Bayt.
Warum sollte ich mir Sorgen machen?
Die Daten werden in Form von Datenstrukturen wie Objekten, Listen, Arrays usw. im Speicher gespeichert. Wenn Sie jedoch Daten über das Netzwerk oder in eine Datei senden möchten, müssen Sie sie als Folge von baytov. Translation codieren Darstellungen im Speicher in einer Folge von Bytes werden als Codierung und inverse Transformation - dekodirovaniem bezeichnet. Schließlich kann sich ein von der Anwendung verarbeitetes oder im Speicher gespeichertes Datendiagramm entwickeln, neue Felder können zu starye hinzugefügt oder daraus entfernt werden. Verwendet Codierung muss muss als Umgekehrt (neuer Code muss be capable read data write old code), so und direct (alter code muss be capable read data wrotenewcode) Kompatibilität.
In
diesem Artikel werden wir eine Vielzahl von Codierungsformaten diskutieren, herausfinden, warum die Binärcodierung besser ist als JSON, XML, und auch als Binärcodierungsmethoden Änderungsschemata unterstützen,
dannyh.
Typen "Formatcodierung"
Esgibt zwei Arten von Codierungsformaten:
- Text Formate
- Binäre Formate
Textformate
Textformatezu einem gewissen Grad chelovekochitaemy. Beispiele für gängige Formate sind JSON, CSV und XML. Textformate sind einfach zu verwenden und zu verstehen, haben jedoch bestimmte Probleme:
- . , XML CSV . JSON , , . . , , 2^53 Twitter, 64- . JSON, API Twitter, ID — JSON- – - , JavaScript- .
- CSV , .
- Textformate beanspruchen mehr Platz als Binärcodierung. Einer der Gründe ist beispielsweise, dass JSON und XML schemenlos sind und daher Feldnamen enthalten müssen.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}Die JSON-Codierung dieses Beispiels benötigt 82 Byte, nachdem alle Leerzeichen entfernt wurden.
Binäre Codierung
Für Datenanalysen, die nur intern verwendet werden, können Sie ein schlankeres oder schnelleres Format auswählen. Obwohl JSON weniger ausführlich als XML ist, nehmen beide im Vergleich zu Binärformaten immer noch viel Platz ein. In diesem Artikel werden drei verschiedene binäre Codierungsformate erläutert:
- Sparsamkeit
- Protokollpuffer
- Avro
Alle bieten eine effiziente Serialisierung von Daten mithilfe von Schemas und Tools zum Generieren von Code sowie Unterstützung für die Arbeit mit verschiedenen Programmiersprachen. Sie alle unterstützen die Schemaentwicklung und bieten sowohl Abwärts- als auch Vorwärtskompatibilität.
Sparsamkeits- und Protokollpuffer
Thrift wird von Facebook und Protocol Buffers von Google entwickelt. In beiden Fällen ist ein Schema erforderlich, um die Daten zu codieren. Thrift definiert ein Schema mithilfe seiner eigenen Interface Definition Language (IDL).
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}
Äquivalentes Schema für Protokollpuffer:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}Wie Sie sehen können, hat jedes Feld einen Datentyp und eine Tag-Nummer (1, 2 und 3). Thrift hat zwei verschiedene binäre Codierungsformate: BinaryProtocol und CompactProtocol. Das Binärformat ist wie unten gezeigt einfach und benötigt 59 Bytes, um die obigen Daten zu codieren.
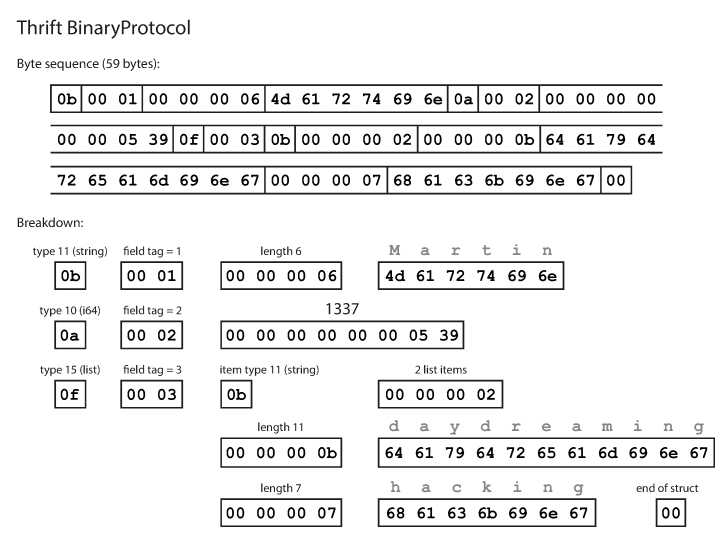
Codierung mit dem Thrift-Binärprotokoll Das
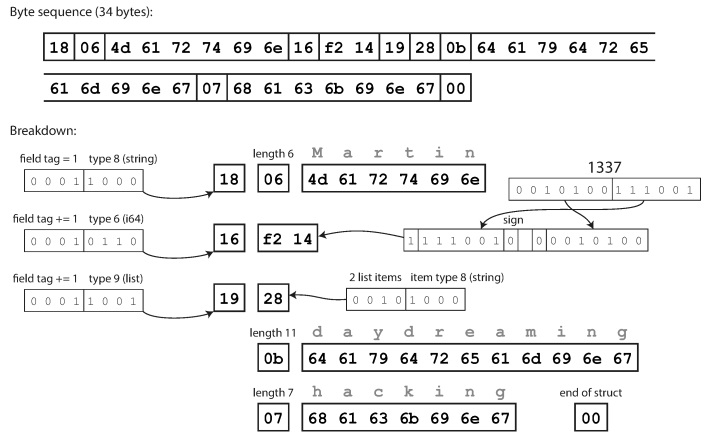
Kompaktprotokoll entspricht semantisch dem Binärprotokoll, packt jedoch die gleichen Informationen in nur 34 Bytes. Einsparungen werden erzielt, indem der Feldtyp und die Tag-Nummer in ein Byte gepackt werden.
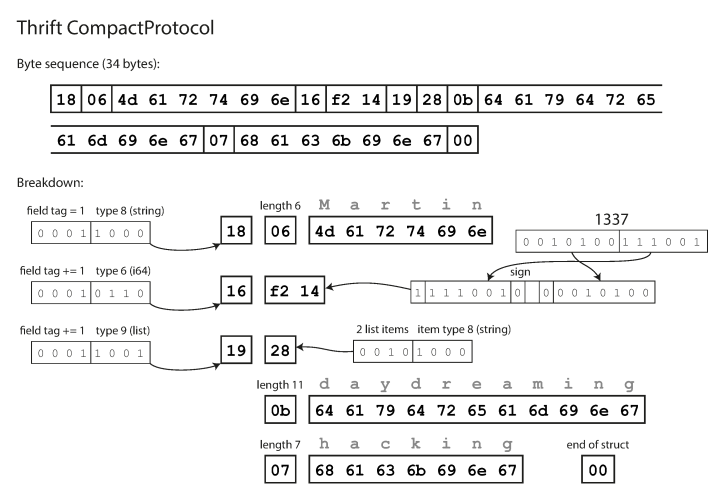
Die Codierung mit Thrift Compact
Protocol Buffers codiert Daten auf ähnliche Weise wie das Thrift Compact Protocol. Nach der Codierung betragen dieselben Daten 33 Byte.
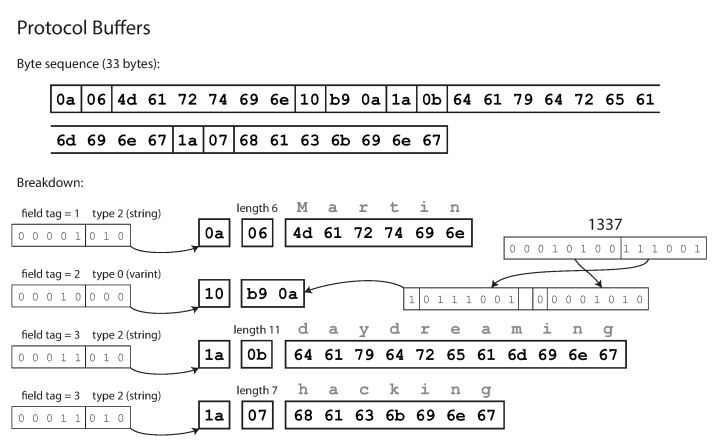
Codierung mit Protokollpuffern
Tag-Nummern unterstützen die Entwicklung von Schemata in Thrift- und Protokollpuffern. Wenn der alte Code versucht, mit dem neuen Schema geschriebene Daten zu lesen, werden die Felder mit den neuen Tag-Nummern einfach ignoriert. Ebenso kann neuer Code Daten lesen, die im alten Schema geschrieben wurden, indem die Werte für fehlende Tag-Nummern als Null markiert werden.
Avro
Avro unterscheidet sich von Protocol Buffers und Thrift. Avro verwendet auch ein Schema, um Daten zu definieren. Das Schema kann mit der Avro IDL (Human Readable Format) definiert werden:
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
Oder JSON (ein maschinenlesbareres Format):
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
Beachten Sie, dass die Felder keine Beschriftungsnummern haben. Dieselben mit Avro codierten Daten benötigen nur 32 Byte.
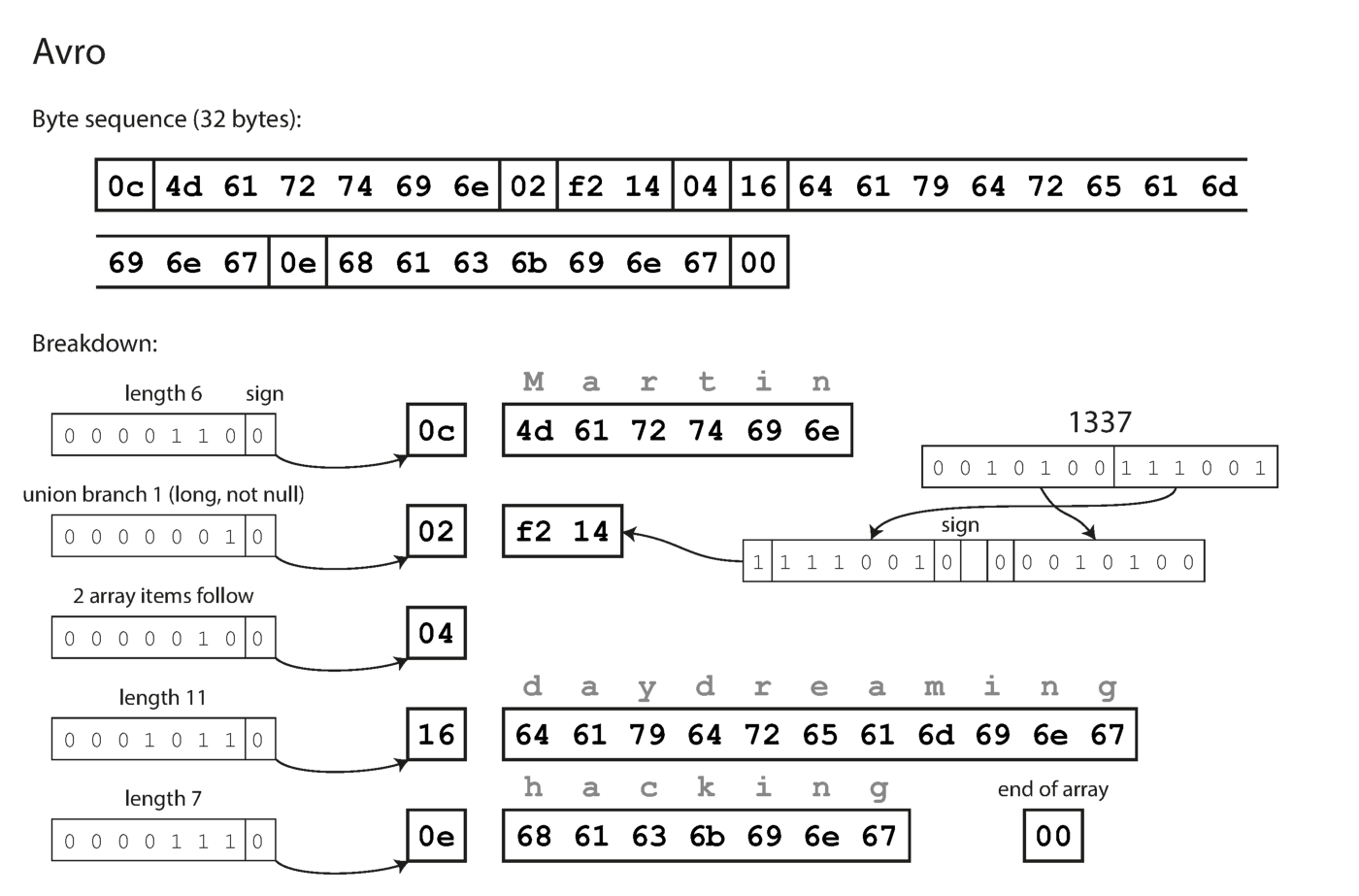
Codierung mit Avro.
Wie Sie aus der obigen Folge von Bytes sehen können, können die Felder nicht identifiziert werden (in Thrift- und Protokollpuffer werden hier Bezeichnungen mit Nummern verwendet), es ist auch unmöglich, den Datentyp des Feldes zu bestimmen. Die Werte werden einfach zusammengesetzt. Bedeutet dies, dass jede Änderung der Schaltung während der Decodierung falsche Daten erzeugt? Die Schlüsselidee von Avro ist, dass das Schema zum Schreiben und Lesen nicht dasselbe sein muss, sondern kompatibel sein muss. Wenn die Daten decodiert werden, löst die Avro-Bibliothek dieses Problem, indem sie beide Schaltkreise betrachtet und die Daten von der Rekorderschaltung in die Leseschaltung übersetzt.
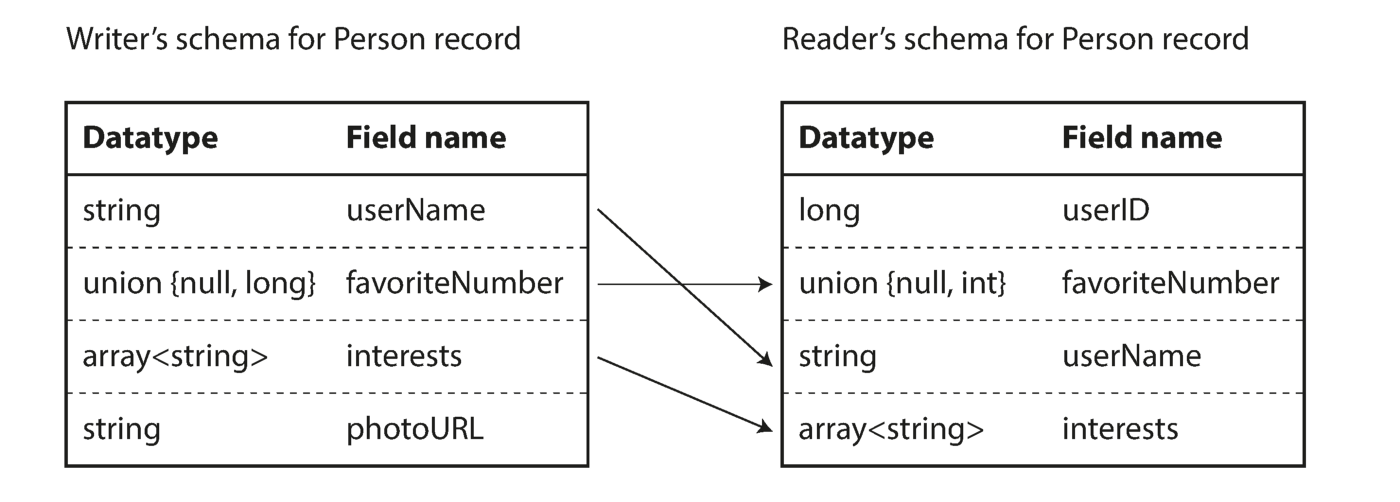
Beseitigung des Unterschieds zwischen Leser- und Schreibschaltung
Sie denken wahrscheinlich darüber nach, wie der Leser von der Schreibschaltung erfährt. Alles dreht sich um das Codierungsnutzungsszenario.
- Bei der Übertragung großer Dateien oder Daten kann der Rekorder die Schaltung einmal am Anfang der Datei einfügen.
- In einer Datenbank mit einzelnen Datensätzen kann jede Zeile mit einem eigenen Schema geschrieben werden. Die einfachste Lösung besteht darin, am Anfang jedes Eintrags eine Versionsnummer einzufügen und eine Liste der Schemas zu führen.
- Um einen Datensatz über das Netzwerk zu senden, können sich Leser und Schreiber beim Herstellen der Verbindung auf ein Schema einigen.
Einer der Hauptvorteile der Verwendung des Avro-Formats ist die Unterstützung dynamisch generierter Schemas. Da keine nummerierten Tags generiert werden, können Sie ein Versionskontrollsystem verwenden, um verschiedene Einträge zu speichern, die mit verschiedenen Schemata codiert sind.
Fazit
In diesem Artikel haben wir uns mit Text- und Binärcodierungsformaten befasst und erläutert, wie dieselben Daten 82 Bytes mit JSON-Codierung, 33 Bytes mit Thrift- und Protokollpuffern und nur 32 Bytes mit Avro-Codierung belegen können. Binärformate bieten gegenüber JSON verschiedene Vorteile, wenn Daten über das Netzwerk zwischen Back-End-Diensten übertragen werden.
Ressourcen
Um mehr über das Codieren und Entwerfen datenintensiver Anwendungen zu erfahren, empfehle ich dringend, das Buch Entwerfen datenintensiver Anwendungen von Martin Kleppman zu lesen.

In den kostenpflichtigen Online-Kursen von SkillFactory erfahren Sie, wie Sie einen hochkarätigen Beruf von Grund auf neu aufbauen oder Ihre Fähigkeiten und Ihr Gehalt verbessern können:
- Kurs für maschinelles Lernen (12 Wochen)
- Data Science von Grund auf lernen (12 Monate)
- Analytics-Beruf mit jedem Startlevel (9 Monate)
- Python für Webentwicklungskurs (9 Monate)