Guten Tag, liebe Leser! Das Material ist theoretischer Natur und richtet sich ausschließlich an unerfahrene Analysten, die zum ersten Mal auf BI-Analytics gestoßen sind.
Was versteht man traditionell unter diesem Konzept? In einfachen Worten ist dies ein komplexes System (wie zum Beispiel die Budgetierung) zum Sammeln, Verarbeiten und Analysieren von Daten, bei dem die Endergebnisse in Form von Grafiken, Diagrammen und Tabellen dargestellt werden.
Dies erfordert die gut koordinierte Arbeit mehrerer Spezialisten gleichzeitig. Der Dateningenieur ist für die Speicher- und ETL / ELT-Prozesse verantwortlich, der Datenanalyst hilft beim Füllen der Datenbank, der BI-Analyst entwickelt Dashboards, der Business Analyst vereinfacht die Kommunikation mit den Berichtskunden. Diese Option ist jedoch nur möglich, wenn das Unternehmen bereit ist, die Arbeit des Teams zu bezahlen. In den meisten Fällen verlassen sich kleine Unternehmen auf eine Person, um die Kosten zu minimieren, die häufig überhaupt keine umfassenden Aussichten im Bereich BI hat, aber nur eine nickende Kenntnis der Berichtsplattform hat.
In diesem Fall geschieht Folgendes: Die Erfassung, Verarbeitung und Analyse von Daten erfolgt durch die Kräfte eines einzigen Tools - der BI-Plattform selbst. In diesem Fall werden die Daten in keiner Weise vorab gelöscht, gehen nicht durch die Verbundwerkstoffe. Die Sammlung von Informationen stammt aus Primärquellen ohne Beteiligung eines Zwischenspeichers. Die Ergebnisse dieses Ansatzes sind in thematischen Foren leicht zu sehen. Wenn Sie versuchen, alle Fragen zu BI-Tools zusammenzufassen, fällt wahrscheinlich Folgendes in die Top 3: Wie werden schlecht strukturierte Daten in das System geladen, wie werden die erforderlichen Metriken daraus berechnet und was ist zu tun, wenn der Bericht ausgeführt wird? sehr langsam. Überraschenderweise finden Sie in diesen Foren kaum Diskussionen zu ETL-Tools, Data Warehouse-Erfahrungen, Best Practices für die Programmierung und SQL-Abfragen. Außerdem bin ich immer wieder auf die Tatsache gestoßenErfahrene BI-Analysten sprachen nicht sehr schmeichelhaft über die Verwendung von R / Python / Scala und verwiesen auf die Tatsache, dass alle Probleme nur mit Hilfe der BI-Plattform gelöst werden können. Gleichzeitig versteht jeder, dass Sie mit kompetentem Date Engineering viele Probleme beim Erstellen von BI-Berichten schließen können.
-. , . -, , , -, .
«Data – BI» . . (-) (csv, txt, xlsx . .).
. . , . , , . BI .
. (, 1). , . ( , , . .). BI-, . .
«Data – DB – BI» , , . , , .
. , . . SQL ( ), BI-. .
. , . . . SQL.
«Data – ETL – DB – BI» . ETL- , R/Python/Scala . . . .
. , . . BI-.
. ETL- SQL. . , .
. «» SQLite. , (). E-Commerce Data Kaggle.
#
import pandas as pd
#
pd.set_option('display.max_columns', 10)
pd.set_option('display.expand_frame_repr', False)
path_dataset = 'dataset/ecommerce_data.csv'
#
def func_main(path_dataset: str):
#
df = pd.read_csv(path_dataset, sep=',')
#
list_col = list(map(str.lower, df.columns))
df.columns = list_col
# -
df['invoicedate'] = df['invoicedate'].apply(lambda x: x.split(' ')[0])
df['invoicedate'] = pd.to_datetime(df['invoicedate'], format='%m/%d/%Y')
#
df['amount'] = df['quantity'] * df['unitprice']
#
df_result = df.drop(['invoiceno', 'quantity', 'unitprice', 'customerid'], axis=1)
#
df_result = df_result[['invoicedate', 'country', 'stockcode', 'description', 'amount']]
return df_result
#
def func_sale():
tbl = func_main(path_dataset)
df_sale = tbl.groupby(['invoicedate', 'country', 'stockcode'])['amount'].sum().reset_index()
return df_sale
#
def func_country():
tbl = func_main(path_dataset)
df_country = pd.DataFrame(sorted(pd.unique(tbl['country'])), columns=['country'])
return df_country
#
def func_product():
tbl = func_main(path_dataset)
df_product = tbl[['stockcode','description']].\
drop_duplicates(subset=['stockcode'], keep='first').reset_index(drop=True)
return df_product
Extract Transform. , . . , , .
#
import pandas as pd
import sqlite3 as sq
from etl1 import func_country,func_product,func_sale
con = sq.connect('sale.db')
cur = con.cursor()
##
# cur.executescript('''DROP TABLE IF EXISTS country;
# CREATE TABLE IF NOT EXISTS country (
# country_id INTEGER PRIMARY KEY AUTOINCREMENT,
# country TEXT NOT NULL UNIQUE);''')
# func_country().to_sql('country',con,index=False,if_exists='append')
##
# cur.executescript('''DROP TABLE IF EXISTS product;
# CREATE TABLE IF NOT EXISTS product (
# product_id INTEGER PRIMARY KEY AUTOINCREMENT,
# stockcode TEXT NOT NULL UNIQUE,
# description TEXT);''')
# func_product().to_sql('product',con,index=False,if_exists='append')
## ()
# cur.executescript('''DROP TABLE IF EXISTS sale;
# CREATE TABLE IF NOT EXISTS sale (
# sale_id INTEGER PRIMARY KEY AUTOINCREMENT,
# invoicedate TEXT NOT NULL,
# country_id INTEGER NOT NULL,
# product_id INTEGER NOT NULL,
# amount REAL NOT NULL,
# FOREIGN KEY(country_id) REFERENCES country(country_id),
# FOREIGN KEY(product_id) REFERENCES product(product_id));''')
## ()
# cur.executescript('''DROP TABLE IF EXISTS sale_data_lake;
# CREATE TABLE IF NOT EXISTS sale_data_lake (
# sale_id INTEGER PRIMARY KEY AUTOINCREMENT,
# invoicedate TEXT NOT NULL,
# country TEXT NOT NULL,
# stockcode TEXT NOT NULL,
# amount REAL NOT NULL);''')
# func_sale().to_sql('sale_data_lake',con,index=False,if_exists='append')
## (sale_data_lake) (sale)
# cur.executescript('''INSERT INTO sale (invoicedate, country_id, product_id, amount)
# SELECT sdl.invoicedate, c.country_id, pr.product_id, sdl.amount
# FROM sale_data_lake as sdl LEFT JOIN country as c ON sdl.country = c.country
# LEFT JOIN product as pr ON sdl.stockcode = pr.stockcode
# ''')
##
# cur.executescript('''DELETE FROM sale_data_lake''')
def select(sql):
return pd.read_sql(sql,con)
sql = '''select *
from (select s.invoicedate,
c.country,
pr.description,
round(s.amount,1) as amount
from sale as s left join country as c on s.country_id = c.country_id
left join product as pr on s.product_id = pr.product_id)'''
print(select(sql))
cur.close()
con.close()
(Load) . . . , . .
SQL, . , BI-.
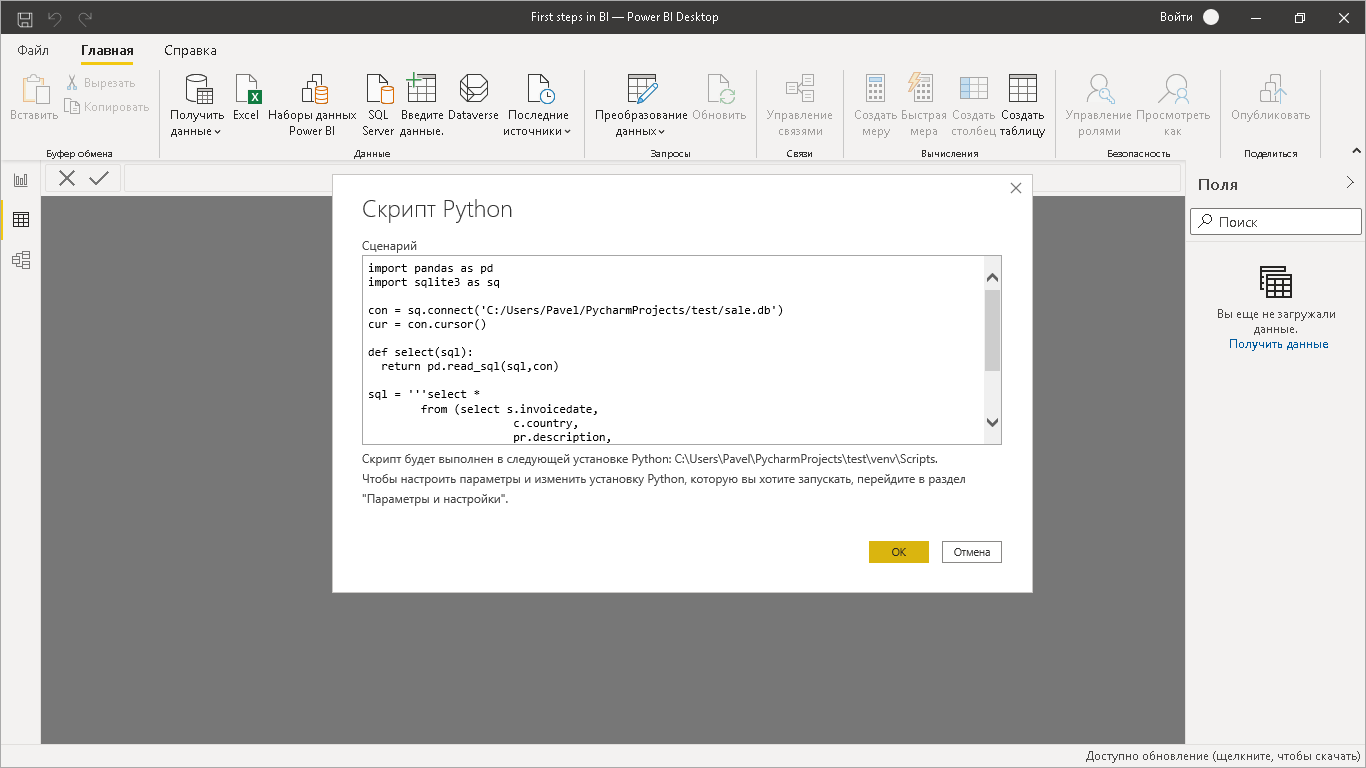
BI- SQLite Python.
import pandas as pd
import sqlite3 as sq
con = sq.connect('C:/Users/Pavel/PycharmProjects/test/sale.db')
cur = con.cursor()
def select(sql):
return pd.read_sql(sql,con)
sql = '''select *
from (select s.invoicedate,
c.country,
pr.description,
replace(round(s.amount,1),'.',',') as amount
from sale as s left join country as c on s.country_id = c.country_id
left join product as pr on s.product_id = pr.product_id)'''
tbl = select(sql)
print(tbl)
.
«Data – Workflow management platform + ETL – DB – BI» . .
. . .
. . BI. .
«Data – Workflow management platform + ELT – Data Lake – Workflow management platform + ETL – DB – BI» , : (Data Lake), (DB), .
. . , Data Lake.
. . Data Lake – , .
.
BI- .
BI , .
, SQL, - , , , .
Das ist alles. Alle Gesundheit, viel Glück und beruflichen Erfolg!