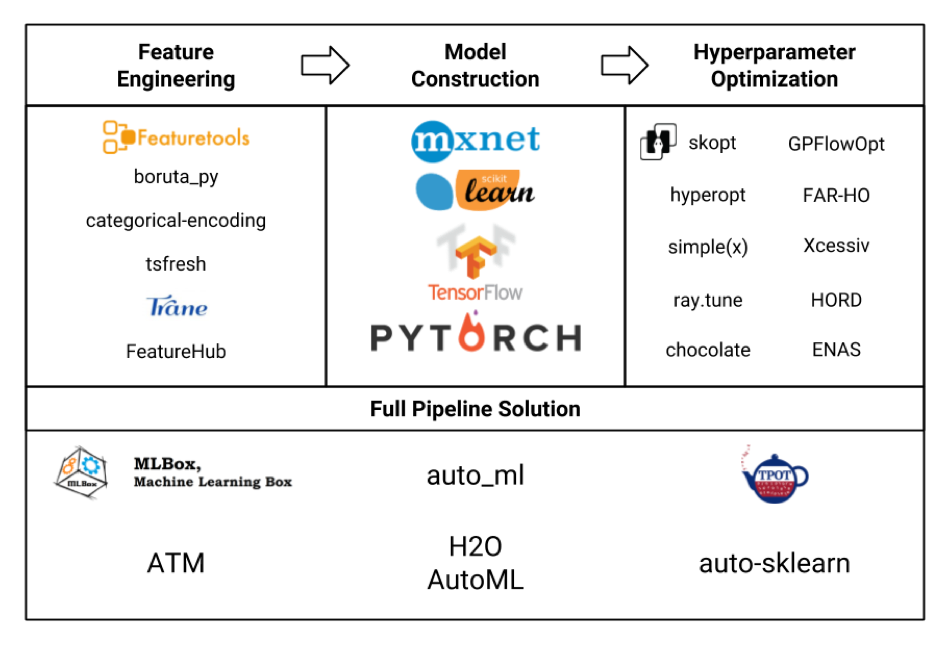
Wir sind in der Feature - Engineering - Block in erster Linie interessiert. Wenn wir uns all diese Frameworks und Pakete ansehen, stellt sich heraus, dass featuretools das ausgefeilteste davon ist und sogar die Funktionalität einiger anderer Bibliotheken wie tsfresh enthält .
Zu den Vorteilen von featuretools (überhaupt keine Werbung!) Gehören:
- Parallele Datenverarbeitung
- Verfügbarkeit vieler Funktionen sofort einsatzbereit
- Flexibilität bei der Anpassung - recht komplexe Dinge können berücksichtigt werden
- Berücksichtigung von Beziehungen zwischen verschiedenen Tabellen (relational)
- weniger Code
- weniger wahrscheinlich, einen Fehler zu machen
- an sich ist alles kostenlos, ohne registrierung und SMS (aber mit pypi)
Aber so einfach ist das nicht.
- Das Framework erfordert etwas Lernen, und das vollständige Mastering wird eine angemessene Zeit in Anspruch nehmen.
- Es gibt keine so große Community, obwohl die beliebtesten Fragen immer noch gut googeln.
- Die Verwendung selbst erfordert auch Sorgfalt, um den Funktionsraum nicht unnötig aufzublasen und die Berechnungszeit nicht zu verlängern.
Ausbildung
Ich werde ein Beispiel für die Konfiguration von featuretools geben.
Als nächstes wird es einen Code mit kurzen Erklärungen geben, der detailliertere Informationen zu featuretools, seinen Klassen, Methoden und Funktionen enthält, die Sie lesen können, einschließlich der Dokumentation auf der Website des Frameworks. Wenn Sie an Beispielen für die praktische Anwendung mit einer Demonstration einiger interessanter Möglichkeiten für reale Aufgaben interessiert sind, dann schreiben Sie in die Kommentare, vielleicht schreibe ich einen separaten Artikel auf.
Damit.
Zunächst müssen Sie ein Objekt der EntitySet-Klasse erstellen, das Tabellen mit Daten enthält und deren Beziehung zueinander kennt.
Ich möchte Sie daran erinnern, dass wir drei Tabellen mit Daten haben:
- orders_meta (Auftrags-Metainformationen)
- orders_items_lists (Informationen zu Artikeln in Bestellungen)
- Artikel (Referenz von Artikeln und deren Eigenschaften)
Wir schreiben (weiter werden die Daten von nur 3 Filialen verwendet):
import featuretools as ft
es = ft.EntitySet(id='orders') # EntitySet
# pandas.DataFrame- (ft.Entity)
es = es.entity_from_dataframe(entity_id='orders_meta',
dataframe=orders_meta,
index='order_id',
time_index='order_creation_dt')
es = es.entity_from_dataframe(entity_id='orders_items',
dataframe=orders_items_lists,
index='order_item_id')
es = es.entity_from_dataframe(entity_id='items',
dataframe=items,
index='item',
variable_types={
'subclass': ft.variable_types.Categorical
})
#
# -,
# -
relationship_orders_items_list = ft.Relationship(es['orders_meta']['order_id'],
es['orders_items']['order_id'])
relationship_items_list_items = ft.Relationship(es['items']['item'],
es['orders_items']['item'])
#
es = es.add_relationship(relationship_orders_items_list)
es = es.add_relationship(relationship_items_list_items)

Hurra! Jetzt haben wir ein Objekt, mit dem wir alle möglichen Zeichen zählen können.
Ich werde einen Code für die Berechnung relativ einfacher Merkmale angeben: Für jede Bestellung berechnen wir verschiedene Statistiken zu Preisen und Warenmengen sowie einige Merkmale nach Zeit und den häufigsten Produkten und Kategorien von Waren in der Bestellung (Funktionen, die verschiedene Transformationen mit Daten durchführen, werden in featuretools als Grundelemente bezeichnet). ...
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'],
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)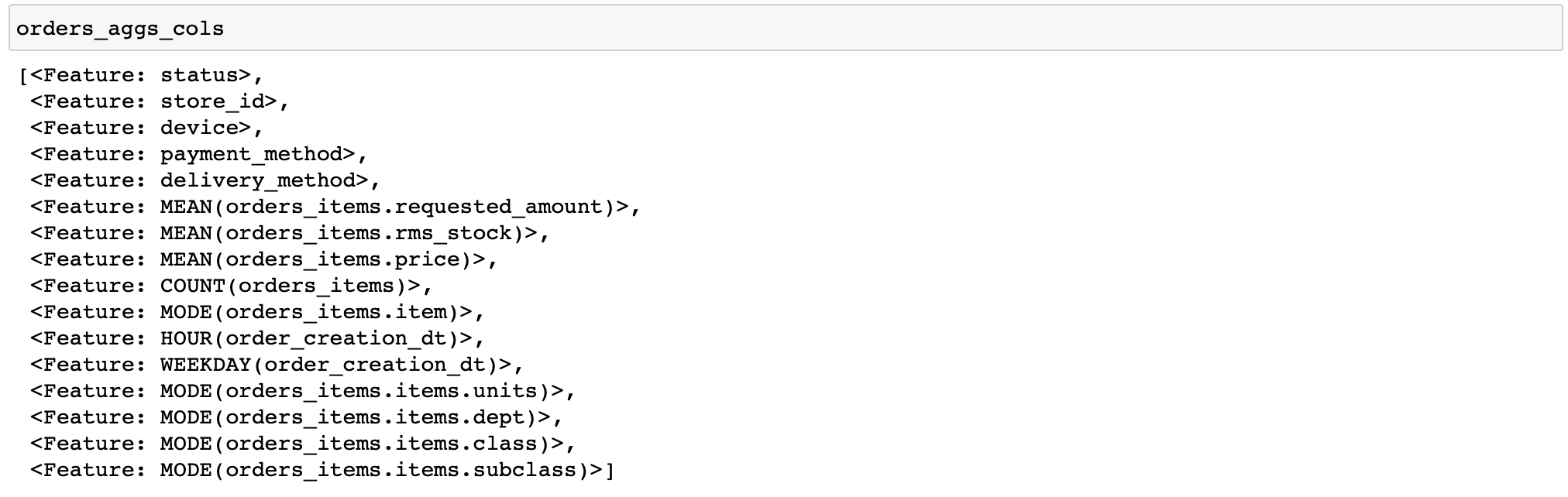

Die Tabellen enthalten keine booleschen Spalten, daher wurde kein Grundelement angewendet. Im Allgemeinen ist es praktisch, dass featuretools selbst den Datentyp analysiert und nur die entsprechenden Funktionen anwendet.
Außerdem habe ich nur wenige Aufträge für die Berechnung manuell angegeben. Auf diese Weise können Sie Ihre Berechnungen schnell debuggen (was passiert, wenn Sie etwas falsch konfiguriert haben).
Fügen wir nun unseren Features einige weitere Aggregate hinzu, nämlich Perzentile. Aber featuretools haben keine eingebauten Grundelemente, um sie zu berechnen. Sie müssen es also selbst schreiben.
from featuretools.variable_types import Numeric
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
def percentile05(x: pandas.Series) -> float:
return numpy.percentile(x, 5)
def percentile25(x: pandas.Series) -> float:
return numpy.percentile(x, 25)
def percentile75(x: pandas.Series) -> float:
return numpy.percentile(x, 75)
def percentile95(x: pandas.Series) -> float:
return numpy.percentile(x, 95)
percentiles = [percentile05, percentile25, percentile75, percentile95]
custom_agg_primitives = [make_agg_primitive(function=fun,
input_types=[Numeric],
return_type=Numeric,
name=fun.__name__)
for fun in percentiles]
Und fügen Sie sie der Berechnung hinzu:
orders_aggs, orders_aggs_cols = ft.dfs(
entityset=es,
target_entity='orders_meta',
agg_primitives=['mean', 'count', 'mode', 'any'] + custom_agg_primitives,
trans_primitives=['hour', 'weekday'],
instance_ids=[200315133283, 200315129511, 200315130383],
max_depth=2
)Dann ist alles gleich. Bisher ist alles ziemlich einfach und leicht (relativ natürlich).
Was ist, wenn wir unseren Feature-Rechner speichern und in der Phase der Modellausführung, dh im Service, verwenden möchten?
Featuretools im Kampf
Hier beginnen die Hauptschwierigkeiten.
Um die Merkmale für einen eingehenden Auftrag zu berechnen, müssen Sie alle Vorgänge mit der Erstellung des EntitySet erneut ausführen. Und wenn es für große Tabellen ganz normal erscheint, pandas.DataFrame-Objekte in das EntitySet zu werfen und dann ähnliche Operationen für DataFrames aus einer Zeile auszuführen (es gibt mehr davon in der Tabelle mit Überprüfungen, aber im Durchschnitt 3,3 Positionen pro Prüfung, das ist nicht genug) - nicht sehr viel. Schließlich beinhaltet die Erstellung solcher Objekte und Berechnungen mit ihrer Hilfe zwangsläufig einen Overhead, dh eine nicht entfernbare Anzahl von Operationen, die beispielsweise für die Speicherzuweisung und -initialisierung beim Erstellen eines Objekts beliebiger Größe oder für den Parallelisierungsprozess selbst bei der gleichzeitigen Berechnung mehrerer Features erforderlich sind.
Daher zeigt in der Betriebsart "eine Bestellung nach der anderen" in unseren Produktmerkmalen nicht die beste Effizienz und nimmt durchschnittlich 75% der Service-Reaktionszeit ein (durchschnittlich 150-200 ms, abhängig von der Hardware). Zum Vergleich: Die Berechnung einer Vorhersage mit Catboost für vorgefertigte Funktionen dauert 3% der Antwortzeit des Dienstes, dh nicht mehr als 10 ms.
Darüber hinaus gibt es eine weitere Gefahr, die mit der Verwendung benutzerdefinierter Grundelemente verbunden ist. Tatsache ist, dass wir ein Objekt der Klasse, das die von uns erstellten Grundelemente enthält, nicht einfach in pickle speichern können, da letztere nicht eingelegt werden.
Verwenden Sie dann die integrierte Funktion save_features (), mit der eine Liste der FeatureBase-Objekte einschließlich der von uns erstellten Grundelemente gespeichert werden kann.
Es werden sie gespeichert, aber es ist nicht möglich, sie später mit der Funktion load_features () zu lesen, wenn wir sie nicht im Voraus erneut erstellen. Das heißt, die Grundelemente, die wir theoretisch von der Festplatte lesen sollten, erstellen wir zuerst erneut, damit wir sie nie wieder verwenden.
Es sieht aus wie das:
from __future__ import annotations
import multiprocessing
import pickle
from typing import List, Optional, Any, Dict
import pandas
from featuretools import EntitySet, dfs, calculate_feature_matrix, save_features, load_features
from featuretools.feature_base.feature_base import FeatureBase, AggregationFeature
from featuretools.primitives.base.aggregation_primitive_base import make_agg_primitive
# -
# ,
#
#
# ( ),
# ,
class AggregationFeaturesCalculator:
def __init__(self,
target_entity: str,
agg_primitives: List[str],
custom_primitives_params: Optional[List[Dict[str, Any]]] = None,
max_depth: int = 2,
drop_contains: Optional[List[str]] = None):
if custom_primitives_params is None:
custom_primitives_params = []
if drop_contains is None:
drop_contains = []
self._target_entity = target_entity
self._agg_primitives = agg_primitives
self._custom_primitives_params = custom_primitives_params
self._max_depth = max_depth
self._drop_contains = drop_contains
self._features = None # ( ft.FeatureBase)
@property
def features_are_built(self) -> bool:
return self._features is not None
@property
def features(self) -> List[AggregationFeature]:
if self._features is None:
raise AttributeError('features have not been built yet')
return self._features
#
def build_features(self, entity_set: EntitySet) -> None:
custom_primitives = [make_agg_primitive(**primitive_params)
for primitive_params in self._custom_primitives_params]
self._features = dfs(
entityset=entity_set,
target_entity=self._target_entity,
features_only=True,
agg_primitives=self._agg_primitives + custom_primitives,
trans_primitives=[],
drop_contains=self._drop_contains,
max_depth=self._max_depth,
verbose=False
)
# ,
#
@staticmethod
def calculate_from_features(features: List[FeatureBase],
entity_set: EntitySet,
parallelize: bool = False) -> pandas.DataFrame:
n_jobs = max(1, multiprocessing.cpu_count() - 1) if parallelize else 1
return calculate_feature_matrix(features=features, entityset=entity_set, n_jobs=n_jobs)
#
def calculate(self, entity_set: EntitySet, parallelize: bool = False) -> pandas.DataFrame:
if not self.features_are_built:
self.build_features(entity_set)
return self.calculate_from_features(features=self.features,
entity_set=entity_set,
parallelize=parallelize)
#
# ,
# save_features()
#
@staticmethod
def save(calculator: AggregationFeaturesCalculator, path: str) -> None:
result = {
'target_entity': calculator._target_entity,
'agg_primitives': calculator._agg_primitives,
'custom_primitives_params': calculator._custom_primitives_params,
'max_depth': calculator._max_depth,
'drop_contains': calculator._drop_contains
}
if calculator.features_are_built:
result['features'] = save_features(calculator.features)
with open(path, 'wb') as f:
pickle.dump(result, f)
#
@staticmethod
def load(path: str) -> AggregationFeaturesCalculator:
with open(path, 'rb') as f:
arguments_dict = pickle.load(f)
# ...
if arguments_dict['custom_primitives_params']:
custom_primitives = [make_agg_primitive(**custom_primitive_params)
for custom_primitive_params in arguments_dict['custom_primitives_params']]
features = None
#
if 'features' in arguments_dict:
features = load_features(arguments_dict.pop('features'))
calculator = AggregationFeaturesCalculator(**arguments_dict)
if features:
calculator._features = features
return calculatorIn der Funktion load () müssen Sie Grundelemente erstellen (die Variable custom_primitives deklarieren), die nicht verwendet werden. Ohne dies schlägt das weitere Laden von Features an der Stelle, an der die Funktion load_features () aufgerufen wird, fehl, wenn RuntimeError: Primitive "perzentile05" im Modul "featuretools.primitives.base.aggregation_primitive_base" nicht gefunden wird .
Es stellt sich als nicht sehr logisch heraus, aber es funktioniert, und Sie können sowohl den Rechner, der bereits an ein bestimmtes Datenformat gebunden ist (da die Features an das EntitySet gebunden sind, für das sie berechnet wurden, wenn auch ohne die Werte selbst), als auch den Rechner nur mit einer bestimmten Liste von Grundelementen speichern.
Vielleicht wird dies in Zukunft korrigiert und es wird möglich sein, einen beliebigen Satz von FeatureBase-Objekten bequem zu speichern.
Warum benutzen wir es dann?
Denn aus Sicht der Entwicklungszeit ist es billig, während die Reaktionszeit unter der vorhandenen Last mit einem Spielraum in unser SLA (5 Sekunden) passt.
Sie sollten sich jedoch bewusst sein, dass für einen Dienst, der schnell auf häufig empfangene Anfragen reagieren muss, die Verwendung von featuretools ohne zusätzliche "Squats" wie asynchrone Anrufe problematisch ist.
Dies ist unsere Erfahrung mit der Verwendung von featuretools in der Lern- und Inferenzphase.
Dieses Framework eignet sich sehr gut als Tool zur schnellen Berechnung einer großen Anzahl von Funktionen für das Training. Es reduziert die Entwicklungszeit erheblich und verringert die Fehlerwahrscheinlichkeit.
Ob Sie es zum Zeitpunkt des Widerrufs verwenden, hängt von Ihren Aufgaben ab.