Ich glaube, dass fast jedes Projekt, das Ruby on Rails und Postgres als Hauptwaffe im Backend verwendet, in einem permanenten Kampf zwischen der Entwicklungsgeschwindigkeit, der Lesbarkeit / Wartbarkeit des Codes und der Geschwindigkeit des Projekts in der Produktion steht. Ich werde Ihnen von meinen Erfahrungen mit dem Balancieren zwischen diesen drei Walen in einem Fall erzählen, in dem Lesbarkeit und Arbeitsgeschwindigkeit am Eingang gelitten haben, und am Ende stellte sich heraus, dass das getan wurde, was mehrere talentierte Ingenieure vor mir erfolglos versucht hatten.

Die ganze Geschichte wird mehrere Teile umfassen. Dies ist der erste, in dem ich darüber spreche, was PMDSC zur Optimierung von SQL-Abfragen ist, nützliche Tools zum Messen der Abfrageleistung in Postgres austauscht und mich an einen nützlichen alten Spickzettel erinnere, der immer noch relevant ist.
Jetzt, nach einiger Zeit, "im Nachhinein" verstehe ich, dass ich am Eingang zu diesem Fall überhaupt nicht erwartet hatte, dass ich Erfolg haben würde. Daher ist dieser Beitrag eher für mutige und nicht die erfahrensten Entwickler nützlich als für Super-Senioren, die Rails mit Bare SQL gesehen haben.
Eingabedaten
Wir bei Appbooster fördern mobile Apps. Um Hypothesen einfach aufstellen und testen zu können, entwickeln wir mehrere unserer Anwendungen. Das Backend für die meisten von ihnen ist die Rails-API und Postgresql.
Der Held dieser Publikation befindet sich seit Ende 2013 in der Entwicklung - damals wurden gerade die Rails 4.1.0.beta1 veröffentlicht. Seitdem hat sich das Projekt zu einer vollständig geladenen Webanwendung entwickelt, die auf mehreren Servern in Amazon EC2 mit einer separaten Datenbankinstanz in Amazon RDS (db.t3.xlarge mit 4 vCPUs und 16 GB RAM) ausgeführt wird. Die Spitzenlasten erreichen 25.000 U / min, die durchschnittliche Tageslast 8-10.000 U / min.
Diese Geschichte begann mit einer Datenbankinstanz oder vielmehr mit ihrem Guthaben.
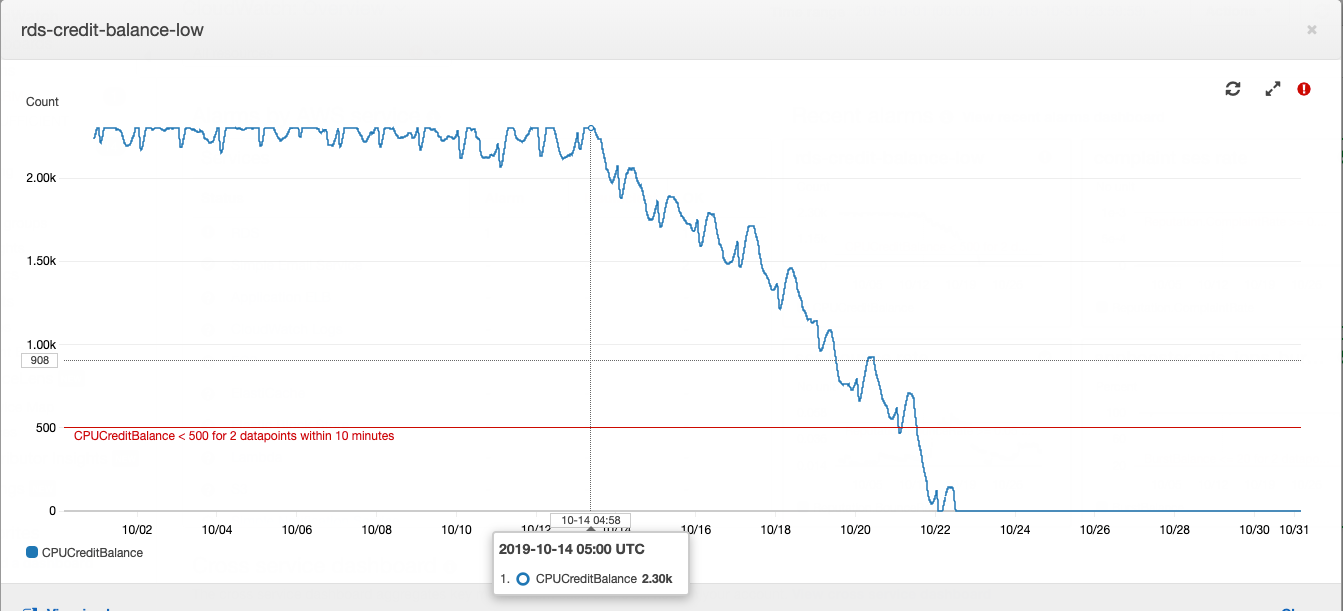
Funktionsweise einer Postgres-Instanz vom Typ "t" in Amazon RDS: Wenn Ihre Datenbank mit einem durchschnittlichen CPU-Verbrauch unter einem bestimmten Wert ausgeführt wird, sammeln Sie Guthaben auf Ihrem Konto, das die Instanz während der Hochlaststunden für den CPU-Verbrauch ausgeben kann. Dies erspart Ihnen Überzahlung für die Serverkapazität und um mit hoher Last fertig zu werden. Weitere Informationen darüber, was und wie viel sie mit AWS bezahlen, finden Sie im Artikel unseres CTO .
Der Kreditsaldo war zu einem bestimmten Zeitpunkt erschöpft. Diesem wurde für einige Zeit keine große Bedeutung beigemessen, da der Restbetrag der Kredite mit Geld aufgefüllt werden kann - es kostete uns etwa 20 USD pro Monat, was für die Gesamtkosten für die Anmietung von Rechenleistung nicht sehr auffällig ist. In der Produktentwicklung ist es üblich, vor allem auf die aus den Geschäftsanforderungen formulierten Aufgaben zu achten. Der erhöhte CPU-Verbrauch des Datenbankservers passt in die technische Verschuldung und wird durch die geringen Kosten für den Kauf eines Guthabens ausgeglichen.
Eines schönen Tages schrieb ich in der täglichen Zusammenfassung, dass ich es sehr leid war, die „Feuer“ zu löschen, die regelmäßig in verschiedenen Teilen des Projekts auftraten. Wenn dies so weitergeht, wird der ausgebrannte Entwickler Zeit für Geschäftsaufgaben verwenden. Am selben Tag ging ich zum Hauptprojektleiter, erklärte die Ausrichtung und bat um Zeit, um die Ursachen für regelmäßige Brände und Reparaturen zu untersuchen. Nachdem ich die Genehmigung erhalten hatte, begann ich, Daten von verschiedenen Überwachungssystemen zu sammeln.
Wir verwenden Newrelic, um die Gesamtantwortzeit pro Tag zu verfolgen. Das Bild sah folgendermaßen aus:
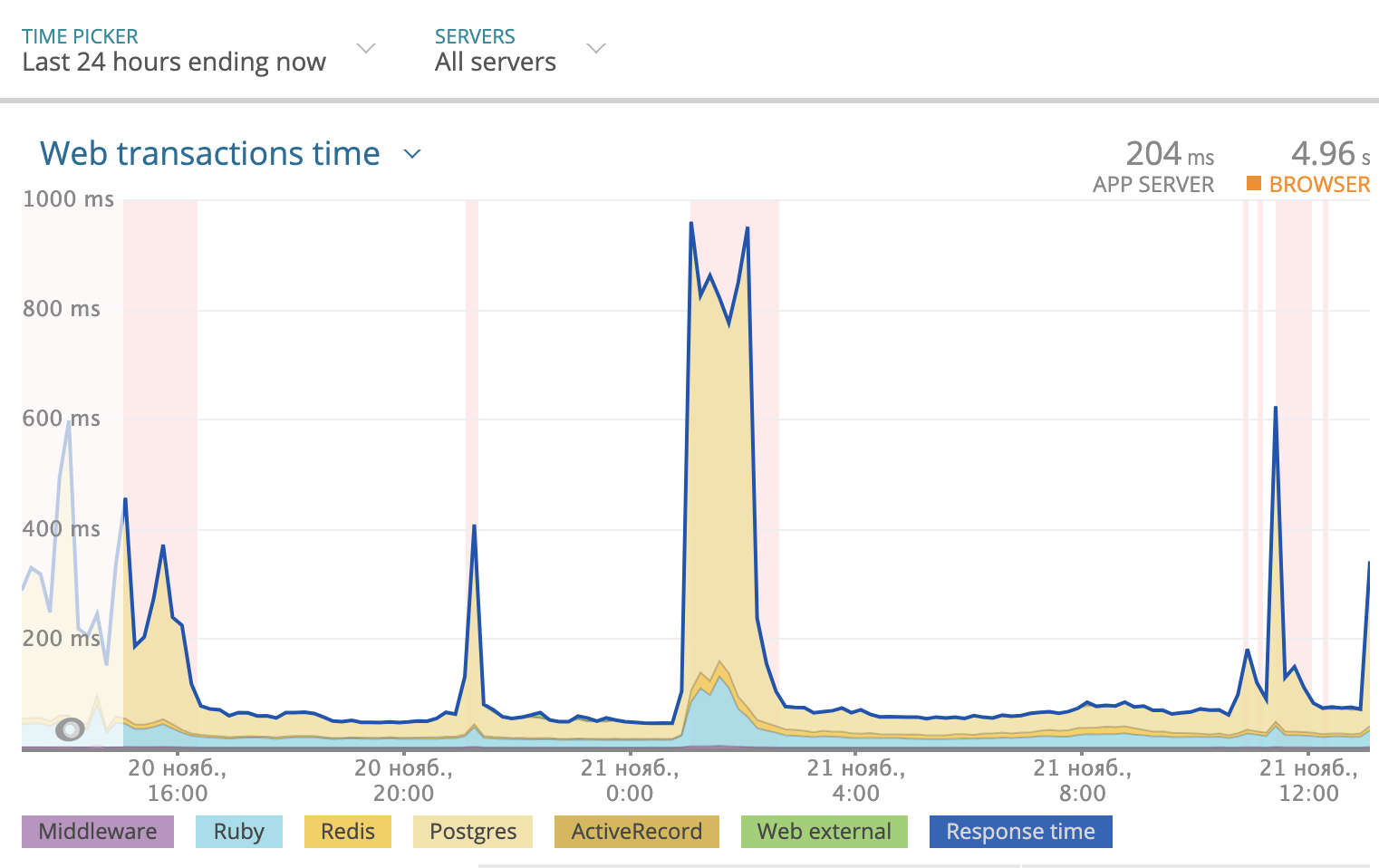
Ein Teil der Reaktionszeit, die Postgres benötigt, wird in der Grafik gelb hervorgehoben. Wie Sie sehen können, erreichte die Antwortzeit manchmal 1000 ms, und meistens war es die Datenbank, die über die Antwort nachdachte. Sie müssen sich also ansehen, was mit SQL-Abfragen passiert.
PMDSC ist eine einfache und unkomplizierte Methode für jeden langweiligen SQL-Optimierungsjob
Spiel es!
Messe Es!
Zeichne es!
Angenommen, es!
Prüfen Sie!
Spiel es!
Vielleicht der wichtigste Teil der gesamten Praxis. Wenn jemand den Satz "Optimieren von SQL-Abfragen" sagt, verursacht dies bei der überwiegenden Mehrheit der Menschen eher ein Gähnen und Langeweile. Wenn Sie "Detektivermittlung und Suche nach gefährlichen Bösewichten" sagen, werden Sie mehr in die richtige Stimmung versetzt. Daher ist es wichtig, ins Spiel zu kommen. Ich habe es genossen, Detektiv zu spielen. Ich stellte mir vor, dass Probleme mit der Datenbank entweder gefährliche Kriminelle oder seltene Krankheiten sind. Und er stellte sich vor, Sherlock Holmes, Lieutenant Columbo oder Doctor House zu sein. Wählen Sie einen Helden nach Ihrem Geschmack und gehen Sie!
Messe Es!

Um Anforderungsstatistiken zu analysieren, habe ich PgHero installiert . Dies ist eine sehr bequeme Möglichkeit, Daten aus der Postgres-Erweiterung pg_stat_statements zu lesen. Gehen Sie zu / queries und sehen Sie sich die Statistiken aller Abfragen der letzten 24 Stunden an. Das standardmäßige Sortieren von Abfragen nach der Spalte "Gesamtzeit" - dem Anteil der Gesamtzeit, in der die Datenbank die Abfrage verarbeitet - ist eine wertvolle Quelle für die Suche nach Verdächtigen. Durchschnittliche Zeit - Wie viele durchschnittlich wird die Anforderung ausgeführt? Anrufe - wie viele Anfragen wurden während der ausgewählten Zeit gestellt. PgHero betrachtet Anforderungen als langsam, wenn sie mehr als 100 Mal pro Tag ausgeführt wurden und durchschnittlich mehr als 20 Millisekunden dauerten. Liste der langsamen Abfragen auf der ersten Seite, unmittelbar nach der Liste der doppelten Indizes.

Wir nehmen den ersten in der Liste und schauen uns die Details der Abfrage an. Sie können sofort sehen, wie sie die Analyse erklärt. Wenn die Planungszeit viel kürzer als die Ausführungszeit ist, stimmt etwas mit dieser Anfrage nicht und wir konzentrieren unsere Aufmerksamkeit auf diesen Verdächtigen.
PgHero hat eine eigene Visualisierungsmethode, aber ich mochte EXPLAIN.depesz.com mehr und kopierte dort Daten aus EXPLAIN- Analyse.
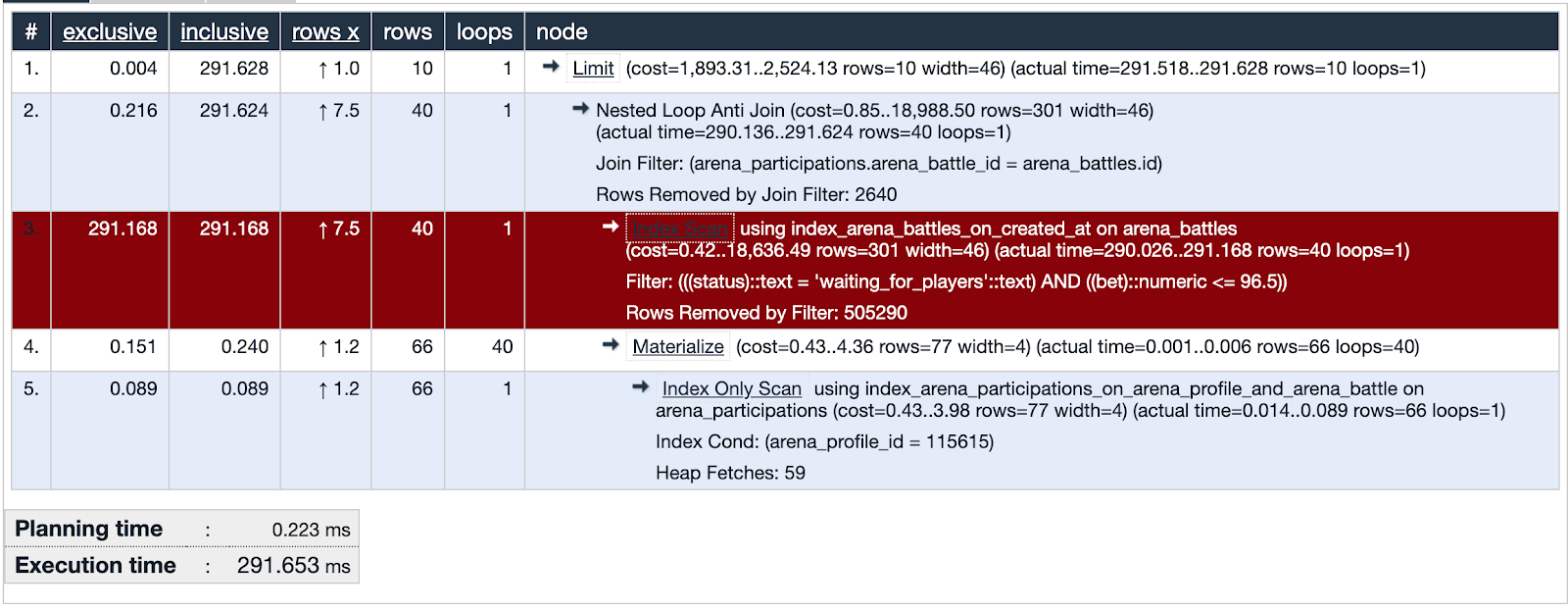
Eine der verdächtigen Abfragen verwendet den Index-Scan. Die Visualisierung zeigt, dass dieser Index nicht effektiv ist und eine Schwachstelle darstellt - rot hervorgehoben. Fein! Wir haben die Spuren des Verdächtigen untersucht und wichtige Beweise gefunden! Gerechtigkeit ist unvermeidlich!
Zeichne es!
Zeichnen wir viele Daten, die im problematischen Teil der Abfrage verwendet werden. Es ist hilfreich zu vergleichen, mit welchen Daten der Index abdeckt.
Ein bisschen Kontext. Wir haben eine der Möglichkeiten getestet, um das Publikum in der Anwendung zu halten - so etwas wie eine Lotterie, bei der Sie eine lokale Währung gewinnen können. Sie setzen eine Wette, raten eine Zahl von 0 bis 100 und nehmen den gesamten Pot, wenn Ihre Zahl derjenigen am nächsten kommt, die der Zufallszahlengenerator erhalten hat. Wir nannten es "Arena" und nannten die Rallyes "Battles".

Die Datenbank zum Zeitpunkt der Untersuchung enthält etwa fünfhunderttausend Aufzeichnungen von Schlachten. Im problematischen Teil der Anfrage suchen wir nach Schlachten, bei denen die Rate das Gleichgewicht des Benutzers nicht überschreitet und der Status des Kampfes auf die Spieler wartet. Wir sehen, dass der Schnittpunkt von Mengen (orange hervorgehoben) eine sehr kleine Anzahl von Datensätzen ist.
Der im verdächtigen Teil der Anfrage verwendete Index deckt alle erstellten Schlachten im Feld created_at ab. Die Anforderung durchläuft 505330 Datensätze, aus denen sie 40 auswählt, und 505290 eliminiert. Es sieht sehr verschwenderisch aus.
Angenommen, es!
Wir stellen eine Hypothese auf. Was hilft der Datenbank, vierzig von fünfhunderttausend Datensätzen zu finden? Versuchen wir, einen Index zu erstellen, der das Ratenfeld abdeckt, nur für Schlachten mit dem Status "Warten auf Spieler" - einen Teilindex.
add_index :arena_battles, :bet,
where: "status = 'waiting_for_players'",
name: "index_arena_battles_on_bet_partial_status"
Teilindex - existiert nur für die Datensätze, die der Bedingung entsprechen: Das Statusfeld entspricht "Warten auf Spieler" und indiziert das Ratenfeld - genau das, was sich in der Abfragebedingung befindet. Es ist sehr vorteilhaft, diesen speziellen Index zu verwenden: Er benötigt nur 40 Kilobyte und deckt nicht die bereits gespielten Schlachten ab, und wir brauchen keine Stichprobe. Zum Vergleich: Der Index_arena_battles_on_created_at-Index, der vom Verdächtigen verwendet wurde, benötigt ungefähr 40 MB, und die Tabelle mit Schlachten ist ungefähr 70 MB groß. Dieser Index kann sicher entfernt werden, wenn andere Abfragen ihn nicht verwenden.
Prüfen Sie!
Wir führen die Migration mit dem neuen Index in die Produktion ein und beobachten, wie sich die Reaktion des Endpunkts auf Schlachten geändert hat.
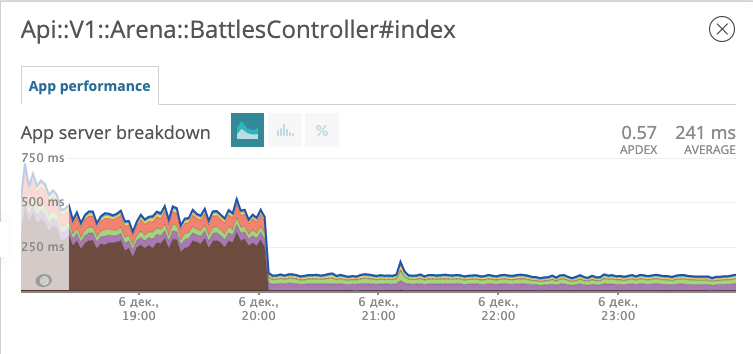
Die Grafik zeigt, wann wir die Migration eingeführt haben. Am Abend des 6. Dezember verringerte sich die Reaktionszeit um das Zehnfache von ~ 500 ms auf ~ 50 ms. Der Verdächtige vor Gericht erhielt den Status eines Gefangenen und befindet sich nun im Gefängnis. Fein!
Gefängnisausbruch
Einige Tage später stellten wir fest, dass wir früh glücklich waren. Es sieht so aus, als hätte der Gefangene Komplizen gefunden, einen Fluchtplan entwickelt und umgesetzt.
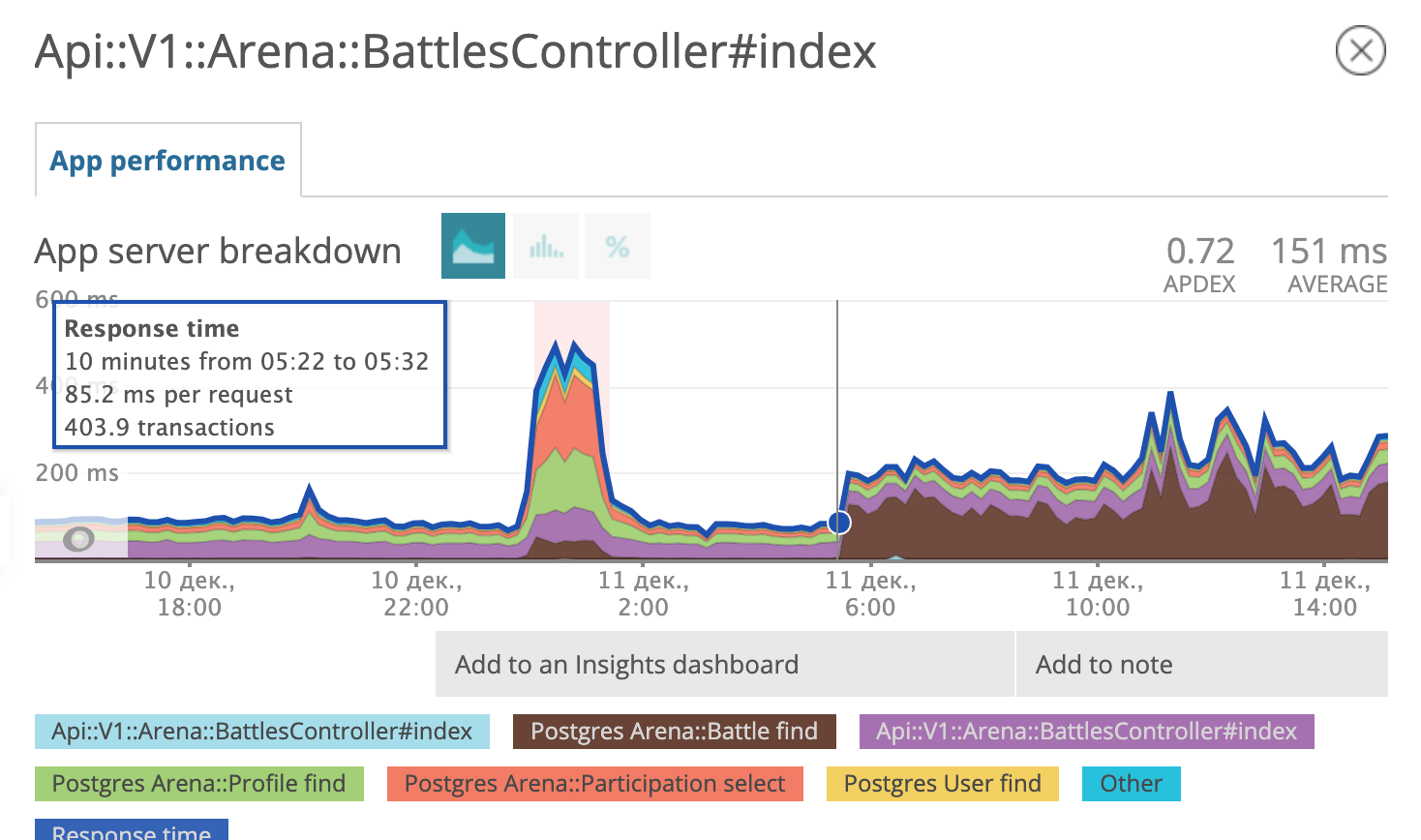
Am Morgen des 11. Dezember entschied der Postgres-Abfrageplaner, dass die Verwendung eines frisch analysierten Index für ihn nicht mehr rentabel war, und begann erneut, den alten zu verwenden.
Wir sind wieder in der Phase "Angenommen, es ist soweit!" Zusammenstellung einer Differentialdiagnose im Sinne von Dr. House:
- Möglicherweise müssen die Postgres-Einstellungen optimiert werden.
- Aktualisieren Sie Postgres möglicherweise geringfügig auf eine neuere Version (9.6.11 -> 9.6.15).
- und vielleicht noch einmal sorgfältig untersuchen, welche SQL-Abfrage Rails bildet?
Wir haben alle drei Hypothesen getestet. Letzteres führte uns auf die Spur eines Komplizen.
SELECT "arena_battles".*
FROM "arena_battles"
WHERE "arena_battles"."status" = 'waiting_for_players'
AND (arena_battles.bet <= 98.13)
AND (NOT EXISTS (
SELECT 1 FROM arena_participations
WHERE arena_battle_id = arena_battles.id
AND (arena_profile_id = 46809)
))
ORDER BY "arena_battles"."created_at" ASC
LIMIT 10 OFFSET 0Lassen Sie uns gemeinsam durch diese SQL gehen. Wir wählen alle Schlachtfelder aus dem Kampftisch aus, deren Status gleich "Warten auf Spieler" ist und dessen Rate kleiner oder gleich einer bestimmten Anzahl ist. Bisher ist alles klar. Der nächste Begriff im Zustand sieht gruselig aus.
NOT EXISTS (
SELECT 1 FROM arena_participations
WHERE arena_battle_id = arena_battles.id
AND (arena_profile_id = 46809)
)Wir suchen nach einem nicht vorhandenen Unterabfrageergebnis. Holen Sie sich das erste Feld aus der Schlachtteilnahmetabelle, in der die Kampf-ID übereinstimmt und das Profil des Teilnehmers unserem Spieler gehört. Ich werde versuchen, die in der Unterabfrage beschriebene Menge zu zeichnen.
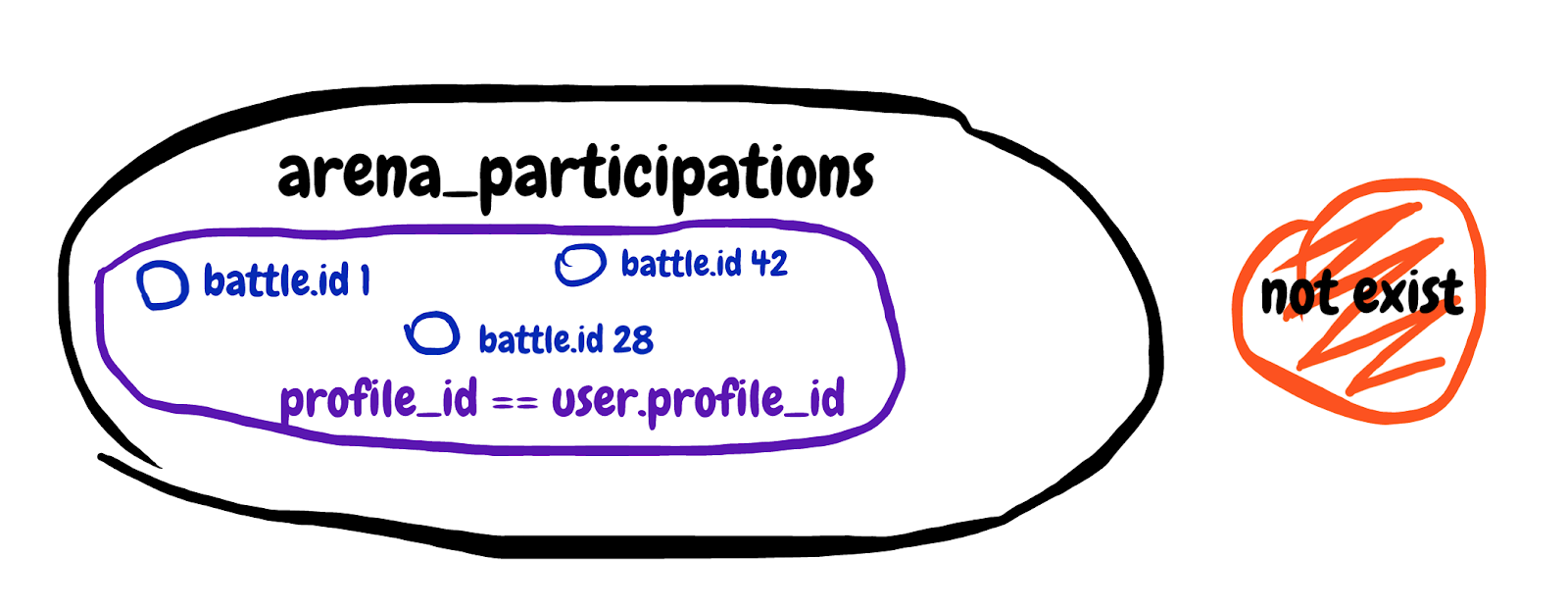
Es ist schwer zu verstehen, aber am Ende haben wir mit dieser Unterabfrage versucht, die Schlachten auszuschließen, an denen der Spieler bereits teilnimmt. Wir sehen uns die allgemeine Erläuterung der Abfrage an und sehen Planungszeit: 0,180 ms, Ausführungszeit: 12,119 ms. Wir haben einen Komplizen gefunden!
Es ist Zeit für meinen Lieblings-Spickzettel, der seit 2008 im Internet verfügbar ist. Hier ist es:

Ja! Sobald eine Abfrage auf etwas stößt, das eine bestimmte Anzahl von Datensätzen basierend auf Daten aus einer anderen Tabelle ausschließen sollte, sollte dieses Mem mit Bart und Locken im Speicher erscheinen.
In der Tat ist dies, was wir brauchen:

Speichern Sie dieses Bild für sich selbst oder drucken Sie es noch besser aus und hängen Sie es an mehreren Stellen im Büro auf.
Wir schreiben die Unterabfrage in LEFT JOIN um, wo B.key NULL ist. Wir erhalten:
SELECT "arena_battles".*
FROM "arena_battles"
LEFT JOIN arena_participations
ON arena_participations.arena_battle_id = arena_battles.id
AND (arena_participations.arena_profile_id = 46809)
WHERE "arena_battles"."status" = 'waiting_for_players'
AND (arena_battles.bet <= 98.13)
AND (arena_participations.id IS NULL)
ORDER BY "arena_battles"."created_at" ASC
LIMIT 10 OFFSET 0Die korrigierte Abfrage wird über zwei Tabellen gleichzeitig ausgeführt. Wir haben eine Tabelle mit Aufzeichnungen über die Teilnahme des Benutzers an den Schlachten auf der linken Seite hinzugefügt und die Bedingung hinzugefügt, dass die Teilnahmekennung nicht vorhanden ist. Lassen Sie uns die EXPLAIN-Analyse der empfangenen Abfrage sehen: Planungszeit: 0,185 ms, Ausführungszeit: 0,337 ms. Fein! Jetzt wird der Abfrageplaner nicht zögern, den Teilindex zu verwenden, sondern die schnellste Option verwenden. Der entkommene Gefangene und sein Komplize wurden in einer Einrichtung des strengen Regimes zu lebenslanger Haft verurteilt. Es wird für sie schwieriger sein zu fliehen.
Die Zusammenfassung ist kurz.
- Verwenden Sie Newrelic oder einen ähnlichen Dienst, um Leads zu finden. Wir haben festgestellt, dass das Problem genau in den Datenbankabfragen liegt.
- Verwenden Sie die PMDSC-Praxis - sie funktioniert und ist auf jeden Fall sehr ansprechend.
- Verwenden Sie PgHero, um Verdächtige zu finden und Hinweise in SQL-Abfragestatistiken zu untersuchen.
- Verwenden Sie EXPLAIN.DEPESZ.com - es ist einfach, EXPLAIN- Analyse-Abfragen dort zu lesen.
- Versuchen Sie, viele Daten zu zeichnen, wenn Sie nicht genau wissen, was die Anforderung tut.
- Denken Sie an den harten Kerl mit den Locken am ganzen Kopf, wenn Sie eine Unterabfrage sehen, die nach etwas sucht, das sich nicht in einem anderen Tisch befindet.
- Spielen Sie Detektiv, Sie könnten sogar ein Abzeichen bekommen.