
Dieser Artikel beschreibt die technischen Details der Probleme, die zum Absturz von Slack am 12. Mai 2020 geführt haben. Um mehr über das Verfahren zu diesem Vorfall zu reagieren, siehe Ryan Katkov ‚s Chronologie, ‚beiden Hände auf der Fernbedienung . ‘
Am 12. Mai 2020 erlebte Slack seinen ersten bedeutenden Absturz seit langer Zeit. Bald haben wir eine Zusammenfassung des Vorfalls veröffentlicht , aber es ist eine ziemlich interessante Geschichte, daher möchten wir uns näher mit den technischen Details befassen.
Die Benutzer bemerkten die Ausfallzeit um 16:45 Uhr, aber die Geschichte begann tatsächlich um 8:30 Uhr. Das Database Reliability Engineering Team erhielt eine Warnung vor einem signifikanten Anstieg der Belastung eines Teils der Infrastruktur. Gleichzeitig erhielt das Verkehrsteam Warnungen, dass wir keine API-Anfragen stellen.
Die erhöhte Datenbanklast wurde durch die Bereitstellung einer neuen Konfiguration verursacht, die einen langjährigen Leistungsfehler verursachte. Die Änderung wurde schnell erkannt und zurückgesetzt - es war ein Flag für eine Funktion, die eine schrittweise Bereitstellung durchführte, sodass das Problem schnell behoben wurde. Der Vorfall hatte nur geringe Auswirkungen auf die Kunden, dauerte jedoch nur drei Minuten, und die meisten Benutzer konnten während dieser kurzen Morgenpanne immer noch erfolgreich Nachrichten senden.
Eine der Folgen des Vorfalls war eine signifikante Erweiterung unserer Hauptschicht für Webanwendungen. Unser CEO Stuart Butterfield schrieb über einige der Auswirkungen von Quarantäne und Selbstisolation auf die Nutzung von Slack. Infolge der Pandemie haben wir auf Webanwendungsebene deutlich mehr Instanzen gestartet als im Februar dieses Jahres. Wir skalieren schnell, wenn die Worker geladen werden, wie hier - aber die Worker haben viel länger gewartet, bis einige Datenbankabfragen abgeschlossen waren, was zu einer höheren Auslastung führte. Während des Vorfalls haben wir die Anzahl der Instanzen um 75% erhöht, was zu der höchsten Anzahl von Webanwendungshosts führte, die wir bisher ausgeführt haben.
In den nächsten acht Stunden schien alles gut zu funktionieren - bis eine ungewöhnlich hohe Anzahl von HTTP 503- Fehlern auftauchte . Wir haben einen neuen Kanal zur Reaktion auf Vorfälle eingerichtet, und der diensthabende Webanwendungsingenieur hat die Webanwendungsflotte als erste Abschwächung manuell erweitert. Seltsamerweise hat es überhaupt nicht geholfen. Wir haben sehr schnell festgestellt, dass einige der Webanwendungsinstanzen stark ausgelastet waren, der Rest jedoch nicht. Zahlreiche Studien haben begonnen, sowohl die Leistung von Webanwendungen als auch den Lastausgleich zu untersuchen. Nach einigen Minuten haben wir das Problem identifiziert.
Hinter dem Layer 4 Load Balancer befindet sich eine Reihe von HAProxy-Instanzen, mit denen Anforderungen an die Webanwendungsebene verteilt werden können. Wir verwenden Consul für die Serviceerkennung und eine Consul-Vorlage zum Rendern von Listen fehlerfreier Webanwendungs-Backends, an die HAProxy Anforderungen weiterleiten soll.
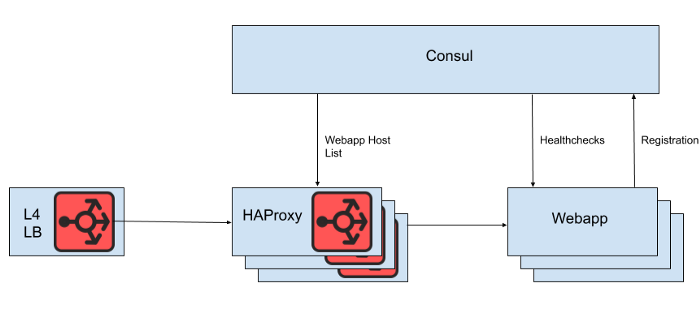
Feige. 1. Eine allgemeine Ansicht der Slack-Lastausgleichsarchitektur
Die Liste der Webanwendungshosts wird jedoch nicht direkt aus der HAProxy-Konfigurationsdatei gerendert, da für die Aktualisierung der Liste in diesem Fall ein Neustart von HAProxy erforderlich ist. Beim Neustart von HAProxy wird ein vollständig neuer Prozess erstellt, während der alte Prozess beibehalten wird, bis die Verarbeitung der aktuellen Anforderungen abgeschlossen ist. Sehr häufige Neustarts können dazu führen, dass zu viele HAProxy-Prozesse ausgeführt werden und die Leistung schlecht ist. Diese Einschränkung steht im Widerspruch zu dem Ziel, die Webanwendungsebene automatisch zu skalieren, um neue Instanzen so schnell wie möglich in die Produktion zu bringen. Daher verwenden wir die HAProxy Runtime APIum den Status des HAProxy-Servers zu verwalten, ohne jedes Mal neu zu starten, wenn der Web-Tier-Server ein- oder ausgeht. Es ist erwähnenswert, dass HAProxy in die Consul-DNS-Schnittstelle integriert werden kann. Dies führt jedoch zu einer Verzögerung aufgrund der DNS-TTL, schränkt die Verwendung von Consul-Tags ein und die Verwaltung sehr großer DNS-Antworten führt häufig zu schmerzhaften Randbedingungen und Fehlern.

Feige. 2. Wie eine Reihe von Webanwendungs-Backends auf einem einzelnen Slack-HAProxy-Server verwaltet wird
In unserem HAProxy-Status definieren wir Vorlagen für HAProxy- Server . Tatsächlich sind dies "Slots", die Webanwendungs-Backends belegen können. Wenn eine Instanz einer neuen Webanwendung eingeführt wird oder die alte fehlschlägt, wird der Consul-Servicekatalog aktualisiert. Consul-template druckt eine neue Version der Hostliste aus, und ein in Slack entwickeltes separates Programm zur Verwaltung des Haproxy-Server-Status liest diese Hostliste und aktualisiert den HAProxy-Status mithilfe der HAProxy Runtime-API.
Wir führen M gleichzeitige HAProxy-Instanzpools und Webanwendungspools aus, die sich jeweils in einer separaten AWS-Verfügbarkeitszone befinden. HAProxy ist mit N "Slots" für Webanwendungs-Backends in jedem AZ konfiguriert, sodass insgesamt N * M-Backends für alle AZs verfügbar sind. Vor ein paar Monaten war diese Zahl mehr als genug - wir haben noch nie etwas in der Nähe so vieler Instanzen unserer Webanwendungsebene gestartet. Nach dem morgendlichen Datenbankvorfall haben wir jedoch etwas mehr als N * M-Webanwendungsinstanzen gestartet. Wenn Sie sich HAProxy-Slots als ein riesiges Stuhlspiel vorstellen, bleiben einige dieser Webapp-Instanzen ohne Speicherplatz. Dies war kein Problem - wir haben mehr als genug Servicekapazität.
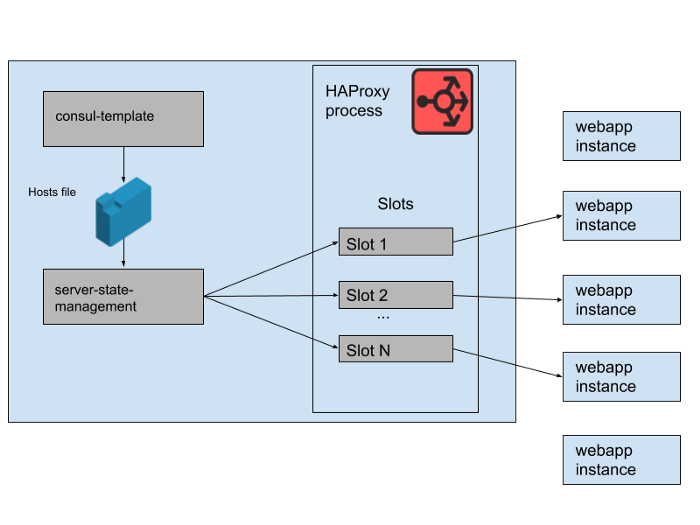
Feige. 3. "Slots" im HAProxy-Prozess mit einigen redundanten Webanwendungsinstanzen, die keinen Datenverkehr empfangen
. Es gab jedoch tagsüber ein Problem. Es gab einen Fehler im Programm, der die von der Konsul-Vorlage generierte Hostliste mit dem Status des HAProxy-Servers synchronisierte. Das Programm hat immer versucht, einen Steckplatz für neue Webapp-Instanzen zu finden, bevor Slots freigegeben wurden, die von alten Webapp-Instanzen belegt wurden, die nicht mehr funktionieren. Dieses Programm hat begonnen, Fehler auszulösen und vorzeitig zu beenden, da keine leeren Slots gefunden werden konnten, was bedeutete, dass die ausgeführten HAProxy-Instanzen ihren Status nicht aktualisierten. Im Laufe des Tages wuchs und schrumpfte die Webapp-Autoscaling-Gruppe, und die Liste der Backends im HAProxy-Status wurde zunehmend veraltet.
Um 16:45 Uhr konnten die meisten HAProxy-Instanzen nur Anfragen an die am Morgen verfügbaren Backends senden, und diese alten Webapp-Backends waren jetzt eine Minderheit. Wir stellen regelmäßig neue HAProxy-Instanzen zur Verfügung, daher gab es einige neue mit der richtigen Konfiguration, aber die meisten waren über acht Stunden alt und hatten daher einen vollständigen und veralteten Backend-Status. Letztendlich stürzte der Dienst ab. Dies geschah am Ende eines Geschäftstages in den USA, da wir dann mit der Skalierung der Webanwendungsebene beginnen, wenn der Datenverkehr abnimmt. Die automatische Skalierung würde die alten Webapp-Instanzen zunächst herunterfahren, was bedeutete, dass im Serverstatus von HAProxy nicht mehr genügend davon vorhanden waren, um die Nachfrage zu bedienen.
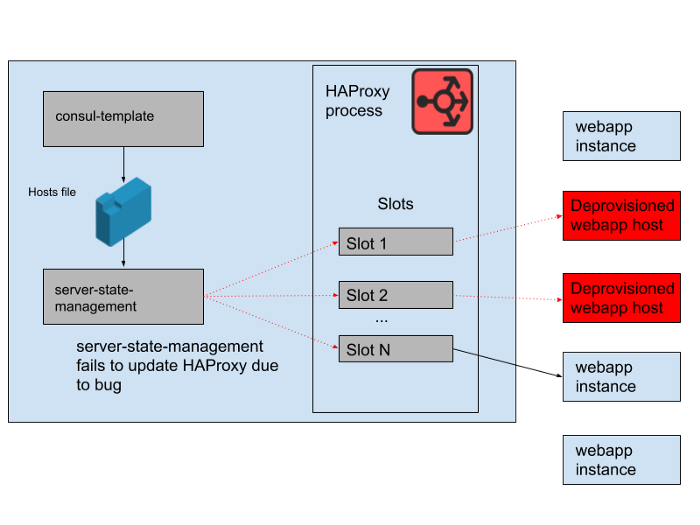
Feige. 4. Der Status von HAProxy änderte sich im Laufe der Zeit und die Slots bezogen sich hauptsächlich auf Remote-Hosts.
Nachdem wir die Ursache des Fehlers herausgefunden hatten, wurde dies durch einen reibungslosen Neustart der HAProxy-Flotte schnell behoben. Danach stellten wir sofort eine Frage: Warum hat die Überwachung dieses Problem nicht erkannt? Wir haben ein Warnsystem für diese spezielle Situation, aber leider hat es nicht wie beabsichtigt funktioniert. Der Überwachungsfehler wurde nicht bemerkt, teilweise weil das System lange Zeit „nur funktioniert“ hat und keine Änderungen erforderlich waren. Die umfassendere HAProxy-Bereitstellung, zu der diese Anwendung gehört, ist ebenfalls relativ statisch. Bei einer langsamen Änderungsrate interagieren weniger Ingenieure mit der Überwachungs- und Alarmierungsinfrastruktur.
Wir haben diesen HAProxy-Stack nicht viel überarbeitet, da wir den gesamten Lastausgleich schrittweise auf Envoy verlagern (wir haben kürzlich den Websocket-Verkehr dorthin verschoben). HAProxy hat viele Jahre lang gute und zuverlässige Dienste geleistet, hat jedoch einige betriebliche Probleme wie bei diesem Vorfall. Wir werden die komplexe Pipeline zur Verwaltung des Status des HAProxy-Servers durch unsere eigene Integration von Envoy in die xDS-Steuerebene für die Endpunkterkennung ersetzen. Die neuesten Versionen von HAProxy (seit Version 2.0) lösen auch viele dieser Betriebsprobleme. Trotzdem vertrauen wir Envoy seit einiger Zeit das interne Service-Mesh an, daher bemühen wir uns, auch den Lastausgleich darauf zu übertragen. Unsere ersten Tests von Envoy + xDS im Maßstab sehen vielversprechend aus, und diese Migration sollte in Zukunft sowohl die Leistung als auch die Verfügbarkeit verbessern.Die neue Architektur für Lastausgleich und Serviceerkennung ist immun gegen das Problem, das diesen Fehler verursacht hat.
Wir bemühen uns, Slack zugänglich und zuverlässig zu halten, aber in diesem Fall sind wir gescheitert. Slack ist ein wesentliches Werkzeug für unsere Benutzer. Deshalb bemühen wir uns, aus jedem Vorfall zu lernen, ob Kunden es bemerkt haben oder nicht. Wir entschuldigen uns für die durch diesen Fehler verursachten Unannehmlichkeiten. Wir versprechen, dieses Wissen zu nutzen, um unsere Systeme und Prozesse zu verbessern.