Heute möchte ich über etwas anderes sprechen - über etwas, das in keiner Weise zu Best Practices gehört, mit dessen Hilfe es sehr einfach ist, sich in den Fuß zu schießen und eine zuvor ausgeführte Abfrage langsamer zu machen oder aufgrund eines Fehlers überhaupt nicht mehr auszuführen ... Es geht um Hinweise und Plananleitungen.
Hinweise sind Hinweise zum Abfrageoptimierer, eine vollständige Liste finden Sie auf MSDN . Einige davon sind wirklich Hinweise (z. B. können Sie OPTION (MAXDOP 4) angeben), damit die Abfrage mit maximalem Parallelitätsgrad = 4 ausgeführt werden kann. Es gibt jedoch keine Garantie dafür, dass SQL Server überhaupt einen parallelen Plan mit diesem Hinweis generiert.
Der andere Teil ist eine direkte Anleitung zum Handeln. Wenn Sie beispielsweise OPTION (HASH JOIN) schreiben, erstellt SQL Server einen Plan ohne NESTED LOOPS und MERGE JOINs. Und wissen Sie, was passieren wird, wenn sich herausstellt, dass es unmöglich ist, einen Plan mit nur Hash-Joins zu erstellen? Der Optimierer sagt dies - ich kann keinen Plan erstellen und die Abfrage wird nicht ausgeführt.
Das Problem ist, dass es nicht sicher ist (zumindest für mich), welche Hinweise Hinweise sind, in die der Optimierer hämmern kann; und welche Hinweise sind manuelle Hinweise, die dazu führen können, dass die Anforderung abstürzt, wenn etwas schief geht. Sicherlich gibt es bereits eine fertige Sammlung, in der dies beschrieben wird, aber dies sind auf keinen Fall offizielle Informationen und können sich jederzeit ändern.
Plan Guide ist so etwas (was ich nicht richtig übersetzen kann), dass Sie einen bestimmten Satz von Hinweisen an eine bestimmte Anfrage binden können, deren Text Sie kennen. Dies kann relevant sein, wenn Sie beispielsweise den vom ORM generierten Anforderungstext nicht direkt beeinflussen können.
Sowohl Hinweise als auch Planleitfäden sind keineswegs bewährte Methoden. Es wird daher empfohlen, Hinweise und diese Leitfäden wegzulassen, da sich die Verteilung von Daten ändern kann, sich Datentypen ändern können und eine Million weitere Dinge passieren können, aufgrund derer Ihre Abfragen mit Hinweisen funktionieren schlechter als ohne sie und funktionieren in einigen Fällen überhaupt nicht mehr. Sie müssen hundertprozentig wissen, was Sie tun und warum.
Nun eine kleine Erklärung, warum ich überhaupt darauf gekommen bin.
Ich habe eine breite Tabelle mit einer Reihe von NVARAR-Feldern unterschiedlicher Größe - von 10 bis max. Diese Tabelle enthält eine Reihe von Abfragen, nach denen CHARINDEX in einer oder mehreren dieser Spalten nach Vorkommen von Teilzeichenfolgen sucht. Zum Beispiel gibt es eine Anfrage, die so aussieht:
SELECT *
FROM table
WHERE CHARINDEX(N' ', column)>1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET x ROWS FETCH NEXT y ROWS ONLYDie Tabelle enthält einen Clustered-Index für die ID und einen nicht eindeutigen, nicht gruppierten Index für die Spalte. Wie Sie selbst verstehen, hat dies alles keinen Sinn, da wir in WHERE CHARINDEX verwenden, was definitiv nicht SARGable ist. Um mögliche Probleme mit dem SB zu vermeiden, werde ich diese Situation in der offenen Datenbank StackOverflow2013 simulieren, die hier zu finden ist .
Betrachten Sie die Tabelle dbo.Posts, die nur einen Clustered-Index nach ID und eine Abfrage wie die folgende enthält:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLYUm mit meiner realen Datenbank übereinzustimmen, erstelle ich einen Index für die Spalte Titel:
CREATE INDEX ix_Title ON dbo.Posts (Title);Als Ergebnis erhalten wir natürlich einen absolut logischen Ausführungsplan, der darin besteht, den Clustered-Index in die entgegengesetzte Richtung zu scannen:
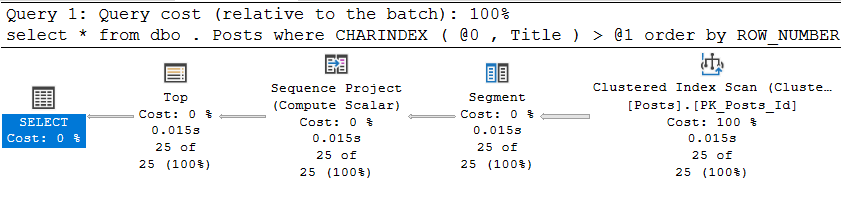

Und er wird zugegebenermaßen recht gut ausgeführt:
Tabelle 'Beiträge'. Scananzahl 1, logische Lesevorgänge 516, physische Lesevorgänge 0, Vorlesevorgänge 0, Lob-Lesevorgänge 0, Lob-Lesevorgänge 0, Vorlesevorgänge 0.
SQL Server-Ausführungszeiten:
CPU-Zeit = 16 ms
Aber was passiert, wenn wir anstelle des gebräuchlichen Wortes "Daten" nach etwas Seltenerem suchen? Zum Beispiel N'Aptana '(keine Ahnung, was es ist). Der Plan wird natürlich derselbe bleiben, aber die Ausführungsstatistik wird sich etwas ändern:
Tabelle 'Beiträge'. Scananzahl 1, logische Lesevorgänge 253191, physische Lesevorgänge 113, Vorlesevorgänge 224602, logische Vorlesevorgänge 0, physische Vorlesevorgänge 0, Vorlesevorgänge 0.
SQL Server-Ausführungszeiten:
CPU-Zeit = 2563 ms
Und das ist auch logisch - das Wort ist viel seltener und SQL Server muss viel mehr Daten scannen, um 25 Zeilen damit zu finden. Aber irgendwie ist es nicht cool, oder?
Und ich habe einen nicht gruppierten Index erstellt. Vielleicht wäre es besser, wenn SQL Server es verwendet? Er selbst wird es nicht benutzen, also füge ich einen Hinweis hinzu:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Title)));Und etwas ist irgendwie völlig traurig. Ausführungsstatistik:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Posts'. Scan count 5, logical reads 109312, physical reads 5, read-ahead reads 104946, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 35031 ms
und der Plan:

Jetzt ist der Ausführungsplan parallel und hat zwei Arten, beide mit Überläufen in Tempdb. Achten Sie übrigens vor der Schlüsselsuche auf die erste Sortierung, die nach einem nicht gruppierten Index-Scan durchgeführt wird. Hierbei handelt es sich um eine spezielle SQL Server-Optimierung, mit der versucht wird, die Anzahl der zufälligen E / A-Schlüssel-Suchvorgänge in aufsteigender Reihenfolge des gruppierten Indexschlüssels zu verringern. Mehr dazu lesen Sie hier .
Die zweite Sortierung wird benötigt, um 25 Zeilen in absteigender Reihenfolge auszuwählen. Übrigens könnte SQL Server davon ausgehen, dass es erneut nach ID sortieren muss, nur in absteigender Reihenfolge, und die Schlüsselsuche in der "entgegengesetzten" Richtung durchführen muss, wobei der Clustered-Indexschlüssel zu Beginn in absteigender Reihenfolge und nicht in aufsteigender Reihenfolge sortiert wird.
Ich biete keine Statistiken zur Ausführung einer Abfrage mit einem Hinweis auf einen nicht gruppierten Index mit einer Suche nach dem Eintrag 'Daten'. Auf meiner halb toten Festplatte in einem Laptop dauerte es mehr als 16 Minuten und ich dachte nicht daran, einen Screenshot zu machen. Entschuldigung, ich möchte nicht mehr so lange warten.
Aber was ist mit der Anfrage? Ist ein Clustered-Index-Scan der ultimative Traum und Sie können nichts schneller machen?
Was wäre, wenn ich versuchen würde, alle möglichen Arten zu vermeiden? Ich dachte und erstellte einen Index ohne Cluster, der im Allgemeinen dem widerspricht, was normalerweise als Best Practices für Indizes ohne Cluster angesehen wird:
CREATE INDEX ix_Id_Title ON dbo.Posts (Id DESC, Title);Jetzt verwenden wir den Hinweis, um SQL Server anzuweisen, ihn zu verwenden:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Id_Title)));Oh, es hat gut funktioniert:

Tabelle 'Beiträge'. Scananzahl 1, logische Lesevorgänge 6259, physische Lesevorgänge 0, Vorlesevorgänge 7816, Lob-Lesevorgänge 0, Lob-Lesevorgänge 0, Vorlesevorgänge 0.
SQL Server-Ausführungszeiten:
CPU-Zeit = 1734 ms
Der Gewinn an Prozessorzeit ist nicht groß, aber Sie müssen viel weniger lesen - nicht schlecht. Was ist mit den häufigen "Daten"?
Tabelle 'Beiträge'. Scananzahl 1, logische Lesevorgänge 208, physische Lesevorgänge 0, Vorlesevorgänge 0, Lob-Lesevorgänge 0, Lob-Lesevorgänge 0, Lobvorlesevorgänge 0.
SQL Server-Ausführungszeiten:
CPU-Zeit = 0 ms
Wow, das ist auch gut. Da die Anfrage nun vom ORM stammt und wir ihren Text nicht ändern können, müssen wir herausfinden, wie dieser Index an die Anfrage "genagelt" werden kann. Und der Planführer kommt zur Rettung.
Die gespeicherte Prozedur sp_create_plan_guide ( MSDN ) wird zum Erstellen eines Planleitfadens verwendet .
Betrachten wir es im Detail:
sp_create_plan_guide [ @name = ] N'plan_guide_name'
, [ @stmt = ] N'statement_text'
, [ @type = ] N'{ OBJECT | SQL | TEMPLATE }'
, [ @module_or_batch = ]
{
N'[ schema_name. ] object_name'
| N'batch_text'
| NULL
}
, [ @params = ] { N'@parameter_name data_type [ ,...n ]' | NULL }
, [ @hints = ] {
N'OPTION ( query_hint [ ,...n ] )'
| N'XML_showplan'
| NULL
} Name - klarer, eindeutiger Planleitfadenname
stmt- Dies ist die Anfrage, zu der Sie den Hinweis hinzufügen müssen. Es ist wichtig zu wissen, dass diese Anfrage genau so geschrieben werden muss wie die Anfrage, die aus der Anwendung stammt. Seltsamer Platz? Der Plan Guide wird nicht verwendet. Falscher Zeilenumbruch? Der Plan Guide wird nicht verwendet. Um es sich leichter zu machen, gibt es einen "Life Hack", auf den ich etwas später zurückkommen werde (und den ich hier gefunden habe ).
Art - gibt an, wo die Anforderung in angegeben ist stmt. Wenn es Teil einer gespeicherten Prozedur ist, sollte es OBJECT sein. Wenn dies Teil eines Stapels aus mehreren Anforderungen ist oder es sich um eine Ad-hoc-Anforderung oder einen Stapel aus einer Anforderung handelt, sollte SQL vorhanden sein. Wenn hier TEMPLATE angegeben ist, handelt es sich um eine separate Geschichte zur Abfrageparametrisierung, über die Sie in MSDN lesen können .
@module_or_batch hängt von abArt. Wenn eineArt= 'OBJECT', dies sollte der Name der gespeicherten Prozedur sein. Wenn eineArt= 'BATCH' - Es sollte den Text des gesamten Stapels geben, der Wort für Wort mit den Angaben aus den Anwendungen angegeben wird. Seltsamer Platz? Nun, du weißt es schon. Wenn es NULL ist, wird davon ausgegangen, dass dies ein Stapel aus einer Anforderung ist und mit den Angaben in übereinstimmtstmt mit allen Einschränkungen.
params- Alle Parameter, die zusammen mit den Datentypen an die Anfrage übergeben werden, sollten hier aufgelistet werden.
@hints ist endlich der nette Teil, hier müssen Sie angeben, welche Hinweise der Anfrage hinzugefügt werden sollen. Hier können Sie den erforderlichen Ausführungsplan gegebenenfalls explizit im XML-Format einfügen. Dieser Parameter kann auch NULL sein, was dazu führt, dass SQL Server keine Hinweise verwendet, die in der Abfrage in explizit angegeben sindstmt.
Daher erstellen wir einen Planleitfaden für die Abfrage:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N''Data'', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY';
exec sp_create_plan_guide @name = N'PG_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = NULL
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'Und wir versuchen die Anfrage auszuführen:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLYWow, es hat funktioniert:
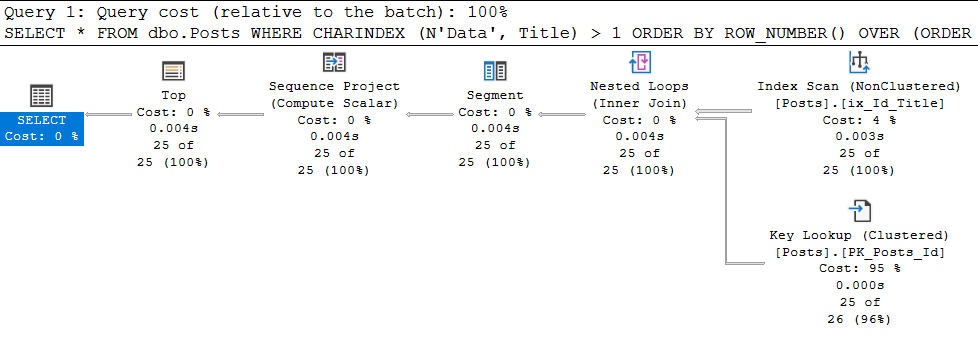
In den Eigenschaften der letzten SELECT-Anweisung sehen wir:

Großartig, der Plan giude wurde angewendet. Was ist, wenn Sie jetzt nach 'Aptana' suchen? Und alles wird schlecht - wir werden wieder zum Scan des Clustered-Index mit allen Konsequenzen zurückkehren. Warum? Und weil der Planleitfaden auf eine SPEZIFISCHE Abfrage angewendet wird, deren Text eins zu eins mit dem ausführenden übereinstimmt.
Zum Glück sind die meisten Anfragen auf meinem System parametrisiert. Ich habe nicht mit nicht parametrisierten Abfragen gearbeitet und hoffe, dass ich das nicht muss. Für sie können Sie Vorlagen verwenden (siehe etwas weiter oben in TEMPLATE), die FORCED PARAMETERIZATION in der Datenbank aktivieren ( tun Sie dies nicht, ohne zu verstehen, was Sie tun !!! ), und möglicherweise können Sie danach den Plan Guide verknüpfen. Aber ich habe es wirklich nicht versucht.
In meinem Fall wird die Anforderung folgendermaßen ausgeführt:
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
, @p0 = N'Aptana', @p1 = 0, @p2 = 25;Deshalb erstelle ich einen entsprechenden Planleitfaden:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;';
exec sp_create_plan_guide @name = N'PG_paramters_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = N'@p0 nvarchar(250), @p1 int, @p2 int'
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'Und, Hurra, alles funktioniert wie erforderlich:
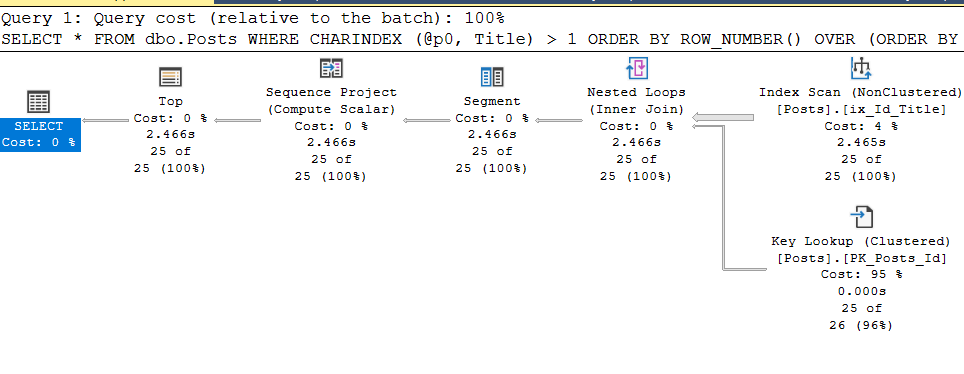

Da es sich außerhalb der Gewächshausbedingungen befindet, ist es nicht immer möglich, den Parameter korrekt anzugebenstmtum einer Anfrage einen Planleitfaden beizufügen, und dafür gibt es einen "Life Hack", den ich oben erwähnt habe. Wir leeren den Plan-Cache, löschen die Hilfslinien, führen die parametrisierte Abfrage erneut aus und holen den Ausführungsplan und das plan_handle aus dem Cache.
Eine Anfrage hierfür kann beispielsweise folgendermaßen verwendet werden:
SELECT qs.plan_handle, st.text, qp.query_plan
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text (qs.sql_handle) st
CROSS APPLY sys.dm_exec_query_plan (qs.plan_handle) qp
Wir können jetzt die gespeicherte Prozedur sp_create_plan_guide_from_handle verwenden, um einen Planleitfaden aus einem vorhandenen Plan zu erstellen.
Es nimmt als ParameterName- Der Name des erstellten Leitfadens, @plan_handle - das Handle des vorhandenen Ausführungsplans und @statement_start_offset - definiert den Beginn der Anweisung in dem Stapel, für den der Leitfaden erstellt werden soll.
Versuch:
exec sp_create_plan_guide_from_handle N'PG_dboPosts_from_handle'
, 0x0600050018263314F048E3652102000001000000000000000000000000000000000000000000000000000000
, NULL;Und jetzt schauen wir uns in SSMS an, was wir in Programmierbarkeit -> Planhandbücher haben:

Jetzt wurde der aktuelle Ausführungsplan mithilfe des Planleitfadens 'PG_dboPosts_from_handle' an unsere Anfrage "genagelt", aber am besten jetzt, wie fast jedes Objekt In SSMS können wir Skripte erstellen und neu erstellen, wie wir es benötigen.
RMB, Skript -> Löschen UND Erstellen und wir erhalten ein vorgefertigtes Skript, in dem wir den Wert des Parameters @hints durch den Wert ersetzen müssen, den wir benötigen. Als Ergebnis erhalten wir:
USE [StackOverflow2013]
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_control_plan_guide @operation = N'DROP', @name = N'[PG_dboPosts_from_handle]'
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_create_plan_guide @name = N'[PG_dboPosts_from_handle]', @stmt = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY', @type = N'SQL', @module_or_batch = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;',
@params = N'@p0 nvarchar(250), @p1 int, @p2 int',
@hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'
GOWir führen die Anfrage aus und führen sie erneut aus. Hurra, alles funktioniert:

Wenn Sie den Parameterwert ersetzen, funktioniert alles auf die gleiche Weise.
Bitte beachten Sie, dass nur eine Anleitung einer Aussage entsprechen kann. Wenn Sie versuchen, derselben Anweisung einen weiteren Leitfaden hinzuzufügen, wird eine Fehlermeldung angezeigt.
Nachricht 10502, Ebene 16,
Status 1, Zeile 1 Planleitfaden 'PG_dboPosts_from_handle2' kann nicht erstellt werden, da die Anweisung von angegeben wirdstmtund @module_or_batch oder @plan_handle und @statement_start_offset stimmen mit dem vorhandenen Planleitfaden 'PG_dboPosts_from_handle' in der Datenbank überein. Löschen Sie den vorhandenen Planleitfaden, bevor Sie den neuen Planleitfaden erstellen.
Das Letzte, was ich erwähnen möchte, ist die gespeicherte Prozedur sp_control_plan_guide .
Mit seiner Hilfe können Sie Plan-Guides löschen, deaktivieren und aktivieren - sowohl einzeln als auch unter Angabe des Namens und aller Guides (ich bin mir nicht sicher - alles überhaupt. Oder alles im Kontext der Datenbank, in der die Prozedur ausgeführt wird) - Werte werden dafür verwendet Parameter @operation - ALL TROPFEN, ALLE DEAKTIVIEREN, ALLE AKTIVIEREN. Ein Beispiel für die Verwendung von HP für einen bestimmten Plan finden Sie oben - ein bestimmter Planleitfaden mit dem angegebenen Namen wird gelöscht.
War es möglich, auf Hinweise und einen Planungsleitfaden zu verzichten?
Im Allgemeinen, wenn es Ihnen so vorkommt, als wäre der Abfrageoptimierer dumm und macht eine Art Spiel, und Sie wissen, wie am besten, mit einer Wahrscheinlichkeit von 99%, machen Sie eine Art Spiel (wie in meinem Fall). Wenn Sie jedoch nicht in der Lage sind, den Anfragetext direkt zu beeinflussen, kann ein Planleitfaden, mit dem Sie der Anforderung einen Hinweis hinzufügen können, ein Lebensretter sein. Angenommen, wir können den Anforderungstext nach Bedarf neu schreiben. Kann dies etwas ändern? Sicher! Auch ohne die Verwendung von "exotisch" in Form einer Volltextsuche, die hier eigentlich verwendet werden sollte. Eine solche Abfrage verfügt beispielsweise über eine völlig normale Plan- und Ausführungsstatistik (für eine Abfrage):
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Tabelle 'Beiträge'. Scananzahl 1, logische Lesevorgänge 6250, physische Lesevorgänge 0, Vorlesevorgänge 0, Lob-Lesevorgänge 0, Lob-Lesevorgänge 0, Vorlesevorgänge 0.
SQL Server-Ausführungszeiten:
CPU-Zeit = 1500 ms
SQL Server findet zuerst die erforderlichen 25 Bezeichner anhand des "krummen" Indexes von ix_Id_Title und führt erst dann eine Suche im Clustered-Index mit den ausgewählten Bezeichnern durch - sogar besser als mit der Anleitung! Aber was passiert, wenn wir eine Abfrage für 'Daten' ausführen und 25 Zeilen ab der 20.000sten Zeile anzeigen:
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 20000 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Tabelle 'Beiträge'. Scananzahl 1, logische Lesevorgänge 5914, physische Lesevorgänge 0, Vorlesevorgänge 0, Lob-Lesevorgänge 11, Lob-Lesevorgänge 0, Lobvorlesevorgänge 0.
SQL Server-Ausführungszeiten:
CPU-Zeit = 1453 ms
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
, @p0 = N'Data', @p1 = 20000, @p2 = 25;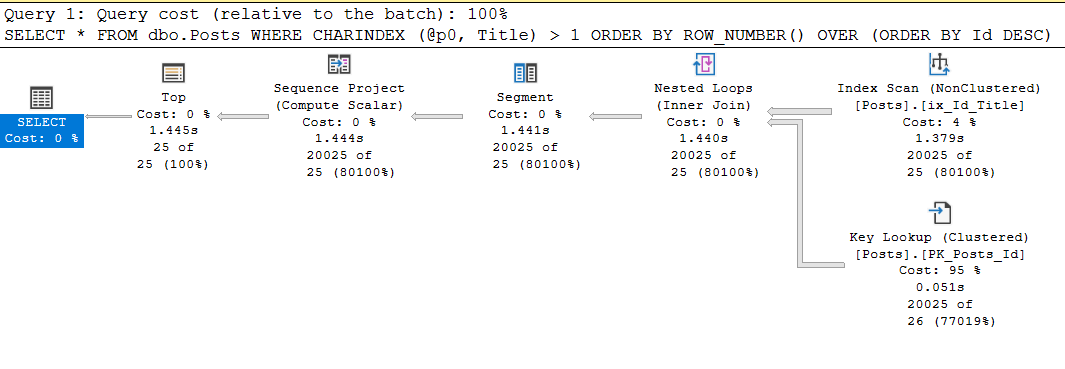
Table 'Posts'. Scan count 1, logical reads 87174, physical reads 0, read-ahead reads 0, lob logical reads 11, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1437 ms
Ja, die Prozessorzeit ist dieselbe, da sie für den Zeichenindex verwendet wird, aber die Anforderung mit dem Handbuch führt eine Größenordnung mehr Lesevorgänge durch, und dies kann zu einem Problem werden.
Lassen Sie mich das Endergebnis zusammenfassen. Hinweise und Anleitungen können Ihnen im Hier und Jetzt sehr helfen, aber sie können die Dinge leicht noch schlimmer machen. Wenn Sie im Anfragetext explizit einen Hinweis mit einem Index angeben und dann den Index löschen, kann die Abfrage einfach nicht ausgeführt werden. Auf meinem SQL Server 2017 wird die Abfrage mit dem Handbuch nach dem Löschen des Index einwandfrei ausgeführt. Das Handbuch wird ignoriert, aber ich kann nicht sicher sein, dass dies immer so und in allen Versionen von SQL Server der Fall ist.
Es gibt nicht viele Informationen über den Planführer auf Russisch, deshalb habe ich beschlossen, ihn selbst zu schreiben. Sie können hier lesenüber Einschränkungen bei der Verwendung von Planleitfäden, insbesondere über die Tatsache, dass manchmal eine explizite Angabe des Index mit einem Hinweis unter Verwendung von PG dazu führen kann, dass Anforderungen fallen. Ich wünschte, Sie würden sie niemals benutzen, und wenn Sie - nun, viel Glück - müssen, wissen Sie, wohin das führen kann.