In diesem Artikel möchte ich darüber sprechen, wie unser Team beschlossen hat, den CQRS & Event Sourcing-Ansatz in einem Projekt anzuwenden, das eine Online-Auktionsseite ist. Und auch darüber, was daraus hervorgegangen ist, welche Schlussfolgerungen aus unserer Erfahrung gezogen werden können und welcher Rechen wichtig ist, um nicht auf diejenigen zu treten, die sich für CQRS & ES entscheiden.

Auftakt
Zunächst ein wenig Geschichte und geschäftlicher Hintergrund. Ein Kunde kam zu uns mit einer Plattform für sogenannte zeitgesteuerte Auktionen, die bereits in Produktion war und zu der eine gewisse Anzahl von Rückmeldungen gesammelt wurde. Der Kunde wollte, dass wir für ihn eine Plattform für Live-Auktionen schaffen.
Nun eine kleine Terminologie. Eine Auktion findet statt, wenn bestimmte Artikel verkauft werden - Lose und Käufer (Bieter) Gebote abgeben. Der Eigentümer des Loses ist der Käufer, der das höchste Gebot abgegeben hat. Eine zeitgesteuerte Auktion ist, wenn jedes Los eine vorgegebene Schließzeit hat. Käufer platzieren Wetten, irgendwann ist das Los geschlossen. Ähnlich wie bei ebay.
Die zeitgesteuerte Plattform wurde auf klassische Weise unter Verwendung von CRUD erstellt. Die Lose wurden durch einen separaten Antrag geschlossen, der nach einem Zeitplan begann. All dies funktionierte nicht sehr zuverlässig: Einige Wetten gingen verloren, andere wurden wie im Auftrag des falschen Käufers abgeschlossen, Lose wurden nicht mehrmals geschlossen oder geschlossen.
Die Live-Auktion bietet die Möglichkeit, über das Internet remote an einer echten Offline-Auktion teilzunehmen. Es gibt einen Raum (in unserer internen Terminologie - "Raum"), der den Gastgeber der Auktion mit einem Hammer und dem Publikum enthält, und direkt neben dem Laptop sitzt der sogenannte Angestellte, der durch Drücken der Tasten in seiner Benutzeroberfläche den Verlauf der Auktion an das Internet und die Verbundenen sendet Zum Zeitpunkt der Auktion sehen Käufer Gebote, die offline abgegeben werden, und können ihre Gebote abgeben.
Beide Plattformen arbeiten im Prinzip in Echtzeit. Wenn sich jedoch alle Käufer zeitgesteuert in einer gleichen Position befinden, ist es im Live-Modus äußerst wichtig, dass Online-Käufer erfolgreich mit denen im Raum konkurrieren können. Das heißt, das System muss sehr schnell und zuverlässig sein. Die traurige Erfahrung der zeitgesteuerten Plattform hat uns ohne Zweifel gezeigt, dass das klassische CRUD nicht für uns geeignet war.
Wir hatten keine eigenen Erfahrungen mit CQRS & ES, deshalb haben wir uns mit Kollegen beraten (wir haben ein großes Unternehmen), ihnen unsere Geschäftsrealitäten vorgestellt und sind gemeinsam zu dem Schluss gekommen, dass CQRS & ES zu uns passen sollte.
Was sind die Besonderheiten von Online-Auktionen:
- — . , « », , . — , 5 . .
- , , .
- — - , , — .
- , .
- Die Lösung muss skalierbar sein - es können mehrere Auktionen gleichzeitig durchgeführt werden.
Ein kurzer Überblick über den CQRS & ES-Ansatz
Ich werde nicht auf die Betrachtung des CQRS & ES-Ansatzes eingehen, es gibt Materialien dazu im Internet und insbesondere zu Habré (zum Beispiel hier: Einführung in CQRS + Event Sourcing ). Ich werde Sie jedoch kurz an die wichtigsten Punkte erinnern:
- Das Wichtigste bei der Ereignisbeschaffung: Das System speichert keine Daten, sondern den Verlauf ihrer Änderung, dh Ereignisse. Der aktuelle Zustand des Systems wird durch sequentielle Anwendung von Ereignissen erhalten.
- Das Domänenmodell ist in Entitäten unterteilt, die als Aggregate bezeichnet werden. Das Gerät hat eine Version. Ereignisse werden auf Aggregate angewendet. Durch Anwenden eines Ereignisses auf ein Aggregat wird dessen Version erhöht.
- write-. , .
- . . , , . «» . .
- , , - ( N- ) . «» . , .
- - , , , , write-.
- write-, read-, , . read- . Read- .
- , — Command Query Responsibility Segregation (CQRS): , , write-; , , read-.

. .
Um Zeit zu sparen und weil es an spezifischer Erfahrung mangelt, haben wir beschlossen, ein Framework für CQRS & ES zu verwenden.
Im Allgemeinen ist unser Technologie-Stack Microsoft, d. H. .NET und C #. Datenbank - Microsoft SQL Server. Alles wird in Azure gehostet. Auf diesem Stapel wurde eine zeitgesteuerte Plattform erstellt. Es war logisch, eine Live-Plattform darauf zu erstellen.
Zu dieser Zeit war Chinchilla , wie ich mich jetzt erinnere, fast die einzige Option, die für uns hinsichtlich des technologischen Stacks geeignet war. Also haben wir sie genommen.
Warum brauchen wir überhaupt ein CQRS & ES-Framework? Er kann "out of the box" Probleme lösen und Aspekte der Implementierung unterstützen wie:
- Aggregierte Entitäten, Befehle, Ereignisse, aggregierte Versionierung, Rehydration, Snapshot-Mechanismus.
- Schnittstellen für die Arbeit mit verschiedenen DBMS. Speichern / Laden von Ereignissen und Snapshots von Aggregaten in / aus der Schreibbasis (Ereignisspeicher).
- Schnittstellen für die Arbeit mit Warteschlangen - Senden von Befehlen und Ereignissen an die entsprechenden Warteschlangen, Lesen von Befehlen und Ereignissen aus der Warteschlange.
- Schnittstelle für die Arbeit mit Websockets.
Unter Berücksichtigung der Verwendung von Chinchilla haben wir unseren Stapel erweitert:
- Der Azure Service Bus als Befehls- und Ereignisbus wird von Chinchilla sofort unterstützt.
- Schreib- und Lesedatenbanken sind Microsoft SQL Server, dh beide sind SQL-Datenbanken. Ich werde nicht sagen, dass dies das Ergebnis einer bewussten Entscheidung ist, sondern aus historischen Gründen.
Ja, das Frontend ist in Angular erstellt.
Wie ich bereits sagte, besteht eine der Anforderungen an das System darin, dass Benutzer so schnell wie möglich über die Ergebnisse ihrer Aktionen und die Aktionen anderer Benutzer informiert werden - dies gilt sowohl für die Kunden als auch für den Sachbearbeiter. Daher verwenden wir SignalR und Websockets, um Daten im Frontend schnell zu aktualisieren. Chinchilla unterstützt die SignalR-Integration.
Auswahl der Einheiten
Eines der ersten Dinge, die bei der Implementierung des CQRS & ES-Ansatzes zu tun sind, ist die Bestimmung, wie das Domänenmodell in Aggregate unterteilt wird.
In unserem Fall besteht das Domänenmodell aus mehreren Hauptentitäten, etwa der folgenden:
public class Auction
{
public AuctionState State { get; private set; }
public Guid? CurrentLotId { get; private set; }
public List<Guid> Lots { get; }
}
public class Lot
{
public Guid? AuctionId { get; private set; }
public LotState State { get; private set; }
public decimal NextBid { get; private set; }
public Stack<Bid> Bids { get; }
}
public class Bid
{
public decimal Amount { get; set; }
public Guid? BidderId { get; set; }
}
Wir haben zwei Aggregate: Auktion und Los (mit Geboten). Im Allgemeinen ist es logisch, aber eines haben wir nicht berücksichtigt: Bei einer solchen Aufteilung wurde der Status des Systems auf zwei Einheiten verteilt, und in einigen Fällen müssen wir zur Aufrechterhaltung der Konsistenz Änderungen an beiden Einheiten vornehmen und nicht an einer. Beispielsweise kann eine Auktion angehalten werden. Wenn die Auktion unterbrochen wird, können Sie nicht auf das Los bieten. Es wäre möglich, das Los selbst anzuhalten, aber eine angehaltene Auktion kann keine anderen Befehle als "Pause aufheben" verarbeiten.
Alternativ könnte nur ein Aggregat erstellt werden, Auktion, mit allen Losen und Geboten im Inneren. Ein solches Objekt wird jedoch ziemlich schwierig sein, da es bis zu mehreren tausend Lose in der Auktion geben kann und es mehrere Dutzend Gebote für ein Los geben kann. Während der Laufzeit der Auktion wird ein solches Aggregat viele Versionen haben, und die Rehydratisierung eines solchen Aggregats (sequentielle Anwendung aller Ereignisse auf das Aggregat), wenn keine Schnappschüsse von Aggregaten erstellt werden, wird ziemlich lange dauern. Was für unsere Situation nicht akzeptabel ist. Wenn Sie Schnappschüsse verwenden (wir verwenden sie), wiegen die Schnappschüsse selbst viel.
Um sicherzustellen, dass Änderungen bei der Verarbeitung einer einzelnen Benutzeraktion auf zwei Aggregate angewendet werden, müssen Sie entweder beide Aggregate innerhalb desselben Befehls mithilfe einer Transaktion ändern oder zwei Befehle innerhalb derselben Transaktion ausführen. Beide sind im Großen und Ganzen eine Verletzung der Architektur.
Solche Umstände müssen bei der Aufteilung des Domänenmodells in Aggregate berücksichtigt werden.
In dieser Phase der Projektentwicklung leben wir mit zwei Einheiten, Auction und Lot, und brechen die Architektur, indem wir beide Einheiten innerhalb einiger Befehle ändern.
Anwenden eines Befehls auf eine bestimmte Version eines Aggregats
Wenn mehrere Käufer gleichzeitig ein Gebot für dasselbe Los abgeben, dh einen Befehl zum Bieten an das System senden, ist nur eines der Gebote erfolgreich. Vieles ist ein Aggregat, es hat eine Version. Während der Befehlsverarbeitung werden Ereignisse generiert, von denen jedes die Version des Aggregats erhöht. Es gibt zwei Möglichkeiten:
- Senden Sie einen Befehl, der angibt, auf welche Version des Aggregats wir es anwenden möchten. Dann kann der Befehlshandler die Version im Befehl sofort mit der aktuellen Version des Geräts vergleichen und nicht fortfahren, wenn sie nicht übereinstimmt.
- Geben Sie im Befehl nicht die Version des Geräts an. Dann wird das Aggregat mit einer Version rehydratisiert, die entsprechende Geschäftslogik wird ausgeführt, Ereignisse werden generiert. Und nur wenn sie gespeichert sind, kann eine Ausführung angezeigt werden, dass eine solche Version der Einheit bereits vorhanden ist. Weil es jemand anderes früher getan hat.
Wir verwenden die zweite Option. Dies gibt den Teams eine bessere Chance, hingerichtet zu werden. Da in dem Teil der Anwendung, der Befehle sendet (in unserem Fall ist dies das Frontend), die aktuelle Version des Aggregats mit einiger Wahrscheinlichkeit hinter der tatsächlichen Version im Backend zurückbleibt. Besonders unter Bedingungen, unter denen viele Befehle gesendet werden und sich die Version des Geräts häufig ändert.
Fehler beim Ausführen eines Befehls mithilfe einer Warteschlange
In unserer Implementierung, die stark von Chinchilla gesteuert wird, liest der Befehlshandler Befehle aus einer Warteschlange (Microsoft Azure Service Bus). Wir unterscheiden klar zwischen Situationen, in denen ein Team aus technischen Gründen (Zeitüberschreitungen, Fehler beim Herstellen einer Verbindung zu einer Warteschlange / Basis) ausfällt und aus geschäftlichen Gründen (ein Versuch, ein Gebot für einen Großteil des bereits akzeptierten Betrags abzugeben usw.). Im ersten Fall wird der Versuch, den Befehl auszuführen, wiederholt, bis die in den Warteschlangeneinstellungen angegebene Anzahl von Wiederholungen erreicht ist. Anschließend wird der Befehl an die Warteschlange für nicht zustellbare Nachrichten gesendet (ein separates Thema für unverarbeitete Nachrichten im Azure Service Bus). Im Falle einer Geschäftsausführung wird das Team sofort an die Dead Letter Queue gesendet.
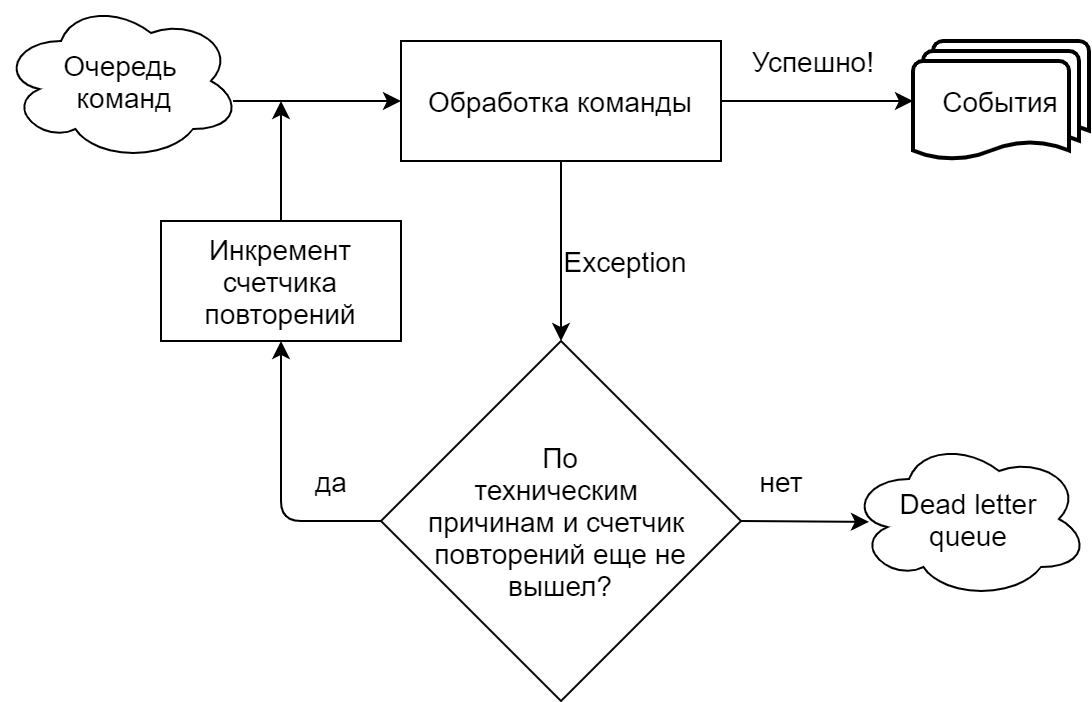
Fehler beim Behandeln von Ereignissen mithilfe einer Warteschlange
Ereignisse, die als Ergebnis der Befehlsausführung generiert werden, können je nach Implementierung auch an die Warteschlange gesendet und von Ereignishandlern aus der Warteschlange entnommen werden. Und bei der Behandlung von Ereignissen treten auch Fehler auf.
Im Gegensatz zur Situation mit einem nicht ausgeführten Befehl ist hier jedoch alles schlimmer - es kann vorkommen, dass der Befehl ausgeführt und die Ereignisse in die Schreibbasis geschrieben wurden, ihre Verarbeitung durch die Handler jedoch fehlschlug. Wenn einer dieser Handler die Lesebasis aktualisiert, wird die Lesebasis nicht aktualisiert. Das heißt, es wird sich in einem inkonsistenten Zustand befinden. Aufgrund des Mechanismus, die Verarbeitung des Leseereignisses erneut zu versuchen, wird die Datenbank fast immer irgendwann aktualisiert, aber die Wahrscheinlichkeit, dass sie nach allen Versuchen weiterhin fehlerhaft bleibt, bleibt bestehen.
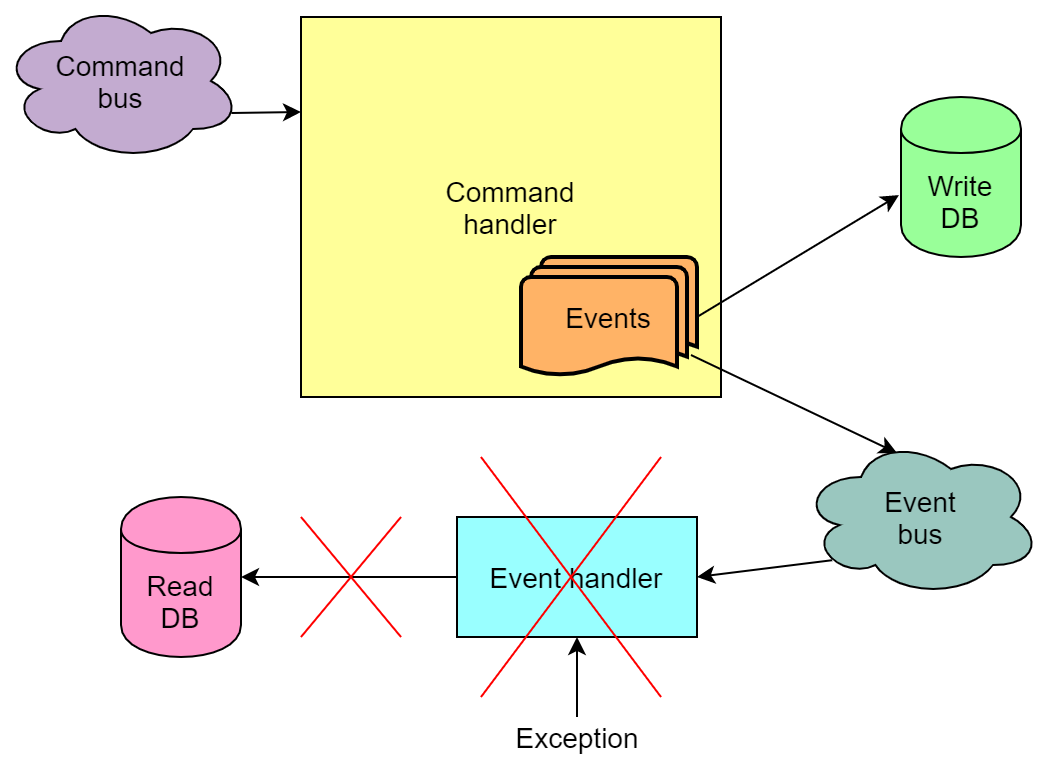
Wir sind zu Hause auf dieses Problem gestoßen. Der Grund war jedoch größtenteils die Tatsache, dass wir eine gewisse Geschäftslogik in der Ereignisverarbeitung hatten, die bei einem intensiven Strom von Wetten von Zeit zu Zeit eine gute Chance hat, zu scheitern. Leider haben wir dies zu spät erkannt, es war nicht möglich, die Geschäftsimplementierung schnell und einfach zu wiederholen.
Aus diesem Grund haben wir als vorübergehende Maßnahme die Verwendung des Azure Service Bus zum Übertragen von Ereignissen vom Schreibteil der Anwendung zum Leseteil eingestellt. Stattdessen wird der sogenannte In-Memory-Bus verwendet, mit dem Sie den Befehl und die Ereignisse in einer Transaktion verarbeiten und im Fehlerfall das Ganze zurücksetzen können.
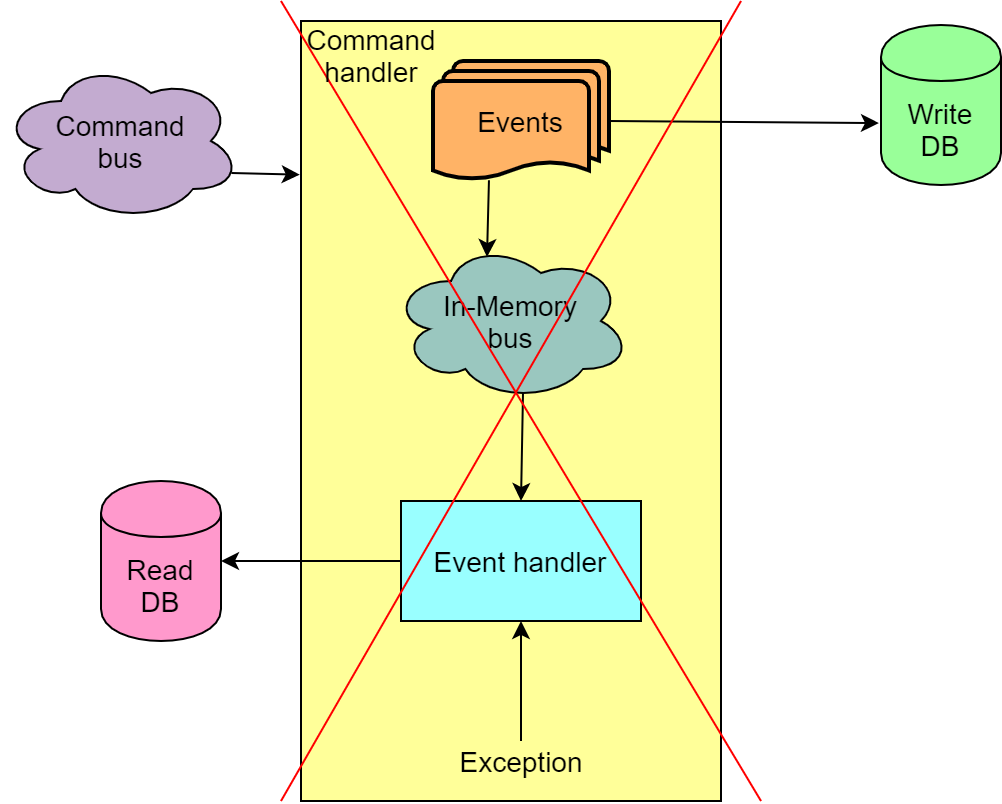
Eine solche Lösung trägt nicht zur Skalierbarkeit bei, aber andererseits schließen wir Situationen aus, in denen unsere Lesebasis kaputt geht, was wiederum Frontends kaputt macht und es unmöglich wird, die Auktion fortzusetzen, ohne die Lesebasis durch Wiedergabe aller Ereignisse neu zu erstellen.
Senden eines Befehls als Antwort auf ein Ereignis
Dies ist im Prinzip angemessen, jedoch nur in dem Fall, in dem die Nichtausführung dieses zweiten Befehls den Status des Systems nicht beeinträchtigt.
Behandlung mehrerer Ereignisse eines Befehls
Im Allgemeinen führt die Ausführung eines Befehls zu mehreren Ereignissen. Es kommt vor, dass wir für jedes der Ereignisse einige Änderungen in der gelesenen Datenbank vornehmen müssen. Es kommt auch vor, dass die Reihenfolge der Ereignisse ebenfalls wichtig ist und in der falschen Reihenfolge die Ereignisverarbeitung nicht ordnungsgemäß funktioniert. All dies bedeutet, dass wir nicht aus der Warteschlange lesen und die Ereignisse eines Befehls unabhängig voneinander verarbeiten können, z. B. mit verschiedenen Codeinstanzen, die Nachrichten aus der Warteschlange lesen. Außerdem benötigen wir eine Garantie dafür, dass die Ereignisse aus der Warteschlange in derselben Reihenfolge gelesen werden, in der sie dorthin gesendet wurden. Oder wir müssen darauf vorbereitet sein, dass nicht alle Befehlsereignisse beim ersten Versuch erfolgreich verarbeitet werden.
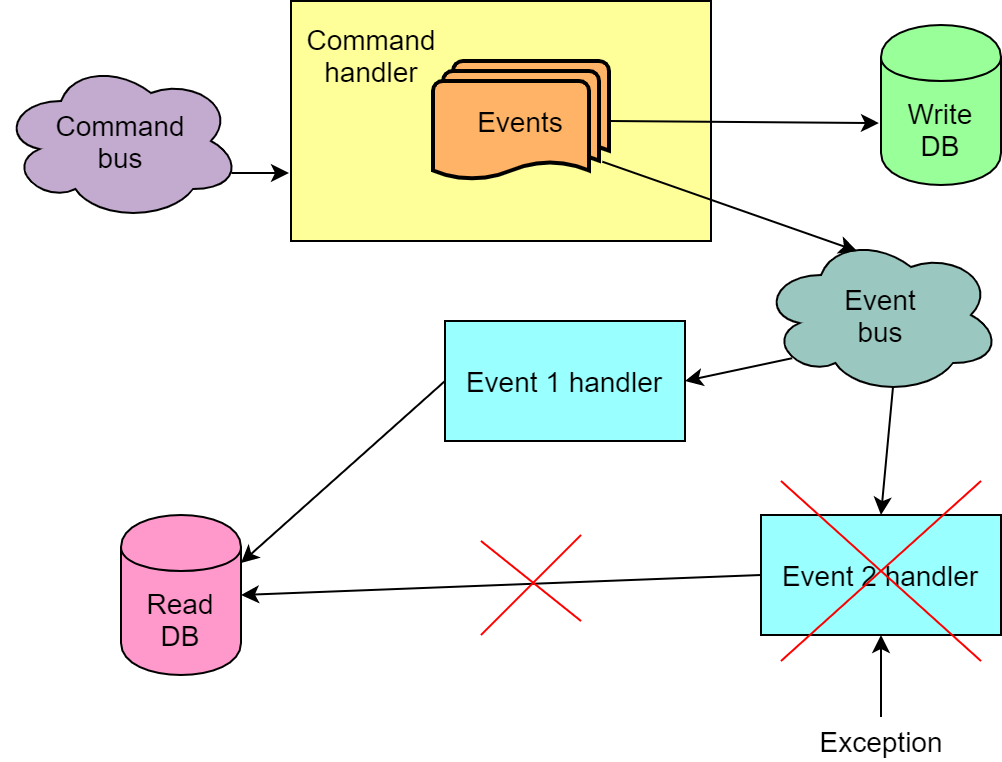
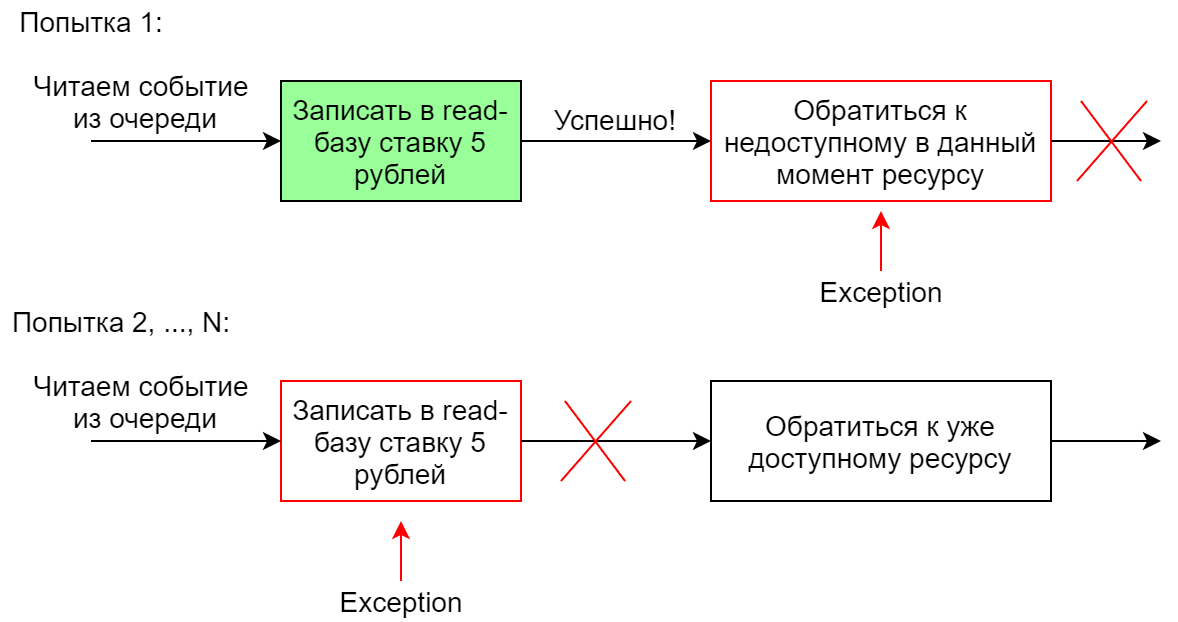
Behandeln eines Ereignisses mit mehreren Handlern
Wenn das System als Reaktion auf ein Ereignis mehrere verschiedene Aktionen ausführen muss, werden normalerweise mehrere Handler für dieses Ereignis erstellt. Sie können parallel oder nacheinander arbeiten. Wenn bei einem sequentiellen Start einer der Handler ausfällt, wird die gesamte Sequenz neu gestartet (dies ist in Chinchilla der Fall). Bei einer solchen Implementierung ist es wichtig, dass die Handler idempotent sind, damit der zweite Lauf eines einmal erfolgreich ausgeführten Handlers nicht fehlschlägt. Wenn der zweite Handler von der Kette fällt, funktioniert die Kette definitiv nicht vollständig, da der erste Handler beim zweiten (und nachfolgenden) Versuch fällt.
Beispielsweise fügt ein Ereignishandler in der Lesebasis ein Gebot für eine Menge von 5 Rubel hinzu. Der erste Versuch, dies zu tun, ist erfolgreich, und der zweite Versuch erlaubt nicht die Ausführung von Einschränkungen in der Datenbank.
Schlussfolgerungen / Schlussfolgerung
Jetzt befindet sich unser Projekt in einem Stadium, in dem wir, wie es uns scheint, bereits auf die meisten vorhandenen Rechen getreten sind, die für unsere Geschäftsspezifikationen relevant sind. Generell halten wir unsere Erfahrung für recht erfolgreich, CQRS & ES ist für unser Fachgebiet gut geeignet. Die weitere Entwicklung des Projekts zeigt sich in der Aufgabe von Chinchilla zugunsten eines anderen Rahmens, der mehr Flexibilität bietet. Es ist jedoch auch möglich, die Verwendung des Frameworks überhaupt zu verweigern. Es ist auch wahrscheinlich, dass sich die Richtung ändert, in der ein Gleichgewicht zwischen Zuverlässigkeit einerseits und Geschwindigkeit und Skalierbarkeit der Lösung andererseits gefunden wird.
Auch hier sind noch einige Fragen zur Geschäftskomponente offen - beispielsweise die Aufteilung des Domain-Modells in Aggregate.
Ich möchte hoffen, dass unsere Erfahrung für jemanden nützlich ist, Zeit spart und einen Rechen vermeidet. Vielen Dank für Ihre Aufmerksamkeit.