Früher war ich Teamleiter und leitete einige Kritikerdienste. Und wenn etwas schief ging, wurden echte Geschäftsprozesse gestoppt. Beispielsweise wurden Bestellungen im Lager nicht mehr zusammengebaut.
Ich bin kürzlich Führungskraft geworden und bin jetzt für drei Teams anstatt für eines verantwortlich. Jeder von ihnen betreibt ein IT-System. Ich möchte verstehen, was in jedem System passiert und was kaputt gehen kann.
In diesem Artikel werde ich darüber sprechen
- was wir überwachen
- wie wir überwachen
- und vor allem: Was machen wir mit den Ergebnissen dieser Beobachtungen?

Lamoda hat viele Systeme. Sie werden alle freigelassen, etwas ändert sich in ihnen, etwas passiert mit Technologie. Und ich möchte zumindest die Illusion haben, dass wir den Zusammenbruch leicht lokalisieren können. Ich werde ständig mit Warnungen bombardiert, die ich herauszufinden versuche. Um von Abstraktionen wegzukommen und zu Einzelheiten überzugehen, werde ich Ihnen das erste Beispiel nennen.
Von Zeit zu Zeit explodiert etwas: Chroniken eines Feuers
An einem warmen Sommermorgen ohne Kriegserklärung, wie es normalerweise der Fall ist, hat die Überwachung für uns funktioniert. Als Warnung verwenden wir Icinga. Alert sagte, dass wir noch 50 GB Festplatte auf dem DBMS-Server haben. Höchstwahrscheinlich sind 50 Gigabyte ein Tropfen auf den heißen Stein und werden sehr schnell enden. Wir haben uns entschlossen, genau zu sehen, wie viel freier Speicherplatz noch vorhanden ist. Sie müssen verstehen, dass es sich nicht um virtuelle Maschinen handelt, sondern um Eisenserver, und die Basis ist stark ausgelastet. Es gibt eine 1,5-Terabyte-SSD. Bald wird diese Erinnerung ein Ende haben: Sie wird 20 bis 30 Tage dauern. Dies ist sehr wenig, Sie müssen das Problem schnell lösen.
Dann haben wir zusätzlich überprüft, wie viel Speicher in 1-2 Tagen tatsächlich verbraucht wurde. Es stellt sich heraus, dass 50 Gigabyte für etwa 5-7 Tage ausreichen. Danach wird der Dienst, der mit dieser Datenbank arbeitet, voraussichtlich beendet. Wir beginnen über die Konsequenzen nachzudenken: Wir archivieren dringend, welche Daten wir löschen werden. Die Datenanalyse-Abteilung verfügt über alle Backups, sodass Sie alles, was älter als 2015 ist, sicher löschen können.
Wir versuchen es zu löschen und denken daran, dass MySQL nach einem halben Kick nicht mehr so funktioniert. Gelöschte Daten sind großartig, aber die Größe der für die Tabelle und die Datenbank zugewiesenen Datei ändert sich nicht. MySQL verwendet dann diesen Raum. Das heißt, das Problem wurde nicht gelöst, es ist kein Platz mehr vorhanden.
Wir versuchen einen anderen Ansatz: Migration von Labels von schnell endenden SSDs zu langsameren. Wählen Sie dazu die Tabletten aus, die viel wiegen, aber unter geringer Last stehen, und verwenden Sie die Percona-Überwachung. Wir haben die Tabellen verschoben und denken bereits darüber nach, die Server selbst zu verschieben. Nach dem zweiten Umzug belegen die Server nicht 1,5, sondern 4 Terabyte SSD.
Wir haben dieses Feuer gelöscht: Wir haben einen Umzug organisiert und natürlich die Überwachung repariert. Jetzt wird die Warnung nicht bei 50 Gigabyte, sondern bei einem halben Terabyte ausgelöst, und der kritische Überwachungswert wird bei 50 Gigabyte ausgelöst. In Wirklichkeit ist dies jedoch nur eine Decke, die das Heck bedeckt. Es wird eine Weile dauern. Aber wenn wir eine Wiederholung der Situation zulassen, ohne die Basis in Teile zu zerbrechen und nicht an Scherben zu denken, wird alles schlecht enden.
Angenommen, wir haben den Server weiter geändert. Irgendwann musste der Master neu gestartet werden. Wahrscheinlich treten in diesem Fall Fehler auf. In unserem Fall betrug die Ausfallzeit etwa 30 Sekunden. Aber es kommen Anfragen, es gibt keinen Ort zum Schreiben, Fehler sind eingegangen, die Überwachung hat funktioniert. Wir verwenden das Prometheus-Überwachungssystem - und wir sehen darin, dass die Metrik von 500 Fehlern oder die Anzahl der Fehler beim Erstellen eines Auftrags gesprungen ist. Aber wir kennen die Details nicht: Welche Art von Bestellung wurde nicht erstellt und so weiter.
Weiter werde ich Ihnen sagen, wie wir mit der Überwachung arbeiten, um nicht in solche Situationen zu geraten.
Überprüfung der Überwachung und klare Beschreibung des Support-Service
Wir haben mehrere Bereiche und Indikatoren, die wir beobachten. Überall im Büro gibt es Fernseher, auf denen sich viele verschiedene technische und geschäftliche Labels befinden, die zusätzlich zu den Entwicklern von einem Support-Service überwacht werden.
In diesem Artikel spreche ich darüber, wie wir es haben und füge hinzu, was wir erreichen wollen. Dies gilt auch für die Überwachung von Überprüfungen. Wenn wir regelmäßig eine Bestandsaufnahme unseres "Eigentums" machen würden, könnten wir alles, was veraltet ist, aktualisieren und reparieren, um eine Wiederholung des Fakap zu verhindern. Dazu benötigen Sie eine übersichtliche Liste.
Wir haben Konfigurationen mit Warnungen im Repository, wo es jetzt 4678 Zeilen gibt. Aus dieser Liste ist schwer zu verstehen, wovon jede spezifische Überwachung spricht. Angenommen, unsere Metrik heißt db_disc_space_left. Der Support-Service wird nicht sofort verstehen, worum es geht. Etwas über freien Speicherplatz, großartig.
Wir wollen tiefer graben. Wir schauen uns die Konfiguration dieser Überwachung an und verstehen, woher sie kommt.
pm_host: "{{ prometheus_server }}"
pm_query: ”mysql_ssd_space_left"
pm_warning: 50
pm_critical: 10 pm_nanok: 1
Diese Metrik hat einen Namen und eigene Einschränkungen. Wenn Sie die Warnüberwachung aktivieren möchten, wird eine Warnung angezeigt, um eine kritische Situation zu melden. Wir verwenden eine metrische Namenskonvention. Am Anfang jeder Metrik steht der Name des Systems. Dadurch wird der Verantwortungsbereich klar. Wenn die für das System verantwortliche Person die Metrik startet, ist sofort klar, an wen sie sich wenden soll.
Warnungen fließen in ein Telegramm oder eine Lücke. Der Support-Service reagiert zunächst rund um die Uhr auf sie. Die Jungs beobachten, was speziell explodiert ist, ist das eine normale Situation. Sie haben Anweisungen:
- diejenigen, die ersetzt werden,
- und Anweisungen, die fortlaufend im Zusammenfluss festgelegt werden. Unter dem Namen der Explosionsüberwachung können Sie herausfinden, was es bedeutet. Für die kritischsten wird beschrieben, was kaputt ist, was die Konsequenzen sind, wer angesprochen werden muss.
Wir haben auch Schichtschichten in Teams, die für Schlüsselsysteme verantwortlich sind. Jedes Team hat jemanden, der immer verfügbar ist. Wenn etwas passiert, holen sie ihn ab.
Wenn die Warnung ausgelöst wird, muss das Support-Team schnell alle wichtigen Informationen herausfinden. Es wäre schön, wenn der Fehlermeldung ein Link zur Überwachungsbeschreibung beigefügt wäre. Zum Beispiel, damit es solche Informationen gibt:
- eine Beschreibung dieser Überwachung in verständlichen, relativ einfachen Begriffen;
- die Adresse, an der es sich befindet;
- eine Erklärung, was diese Metrik ist;
- Konsequenzen: Wie wird es enden, wenn wir den Fehler nicht korrigieren?
- , , . , , . -, .
Es wäre auch praktisch, die Verkehrsdynamik sofort in der Prometheus-Oberfläche zu sehen.
Ich möchte solche Beschreibungen für jede Überwachung machen. Sie helfen dabei, eine Überprüfung zu erstellen und Anpassungen vorzunehmen. Wir führen diese Praxis ein: In der Vereisungskonfiguration gibt es bereits einen Link zum Zusammenfluss mit diesen Informationen. Ich arbeite seit fast 4 Jahren an einem System, es gibt grundsätzlich keine solchen Beschreibungen dafür. Deshalb sammle ich jetzt gemeinsam Wissen. Beschreibungen lösen auch das Problem der Teamunwissenheit.
Wir haben Anweisungen für die meisten Warnungen, in denen geschrieben ist, was zu bestimmten geschäftlichen Auswirkungen führt. Deshalb müssen wir die Situation schnell verstehen. Die Schwere möglicher Vorfälle wird vom Support-Service zusammen mit dem Unternehmen festgelegt.
Ich werde ein Beispiel geben: Wenn die Überwachung des Speicherverbrauchs auf dem RabbitMQ-Server des Auftragsverarbeitungsdienstes ausgelöst wird, bedeutet dies, dass der Warteschlangendienst in wenigen Stunden oder sogar Minuten abstürzen kann. Dies wiederum wird viele Geschäftsprozesse stoppen. Infolgedessen warten Kunden erfolglos auf Bestellungen, SMS- / Push-Benachrichtigungen, Statusänderungen und vieles mehr.
Diskussionen über die Überwachung mit Unternehmen finden häufig nach schwerwiegenden Vorfällen statt. Wenn etwas kaputt geht, sammeln wir eine Provision mit Vertretern der Richtung, die von unserer Freilassung oder unserem Vorfall betroffen war. Während des Meetings analysieren wir die Ursachen des Vorfalls, wie wir sicherstellen können, dass es nie wieder passiert, welchen Schaden wir erlitten haben, wie viel Geld wir verloren haben und wofür.
Es kommt vor, dass Sie ein Unternehmen verbinden müssen, um Probleme zu lösen, die für Kunden entstehen. Dort diskutieren wir proaktive Maßnahmen: Welche Art von Überwachung soll gestartet werden, damit dies nicht noch einmal passiert.
Der Support-Service überwacht die Werte der Metriken mithilfe eines Telegramm-Bots. Wenn eine neue Überwachung hinzukommt, benötigt der Supportmitarbeiter ein einfaches Tool, um herauszufinden, wo die Aufschlüsselung liegt und was dagegen zu tun ist. Der Link zur Beschreibung in der Warnung löst dieses Problem.
Ich sehe die Fakap wie in der Realität: Sentry für die Nachbesprechung verwenden
Es reicht nicht aus, nur den Fehler herauszufinden, ich möchte die Details sehen. Unser Standardanwendungsfall lautet wie folgt: Einführung der Freigabe und Empfang von Warnungen vom K8S-Stack. Dank der Überwachung sehen wir uns den Status der Pods an: Welche Versionen der Anwendung eingeführt wurden, wie die Bereitstellung endete, ist alles gut.
Dann schauen wir uns das RMM an, das wir mit der Basis und der Last darauf haben. Für Grafana und Boards betrachten wir die Anzahl der Verbindungen zu Rabbit. Er ist cool, aber er weiß, wie man fließt, wenn der Speicher leer ist. Wir überwachen diese Dinge und überprüfen dann den Wachposten. Sie können online verfolgen, wie sich das nächste Debakel mit allen Details entwickelt. In diesem Fall meldet die Überwachung nach der Veröffentlichung, was und wie kaputt gegangen ist.
In PHP-Projekten verwenden wir einen Raven-Client und bereichern ihn zusätzlich mit Daten. Sentry fasst alles gut zusammen. Und wir sehen die Dynamik für jeden Fakap, wie oft es passiert. Und wir sehen uns auch Beispiele an, welche Anfragen nicht erfolgreich waren, welche Erweiterungen herauskamen.
So sieht es ungefähr aus. Ich sehe, dass es bei der nächsten Veröffentlichung von Fehlern deutlich mehr als üblich gab. Wir werden prüfen, was speziell kaputt gegangen ist. Und dann, falls erforderlich, erhalten wir die fehlgeschlagenen Bestellungen entsprechend dem Kontext und beheben sie.
Wir haben eine coole Sache - Bindung an Jira. Dies ist ein Ticket-Tracker: Ich habe einen Knopf gedrückt und Jira hat eine Fehleraufgabe mit einem Link zu Sentry und einer Stapelverfolgung dieses Fehlers erstellt. Die Aufgabe ist mit bestimmten Beschriftungen gekennzeichnet.
Einer der Entwickler brachte eine vernünftige Initiative ein - "Clean Project, Clean Sentry". Während der Planung werfen wir jedes Mal, wenn wir mindestens 1-2 Aufgaben aus Sentry erstellen, in den Sprint. Wenn ständig etwas im System kaputt ist, wird Sentry mit Millionen kleiner alberner Fehler überschwemmt. Wir reinigen sie regelmäßig, damit wir die wirklich ernsten nicht versehentlich verpassen.
Blazes aus irgendeinem Grund: Wir werden die Überwachung los, bei der jeder verstopft
- Sich an Fehler gewöhnen
Wenn etwas ständig blinkt und kaputt aussieht, entsteht das Gefühl einer falschen Norm. Der Support-Service kann sich irren, wenn er denkt, dass die Situation angemessen ist. Und wenn etwas Ernstes kaputt geht, werden sie es ignorieren. Wie in einer Fabel über einen Jungen, der schreit: "Wölfe, Wölfe!".
Der klassische Fall ist unser Projekt, das für die Auftragsabwicklung verantwortlich ist. Es arbeitet mit dem Lagerautomatisierungssystem und überträgt dort Daten. Dieses System wird normalerweise um 7 Uhr morgens freigegeben. Danach beginnen wir mit der Überwachung. Jeder ist daran gewöhnt und punktet, was nicht sehr gut ist. Es wäre ratsam, diese Steuerelemente zu optimieren. Um beispielsweise die Freigabe eines bestimmten Systems und einige Warnungen über Prometheus zu verknüpfen, schneiden Sie den zusätzlichen Alarm einfach nicht ab.
- Bei der Überwachung werden keine Geschäftsmetriken berücksichtigt
Das Auftragsabwicklungssystem überträgt die Daten an das Lager. Wir haben diesem System eine Überwachung hinzugefügt. Keiner von ihnen hat geschossen, und es scheint, dass alles in Ordnung ist. Der Zähler zeigt an, dass die Daten verlassen werden. Dieser Fall verwendet Seife. Tatsächlich kann der Zähler so aussehen: Der grüne Teil sind die eingehenden Vermittlungsstellen, die gelben die ausgehenden.
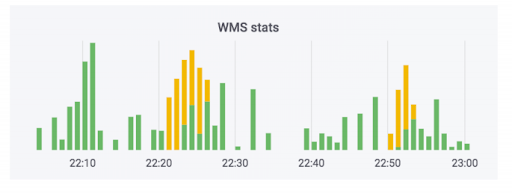
Wir hatten einen Fall, in dem die Daten wirklich zufrieden waren, aber die Kurven. Bestellungen wurden nicht bezahlt, aber als bezahlt markiert. Das heißt, der Käufer kann sie kostenlos abholen. Es scheint beängstigend zu sein. Das Gegenteil macht jedoch mehr Spaß: Eine Person holt eine bezahlte Bestellung ab und wird aufgrund eines Fehlers im System aufgefordert, erneut zu zahlen.
Um diese Situation zu vermeiden, überwachen wir nicht nur die Technologie, sondern auch die Geschäftsmetriken. Wir haben eine spezielle Überwachung, die die Anzahl der Bestellungen überwacht, die nach Erhalt bezahlt werden müssen. Alle ernsthaften Sprünge in dieser Metrik zeigen, ob etwas schief gelaufen ist.
Die Überwachung von Geschäftsindikatoren liegt auf der Hand, wird jedoch häufig vergessen, wenn neue Dienste, einschließlich uns, veröffentlicht werden. Jeder verschmiert neue Dienste mit rein technischen Metriken in Bezug auf Festplatten, Prozent, was auch immer. Als Online-Shop haben wir eine wichtige Sache - die Anzahl der erstellten Bestellungen. Wir wissen, wie viele Leute normalerweise für Marketingkampagnen bereinigt kaufen. Daher folgen wir bei Releases diesem Indikator.
Ein weiterer wichtiger Punkt: Wenn ein Kunde wiederholt Lieferungen an dieselbe Adresse bestellt, quälen wir ihn nicht durch die Kommunikation mit dem Callcenter, sondern bestätigen die Bestellung automatisch. Ein Ausfall des Systems wirkt sich stark auf das Kundenerlebnis aus. Wir folgen auch dieser Metrik, da Releases von verschiedenen Systemen sie stark beeinflussen können.
Wir beobachten die reale Welt: Wir kümmern uns um einen gesunden Sprint und unsere Leistung
Damit das Unternehmen die verschiedenen Indikatoren im Auge behalten kann, haben wir ein kleines Echtzeit-Dashboard-System aufgeschrieben. Anfangs wurde es für einen anderen Zweck gemacht. Das Unternehmen hat einen Plan für die Anzahl der Bestellungen, die wir an einem bestimmten Tag des kommenden Monats verkaufen möchten. Dieses System zeigt die Übereinstimmung der Pläne mit dem, was tatsächlich getan wurde. Für die Grafik nimmt sie Daten aus der Produktionsdatenbank und liest sie von dort im laufenden Betrieb.
Einmal fiel unser Nachbau auseinander. Es gab keine Überwachung, daher hatten wir keine Zeit, uns darüber zu informieren. Das Unternehmen stellte jedoch fest, dass wir den Plan für 10 konventionelle Auftragseinheiten nicht erfüllten, und kam mit Kommentaren. Wir begannen die Gründe zu verstehen. Es stellte sich heraus, dass irrelevante Daten aus dem defekten Replikat gelesen wurden. Dies ist ein Fall, in dem ein Unternehmen interessante Indikatoren beobachtet und wir uns gegenseitig helfen, wenn Probleme auftreten.
Ich erzähle Ihnen von einer weiteren Überwachung der realen Welt, die sich seit langem in der Entwicklung befindet und von jedem Team ständig optimiert wird. Wir haben Jira Viewer - damit können Sie den Entwicklungsprozess verfolgen. Das System ist äußerst einfach: Das Symfony PHP-Framework, das in Jira Api ausgeführt wird und Daten zu Aufgaben, Sprints usw. abruft, je nachdem, was für die Eingabe angegeben wurde. Jira Viewer schreibt regelmäßig Metriken zu Teams und ihren Projekten an Prometeus. Dort werden sie überwacht, alarmiert und von dort in Grafana angezeigt. Dank dieses Systems verfolgen wir Work in Progress.
- Wir überwachen, wie lange eine Aufgabe vom laufenden Moment bis zur Einführung in der Produktion in Arbeit war. Wenn die Anzahl zu groß ist, weist dies theoretisch auf ein Problem mit den Prozessen, dem Team, der Aufgabenbeschreibung usw. hin. Die Lebensdauer von Aufgaben ist eine wichtige Messgröße, die jedoch allein nicht ausreicht.
- . , , . , .
- – ready for release, . - - , « ».
- : , . .
- . 400 150. , , .
- Ich habe in meinem Team die Anzahl der Pull-Anfragen von Entwicklern außerhalb der Arbeitszeit überwacht. Besonders nach 20 Uhr. Und wenn die Metrik schießt, ist dies ein alarmierendes Zeichen: Eine Person hat entweder keine Zeit für etwas oder gibt sich zu viel Mühe und brennt früher oder später einfach aus.
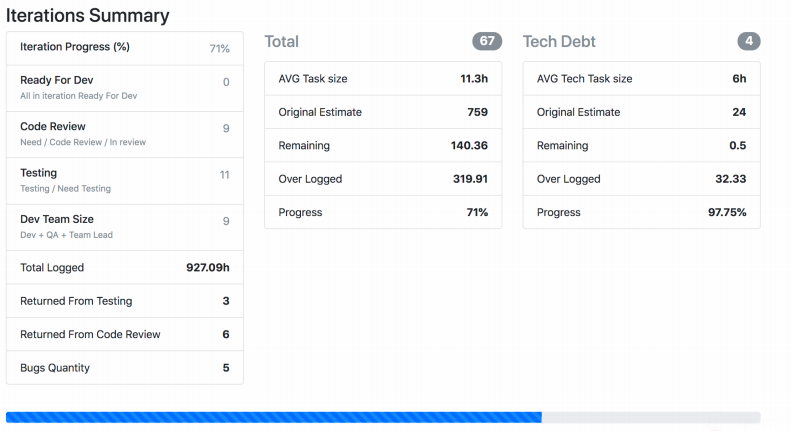
Der Screenshot zeigt, wie Jira Viewer Daten anzeigt. Auf dieser Seite finden Sie eine Zusammenfassung des Status der Aufgaben aus dem Sprint, wie viel jeder wiegt und dergleichen. Solche Dinge sammeln sich auch und fliegen zu Prometheus.
Nicht nur technische Kennzahlen: Was wir bereits überwachen, was wir überwachen können und warum dies alles notwendig ist
Um alles zusammenzufassen, schlage ich vor, sowohl Technologie als auch Metriken in Bezug auf Prozesse, Entwicklung und Geschäft zusammen zu überwachen. Technische Kennzahlen allein reichen nicht aus.
- , -, Grafana-. . , , .
- : , . , , crontab supervisor. . , , .
- – , , .
- : , - , . , .
- , . – Sentry . - , . - , . Sentry , , .
- . , , .
- , . , - , - . .