
data science Python –
Warum? Die vorhandenen Tools eignen sich schlecht zur Lösung von Problemen im Zusammenhang mit Zeitreihen, und diese Tools lassen sich nur schwer miteinander integrieren. Die Methoden von Scikit-learn setzen voraus, dass die Daten tabellarisch strukturiert sind und dass jede Spalte aus unabhängigen und gleichmäßig verteilten Zufallsvariablen besteht - Annahmen, die nichts mit Zeitreihendaten zu tun haben. Pakete, die Module für maschinelles Lernen enthalten und mit Zeitreihen arbeiten, wie z. B. Statistikmodelle , sind nicht sehr gut miteinander befreundet. Darüber hinaus sind viele wichtige Vorgänge mit Zeitreihen, wie das Aufteilen von Daten in Trainings- und Testsätze über Zeitintervalle, in vorhandenen Paketen nicht verfügbar.
Um ähnliche Probleme zu lösen, wurde sktime erstellt .

Sktime-Bibliothekslogo auf GitHub
Sktime ist ein Open-Source-Toolkit für maschinelles Lernen in Python, das speziell für die Arbeit mit Zeitreihen entwickelt wurde. Dieses Projekt wurde vom British Council für Wirtschafts- und Sozialforschung , Verbraucherdatenforschung und dem Alan Turing Institute entwickelt und finanziert.
Sktime erweitert die Scikit-Learn-API zur Lösung von Zeitreihenproblemen. Es enthält alle erforderlichen Algorithmen und Transformationswerkzeuge zur effizienten Lösung von Problemen der Zeitreihenregression, -prognose und -klassifizierung. Die Bibliothek enthält spezielle Algorithmen für maschinelles Lernen und Transformationsmethoden für Zeitreihen, die in anderen gängigen Bibliotheken nicht zu finden sind.
Sktime wurde entwickelt, um mit Scikit-Learn zu arbeiten, Algorithmen einfach an miteinander verbundene Zeitreihenprobleme anzupassen und komplexe Modelle zu erstellen. Wie es funktioniert? Viele Zeitreihenprobleme hängen auf die eine oder andere Weise miteinander zusammen. Ein Algorithmus, der zur Lösung eines Problems verwendet werden kann, kann sehr häufig zur Lösung eines anderen damit verbundenen Problems angewendet werden. Diese Idee nennt man Reduktion. Beispielsweise kann ein Modell für die Zeitreihenregression (das eine Reihe zur Vorhersage eines Ausgabewerts verwendet) für ein Zeitreihenprognoseproblem (das einen Ausgabewert vorhersagt - einen Wert, der in Zukunft empfangen wird) wiederverwendet werden.
Die Hauptidee des Projekts:„Sktime bietet leicht verständliches und integrierbares maschinelles Lernen mithilfe von Zeitreihen. Es verfügt über Algorithmen, die mit Scikit-Learn- und Model-Sharing-Tools kompatibel sind und von einer klaren Taxonomie der Lernaufgaben, einer klaren Dokumentation und einer freundlichen Community unterstützt werden. "
In diesem Artikel werde ich einige der einzigartigen Funktionen von sktime hervorheben .
Korrektes Datenmodell für Zeitreihen
Sktime verwendet eine verschachtelte Datenstruktur für Zeitreihen in Form von Pandas- Datenrahmen .
Jede Zeile in einem typischen Datenrahmen enthält unabhängige und gleichmäßig verteilte Zufallsvariablen - Fälle und die Spalten - verschiedene Variablen. Bei sktime- Methoden kann jede Zelle in einem Pandas-Datenrahmen jetzt eine ganze Zeitreihe enthalten. Dieses Format ist flexibel für mehrdimensionale, Panel- und heterogene Daten und ermöglicht die Wiederverwendung von Methoden sowohl in Pandas als auch in Scikit-Learn .
In der folgenden Tabelle ist jede Zeile eine Beobachtung, die ein Array von Zeitreihen in Spalte X und einen Klassenwert in Spalte Y enthält. Sktime-Evaluatoren und -Transformatoren können mit solchen Zeitreihen arbeiten.
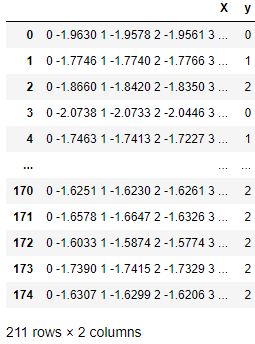
Eine native sktime-kompatible Zeitreihendatenstruktur.
In der folgenden Tabelle wurde jedes Element der X-Reihe in eine separate Spalte verschoben, wie dies für Scikit-Lernmethoden erforderlich ist. Die Dimension ist ziemlich hoch - 251 Spalten! Darüber hinaus wird die zeitliche Reihenfolge der Spalten von Lernalgorithmen ignoriert, die mit Tabellenwerten arbeiten (jedoch von Zeitreihenklassifizierungs- und Regressionsalgorithmen verwendet werden).
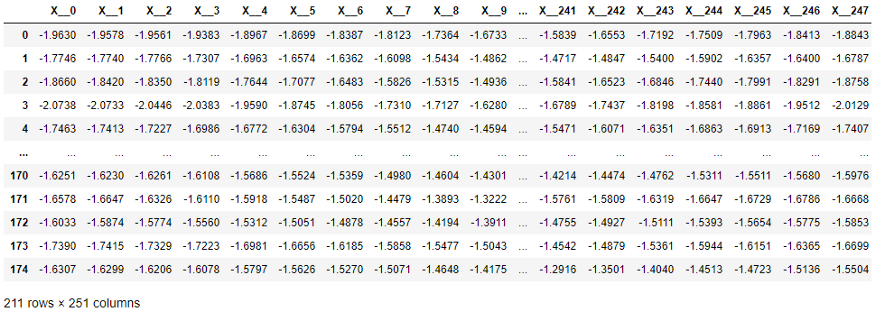
Zeitreihendatenstruktur, die von scikit-learn benötigt wird.
Für Modellierungsaufgaben mehrerer gemeinsamer Reihen ist eine native Zeitreihendatenstruktur ideal , die mit sktime kompatibel ist. Modelle, die auf den von scikit-learn erwarteten Tabellendaten trainiert werden, werden in vielen Funktionen stecken bleiben .
Was kann sktime tun?
Laut der GitHub- Seite bietet sktime derzeit die folgenden Funktionen:
- Moderne Algorithmen zur Klassifizierung, Regressionsanalyse und Prognose von Zeitreihen (vom Toolkit
tsmlnach Java portiert ); - Zeitreihentransformatoren: Transformationen einzelner Serien (z. B. Detrending oder Deseasonization), Transformationen von Serien als Features (z. B. Extraktion von Features) und Tools zum Teilen mehrerer Transformatoren.
- Rohrleitungen für Transformatoren und Modelle;
- Einrichten des Modells;
- Modellensemble, z. B. vollständig anpassbare Zufallsstruktur für Klassifizierung und Zeitreihenregression, Ensemble für mehrdimensionale Probleme.
API sktime
Wie bereits erwähnt, sktime unterstützt grundlegende API - Methoden , um Klassen Scikit-Learn
fit, predictund transform.
Für Evaluatorklassen (oder Modelle) bietet sktime eine Methode
fitzum Trainieren des Modells und eine Methode predictzum Generieren neuer Vorhersagen.
Die sktime-Evaluatoren erweitern die Regressoren und Klassifikatoren von scikit-learn, indem sie Zeitreihenanaloga zu diesen Methoden bereitstellen.
Für Klassen bietet sktime transformator Methoden
fitund transformzum Konvertieren der Seriendaten . Es gibt verschiedene Arten von Transformationen:
- , , ;
- , (, );
- (, );
- , , , (, ).
Das nächste Beispiel ist eine Anpassung des Prognosehandbuchs von GitHub . Die Serie in diesem Beispiel (der Airline-Datensatz von Box-Jenkins) zeigt die Anzahl der internationalen Fluggäste pro Monat von 1949 bis 1960.
Laden Sie zunächst die Daten, teilen Sie sie in Trainings- und Testsuiten auf und erstellen Sie ein Diagramm. In sktime gibt es zwei praktische Funktionen für die einfache Ausführung dieser Aufgaben -
temporal_train_test_splitfordie durch einen Satz von Daten und Zeit getrennt sind plot_ys, die auf der Grundlage des Tests und des Trainingsmusters aufgezeichnet werden.
from sktime.datasets import load_airline
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.utils.plotting.forecasting import plot_ys
y = load_airline()
y_train, y_test = temporal_train_test_split(y)
plot_ys(y_train, y_test, labels=["y_train", "y_test"])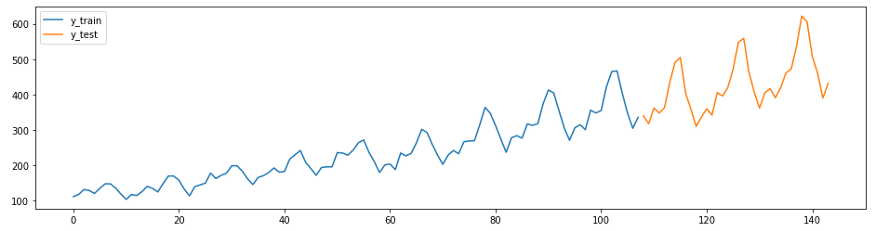
Bevor Sie komplexe Prognosen erstellen, ist es hilfreich, Ihre Prognose mit den Werten zu vergleichen, die mit naiven Bayes'schen Algorithmen erhalten wurden. Ein gutes Modell sollte diese Werte überschreiten. In sktime haben Sie eine Methode
NaiveForecastermit verschiedenen Strategien, um eine Basisprojektion zu erstellen.
Der folgende Code und das folgende Diagramm zeigen zwei naive Vorhersagen. Forecaster c
strategy = “last”sagt immer den letzten Wert der Serie voraus.
Forecaster s
strategy = “seasonal_last”sagt den letzten Wert der Serie für die gegebene Saison voraus. Die Saisonalität im Beispiel beträgt “sp=12”12 Monate.
from sktime.forecasting.naive import NaiveForecaster
naive_forecaster_last = NaiveForecaster(strategy="last")
naive_forecaster_last.fit(y_train)
y_last = naive_forecaster_last.predict(fh)
naive_forecaster_seasonal = NaiveForecaster(strategy="seasonal_last", sp=12)
naive_forecaster_seasonal.fit(y_train)
y_seasonal_last = naive_forecaster_seasonal.predict(fh)
plot_ys(y_train, y_test, y_last, y_seasonal_last, labels=["y_train", "y_test", "y_pred_last", "y_pred_seasonal_last"]);
smape_loss(y_last, y_test)
>>0.231957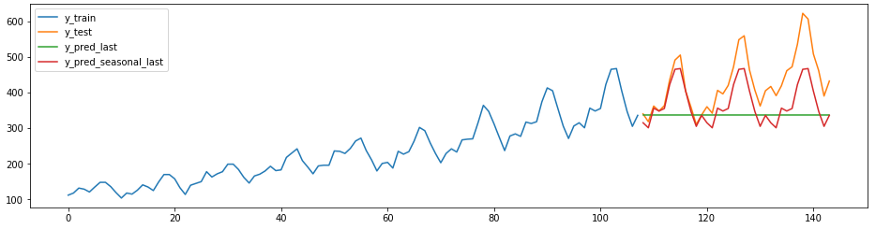
Das folgende Vorhersage-Snippet zeigt, wie vorhandene sklearn-Regressoren einfach, korrekt und mit minimalem Aufwand für Vorhersageaufgaben angepasst werden können. Unten finden Sie eine Methode
ReducedRegressionForecastervon sktime, die eine Serie anhand eines Modells vorhersagt sklearnRandomForestRegressor. Unter der Haube teilt sktime die Trainingsdaten in Fenster von 12 auf, damit der Regressor das Training fortsetzen kann.
from sktime.forecasting.compose import ReducedRegressionForecaster
from sklearn.ensemble import RandomForestRegressor
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.performance_metrics.forecasting import smape_loss
regressor = RandomForestRegressor()
forecaster = ReducedRegressionForecaster(regressor, window_length=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=['y_train', 'y_test', 'y_pred'])
smape_loss(y_test, y_pred)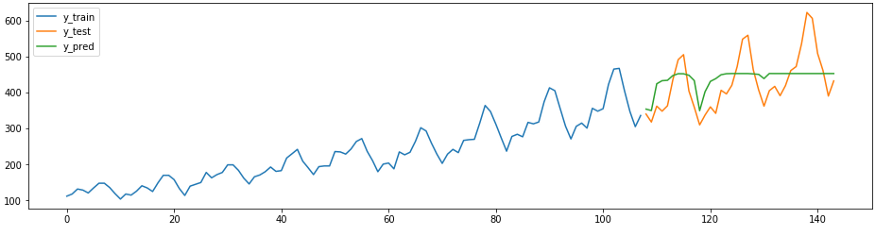
In sktime gibt es zum Beispiel auch eigene Prognosemethoden
AutoArima.
from sktime.forecasting.arima import AutoARIMA
forecaster = AutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]);
smape_loss(y_test, y_pred)
>>0.07395319887252469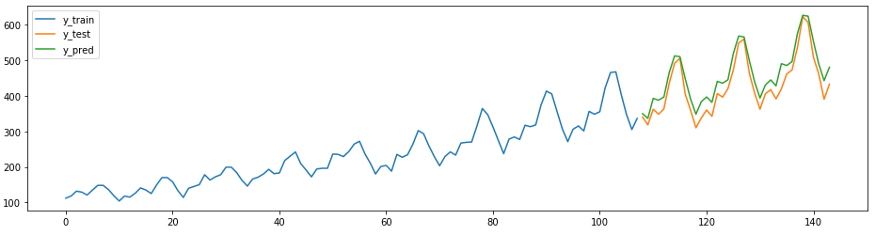
Weitere Informationen zur Sktime- Vorhersagefunktion finden Sie im Tutorial hier .
Zeitreihenklassifikation
Es
sktimekann auch verwendet werden, um Zeitreihen in verschiedene Gruppen zu klassifizieren.
Im folgenden Codebeispiel ist die Klassifizierung einzelner Zeitreihen so einfach wie die Klassifizierung in Scikit-Learn. Der einzige Unterschied ist die verschachtelte Zeitreihendatenstruktur, über die wir oben gesprochen haben.
from sktime.datasets import load_arrow_head
from sktime.classification.compose import TimeSeriesForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = load_arrow_head(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
classifier = TimeSeriesForestClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy_score(y_test, y_pred)
>>0.8679245283018868Das Beispiel stammt aus pypi.org/project/sktime
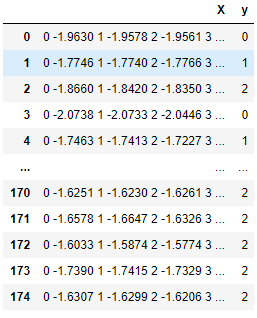
Daten, die an TimeSeriesForestClassifier übergeben wurden. Weitere Informationen zur Serienklassifizierung finden Sie in
den univariaten und mehrdimensionalen Klassifizierungs- Tutorials von sktime .
Zusätzliche Sktime- Ressourcen
Weitere Informationen zu Sktime finden Sie unter den folgenden Links für Dokumentation und Beispiele.
- Detaillierte API-Beschreibung: sktime.org
- sktime GitHub ( );
- ;
- Sktime: Markus Löning, Anthony Bagnall, Sajaysurya Ganesh, Viktor Kazakov, Jason Lines, Franz Király (2019): “sktime: A Unified Interface for Machine Learning with Time Series”
. .