Um einen Überblick zu erhalten, haben wir 10 Jahre lang die Arbeiten der CHI: Konferenz über Human Factors in Computersystemen durchgeführt und mithilfe von NLP und der Analyse sozialer Netzwerke Themen und Bereiche an der Schnittstelle von Disziplinen untersucht.

In Russland liegt der Fokus besonders stark auf angewandten Problemen des UX-Designs. Viele der Ereignisse, die zum Wachstum von HCI im Ausland beigetragen haben, fanden in unserem Land nicht statt: iSchools sind nicht erschienen , viele Spezialisten, die mit verwandten Aspekten der Ingenieurpsychologie befasst waren, haben die Wissenschaft verlassen usw. Infolgedessen tauchte der Beruf wieder auf, angefangen bei angewandten Problemen und Forschung. Eines der Ergebnisse ist bereits jetzt sichtbar - es ist die äußerst geringe Repräsentation der russischen HCI-Arbeit auf Schlüsselkonferenzen.
Außerhalb Russlands hat sich HCI jedoch auf sehr unterschiedliche Weise entwickelt und sich auf eine Vielzahl von Themen und Bereichen konzentriert. Im Masterstudiengang " Informationssysteme und Mensch-Computer-Interaktion„An der HSE in St. Petersburg diskutieren wir unter anderem mit Studenten, Kollegen, Absolventen ähnlicher Fachrichtungen europäischer Universitäten und Partnern, die an der Entwicklung des Programms beteiligt sind, was zum Bereich der Mensch-Computer-Interaktion gehört. Und diese Diskussionen zeigen die Heterogenität der Richtung, in die jeder Spezialist sein eigenes, unvollständiges Bild des Fachgebiets hat.
Von Zeit zu Zeit hören wir Fragen, wie diese Richtung mit maschinellem Lernen und Datenanalyse zusammenhängt (und ob sie überhaupt verbunden ist). Um sie zu beantworten, haben wir uns den jüngsten Forschungsergebnissen zugewandt, die auf der CHI- Konferenz vorgestellt wurden .
Zunächst werden wir Ihnen erzählen, was in Bereichen wie xAI und iML (eXplainable Artificial Intelligence und Interpretable Machine Learning) geschieht. Von der Seite der Schnittstellen und Benutzer sowie wie sie in HCI die kognitiven Aspekte der Arbeit von Datenwissenschaftlern untersuchen, werden wir Beispiele für interessante Arbeiten der letzten Jahre in jedem Bereich geben.
xAI und iML
Techniken des maschinellen Lernens werden intensiv weiterentwickelt und - was noch wichtiger ist, aus Sicht des diskutierten Bereichs - aktiv in die automatisierte Entscheidungsfindung implementiert. Daher diskutieren Forscher zunehmend die folgenden Fragen: Wie interagieren Benutzer ohne maschinelles Lernen mit Systemen, in denen ähnliche Algorithmen verwendet werden? Eine der wichtigen Fragen dieser Interaktion: Wie können Benutzer den Entscheidungen der Modelle vertrauen? Daher werden die Themen interpretiertes maschinelles Lernen (Interpretierbares Maschinelles Lernen - iML) und erklärbare künstliche Intelligenz (eXplainable Artificial Intelligence - XAI) von Jahr zu Jahr heißer.
Wenn auf Konferenzen wie NeurIPS, ICML, IJCAI, KDD die Algorithmen und Mittel von iML und XAI erörtert werden, konzentriert sich das CHI gleichzeitig auf verschiedene Themen im Zusammenhang mit den Konstruktionsmerkmalen und der Erfahrung bei der Verwendung dieser Systeme. Zum Beispiel wurden bei CHI-2020 mehrere Abschnitte gleichzeitig diesem Thema gewidmet, darunter „AI / ML & Durchschauen der Black Box“ und „Umgang mit AI: nicht wieder!“. Aber schon vor dem Erscheinen separater Abschnitte gab es viele solcher Werke. Wir haben vier Bereiche in ihnen identifiziert.
Entwurf von Interpretationssystemen zur Lösung angewandter Probleme
Die erste Richtung ist der Entwurf von Systemen, die auf Interpretierbarkeitsalgorithmen in verschiedenen angewandten Problemen basieren: medizinisch, sozial usw. Solche Arbeiten entstehen in sehr unterschiedlichen Bereichen. Zum Beispiel bei CHI-2020 CheXplain arbeiten: Ärzte in die Lage versetzen, datengesteuerte, AI-fähige medizinische Bildgebungsanalysen zu erforschen und zu verstehen beschreibt ein System, mit dem Ärzte die Ergebnisse der Röntgenaufnahme des Brustkorbs untersuchen und erklären können. Sie bietet zusätzliche textuelle und visuelle Erklärungen sowie Bilder mit dem gleichen und entgegengesetzten Ergebnis (unterstützende und widersprüchliche Beispiele). Wenn das System vorhersagt, dass eine Krankheit im Röntgenbild sichtbar ist, werden zwei Beispiele angezeigt. Das erste unterstützende Beispiel ist eine Momentaufnahme der Lunge eines anderen Patienten, der dieselbe Krankheit bestätigt hat. Das zweite, widersprüchliche Beispiel ist eine Momentaufnahme, bei der es keine Krankheit gibt, dh eine Momentaufnahme der Lunge eines gesunden Menschen. Die Hauptidee besteht darin, offensichtliche Fehler zu reduzieren und die Anzahl externer Konsultationen in einfachen Fällen zu reduzieren, um eine Diagnose schneller zu machen.
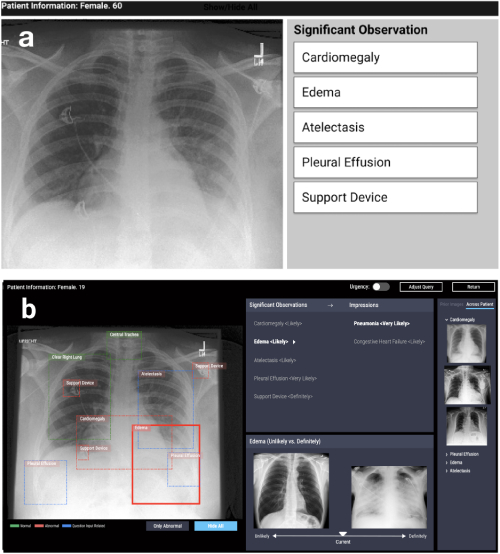
CheXpert: automatisierte Regionsauswahl + Beispiele (unwahrscheinlich vs. definitiv)
Entwicklung von Systemen zur Erforschung maschineller Lernmodelle
Die zweite Richtung ist die Entwicklung von Systemen, mit deren Hilfe verschiedene Methoden und Algorithmen interaktiv verglichen oder kombiniert werden können. Zum Beispiel wurde in der Arbeit von Silva: Interaktive Bewertung der Fairness des maschinellen Lernens mithilfe der Kausalität auf der CHI-2020 ein System vorgestellt, das mehrere Modelle des maschinellen Lernens auf Benutzerdaten aufbaut und die Möglichkeit ihrer anschließenden Analyse bietet. Die Analyse umfasst die Erstellung eines Kausaldiagramms zwischen Variablen und die Berechnung einer Reihe von Metriken, die nicht nur die Genauigkeit, sondern auch die Fairness des Modells bewerten (statistischer Paritätsunterschied, Unterschied bei Chancengleichheit, durchschnittlicher Wahrscheinlichkeitsunterschied, unterschiedliche Auswirkung, Theil-Index), um die Verzerrung zu ermitteln in Vorhersagen.

Silva : Diagramm der Beziehungen zwischen Variablen + Diagramme zum Vergleichen von Fairness-Metriken + Farbhervorhebung einflussreicher Variablen in jeder Gruppe
Allgemeine Fragen der Modellinterpretierbarkeit
Der dritte Bereich ist die Diskussion von Ansätzen zum Problem der Interpretierbarkeit von Modellen im Allgemeinen. Meist handelt es sich dabei um Reviews, Kritik an Ansätzen und offene Fragen: Zum Beispiel, was unter „Interpretierbarkeit“ zu verstehen ist. Hier möchte ich den Rückblick auf CHI-2018 Trends und Trajektorien für erklärbare, rechenschaftspflichtige und verständliche Systeme zur Kenntnis nehmen: Eine HCI-Forschungsagenda, in dem die Autoren 289 wichtige Artikel zu Erklärungen in der künstlichen Intelligenz und 12.412 Veröffentlichungen, in denen sie zitiert wurden, überprüften. Mithilfe von Netzwerkanalysen und Fallmodellen identifizierten sie vier Forschungsschwerpunkte: 1) Intelligente und Umgebungssysteme (I & A), 2) Erklärbare KI: Faire, rechenschaftspflichtige und transparente (FAT) Algorithmen und interpretierbares maschinelles Lernen (iML), 3) Theorien von Erklärungen: Kausalität und kognitive Psychologie, 4) Interaktivität und Lernfähigkeit. Darüber hinaus beschrieben die Autoren die wichtigsten Forschungstrends: interaktives Lernen und Interaktion mit dem System.
Nutzerforschung
Der vierte Bereich ist schließlich die Benutzerforschung zu Algorithmen und Systemen, die maschinelle Lernmodelle interpretieren. Mit anderen Worten, es handelt sich um Studien darüber, ob in der Praxis neue Systeme klarer und transparenter werden, welche Schwierigkeiten Benutzer bei der Arbeit mit interpretativen und nicht mit Originalmodellen haben und wie festgestellt werden kann, ob das System wie geplant verwendet wird (oder ob eine neue Verwendung dafür gefunden wurde). - vielleicht falsch), was sind die Bedürfnisse der Benutzer und ob die Entwickler ihnen anbieten, was sie wirklich brauchen.
Es gibt viele Interpretationswerkzeuge und -algorithmen, daher stellt sich die Frage: Wie kann man verstehen, welchen Algorithmus man wählen soll? Bei der Befragung der KI: Informieren über Entwurfspraktiken für erklärbare KI-BenutzererfahrungenDie Motivationsprobleme für die Verwendung von Erklärungsalgorithmen werden diskutiert und Probleme identifiziert, die mit der Vielfalt der Methoden noch nicht ausreichend gelöst wurden. Die Autoren kommen zu einem unerwarteten Ergebnis: Die meisten vorhandenen Methoden sind so aufgebaut, dass sie die Frage "Warum" ("Warum hatte ich ein solches Ergebnis") beantworten, während Benutzer auch eine Antwort auf die Frage "Warum nicht" ("Warum" benötigen nicht ein anderes ") und manchmal -" was zu tun ist, um das Ergebnis zu ändern. "
Das Papier sagt auch, dass Benutzer verstehen müssen, wo die Grenzen der Anwendbarkeit von Methoden liegen, welche Einschränkungen sie haben - und dies muss explizit in den vorgeschlagenen Tools implementiert werden. Dieses Problem wird im Artikel deutlicher dargestelltInterpretierbarkeit interpretieren: Den Einsatz von Interpretierbarkeitstools für maschinelles Lernen durch Datenwissenschaftler verstehen . Die Autoren führten ein kleines Experiment mit Spezialisten auf dem Gebiet des maschinellen Lernens durch: Sie zeigten die Ergebnisse mehrerer beliebter Werkzeuge zur Interpretation von Modellen des maschinellen Lernens und baten sie, Fragen zu beantworten, die sich auf Entscheidungen beziehen, die auf diesen Ergebnissen basieren. Es stellte sich heraus, dass selbst Experten solchen Modellen zu sehr vertrauen und die Ergebnisse nicht kritisch nehmen. Wie bei jedem Tool können erklärende Modelle missbraucht werden. Bei der Entwicklung des Toolkits ist es wichtig, dies zu berücksichtigen und das gesammelte Wissen (oder die Spezialisten) auf dem Gebiet der Mensch-Computer-Interaktion zu nutzen, um die Merkmale und Bedürfnisse potenzieller Benutzer zu berücksichtigen.
Data Science, Notebooks, Visualization
Ein weiterer interessanter Bereich von HCI ist die Analyse der kognitiven Aspekte der Arbeit mit Daten. In jüngster Zeit hat die Wissenschaft die Frage aufgeworfen, wie sich die „Freiheitsgrade“ des Forschers - die Merkmale der Datenerfassung, des experimentellen Designs und der Wahl der Analysemethoden - auf die Forschungsergebnisse und deren Reproduzierbarkeit auswirken. Während sich ein Großteil der Diskussion und Kritik auf die Psychologie und die Sozialwissenschaften bezieht, betreffen viele Fragen die Zuverlässigkeit von Schlussfolgerungen in der Arbeit von Datenanalysten im Allgemeinen sowie die Schwierigkeiten bei der Übermittlung dieser Ergebnisse an Analysekonsumenten.
Daher ist das Thema dieses HCI-Bereichs die Entwicklung neuer Methoden zur Visualisierung von Unsicherheiten bei Modellvorhersagen, die Erstellung von Systemen zum Vergleich von auf unterschiedliche Weise durchgeführten Analysen sowie die Analyse der Arbeit von Analysten mit Tools wie Jupyter-Notebooks.
Unsicherheit visualisieren
Die Unsicherheitsvisualisierung ist eines der Merkmale, die wissenschaftliche Grafiken von Präsentations- und Geschäftsvisualisierung unterscheiden. Das Prinzip des Minimalismus und der Konzentration auf die Haupttrends galt lange Zeit als Schlüssel für letztere. Dies führt jedoch zu einem übermäßigen Vertrauen der Benutzer in eine Punktschätzung einer Größenordnung oder Prognose, was kritisch sein kann, insbesondere wenn Prognosen mit unterschiedlichen Unsicherheitsgraden verglichen werden müssen. Job Mit Unsicherheit Displays Quantilsgrenzen Dotplots oder CDF verbessern Transit Entscheidungsfindunguntersucht anhand des Beispiels des Problems der Schätzung der Ankunftszeit eines Busses anhand der Daten einer mobilen Anwendung, wie die Visualisierung der Unsicherheit bei der Vorhersage von Streudiagrammen und kumulativen Verteilungsfunktionen den Benutzern hilft, rationalere Entscheidungen zu treffen. Besonders schön ist, dass einer der Autoren das ggdist-Paket für R mit verschiedenen Optionen zum Rendern von Mehrdeutigkeiten verwaltet.

Beispiele für die Visualisierung von Unsicherheiten ( https://mjskay.github.io/ggdist/ ) Es
gibt jedoch häufig Probleme bei der Visualisierung möglicher Alternativen, z. B. für Benutzeraktionssequenzen in der Webanalyse oder Anwendungsanalyse. Die Arbeit zur Visualisierung von Unsicherheiten und Alternativen in Ereignissequenzvorhersagen analysiert, wie eine grafische Darstellung der Alternativen auf der Grundlage des Modells Time-Aware Recurrent Neural Network (TRNN ) Experten hilft, Entscheidungen zu treffen und ihnen zu vertrauen.
Modellvergleich
Ein Aspekt der Arbeit von Analysten ist ebenso wichtig wie die Visualisierung von Unsicherheit. Sie vergleicht, wie oft versteckt die Wahl des Forschers für verschiedene Modellierungsansätze in allen Phasen zu unterschiedlichen Analyseergebnissen führen kann. In der Psychologie und den Sozialwissenschaften gewinnen die Vorregistrierung von Forschungsdesign und eine klare Trennung von explorativen und bestätigenden Studien an Popularität. Bei Aufgaben, bei denen die Forschung stärker datengesteuert ist, können Tools eine Alternative sein, mit denen Sie die verborgenen Risiken der Analyse durch Vergleichen von Modellen bewerten können. Arbeiten zur Erhöhung der Transparenz von Forschungsarbeiten mit erforschbaren Multiversum-Analysenschlägt vor, in Artikeln eine interaktive Visualisierung verschiedener Analyseansätze zu verwenden. Im Wesentlichen wird der Artikel zu einer interaktiven Anwendung, in der der Leser bewerten kann, was sich an den Ergebnissen und Schlussfolgerungen ändert, wenn ein anderer Ansatz angewendet wird. Dies scheint auch für die praktische Analyse eine nützliche Idee zu sein.
Arbeiten mit Tools zum Organisieren und Analysieren von Daten
Der letzte Arbeitsblock bezieht sich auf die Untersuchung, wie Analysten mit Systemen wie Jupyter Notebooks arbeiten, die zu einem beliebten Werkzeug für die Organisation von Datenanalysen geworden sind. Artikel Exploration und Erklärung in Computational Notebooks analysiert die Widersprüche zwischen Forschung und Erläuterung der Lernziele, die in interaktiven Github-Dokumenten gefunden wurden, und Verwalten von Messes in Computational NotebooksDie Autoren analysieren, wie sich Notizen, Codeteile und Visualisierungen in einem iterativen Analysten-Workflow entwickeln, und schlagen mögliche Ergänzungen zu Tools vor, um diesen Prozess zu unterstützen. Bereits bei CHI 2020 werden die Hauptprobleme von Analysten in allen Arbeitsphasen, vom Laden von Daten bis zur Übertragung eines Modells in die Produktion, sowie Ideen zur Verbesserung von Werkzeugen in dem Artikel Was ist los mit Computational Notebooks? Zusammengefasst. Schmerzpunkte, Bedürfnisse und Gestaltungsmöglichkeiten .
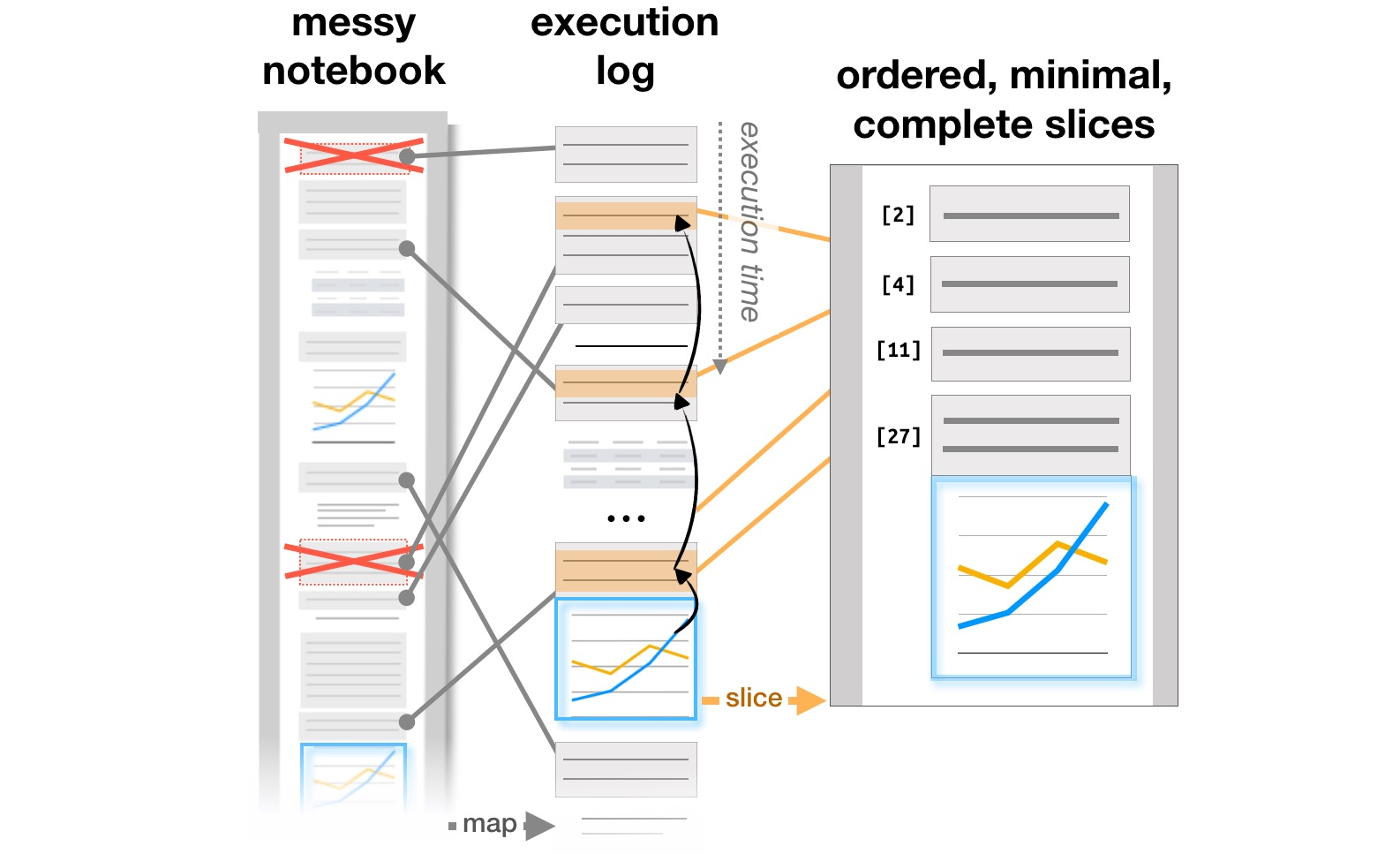
Transformation der Struktur von Berichten basierend auf Ausführungsprotokollen ( https://microsoft.github.io/gather/ )
Zusammenfassen
Abschließend möchte ich den Teil der Diskussion "Was macht HCI?" Und "Warum kennt ein HCI-Spezialist maschinelles Lernen?" Abschließend die allgemeine Schlussfolgerung aus der Motivation und den Ergebnissen dieser Studien wiederholen. Sobald eine Person im System erscheint, führt dies sofort zu einer Reihe weiterer Fragen: Wie kann die Interaktion mit dem System vereinfacht und Fehler vermieden werden, wie ändert der Benutzer das System, ob die tatsächliche Verwendung von der geplanten abweicht. Daher brauchen wir diejenigen, die verstehen, wie der Prozess des Entwurfs von Systemen mit künstlicher Intelligenz funktioniert, und wissen, wie man den menschlichen Faktor berücksichtigt.
All dies unterrichten wir im Masterstudiengang " Informationssysteme und Mensch-Computer-Interaktion"". Wenn Sie an HCI-Forschung interessiert sind, schauen Sie sich das Licht an (die Zulassungskampagne hat gerade begonnen ). Oder folgen Sie unserem Blog: Wir erzählen Ihnen mehr über die Projekte, an denen die Studenten in diesem Jahr gearbeitet haben.