Der Hinweis beschreibt ein Experiment zum Erstellen einer kleinen Kopie eines hochtechnischen Data Warehouse-Unternehmens. Basierend auf einem Single-Board-Computer Raspberry Pi.
Das Modell und die Architektur werden vereinfacht, ähneln jedoch dem Unternehmensspeicher. Das Ergebnis ist eine Bewertung der Möglichkeit, den Raspberry Pi im Bereich der Datenverarbeitung und -analyse einzusetzen.

# 1
Die Rolle eines erfahrenen und starken Spielers spielt das Exadata X5-Fahrzeug (eine Einheit) der Oracle Corporation.
Der Datenverarbeitungsprozess umfasst die folgenden Schritte:
- Lesen aus einer 10,3-GB-Datei - 350 Millionen Datensätze in 90 Minuten.
- Datenverarbeitung und -bereinigung - 2 SQL-Abfragen und 15 Minuten (mit Verschlüsselung persönlicher Daten 180 Minuten).
- Lademessungen - 10 Minuten.
- Herunterladen von Faktentabellen mit 20 Millionen neuen Datensätzen - 5 SQL-Abfragen und 35 Minuten.
Die Gesamtintegration von 350 Millionen Datensätzen in 2,5 Stunden entspricht 2,3 Millionen Datensätzen pro Minute oder ungefähr 39.000 Rohdatensätzen pro Sekunde.
# 2
Der experimentelle Gegner wird der Raspberry Pi 3 Model B + mit einem 1,4-GHz-4-Core-Prozessor sein.
Sqlite3 wird als Speicher verwendet, Dateien werden mit PHP gelesen. Die Dateien und die Datenbank befinden sich auf einer 32-GB-SD-Karte der Klasse 10 im integrierten Lesegerät. Das Backup wird auf einem 64-GB-Flash-Laufwerk erstellt, das an USB angeschlossen ist.
Das Datenmodell in der relationalen Datenbank sqlite3 und die Berichte werden im Artikel über kleinen Speicher beschrieben .
Datenmodell
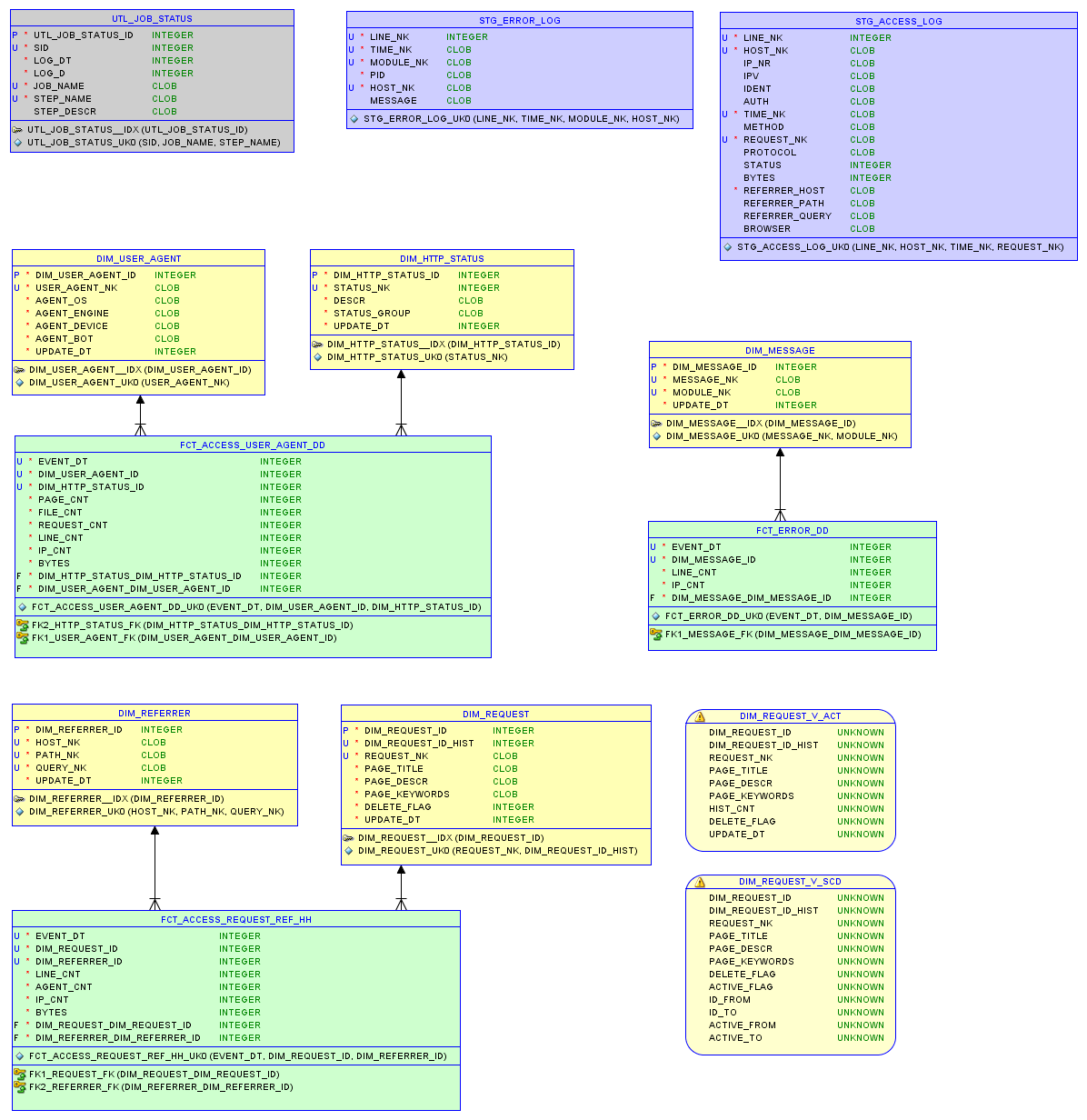
Testen Sie einen
Die ursprüngliche Datei access.log ist 37 MB groß und enthält 200.000 Einträge.
- Es dauerte 340 Sekunden, um das Protokoll zu lesen und in die Datenbank zu schreiben.
- Das Laden von Messungen mit 5.000 Datensätzen dauerte 5 Sekunden.
- Laden von Faktentabellen mit 90.000 neuen Datensätzen - 32 Sekunden.
Insgesamt dauerte die Integration von 200.000 Datensätzen fast 7 Minuten, was 28.000 Datensätzen pro Minute oder 470 Rohdatensätzen pro Sekunde entspricht. Die Datenbank ist 7,5 MB groß; Nur 8 SQL-Abfragen für die Datenverarbeitung.
Zweitens testen
Eine aktivere Site-Datei. Die ursprüngliche Datei access.log ist 67 MB groß und enthält 290.000 Einträge.
- Es dauerte 670 Sekunden, um das Protokoll zu lesen und in die Datenbank zu schreiben.
- Das Laden von Messungen mit 25.000 Datensätzen dauerte 8 Sekunden.
- Laden von Faktentabellen mit 240.000 neuen Datensätzen - 80 Sekunden.
Insgesamt dauerte die Integration von 290.000 Datensätzen etwas mehr als 12 Minuten, was 23.000 Datensätzen pro Minute oder 380 Rohdatensätzen pro Sekunde entspricht. Die Datenbank ist 22,9 MB groß
Ausgabe
Um Daten in Form eines Modells zu erhalten, das eine effektive Analyse ermöglicht, sind erhebliche Rechen- und Materialressourcen sowie in jedem Fall Zeit erforderlich.
Beispielsweise kostet eine Exadata-Einheit mehr als 100.000. Ein Raspberry Pi kostet 60 Einheiten.
Sie können da nicht linear verglichen werden Mit dem Anstieg des Datenvolumens und der Zuverlässigkeitsanforderungen treten Schwierigkeiten auf.
Wenn wir uns jedoch einen Fall vorstellen, in dem tausend Raspberry Pi parallel arbeiten, werden sie basierend auf dem Experiment ungefähr 400.000 Datensätze mit Rohdaten pro Sekunde verarbeiten.
Und wenn die Lösung für Exadata auf 60 oder 100.000 Datensätze pro Sekunde optimiert ist, sind dies deutlich weniger als 400.000. Dies bestätigt das innere Gefühl, dass die Preise für Unternehmenslösungen zu hoch sind.
In jedem Fall leistet der Raspberry Pi hervorragende Arbeit mit Datenverarbeitung und relationalen Modellen im entsprechenden Maßstab.
Verknüpfung
Der Home Raspberry Pi wurde als Webserver konfiguriert. Ich werde diesen Prozess im nächsten Beitrag beschreiben.
Sie können selbst unter der Adresse mit der Raspberry Pi-Leistung und der Datei access.log experimentieren . Dort können das Datenbankmodell (DDL), die Ladeprozeduren (ETL) und die Datenbank selbst heruntergeladen werden. Die Idee ist, schnell eine Vorstellung vom Status der Site aus dem Protokoll mit Daten aus den letzten Wochen zu erhalten.
Änderungen
Dank Kommentaren wurde der Fehler beim Laden der Exadata-Datei behoben und die Nummern in der Notiz wurden behoben. Sqlloader wird zum Lesen verwendet, ein Fehler löschte die Parameter BINDSIZE und ROWS. Aufgrund der instabilen Belastung von einem Remote-Laufwerk wurde anstelle des direkten Pfads die herkömmliche Methode gewählt, die die Geschwindigkeit um weitere 30-50% erhöhen könnte.