
In der modernen Welt von Big Data ist Apache Spark der De-facto-Standard für die Entwicklung von Stapelverarbeitungsaufgaben. Darüber hinaus werden damit Streaming-Anwendungen erstellt, die im Micro-Batch-Konzept ausgeführt werden und Daten in kleinen Portionen verarbeiten und senden (Spark Structured Streaming). Und traditionell war es Teil des gesamten Hadoop-Stacks, wobei YARN (oder in einigen Fällen Apache Mesos) als Ressourcenmanager verwendet wurde. Bis 2020 ist die traditionelle Verwendung für die meisten Unternehmen aufgrund des Mangels an anständigen Hadoop-Distributionen fraglich - die HDP- und CDH-Entwicklung wurde eingestellt, CDH ist unterentwickelt und hat hohe Kosten, und der Rest der Hadoop-Anbieter existiert entweder nicht mehr oder hat eine vage Zukunft.Daher wächst das Interesse der Community und großer Unternehmen an der Einführung von Apache Spark mithilfe von Kubernetes. Es wird zum Standard für die Container-Orchestrierung und das Ressourcenmanagement in privaten und öffentlichen Clouds. Es löst das Problem der unbequemen Ressourcenplanung von Spark-Aufgaben auf YARN und bietet eine sich stetig entwickelnde Plattform mit vielen kommerziellen Funktionen und Open-Source-Distributionen für Unternehmen aller Größen und Streifen. Darüber hinaus ist es der Mehrheit auf der Welle der Popularität bereits gelungen, einige ihrer Installationen zu erwerben und ihr Fachwissen in der Verwendung zu erweitern, was den Umzug vereinfacht.Es löst die umständliche Planung von Spark-Aufgaben auf YARN und bietet eine sich ständig weiterentwickelnde Plattform mit vielen kommerziellen und Open-Source-Distributionen für Unternehmen aller Größen und Bereiche. Darüber hinaus ist es der Mehrheit auf der Welle der Popularität bereits gelungen, einige ihrer Installationen zu erwerben und ihr Fachwissen in der Verwendung zu erweitern, was den Umzug vereinfacht.Es löst die umständliche Planung von Spark-Aufgaben auf YARN und bietet eine sich ständig weiterentwickelnde Plattform mit vielen kommerziellen und Open-Source-Distributionen für Unternehmen aller Größen und Bereiche. Darüber hinaus ist es der Mehrheit auf der Welle der Popularität bereits gelungen, einige ihrer Installationen zu erwerben und ihr Fachwissen in der Verwendung zu erweitern, was den Umzug vereinfacht.
Ab Version 2.3.0 erhielt Apache Spark offizielle Unterstützung für die Ausführung von Aufgaben im Kubernetes-Cluster. Heute werden wir über die aktuelle Reife dieses Ansatzes, die verschiedenen Optionen für seine Verwendung und die Fallstricke sprechen, die bei der Implementierung auftreten werden.
Zunächst werden wir den Prozess der Entwicklung von Aufgaben und Anwendungen auf der Basis von Apache Spark betrachten und typische Fälle hervorheben, in denen Sie eine Aufgabe in einem Kubernetes-Cluster ausführen müssen. Bei der Vorbereitung dieses Beitrags wird OpenShift als Distributionskit verwendet, und die Befehle, die für das Befehlszeilenprogramm (oc) relevant sind, werden angegeben. Für andere Kubernetes-Distributionen können die entsprechenden Befehle des Standard-Kubernetes-Befehlszeilenprogramms (kubectl) oder deren Analoga (z. B. für die oc adm-Richtlinie) verwendet werden.
Der erste Anwendungsfall ist Spark-Submit
Bei der Entwicklung von Aufgaben und Anwendungen muss der Entwickler Aufgaben ausführen, um die Datentransformation zu debuggen. Theoretisch können Stubs für diese Zwecke verwendet werden, aber die Entwicklung unter Beteiligung realer (wenn auch Test-) Instanzen endlicher Systeme hat sich in dieser Aufgabenklasse schneller und besser gezeigt. Beim Debuggen auf realen Instanzen von Endsystemen sind zwei Szenarien möglich:
- Der Entwickler führt die Spark-Task lokal im Standalone-Modus aus.
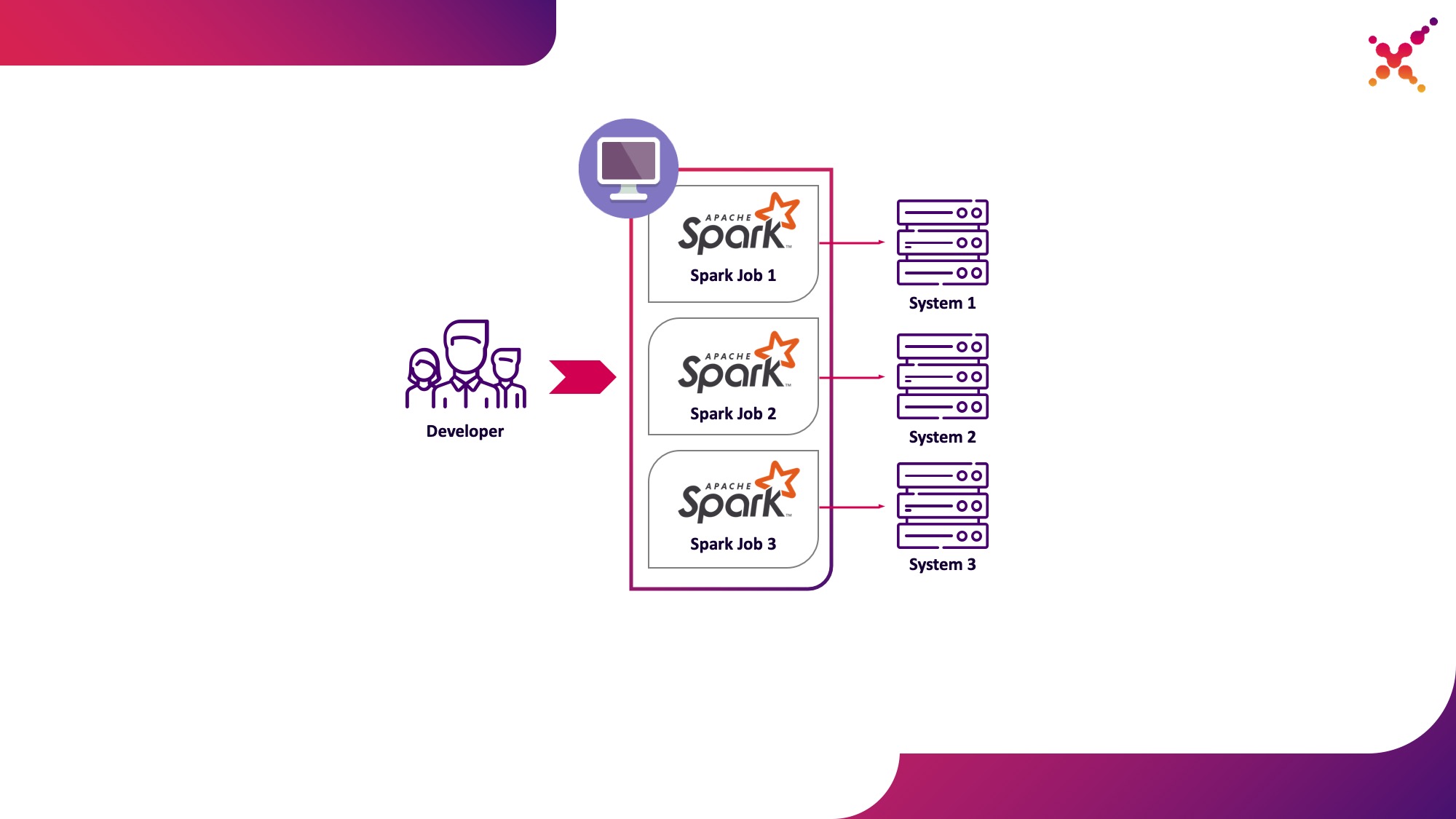
- Ein Entwickler führt eine Spark-Aufgabe in einem Kubernetes-Cluster in einer Testschleife aus.

Die erste Option hat das Existenzrecht, bringt jedoch eine Reihe von Nachteilen mit sich:
- Für jeden Entwickler ist es erforderlich, vom Arbeitsplatz aus Zugriff auf alle Kopien der von ihm benötigten Endsysteme zu gewähren.
- Die Produktionsmaschine benötigt ausreichende Ressourcen, um die entwickelte Aufgabe auszuführen.
Die zweite Option weist diese Nachteile nicht auf, da Sie durch die Verwendung eines Kubernetes-Clusters den erforderlichen Ressourcenpool für die Ausführung von Aufgaben zuweisen und ihm den erforderlichen Zugriff auf Instanzen von Endsystemen gewähren können, sodass alle Mitglieder des Entwicklungsteams mithilfe des Kubernetes-Vorbilds flexibel darauf zugreifen können. Lassen Sie es uns als ersten Anwendungsfall hervorheben - Ausführen von Spark-Tasks von einem lokalen Entwicklungscomputer auf einem Kubernetes-Cluster in einer Testschleife.
Schauen wir uns den Prozess der Konfiguration von Spark für die lokale Ausführung genauer an. Um Spark verwenden zu können, müssen Sie es installieren:
mkdir /opt/spark
cd /opt/spark
wget http://mirror.linux-ia64.org/apache/spark/spark-2.4.5/spark-2.4.5.tgz
tar zxvf spark-2.4.5.tgz
rm -f spark-2.4.5.tgz
Wir sammeln die notwendigen Pakete für die Arbeit mit Kubernetes:
cd spark-2.4.5/
./build/mvn -Pkubernetes -DskipTests clean package
Die vollständige Erstellung nimmt viel Zeit in Anspruch. Um Docker-Images zu erstellen und auf dem Kubernetes-Cluster auszuführen, benötigen Sie in Wirklichkeit nur JAR-Dateien aus dem Verzeichnis "Assembly /", sodass Sie nur dieses Teilprojekt erstellen können:
./build/mvn -f ./assembly/pom.xml -Pkubernetes -DskipTests clean package
Um Spark-Aufgaben in Kubernetes auszuführen, müssen Sie ein Docker-Image erstellen, das als Basis-Image verwendet werden soll. Hier sind 2 Ansätze möglich:
- Das generierte Docker-Image enthält den ausführbaren Code für die Spark-Task.
- Das erstellte Image enthält nur Spark und die erforderlichen Abhängigkeiten. Der ausführbare Code wird remote gehostet (z. B. in HDFS).
Lassen Sie uns zunächst ein Docker-Image erstellen, das ein Testbeispiel für eine Spark-Aufgabe enthält. Zum Erstellen von Docker-Images verfügt Spark über ein Tool namens "Docker-Image-Tool". Lassen Sie uns die Hilfe dazu studieren:
./bin/docker-image-tool.sh --help
Es kann verwendet werden, um Docker-Images zu erstellen und in Remote-Registries hochzuladen. Standardmäßig weist es jedoch mehrere Nachteile auf:
- erstellt ohne Fehler 3 Docker-Images gleichzeitig - für Spark, PySpark und R;
- Sie können den Namen des Bildes nicht angeben.
Daher verwenden wir eine modifizierte Version dieses Dienstprogramms (siehe unten):
vi bin/docker-image-tool-upd.sh
#!/usr/bin/env bash
function error {
echo "$@" 1>&2
exit 1
}
if [ -z "${SPARK_HOME}" ]; then
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)"
fi
. "${SPARK_HOME}/bin/load-spark-env.sh"
function image_ref {
local image="$1"
local add_repo="${2:-1}"
if [ $add_repo = 1 ] && [ -n "$REPO" ]; then
image="$REPO/$image"
fi
if [ -n "$TAG" ]; then
image="$image:$TAG"
fi
echo "$image"
}
function build {
local BUILD_ARGS
local IMG_PATH
if [ ! -f "$SPARK_HOME/RELEASE" ]; then
IMG_PATH=$BASEDOCKERFILE
BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
img_path=$IMG_PATH
--build-arg
datagram_jars=datagram/runtimelibs
--build-arg
spark_jars=assembly/target/scala-$SPARK_SCALA_VERSION/jars
)
else
IMG_PATH="kubernetes/dockerfiles"
BUILD_ARGS=(${BUILD_PARAMS})
fi
if [ -z "$IMG_PATH" ]; then
error "Cannot find docker image. This script must be run from a runnable distribution of Apache Spark."
fi
if [ -z "$IMAGE_REF" ]; then
error "Cannot find docker image reference. Please add -i arg."
fi
local BINDING_BUILD_ARGS=(
${BUILD_PARAMS}
--build-arg
base_img=$(image_ref $IMAGE_REF)
)
local BASEDOCKERFILE=${BASEDOCKERFILE:-"$IMG_PATH/spark/docker/Dockerfile"}
docker build $NOCACHEARG "${BUILD_ARGS[@]}" \
-t $(image_ref $IMAGE_REF) \
-f "$BASEDOCKERFILE" .
}
function push {
docker push "$(image_ref $IMAGE_REF)"
}
function usage {
cat <<EOF
Usage: $0 [options] [command]
Builds or pushes the built-in Spark Docker image.
Commands:
build Build image. Requires a repository address to be provided if the image will be
pushed to a different registry.
push Push a pre-built image to a registry. Requires a repository address to be provided.
Options:
-f file Dockerfile to build for JVM based Jobs. By default builds the Dockerfile shipped with Spark.
-p file Dockerfile to build for PySpark Jobs. Builds Python dependencies and ships with Spark.
-R file Dockerfile to build for SparkR Jobs. Builds R dependencies and ships with Spark.
-r repo Repository address.
-i name Image name to apply to the built image, or to identify the image to be pushed.
-t tag Tag to apply to the built image, or to identify the image to be pushed.
-m Use minikube's Docker daemon.
-n Build docker image with --no-cache
-b arg Build arg to build or push the image. For multiple build args, this option needs to
be used separately for each build arg.
Using minikube when building images will do so directly into minikube's Docker daemon.
There is no need to push the images into minikube in that case, they'll be automatically
available when running applications inside the minikube cluster.
Check the following documentation for more information on using the minikube Docker daemon:
https://kubernetes.io/docs/getting-started-guides/minikube/#reusing-the-docker-daemon
Examples:
- Build image in minikube with tag "testing"
$0 -m -t testing build
- Build and push image with tag "v2.3.0" to docker.io/myrepo
$0 -r docker.io/myrepo -t v2.3.0 build
$0 -r docker.io/myrepo -t v2.3.0 push
EOF
}
if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then
usage
exit 0
fi
REPO=
TAG=
BASEDOCKERFILE=
NOCACHEARG=
BUILD_PARAMS=
IMAGE_REF=
while getopts f:mr:t:nb:i: option
do
case "${option}"
in
f) BASEDOCKERFILE=${OPTARG};;
r) REPO=${OPTARG};;
t) TAG=${OPTARG};;
n) NOCACHEARG="--no-cache";;
i) IMAGE_REF=${OPTARG};;
b) BUILD_PARAMS=${BUILD_PARAMS}" --build-arg "${OPTARG};;
esac
done
case "${@: -1}" in
build)
build
;;
push)
if [ -z "$REPO" ]; then
usage
exit 1
fi
push
;;
*)
usage
exit 1
;;
esac
Damit erstellen wir ein Basis-Spark-Image, das eine Testaufgabe zur Berechnung der Pi-Nummer mit Spark enthält (hier ist {docker-registry-url} die URL Ihrer Docker-Image-Registrierung, {repo} der Name des Repositorys in der Registrierung, das mit dem Projekt in OpenShift übereinstimmt , {Bildname} ist der Name des Bildes (wenn beispielsweise eine dreistufige Bildtrennung verwendet wird, wie in der integrierten Bildregistrierung von Red Hat OpenShift), {tag} ist das Tag dieser Version des Bildes):
./bin/docker-image-tool-upd.sh -f resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile -r {docker-registry-url}/{repo} -i {image-name} -t {tag} build
Melden Sie sich mit dem Konsolendienstprogramm beim OKD-Cluster an (hier ist {OKD-API-URL} die OKD-Cluster-API-URL):
oc login {OKD-API-URL}
Lassen Sie uns das Token des aktuellen Benutzers zur Autorisierung in der Docker-Registrierung abrufen:
oc whoami -t
Melden Sie sich bei der internen Docker-Registrierung des OKD-Clusters an (verwenden Sie das mit dem vorherigen Befehl erhaltene Token als Kennwort):
docker login {docker-registry-url}
Laden Sie das erstellte Docker-Image in die Docker-Registrierung hoch. OKD:
./bin/docker-image-tool-upd.sh -r {docker-registry-url}/{repo} -i {image-name} -t {tag} push
Lassen Sie uns überprüfen, ob das zusammengestellte Bild in OKD verfügbar ist. Öffnen Sie dazu die URL mit einer Liste der Bilder des entsprechenden Projekts im Browser (hier ist {Projekt} der Name des Projekts im OpenShift-Cluster, {OKD-WEBUI-URL} die URL der OpenShift-Webkonsole) - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / images / {image-name}.
Zum Ausführen von Aufgaben muss ein Dienstkonto mit den Berechtigungen zum Ausführen von Pods als Root erstellt werden (wir werden diesen Punkt später erläutern):
oc create sa spark -n {project}
oc adm policy add-scc-to-user anyuid -z spark -n {project}
Führen Sie den Befehl spark-submit aus, um die Spark-Aufgabe im OKD-Cluster zu veröffentlichen, und geben Sie das erstellte Dienstkonto und das Docker-Image an:
/opt/spark/bin/spark-submit --name spark-test --class org.apache.spark.examples.SparkPi --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar
Hier:
--name ist der Name der Aufgabe, die an der Bildung des Kubernetes-Pod-Namens beteiligt ist.
--class - die Klasse der ausführbaren Datei, die beim Start der Aufgabe aufgerufen wird;
--conf - Spark-Konfigurationsparameter;
spark.executor.instances Die Anzahl der auszuführenden Spark-Executoren.
spark.kubernetes.authenticate.driver.serviceAccountName Der Name des Kubernetes-Dienstkontos, das beim Starten von Pods verwendet wird (um den Sicherheitskontext und die Funktionen bei der Interaktion mit der Kubernetes-API zu definieren).
spark.kubernetes.namespace - Kubernetes-Namespace, in dem die Treiber- und Executor-Pods ausgeführt werden.
spark.submit.deployMode - Spark-Startmethode ("Cluster" wird für Standard-Spark-Submit verwendet, "Client" für Spark Operator und spätere Versionen von Spark);
spark.kubernetes.container.image Das Docker-Image, mit dem die Pods ausgeführt werden.
spark.master - URL der Kubernetes-API (die externe wird angegeben, sodass der Aufruf vom lokalen Computer stammt);
local: // ist der Pfad zur ausführbaren Spark-Datei im Docker-Image.
Gehen Sie zum entsprechenden OKD-Projekt und studieren Sie die erstellten Pods - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods.
Um den Entwicklungsprozess zu vereinfachen, kann eine andere Option verwendet werden, bei der ein gemeinsames Basis-Spark-Image erstellt wird, das von allen Aufgaben zum Starten verwendet wird, und Snapshots der ausführbaren Dateien in einem externen Speicher (z. B. Hadoop) veröffentlicht und beim Aufrufen von spark-submit als Link angegeben werden. In diesem Fall können Sie verschiedene Versionen von Spark-Tasks ausführen, ohne Docker-Images neu zu erstellen. Verwenden Sie beispielsweise WebHDFS, um Images zu veröffentlichen. Wir senden eine Anfrage zum Erstellen einer Datei (hier ist {host} der Host des WebHDFS-Dienstes, {port} der Port des WebHDFS-Dienstes, {path-to-file-on-hdfs} der gewünschte Pfad zur Datei in HDFS):
curl -i -X PUT "http://{host}:{port}/webhdfs/v1/{path-to-file-on-hdfs}?op=CREATE
Dies wird eine Antwort des Formulars erhalten (hier ist {location} die URL, die zum Herunterladen der Datei verwendet werden muss):
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: {location}
Content-Length: 0
Laden Sie die ausführbare Spark-Datei in HDFS (hier ist {Pfad zur lokalen Datei} der Pfad zur ausführbaren Spark-Datei auf dem aktuellen Host):
curl -i -X PUT -T {path-to-local-file} "{location}"
Danach können wir mithilfe der in HDFS hochgeladenen Spark-Datei eine Spark-Übermittlung durchführen (hier ist {Klassenname} der Name der Klasse, die gestartet werden muss, um die Aufgabe abzuschließen):
/opt/spark/bin/spark-submit --name spark-test --class {class-name} --conf spark.executor.instances=3 --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark --conf spark.kubernetes.namespace={project} --conf spark.submit.deployMode=cluster --conf spark.kubernetes.container.image={docker-registry-url}/{repo}/{image-name}:{tag} --conf spark.master=k8s://https://{OKD-API-URL} hdfs://{host}:{port}/{path-to-file-on-hdfs}
Es ist zu beachten, dass Sie möglicherweise die Docker-Datei und das Skript entrypoint.sh ändern müssen, um auf HDFS zuzugreifen und den Betrieb der Aufgabe sicherzustellen. Fügen Sie der Docker-Datei eine Anweisung hinzu, um abhängige Bibliotheken in das Verzeichnis / opt / spark / jars zu kopieren, und fügen Sie die HDFS-Konfigurationsdatei in SPARK_CLASSPATH in den Einstiegspunkt ein. Sch.
Zweiter Anwendungsfall - Apache Livy
Wenn die Aufgabe entwickelt wird und das erhaltene Ergebnis getestet werden muss, stellt sich die Frage, ob sie innerhalb des CI / CD-Prozesses gestartet und der Status ihrer Ausführung verfolgt werden soll. Natürlich können Sie es mit einem lokalen Spark-Submit-Aufruf ausführen, dies erschwert jedoch die CI / CD-Infrastruktur, da Spark auf den CI-Server-Agenten / -Läufern installiert und konfiguriert und der Zugriff auf die Kubernetes-API eingerichtet werden muss. In diesem Fall hat die Zielimplementierung Apache Livy als REST-API zum Ausführen von Spark-Aufgaben verwendet, die im Kubernetes-Cluster gehostet werden. Es kann verwendet werden, um Spark-Tasks im Kubernetes-Cluster mithilfe regulärer cURL-Anforderungen zu starten, die auf der Grundlage jeder CI-Lösung problemlos implementiert werden können. Durch die Platzierung im Kubernetes-Cluster wird das Problem der Authentifizierung bei der Interaktion mit der Kubernetes-API gelöst.
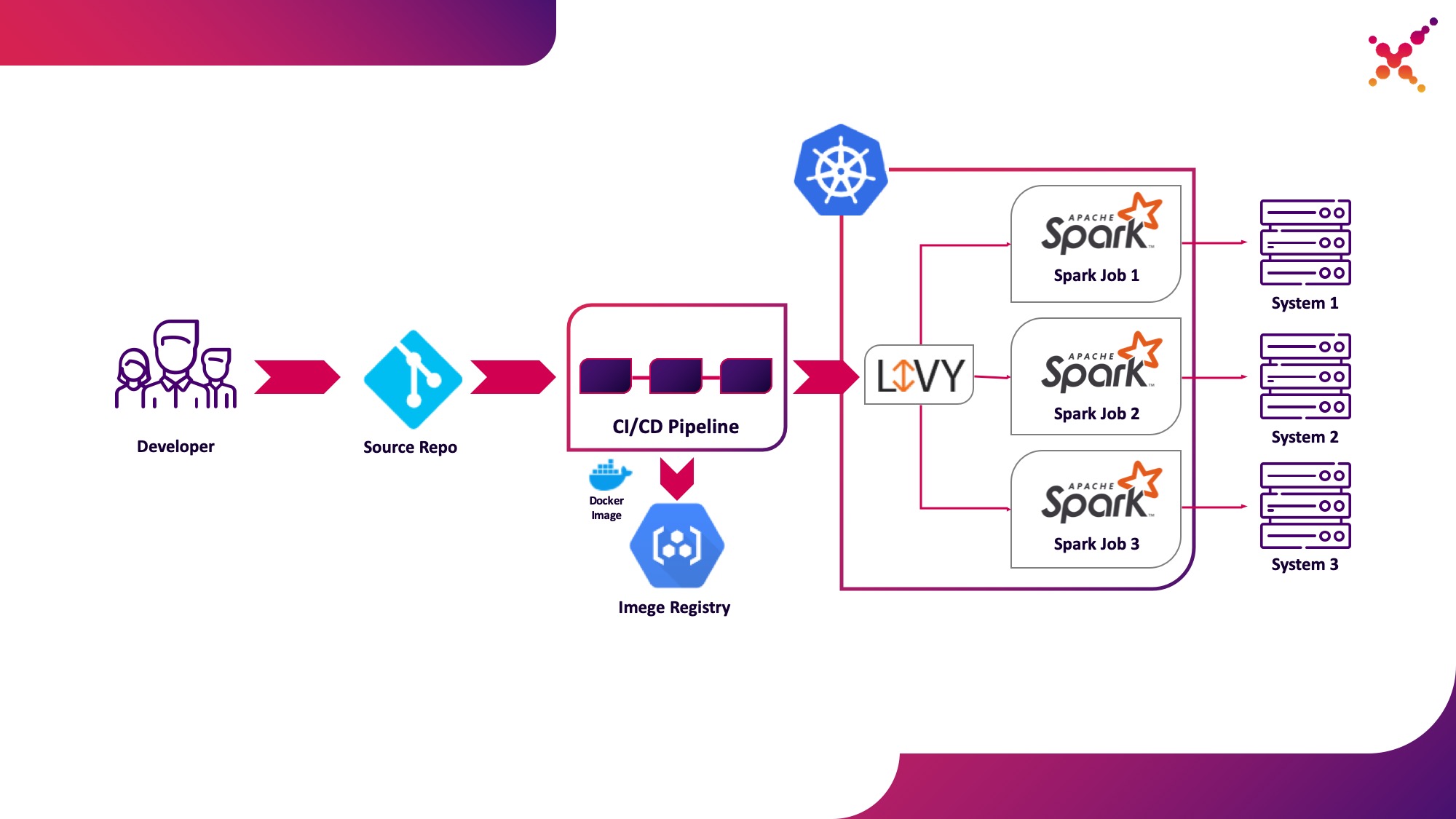
Lassen Sie es uns als zweiten Anwendungsfall hervorheben - Ausführen von Spark-Tasks als Teil des CI / CD-Prozesses auf einem Kubernetes-Cluster in einer Testschleife.
Ein wenig über Apache Livy: Es funktioniert als HTTP-Server, der eine Webschnittstelle und eine RESTful-API bereitstellt, mit der Sie Spark-Submit aus der Ferne ausführen können, indem Sie die erforderlichen Parameter übergeben. Traditionell wurde es als Teil der HDP-Distribution ausgeliefert, kann aber auch für OKD oder eine andere Kubernetes-Installation mithilfe des entsprechenden Manifests und einer Reihe von Docker-Images wie diesem bereitgestellt werden - github.com/ttauveron/k8s-big-data-experiments/tree/master /livy-spark-2.3 . In unserem Fall wurde ein ähnliches Docker-Image erstellt, einschließlich Spark Version 2.4.5 aus der folgenden Docker-Datei:
FROM java:8-alpine
ENV SPARK_HOME=/opt/spark
ENV LIVY_HOME=/opt/livy
ENV HADOOP_CONF_DIR=/etc/hadoop/conf
ENV SPARK_USER=spark
WORKDIR /opt
RUN apk add --update openssl wget bash && \
wget -P /opt https://downloads.apache.org/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz && \
tar xvzf spark-2.4.5-bin-hadoop2.7.tgz && \
rm spark-2.4.5-bin-hadoop2.7.tgz && \
ln -s /opt/spark-2.4.5-bin-hadoop2.7 /opt/spark
RUN wget http://mirror.its.dal.ca/apache/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip && \
unzip apache-livy-0.7.0-incubating-bin.zip && \
rm apache-livy-0.7.0-incubating-bin.zip && \
ln -s /opt/apache-livy-0.7.0-incubating-bin /opt/livy && \
mkdir /var/log/livy && \
ln -s /var/log/livy /opt/livy/logs && \
cp /opt/livy/conf/log4j.properties.template /opt/livy/conf/log4j.properties
ADD livy.conf /opt/livy/conf
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ADD entrypoint.sh /entrypoint.sh
ENV PATH="/opt/livy/bin:${PATH}"
EXPOSE 8998
ENTRYPOINT ["/entrypoint.sh"]
CMD ["livy-server"]
Das generierte Image kann erstellt und in Ihr vorhandenes Docker-Repository hochgeladen werden, z. B. das interne OKD-Repository. Für die Bereitstellung wird das folgende Manifest verwendet ({Registrierungs-URL} ist die URL der Docker-Image-Registrierung, {Image-Name} ist der Name des Docker-Image, {Tag} ist das Tag des Docker-Image, {Livy-URL} ist die gewünschte URL, unter der der Server verfügbar sein wird Livy; das "Route" -Manifest wird verwendet, wenn Red Hat OpenShift als Kubernetes-Distribution verwendet wird, andernfalls wird das entsprechende Ingress- oder Service-Manifest vom Typ NodePort verwendet.
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: livy
name: livy
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
component: livy
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
component: livy
spec:
containers:
- command:
- livy-server
env:
- name: K8S_API_HOST
value: localhost
- name: SPARK_KUBERNETES_IMAGE
value: 'gnut3ll4/spark:v1.0.14'
image: '{registry-url}/{image-name}:{tag}'
imagePullPolicy: Always
name: livy
ports:
- containerPort: 8998
name: livy-rest
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log/livy
name: livy-log
- mountPath: /opt/.livy-sessions/
name: livy-sessions
- mountPath: /opt/livy/conf/livy.conf
name: livy-config
subPath: livy.conf
- mountPath: /opt/spark/conf/spark-defaults.conf
name: spark-config
subPath: spark-defaults.conf
- command:
- /usr/local/bin/kubectl
- proxy
- '--port'
- '8443'
image: 'gnut3ll4/kubectl-sidecar:latest'
imagePullPolicy: Always
name: kubectl
ports:
- containerPort: 8443
name: k8s-api
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: spark
serviceAccountName: spark
terminationGracePeriodSeconds: 30
volumes:
- emptyDir: {}
name: livy-log
- emptyDir: {}
name: livy-sessions
- configMap:
defaultMode: 420
items:
- key: livy.conf
path: livy.conf
name: livy-config
name: livy-config
- configMap:
defaultMode: 420
items:
- key: spark-defaults.conf
path: spark-defaults.conf
name: livy-config
name: spark-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: livy-config
data:
livy.conf: |-
livy.spark.deploy-mode=cluster
livy.file.local-dir-whitelist=/opt/.livy-sessions/
livy.spark.master=k8s://http://localhost:8443
livy.server.session.state-retain.sec = 8h
spark-defaults.conf: 'spark.kubernetes.container.image "gnut3ll4/spark:v1.0.14"'
---
apiVersion: v1
kind: Service
metadata:
labels:
app: livy
name: livy
spec:
ports:
- name: livy-rest
port: 8998
protocol: TCP
targetPort: 8998
selector:
component: livy
sessionAffinity: None
type: ClusterIP
---
apiVersion: route.openshift.io/v1
kind: Route
metadata:
labels:
app: livy
name: livy
spec:
host: {livy-url}
port:
targetPort: livy-rest
to:
kind: Service
name: livy
weight: 100
wildcardPolicy: None
Nach der Anwendung und dem erfolgreichen Start des Pods ist die grafische Oberfläche von Livy unter folgendem Link verfügbar: http: // {livy-url} / ui. Mit Livy können wir unsere Spark-Aufgabe mithilfe einer REST-Anfrage veröffentlichen, beispielsweise von Postman. Ein Beispiel für eine Sammlung mit Anforderungen ist unten dargestellt (im Array "args" können Konfigurationsargumente mit Variablen übergeben werden, die für die Ausführung der laufenden Aufgabe erforderlich sind):
{
"info": {
"_postman_id": "be135198-d2ff-47b6-a33e-0d27b9dba4c8",
"name": "Spark Livy",
"schema": "https://schema.getpostman.com/json/collection/v2.1.0/collection.json"
},
"item": [
{
"name": "1 Submit job with jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar\", \n\t\"className\": \"org.apache.spark.examples.SparkPi\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-1\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t}\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
},
{
"name": "2 Submit job without jar",
"request": {
"method": "POST",
"header": [
{
"key": "Content-Type",
"value": "application/json"
}
],
"body": {
"mode": "raw",
"raw": "{\n\t\"file\": \"hdfs://{host}:{port}/{path-to-file-on-hdfs}\", \n\t\"className\": \"{class-name}\",\n\t\"numExecutors\":1,\n\t\"name\": \"spark-test-2\",\n\t\"proxyUser\": \"0\",\n\t\"conf\": {\n\t\t\"spark.jars.ivy\": \"/tmp/.ivy\",\n\t\t\"spark.kubernetes.authenticate.driver.serviceAccountName\": \"spark\",\n\t\t\"spark.kubernetes.namespace\": \"{project}\",\n\t\t\"spark.kubernetes.container.image\": \"{docker-registry-url}/{repo}/{image-name}:{tag}\"\n\t},\n\t\"args\": [\n\t\t\"HADOOP_CONF_DIR=/opt/spark/hadoop-conf\",\n\t\t\"MASTER=k8s://https://kubernetes.default.svc:8443\"\n\t]\n}"
},
"url": {
"raw": "http://{livy-url}/batches",
"protocol": "http",
"host": [
"{livy-url}"
],
"path": [
"batches"
]
}
},
"response": []
}
],
"event": [
{
"listen": "prerequest",
"script": {
"id": "41bea1d0-278c-40c9-ad42-bf2e6268897d",
"type": "text/javascript",
"exec": [
""
]
}
},
{
"listen": "test",
"script": {
"id": "3cdd7736-a885-4a2d-9668-bd75798f4560",
"type": "text/javascript",
"exec": [
""
]
}
}
],
"protocolProfileBehavior": {}
}
Lassen Sie uns die erste Anforderung aus der Sammlung ausführen, zur OKD-Oberfläche gehen und überprüfen, ob die Aufgabe erfolgreich gestartet wurde - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods. In diesem Fall wird eine Sitzung in der Livy-Oberfläche (http: // {livy-url} / ui) angezeigt, in der Sie mithilfe der Livy-API oder der grafischen Oberfläche den Fortschritt der Aufgabe verfolgen und die Sitzungsprotokolle studieren können.
Lassen Sie uns nun zeigen, wie Livy funktioniert. Untersuchen wir dazu die Protokolle des Livy-Containers im Pod mit dem Livy-Server - https: // {OKD-WEBUI-URL} / console / project / {project} / browse / pods / {livy-pod-name}? Tab = logs. Daraus können Sie ersehen, dass beim Aufrufen der Livy-REST-API in einem Container mit dem Namen "livy" eine Funkenübermittlung ausgeführt wird, ähnlich der oben verwendeten (hier ist {livy-pod-name} der Name des mit dem Livy-Server erstellten Pods). Die Sammlung enthält auch eine zweite Anforderung, mit der Sie Aufgaben mit Remote-Hosting der ausführbaren Spark-Datei über den Livy-Server ausführen können.
Dritter Anwendungsfall - Spark Operator
Nachdem die Aufgabe getestet wurde, stellt sich die Frage, ob sie regelmäßig ausgeführt werden soll. Eine native Methode zum regelmäßigen Ausführen von Aufgaben in einem Kubernetes-Cluster ist die CronJob-Entität, die Sie verwenden können. Derzeit ist die Verwendung von Operatoren zur Steuerung von Anwendungen in Kubernetes sehr beliebt, und für Spark gibt es einen ziemlich ausgereiften Operator, der unter anderem in Lösungen auf Unternehmensebene verwendet wird (z. B. Lightbend FastData Platform). Wir empfehlen die Verwendung - die aktuelle stabile Version von Spark (2.4.5) bietet nur sehr begrenzte Optionen zum Konfigurieren des Starts von Spark-Tasks in Kubernetes, während in der nächsten Hauptversion (3.0.0) die vollständige Unterstützung für Kubernetes angekündigt wird, das Veröffentlichungsdatum jedoch unbekannt bleibt. Der Spark-Operator gleicht diesen Mangel durch Hinzufügen wichtiger Konfigurationsparameter aus (z. B.Mounten von ConfigMap mit Konfiguration des Zugriffs auf Hadoop in Spark-Pods und der Möglichkeit, die Aufgabe regelmäßig nach einem Zeitplan auszuführen.
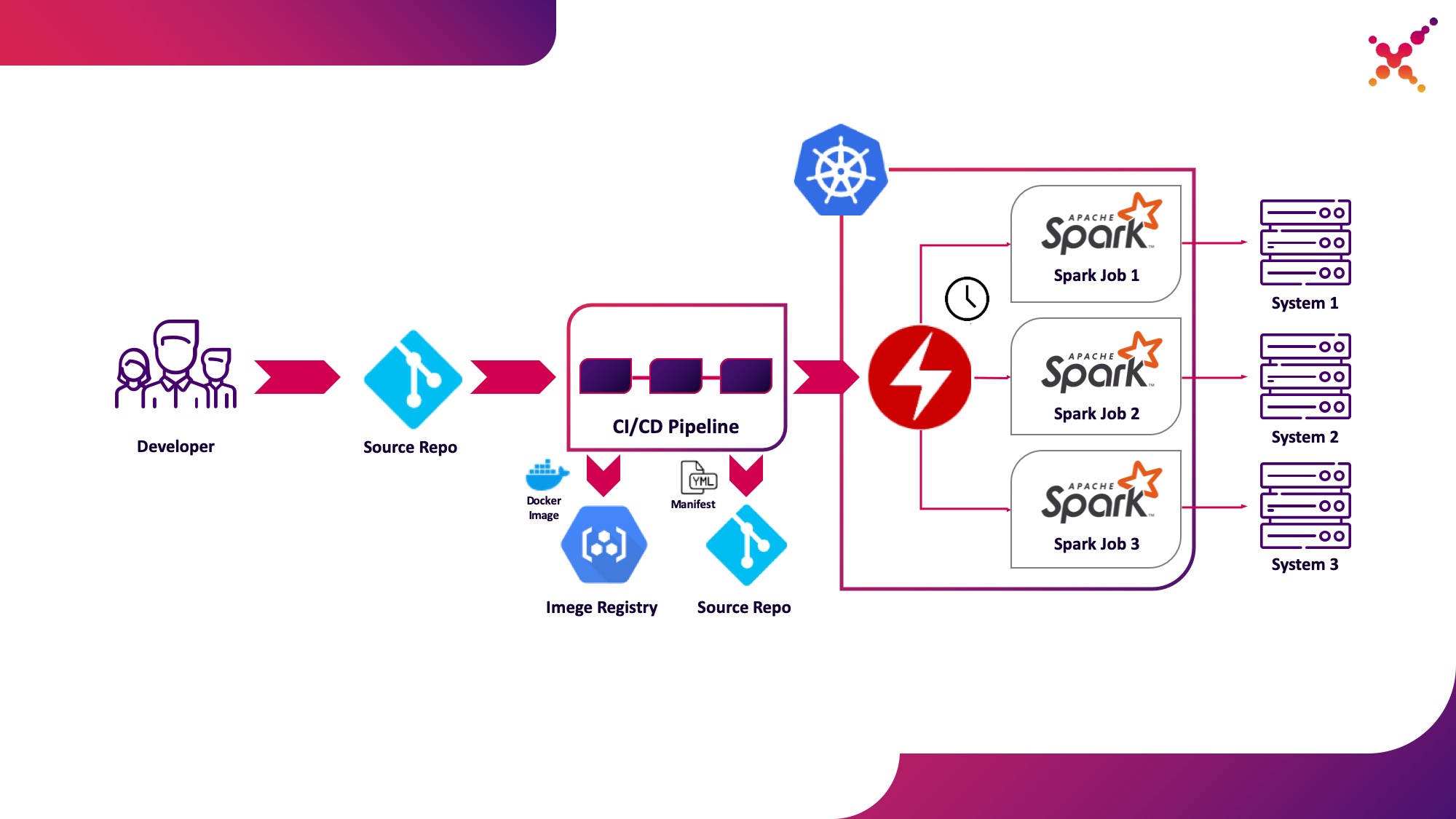
Lassen Sie es uns als dritten Anwendungsfall hervorheben - regelmäßige Ausführung von Spark-Tasks auf einem Kubernetes-Cluster in einer Produktionsschleife.
Spark Operator ist Open Source und wurde als Teil der Google Cloud Platform entwickelt - github.com/GoogleCloudPlatform/spark-on-k8s-operator . Die Installation kann auf drei Arten erfolgen:
- Im Rahmen der Lightbend FastData Platform / Cloudflow-Installation;
- Mit Helm:
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator helm install incubator/sparkoperator --namespace spark-operator
- (https://github.com/GoogleCloudPlatform/spark-on-k8s-operator/tree/master/manifest). — Cloudflow API v1beta1. , Spark Git API, , «v1beta1-0.9.0-2.4.0». CRD, «versions»:
oc get crd sparkapplications.sparkoperator.k8s.io -o yaml
Wenn der Operator korrekt installiert ist, wird im entsprechenden Projekt ein aktiver Pod mit dem Spark-Operator (z. B. cloudflow-fdp-sparkoperator im Cloudflow-Bereich für die Installation von Cloudflow) und der entsprechende Kubernetes-Ressourcentyp mit dem Namen "sparkapplications" angezeigt. Sie können die verfügbaren Spark-Anwendungen mit dem folgenden Befehl untersuchen:
oc get sparkapplications -n {project}
Um Aufgaben mit Spark Operator auszuführen, müssen Sie drei Dinge tun:
- Erstellen Sie ein Docker-Image, das alle erforderlichen Bibliotheken sowie Konfigurations- und ausführbare Dateien enthält. Im Zielbild ist dies ein Bild, das im CI / CD-Stadium erstellt und in einem Testcluster getestet wurde.
- Veröffentlichen Sie das Docker-Image in der Registrierung, auf die über den Kubernetes-Cluster zugegriffen werden kann.
- «SparkApplication» . (, github.com/GoogleCloudPlatform/spark-on-k8s-operator/blob/v1beta1-0.9.0-2.4.0/examples/spark-pi.yaml). :
- «apiVersion» API, ;
- «metadata.namespace» , ;
- «spec.image» Docker ;
- «spec.mainClass» Spark, ;
- «spec.mainApplicationFile» jar ;
- Das Wörterbuch "spec.sparkVersion" muss die verwendete Version von Spark angeben.
- Das Wörterbuch "spec.driver.serviceAccount" muss ein Dienstkonto im entsprechenden Kubernetes-Namespace enthalten, das zum Starten der Anwendung verwendet wird.
- Das Wörterbuch "spec.executor" sollte die Menge der der Anwendung zugewiesenen Ressourcen angeben.
- Das Wörterbuch "spec.volumeMounts" muss das lokale Verzeichnis angeben, in dem die lokalen Spark-Aufgabendateien erstellt werden.
Ein Beispiel für das Generieren eines Manifests (hier ist {spark-service-account} ein Dienstkonto im Kubernetes-Cluster zum Ausführen von Spark-Tasks):
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 0.1
coreLimit: "200m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: {spark-service-account}
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Dieses Manifest gibt ein Dienstkonto an, für das Sie vor dem Veröffentlichen des Manifests die erforderlichen Rollenbindungen erstellen müssen, die die erforderlichen Zugriffsrechte für die Spark-Anwendung bereitstellen, um mit der Kubernetes-API zu interagieren (falls erforderlich). In unserem Fall benötigt die Anwendung die Rechte zum Erstellen von Pods. Erstellen wir die erforderliche Rollenbindung:
oc adm policy add-role-to-user edit system:serviceaccount:{project}:{spark-service-account} -n {project}
Es ist auch erwähnenswert, dass die Spezifikation dieses Manifests den Parameter hadoopConfigMap angeben kann, mit dem Sie eine ConfigMap mit einer Hadoop-Konfiguration angeben können, ohne zuerst die entsprechende Datei im Docker-Image platzieren zu müssen. Es eignet sich auch für den regulären Start von Aufgaben. Mit dem Parameter "Zeitplan" kann ein Zeitplan für den Start dieser Aufgabe festgelegt werden.
Danach speichern wir unser Manifest in der Datei spark-pi.yaml und wenden es auf unseren Kubernetes-Cluster an:
oc apply -f spark-pi.yaml
Dadurch wird ein Objekt vom Typ "sparkapplications" erstellt:
oc get sparkapplications -n {project}
> NAME AGE
> spark-pi 22h
Dadurch wird ein Pod mit einer Anwendung erstellt, deren Status in den erstellten "Sparkapplications" angezeigt wird. Es kann mit dem folgenden Befehl angezeigt werden:
oc get sparkapplications spark-pi -o yaml -n {project}
Nach Abschluss der Aufgabe wechselt der POD in den Status "Abgeschlossen", der ebenfalls auf "Funkenanwendungen" aktualisiert wird. Anwendungsprotokolle können in einem Browser oder mit dem folgenden Befehl angezeigt werden (hier ist {sparkapplications-pod-name} der Name des Pods der laufenden Aufgabe):
oc logs {sparkapplications-pod-name} -n {project}
Spark-Aufgaben können auch mit dem speziellen Dienstprogramm sparkctl verwaltet werden. Um es zu installieren, klonen wir das Repository mit seinem Quellcode, installieren Go und erstellen dieses Dienstprogramm:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator/
wget https://dl.google.com/go/go1.13.3.linux-amd64.tar.gz
tar -xzf go1.13.3.linux-amd64.tar.gz
sudo mv go /usr/local
mkdir $HOME/Projects
export GOROOT=/usr/local/go
export GOPATH=$HOME/Projects
export PATH=$GOPATH/bin:$GOROOT/bin:$PATH
go -version
cd sparkctl
go build -o sparkctl
sudo mv sparkctl /usr/local/bin
Lassen Sie uns die Liste der ausgeführten Spark-Aufgaben untersuchen:
sparkctl list -n {project}
Erstellen wir eine Beschreibung für die Spark-Aufgabe:
vi spark-app.yaml
apiVersion: "sparkoperator.k8s.io/v1beta1"
kind: SparkApplication
metadata:
name: spark-pi
namespace: {project}
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.0"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar"
sparkVersion: "2.4.0"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1000m"
memory: "512m"
labels:
version: 2.4.0
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.0
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
Beginnen wir die beschriebene Aufgabe mit sparkctl:
sparkctl create spark-app.yaml -n {project}
Lassen Sie uns die Liste der ausgeführten Spark-Aufgaben untersuchen:
sparkctl list -n {project}
Lassen Sie uns die Liste der Ereignisse der gestarteten Spark-Aufgabe untersuchen:
sparkctl event spark-pi -n {project} -f
Lassen Sie uns den Status der laufenden Spark-Task untersuchen:
sparkctl status spark-pi -n {project}
Abschließend möchte ich die entdeckten Nachteile des Betriebs der aktuellen stabilen Version von Spark (2.4.5) in Kubernetes betrachten:
- , , — Data Locality. YARN , , ( ). Spark , , , . Kubernetes , . , , , , Spark . , Kubernetes (, Alluxio), Kubernetes.
- — . , Spark , Kerberos ( 3.0.0, ), Spark (https://spark.apache.org/docs/2.4.5/security.html) YARN, Mesos Standalone Cluster. , Spark, — , , . root, , UID, ( PodSecurityPolicies ). Docker, Spark , .
- Das Ausführen von Spark-Tasks mit Kubernetes befindet sich offiziell noch im experimentellen Modus. In Zukunft können sich die verwendeten Artefakte (Konfigurationsdateien, Docker-Basisimages und Startskripte) erheblich ändern. Bei der Vorbereitung des Materials wurden die Versionen 2.3.0 und 2.4.5 getestet. Das Verhalten war jedoch erheblich anders.
Wir werden auf Updates warten - kürzlich wurde eine neue Version von Spark (3.0.0) veröffentlicht, die konkrete Änderungen an der Arbeit von Spark auf Kubernetes mit sich brachte, aber den experimentellen Status der Unterstützung für diesen Ressourcenmanager beibehielt. Vielleicht können Sie mit den nächsten Updates wirklich empfehlen, YARN aufzugeben und Spark-Tasks auf Kubernetes auszuführen, ohne die Sicherheit Ihres Systems zu fürchten und ohne funktionale Komponenten unabhängig zu verfeinern.
Flosse.