 Der Dialog 2020 , eine internationale wissenschaftliche Konferenz über Computerlinguistik und intelligente Technologie, wurde kürzlich beendet . Zum ersten Mal wurde die MIPT Phystech School für Angewandte Mathematik und Informatik (FPMI) Partner der Konferenz . Traditionell ist eines der Schlüsselereignisse des Dialogs die Dialogbewertung , ein Wettbewerb zwischen den Entwicklern automatischer Systeme für die sprachliche Textanalyse. Wir haben bereits über Habré über die Aufgaben gesprochen, die die Teilnehmer des Wettbewerbs im vergangenen Jahr gelöst haben, beispielsweise über das Generieren von Überschriften und das Auffinden fehlender Wörter im Text. Heute haben wir mit den Gewinnern von zwei Tracks der diesjährigen Dialogevaluation - Vladislav Korzun und Daniil Anastasyev - darüber gesprochen, warum sie beschlossen haben, an Technologiewettbewerben teilzunehmen, welche Probleme und auf welche Weise sie gelöst haben, woran die Jungs interessiert sind, wo sie studiert haben und was sie in Zukunft vorhaben. Willkommen bei der Katze!
Der Dialog 2020 , eine internationale wissenschaftliche Konferenz über Computerlinguistik und intelligente Technologie, wurde kürzlich beendet . Zum ersten Mal wurde die MIPT Phystech School für Angewandte Mathematik und Informatik (FPMI) Partner der Konferenz . Traditionell ist eines der Schlüsselereignisse des Dialogs die Dialogbewertung , ein Wettbewerb zwischen den Entwicklern automatischer Systeme für die sprachliche Textanalyse. Wir haben bereits über Habré über die Aufgaben gesprochen, die die Teilnehmer des Wettbewerbs im vergangenen Jahr gelöst haben, beispielsweise über das Generieren von Überschriften und das Auffinden fehlender Wörter im Text. Heute haben wir mit den Gewinnern von zwei Tracks der diesjährigen Dialogevaluation - Vladislav Korzun und Daniil Anastasyev - darüber gesprochen, warum sie beschlossen haben, an Technologiewettbewerben teilzunehmen, welche Probleme und auf welche Weise sie gelöst haben, woran die Jungs interessiert sind, wo sie studiert haben und was sie in Zukunft vorhaben. Willkommen bei der Katze!
Vladislav Korzun, Gewinner des RuREBus-2020-Tracks zur Dialogbewertung

Was machst du?
Ich bin Entwickler bei der NLP Advanced Research Group bei ABBYY. Wir lösen derzeit eine One-Shot-Lernaufgabe zum Extrahieren von Entitäten. Mit einer kleinen Schulungsprobe (5-10 Dokumente) müssen Sie lernen, wie Sie bestimmte Entitäten aus ähnlichen Dokumenten extrahieren. Zu diesem Zweck werden wir die Ausgaben des NER-Modells verwenden, die auf Standardentitätstypen (Person, Standort, Organisation) trainiert wurden, um dieses Problem zu lösen. Wir planen auch die Verwendung eines speziellen Sprachmodells, das an Dokumenten geschult wurde, die in Bezug auf unsere Aufgabe ähnlich sind.
Welche Aufgaben haben Sie bei Dialogue Evaluation gelöst?
Während des Dialogs nahm ich am RuREBus- Wettbewerb teil, bei dem es darum ging, Entitäten und Beziehungen aus bestimmten Dokumenten des Korpus des Ministeriums für wirtschaftliche Entwicklung zu extrahieren. Dieser Fall unterschied sich stark von den Fällen, die beispielsweise im Conll- Wettbewerb verwendet wurden . Erstens waren die Arten von Entitäten selbst nicht Standard (Personen, Standorte, Organisationen), darunter gab es sogar unbenannte und inhaltliche Maßnahmen. Zweitens waren die Texte selbst keine Sätze verifizierter Sätze, sondern echte Dokumente, die zu verschiedenen Listen, Überschriften und sogar Tabellen führten. Infolgedessen traten die Hauptschwierigkeiten genau bei der Datenverarbeitung und nicht bei der Lösung des Problems auf. Tatsächlich handelt es sich hierbei um klassische Aufgaben zur Erkennung benannter Entitäten und zur Extraktion von Beziehungen.
Im Wettbewerb selbst gab es 3 Tracks: NER, RE mit bestimmten Entitäten und End-to-End-RE. Ich habe versucht, die ersten beiden zu lösen. In der ersten Aufgabe habe ich klassische Ansätze verwendet. Zuerst habe ich versucht, ein wiederkehrendes Netzwerk als Modell zu verwenden und Fasttext-Worteinbettungen, Großschreibmuster, symbolische Einbettungen und POS-Tags als Features zu verwenden [1]. Dann habe ich bereits verschiedene vorab trainierte BERTs [2] verwendet, die meinem bisherigen Ansatz weit überlegen sind. Dies reichte jedoch nicht aus, um auf dieser Strecke den ersten Platz einzunehmen.
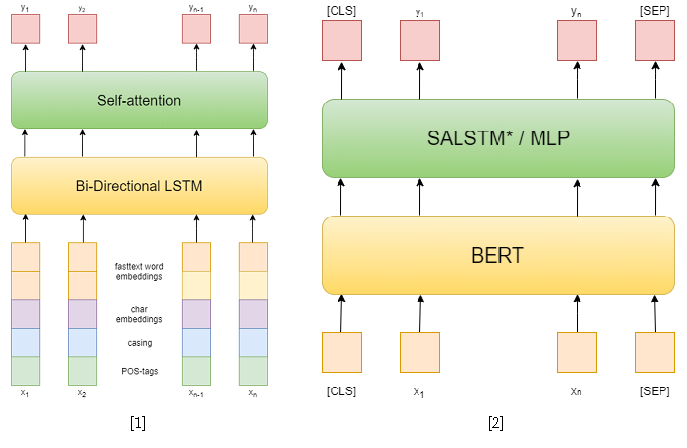
Aber im zweiten Track war ich erfolgreich. Um das Problem des Extrahierens von Beziehungen zu lösen, habe ich es auf das Problem des Klassifizierens von Beziehungen reduziert, ähnlich wie bei SemEval 2010, Aufgabe 8 . In diesem Problem wird für jeden Satz ein Entitätspaar angegeben, für das die Beziehung klassifiziert werden muss. Und in einer Spur kann jeder Satz so viele Entitäten enthalten, wie Sie möchten. Er wird jedoch einfach auf die vorherige reduziert, indem der Satz für jedes Entitätspaar abgetastet wird. Während des Trainings habe ich zufällig negative Beispiele für jeden Satz in einer Größe genommen, die nicht doppelt so groß ist wie die Anzahl der positiven, um die Trainingsstichprobe zu reduzieren.
Als Lösungsansätze für das Problem der Klassifizierung von Beziehungen habe ich zwei auf BERT-e basierende Modelle verwendet. Im ersten Fall habe ich einfach BERT-Ausgaben mit NER-Einbettungen verkettet und dann die Merkmale für jedes Token mithilfe von Self-Attention gemittelt [3]. Eine der besten Lösungen für SemEval 2010 Aufgabe 8 - R-BERT [4] wurde als zweites Modell verwendet. Das Wesentliche dieses Ansatzes ist wie folgt: Fügen Sie vor und nach jeder Entität spezielle Token ein, mitteln Sie die BERT-Ausgaben für die Token jeder Entität, kombinieren Sie die resultierenden Vektoren mit der Ausgabe, die dem CLS-Token entspricht, und klassifizieren Sie den resultierenden Merkmalsvektor. Damit belegte dieses Modell den ersten Platz in der Strecke. Die Ergebnisse des Wettbewerbs finden Sie hier .
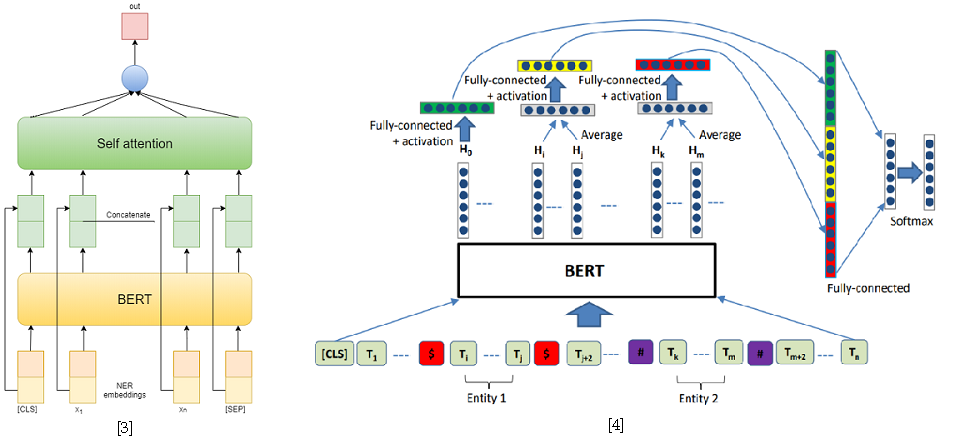
[4] Wu, S., He, Y. (2019, November). Anreicherung des vorab trainierten Sprachmodells mit Entitätsinformationen für die Beziehungsklassifizierung. In Proceedings of the 28. ACM International Conference on Information and Knowledge Management ( S. 2361-2364 ).
Was erschien Ihnen bei diesen Aufgaben am schwierigsten?
Am problematischsten war die Bearbeitung des Falles. Die Aufgaben selbst sind so klassisch wie möglich, für ihre Lösung gibt es bereits vorgefertigte Frameworks, zum Beispiel AllenNLP. Die Antwort muss jedoch mit dem Speichern von Token-Bereichen gegeben werden, sodass ich die vorgefertigte Pipeline nicht einfach verwenden konnte, ohne viel zusätzlichen Code zu schreiben. Deshalb habe ich beschlossen, die gesamte Pipeline in reinem PyTorch zu schreiben, um nichts zu verpassen. Obwohl ich noch einige Module von AllenNLP verwendet habe.
Es gab auch viele ziemlich lange Sätze im Korpus, die Unannehmlichkeiten beim Unterrichten großer Transformatoren verursachten, zum Beispiel BERT, weil Mit zunehmender Satzlänge stellen sie hohe Anforderungen an den Videospeicher. Die meisten dieser Sätze sind jedoch durch Semikolons getrennte Aufzählungen und können durch dieses Zeichen getrennt werden. Ich habe die restlichen Angebote einfach durch die maximale Anzahl von Token geteilt.
Haben Sie schon einmal an Dialogen und Tracks teilgenommen?
Letztes Jahr habe ich bei der Studentensitzung mit meinem Master gesprochen.
Warum hast du dich dieses Jahr für den Wettbewerb entschieden?
Zu dieser Zeit löste ich nur das Problem des Extrahierens von Beziehungen, aber für ein anderes Korps. Ich habe versucht, einen anderen Ansatz zu verwenden, der auf Analysebäumen basiert. Der Pfad im Baum von einer Entität zu einer anderen wurde als Eingabe verwendet. Leider zeigte dieser Ansatz keine starken Ergebnisse, obwohl er auf einer Ebene mit dem auf wiederkehrenden Netzwerken basierenden Ansatz lag, bei dem Token-Einbettungen und andere Merkmale als Zeichen verwendet wurden, z. B. die Länge des Pfades von einem Token zu einem Stamm oder einer der Entitäten im syntaktischen Baum. Analyse sowie die relative Position der Entitäten.
An diesem Wettbewerb habe ich mich für die Teilnahme entschieden, da ich bereits einige Grundlagen für die Lösung ähnlicher Probleme hatte. Und warum nicht in einem Wettbewerb anwenden und veröffentlicht werden? Es stellte sich als nicht so einfach heraus, wie ich dachte, aber es ist eher auf Probleme mit der Interaktion mit den Rümpfen zurückzuführen. Daher war es für mich eher eine technische als eine Forschungsaufgabe.
Haben Sie an anderen Wettbewerben teilgenommen?
Gleichzeitig nahm unser Team an SemEval teil . Ilya Dimov war hauptsächlich an der Aufgabe beteiligt, ich schlug nur ein paar Ideen vor. Es gab die Aufgabe, Propaganda zu klassifizieren: Die Spanne des Textes wurde ausgewählt und es war notwendig, ihn zu klassifizieren. Ich schlug vor, den R-BERT-Ansatz zu verwenden, dh diese Entität in Token auszuwählen, ein spezielles Token davor und danach einzufügen und die Ausgaben zu mitteln. Infolgedessen ergab sich ein geringfügiger Anstieg. Dies ist der wissenschaftliche Wert: Um das Problem zu lösen, haben wir ein Modell verwendet, das für etwas völlig anderes entwickelt wurde.
Ich habe auch am ABBYY-Hackathon teilgenommen, am ACM icpc - Wettbewerb in der Sportprogrammierung in den ersten Jahren. Wir sind damals nicht weit gekommen, aber es hat Spaß gemacht. Solche Wettbewerbe unterscheiden sich stark von denen des Dialogs, bei dem genügend Zeit vorhanden ist, um verschiedene Ansätze ruhig umzusetzen und zu testen. Bei Hackathons muss man alles schnell machen, es gibt keine Zeit zum Entspannen, es gibt keinen Tee. Aber das ist das Schöne an solchen Ereignissen - sie haben eine bestimmte Atmosphäre.
Was sind die interessantesten Probleme, die Sie bei Wettbewerben oder bei der Arbeit gelöst haben?
In Kürze steht ein GENEA-Wettbewerb zur Generierung von Gesten an, und ich werde dorthin gehen. Ich denke es wird interessant sein. Dies ist ein Workshop auf der ACM - International Conference on Intelligent Virtual Agents . In diesem Wettbewerb wird vorgeschlagen, Gesten für ein 3D-menschliches Modell basierend auf der Stimme zu generieren. Ich habe dieses Jahr beim Dialog mit einem ähnlichen Thema gesprochen und einen kleinen Überblick über Ansätze zum Problem der automatischen Erzeugung von Gesichtsausdrücken und Gesten aus der Stimme gegeben. Ich muss Erfahrung sammeln, weil ich meine Dissertation zu einem ähnlichen Thema noch verteidigen muss. Ich möchte versuchen, einen virtuellen Lese-Agenten mit Mimik, Gesten und natürlich Stimme zu erstellen. Gegenwärtige Ansätze zur Sprachsynthese ermöglichen es, ziemlich realistische Sprache aus Text zu erzeugen, während Ansätze zur Gestenerzeugung es ermöglichen, Gesten aus Sprache zu erzeugen. Warum also nicht diese Ansätze kombinieren?
Übrigens, wo studierst du jetzt?
Ich bin ein Doktorand am Institut für Computerlinguistik von ABBYY an der Phystech School für Angewandte Mathematik und Informatik am MIPT . Ich werde meine These in zwei Jahren verteidigen.
Welche an der Universität erworbenen Kenntnisse und Fähigkeiten helfen Ihnen jetzt?
Seltsamerweise Mathematik. Obwohl ich nicht jeden Tag integriere und keine Matrizen in meinem Kopf multipliziere, lehrt die Mathematik analytisches Denken und die Fähigkeit, etwas herauszufinden. Schließlich beinhaltet jede Prüfung das Beweisen von Theoremen, und der Versuch, sie zu lernen, ist nutzlos, aber es ist möglich, sich selbst zu verstehen und zu beweisen, indem man sich nur an eine Idee erinnert. Wir hatten auch gute Programmierkurse, in denen wir auf niedrigem Niveau gelernt haben, wie alles funktioniert, verschiedene Algorithmen und Datenstrukturen analysiert haben. Und jetzt wird es kein Problem mehr sein, sich mit einem neuen Framework oder einer Programmiersprache zu befassen. Ja, natürlich hatten wir Kurse in maschinellem Lernen und insbesondere in NLP, aber dennoch scheinen mir grundlegende Fähigkeiten wichtiger zu sein.
Daniil Anastasyev, Gewinner des Dialogs Evaluation GramEval-2020

Was machst du?
Ich entwickle den Sprachassistenten "Alice", ich arbeite auf der Suche nach Bedeutungsgruppen. Wir analysieren die Anfragen, die an Alice kommen. Ein Standardbeispiel für eine Abfrage ist "Wie ist das Wetter morgen in Moskau?" Sie müssen verstehen, dass dies eine Anfrage über das Wetter ist, dass die Anfrage nach dem Ort (Moskau) fragt und es eine Angabe der Zeit (morgen) gibt.
Erzählen Sie uns von dem Problem, das Sie in diesem Jahr auf einem der Tracks zur Dialogbewertung gelöst haben.
Ich habe eine Aufgabe erledigt, die der von ABBYY sehr nahe kommt. Es war notwendig, ein Modell zu erstellen, das den Satz analysiert, morphologische und syntaktische Analysen durchführt und Deckspelzen definiert. Dies ist sehr ähnlich zu dem, was sie in der Schule machen. Ich habe ungefähr 5 Tage frei gebraucht, um das Modell zu bauen.

Das Modell wurde in normalem Russisch gelernt, aber wie Sie sehen, funktioniert es auch in der Sprache, in der das Problem aufgetreten ist.
Klingt das nach dem, was Sie bei der Arbeit machen?
Wahrscheinlich nicht. Hier müssen Sie verstehen, dass diese Aufgabe an sich nicht viel Bedeutung hat - sie wird als Teilaufgabe im Rahmen der Lösung eines wichtigen Geschäftsproblems gelöst. So ist beispielsweise in ABBYY, wo ich einmal gearbeitet habe, die morphosyntaktische Analyse der erste Schritt zur Lösung des Problems der Informationsextraktion. Im Rahmen meiner aktuellen Aufgaben benötige ich solche Analysen nicht. Die zusätzliche Erfahrung mit vorgefertigten Sprachmodellen wie BERT scheint jedoch für meine Arbeit sicherlich nützlich zu sein. Im Allgemeinen war dies die Hauptmotivation für die Teilnahme - ich wollte nicht gewinnen, sondern üben und einige nützliche Fähigkeiten erwerben. Außerdem war mein Diplom teilweise mit dem Thema des Problems verbunden.
Haben Sie schon einmal an der Dialogbewertung teilgenommen?
Hat im 5. Jahr an der MorphoRuEval-2017-Strecke teilgenommen und dann auch den 1. Platz belegt. Dann war es notwendig, nur Morphologie und Deckspelzen ohne syntaktische Beziehungen zu definieren.
Ist es realistisch, Ihr Modell jetzt auf andere Aufgaben anzuwenden?
Ja, mein Modell kann für andere Aufgaben verwendet werden. Ich habe den gesamten Quellcode veröffentlicht. Ich plane, den Code mit einem leichteren und schnelleren, aber weniger genauen Modell zu veröffentlichen. Wenn jemand möchte, kann theoretisch das aktuelle Modell verwendet werden. Das Problem ist, dass es für die meisten zu groß und zu langsam sein wird. Im Wettbewerb kümmert sich niemand um Geschwindigkeit, es ist interessant, die höchstmögliche Qualität zu erreichen, aber in der praktischen Anwendung ist normalerweise alles umgekehrt. Daher besteht der Hauptvorteil derart großer Modelle darin, zu wissen, welche Qualität am besten erreichbar ist, um zu verstehen, was Sie opfern.
Warum nehmen Sie an Dialogevaluation und anderen ähnlichen Wettbewerben teil?
Hackathons und solche Wettbewerbe stehen nicht in direktem Zusammenhang mit meiner Arbeit, aber es ist immer noch eine lohnende Erfahrung. Als ich zum Beispiel letztes Jahr am AI Journey Hackathon teilgenommen habe, habe ich einige Dinge gelernt, die ich dann in meiner Arbeit verwendet habe. Die Aufgabe bestand darin, zu lernen, wie man die Prüfung in russischer Sprache besteht, dh Tests zu lösen und einen Aufsatz zu schreiben. Es ist klar, dass dies alles wenig mit Arbeit zu tun hat. Die Möglichkeit, schnell ein Modell zu entwickeln und zu trainieren, das ein Problem löst, ist jedoch sehr nützlich. Mein Team und ich haben übrigens den ersten Platz gewonnen.
Welche Ausbildung haben Sie erhalten und was haben Sie nach dem Studium gemacht?
Er absolvierte die Bachelor- und Masterabschlüsse der Abteilung für Computerlinguistik ABBYY am Moskauer Institut für Physik und Technologie, die er 2018 abschloss. Er studierte auch an der School of Data Analysis (SHAD). Als es im 2. Jahr an der Zeit war, eine Basisabteilung zu wählen, ging der größte Teil unserer Gruppe in die Abteilungen von ABBYY - Computerlinguistik oder Bilderkennung und Textverarbeitung. Im Grundstudium wurde uns beigebracht, gut zu programmieren - es gab sehr nützliche Kurse. Ab dem 4. Jahr habe ich 2,5 Jahre bei ABBYY gearbeitet. Zuerst in der Morphologiegruppe, dann war ich mit Aufgaben im Zusammenhang mit Sprachmodellen beschäftigt, um die Texterkennung in ABBYY FineReader zu verbessern. Ich habe Code geschrieben, Modelle trainiert, jetzt mache ich dasselbe, aber für ein völlig anderes Produkt.
Wie verbringst du deine Freizeit?
Ich liebe, Bücher zu lesen. Je nach Jahreszeit versuche ich zu laufen oder Ski zu fahren. Ich fotografiere gern auf Reisen.
Haben Sie Pläne oder Ziele für die nächsten 5 Jahre?
5 Jahre ist zu weit Planungshorizont. Ich habe nicht einmal 5 Jahre Berufserfahrung. In den letzten 5 Jahren hat sich viel verändert, jetzt gibt es eindeutig ein anderes Gefühl als im Leben. Ich kann mir kaum vorstellen, was sich sonst noch ändern kann, aber es gibt Gedanken über eine Promotion im Ausland.
Welchen Rat können Sie jungen Entwicklern geben, die sich mit Computerlinguistik beschäftigen und am Anfang ihrer Reise stehen?
Es ist am besten zu üben, zu versuchen und zu konkurrieren. Komplette Anfänger können einen der vielen Kurse belegen : zum Beispiel von SHAD , DeepPavlov oder sogar von meinem eigenen, den ich einmal bei ABBYY unterrichtet habe .
, ABBYY : () (). 15 brains@abbyy.com , , GPA 5- 10- .
, ABBYY – .