Tipps zum Trennen von Ablenkungen von nützlichen Informationen

Wenn Sie einen Einführungskurs in Statistik belegen, werden Sie feststellen, dass Daten verwendet werden können, um Inspiration oder Testtheorie zu finden, jedoch niemals für beide. Warum so?
Die Leute sind zu gut darin, Muster in allem zu finden. Sie bestimmen selbst, welche Muster tatsächlich existieren und welche erfunden werden. Wir sind Kreaturen, die Elvis 'Gesicht in einem Kartoffelchip finden. Wenn Sie versucht sind, Muster mit Konzepten gleichzusetzen, denken Sie daran, dass es drei Arten von Mustern gibt:
- Muster, die sowohl in Ihrem Datensatz als auch darüber hinaus vorhanden sind.
- Muster, die nur in Ihrem Datensatz vorhanden sind.
- Muster, die nur in Ihrer Vorstellung existieren (Apophenie).
Datenmuster können (1) in der gesamten interessierenden Population, (2) nur in einer Stichprobe oder (3) nur in Ihrem Kopf existieren.
Welche Muster und Datenmuster können für Sie nützlich sein? Es hängt von Ihren Zielen ab.
Inspiration
Wenn Sie reine Inspiration benötigen, können Daten Wunder wirken. Selbst Apophenie (die menschliche Tendenz, Zusammenhänge und Bedeutungen zwischen nicht verwandten Dingen fälschlicherweise wahrzunehmen) kann Ihre Kreativität in vollen Zügen nutzen. Kreativität hat keine richtigen Antworten. Sie müssen sich also nur Ihre Daten ansehen und damit spielen. Versuchen Sie als zusätzlichen Bonus, nicht zu viel Zeit zu verschwenden (von Ihnen oder den Betroffenen).
Fakten
Wenn Ihre Regierung Steuern von Ihnen erheben möchte, kann sie die Werte nicht ignorieren, die über Ihre Finanzdaten für das Jahr hinausgehen. Das IRS muss eine sachliche Entscheidung darüber treffen, wie viel Sie schulden, und der Hauptweg, um diese Entscheidung zu treffen, ist die Analyse der Daten des vergangenen Jahres. Mit anderen Worten, schauen Sie sich die Daten an und wenden Sie die Formel an. In diesem Fall handelt es sich um eine rein deskriptive Analyse, die an verfügbare Daten gebunden ist. Jede der ersten beiden Arten von Mustern ist dafür gut.
Beschreibende Analyse, die an vorhandene Daten gebunden ist.
(Ich habe meine Abschlüsse nie versteckt, aber ich denke, die Regierung der Vereinigten Staaten wäre nicht begeistert, wenn ich die Datenberechnungsmethoden, die ich in der Graduiertenschule gelernt habe, verwenden würde, um Steuern statistisch zu zahlen, um sie zu ersetzen.)
Entscheidungen angesichts der Unsicherheit
Manchmal stimmen die verfügbaren Fakten nicht mit den gewünschten überein. Wenn Sie nicht über alle Informationen verfügen, die Sie für eine Entscheidung benötigen, müssen Sie die Unsicherheit überwinden und versuchen, eine angemessene Vorgehensweise zu wählen.
Genau das sind Statistiken - die Wissenschaft, wie Sie Ihre Meinung angesichts von Unsicherheit ändern können. Das Spiel besteht darin, wie Ikarus ins Unbekannte zu springen ... und gleichzeitig nicht in Stücke zu schlagen.
Dies ist die größte Herausforderung der Datenwissenschaft: Wie kann man als Ergebnis der Datenwissenschaft nicht * unwissend * sein?
Bevor Sie von dieser Klippe springen, ist es besser zu hoffen, dass die Muster, die Sie in Ihrer eingeschränkten Sicht auf die Realität gefunden haben, tatsächlich außerhalb Ihrer Sicht funktionieren. Mit anderen Worten, Vorlagen müssen verallgemeinert werden, um für Sie nützlich zu sein.

Von den drei Arten von Mustern ist nur das erste (verallgemeinerte) sicher, wenn Entscheidungen angesichts von Unsicherheit getroffen werden. Leider finden Sie in Ihren Daten andere Arten von Mustern - dies ist das große Problem im Herzen der Datenwissenschaft: Wie Sie Ihr Bewusstsein durch die Datenexploration nicht verlieren können.
Verallgemeinerung
Wenn Sie der Meinung sind, dass das Auffinden nutzloser Muster in Daten ein rein menschliches Privileg ist, denken Sie noch einmal darüber nach! Wenn Sie nicht aufpassen, können Maschinen das Gleiche automatisch tun.
Der Sinn des maschinellen Lernens und der KI besteht darin, neue Situationen richtig zu verallgemeinern.
Maschinelles Lernen ist ein Ansatz, um viele ähnliche Entscheidungen zu treffen. Dazu gehört eine algorithmische Suche nach Mustern in Ihren Daten und deren Verwendung, um auf völlig neue Daten korrekt zu reagieren. Im Jargon des maschinellen Lernens und der KI bezieht sich Verallgemeinerung auf die Fähigkeit Ihres Modells, gut mit Daten zu arbeiten, die es noch nicht gesehen hat. Was bringt ein vorlagenbasiertes Modell, das nur mit alten Daten gut funktioniert? Dazu können Sie einfach die Nachschlagetabelle verwenden. Der Sinn des maschinellen Lernens und der KI besteht darin, in neuen Situationen die richtigen Verallgemeinerungen korrekt vorzunehmen.

Aus diesem Grund ist die erste Art von Mustern auf unserer Liste die einzige, die für maschinelles Lernen gut geeignet ist. Diese Art von Daten ist ein Signal, alles andere ist nur Rauschen (Faktoren, die nur in Ihren alten Daten vorhanden sind und die Erstellung eines verallgemeinerbaren Modells beeinträchtigen).
Signal: Muster, die sowohl in Ihrem Datensatz als auch darüber hinaus vorhanden sind.
Rauschen: Muster, die nur in Ihrem Datensatz vorhanden sind.
Tatsächlich wird eine Lösung, die alte Geräusche anstelle neuer Daten verarbeitet, als Überanpassung beim maschinellen Lernen bezeichnet (wir sprechen diesen Begriff in demselben Ton aus, in dem Sie Ihr Lieblingsfluchwort aussprechen). Beim maschinellen Lernen wird fast alles getan, um eine Überanpassung zu vermeiden.
Also, auf welche Art von * dieser * Probe bezieht sich?
Angenommen, das Muster, das Sie (oder Ihr Computer) aus Ihren Daten extrahiert haben, existiert jenseits Ihrer Vorstellungskraft - zu welcher Kategorie gehört es? Handelt es sich um ein reales Phänomen, das in Ihrer Gesamtheit von Interesse ist (Signal), oder ist es ein Merkmal Ihres Datensatzes (Rauschen)? Wie bestimmen Sie die Art des Musters, das beim Arbeiten mit Daten gefunden wird?
Wenn Sie alle verfügbaren Daten studieren, können Sie dies nicht tun. Sie sind ratlos und können nicht feststellen, ob Ihre Vorlage an anderer Stelle vorhanden ist. Jede Rhetorik über das Testen statistischer Hypothesen hängt vom Unerwarteten ab, und vorzutäuschen, dass das bereits bekannte Muster Sie überrascht, ist ein schlechter Geschmack (tatsächlich ist dies Hacking).

Es ist, als würde man eine kaninchenförmige Wolke sehen und dann prüfen, ob alle Wolken wie Kaninchen aussehen ... und dieselbe Wolke betrachten. Ich hoffe du verstehst, dass du neue Wolken brauchst, um deine Theorie zu testen.
Daten, die zur Formulierung einer Theorie oder einer Frage verwendet werden, können nicht zur Überprüfung derselben Theorie verwendet werden.
Was würden Sie tun, wenn Sie wüssten, dass Sie nur Zugriff auf eine Cloud haben? Im Schrank meditiert, das ist was. Stellen Sie Ihre Frage, bevor Sie sich die Daten ansehen.
Mathematik widerspricht niemals dem gesunden Menschenverstand.
Hier kommen wir zu dem traurigsten Schluss. Wenn Sie Ihren Datensatz auf der Suche nach Inspiration verwenden, können Sie ihn nicht erneut verwenden, um die von ihm inspirierte Theorie gründlich zu testen (unabhängig davon, welche Tricks des mathematischen Jujitsu Sie verwenden - Mathematik widerspricht niemals dem gesunden Menschenverstand).
Schwere Entscheidung
Der Punkt ist, dass Sie eine Wahl treffen müssen! Wenn Sie nur einen Datensatz haben, müssen Sie sich fragen: „Ich meditiere im Schrank, formuliere meine Hypothesen für statistische Tests und gehe dann vorsichtig streng vor - alles, damit ich mich selbst ernst nehmen kann? Oder sammle ich nur Daten, um mich inspirieren zu lassen, und gleichzeitig verstehe ich, dass ich mich selbst täuschen kann und daran denke, dass ich Sätze wie „Ich fühle“ oder „Es inspiriert“ oder „Ich bin nicht sicher“ verwenden sollte. “ Schwere Entscheidung!
Oder gibt es eine Möglichkeit, ein Stück Kuchen zweimal zu essen? Das Problem ist, dass Sie nur einen Datensatz haben und mehr als einen Datensatz benötigen. Und wenn Sie genug Daten haben, dann habe ich einen Trick, der. Wird explodieren. Ihre. Gehirn.

Tricky Trick
Um in der Datenwissenschaft erfolgreich zu sein, verwandeln Sie einfach einen Datensatz (mindestens) in zwei, indem Sie Ihre Daten teilen. Verwenden Sie dann eine als Inspiration und die andere für strenge Tests. Wenn das Muster, das Sie ursprünglich inspiriert hat, in den Daten vorhanden ist, die Ihre Meinung nicht beeinflussen konnten, ist es wahrscheinlich, dass dieses Muster eine allgemeine Regel ist, die in der Katzenablage angewendet wird, aus der Sie Ihre Daten entnehmen.
Wenn in beiden Datensätzen dasselbe Phänomen auftritt, ist dies möglicherweise eine allgemeine Regel, die für alle Quellen dieses Datensatzes gilt.
RSChD!
Da Leben ohne Forschung überhaupt kein Leben ist, sind hier vier Wörter, die es wert sind, gelebt zu werden: Teilen Sie Ihre verdammten Daten .
Die Welt wäre besser, wenn alle ihre Daten teilen würden. Wir hätten bessere Antworten (dank Statistiken) und bessere Fragen (dank Analysen). Der einzige Grund, warum Menschen den Datenaustausch nicht als obligatorische Gewohnheit ansehen, ist, dass es im letzten Jahrhundert ein Luxus war, den sich nur sehr wenige Menschen leisten konnten. Die Datensätze waren so klein, dass beim Versuch, sie zu teilen, möglicherweise nichts mehr von ihnen übrig ist.
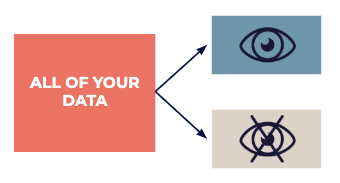
Teilen Sie Ihre Daten in einen Forschungsdatensatz auf, der allen zur Verfügung steht, der als Inspiration verwendet werden kann, und in einen Testdatensatz, der anschließend von Experten verwendet wird, um alle in der Forschungsphase gefundenen „Vermutungen“ genau zu bestätigen.
Einige Projekte sind immer noch mit diesem Problem konfrontiert, insbesondere in der medizinischen Forschung (ich war früher in den Neurowissenschaften tätig, daher habe ich großen Respekt vor der Komplexität der Arbeit mit kleinen Datensätzen), aber viele von Ihnen haben so viele Daten, dass Sie Ingenieure einstellen müssen. nur um dafür zu sorgen, dass sie bewegt werden ... was ist deine Entschuldigung ?! Sparen Sie nicht, teilen Sie Ihre Daten.
Wenn Sie nicht die Gewohnheit haben, Daten auszutauschen, stecken Sie möglicherweise im 20. Jahrhundert fest.
Wenn Sie viele Daten haben und deren Mengen nicht geteilt sind, existieren Sie in einem veralteten Paradigma. Menschen, die in diesem Paradigma existieren, haben sich mit archaischem Denken abgefunden und sich geweigert, sich rechtzeitig weiterzuentwickeln.
Maschinelles Lernen ist ein Nachkomme des Datenaustauschs
Am Ende ist die Idee einfach. Verwenden Sie einen Datensatz, um eine Theorie zu erstellen, diesen Datensatz herauszufinden und dann die Magie auszuführen - beweisen Sie Ihre Ideen an einem ganz neuen Datensatz.
Der Datenaustausch ist die einfachste und schnellste Lösung für eine gesündere Datenkultur.
Auf diese Weise können Sie sicher statistische Methoden anwenden und sich gegen Überanpassung versichern. Tatsächlich ist die Geschichte des maschinellen Lernens die Geschichte des Datenaustauschs.
Wie man die beste Idee in der Datenwissenschaft verwendet
Um die beste Idee in der Datenwissenschaft zu nutzen, müssen Sie lediglich sicherstellen, dass die Testdaten außerhalb der Reichweite neugieriger Blicke liegen, und dann Ihre Analysten über alles andere verrückt machen.
Um in der Datenwissenschaft erfolgreich zu sein, verwandeln Sie einfach einen Datensatz in (mindestens) zwei, indem Sie Ihre Daten aufteilen.
Wenn Sie der Meinung sind, dass sie Ihnen nützliche Informationen über das Gelernte hinaus gebracht haben, verwenden Sie Ihren geheimen Vorrat an Testdaten, um Ihre Ergebnisse zu testen.

In den kostenpflichtigen Online-Kursen von SkillFactory erfahren Sie, wie Sie einen hochkarätigen Beruf von Grund auf neu aufbauen oder Ihre Fähigkeiten und Ihr Gehalt verbessern können:
- Kurs für maschinelles Lernen (12 Wochen)
- Data Science von Grund auf lernen (12 Monate)
- (9 )
- «Python -» (9 )