
Dodo Pizza hat mehr als 600 Pizzerien in 13 Ländern, und die meisten Prozesse in Pizzerien werden vom Dodo IS- Informationssystem gesteuert , das wir schreiben und unterstützen. Daher ist die Zuverlässigkeit und Stabilität des Systems überlebenswichtig.
Jetzt wird die Stabilität und Zuverlässigkeit des Informationssystems im Unternehmen vom SRE- Team ( Site Reliability Engineering ) unterstützt, was jedoch nicht immer der Fall war.
Hintergrund: Parallele Welten von Entwicklern und Infrastruktur
Viele Jahre lang entwickelte ich mich als typischer Full-Stack-Entwickler (und ein bisschen wie ein Scrum-Master), lernte das Schreiben von gutem Code, wandte Praktiken aus der extremen Programmierung an und reduzierte fleißig die Menge an WTF in Projekten, die ich berührte. Aber je mehr Erfahrung ich in der Softwareentwicklung gesammelt habe, desto mehr wurde mir klar, wie wichtig zuverlässige Überwachungs- und Verfolgungssysteme für Anwendungen, hochwertige Protokolle, vollautomatische Tests und Mechanismen sind, die eine hohe Zuverlässigkeit der Dienste gewährleisten. Und immer öfter schaute er "über den Zaun" zum Infrastruktur-Team.
Je besser ich die Umgebung verstand, in der mein Code funktioniert, desto mehr war ich überrascht: Automatische Tests für alles und jedes, CI, häufige Releases, sicheres Refactoring und kollektiver Codebesitz in der Softwarewelt sind seit langem Routine und vertraut. Gleichzeitig ist es in der Welt der "Infrastruktur" immer noch normal, keine automatischen Tests durchzuführen, Änderungen an Produktionssystemen im halbmanuellen Modus vorzunehmen, und die Dokumentation befindet sich häufig nur in den Köpfen von Einzelpersonen, nicht jedoch im Code.
Diese kulturelle und technologische Kluft verursacht nicht nur Verwirrung, sondern auch Probleme: an der Schnittstelle von Entwicklung, Infrastruktur und Wirtschaft. Aufgrund der Nähe zur Hardware und der relativ schlecht entwickelten Tools ist es schwierig, einige Probleme in der Infrastruktur zu lösen. Der Rest kann jedoch besiegt werden, wenn Sie alle Ihre Ansible-Playbooks und Bash-Skripte als vollständiges Softwareprodukt betrachten und dieselben Anforderungen auf sie anwenden.
Bermuda-Dreieck der Probleme
Ich werde jedoch von weitem beginnen - mit den Problemen, für die all diese Tänze benötigt werden.
Entwicklerprobleme
Vor zwei Jahren haben wir festgestellt, dass ein großes Netzwerk von Pizzerien ohne unsere eigene mobile Anwendung nicht leben kann, und beschlossen, sie zu schreiben:
- ein tolles Team zusammenstellen;
- Wir haben in sechs Monaten eine bequeme und schöne Bewerbung geschrieben.
- unterstützte den großen Start mit köstlichen Aktionen;
- und am ersten Tag fielen sie sicher unter Last.
Am Anfang gab es natürlich viele Untiefen, aber am allermeisten erinnere ich mich an einen. Zum Zeitpunkt der Entwicklung wurde ein schwacher Server in der Produktion bereitgestellt, fast ein Taschenrechner, der Anforderungen aus der Anwendung verarbeitete. Vor der öffentlichen Ankündigung der Anwendung musste sie erhöht werden - wir leben in Azure, und dies wurde mit einem Klick auf eine Schaltfläche gelöst.
Aber niemand drückte diesen Knopf: Das Infrastruktur-Team wusste nicht einmal, dass heute eine Anwendung veröffentlicht wurde. Sie entschieden, dass es in der Verantwortung des Anwendungsteams liegt, die Produktion des "unkritischen" Dienstes zu überwachen. Und der Backend-Entwickler (dies war sein erstes Projekt in Dodo) entschied, dass die Leute von der Infrastruktur dies in großen Unternehmen tun.
Dieser Entwickler war ich. Dann kam ich auf eine offensichtliche, aber wichtige Regel:
, , , . .
Jetzt ist es nicht schwer. In den letzten Jahren ist eine Vielzahl von Tools erschienen, mit denen Programmierer in die Welt der Ausbeutung blicken und nichts kaputt machen können: Prometheus, Zipkin, Jaeger, ELK-Stack, Kusto.
Viele Entwickler haben jedoch immer noch ernsthafte Probleme mit den als Infrastruktur / DevOps / SRE bezeichneten. Programmierer:
Verlassen Sie sich auf das Infrastruktur-Team. Dies verursacht Schmerzen, Missverständnisse und manchmal gegenseitigen Hass.
Sie entwerfen ihre Systeme isoliert von der Realität und berücksichtigen nicht, wo und wie ihr Code ausgeführt wird. Beispielsweise unterscheiden sich Architektur und Design eines Systems, das für das Leben in der Cloud entwickelt wird, von dem eines Systems, das vor Ort gehostet wird.
Sie verstehen die Art der Fehler und Probleme, die mit ihrem Code verbunden sind, nicht.Dies macht sich insbesondere dann bemerkbar, wenn Probleme im Zusammenhang mit der Last, dem Abfrageausgleich, der Netzwerk- oder Festplattenleistung auftreten. Entwickler haben dieses Wissen nicht immer.
Geld und andere Unternehmensressourcen , die zur Pflege des Codes verwendet werden, können nicht optimiert werden. Nach unserer Erfahrung überflutet das Infrastruktur-Team das Problem einfach mit Geld, indem es beispielsweise die Größe des Datenbankservers in der Produktion erhöht. Daher erreichen Codeprobleme oft nicht einmal Programmierer. Nur aus irgendeinem Grund kostet die Infrastruktur mehr.
Infrastrukturprobleme
Es gibt auch Schwierigkeiten auf der "anderen Seite".
Es ist schwierig, Dutzende von Diensten und Umgebungen ohne Qualitätscode zu verwalten. Wir haben mehr als 450 Repositories auf GitHub. Einige von ihnen benötigen keine Betriebsunterstützung, andere sind tot und für den Verlauf gespeichert, aber ein wesentlicher Teil enthält Dienste, die unterstützt werden müssen. Sie müssen irgendwo gehostet werden, sie müssen überwacht, Protokolle gesammelt und einheitliche CI / CD-Pipelines erstellt werden.
Um all dies zu verwalten, haben wir kürzlich Ansible aktiv eingesetzt. Unser Ansible-Repository hatte:
- 60 Rollen;
- 102 Spielbücher;
- Bindung in Python und Bash;
- manuelle Tests in Vagrant.
All dies wurde von einer intelligenten Person geschrieben und gut geschrieben. Sobald jedoch andere Entwickler aus der Infrastruktur und Programmierer anfingen, aktiv mit diesem Code zu arbeiten, stellte sich heraus, dass Playbooks kaputt gehen und Rollen dupliziert und "mit Moos bewachsen" sind.
Der Grund war, dass dieser Code nicht viele der Standardpraktiken in der Welt der Softwareentwicklung verwendete. Es gab keine CI / CD-Pipeline, und die Tests waren kompliziert und langsam, sodass jeder zu faul oder "keine Zeit" war, sie manuell auszuführen, geschweige denn neue zu schreiben. Ein solcher Code ist zum Scheitern verurteilt, wenn mehr als eine Person daran arbeitet.
Ohne Kenntnis des Codes ist es schwierig, effektiv auf Vorfälle zu reagieren.Wenn eine Warnung um 3 Uhr morgens in PagerDuty eintrifft, müssen Sie einen Programmierer suchen, der erklärt, was und wie. Zum Beispiel, dass diese Fehler 500 den Benutzer betreffen, während andere mit dem sekundären Dienst zusammenhängen, die Endclients ihn nicht sehen und Sie ihn bis zum Morgen so lassen können. Um drei Uhr morgens ist es jedoch schwierig, Programmierer zu wecken. Daher ist es ratsam zu verstehen, wie der von Ihnen unterstützte Code funktioniert.
Viele Tools müssen in Anwendungscode eingebettet werden. Die Mitarbeiter der Infrastruktur wissen, was zu überwachen ist, wie zu protokollieren ist und welche Dinge für die Rückverfolgung zu beachten sind. All dies können sie jedoch häufig nicht in den Anwendungscode einbetten. Und diejenigen, die können, wissen nicht, was und wie sie einbetten sollen.
"Telefon kaputt".Zum hundertsten Mal ist es unangenehm zu erklären, was und wie zu überwachen ist. Es ist einfacher, eine gemeinsam genutzte Bibliothek zu schreiben, um sie zur Wiederverwendung in ihren Anwendungen an Programmierer weiterzugeben. Dazu müssen Sie jedoch in der Lage sein, Code in derselben Sprache, im selben Stil und mit denselben Ansätzen zu schreiben, die die Entwickler Ihrer Anwendungen verwenden.
Geschäftliche Probleme
Das Geschäft hat auch zwei große Probleme, die angegangen werden müssen.
Direkte Verluste durch Systeminstabilität in Bezug auf Zuverlässigkeit und Verfügbarkeit.
Im Jahr 2018 hatten wir 51 kritische Vorfälle, und kritische Elemente des Systems funktionierten nicht länger als 20 Stunden. In Geld ausgedrückt sind dies 25 Millionen Rubel direkter Verluste aufgrund nicht gelieferter und nicht gelieferter Bestellungen. Und wie viel wir durch das Vertrauen von Mitarbeitern, Kunden und Franchisenehmern verloren haben, lässt sich nicht berechnen, es wird nicht in Geld bewertet.
Supportkosten für die aktuelle Infrastruktur. Gleichzeitig hat sich das Unternehmen für 2018 ein Ziel gesetzt: die Infrastrukturkosten pro Pizzeria um das Dreifache zu senken. Aber weder Programmierer noch DevOps-Ingenieure in ihren Teams konnten dieses Problem annähernd lösen. Dafür gibt es Gründe:
- , ;
- , operations ( DevOps), ;
- , .
?
Wie kann man all diese Probleme lösen? Die Lösung haben wir im Buch "Site Reliability Engineering" von Google gefunden. Als wir es gelesen haben, haben wir verstanden - das ist es, was wir brauchen.
Aber es gibt eine Nuance - es dauert Jahre, um all dies umzusetzen, und Sie müssen irgendwo anfangen. Betrachten Sie die anfänglichen Daten, die wir ursprünglich hatten.
Unsere gesamte Infrastruktur befindet sich fast ausschließlich in Microsoft Azure. Es gibt mehrere unabhängige Vertriebscluster, die auf verschiedene Kontinente verteilt sind: Europa, Amerika und China. Es gibt Ladestationen, die die Produktion wiederholen, aber in einer isolierten Umgebung leben, sowie Dutzende von DEV-Umgebungen für Entwicklungsteams.
Von den guten SRE-Praktiken, die wir bereits hatten:
- Mechanismen zur Überwachung von Anwendungen und Infrastruktur (Spoiler: 2018 fanden wir sie gut, aber jetzt haben wir alles neu geschrieben);
- 24/7 on-call;
- ;
- ;
- CI/CD- ;
- , ;
- SRE .
Aber es gab Probleme, die ich zuerst lösen wollte:
Das Infrastruktur-Team war überlastet. Aufgrund des aktuellen Betriebssystems gab es nicht genügend Zeit und Mühe für globale Verbesserungen. Zum Beispiel wollten wir schon sehr lange, konnten aber Elasticsearch in unserem Stack nicht loswerden oder die Infrastruktur eines anderen Cloud-Anbieters duplizieren, um Risiken zu vermeiden (hier können diejenigen lachen, die es bereits in Multi-Cloud versucht haben).
Chaos im Code. Der Infrastrukturcode war chaotisch, über verschiedene Repositorys verteilt und nirgendwo dokumentiert. Alles beruhte auf dem Wissen des Einzelnen und sonst nichts. Dies war ein gigantisches Problem des Wissensmanagements.
"Es gibt Programmierer, aber es gibt Infrastrukturingenieure."Trotz der Tatsache, dass wir eine ziemlich gut entwickelte DevOps-Kultur hatten, gab es immer noch diese Trennung. Zwei Klassen von Menschen mit völlig unterschiedlichen Erfahrungen, die unterschiedliche Sprachen sprechen und unterschiedliche Werkzeuge verwenden. Sie sind natürlich Freunde und kommunizieren, verstehen sich aber oft aufgrund völlig unterschiedlicher Erfahrungen nicht.
Onboarding von SRE-Teams
Um diese Probleme zu lösen und irgendwie auf SRE umzusteigen, haben wir ein Onboarding-Projekt gestartet. Nur war es kein klassisches Onboarding - die Schulung neuer Mitarbeiter (Newcomer), um Mitarbeiter zum aktuellen Team hinzuzufügen. Es war die Schaffung eines neuen Teams von Infrastrukturingenieuren und Programmierern - der erste Schritt in Richtung einer vollwertigen SRE-Struktur.
Wir haben dem Projekt 4 Monate zugewiesen und drei Ziele festgelegt:
- Programmierer mit den Kenntnissen und Fähigkeiten zu schulen, die für den Dienst und die operativen Aktivitäten im Infrastruktur-Team erforderlich sind.
- Schreiben Sie IaC - eine Beschreibung der gesamten Infrastruktur im Code. Und es sollte ein vollwertiges Softwareprodukt mit CI / CD-Tests sein.
- Erstellen Sie unsere gesamte Infrastruktur aus diesem Code neu und vergessen Sie, in Azure manuell mit der Maus auf virtuelle Maschinen zu klicken.
Teilnehmer: 9 Personen, 6 davon aus dem Entwicklungsteam, 3 aus der Infrastruktur. Für 4 Monate mussten sie ihre regulären Jobs verlassen und sich in die vorgesehenen Aufgaben vertiefen. Um das "Leben" im Geschäft aufrechtzuerhalten, blieben 3 weitere Personen aus der Infrastruktur im Dienst, beschäftigten sich mit Betriebssystemen und deckten das Heck ab. Infolgedessen wurde das Projekt spürbar ausgedehnt und dauerte mehr als fünf Monate (von Mai bis Oktober 2019).
Zwei Komponenten des Onboarding: Training und Übung
Onboarding bestand aus zwei Teilen: Lernen und Arbeiten an der Infrastruktur in Code.
Ausbildung. Für das Training wurden mindestens 3 Stunden pro Tag bereitgestellt:
- Artikel und Bücher aus der Referenzliste zu lesen: Linux, Netzwerke, SRE;
- bei Vorträgen zu bestimmten Werkzeugen und Technologien;
- an Technologieclubs, zum Beispiel Linux, wo wir uns mit schwierigen Fällen und Fällen befasst haben.
Ein weiteres Lernwerkzeug ist die interne Demo. Dies ist ein wöchentliches Meeting, bei dem alle (die etwas zu sagen haben) in 10 Minuten über eine Technologie oder ein Konzept sprachen, die sie in einer Woche in unseren Code implementiert haben. Zum Beispiel hat Vasya die Pipeline für die Arbeit mit Terraform-Modulen geändert, und Petya hat die Image-Assembly mit Packer neu geschrieben.
Nach der Demo haben wir in Slack Diskussionen zu jedem Thema gestartet, bei denen interessierte Teilnehmer asynchron alles detaillierter diskutieren konnten. So haben wir lange Besprechungen für 10 Personen vermieden, aber gleichzeitig haben alle im Team gut verstanden, was mit unserer Infrastruktur passiert und wohin wir gehen.

Trainieren. Der zweite Teil des Onboarding ist die Erstellung / Beschreibung der Infrastruktur im Code . Dieser Teil war in mehrere Phasen unterteilt.
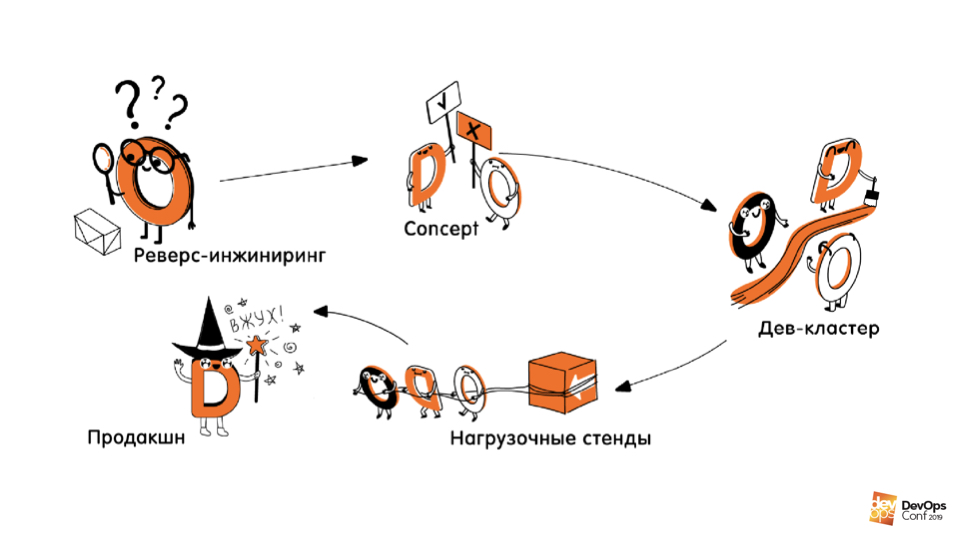
Reverse Engineering der Infrastruktur.Dies ist die erste Phase, in der wir herausgefunden haben, wo es repariert ist, wie was funktioniert, wo welche Services funktionieren, wo welche Maschinen und deren Größen. Alles wurde vollständig dokumentiert.
Konzepte. Wir haben mit verschiedenen Technologien, Sprachen und Ansätzen experimentiert und herausgefunden, wie wir unsere Infrastruktur beschreiben können und welche Tools dafür verwendet werden sollten.
Code schreiben. Dies beinhaltete das Schreiben des Codes selbst, das Erstellen von CI / CD-Pipelines, Tests und das Erstellen von Prozessen. Wir haben den beschriebenen Code geschrieben und wussten, wie wir unsere Entwicklungsinfrastruktur von Grund auf neu erstellen können.
Re-Creating steht für Lastprüfung und Produktion.Dies ist die vierte Phase, die nach dem Onboarding stattfinden sollte, aber sie wurde bisher verschoben, da der Gewinn daraus seltsamerweise viel geringer ist als bei den Mädchen, die sehr oft erstellt / neu erstellt werden.
Stattdessen wechselten wir zu Projektaktivitäten: Wir teilten uns in kleine Subteams auf und packten die globalen Infrastrukturprojekte an, zu denen wir noch nie gekommen waren. Und natürlich haben wir uns der Uhr angeschlossen.
Unsere IaC-Tools
- Terraform .
- Packer Ansible .
- Jsonnet Python .
- Azure, .
- VS Code — IDE, , , , .
- — , .
Extreme Programmierpraktiken in der Infrastruktur
Die Hauptsache, die wir als Programmierer mitgebracht haben, sind die extremen Programmierpraktiken, die wir in unserer Arbeit anwenden. XP ist eine agile Softwareentwicklungsmethode, die eine Zusammenstellung der besten Entwicklungsansätze, -praktiken und -werte kombiniert.
Es gibt keinen einzigen Programmierer, der nicht mindestens einige der Praktiken der extremen Programmierung angewendet hat, auch wenn er nichts davon weiß. Gleichzeitig werden diese Praktiken in der Infrastrukturwelt umgangen, obwohl sie sich stark mit den Praktiken von Google SRE überschneiden.
Es gibt einen separaten Artikel darüber, wie wir XP für die Infrastruktur angepasst haben .... Aber auf den Punkt gebracht: XP-Praktiken funktionieren für Infrastrukturcode, wenn auch mit Einschränkungen, Anpassungen, aber sie funktionieren. Wenn Sie sie zu Hause anwenden möchten, laden Sie Personen mit Erfahrung in der Anwendung dieser Praktiken ein. Die meisten dieser Praktiken werden auf die eine oder andere Weise im selben Buch über SRE beschrieben .
Alles hätte gut funktionieren können, aber das tut es nicht.
Technische und anthropogene Probleme unterwegs
Innerhalb des Projekts gab es zwei Arten von Problemen:
- Technisch : Grenzen der „Eisen“ -Welt, mangelndes Wissen und Rohwerkzeuge, die verwendet werden mussten, weil es keine anderen gibt. Dies sind häufige Probleme für jeden Programmierer.
- Mensch : die Interaktion von Menschen in einem Team. Kommunikation, Entscheidungsfindung, Schulung. Damit war es schlimmer, also müssen wir genauer darauf eingehen.
Wir haben begonnen, das Onboarding-Team so zu entwickeln, wie wir es mit jedem anderen Programmierteam tun würden. Wir haben erwartet, dass es die üblichen Phasen des Aufbaus eines Takman-Teams geben wird : Stürmen, Normalisieren, und am Ende werden wir zu Produktivität und produktiver Arbeit übergehen . Daher machten sie sich keine Sorgen, dass es am Anfang einige Schwierigkeiten bei der Kommunikation, Entscheidungsfindung und Schwierigkeiten gab, sich zu einigen.
Zwei Monate vergingen, aber die Sturmphase ging weiter. Erst gegen Ende des Projekts stellten wir fest, dass alle Probleme, mit denen wir zu kämpfen hatten und die wir nicht als miteinander verbunden empfanden, das Ergebnis eines gemeinsamen Grundproblems waren - zwei Gruppen völlig unterschiedlicher Personen kamen im Team zusammen:
- Erfahrene Programmierer mit langjähriger Erfahrung, für die sie ihre Ansätze, Gewohnheiten und Werte in der Arbeit entwickelt haben.
- Eine weitere Gruppe aus der Welt der Infrastruktur mit eigenen Erfahrungen. Sie haben unterschiedliche Beulen, unterschiedliche Gewohnheiten und denken auch, dass sie wissen, wie man richtig lebt.
Es gab einen Konflikt zwischen zwei Ansichten über das Leben in einem Team. Wir haben das nicht sofort gesehen und nicht angefangen, damit zu arbeiten, wodurch wir viel Zeit, Kraft und Nerven verloren haben.
Diese Kollision kann jedoch nicht vermieden werden. Wenn Sie starke Programmierer und schwache Infrastrukturingenieure zum Projekt einladen, haben Sie einen einseitigen Wissensaustausch. Im Gegenteil, es funktioniert auch nicht - manche schlucken andere und das war's. Und Sie müssen eine Mischung erhalten, also müssen Sie darauf vorbereitet sein, dass das „Schleifen“ sehr lang sein kann (in unserem Fall konnten wir das Team nur ein Jahr später stabilisieren und uns von einem der technisch leistungsstärksten Ingenieure verabschieden).
Wenn Sie ein solches Team zusammenstellen möchten, vergessen Sie nicht, einen starken agilen Trainer, Scrum Master oder Psychotherapeuten anzurufen - je nachdem, was Ihnen am besten gefällt. Vielleicht helfen sie.
Onboarding-Ergebnisse
Basierend auf den Ergebnissen des Onboarding-Projekts (das im Oktober 2019 endete) haben wir:
- Wir haben ein vollwertiges Softwareprodukt entwickelt, das unsere DEV-Infrastruktur mit einer eigenen CI-Pipeline, Tests und anderen Attributen eines hochwertigen Softwareprodukts verwaltet.
- Wir haben die Anzahl der Leute, die bereit sind, im Dienst zu sein, verdoppelt und das aktuelle Team entlastet. Sechs Monate später wurden diese Leute zu vollwertigen SREs. Jetzt können sie ein Feuer auf dem Markt löschen, ein Team von Programmierern auf NTF konsultieren oder eine eigene Bibliothek für Entwickler schreiben.
- SRE. , , .
- : , , , .
: ,
Mehrere Einblicke vom Entwickler. Treten Sie nicht auf unseren Rechen, sparen Sie sich und Ihren Mitmenschen Nerven und Zeit.
Infrastruktur gehört der Vergangenheit an. Als ich in meinem ersten Jahr (vor 15 Jahren) anfing, JavaScript zu lernen, hatte ich NotePad ++ und Firebug zum Debuggen. Schon damals war es notwendig, mit diesen Werkzeugen einige komplexe und schöne Dinge zu tun.
Ungefähr so fühle ich mich jetzt, wenn ich mit Infrastruktur arbeite. Aktuelle Tools werden nur gebildet, viele von ihnen wurden noch nicht veröffentlicht und haben Version 0.12 (hi, Terraform), und viele brechen regelmäßig die Abwärtskompatibilität mit früheren Versionen.
Für mich als Unternehmensentwickler ist es absurd, solche Dinge in der Produktion einzusetzen. Aber es gibt einfach keine anderen.
Lesen Sie die Dokumentation.Als Programmierer ging ich relativ selten zu den Docks. Ich kannte meine Werkzeuge sehr gut: meine Lieblingsprogrammiersprache, mein Lieblingsframework und meine Lieblingsdatenbank. Alle zusätzlichen Tools, z. B. Bibliotheken, sind normalerweise in derselben Sprache geschrieben, sodass Sie immer den Quellcode anzeigen können. Die IDE teilt Ihnen immer mit, welche Parameter wo benötigt werden. Selbst wenn ich einen Fehler mache, werde ich dies schnell verstehen, indem ich schnelle Tests durchführe.
Dies funktioniert in der Infrastruktur nicht. Es gibt eine Vielzahl unterschiedlicher Technologien, die Sie kennen müssen. Aber es ist unmöglich, alles tief zu wissen, und vieles wurde in unbekannten Sprachen geschrieben. Lesen (und schreiben) Sie daher die Dokumentation sorgfältig - ohne diese Angewohnheit leben sie hier nicht lange.
Kommentare zum Infrastrukturcode sind unvermeidlich.In der Entwicklungswelt sind Kommentare ein Zeichen für schlechten Code. Sie werden schnell veraltet und beginnen zu lügen. Dies ist ein Zeichen dafür, dass der Entwickler seine Gedanken nicht anders ausdrücken konnte. Bei der Arbeit mit der Infrastruktur sind Kommentare auch ein Zeichen für schlechten Code, auf den Sie jedoch nicht verzichten können. Für verstreute Instrumente, die lose miteinander verwandt sind und nichts voneinander wissen, sind Kommentare unabdingbar.
Oft sind die üblichen Konfigurationen und DSL unter dem Code versteckt. In diesem Fall findet die gesamte Logik an einem tieferen Ort statt, an dem kein Zugriff besteht. Dies ändert die Herangehensweise an Code, das Testen und Arbeiten damit erheblich.
Haben Sie keine Angst, Entwickler in die Infrastruktur zu lassen.Sie können nützliche (und frische) Praktiken und Ansätze aus der Welt der Softwareentwicklung einbringen. Nutzen Sie die im Buch über SRE beschriebenen Praktiken und Ansätze von Google, profitieren Sie und seien Sie glücklich.
PS: , , , .
PPS: DevOpsConf 2019 . , , : , , DevOps-, .
PPPS: , DevOps-, DevOps Live 2020. : , - . , DevOps-. — « » .
, DevOps Live , , CTO, .