
Guten Tag. Unsere Namen sind Tatiana Voronova und Elvira Dyaminova, wir beschäftigen uns mit Datenanalyse im Center 2M. Insbesondere trainieren wir neuronale Netzwerkmodelle zur Erkennung von Objekten in Bildern: Menschen, Spezialausrüstung, Tiere.
Zu Beginn jedes Projekts verhandelt das Unternehmen mit den Kunden über die akzeptable Erkennungsqualität. Dieses Qualitätsniveau muss nicht nur bei Lieferung des Projekts sichergestellt, sondern auch während des weiteren Betriebs des Systems aufrechterhalten werden. Es stellt sich heraus, dass das System ständig überwacht und umgeschult werden muss. Ich möchte die Kosten dieses Prozesses senken und das Routineverfahren loswerden, um Zeit für die Arbeit an neuen Projekten zu gewinnen.
Automatische Umschulung ist keine einzigartige Idee, viele Unternehmen verfügen über ähnliche interne Pipeline-Tools. In diesem Artikel möchten wir unsere Erfahrungen teilen und zeigen, dass es überhaupt nicht notwendig ist, ein großes Unternehmen zu sein, um solche Praktiken erfolgreich umzusetzen.
Eines unserer Projekte ist das Zählen von Personen in Warteschlangen . Aufgrund der Tatsache, dass der Kunde ein großes Unternehmen mit einer großen Anzahl von Niederlassungen ist, sammeln sich zu bestimmten Zeiten Personen wie geplant an, dh eine große Anzahl von Objekten (Personenköpfen) wird regelmäßig erkannt. Aus diesem Grund haben wir uns entschlossen, genau für diese Aufgabe mit der Implementierung der automatischen Umschulung zu beginnen.
So sah unser Plan aus. Alle Elemente mit Ausnahme der Arbeit des Schreibers werden im automatischen Modus ausgeführt:
- Einmal im Monat werden automatisch alle Kamerabilder der letzten Woche ausgewählt.
- xls- sharepoint, - : « ».
- ( ) – xml- ( ), – .
- « ». xls- ( – , – ). «». , , .
, : (, ) , , (, - ). -. - xls- «» > 0. , ( ). , . , , « ». , . , . , , .
- «» 0, – - .
- , , , , . , .
Am Ende hat uns dieser Prozess sehr geholfen. Wir haben die Zunahme von Fehlern der zweiten Art verfolgt, als viele Köpfe plötzlich "maskiert" wurden, den Trainingsdatensatz rechtzeitig mit einem neuen Kopftyp angereichert und das aktuelle Modell umgeschult. Außerdem können Sie bei dieser Reise die Saisonalität berücksichtigen. Wir passen den Datensatz ständig an die aktuelle Situation an: Menschen tragen oft Hüte oder im Gegenteil, fast jeder kommt ohne sie in die Einrichtung. Im Herbst steigt die Zahl der Menschen, die Kapuzen tragen. Das System wird flexibler und reagiert auf die Situation.
Zum Beispiel im Bild unten - einer der Zweige (an einem Wintertag), dessen Rahmen im Trainingsdatensatz nicht dargestellt wurden:
Wenn wir die Metriken für diesen Rahmen berechnen (TP = 25, FN = 3, FP = 0), stellt sich heraus, dass der Rückruf 89%, die Genauigkeit 100% und der harmonische Durchschnitt zwischen Genauigkeit und Vollständigkeit etwa 94 beträgt. 2% (über Metriken direkt darunter). Ziemlich gutes Ergebnis für ein neues Zimmer.
Unser Trainingsdatensatz hatte sowohl Kappen als auch Hauben, so dass das Modell nicht verwirrt wurde, aber mit dem Einsetzen des Maskenmodus begann es Fehler zu machen. In den meisten Fällen treten keine Probleme auf, wenn der Kopf deutlich sichtbar ist. Befindet sich eine Person jedoch weit von der Kamera entfernt, erkennt das Modell in einem bestimmten Winkel den Kopf nicht mehr (das linke Bild ist das Ergebnis der Arbeit des alten Modells). Dank der halbautomatischen Markierung konnten wir solche Fälle beheben und das Modell rechtzeitig neu trainieren (das richtige Bild ist das Ergebnis des neuen Modells).

Lady Close:

Beim Testen des Modells haben wir Rahmen ausgewählt, die nicht am Training beteiligt waren (ein Datensatz mit einer unterschiedlichen Anzahl von Personen auf dem Rahmen, aus verschiedenen Winkeln und verschiedenen Größen), um die Qualität des Modells zu bewerten. Wir haben Rückruf und Präzision verwendet.
Rückruf - Vollständigkeit zeigt, welchen Anteil von Objekten, die wirklich zu einer positiven Klasse gehören, richtig vorhergesagt haben.
Präzision - Die Genauigkeit zeigt, welchen Anteil von Objekten, die als Objekte einer positiven Klasse erkannt wurden, korrekt vorhergesagt wurden.
Wenn ein Kunde eine einzelne Ziffer, eine Kombination aus Präzision und Vollständigkeit, benötigte, gaben wir das harmonische Mittel oder F-Maß an. Erfahren Sie mehr über Metriken.
Nach einem Zyklus haben wir folgende Ergebnisse erhalten:
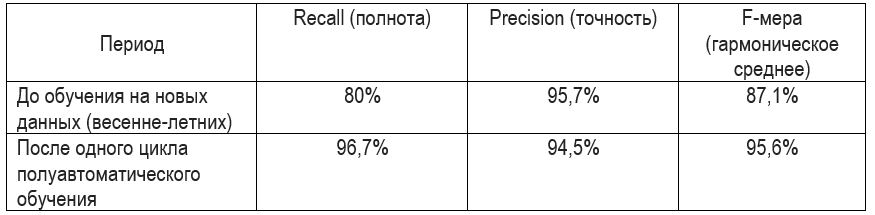
Die Vollständigkeit von 80% vor Änderungen beruht auf der Tatsache, dass eine große Anzahl neuer Abteilungen zum System hinzugefügt wurden und neue Ansichten angezeigt wurden. Außerdem hat sich die Jahreszeit geändert, davor wurden im Trainingsdatensatz "Herbst-Winter-Menschen" vorgestellt.
Nach dem ersten Zyklus betrug die Vollständigkeit 96,7%. Gegenüber dem ersten Artikel erreichte die Vollständigkeit dort 90%. Solche Änderungen sind auf die Tatsache zurückzuführen, dass jetzt die Anzahl der Mitarbeiter in den Abteilungen zurückgegangen ist, sie sich viel weniger überlappen (sperrige Daunenjacken sind ausgegangen) und die Vielfalt der Hüte abgenommen hat.
Zum Beispiel war vor der Norm ungefähr die gleiche Anzahl von Personen wie im Bild unten.

So ist es jetzt.

Lassen Sie uns zusammenfassend die Vorteile der Automatisierung nennen:
- Teilautomatisierung des Markierungsprozesses.
- ( ).
- ( ).
- . .
- . , .
Der Nachteil ist der menschliche Faktor seitens des Vermarkters - er ist möglicherweise nicht verantwortlich genug für das Markup, daher Markup mit Überlappung oder Verwendung von goldenen Sätzen - Aufgaben mit einer vorgegebenen Antwort, die nur zur Kontrolle der Markup-Qualität dienen, sind erforderlich. Bei vielen komplexeren Aufgaben muss der Analyst das Markup persönlich überprüfen. Bei solchen Aufgaben funktioniert der automatische Modus nicht.
Im Allgemeinen hat sich die Praxis der automatischen Umschulung als praktikabel erwiesen. Eine solche Automatisierung kann als zusätzlicher Mechanismus angesehen werden, der es ermöglicht, die Erkennungsqualität während des weiteren Betriebs des Systems auf einem guten Niveau zu halten.
Autoren des Artikels: Tatiana Voronova (tvoronova), Elvira Dyaminova (Elviraa)