Es gab viele Kontroversen darüber, wie Software mit erhöhter Zuverlässigkeit erstellt werden kann, Methoden, Ansätze für die Organisation der Entwicklung und Tools wurden diskutiert. Bei all diesen Diskussionen geht jedoch verloren, dass Softwareentwicklung ein Prozess ist , der recht gut untersucht und formalisiert ist. Wenn Sie sich diesen Prozess ansehen, werden Sie feststellen, dass sich dieser Prozess nicht nur darauf konzentriert, wie der Code geschrieben / generiert wird, sondern auch darauf, wie dieser Code überprüft wird. Vor allem erfordert die Entwicklung die Verwendung von Tools, denen Sie "vertrauen" können.
Diese kurze Tour ist vorbei und wir werden sehen, wie sich der Code als zuverlässig erwiesen hat. Zunächst müssen Sie die Eigenschaften des Codes verstehen, die die Zuverlässigkeitsanforderungen erfüllen. Der Begriff "Codezuverlässigkeit" sieht eher vage und widersprüchlich aus. Daher ziehe ich es vor, nichts zu erfinden, und bei der Beurteilung der Zuverlässigkeit des Codes orientiere ich mich an Industriestandards, beispielsweise GOST R ISO 26262 oder KT-178C. Der Wortlaut ist unterschiedlich, aber die Idee ist dieselbe: Zuverlässiger Code wird nach einem einzigen Standard (dem sogenannten Codierungsstandard ) entwickelt und die Anzahl der darin enthaltenen Laufzeitfehler wird minimiert. Hier ist jedoch nicht alles so einfach - die Standards sehen Situationen vor, in denen beispielsweise die Einhaltung des Codierungsstandards nicht möglich ist und eine solche Abweichung dokumentiert werden muss
Gefährlicher Sumpf MISRA und dergleichen
Codierungsstandards sollen die Verwendung von Programmiersprachenkonstrukten einschränken, die möglicherweise gefährlich sein können. Theoretisch sollte dies die Qualität des Codes verbessern, oder? Ja, dies stellt die Qualität des Codes sicher, aber es ist immer wichtig zu bedenken, dass die 100% ige Einhaltung der Codierungsregeln kein Selbstzweck ist. Wenn der Code zu 100% den Regeln einiger MISRA entspricht, bedeutet dies überhaupt nicht, dass er gut und korrekt ist. Sie können viel Zeit mit Refactoring verbringen, um Verstöße gegen den Codierungsstandard zu beseitigen. All dies wird jedoch verschwendet, wenn der Code nicht ordnungsgemäß funktioniert oder Laufzeitfehler enthält. Darüber hinaus sind die Regeln von MISRA oder CERT normalerweise nur ein Teil des im Unternehmen festgelegten Kodierungsstandards.
Statische Analyse ist kein Allheilmittel
Die Standards schreiben eine systematische Codeüberprüfung vor, um Fehler im Code zu finden und den Code für Codierungsstandards zu analysieren.
Die üblicherweise für diesen Zweck verwendeten statischen Analysetools können Fehler gut erkennen, beweisen jedoch nicht, dass der Quellcode frei von Laufzeitfehlern ist. Und viele Fehler, die von statischen Analysegeräten erkannt werden, sind tatsächlich falsch positive Ergebnisse von Werkzeugen. Infolgedessen reduziert die Verwendung dieser Tools den Zeitaufwand für die Überprüfung des Codes nicht wesentlich, da die Ergebnisse der Überprüfung überprüft werden müssen. Schlimmer noch, sie erkennen möglicherweise keine Laufzeitfehler, was für Anwendungen, die eine hohe Zuverlässigkeit erfordern, nicht akzeptabel ist.
Formale Codeüberprüfung
Statische Analysatoren sind daher nicht immer in der Lage, Laufzeitfehler zu erkennen. Wie können sie erkannt und beseitigt werden? In diesem Fall ist eine formale Überprüfung des Quellcodes erforderlich.
Zunächst müssen Sie verstehen, um was für ein Tier es sich handelt? Die formale Überprüfung ist der Nachweis des fehlerfreien Codes mit formalen Methoden. Es klingt beängstigend, aber in der Tat - es ist wie ein Beweis für einen Satz von Matan. Hier gibt es keine Magie. Diese Methode unterscheidet sich von der herkömmlichen statischen Analyse durch die Verwendung einer abstrakten Interpretationeher als Heuristiken. Dies gibt uns Folgendes: Wir können beweisen, dass der Code keine spezifischen Laufzeitfehler enthält. Was sind diese Fehler? Dies sind alle Arten von Array-Überläufen, Division durch Null, Ganzzahl-Überlauf usw. Ihre Gemeinheit liegt in der Tatsache, dass der Compiler Code sammelt, der solche Fehler enthält (da dieser Code syntaktisch korrekt ist), aber wenn dieser Code ausgeführt wird, werden sie angezeigt.
Schauen wir uns ein Beispiel an. Unten in den Spoilern befindet sich der Code für einen einfachen PI-Regler:
Code anzeigen
pictrl.c
#include "pi_control.h"
/* Global variable definitions */
float inp_volt[2];
float integral_state;
float duty_cycle;
float direction;
float normalized_error;
/* Static functions */
static void pi_alg(float Kp, float Ki);
static void process_inputs(void);
/* control_task implements a PI controller algorithm that ../
*
* - reads inputs from hardware on actual and desired position
* - determines error between actual and desired position
* - obtains controller gains
* - calculates direction and duty cycle of PWM output using PI control algorithm
* - sets PWM output to hardware
*
*/
void control_task(void)
{
float Ki;
float Kp;
/* Read inputs from hardware */
read_inputs();
/* Convert ADC values to their respective voltages provided read failure did not occur, otherwise do not update input values */
if (!read_failure) {
inp_volt[0] = 0.0048828125F * (float) inp_val[0];
inp_volt[1] = 0.0048828125F * (float) inp_val[1];
}
/* Determine error */
process_inputs();
/* Determine integral and proprortional controller gains */
get_control_gains(&Kp,&Ki);
/* PI control algorithm */
pi_alg(Kp, Ki);
/* Set output pins on hardware */
set_outputs();
}
/* process_inputs computes the error between the actual and desired position by
* normalizing the input values using lookup tables and then taking the difference */
static void process_inputs(void)
{
/* local variables */
float rtb_AngleNormalization;
float rtb_PositionNormalization;
/* Normalize voltage values */
look_up_even( &(rtb_AngleNormalization), inp_volt[1], angle_norm_map, angle_norm_vals);
look_up_even( &(rtb_PositionNormalization), inp_volt[0], pos_norm_map, pos_norm_vals);
/* Compute error */
normalized_error = rtb_PositionNormalization - rtb_AngleNormalization;
}
/* look_up_even provides a lookup table algorithm that works for evenly spaced values.
*
* Inputs to the function are...
* pY - pointer to the output value
* u - input value
* map - structure containing the static lookup table data...
* valueLo - minimum independent axis value
* uSpacing - increment size of evenly spaced independent axis
* iHi - number of increments available in pYData
* pYData - pointer to array of values that make up dependent axis of lookup table
*
*/
void look_up_even( float *pY, float u, map_data map, float *pYData)
{
/* If input is below range of lookup table, output is minimum value of lookup table (pYData) */
if (u <= map.valueLo )
{
pY[1] = pYData[1];
}
else
{
/* Determine index of output into pYData based on input and uSpacing */
float uAdjusted = u - map.valueLo;
unsigned int iLeft = uAdjusted / map.uSpacing;
/* If input is above range of lookup table, output is maximum value of lookup table (pYData) */
if (iLeft >= map.iHi )
{
(*pY) = pYData[map.iHi];
}
/* If input is in range of lookup table, output will interpolate between lookup values */
else
{
{
float lambda; // fractional part of difference between input and nearest lower table value
{
float num = uAdjusted - ( iLeft * map.uSpacing );
lambda = num / map.uSpacing;
}
{
float yLeftCast; // table value that is just lower than input
float yRghtCast; // table value that is just higher than input
yLeftCast = pYData[iLeft];
yRghtCast = pYData[((iLeft)+1)];
if (lambda != 0) {
yLeftCast += lambda * ( yRghtCast - yLeftCast );
}
(*pY) = yLeftCast;
}
}
}
}
}
static void pi_alg(float Kp, float Ki)
{
{
float control_output;
float abs_control_output;
/* y = integral_state + Kp*error */
control_output = Kp * normalized_error + integral_state;
/* Determine direction of torque based on sign of control_output */
if (control_output >= 0.0F) {
direction = TRUE;
} else {
direction = FALSE;
}
/* Absolute value of control_output */
if (control_output < 0.0F) {
abs_control_output = -control_output;
} else if (control_output > 0.0F) {
abs_control_output = control_output;
}
/* Saturate duty cycle to be less than 1 */
if (abs_control_output > 1.0F) {
duty_cycle = 1.0F;
} else {
duty_cycle = abs_control_output;
}
/* integral_state = integral_state + Ki*Ts*error */
integral_state = Ki * normalized_error * 1.0e-002F + integral_state;
}
}
pi_control.h
/* Lookup table structure */
typedef struct {
float valueLo;
unsigned int iHi;
float uSpacing;
} map_data;
/* Macro definitions */
#define TRUE 1
#define FALSE 0
/* Global variable declarations */
extern unsigned short inp_val[];
extern map_data angle_norm_map;
extern float angle_norm_vals[11];
extern map_data pos_norm_map;
extern float pos_norm_vals[11];
extern float inp_volt[2];
extern float integral_state;
extern float duty_cycle;
extern float direction;
extern float normalized_error;
extern unsigned char read_failure;
/* Function declarations */
void control_task(void);
void look_up_even( float *pY, float u, map_data map, float *pYData);
extern void read_inputs(void);
extern void set_outputs(void);
extern void get_control_gains(float* c_prop, float* c_int);
Lassen Sie uns den Test mit Polyspace Bug Finder , einem zertifizierten und qualifizierten statischen Analysator, ausführen und die folgenden Ergebnisse erhalten:
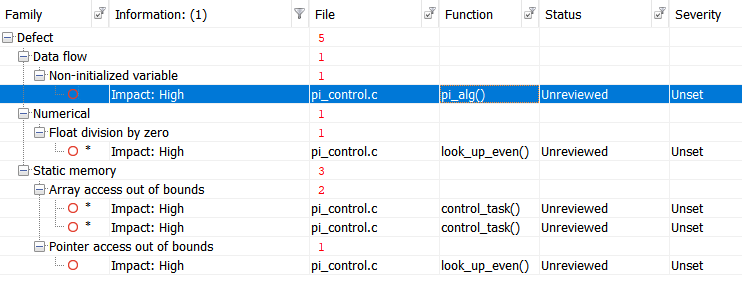
Zur Vereinfachung tabellieren wir die Ergebnisse:
Ergebnisse anzeigen
|
|
|
|
| Non-initialized variable
|
Local variable 'abs_control_output' may be read before being initialized.
|
159
|
| Float division by zero
|
Divisor is 0.0.
|
99
|
| Array access out of bounds
|
Attempt to access element out of the array bounds.
Valid index range starts at 0. |
38
|
| Array access out of bounds
|
Attempt to access element out of the array bounds.
Valid index range starts at 0. |
39
|
| Pointer access out of bounds
|
Attempt to dereference pointer outside of the pointed object at offset 1.
|
93
|
Lassen Sie uns nun denselben Code mit dem formalen Überprüfungstool Polyspace Code Prover überprüfen:
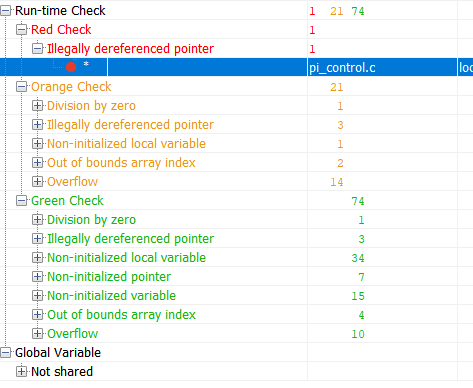
Grün in den Ergebnissen ist Code, der nachweislich frei von Laufzeitfehlern ist. Rot - nachgewiesener Fehler. Orange - Das Tool hat keine Daten mehr. Die grün markierten Ergebnisse sind die interessantesten. Wenn für einen Teil des Codes das Fehlen eines Laufzeitfehlers nachgewiesen wurde, kann für diesen Teil des Codes der Testaufwand erheblich reduziert werden (z. B. kann der Robustheitstest nicht mehr durchgeführt werden). Schauen wir uns nun die Übersichtstabelle mit potenziellen und nachgewiesenen Fehlern an:
Ergebnisse anzeigen
|
|
|
|
| Out of bounds array index
|
38
|
Warning: array index may be outside bounds: [array size undefined]
|
| Out of bounds array index
|
39
|
Warning: array index may be outside bounds: [array size undefined]
|
| Overflow
|
70
|
Warning: operation [-] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Illegally dereferenced pointer
|
93
|
Error: pointer is outside its bounds
|
| Overflow
|
98
|
Warning: operation [-] on float may overflow (result strictly greater than MAX FLOAT32)
|
| Division by zero
|
99
|
Warning: float division by zero may occur
|
| Overflow
|
99
|
Warning: operation [conversion from float32 to unsigned int32] on scalar may overflow (on MIN or MAX bounds of UINT32)
|
| Overflow
|
99
|
Warning: operation [/] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Illegally dereferenced pointer
|
104
|
Warning: pointer may be outside its bounds
|
| Overflow
|
114
|
Warning: operation [-] on float may overflow (result strictly greater than MAX FLOAT32)
|
| Overflow
|
114
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
115
|
Warning: operation [/] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Illegally dereferenced pointer
|
121
|
Warning: pointer may be outside its bounds
|
| Illegally dereferenced pointer
|
122
|
Warning: pointer may be outside its bounds
|
| Overflow
|
124
|
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
124
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
124
|
Warning: operation [-] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
142
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
142
|
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Non-uninitialized local variable
|
159
|
Warning: local variable may be non-initialized (type: float 32)
|
| Overflow
|
166
|
Warning: operation [*] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
| Overflow
|
166
|
Warning: operation [+] on float may overflow (on MIN or MAX bounds of FLOAT32)
|
Diese Tabelle sagt mir Folgendes: In
Zeile 93 ist ein Laufzeitfehler aufgetreten, der garantiert auftritt. Die restlichen Warnungen zeigen an, dass ich die Überprüfung entweder falsch konfiguriert habe oder einen Sicherheitscode schreiben oder auf andere Weise überwinden muss.
Es mag scheinen, dass die formale Überprüfung sehr cool ist und das gesamte Projekt unkontrolliert überprüft werden sollte. Wie bei jedem Instrument gibt es jedoch Einschränkungen, die sich hauptsächlich auf die Zeitkosten beziehen. Kurz gesagt, die formale Überprüfung ist langsam. So langsam. Die Leistung wird durch die mathematische Komplexität sowohl der abstrakten Interpretation selbst als auch des Volumens des zu verifizierenden Codes begrenzt. Daher sollten Sie nicht versuchen, den Linux-Kernel schnell zu überprüfen. Alle Überprüfungsprojekte in Polyspace können in Module unterteilt werden, die unabhängig voneinander überprüft werden können, und jedes Modul hat seine eigene Konfiguration. Das heißt, wir können die Verifizierungsgründlichkeit für jedes Modul separat anpassen.
"Vertrauen" in Werkzeuge
Wenn Sie sich mit Industriestandards wie KT-178C oder GOST R ISO 26262 beschäftigen, stoßen Sie ständig auf Dinge wie "Vertrauen in das Werkzeug" oder "Qualifizierung des Werkzeugs". Was ist es? In diesem Prozess zeigen Sie, dass die Ergebnisse der im Projekt verwendeten Entwicklungs- oder Testtools vertrauenswürdig sind und ihre Fehler dokumentiert werden. Dieser Prozess ist ein Thema für einen separaten Artikel, da nicht alles offensichtlich ist. Die Hauptsache hier ist die folgende: Die in der Branche verwendeten Tools werden immer mit einer Reihe von Dokumenten und Tests geliefert, die bei diesem Prozess hilfreich sind.
Ergebnis
Anhand eines einfachen Beispiels haben wir den Unterschied zwischen klassischer statischer Analyse und formaler Verifikation untersucht. Kann es außerhalb von Projekten angewendet werden, bei denen Industriestandards eingehalten werden müssen? Natürlich kannst du. Sie können sogar für eine Testversion fragen hier .
Übrigens, wenn Sie interessiert sind, können Sie einen separaten Artikel über die Instrumentenzertifizierung verfassen. Schreiben Sie in die Kommentare, wenn Sie einen solchen Artikel benötigen.