
Heute werden wir Ihnen ohne Bezugnahme auf bestimmte Modelle von Netzwerkgeräten erklären, wie das Prinzip "von der Automatisierung zur Autonomie" in den neuen Funktionen des FabricInsight-Produkts enthalten ist. In der Tat hat sich in den letzten Jahren nicht nur die Zusammensetzung geändert, sondern es sind auch zahlreiche neue Szenarien aufgetreten, die es ermöglichen, den aktuellen Status des Netzwerks zu bestimmen und mögliche Probleme darin vorherzusagen.
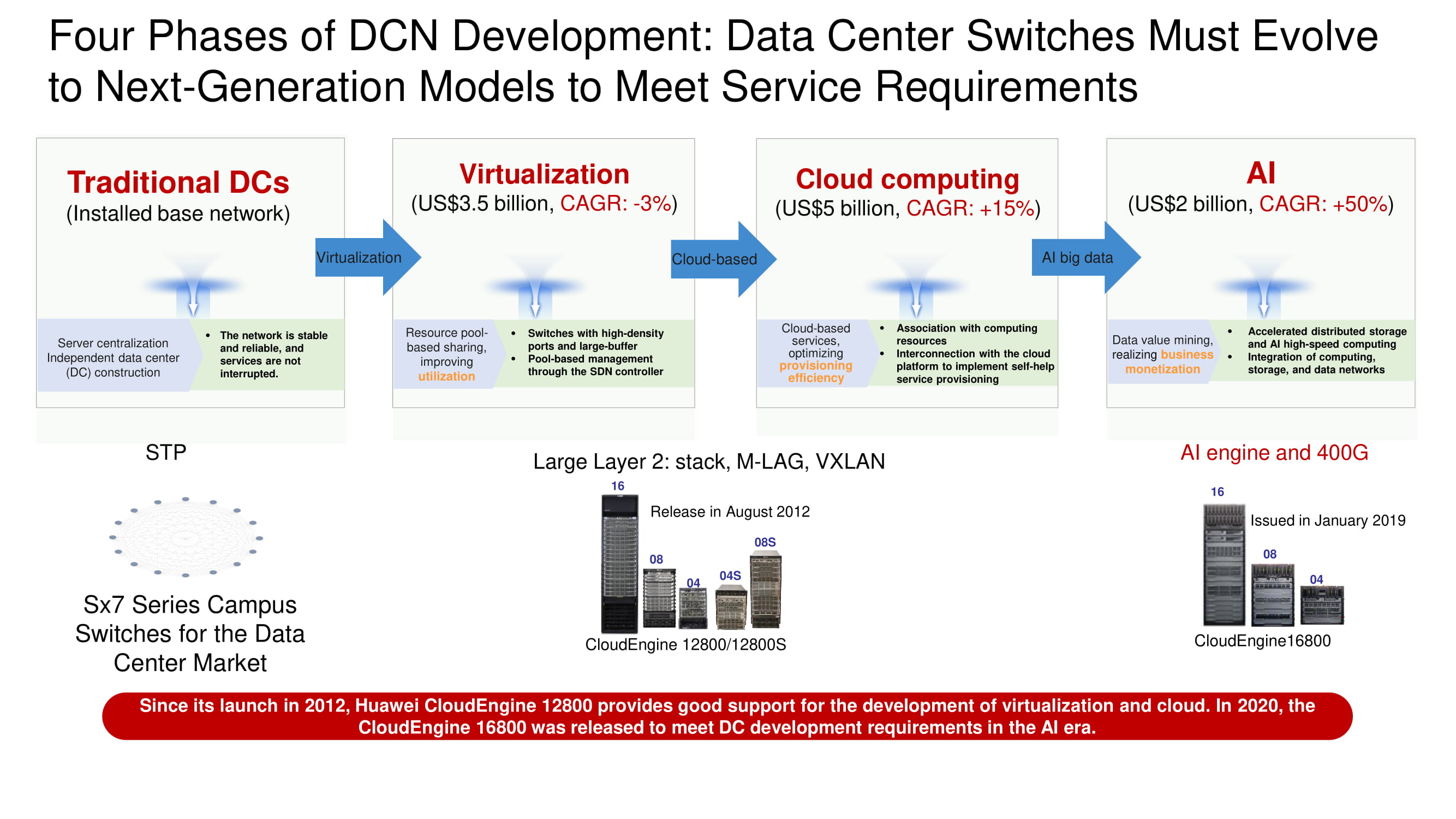
Vier Phasen der Entwicklung von Rechenzentren
Bei der Bestimmung des Entwicklungsvektors von Rechenzentrumsnetzwerken ist leicht zu erkennen, wie traditionelle Rechenzentrumsarchitekturen allmählich unter den Ansturm von Virtualisierungssystemen gerieten, dann eine massive Migration von Ressourcen und Diensten in die Cloud überstanden und nun der weit verbreiteten Einführung künstlicher Intelligenzsysteme und Hochgeschwindigkeitsschnittstellen mit 400 Gbit / s nahe kamen. KI-Funktionen sind erforderlich, um verlustfreie Ethernet-Netzwerke aufzubauen und Anwendungen zu erstellen, die absolut unempfindlich gegen Latenz sind.
Ein weiterer Anwendungsbereich von AI ist die Analyse und Überwachung des Betriebs von Rechenzentren. Wir müssen von einer Ideologie, die eine funktional begrenzte Überwachung des Zustands bestimmter "Black Boxes" impliziert, zu dem Konzept vollständig transparenter Netzwerke übergehen, über die alles bekannt ist.

Als Hauptinfrastruktur-Netzwerkeinheiten für den Aufbau von Rechenzentrumsnetzwerken bietet Huawei jetzt eine Reihe von CloudEngine 16800-Switches mit vier, acht und sechzehn Steckplätzen und 400-Gbit / s-Uplinks an. Ihre Veröffentlichung ist für das laufende Jahr geplant. Unter den neuen Produkten finden wir auch die ToE-Switches CloudEngine 6881 und 6863, die auf unserer eigenen Elementbasis mit 10- bzw. 25-Gbit / s-Schnittstellen basieren.

Die Abbildung zeigt die Modelle von Switches der CloudEngine 16800-Linie mit klassischer orthogonaler Architektur, die mit einem Front-to-Back-Kühlsystem ausgestattet sind, sowie kompatible Leitungskarten mit 10-, 40- und 100-Gbit / s-Schnittstellen.
Von den wichtigen Grundfunktionen von CloudEngine 16800 unterstreichen wir die Fähigkeit, mit NSH (Network Service Header) zu arbeiten, das die Implementierung einer Mikrosegmentierung ermöglicht, die auf mehrere Switches im Rechenzentrum verteilt ist (Isolation auf der Ebene der virtuellen Maschine), umfassende Telemetriefunktionen bietet und den Datenverkehr am Netzwerkrand analysiert (Edge Intelligence) ) unter Verwendung von Technologien für künstliche Intelligenz, die auf Huawei AI-Chips basieren.
Der V1R19C10 wird wirklich revolutionär sein. Darin sollten viele lang erwartete Funktionen implementiert werden, einschließlich EVPN Multihoming ohne einen "Jumper" in Form von M-LAG (Multi-Switch Link Aggregation) basierend auf dem ersten und vierten Routentyp im EVPN VXLAN-Routing.
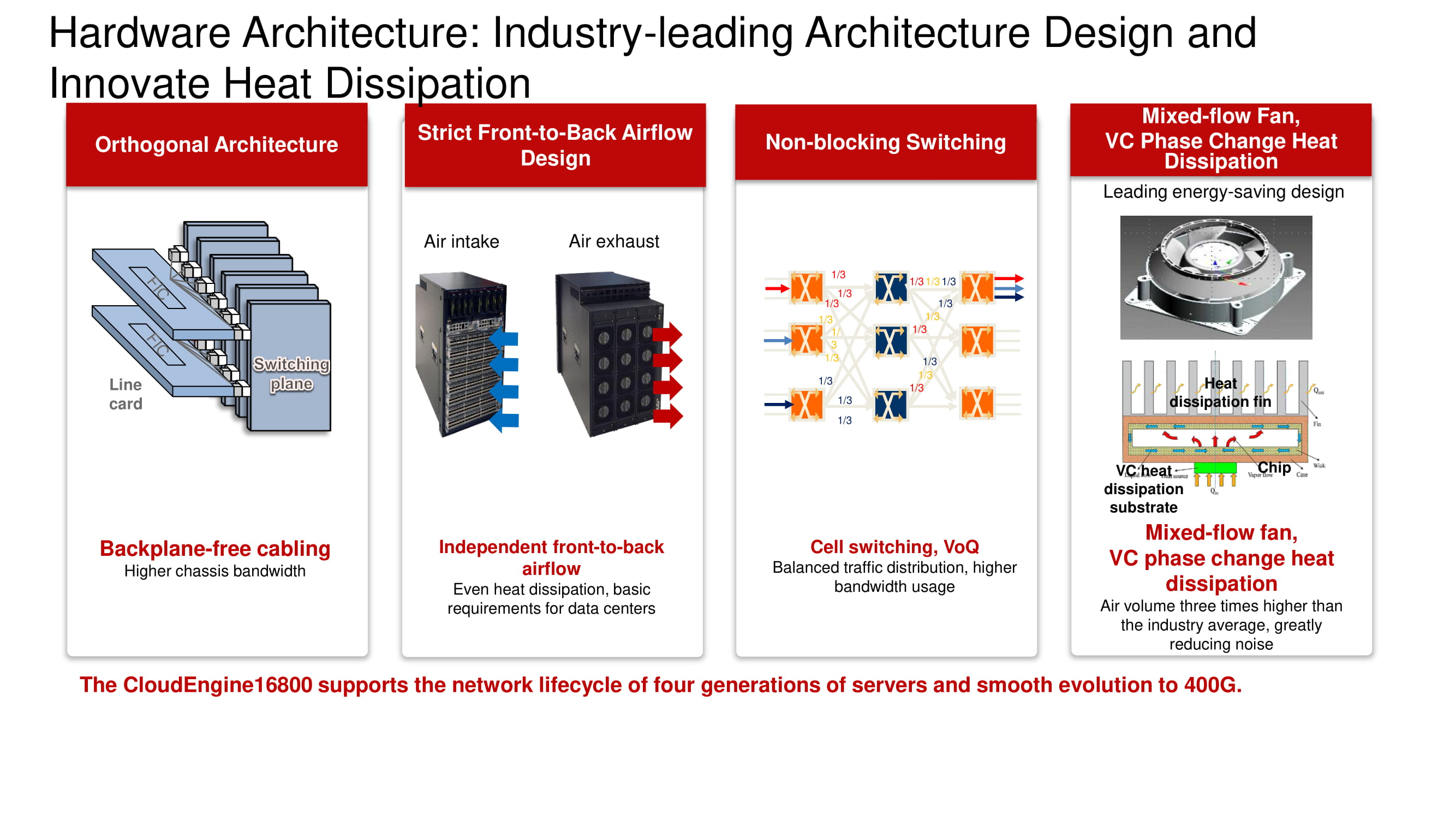
Vertraute Architektur und neue Möglichkeiten
Das Diagramm zeigt die bekannte orthogonale Architektur eines dreistufigen "Factory" Non-Blocking Switching. Zu den Hauptvorteilen gehört die optimale Anordnung der "Werks" -Karten, Leitungskarten, Steckverbinder und eines Gebläsesystems auf der Basis von Ventilatoren mit variabler Drehzahl.
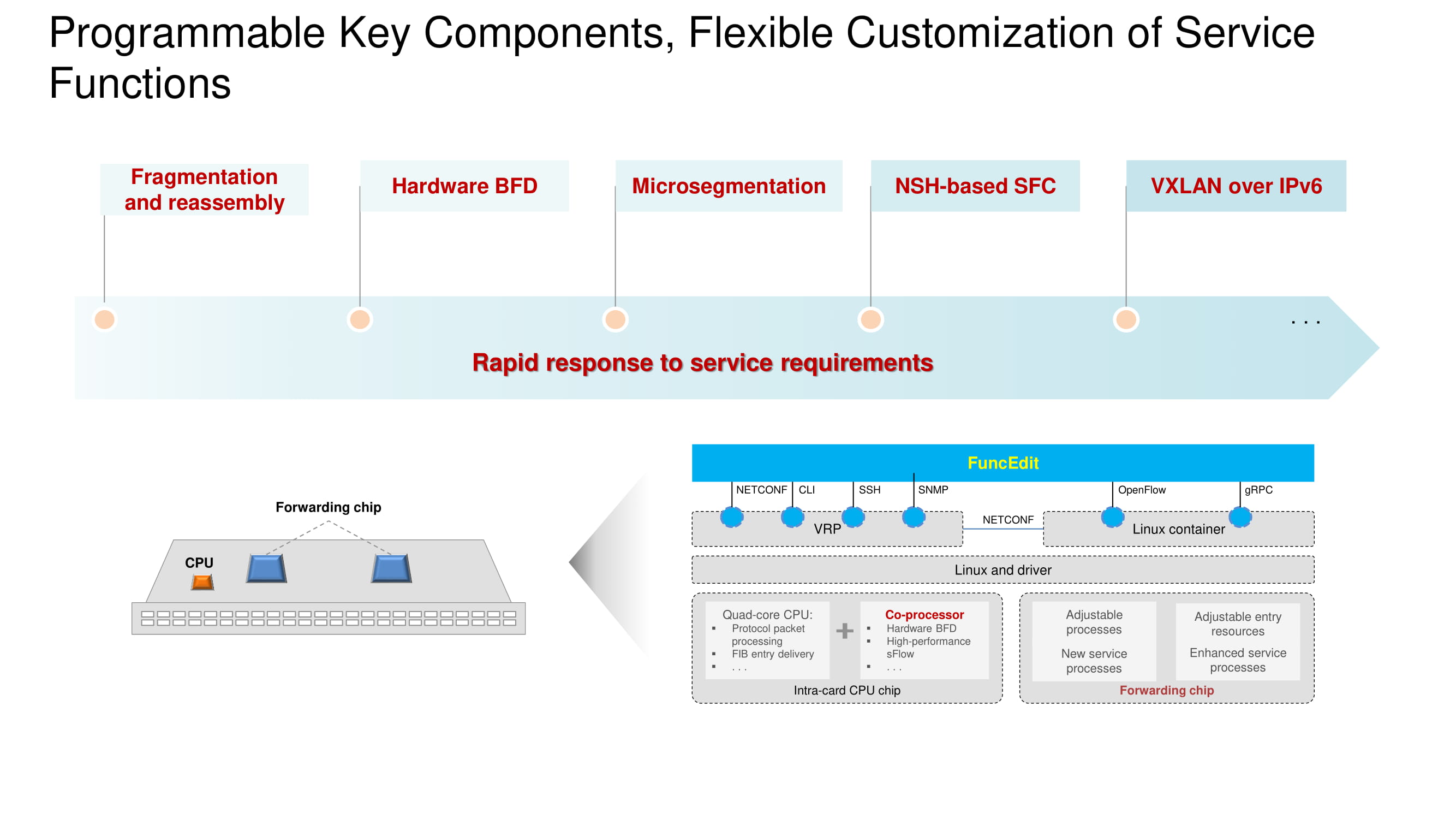
Es ist wichtig, dass das BFD-Protokoll (Bidirectional Forwarding Detection) Hardware ist, die auf den neuen Switch-Modellen implementiert ist, und dass VXLAN im IPv6-Adressraum konfiguriert werden kann. Die Grundarchitektur bleibt unverändert und basiert auf einem Prozessor, einem Coprozessor und einem Weiterleitungschip. Die Funktionalität jedes Knotens ist im Diagramm dargestellt. Die wichtigste Änderung im Jahr 2020 ist der Übergang zu Huawei-eigenen Chips in Flaggschiff-Switches, die mit ihren Kollegen von Broadcom vollständig konkurrieren.
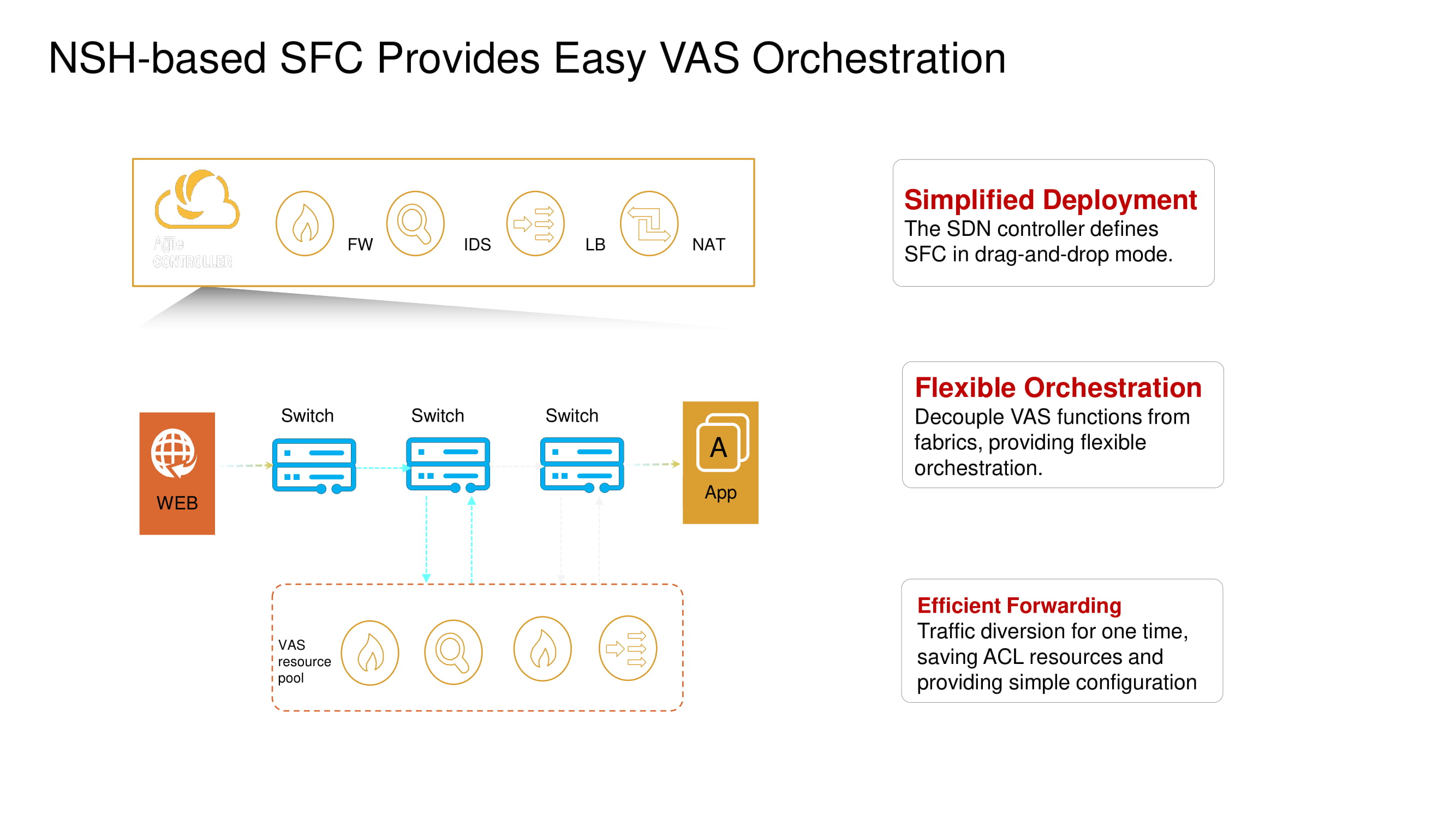
Durch die Unterstützung von Network Service Header-Vorgängen können neue Switches die Standard-VXLAN-Paketrouten ändern und Dienste wie Firewalls (FW), Intrusion Detection-Systeme (IDS), Load Balancer (SLB) und NAT aktivieren.
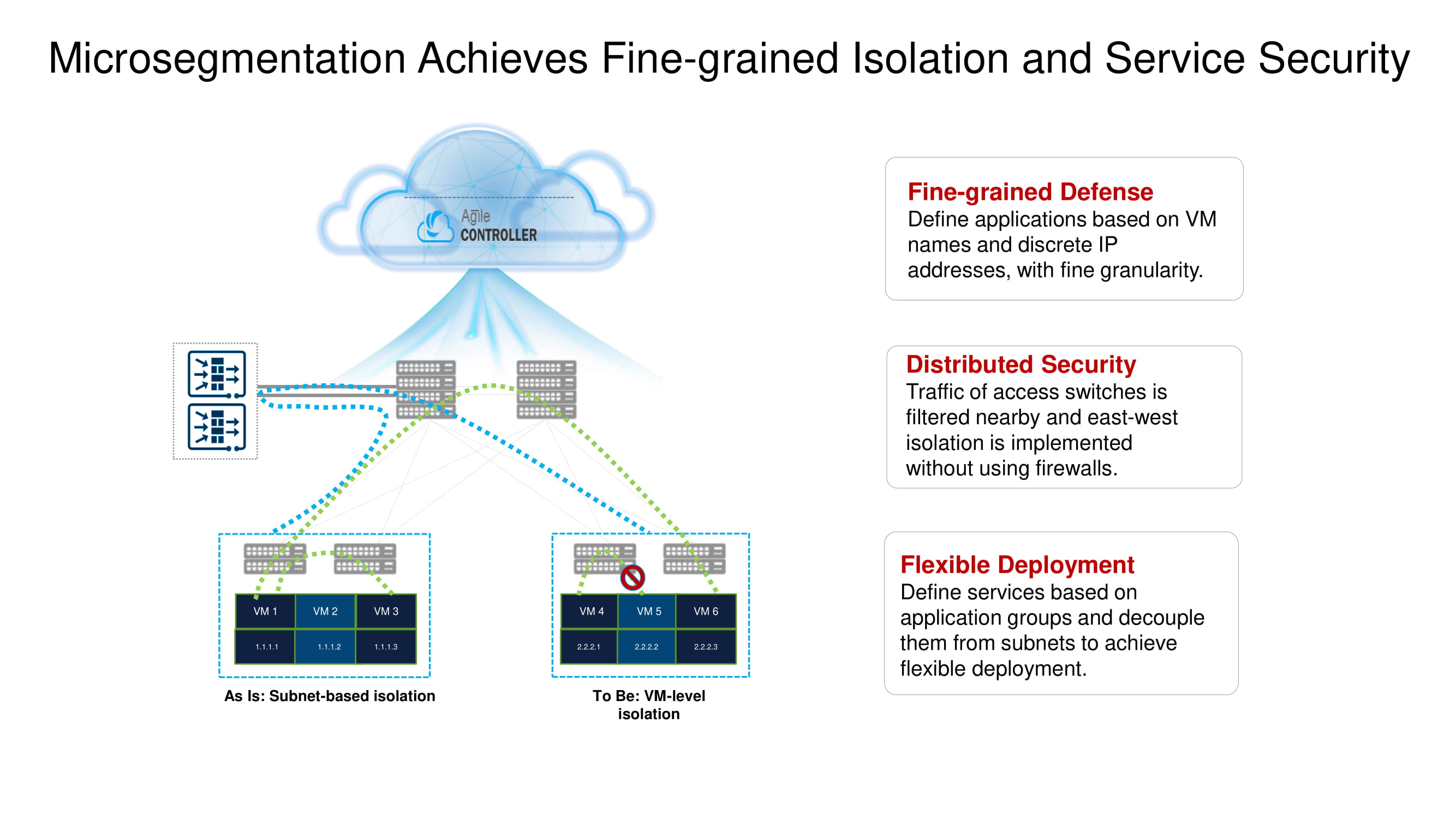
Kehren wir kurz zu der zuvor erwähnten geteilten Mikrosegmentierung zurück. Mit den neuen Huawei ToR-Switches können Sie mithilfe desselben NSH Workloads auf der Ebene der Namen der virtuellen Maschinen isolieren. Diese Maschinen können auf Subnetzebene basierend auf Portnummern, übergeordneten Protokollen usw. weiter gruppiert werden, wodurch Anwendungsgruppen gebildet werden.
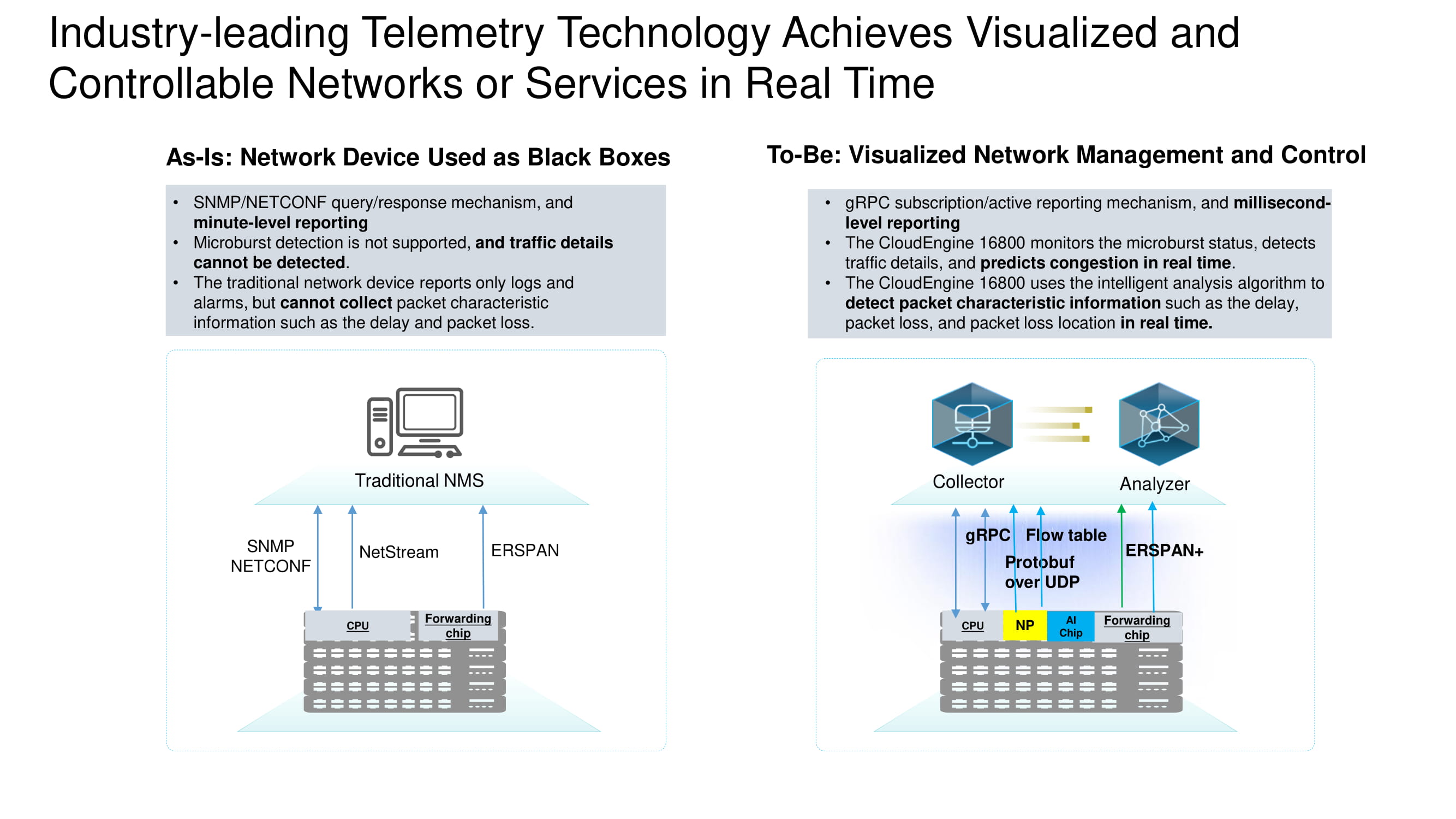
Vollständige Auswahl an Telemetriedaten
Informationen von Geräten werden in Echtzeit mithilfe mehrerer wichtiger Protokolle erfasst. Die Aufgabe von ERSPAN + besteht darin, TCP-Header für die anschließende detaillierte Analyse von TCP-Streams im Rechenzentrum zu sammeln. Zusätzliche Daten werden mithilfe des gRPC-Protokolls und der Flusstabelle ermittelt. All dies wird mit Protobuf über UDP gesammelt.
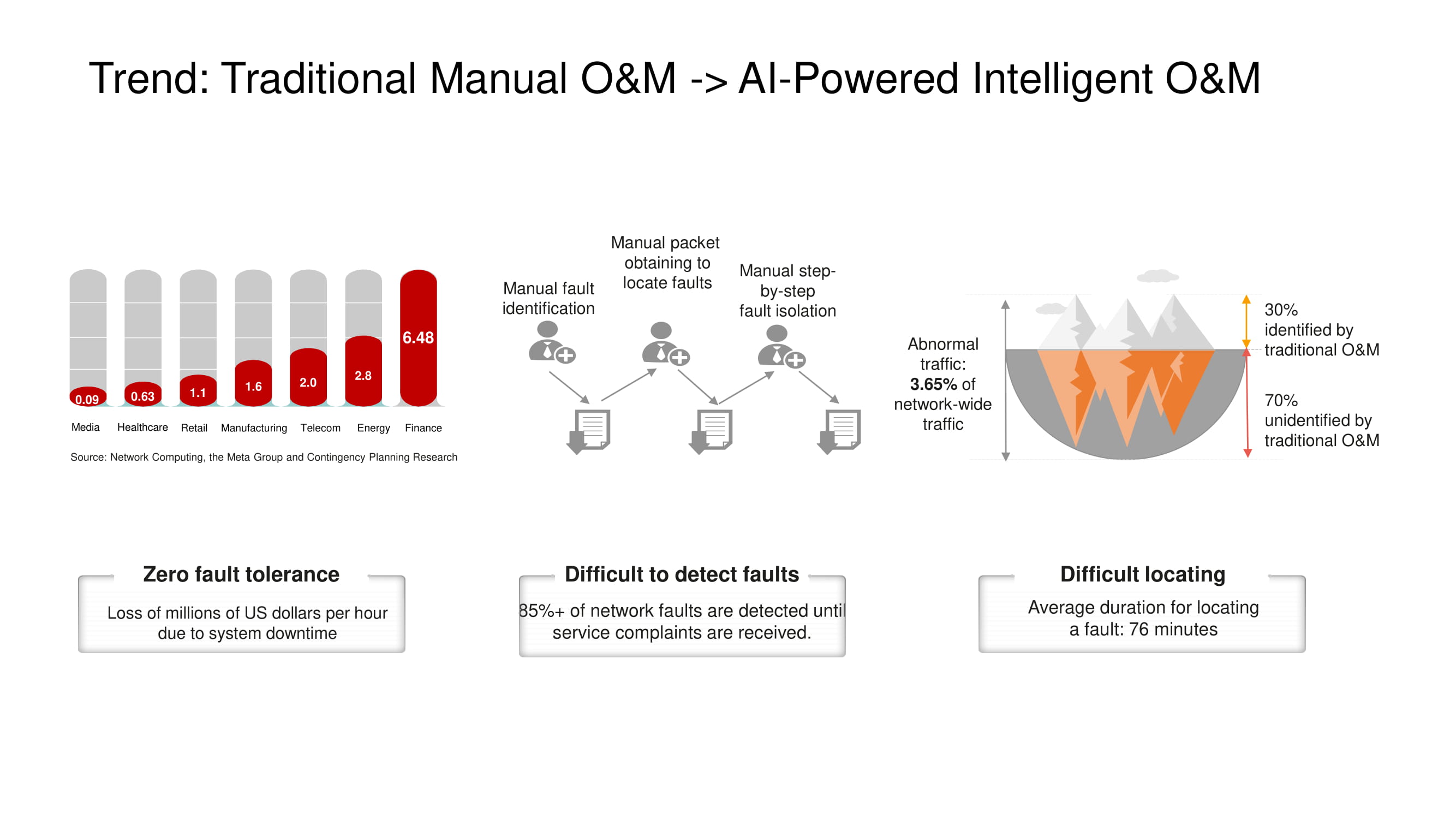
Die Hauptrichtung der Entwicklung von O & M-Tools bei Huawei ist der Übergang von der manuellen oder halbautomatischen Netzwerksteuerung zur vollautomatischen , basierend auf Technologien der künstlichen Intelligenz. Ein umfassendes Telemetriesystem eines relativ großen Standorts erzeugt riesige Datenmengen, deren Analyse in kurzer Zeit nur mit KI möglich ist. Dies ist besonders wichtig in Rechenzentren, in denen Ausfälle und Ausfallzeiten einfach nicht akzeptabel sind.
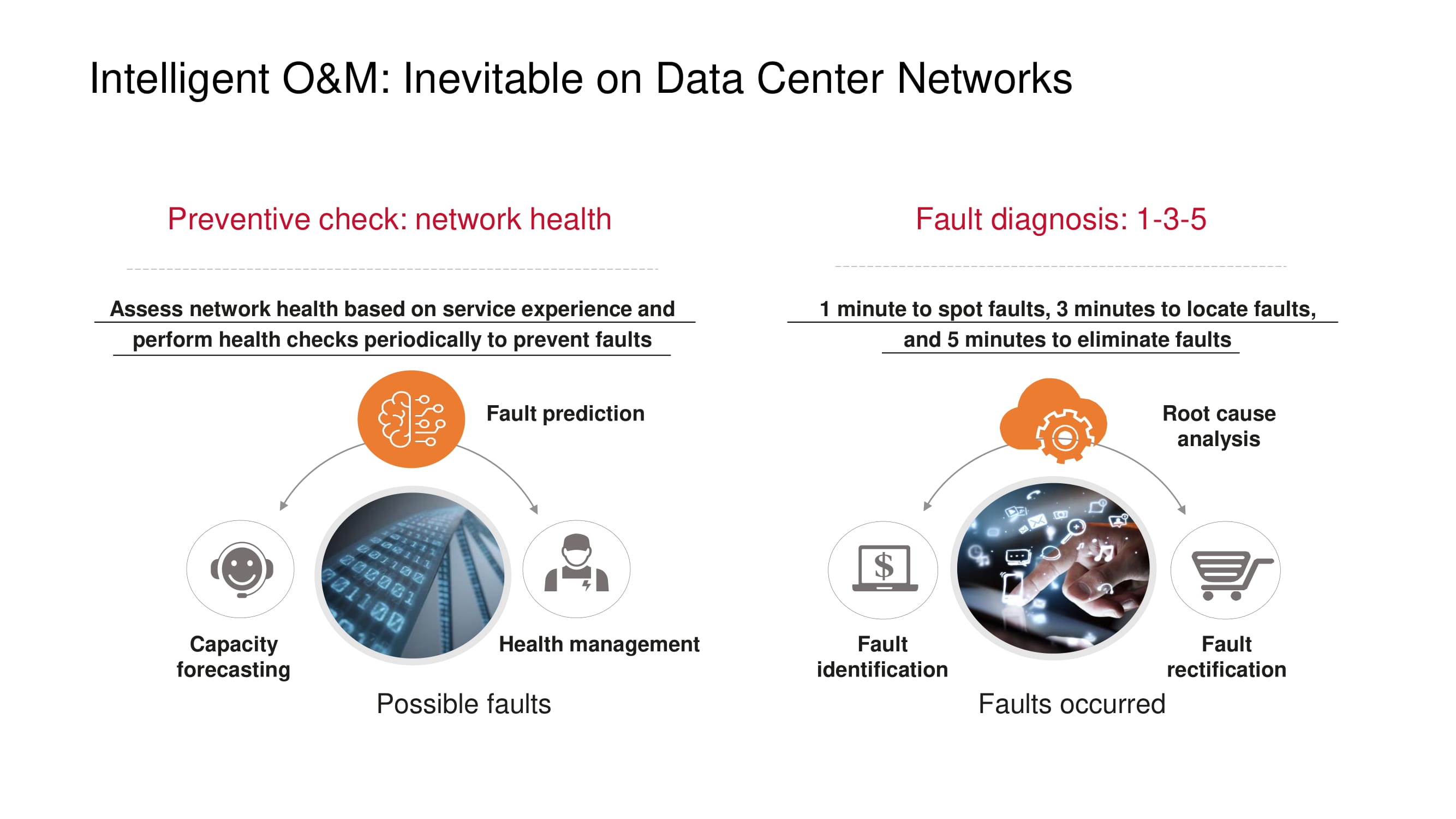
Zu den vorbeugenden Maßnahmen, die das Auftreten von Netzwerkproblemen verhindern sollen, gehören zunächst die Überwachung des "Zustands" des Netzwerks: Überwachung der Kanallast, Ermittlung der Ursachen für Paketverlust (z. B. Suche nach einer Korrelation mit der Tageszeit oder den Betriebsperioden einer Anwendung), Erkennung " Engpässe (Kapazitätsprognosen) usw.
Wenn immer noch Probleme auftreten, hilft das von Huawei vorgeschlagene 1-3-5-Prinzip, die Diagnose- und Wiederherstellungszeit zu minimieren: eine Minute für die Suche, drei Minuten für die Lokalisierung, fünf Minuten für die Behebung des Problems. Um in diesem Rahmen zu bleiben, unterstützen Huawei-Produkte eine ständig wachsende Liste typischer Fehler, die automatisch erkannt werden.

Modell V100R019C10 für kleine Rechenzentren
Eine der wichtigsten Innovationen des V100R019C10 ist die Unterstützung der telemetriebasierten Visualisierung in allen Arten von Szenarien. Tatsächlich handelt es sich um eine visuelle Anzeige von Änderungen im Netzwerk. Darüber hinaus kann das Gerät jetzt mehr als 75 Hauptursachen für bestimmte Probleme identifizieren und Maßnahmen zur Beseitigung dieser Probleme (Starten von Skripten usw.) skizzieren.
Wichtige Neuigkeiten waren die Einführung der Standalone-Version, die sowohl iMaster NCE als auch FabricInsight enthält und hauptsächlich für kleine Rechenzentren gedacht ist, für deren Verwaltung nicht mehrere Server erforderlich sind.
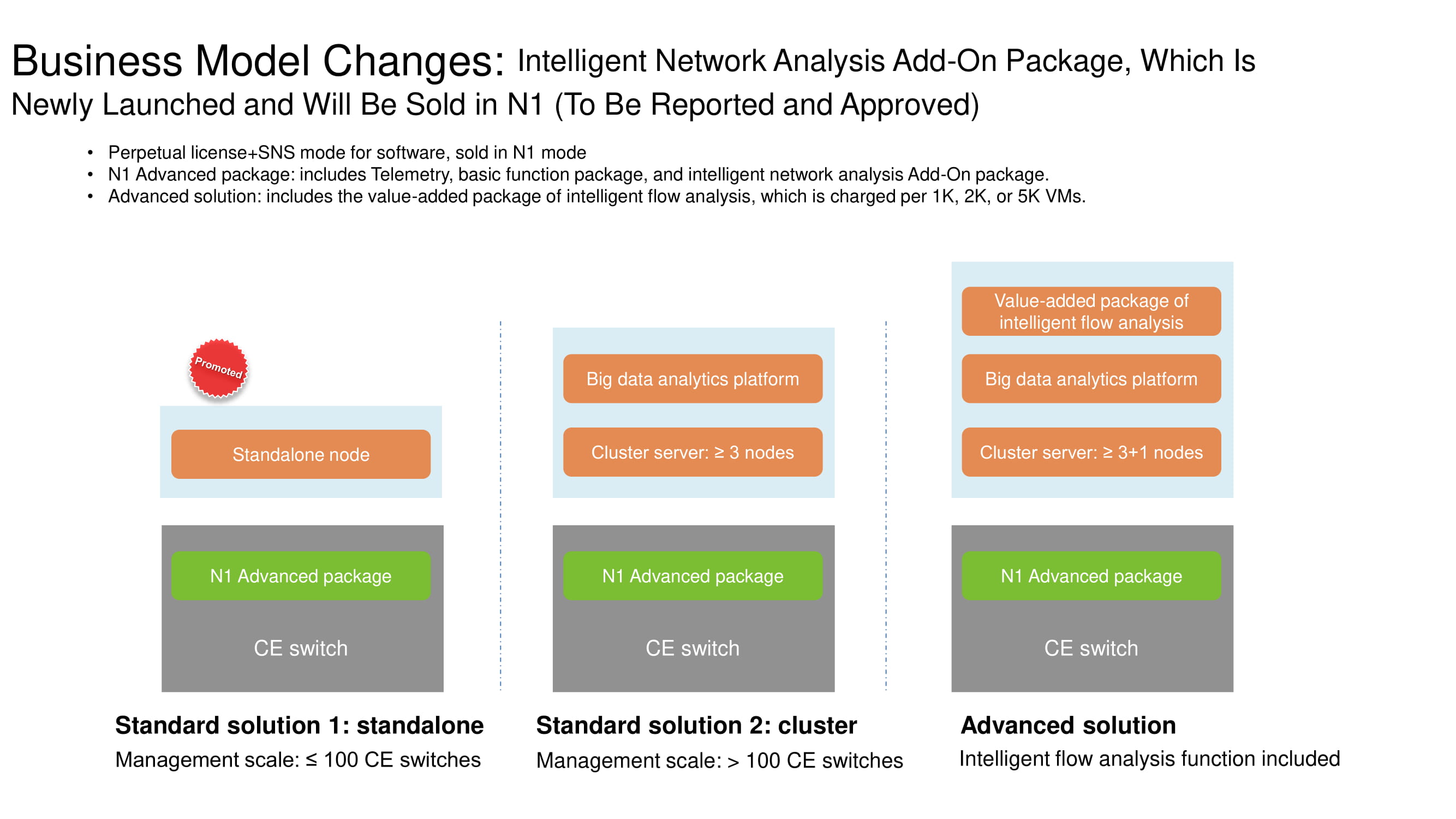
Änderungen im Lizenzsystem
Um die Funktionalität von FabricInsight besser zu verstehen, sollte erläutert werden, welche Änderungen im Geschäftsmodell für den Vertrieb von Huawei-Netzwerkprodukten aufgetreten sind. Wenn die Anzahl der Switches nicht Hunderte erreicht, wird diese Option als eigenständige Edition klassifiziert und impliziert eine N1-Lizenz. Ein Cluster mit drei oder mehr Servern wird bereits mit einer Big-Data-Analyseplattform geliefert. Es wird empfohlen, die Advanced-Lösung mit mehreren hundert Switches in Verbindung mit Tools zur Analyse von Netzwerkflüssen zu verwenden. Alle drei Optionen ermöglichen FabricInsight-Funktionen mit einer N1-Lizenz.
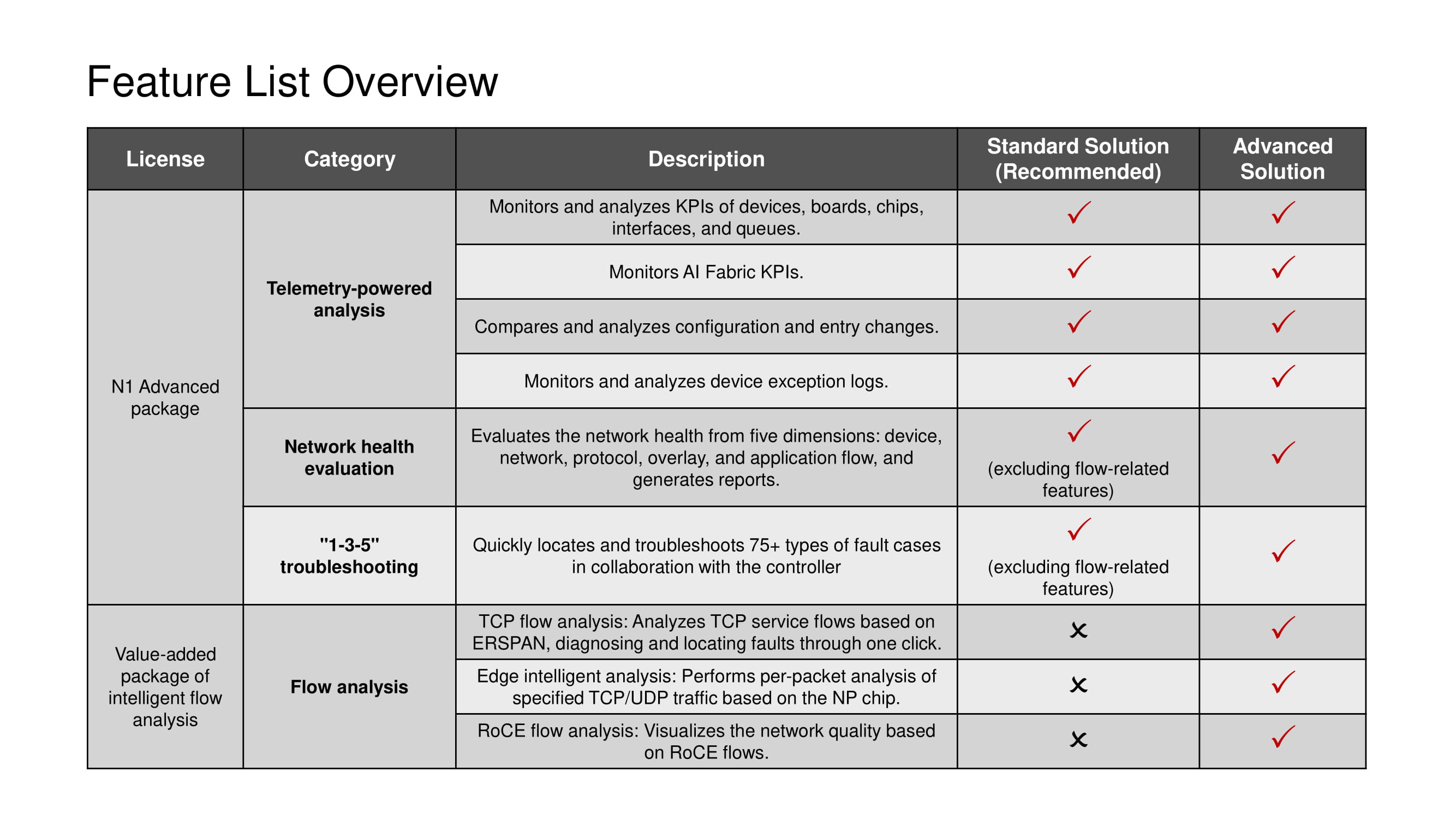
Jede Lizenz beinhaltet die Verwendung des gesamten Satzes von Telemetrietools und -szenarien 1-3-5, mit Ausnahme der TCP-Stream-Analyse-Tools, die nur in der Advanced-Lösung verfügbar sind.
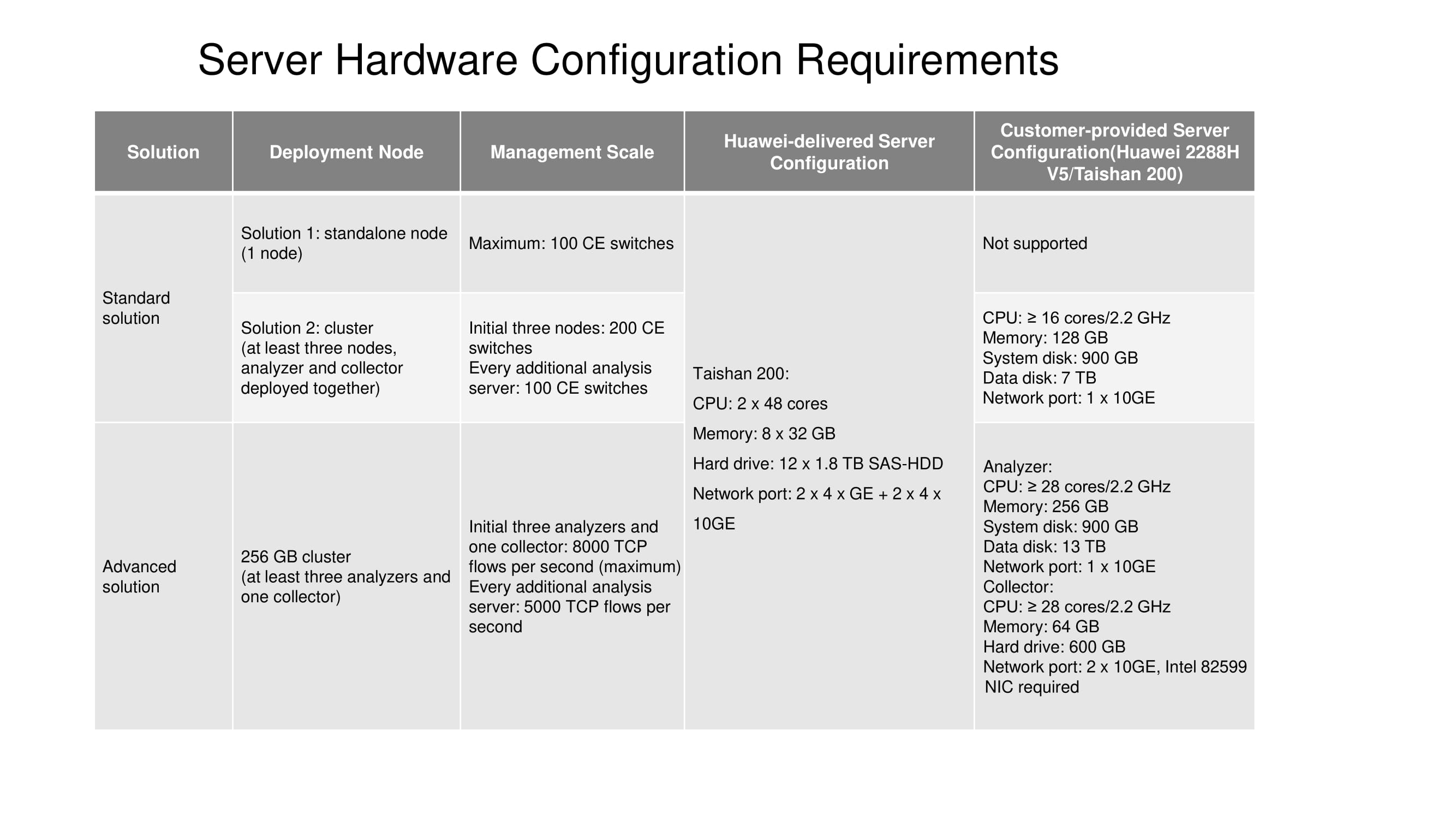
Es bleibt Ihnen noch etwas über die Serverkonfigurationen zu erzählen, die für Standard- und erweiterte Lösungen entwickelt wurden. Derzeit ist ein eigenständiger Knoten (ein Knoten) nur auf dem Taishan 200-Server verfügbar. Für einen Cluster mit drei Knoten sind 16 oder mehr Rechenkerne, 128 GB RAM usw. erforderlich (siehe Abbildung). Die Größe der Datenfestplatte hängt direkt davon ab, wie lange die Statistiken gespeichert werden sollen.

KPI-Überwachung
Schauen wir uns die KPI-Überwachung genauer an. Um es zu verwenden, reicht es aus, ein Zeitintervall und bestimmte Schwellenwerte festzulegen, deren Erreichung anhand der empfangenen Telemetriedaten überprüft wird. Es stehen viele Arten von Metriken zur Verfügung, darunter:
- CPU- und Speicherauslastung;
- mit FIB / MAC;
- Verwendung des ternären assoziativen Speichers (TCAM) des Chips;
- Portparameter;
- die Größe des Puffers für die Warteschlange;
- verschiedene AI Fabric-Metriken;
- Signalpegel, Temperatur und andere Parameter des optischen Moduls;
- Paketverlust.
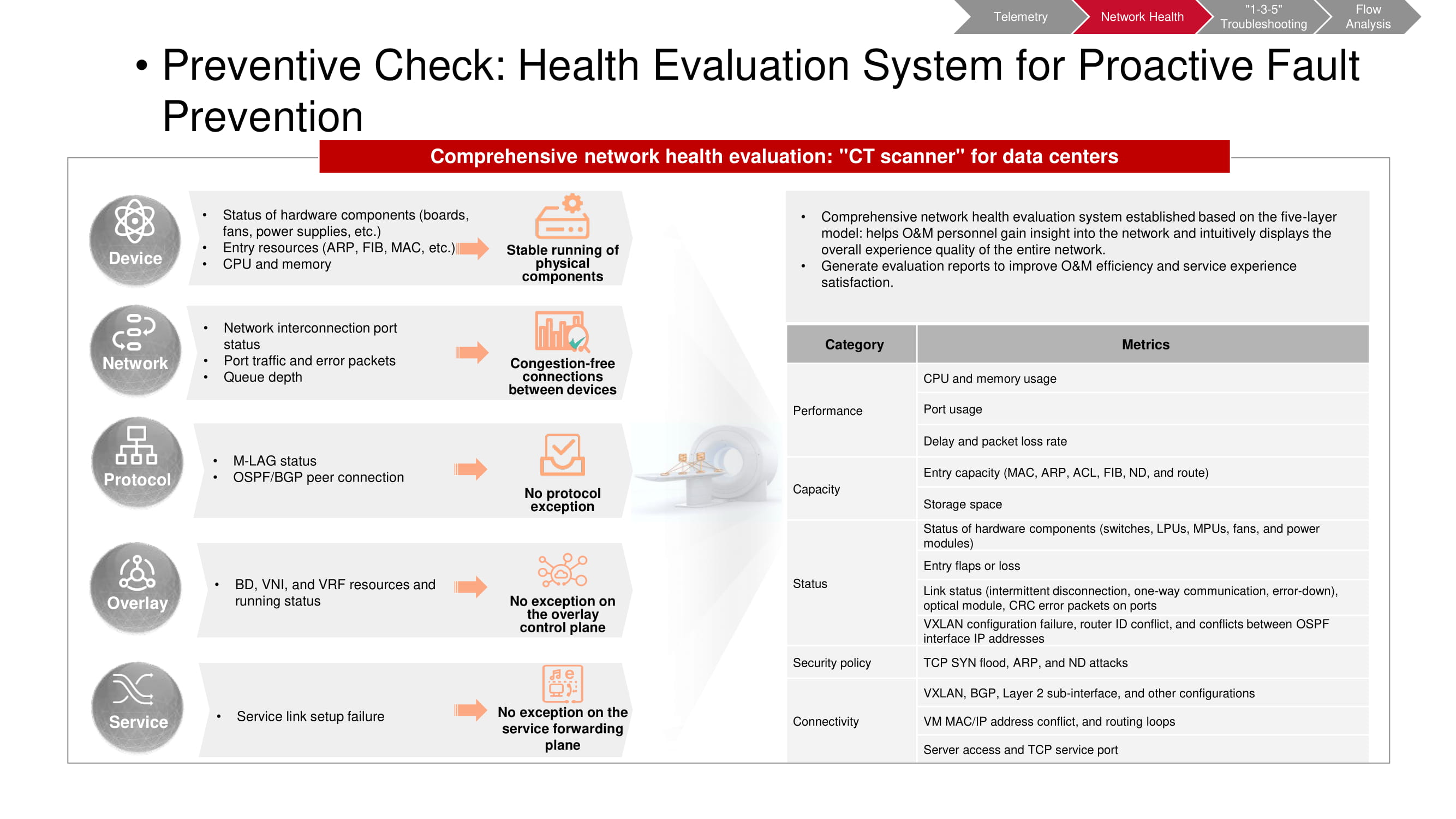
Vorabprüfung
Das Vorvalidierungs-Tool verarbeitet auch Telemetriedaten. Mit dem CT-Scanner können Sie nachvollziehen, ob bestimmte unerwünschte Ereignisse im Netzwerk aufgetreten sind. Einige der Metriken stimmen mit den KPI-Überwachungsmetriken der "Fabrik" überein (hauptsächlich in Bezug auf Kapazität und Leistung). Der Rest basiert auf den Ergebnissen der Analyse auf oberster Ebene (VXLAN, BGP usw.) und der Konfigurationsanalyse. Nach dem Starten des CT-Scanners werden die erforderlichen Informationen gesammelt und ein umfassender Bericht über den Status des Netzwerks erstellt.
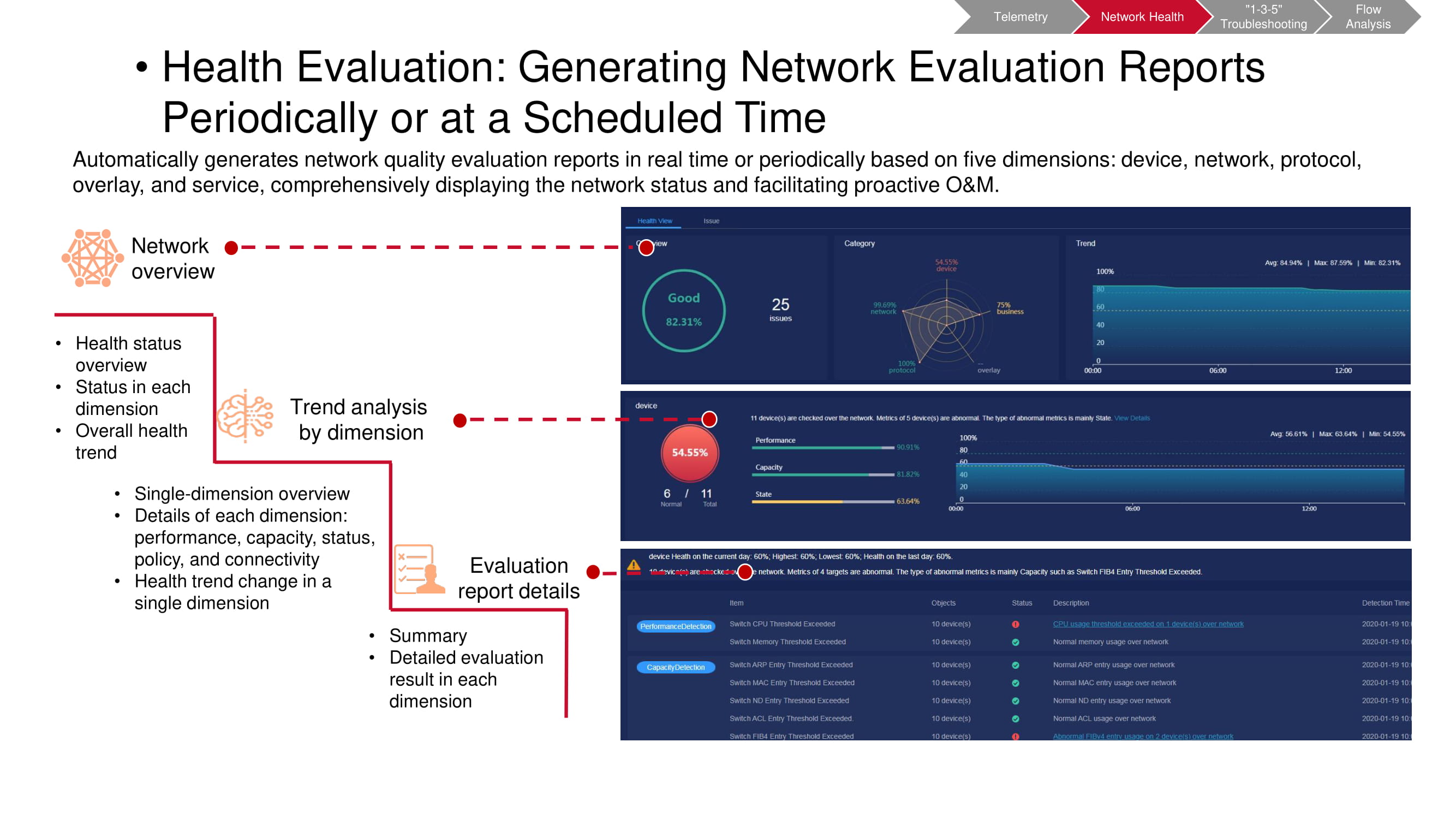
Es ist notwendig, solche Überprüfungen regelmäßig durchzuführen, wobei die Zeitintervalle zwischen ihnen vorbestimmt sind. Dies erleichtert das rechtzeitige Erkennen von Trends im Netzwerk, einschließlich periodischer und nicht periodischer Änderungen. Auf diese Weise können Sie viel genauer und schneller verstehen, was genau passiert. Darüber hinaus kann jeder Parameter von besonderem Interesse für eine detailliertere Überwachung ausgewählt werden.
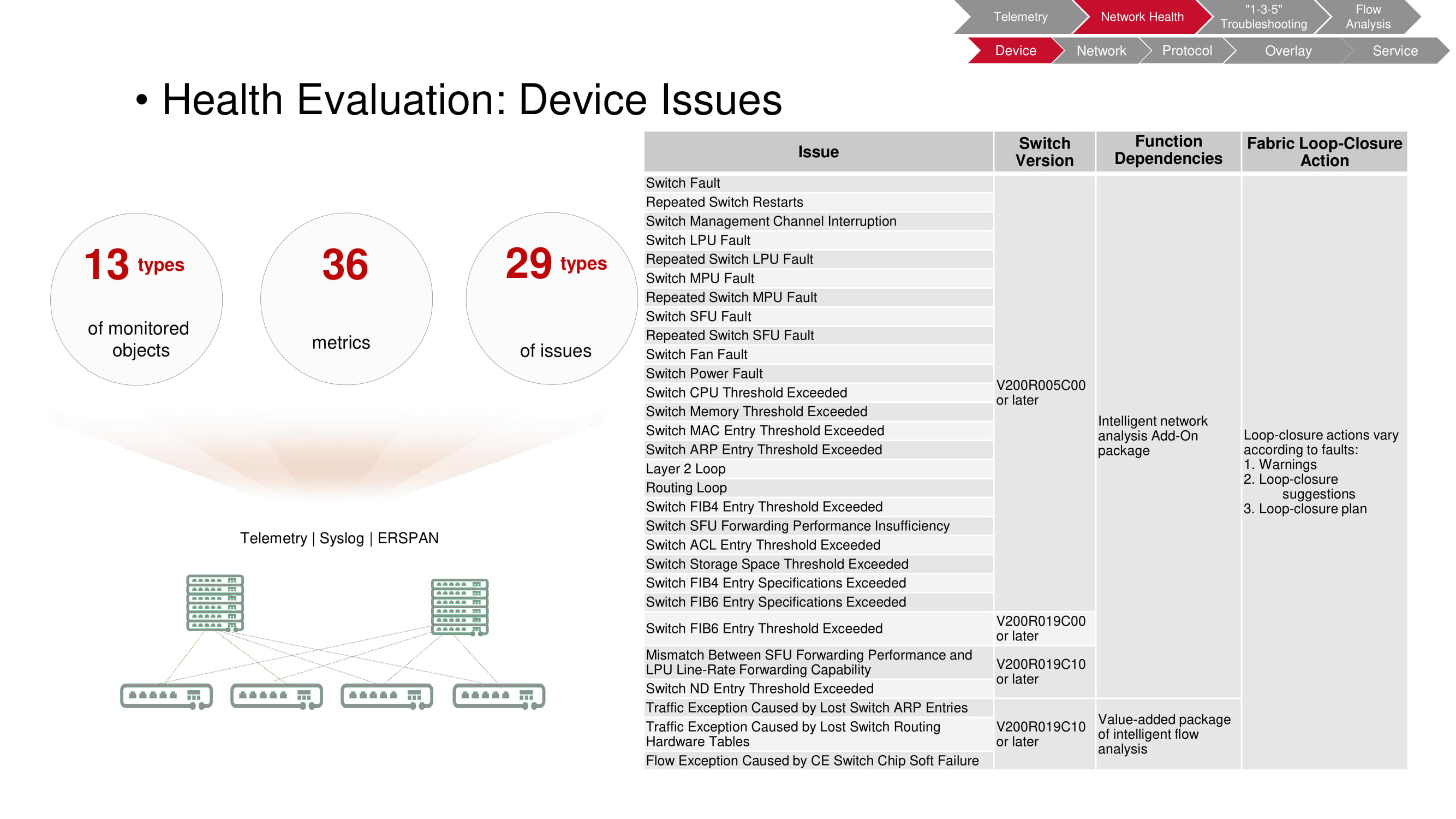
Geräteprobleme
Durch die Überwachung können Sie eine Vielzahl von Problemen identifizieren, die auf Geräteebene auftreten. In diesem Fall ist das Überprüfungsobjekt ein Schalter, dessen registrierte Betriebsparameter es ermöglichen, 29 Arten von Fehlern zu erkennen.
In der Tabelle im Diagramm sind die Arten von Fehlern aufgeführt. Wechseln Sie Modelle, mit denen FabricInsight das Problem erkennen kann. von FabricInsight verwendete Funktionen; Automatische Maßnahmen, wenn Probleme erkannt werden (Warnungen, Empfehlungen, Skriptstart).
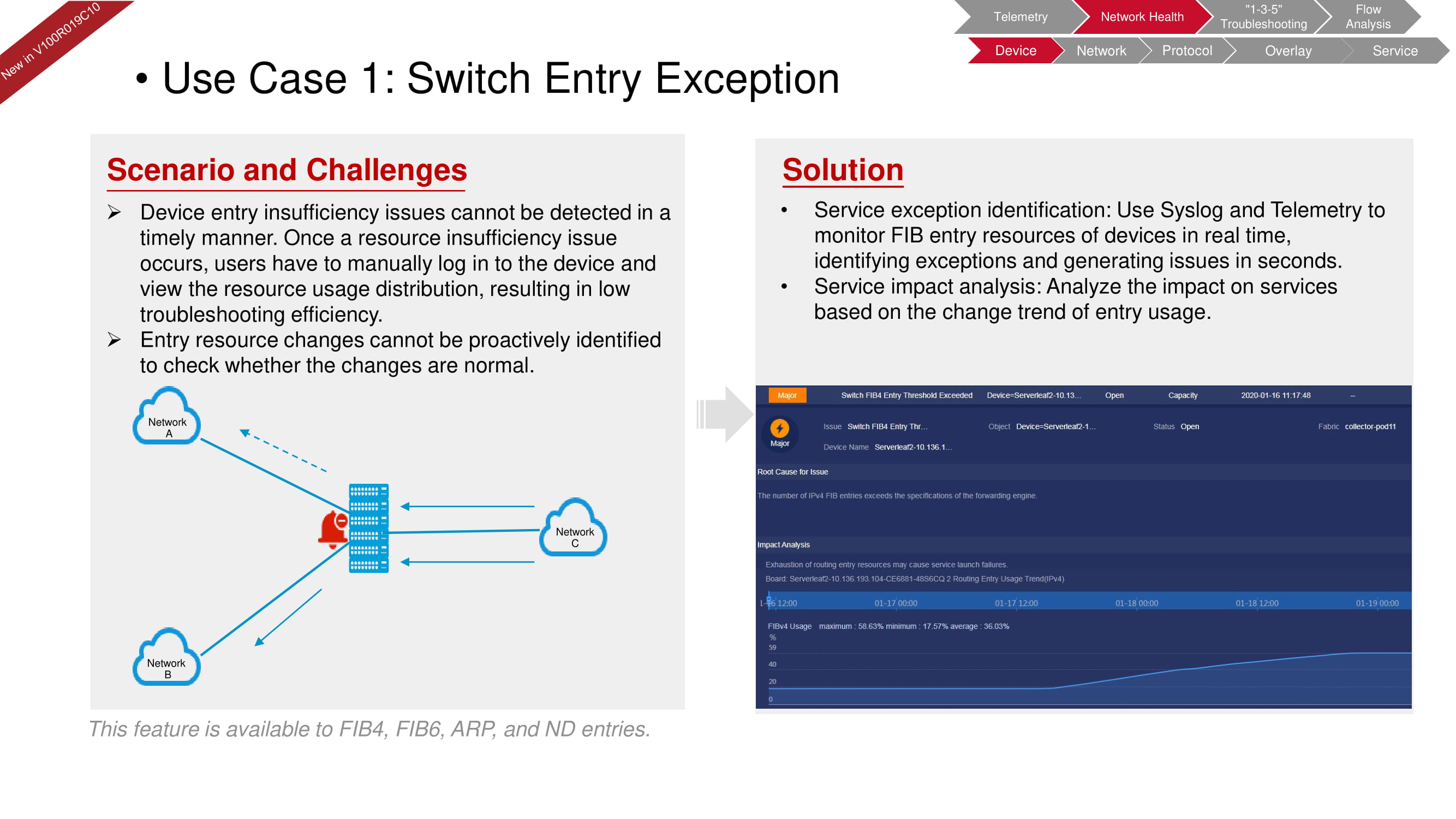
Angenommen, das Gerät verfügt über einen Mangel an Ressourcen, was zu einem Rückgang des Servicelevels führt. Mit den Daten aus dem Systemprotokoll und den Telemetriedaten der FIB-Ressourcen können Sie die Situation im manuellen Überprüfungsmodus schnell beurteilen.
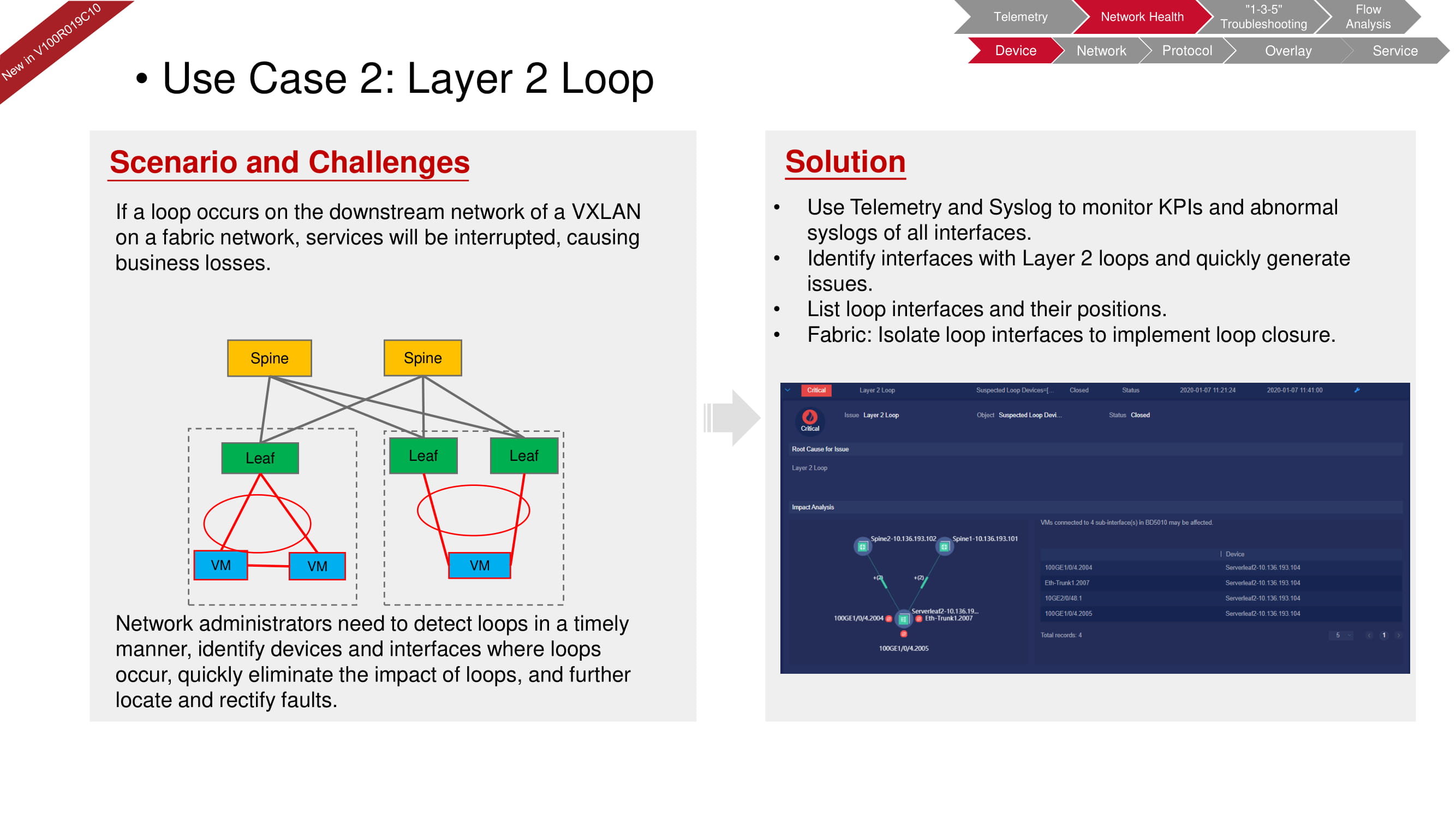
Es ist einfach nicht möglich, dass eine Schleife auf Hardwareebene auftritt, da das Gerät nicht zulässt, dass ein solcher Fehler in die Konfiguration eingeführt wird. Eine Schleife kann jedoch beispielsweise auf der zweiten Ebene (auf der Ebene der virtuellen Maschine) aufgrund eines falsch konfigurierten Software-Switches auftreten, wie in der obigen Abbildung dargestellt. Mit FabricInsight können Sie nicht nur ein Problem erkennen, sondern auch den gewünschten Abschnitt des Netzwerks isolieren, um dessen Auswirkungen auf die Funktion der gesamten "Fabric" zu eliminieren.

Netzwerkprobleme
Basierend auf 18 zur Analyse verfügbaren Metriken identifiziert FabricInsight 10 Arten von Netzwerkproblemen. Das Diagramm enthält eine vollständige Liste dieser Switches sowie - wie bei Geräteproblemen - die Switch-Modelle, mit denen FabricInsight das Problem, die verwendeten Funktionen und die verfügbaren automatischen Aktionen erkennen kann.

Angenommen, eine Verschlechterung oder Fehlfunktion eines optischen Moduls führt zu einer Verschlechterung seiner Leistung: Die Verbindung wird instabil. Diese Situationen treten unregelmäßig auf und sind schwer zu reproduzieren. Dies kann lange dauern, bis das Problem gefunden ist. Mit FabricInsight können Sie sofort einen Abfall des Signalpegels oder eine Spannungsänderung an einem Modul feststellen.
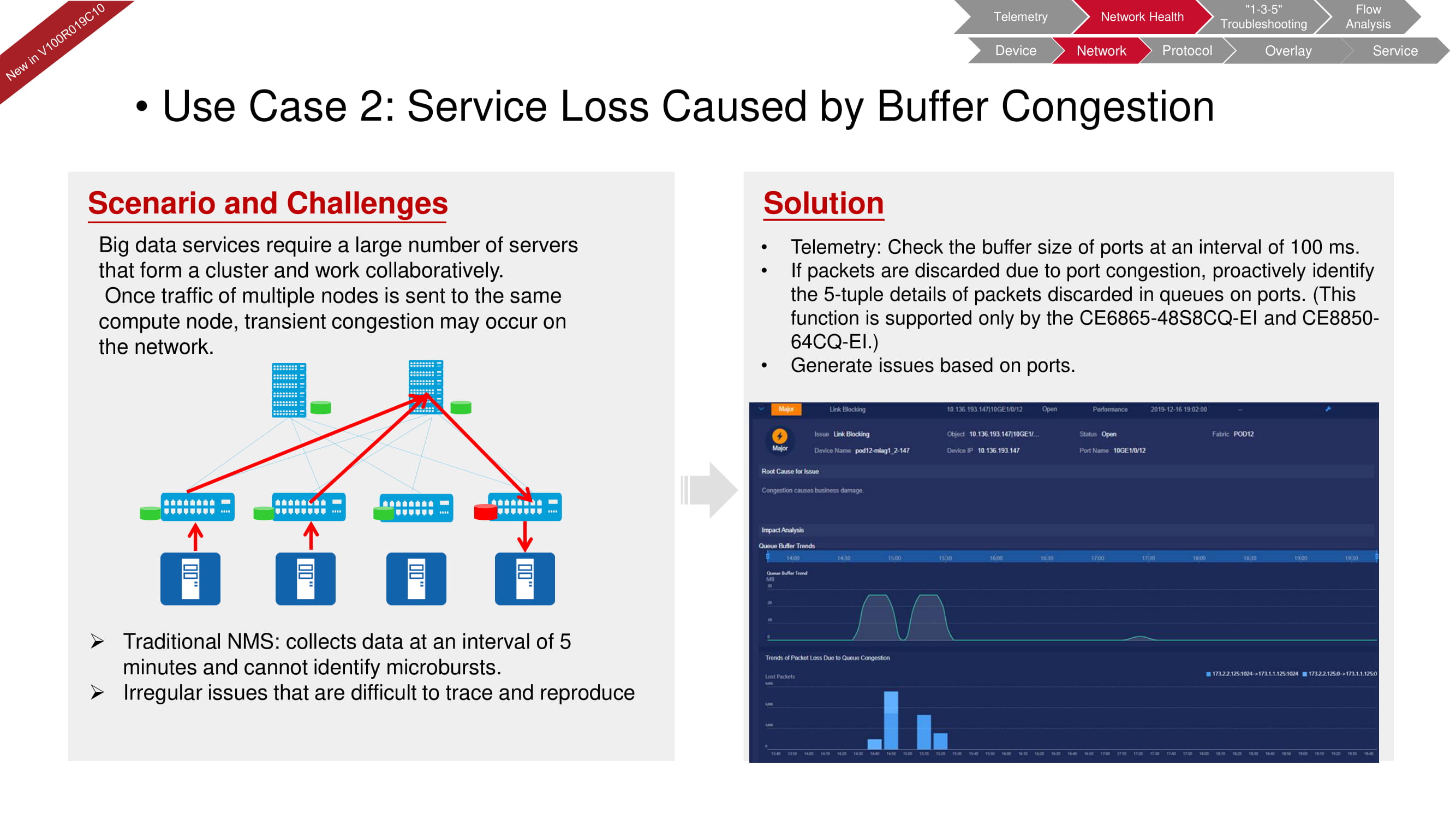
Die FabricInsight-Netzwerkdiagnose kann auch Pufferprobleme, die häufig in Systemen mit einer großen Anzahl von Servern auftreten, die für die Verarbeitung großer Datenmengen vorgesehen sind, schnell identifizieren. Das herkömmliche NMS (Network Management System) überprüft alle fünf Minuten die pufferbezogenen Parameter. Mit den FabricInsight-Telemetriefunktionen können diese Intervalle auf 100 ms reduziert und selbst kürzeste Mikrovorfälle erkannt werden.

Probleme auf Protokollebene
Hier kann FabricInsight sechs Arten von Problemen identifizieren, einschließlich eines Konflikts zwischen zwei Hauptschaltern in der M-LAG. Probleme mit der Interaktion benachbarter Switches usw. Diese Funktionalität ist verfügbar, wenn Switches V200R005C00 und höher verwendet werden.

Betrachten Sie den Konflikt der Hauptschalter. Mit allen Vorteilen der M-LAG-Technologie erscheinen im Falle eines Verbindungsbruchs und eines Peer-to-Peer-Netzwerkausfalls zwei Hauptschalter im System. FabricInsight kann proaktiv auf eine solche Situation reagieren, indem es den Status von Peer-Link und DFS ständig überwacht.

Überlagern Sie Netzwerkprobleme
Sieben Arten von Overlay-Netzwerkproblemen können durch Überwachen von zehn verschiedenen Metriken identifiziert werden. FabricInsight kann den VXLAN-Lizenzstatus überprüfen, Konfigurationsfehler finden, Abstürze unter der Schnittstelle erkennen usw. Die Antwortoptionen ähneln den zuvor beschriebenen.

Serviceprobleme
Sieben Metriken werden überwacht, um sechs Arten von Service-Level-Problemen zu identifizieren. Konflikte mit IP-Adressen, Verbindungsproblemen, TCP-SYN-Flood-Angriffen usw. können erkannt werden. Beachten Sie, dass zur Unterstützung dieser Funktionen von FabricInsight möglicherweise ein TCP-Stream-Analysator erforderlich ist.
FabricInsight ist mehr als nur ein Gerätekollektor, sondern eine erweiterbare Skriptbibliothek, die eine Vielzahl von Problemtypen behandelt.

Von der Automatisierung zur Autonomie
Zusammenfassend werden wir sagen, dass die Ideologie des Intent-Driven Network auf einem dreistufigen Antwortmodell basiert, das die Sammlung von Informationen, deren Analyse mithilfe von KI und Vorschläge zur Änderung des Netzwerkzustands, auch im automatischen Modus, umfasst.
***.
Wir erinnern Sie daran, dass unsere Experten regelmäßig Webinare zu Huawei-Produkten und den von ihnen verwendeten Technologien veranstalten. Eine Liste der Webinare für die kommenden Wochen finden Sie hier .