
Nach einem bekannten Witz sollten sich alle Memoiren in Buchhandlungen im Bereich "Science Fiction" befinden. Aber in meinem Fall ist das wahr! Vor langer Zeit hatte ich
3D Talking Heads - Dies ist eine zungenklebende und blinzelnde Bronzebüste von Max Planck; ein Affe, der Ihre Mimik in Echtzeit kopiert; Dies ist ein 3D-Modell des durchaus erkennbaren Leiters des Vizepräsidenten von Intel, das mit seiner Teilnahme vollautomatisch aus Videos erstellt wurde und vieles mehr ... Aber das Wichtigste zuerst.
Synthetisches Video: MPEG-4-kompatible 3D-Sprechköpfe - der vollständige Name des Projekts, das in den Jahren 2000-2003 im Intel Nizhny Novgorod Forschungs- und Entwicklungszentrum durchgeführt wurde. Die Entwicklung bestand aus drei Haupttechnologien, die sowohl zusammen als auch getrennt in vielen Anwendungen verwendet werden können, die sich auf die Erstellung und Animation synthetischer dreidimensional sprechender Zeichen beziehen.
- Automatische Erkennung und Verfolgung von Gesichtsausdrücken und Bewegungen des Kopfes der Person in der Videosequenz. In diesem Fall werden nicht nur die Dreh- und Neigungswinkel des Kopfes in allen Ebenen bewertet, sondern auch die äußeren und inneren Konturen der Lippen und Zähne während eines Gesprächs, die Position der Augenbrauen, der Grad der Augenbedeckung und sogar die Blickrichtung.
- Automatische Echtzeitanimation nahezu beliebiger dreidimensionaler Kopfmodelle gemäß den Animationsparametern, die mit den Erkennungs- und Verfolgungsalgorithmen vom ersten Punkt sowie aus anderen Quellen erhalten wurden.
- Automatische Erstellung eines fotorealistischen 3D-Modells des Kopfes einer bestimmten Person unter Verwendung von zwei Fotos des Prototyps (Vorder- und Seitenansicht) oder einer Videosequenz, in der eine Person ihren Kopf von einer Schulter zur anderen dreht.
Und noch ein Bonus - Technologie oder besser gesagt einige Tricks zum realistischen Rendern von "sprechenden Köpfen" in Echtzeit, unter Berücksichtigung der Einschränkungen der Hardwareleistung und der Softwarefunktionen, die Anfang der 2000er Jahre bestanden.
Die Verbindung zwischen diesen dreieinhalb Punkten sowie die Verbindung zu Intel bestehen aus vier Buchstaben und einer Zahl: MPEG-4.
MPEG-4
Nur wenige Menschen wissen, dass der 1998 erschienene MPEG-4- Standard neben der Codierung gewöhnlicher realer Video- und Audiostreams auch die Codierung von Informationen über synthetische Objekte und deren Animation ermöglicht - das sogenannte synthetische Video. Eines dieser Objekte ist ein menschliches Gesicht, genauer gesagt ein Kopf, der als triangulierte Oberfläche definiert ist - ein Netz im 3D-Raum. MPEG-4 definiert 84 spezielle Punkte im Gesicht einer Person - Feature Points (FP): Ecken und Mittelpunkte von Lippen, Augen, Augenbrauen, Nasenspitze usw.
Facial Animation Parameters (FAP) werden auf diese speziellen Punkte (oder auf das gesamte Modell bei Drehungen und Neigungen) angewendet, die die Änderung der Position und des Gesichtsausdrucks im Vergleich zum neutralen Zustand beschreiben.
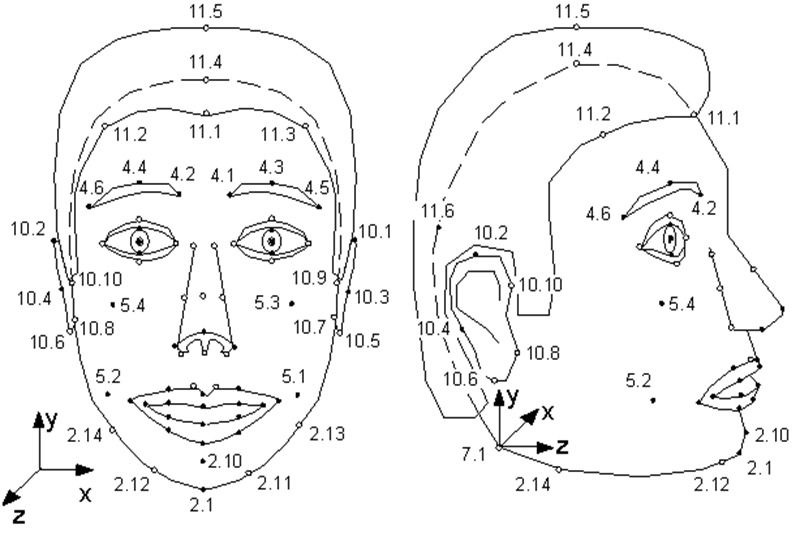
Abbildung aus der MPEG-4-Spezifikation. Singuläre Punkte des Modells. Wie Sie sehen können, kann das Modell an ihren Ohren schnüffeln und wackeln.
Das heißt, die Beschreibung jedes Einzelbilds eines synthetischen Videos, das ein sprechendes Zeichen zeigt, sieht aus wie ein kleiner Satz von Parametern, mit denen der MPEG-4-Decoder das Modell animieren muss.
Welches Modell? MPEG-4 bietet zwei Optionen. Entweder wird das Modell vom Encoder erstellt und zu Beginn der Sequenz einmal an den Decoder übertragen, oder der Decoder verfügt über ein eigenes proprietäres Modell, das in der Animation verwendet wird.
Gleichzeitig die einzigen MPEG-4-Anforderungen für das Modell: Speicherung in VRML-Format und das Vorhandensein von speziellen Punkten. Das heißt, ein Modell kann eine fotorealistische Kopie einer Person sein, deren FAP für Animationen verwendet wird, sowie ein Modell einer anderen Person und sogar ein sprechender Wasserkocher - Hauptsache, er hat neben einer Nase einen Mund und Augen.

Eines unserer MPEG-4-kompatiblen Modelle lächelt am meisten.
Neben dem Hauptobjekt "Gesicht" beschreibt MPEG-4 unabhängige Objekte "Oberkiefer", "Unterkiefer", "Zunge", "Augen", auf die auch spezielle Punkte gesetzt sind. Wenn jedoch ein Modell diese Objekte nicht hat, werden die entsprechenden FAPs vom Decoder einfach nicht verwendet.

- Modell, Modell, warum hast du so große Augen und Zähne? - Um dich besser zu animieren!
Woher kommen personalisierte Animationsmodelle? Wie bekomme ich FAP? Und schließlich, wie implementieren Sie realistische Animationen und Renderings basierend auf diesen FAPs? MPEG-4 gibt keine Antworten auf all diese Fragen - genau wie jeder Videokomprimierungsstandard nichts über den Aufnahmevorgang und den Inhalt der von ihm codierten Filme aussagt.
Wie weit ist der Fortschritt gekommen? Bis zu beispiellosen Wundern!
Natürlich können sowohl das Modell als auch die Animation manuell von professionellen Künstlern erstellt werden, die Dutzende von Stunden damit verbringen und zehntausende von Dollar erhalten. Dies schränkt jedoch den Umfang der Technologie erheblich ein und macht sie im industriellen Maßstab nicht anwendbar. Und es gibt viele Einsatzmöglichkeiten für die Technologie, die hochauflösende Videobilder tatsächlich auf mehrere Bytes komprimiert (oh, schade, dass es kein Video gibt). Zunächst Networking - Spiele, Bildung und Kommunikation (Videokonferenzen) mit synthetischen Zeichen.
Solche Anwendungen waren vor 20 Jahren besonders relevant, als noch mit Modems auf das Internet zugegriffen wurde und das unbegrenzte Gigabit-Internet so etwas wie Teleportation zu sein schien. Wie das Leben zeigt, ist die Bandbreite der Internetkanäle im Jahr 2020 in vielen Fällen immer noch ein Problem. Und selbst wenn es kein solches Problem gibt, sagen wir, wir sprechen über die lokale Verwendung, sind synthetische Zeichen zu viel fähig. Zum Beispiel "wiederbeleben" in einem Film einen berühmten Schauspieler des letzten Jahrhunderts, oder geben Sie die Gelegenheit, in die Augen der heute beliebten und immer noch körperlosen Sprachassistenten zu schauen. Aber zuerst sollte der Übergang von einem realen Video einer sprechenden Person zu einem synthetischen automatisch oder zumindest mit minimaler menschlicher Beteiligung erfolgen.
Genau dies wurde in Nischni Nowgorod Intel implementiert. Die Idee entstand zuerst im Rahmen der Implementierung der damals von Intel entwickelten MPEG Processing Library und entwickelte sich dann nicht nur zu einem vollwertigen Spin-off, sondern zu einem wirklich fantastischen Blockbuster.
Darüber hinaus komplett "made in Russia" - dieses Projekt scheint das einzige für die gesamte Existenz des russischen Intel zu sein, es gab keinen Kurator in Intel USA. Während seines Besuchs in Nischni Nowgorod gefiel Justin Ratner (Leiter der Forschungsabteilung von Intel Labs) die Idee und er gab die Erlaubnis

Synthetic Valery Fedorovich Kuryakin, Produzent, Regisseur, Drehbuchautor und an einigen Stellen der Stuntman des Projekts - zu dieser Zeit der Leiter der Intel-Entwicklungsgruppe.
Erstens war die Kombination derart unterschiedlicher Technologien in einem kleinen Projekt, an dem nur drei bis sieben Personen gleichzeitig arbeiteten, fantastisch. In diesen Jahren gab es bereits mindestens ein Dutzend Unternehmen auf der Welt, die sich sowohl mit Gesichtserkennung und -verfolgung als auch mit der Erstellung und Animation von "sprechenden Köpfen" befassten. Alle hatten natürlich Erfolge in einigen Bereichen: Einige hatten eine hervorragende Modellqualität, einige zeigten sehr realistische Animationen, einige waren erfolgreich bei der Erkennung und Verfolgung. Kein einziges Unternehmen war jedoch in der Lage, alle Technologien anzubieten, mit denen Sie vollständig automatisch ein synthetisches Video erstellen können, in dem ein Modell, das seinem Prototyp sehr ähnlich ist, seine Gesichtsausdrücke und Bewegungen gut kopiert.
Das Intel 3D Talking Heads-Projekt war die erste und zu dieser Zeit einzige Implementierung eines vollständigen Zyklus der Videokommunikation, der auf allen Elementen des synthetischen MPEG-4-Profils basiert.

Förderer des Projekts zur Herstellung synthetischer Klone des Modells 2003.
Zweitens war die Kombination der damals vorhandenen Hardware und der im Projekt implementierten technologischen Lösungen sowie der Pläne für deren Verwendung fantastisch. Zu Beginn des Projekts hatte ich ein Nokia 3310 in der Tasche, auf meinem Desktop befand sich ein Pentium III-500MHz, und Algorithmen, die für die Leistung in Echtzeit besonders wichtig waren, wurden auf einem Pentium 4-1,7 GHz-Server mit 128 MB RAM getestet.
Gleichzeitig hofften wir, dass unsere Modelle bald auf Mobilgeräten funktionieren würden und die Qualität nicht schlechter sein würde als die der Helden des damals (2001) veröffentlichten fotorealistischen Computeranimationsfilms " Final Fantasy ".

137 Millionen Dollar waren die Kosten für einen Film, der auf einer Renderfarm von ~ 1000 Pentium III-Computern erstellt wurde. Poster von www.thefinalfantasy.com
Aber mal sehen, was mit uns passiert ist.
Gesichtserkennung und -verfolgung, FAP-Erfassung.
Diese Technologie wurde in zwei Versionen vorgestellt:
- Echtzeitmodus (25 Bilder pro Sekunde auf dem bereits erwähnten Pentium 4-1,7 GHz-Prozessor), wenn eine Person verfolgt wird, die direkt vor einer an einen Computer angeschlossenen Videokamera steht;
- ( 1 ), .
Gleichzeitig wurde die Dynamik von Änderungen der Position / des Zustands eines menschlichen Gesichts in Echtzeit überwacht. Wir konnten die Dreh- und Neigungswinkel des Kopfes in allen Ebenen, den ungefähren Grad der Öffnung und Dehnung des Mundes und das Anheben der Augenbrauen ungefähr abschätzen und ein Blinzeln erkennen. Für einige Anwendungen ist eine solche grobe Schätzung ausreichend. Wenn Sie jedoch die Mimik einer Person genau verfolgen müssen, sind komplexere Algorithmen erforderlich und daher langsamer.
Im Offline-Modus ermöglichte unsere Technologie, nicht nur die Position des gesamten Kopfes zu bestimmen, sondern auch die äußeren und inneren Konturen der Lippen und Zähne während eines Gesprächs, die Position der Augenbrauen, den Grad der Augenbedeckung und sogar die Verschiebung der Pupillen - die Richtung des Blicks - absolut genau zu erkennen und zu verfolgen.
Zur Erkennung und Verfolgung wurde eine Kombination bekannter Computer-Vision-Algorithmen verwendet, von denen einige bereits in der neu veröffentlichten OpenCV-Bibliothek implementiert waren - zum Beispiel Optical Flow - sowie unsere eigenen ursprünglichen Methoden, die auf der Kenntnis der Form der entsprechenden Objekte von vornherein basieren. Insbesondere - auf unsere verbesserte Version der Methode der verformbaren Schablonen , für die die Projektteilnehmer ein Patent erhalten haben .
Die Technologie wurde in Form einer Bibliothek von Funktionen implementiert, die Videobilder mit einem menschlichen Gesicht als Eingabe und Ausgabe der entsprechenden FAPs empfingen.
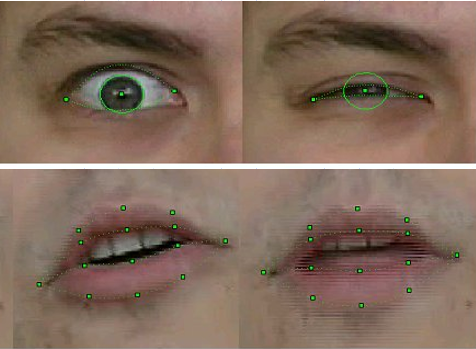
Qualität der Erkennung und Verfolgung der FP-Stichprobe 2003
Natürlich war die Technologie nicht perfekt. Die Erkennung und Verfolgung schlug fehl, wenn die Person im Rahmen einen Schnurrbart, eine Brille oder tiefe Falten hatte. In drei Jahren Arbeit hat sich die Qualität jedoch erheblich verbessert. Wenn in den ersten Versionen für Bewegungserkennungsmodelle beim Aufnehmen eines Videos spezielle Markierungen auf die entsprechenden FP-Punkte des Gesichts geklebt werden mussten - weiße Papierkreise, die mit einem Büropunsch erhalten wurden, dann war im Finale des Projekts natürlich nichts dergleichen erforderlich. Darüber hinaus ist es uns gelungen, die Position der Zähne und die Blickrichtung ziemlich stetig zu verfolgen - und dies bei der Auflösung von Videos von Webcams jener Zeit, bei denen solche Details kaum zu unterscheiden waren!

Dies sind keine Windpocken, sondern Aufnahmen aus der "Kindheit" der Erkennungstechnologie. Intel Principle Engineer und damals noch unerfahrener Intel-Mitarbeiter Alexander Bovyrin lehrt ein synthetisches Modell zum Lesen von Gedichten
Animation
Wie schon oft gesagt, wird die Animation eines Modells in MPEG-4 vollständig vom FAP bestimmt. Und alles wäre einfach, wenn nicht ein paar Probleme.
Erstens die Tatsache, dass die FAPs aus den Videosequenzen in 2D extrahiert werden und das Modell 3D ist und es irgendwie erforderlich ist, die dritte Koordinate zu vervollständigen. Das heißt, ein einladendes Lächeln im Profil (und Benutzer sollten dieses Profil sehen können, sonst macht 3D wenig Sinn) sollte nicht zu einem bedrohlichen Grinsen werden.
Zweitens beschreiben FAPs, wie bereits gesagt, die Bewegung einzelner Punkte, von denen das Modell etwa achtzig enthält, während zumindest ein etwas realistisches Modell insgesamt aus mehreren tausend Eckpunkten besteht (in unserem Fall von vier bis achttausend). Es werden Algorithmen benötigt, die die Verschiebung aller anderen Punkte im Modell basierend auf den FP-Verschiebungen berechnen.
Das heißt, es ist klar, dass sich alle Punkte drehen, wenn der Kopf um einen gleichen Winkel gedreht wird. Wenn Sie jedoch lächeln, selbst wenn es bis zu den Ohren reicht, sollte die „Empörung“ über die Verschiebung des Mundwinkels allmählich nachlassen und die Wange bewegen, nicht jedoch die Ohren. Darüber hinaus sollte dies automatisch und realistisch für jedes Modell mit einer beliebigen Mundbreite und Netzgeometrie geschehen. Um diese Probleme zu lösen, wurden im Projekt Animationsalgorithmen erstellt. Sie basierten auf einem pseudomuskulären Modell, das einfach die Muskeln beschreibt, die den Gesichtsausdruck steuern.
Und dann wurde für jedes Modell und jeden FAP vorab automatisch die "Einflusszone" bestimmt - die an der entsprechenden Aktion beteiligten Eckpunkte, deren Bewegungen unter Berücksichtigung von Anatomie und Geometrie berechnet wurden -, wobei die Glätte und Konnektivität der Oberfläche erhalten blieb. Das heißt, die Animation bestand aus zwei Teilen - vorläufig, offline durchgeführt, wobei bestimmte Koeffizienten für die Netzscheitelpunkte erstellt und in die Tabelle eingegeben wurden, und online, wobei unter Berücksichtigung der Daten aus der Tabelle eine Echtzeitanimation auf das Modell angewendet wurde.

Das Lächeln ist für ein 3D-Modell und seine Entwickler nicht einfach
Erstellung eines 3D-Modells einer bestimmten Person.
Im allgemeinen Fall ist die Aufgabe, ein dreidimensionales Objekt aus seinen zweidimensionalen Bildern zu rekonstruieren, sehr schwierig. Das heißt, die Algorithmen zur Lösung sind der Menschheit seit langem bekannt, aber in der Praxis ist das Ergebnis aufgrund vieler Faktoren weit vom gewünschten entfernt. Dies macht sich insbesondere bei der Rekonstruktion der Gesichtsform einer Person bemerkbar - hier können Sie sich an unsere ersten Modelle mit Augen in Form einer Acht (der Schatten der Wimpern auf den Originalfotos war erfolglos) oder einer leichten Gabelung der Nase (der Grund für die Verschreibung von Jahren kann nicht wiederhergestellt werden) erinnern.
Bei MPEG-4-Sprechköpfen wird die Aufgabe jedoch erheblich vereinfacht, da die menschlichen Gesichtsmerkmale (Nase, Mund, Augen usw.) für alle Menschen gleich sind und die äußeren Unterschiede, durch die wir alle (und Computer-Vision-Programme) unterscheiden Menschen voneinander "geometrisch" - die Größe / Proportionen und Lage dieser Merkmale und "Textur" - die Farben und Reliefs. In einem der im Projekt implementierten Profile der synthetischen MPEG-4-Video-Kalibrierung wird daher davon ausgegangen, dass der Decoder über ein verallgemeinertes Modell einer „abstrakten Person“ verfügt, das mithilfe einer Foto- oder Videosequenz für eine bestimmte Person personalisiert ist.
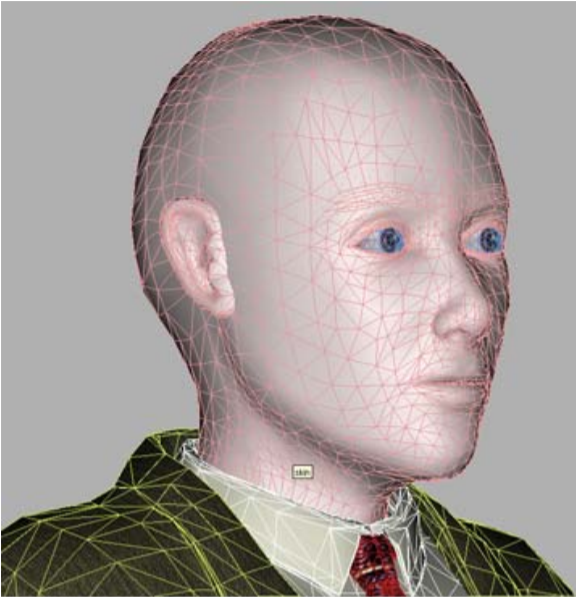
Unser "kugelförmiger Mann im luftleeren Raum" - ein Modell für Personalisierung
Das heißt, globale und lokale Verformungen des 3D-Netzes treten auf, um den Proportionen der Gesichtsmerkmale des Prototyps zu entsprechen, die in seinem Foto / Video hervorgehoben sind. Danach wird die „Textur“ des Prototyps auf das Modell angewendet, dh die Textur, die aus denselben Eingabebildern erstellt wurde. Das Ergebnis ist ein synthetisches Modell. Dies geschieht einmal für jedes Modell, natürlich offline und natürlich nicht so einfach.
Zunächst müssen die eingegebenen Bilder registriert oder korrigiert werden , um sie auf ein Koordinatensystem zu bringen, das mit dem Koordinatensystem des 3D-Modells übereinstimmt. Ferner ist es notwendig, spezielle Punkte auf den Eingabebildern zu erfassen und basierend auf ihrer Position das 3D-Modell beispielsweise unter Verwendung der Methode der radialen Basisfunktionen zu verformenAnschließend erzeugen Sie mithilfe von Panorama-Stitching- Algorithmen eine Textur aus zwei oder mehr Eingabebildern, dh "mischen" sie im richtigen Verhältnis, um maximale visuelle Informationen zu erhalten, und kompensieren den Unterschied in Beleuchtung und Ton, der auch bei aufgenommenen Fotos immer vorhanden ist mit den gleichen Kameraeinstellungen (was nicht immer der Fall ist) und sehr auffällig beim Kombinieren dieser Fotos.

Dies ist kein Standbild aus Horrorfilmen, sondern die Textur eines 3D-Modells von Pat Gelsinger , das mit seiner Erlaubnis erstellt wurde, als das Projekt 2003 auf dem Intel Developer Forum demonstriert wurde.
Die erste Version der Technologie zur Personalisierung des Modells anhand von zwei Fotos wurde von den Projektteilnehmern selbst bei Intel implementiert. Nachdem jedoch ein bestimmtes Qualitätsniveau erreicht und die Grenzen ihrer Fähigkeiten erkannt worden waren, wurde beschlossen, diesen Teil der Arbeit an die Forschungsgruppe der Moskauer Staatlichen Universität zu übertragen, die über Erfahrung auf diesem Gebiet verfügte. Das Ergebnis der Arbeit von Forschern der Moskauer Staatlichen Universität unter der Leitung von Denis Ivanov war die Anwendung "Head Calibration Environment", die alle oben genannten Operationen durchführte, um ein personalisiertes Modell einer Person aus ihrem Foto in vollem Gesicht und Profil zu erstellen.
Der einzige subtile Punkt ist, dass die Anwendung nicht in die oben beschriebene Gesichtserkennungseinheit integriert wurde, die in unserem Projekt entwickelt wurde. Daher mussten die speziellen Punkte auf dem Foto, die für das Funktionieren der Algorithmen erforderlich sind, manuell markiert werden. Natürlich nicht alle 84, sondern nur die wichtigsten, und da die Anwendung über eine geeignete Benutzeroberfläche verfügte, dauerte dieser Vorgang nur wenige Sekunden.
Außerdem wurde eine vollautomatische Version der Modellrekonstruktion aus einer Videosequenz implementiert, bei der eine Person ihren Kopf von einer Schulter zur anderen dreht. Wie Sie sich vorstellen können, war die Qualität der aus dem Video extrahierten Textur jedoch erheblich schlechter als die Textur, die aus Fotografien von Digitalkameras dieser Zeit mit einer Auflösung von ~ 4K (3-5 Megapixel) erstellt wurde, was bedeutet, dass das resultierende Modell weniger attraktiv aussah. Daher gab es auch eine Zwischenversion mit mehreren Fotos mit unterschiedlichen Kopfdrehwinkeln.

Die obere Reihe sind virtuelle Menschen, die untere Reihe ist real.
Wie gut war das erzielte Ergebnis? Die Qualität des resultierenden Modells sollte nicht statisch, sondern direkt auf dem synthetischen Video anhand seiner Ähnlichkeit mit dem entsprechenden Video des Originals bewertet werden. Die Begriffe "ähnlich und nicht ähnlich" sind jedoch nicht mathematisch, sondern hängen von der Wahrnehmung einer bestimmten Person ab, und es ist schwer zu verstehen, wie sich unser synthetisches Modell und seine Animation vom Prototyp unterscheiden. Manche Leute mögen es, andere nicht. Das Ergebnis dreijähriger Arbeit war jedoch, dass das Publikum bei der Demonstration der Ergebnisse auf verschiedenen Ausstellungen erklären musste, in welchem Fenster sich das eigentliche Video vor ihnen befand und in welchem - dem synthetischen.
Visualisierung.
Um die Ergebnisse aller oben genannten Technologien zu demonstrieren, wurde ein spezieller synthetischer MPEG-4-Videoplayer entwickelt. Der Player erhielt als Eingabe eine VRML-Datei mit einem Modell, einen Stream (oder eine Datei) mit FAP sowie Streams (Dateien) mit echtem Video und Audio für die synchronisierte Anzeige mit synthetischem Video mit Unterstützung für den Modus "Bild in Bild". Bei der Demonstration eines synthetischen Videos hatte der Benutzer die Möglichkeit, das Modell zu vergrößern und von allen Seiten zu betrachten, indem er einfach die Maus in einem beliebigen Winkel drehte.

Der Player wurde zwar für Windows geschrieben, berücksichtigt aber mögliche Portierungen in Zukunft auf andere Betriebssysteme, auch mobile. Daher wurde als 3D-Bibliothek das "klassische" OpenGL 1.1 ohne Erweiterungen gewählt.
Gleichzeitig zeigte der Spieler das Modell nicht nur, sondern versuchte es auch zu verbessern, aber nicht zu retuschieren, wie es heute bei Fotomodellen üblich ist, sondern im Gegenteil, um es so realistisch wie möglich zu gestalten. Die Rendering-Einheit des Players blieb im Rahmen der einfachsten Phong-Beleuchtung und hatte keine Shader, aber strenge Leistungsanforderungen. Sie erstellte automatisch synthetische Modelle: imitieren Falten, Wimpern, die Pupillen realistisch verengen und erweitern können; Setzen Sie eine Brille geeigneter Größe auf das Modell. und auch unter Verwendung der einfachsten Strahlverfolgung berechnete die Beleuchtung (Schattierung) der Zunge und der Zähne beim Sprechen.
Natürlich sind solche Methoden jetzt nicht mehr relevant, aber es ist sehr interessant, sich daran zu erinnern. Für die Synthese von Mimikfalten, dh kleinen Biegungen des Hautreliefs im Gesicht, die während der Kontraktion der Gesichtsmuskeln sichtbar sind, erlaubten die relativ großen Dreiecke des Netzes des Modells keine echten Falten. Daher wurde eine Art Bump-Mapping- Technologie angewendet - normales Mapping. Anstatt die Geometrie des Modells zu ändern, änderte sich die Richtung der Normalen zur Oberfläche an den richtigen Stellen, und die Abhängigkeit der diffusen Beleuchtungskomponente an jedem Punkt von der Normalen erzeugte den gewünschten Effekt.

Das ist synthetischer Realismus.
Aber der Spieler hörte hier nicht auf. Um Technologien zu nutzen und nach außen zu übertragen, wurde die Objektbibliothek der Intel Facial Animation Library erstellt, die Funktionen für die Animation (3D-Transformation) und Visualisierung des Modells enthält, sodass jeder, der eine FAP-Quelle haben möchte (und über eine FAP-Quelle verfügt), mehrere Funktionen aufruft: "Szene erstellen", " CreateActor “,„ Animate “könnte sein Modell animieren und in seiner Anwendung anzeigen.
Ergebnis
Was hat mir die Teilnahme an diesem Projekt persönlich gebracht? Natürlich die Möglichkeit, mit wunderbaren Menschen an interessanten Technologien zusammenzuarbeiten. Sie nahmen mich mit in das Projekt, weil ich Kenntnisse über Methoden und Bibliotheken zum Rendern von 3D-Modellen und zur Optimierung der Leistung für x86 hatte. Aber natürlich war es nicht möglich, uns auf 3D zu beschränken, und wir mussten in andere Dimensionen gehen. Um einen Player zu schreiben, musste man sich mit VRML-Parsing befassen (es gab keine vorgefertigten Bibliotheken für diesen Zweck), die native Arbeit mit Threads in Windows beherrschen, die gemeinsame Arbeit mehrerer Threads mit Synchronisation 25 Mal pro Sekunde sicherstellen, die Benutzerinteraktion nicht vergessen und sogar überlegen und implementieren Schnittstelle. Später wurde diese Liste durch die Teilnahme an der Verbesserung der Gesichtsverfolgungsalgorithmen ergänzt. Und die Notwendigkeit, ständig von anderen Teammitgliedern geschriebene Komponenten zu integrieren und einfach mit dem Spieler zu kombinieren,Durch die Präsentation des Projekts nach außen wurden meine Kommunikations- und Koordinationsfähigkeiten erheblich verbessert.
Was hat Intels Teilnahme an diesem Projekt gebracht? Aus diesem Grund hat unser Team ein Produkt entwickelt, das als guter Test und Demonstration der Funktionen von Intel-Plattformen und -Produkten dienen kann. Darüber hinaus haben sowohl Hardware - CPU und GPU als auch Software - unsere Köpfe (sowohl echte als auch synthetische) zur Verbesserung der OpenCV-Bibliothek beigetragen.
Darüber hinaus können wir mit Sicherheit sagen, dass das Projekt sichtbare Spuren in der Geschichte hinterlassen hat. Aufgrund seiner Arbeit schrieben die Teilnehmer Artikel und präsentierten Berichte auf Fachkonferenzen zu Computer Vision und Computergrafik, Russisch ( GraphiCon ) und International.
Und 3D Talking Heads-Demoanwendungen wurden von Intel auf Dutzenden von Messen, Foren und Kongressen auf der ganzen Welt gezeigt.
Seitdem hat die Technologie sicherlich große Fortschritte gemacht, was es einfacher macht, synthetische Zeichen automatisch zu erstellen und zu animieren. Es gab eine Intel Real Sense- Kammertiefendefinition, und neuronale Netze, die auf großen Datenmengen basierten, lernten, wie man realistische Bilder von Menschen erzeugt, auch wenn sie nicht existieren.
Dennoch werden die Entwicklungen des öffentlich zugänglichen 3D Talking Heads-Projekts bis jetzt weiterhin betrachtet.
Schauen Sie sich unseren jungen, fast zwanzigjährigen synthetischen MPEG-4-Lautsprecher an und Sie: