
Ich muss gleich sagen: Ich bin kein IT-Spezialist, sondern ein Enthusiast auf dem Gebiet der Statistik. Darüber hinaus habe ich im Laufe der Jahre an verschiedenen Formel-1-Vorhersagewettbewerben teilgenommen. Daher die Aufgaben, vor denen mein Modell stand: Prognosen abzugeben, die nicht schlechter wären als diejenigen, die "mit dem Auge" erstellt wurden. Und im Idealfall sollte das Modell natürlich menschliche Gegner schlagen.
Dieses Modell konzentriert sich ausschließlich auf die Vorhersage des Ergebnisses von Qualifikationen, da Qualifikationen vorhersehbarer als Rennen sind und einfacher zu modellieren sind. Natürlich plane ich jedoch, in Zukunft ein Modell zu erstellen, mit dem die Ergebnisse der Rennen mit ausreichender Genauigkeit vorhergesagt werden können.
Um ein Modell zu erstellen, habe ich alle Ergebnisse der Praktiken und Qualifikationen für die Jahreszeiten 2018 und 2019 in einer Tabelle zusammengefasst. 2018 diente als Trainingsstichprobe und 2019 als Teststichprobe. Basierend auf diesen Daten haben wir eine lineare Regression erstellt . Um die Regression so einfach wie möglich zu gestalten, sind unsere Daten eine Sammlung von Punkten auf einer Koordinatenebene. Wir haben eine gerade Linie gezogen, die am wenigsten von der Gesamtheit dieser Punkte abweicht. Und die Funktion, deren Graph diese Linie ist - das ist unsere lineare Regression.
Aus der aus dem Lehrplan bekannten FormelUnsere Funktion zeichnet sich nur dadurch aus, dass wir zwei Variablen haben. Die erste Variable (X1) ist die Verzögerung in der dritten Übung, und die zweite Variable (X2) ist die durchschnittliche Verzögerung in den vorherigen Qualifikationen. Diese Variablen sind nicht äquivalent, und eines unserer Ziele ist es, das Gewicht jeder Variablen im Bereich von 0 bis 1 zu bestimmen. Je weiter eine Variable von Null entfernt ist, desto wichtiger ist sie für die Erklärung der abhängigen Variablen. In unserem Fall ist die abhängige Variable die Rundenzeit, ausgedrückt in der Verzögerung hinter dem Führenden (oder genauer gesagt aus einem bestimmten „idealen Kreis“, da dieser Wert für alle Piloten positiv war).
Fans des Moneyball-Buches (das im Film nicht erklärt wird) können sich daran erinnern, dass sie mithilfe der linearen Regression festgestellt haben, dass der Basisprozentsatz, auch bekannt als OBP (Basisprozentsatz), enger mit den erlittenen Wunden zusammenhängt als andere Statistiken. Unser Ziel ist ungefähr dasselbe: zu verstehen, welche Faktoren am engsten mit den Qualifikationsergebnissen zusammenhängen. Einer der großen Vorteile der Regression besteht darin, dass keine fortgeschrittenen Mathematikkenntnisse erforderlich sind: Wir geben nur die Daten ein, und Excel oder ein anderer Tabellenkalkulationseditor liefert uns vorgefertigte Koeffizienten.
Grundsätzlich wollen wir zwei Dinge mit linearer Regression wissen. Erstens, inwieweit unsere gewählten unabhängigen Variablen die Funktionsänderung erklären. Und zweitens, wie wichtig jede dieser unabhängigen Variablen ist. Mit anderen Worten, was erklärt die Qualifikationsergebnisse besser: die Ergebnisse von Rennen auf vorherigen Strecken oder die Ergebnisse von Trainingseinheiten auf derselben Strecke.
Ein wichtiger Punkt sollte hier beachtet werden. Das Endergebnis war die Summe von zwei unabhängigen Parametern, von denen jeder aus zwei unabhängigen Regressionen resultierte. Der erste Parameter ist die Stärke des Teams in dieser Phase, genauer gesagt die Verzögerung des besten Piloten des Teams vom Anführer. Der zweite Parameter ist die Verteilung der Kräfte innerhalb des Teams.
Was bedeutet das beispielhaft? Nehmen wir an, wir nehmen den Großen Preis von Ungarn 2019. Das Modell zeigt, dass Ferrari 0,218 Sekunden hinter dem Führenden liegt. Dies ist jedoch die Verzögerung des ersten Piloten, und wer sie sein werden - Vettel oder Leclair - und wie groß die Lücke zwischen ihnen sein wird, wird durch einen anderen Parameter bestimmt. In diesem Beispiel zeigte das Modell, dass Vettel vorne sein wird und Leclair 0,096 Sekunden an ihn verlieren wird.
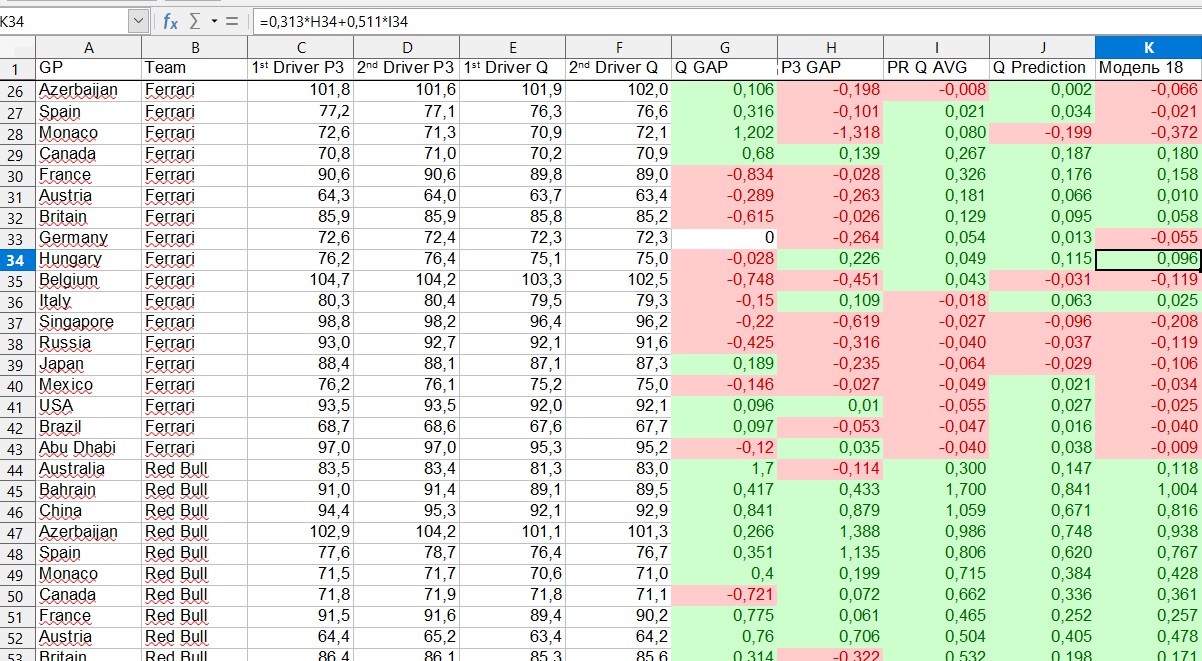
Warum solche Schwierigkeiten? Ist es nicht einfacher, jeden Piloten einzeln zu betrachten, als diese Aufteilung in die Verzögerung des Teams und die Verzögerung des ersten Piloten vom zweiten innerhalb des Teams? Vielleicht ist das so, aber meine persönlichen Beobachtungen zeigen, dass es viel zuverlässiger ist, die Ergebnisse des Teams als die Ergebnisse jedes Piloten zu betrachten. Ein Pilot kann einen Fehler machen oder von der Strecke abfliegen, oder er hat technische Probleme - all dies bringt Chaos in das Modell, es sei denn, Sie verfolgen jede Situation höherer Gewalt manuell, was zu lange dauert. Der Einfluss höherer Gewalt auf die Ergebnisse des Teams ist viel geringer.
Aber zurück zu dem Punkt, an dem wir bewerten wollten, wie gut unsere gewählten erklärenden Variablen die Funktionsänderung erklären. Dies kann unter Verwendung des Bestimmungskoeffizienten erfolgen. Es wird gezeigt, inwieweit die Qualifikationsergebnisse durch die Ergebnisse von Praktika und früheren Qualifikationen erklärt werden.
Da wir zwei Regressionen erstellt haben, haben wir auch zwei Bestimmungskoeffizienten. Die erste Regression ist für das Niveau des Teams auf der Bühne verantwortlich, die zweite für die Konfrontation zwischen den Piloten desselben Teams. Im ersten Fall beträgt der Bestimmungskoeffizient 0,82, dh 82% der Qualifikationsergebnisse werden durch die von uns gewählten Faktoren und weitere 18% durch einige andere Faktoren erklärt, die wir nicht berücksichtigt haben. Das ist ein ziemlich gutes Ergebnis. Im zweiten Fall betrug der Bestimmungskoeffizient 0,13.
Diese Metriken bedeuten im Wesentlichen, dass das Modell die Teamebene relativ gut vorhersagt, jedoch Schwierigkeiten hat, die Lücke zwischen den Teammitgliedern zu bestimmen. Für das endgültige Ziel müssen wir jedoch nicht die Lücke kennen, sondern nur wissen, welcher der beiden Piloten höher sein wird, und das Modell bewältigt dies im Grunde genommen. In 62% der Fälle lag das Modell höher als der Pilot, der in der Qualifikation wirklich höher war.
Gleichzeitig waren bei der Beurteilung der Stärke des Teams die Ergebnisse des letzten Trainings eineinhalb Mal wichtiger als die Ergebnisse der vorherigen Qualifikationen, aber bei Zweikämpfen innerhalb des Teams war es umgekehrt. Der Trend manifestierte sich sowohl in den Daten für 2018 als auch für 2019.
Die endgültige Formel sieht folgendermaßen aus:
Erster Pilot:
Zweiter Pilot:
Ich möchte Sie daran erinnern, dass X1 die Verzögerung in der dritten Übung und X2 die durchschnittliche Verzögerung in den vorherigen Qualifikationen ist.
Was bedeuten diese Zahlen? Sie bedeuten, dass das Niveau des Teams in der Qualifikation zu 60% durch die Ergebnisse des dritten Trainings und zu 40% durch die Ergebnisse der Qualifikationen in den vorherigen Phasen bestimmt wird. Dementsprechend sind die Ergebnisse der dritten Übung ein anderthalbmal bedeutenderer Faktor als die Ergebnisse früherer Qualifikationen.
Fans der Formel 1 kennen wahrscheinlich die Antwort auf diese Frage, aber im Übrigen sollten Sie kommentieren, warum ich die Ergebnisse des dritten Trainings genommen habe. In der Formel 1 gibt es drei Praktiken. In letzterem trainieren die Teams traditionell Qualifikationen. In Fällen, in denen die dritte Übung aufgrund von Regen oder anderer höherer Gewalt fehlschlägt, habe ich die Ergebnisse der zweiten Übung übernommen. Soweit ich mich erinnere, gab es 2019 nur einen solchen Fall - beim Großen Preis von Japan, als die Bühne aufgrund eines Taifuns in einem verkürzten Format abgehalten wurde.
Wahrscheinlich hat auch jemand bemerkt, dass das Modell die durchschnittliche Verzögerung in früheren Qualifikationen verwendet. Aber was ist mit der ersten Etappe der Saison? Ich habe die Verzögerungen aus dem Vorjahr verwendet, sie aber nicht unverändert gelassen, sondern manuell nach dem gesunden Menschenverstand angepasst. Zum Beispiel war Ferrari 2019 durchschnittlich 0,3 Sekunden schneller als Red Bull. Es scheint jedoch, dass die italienische Mannschaft in diesem Jahr keinen solchen Vorteil haben wird, oder dass sie möglicherweise völlig zurückbleibt. Deshalb habe ich für die erste Etappe der Saison 2020, den Großen Preis von Österreich, den Red Bull manuell näher an den Ferrari gebracht.
Auf diese Weise erhielt ich die Verzögerung jedes Piloten, stufte die Piloten nach der Verzögerung ein und erhielt die endgültige Vorhersage für die Qualifikation. Es ist jedoch wichtig zu verstehen, dass der erste und der zweite Pilot reine Konventionen sind. Zurück zum Beispiel mit Vettel und Leclair beim Großen Preis von Ungarn betrachtete das Modell Sebastian als den ersten Piloten, aber in vielen anderen Phasen bevorzugte sie Leclair.
Ergebnisse
Wie gesagt, die Aufgabe bestand darin, ein Modell zu erstellen, das es ermöglicht, sowohl Menschen als auch Menschen vorherzusagen. Als Grundlage habe ich meine Prognosen und Prognosen meiner Teamkollegen genommen, die "von Auge" erstellt wurden, aber mit einer sorgfältigen Untersuchung der Ergebnisse der Praktiken und einer gemeinsamen Diskussion.
Das Bewertungssystem war wie folgt. Nur die zehn besten Piloten wurden berücksichtigt. Für einen genauen Treffer erhielt die Prognose 9 Punkte, für einen Fehlschlag in 1 Position 6 Punkte, für einen Fehlschlag in 2 Positionen 4 Punkte, für einen Fehlschlag in 3 Positionen 2 Punkte und für einen Fehlschlag in 4 Positionen - 1 Punkt. Das heißt, wenn der Pilot in der Prognose auf dem 3. Platz liegt und infolgedessen die Pole Position einnimmt, erhält die Prognose 4 Punkte.
Mit diesem System beträgt die maximale Punktzahl für 21 Grand Prix 1890.
Menschliche Teilnehmer erzielten 1056, 1048 bzw. 1034 Punkte.
Das Modell erzielte 1031 Punkte, obwohl ich bei leichter Manipulation der Koeffizienten auch 1045 und 1053 Punkte erhielt.
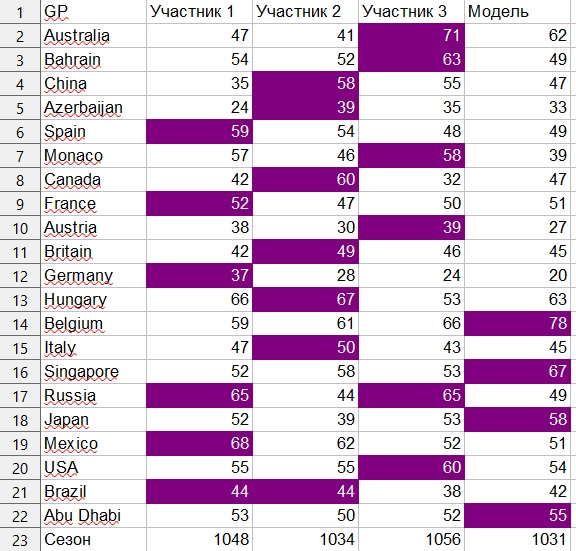
Persönlich bin ich mit den Ergebnissen zufrieden, da dies meine erste Erfahrung beim Aufbau von Regressionen ist und zu durchaus akzeptablen Ergebnissen geführt hat. Natürlich möchte ich sie verbessern, denn ich bin sicher, dass Sie durch das Erstellen von Modellen, die so einfach wie dieses sind, bessere Ergebnisse erzielen können, als nur die Daten "mit dem Auge" auszuwerten. Im Rahmen dieses Modells wäre es beispielsweise möglich, den Faktor zu berücksichtigen, dass einige Teams in der Praxis schwach sind, aber in der Qualifikation „schießen“. Zum Beispiel gibt es eine Beobachtung, dass Mercedes während des Trainings oft nicht das beste Team war, aber in der Qualifikation viel besser abschnitt. Diese menschlichen Beobachtungen spiegelten sich jedoch nicht im Modell wider. In der Saison 2020, die im Juli beginnt (wenn nichts Unerwartetes passiert), möchte ich dieses Modell in einem Wettbewerb gegen Live-Prognostiker testen und außerdem feststellen,wie es besser gemacht werden kann.
Darüber hinaus hoffe ich, mit der Formel-1-Fan-Community in Resonanz zu treten und zu glauben, dass wir durch den Austausch von Ideen besser verstehen können, was die Ergebnisse von Qualifikationen und Rennen ausmacht, und dies ist letztendlich das Ziel jeder Person, die Vorhersagen trifft.