
Rückblickend kann ich sagen, dass alle Platzierungsaktionen seitdem erzwungene Bewegungen sind. Und erst jetzt, im fünfzehnten Jahr, können wir die Infrastruktur nach Bedarf konfigurieren.
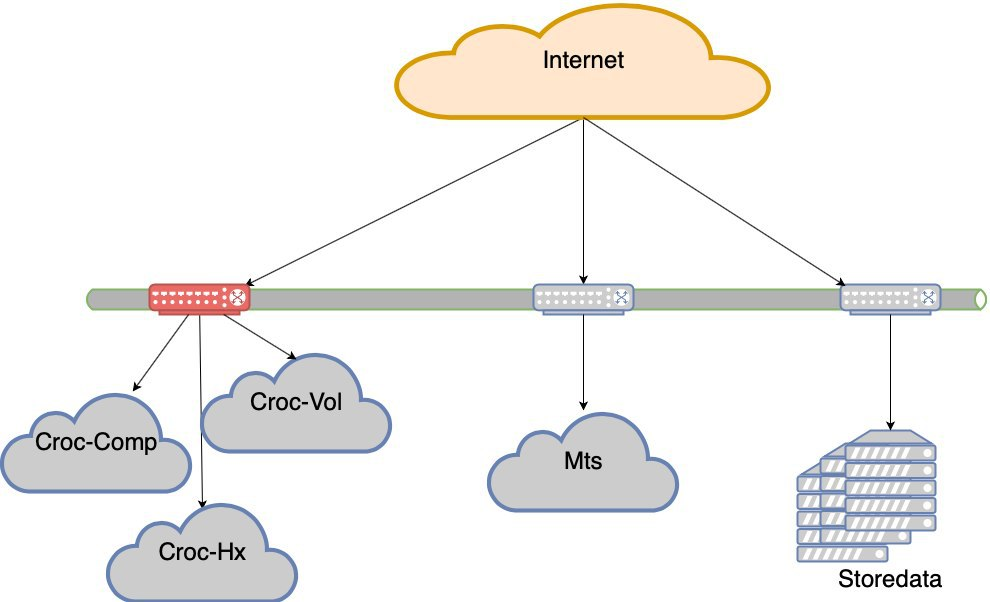
Jetzt stehen wir in 4 physisch unterschiedlichen Rechenzentren, die durch einen Ring aus dunkler Optik verbunden sind, und platzieren dort 5 unabhängige Ressourcenpools. Und so kam es, dass, wenn ein Meteorit in eine der Überkreuzungen fällt, 3 dieser Pools sofort abfallen und die verbleibenden zwei die Last nicht ziehen. Also haben wir eine komplette Neuausrichtung begonnen, um die Dinge in Ordnung zu bringen.
Erstes Rechenzentrum
Anfangs gab es kein Rechenzentrum. Es gab einen alten Systemisten im Schlafsaal der Moskauer Staatsuniversität. Dann fast sofort - virtuelles Hosting von Masterhost (sie leben noch, Teufel). Der Website-Verkehr mit einem Zugfahrplan verdoppelte sich alle 4 Wochen. Sehr bald wechselten wir zu KVM-VPS. Dies geschah um 2005. Irgendwann stießen wir auf Verkehrsbeschränkungen, weil es dann notwendig war, ein Gleichgewicht zwischen eingehend und ausgehend zu halten. Wir hatten zwei Installationen und haben jede Nacht ein paar gewichtige Dateien von einer zur anderen übertragen, um die erforderlichen Proportionen beizubehalten.
Im März 2009 gab es nur VPS. Das ist gut so, wir haben uns entschieden, auf Colocation umzusteigen. Wir haben ein paar physische Eisenserver gekauft (einer davon ist der von der Wand, dessen Körper wir als Erinnerung speichern). Wir haben Fiord in das Rechenzentrum gestellt (und sie leben noch, Teufel). Warum? Da es nicht weit vom damaligen Büro entfernt war, empfahl mir ein Freund, und ich musste schnell aufstehen. Außerdem war es relativ günstig.
Die Lastverteilung zwischen den Servern war einfach: Jeder hatte ein Back-End, MySQL mit Master-Slave-Replikation, die Front befand sich am selben Ort wie das Replikat. Nun das ist fast keine Trennung nach Art der Last. Ziemlich bald begannen auch sie zu vermissen, kauften ein drittes.
Um den 1. Oktober 2009 herum haben wir festgestellt, dass es bereits mehr Server gibt, aber wir werden uns für das neue Jahr festlegen... Verkehrsprognosen zeigten, dass die mögliche Kapazität mit einer Marge abgeschnitten wird. Und wir haben uns auf die Datenbankleistung gestützt. Es waren anderthalb Monate Zeit, um sich auf das Verkehrswachstum vorzubereiten. Dies war die Zeit der ersten Optimierungen. Wir haben ein paar Server nur für die Datenbank gekauft. Sie konzentrierten sich auf schnelle Festplatten mit einer Rotationsgeschwindigkeit von 15 U / min (ich erinnere mich nicht an den genauen Grund, warum wir keine SSDs verwendeten, aber höchstwahrscheinlich hatten sie eine niedrige Grenze für die Anzahl der Schreibvorgänge und kosteten gleichzeitig so viel wie ein Flugzeug). Wir haben die Vorder- und Rückseite sowie die Basen aufgeteilt, die Einstellungen von Nginx und MySQL angepasst und die Größe geändert, um SQL-Abfragen zu optimieren. Überlebt.

Jetzt stehen wir in zwei Tier-III-Rechenzentren und in der Tier-II-Benutzeroberfläche (mit einem Rückschwung auf T3, aber ohne Zertifikate). Aber Fiord war noch nie ein T-II. Sie hatten Überlebensprobleme, es gab Situationen aus der Kategorie "Alle Stromkabel in einem Kollektor, und es gab ein Feuer, und der Generator fuhr drei Stunden lang." Im Allgemeinen haben wir beschlossen, umzuziehen.
Wählen Sie ein anderes Rechenzentrum, Caravan. Herausforderung: Wie können Server ohne Ausfallzeiten verschoben werden? Wir haben uns entschlossen, eine Weile in zwei Rechenzentren zu leben. Der Nutzen des Datenverkehrs innerhalb des Systems war zu dieser Zeit nicht so sehr wie jetzt, es war möglich, den VPN-Verkehr für einige Zeit (insbesondere außerhalb der Saison) zwischen Standorten zu lenken. Den Verkehr ausbalancieren. Wir haben den Anteil der Karawane schrittweise erhöht, nach einer Weile sind wir komplett dorthin gezogen. Und jetzt haben wir noch ein Rechenzentrum. Und wir brauchen zwei, das haben wir dank der Fehler bei Fiord bereits verstanden. Rückblickend kann ich sagen, dass TIER III auch kein Allheilmittel ist, die Überlebensfähigkeit wird 99,95 betragen, aber die Verfügbarkeit ist anders. Ein Rechenzentrum reicht also definitiv nicht für eine Verfügbarkeit von 99,95 und höher. Stordata wurde
als zweiter gewähltund es bestand bereits die Möglichkeit einer optischen Verbindung mit dem Caravan-Standort. Wir haben es geschafft, die erste Ader zu dehnen. Sobald sie anfingen, das neue Rechenzentrum zu laden, gab Caravan bekannt, dass sie ihren Hintern gefickt bekommen. Sie mussten das Gelände verlassen, weil das Gebäude abgerissen wird. Bereits. Überraschung! Es gibt einen neuen Standort, sie schlagen vor, alles zu löschen, Gestelle mit Ausrüstung mit Kränen anzuheben (damals hatten wir bereits 2,5 Eisengestelle), zu übersetzen, einzuschalten, und es wird funktionieren ... 4 Stunden für alles ... Märchen ... Ich schweige, dass wir sogar eine Stunde Ausfallzeit haben passte nicht, aber hier hätte sich die Geschichte mindestens einen Tag hingezogen. Und all dies wurde im Geiste serviert: "Alles ist weg, der Gips wird entfernt, der Kunde geht!" Der 29. September ist der erste Anruf, und am 10. Oktober wollten sie alles abholen und annehmen. In 3-5 Tagen mussten wir einen Umzugsplan entwickeln und in 3 StufenWenn Sie 1/3 der Ausrüstung gleichzeitig ausschalten und dabei den Service und die Betriebszeit erhalten, transportieren Sie die Autos nach Stordata. Infolgedessen waren es nur 15 Minuten in einem nicht der kritischsten Dienst.
Also blieb uns wieder ein Rechenzentrum.
In diesem Moment haben wir es satt, mit Servern unter dem Arm herumzuschleppen und Lader zu spielen. Außerdem haben wir es satt, mit der Hardware selbst im Rechenzentrum umzugehen. Sie begannen in Richtung der öffentlichen Wolken zu schauen.
2 bis 5 (fast) Rechenzentren
Begann nach Optionen mit Wolken zu suchen. Wir gingen zu Krok, probierten es aus, testeten es und einigten uns auf die Bedingungen. Wir sind in die Cloud gekommen, die sich im Compressor-Rechenzentrum befindet. Sie machten einen Ring aus dunkler Optik zwischen Stordata, Compressor und dem Büro. Überall gibt es einen Uplink und zwei Schultern der Optik. Durch das Zerhacken der Strahlen wird das Netzwerk nicht zerstört. Der Verlust einer Aufwärtsverbindung zerstört das Netzwerk nicht. Erhielt den LIR-Status, hat ein eigenes Subnetz, BGP-Ankündigungen, Netzwerkredundanz und Schönheit. Ich werde nicht beschreiben, wie sie aus Sicht des Netzwerks in die Cloud gelangt sind, aber es gab Nuancen.
Wir haben also 2 Rechenzentren.
Krok hat auch ein Rechenzentrum in Volochaevskaya, sie haben dort ihre Cloud erweitert und angeboten, einen Teil unserer Ressourcen dorthin zu übertragen. Aber ich erinnerte mich an die Geschichte der Karawane, die sich nach dem Abriss des Rechenzentrums tatsächlich nie wieder erholte, und wollte Cloud-Ressourcen von verschiedenen Anbietern beziehen, um das Risiko zu verringern, dass das Unternehmen nicht mehr existiert (das Land ist so beschaffen, dass ein solches Risiko nicht ignoriert werden kann). Daher wurde Volochaevskaya zu diesem Zeitpunkt nicht kontaktiert. Nun, der zweite Anbieter zaubert auch mit den Preisen. Denn wenn Sie flexibel abholen und abreisen können, haben Sie eine starke Verhandlungsmacht in Bezug auf die Preise.
Wir haben uns verschiedene Optionen angesehen, aber die Wahl fiel auf #CloudMTS. Dafür gab es mehrere Gründe: Die Cloud erwies sich in den Tests als gut, die Jungs wissen auch, wie man mit dem Netzwerk arbeitet (schließlich ein Telekommunikationsbetreiber), und eine sehr aggressive Marketingpolitik, um den Markt zu erobern, was zu interessanten Preisen führte.
Insgesamt 3 Rechenzentren.
Danach haben wir auch Volochaevskaya verbunden - wir brauchten zusätzliche Ressourcen, aber Compressor war schon etwas eng. Im Allgemeinen haben wir die Last zwischen den drei Wolken und unserer Ausrüstung im Stordat neu verteilt.
4 Rechenzentren. Und schon in Bezug auf die Überlebensfähigkeit ist T3 überall. Es scheint, dass nicht jeder Zertifikate hat, aber ich werde nicht sicher sagen.
MTS hatte eine Nuance. Nichts als MGTS konnte die letzte Meile dorthin gelangen. Gleichzeitig war es nicht möglich, die dunkle Optik von MGTS vollständig vom Rechenzentrum zum Rechenzentrum zu ziehen (lange Zeit ist es teuer, und wenn ich sie nicht verwechsle, bieten sie keinen solchen Service an). Ich musste es mit einer Verbindung machen und zwei Strahlen vom Rechenzentrum zu den nächstgelegenen Bohrlöchern ausgeben, wo sich unser Anbieter für dunkle Optik Mastertel befindet. Sie haben ein ausgedehntes Netzwerk an Optiken in der ganzen Stadt, und wenn überhaupt, schweißen sie einfach die gewünschte Route und geben Ihnen eine Ader. In der Zwischenzeit kam die FIFA-Weltmeisterschaft unerwartet wie Schnee im Winter in die Stadt, und der Zugang zu den Brunnen in Moskau wurde geschlossen. Wir haben darauf gewartet, dass dieses Wunder endet, und wir können unsere Verbindung herstellen. Es scheint notwendig zu sein, das MTS-Rechenzentrum mit der Optik in der Hand zu verlassen und zu pfeifen, um die gewünschte Luke zu erreichen und dort abzusenken. Bedingt. Sie machten dreieinhalb Monate. Genauer gesagt, der erste Strahl wurde ziemlich schnell gemacht,Anfang August (ich erinnere mich, dass die Weltmeisterschaft am 15. Juli endete). Aber ich musste an meiner zweiten Schulter basteln - die erste Option implizierte, dass wir die Kashirskoye-Autobahn graben mussten, für die wir sie für eine Woche blockieren mussten (es gab einen Tunnel im Wiederaufbau, in dem einige Kommunikationen lagen, wir mussten ausgraben). Zum Glück fanden sie eine Alternative: eine andere Route, dieselbe geounabhängige. Es stellte sich heraus, dass zwei Adern von diesem Rechenzentrum zu verschiedenen Punkten unserer Präsenz führten. Der Optikring hat sich in einen Ring mit Griff verwandelt.Es stellte sich heraus, dass zwei Adern von diesem Rechenzentrum zu verschiedenen Punkten unserer Präsenz führten. Der Optikring hat sich in einen Ring mit Griff verwandelt.Es stellte sich heraus, dass zwei Adern von diesem Rechenzentrum zu verschiedenen Punkten unserer Präsenz führten. Der Optikring hat sich in einen Ring mit Griff verwandelt.
Ich werde sagen, dass sie es uns trotzdem sagen. Zum Glück zu Beginn der Operation, als nicht viel übertragen wurde. In einem Brunnen brach ein Feuer aus, und während die Installateure in Schaum schworen, zog im zweiten Brunnen jemand einen Stecker heraus, um ihn anzusehen (es war irgendwie ein neues Design, frage ich mich). Mathematisch war die Wahrscheinlichkeit eines gleichzeitigen Ausfalls vernachlässigbar. Wir haben ihn praktisch erwischt. Eigentlich hatten wir Glück in Fiord - die Hauptstromversorgung wurde dort unterbrochen, und anstatt sie wieder einzuschalten, verwirrte jemand den Schalter und schaltete die Sicherungsleitung aus.
Es gab nicht nur technische Anforderungen für die Verteilung der Ladung auf die Standorte: Es gibt keine Wunder, und eine aggressive Marketingpolitik mit guten Preisen impliziert eine gewisse Wachstumsrate des Ressourcenverbrauchs. Daher haben wir den Prozentsatz der Ressourcen berücksichtigt, die an MTS gesendet werden müssen. Alles andere haben wir mehr oder weniger gleichmäßig auf andere Rechenzentren verteilt.
Wieder dein Eisen
Die Erfahrung mit öffentlichen Clouds hat gezeigt, dass es praktisch ist, sie zu verwenden, wenn Sie schnell Ressourcen hinzufügen müssen, für Experimente, für einen Piloten usw. Bei ständiger Belastung ist es teurer als das Verdrehen des eigenen Bügeleisens. Wir konnten jedoch die Idee von Containern, nahtlosen Migrationen virtueller Maschinen innerhalb eines Clusters usw. nicht länger aufgeben. Wir haben Automatisierung geschrieben, um einige Autos nachts auszulöschen, aber die Wirtschaft hat immer noch nicht geklappt. Wir hatten nicht genug Kompetenz, um eine private Cloud zu unterstützen, wir mussten sie erweitern.
Wir suchten nach einer Lösung, mit der Sie relativ einfach eine Cloud auf Ihrer Hardware installieren können. Zu dieser Zeit haben wir nie mit Cisco-Servern gearbeitet, nur mit einem Netzwerkstapel. Dies war ein Risiko. Dellah verfügt über einfache, vertraute Hardware, die so zuverlässig ist wie ein Kalaschnikow-Sturmgewehr. Wir haben das seit Jahren und haben immer noch irgendwo. Die Idee hinter Hyperflex ist jedoch, dass es sofort die Hyperkonvergenz der endgültigen Lösung unterstützt. Und alles von Dell lebt auf gewöhnlichen Routern, und es gibt Nuancen. Insbesondere ist die Leistung aufgrund des Overheads nicht so cool wie bei Präsentationen. Ich meine, sie können korrekt eingerichtet werden und es wird super, aber wir haben entschieden, dass dies nicht unser Geschäft ist, und lassen Dell von denen vorbereitet werden, die dies als Berufung empfinden. Aus diesem Grund haben wir uns für Cisco Hyperflex entschieden. Diese Option gewann insgesamt als die interessanteste: weniger Hämorrhoiden in Einrichtung und Betrieb,und während der Tests war alles in Ordnung. Im Sommer 2019 haben wir den Cluster in die Schlacht gezogen. Wir hatten ein halb leeres Rack im Kompressor, das größtenteils nur mit Netzwerkgeräten besetzt war, und sie wurden dort platziert. So haben wir das fünfte „Rechenzentrum“ - physisch vier, aber fünf von den Ressourcenpools.
Sie nahmen, berechneten das Volumen der konstanten Last und das Volumen der Variablen. Permanent verwandelte sich in eine Last auf ihrem Eisen. Auf Hardwareebene bietet es der Cloud jedoch Vorteile in Bezug auf Ausfallsicherheit und Redundanz.
Die Amortisation des Eisenprojekts erfolgt zu den Durchschnittspreisen unserer Wolken für das Jahr.
Du bist hier
In diesem Moment beendeten wir die erzwungenen Bewegungen. Wie Sie sehen, hatten wir nicht viele wirtschaftliche Optionen und haben ständig dort geladen, wo wir aus irgendeinem Grund aufstehen mussten. Dies führte zu einer merkwürdigen Situation, dass die Last ungleichmäßig ist. Der Ausfall eines Segments (und das Segment mit den Krok-Rechenzentren befindet sich auf zwei Nexus in einem Engpass) führt zu einem Verlust der Benutzererfahrung. Das heißt, die Site bleibt erhalten, es gibt jedoch offensichtliche Schwierigkeiten bei der Zugänglichkeit.
In MTS ist ein Fehler im gesamten Rechenzentrum aufgetreten. Es waren noch zwei in den anderen. Von Zeit zu Zeit fielen Wolken ab oder Cloud-Controller oder ein komplexes Netzwerkproblem traten auf. Kurz gesagt, wir verlieren von Zeit zu Zeit Rechenzentren. Ja, für kurze Zeit, aber immer noch unangenehm. Irgendwann hielten sie es für selbstverständlich, dass die Rechenzentren abfielen.
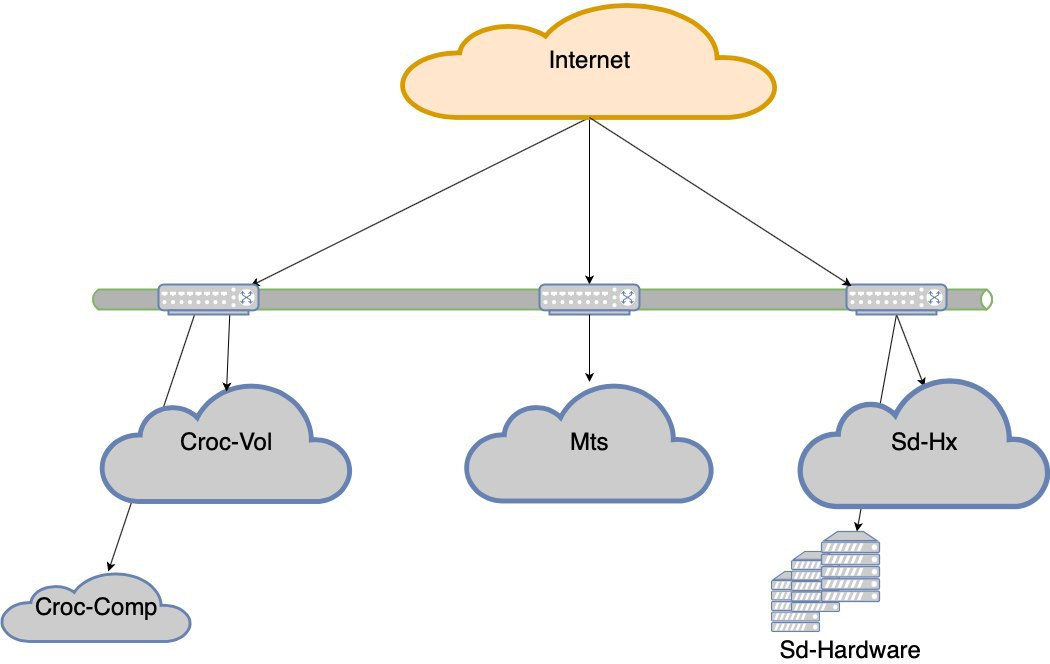
Wir haben uns für eine Fehlertoleranz auf Rechenzentrumsebene entschieden.
Jetzt gehen wir nicht ins Bett, wenn eines der 5 Rechenzentren ausfällt. Aber wenn wir Crocs Schulter verlieren, wird es sehr ernsthafte Drawdowns geben. Und so wurde das Projekt der Ausfallsicherheit von Rechenzentren geboren. Das Ziel ist Folgendes: Wenn der Gleichstrom ausfällt, das Netzwerk ausfällt oder das Gerät ausfällt, sollte der Standort ohne manuellen Eingriff funktionieren. Außerdem müssen wir uns nach dem Unfall regelmäßig erholen.
Was sind die Fallstricke?
Jetzt:
Müssen:
Jetzt:
Müssen:
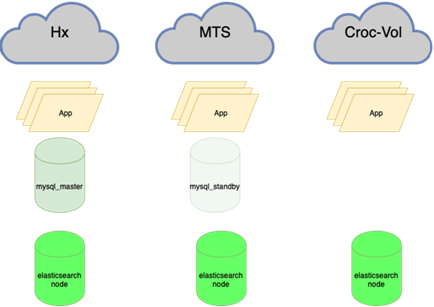
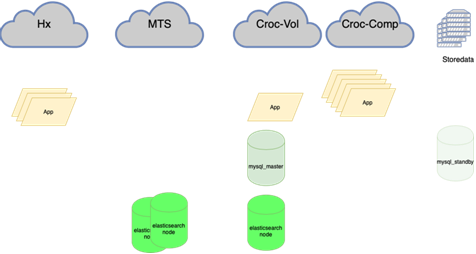
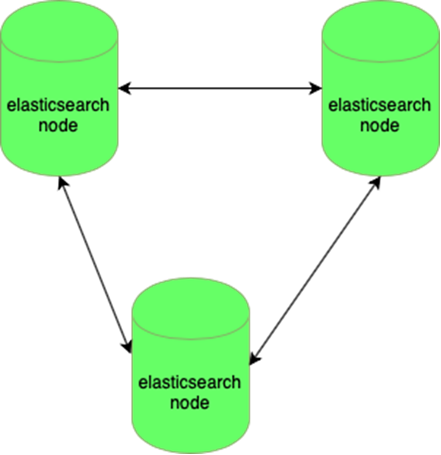
Elastic ist beständig gegen den Verlust eines Knotens:
MySQL-Datenbanken (viele kleine) sind schwer zu verwalten:
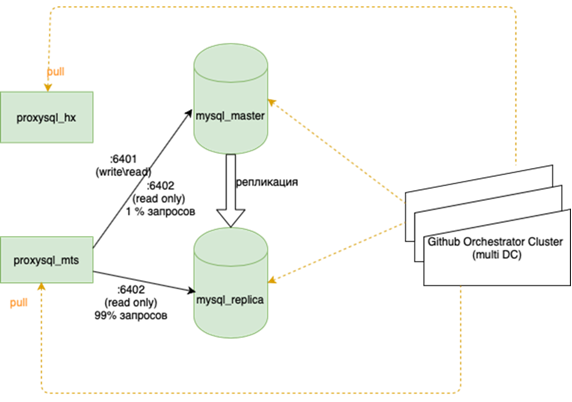
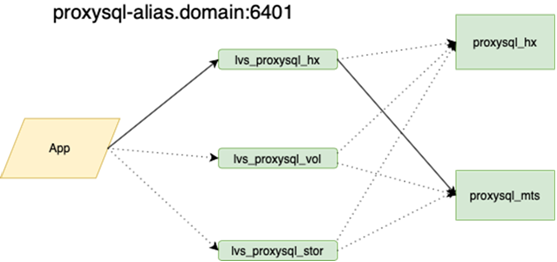
Darüber wird von meinem Kollegen, der den Ausgleich vorgenommen hat, besser ausführlich geschrieben. Es ist wichtig, dass wir, bevor wir dies aufgehängt haben, wenn wir den Meister verloren haben, mit unseren Händen in die Reserve gehen und dort die Flagge r / o = 0 setzen müssen, alle Repliken für diesen neuen Meister mit Ansible neu erstellen müssen und es mehr als zwei davon in der Hauptgirlande gibt Dutzende, ändern Sie die Anwendungskonfigurationen, rollen Sie die Konfigurationen aus und warten Sie auf das Update. Jetzt läuft die Anwendung auf einer Anycast-IP, die sich den LVS-Balancer ansieht. Die permanente Konfiguration ändert sich nicht. Alle Basistopologien auf dem Orchestrator.
Jetzt ist die dunkle Optik zwischen unseren Rechenzentren gespannt, sodass wir als lokale auf jede Ressource in unserem Ring zugreifen können. Die Antwortzeit zwischen Rechenzentren und die Zeit innerhalb von Plus oder Minus sind gleich. Dies ist ein wichtiger Unterschied zu anderen Unternehmen, die Geocluster bauen. Wir sind sehr stark an unsere Hardware und unser Netzwerk gebunden und versuchen nicht, Anforderungen innerhalb des Rechenzentrums zu lokalisieren. Das ist einerseits cool und andererseits, wenn wir nach Europa oder China wollen, werden wir unsere dunkle Optik nicht herausziehen.
Dies bedeutet, fast alles neu auszugleichen, insbesondere Datenbanken. Es gibt viele Schemata, bei denen der aktive Master die gesamte Last zum Lesen und Schreiben hält und daneben eine synchrone Replik zum schnellen Umschalten (wir schreiben nicht in zwei gleichzeitig, aber wir replizieren, sonst funktioniert es nicht sehr gut). Die Hauptbasis befindet sich in einem Rechenzentrum und das Replikat in einem anderen. Es kann auch Teilkopien im dritten für einzelne Anwendungen geben. Je nach Jahreszeit gibt es 10 bis 15 solcher Fälle. Orchestrator ist ein ausgedehnter Cluster zwischen Rechenzentren und drei Rechenzentren. Hier werden wir Ihnen ausführlicher erzählen, wenn Sie die Kraft haben, zu beschreiben, wie all diese Musik spielt.
Sie müssen sich mit den Anwendungen befassen. Dies wird jetzt noch benötigt: Manchmal kommt es vor, dass wenn eine Verbindung unterbrochen wird, es richtig ist, die alte zu löschen und eine neue zu öffnen. Manchmal werden Anforderungen in einer bereits verlorenen Verbindung in einer Schleife wiederholt, bis der Prozess beendet ist. Das Letzte, was gefangen wurde, war die Aufgabe für die Krone, eine Erinnerung an den Zug wurde nicht ausgeschrieben.
Im Allgemeinen gibt es noch viel zu tun, aber der Plan ist klar.