Inspector und sogar irgendwo "Interpreter", LIT oder Language Interpretability Tool ist eine leistungsstarke Open-Source-Plattform zur Visualisierung und Interpretation von NLP-Modellen. Die Plattform wurde auf der EMNLP 2020 von Google Research im November 2020 vorgestellt. LIT befindet sich noch im Entwicklungsstatus, daher garantieren die Entwickler nichts, einschließlich der Arbeit an der Windows-Plattform. Aber ich habe es geschafft, ich teile meine Erfahrungen.
LIT ist ein interaktives, erweiterbares visuelles Tool für Entwickler und Forscher von NLP-Modellen, die unter anderem verstehen möchten, welche Fälle das Modell nicht bewältigt, warum die Prognose genau gleich ist und welche Wörter im Text das Ergebnis beeinflussen und was passiert, wenn ein oder ein anderes Token oder sogar der gesamte Text. LIT ist eine offene Plattform. Sie können Ihre eigene Berechnung von Metriken, neue Interpretationsmethoden oder benutzerdefinierte Visualisierungstools hinzufügen. Es ist wichtig, dass Sie anhand der Architektur des Modells die benötigten Informationen abrufen können.
Die Plattform unterstützt verschiedene Arten von Modellen und Frameworks, einschließlich TensorFlow 1.x, TensorFlow 2.x und PyTorch. LIT kann benutzerdefinierten Python-Code über einem neuronalen Netzwerk und sogar RPC- Modellen ausführen .
Zwei Worte zur Architektur. Das Frontend basiert auf TypeScript. Es ist eine einseitige Anwendung, die aus unabhängigen Webkomponenten besteht. Das Backend basiert auf einem WSGI- Server. Das Backend verwaltet Modelle, Datensätze, Metriken, Generatoren und Interpretationskomponenten sowie einen Cache, der die Modell- und Datenmanipulation beschleunigt, was für große Modelle sehr wichtig ist. Weitere Details hier .
Standardmäßig unterstützt LIT Klassifizierung, Regression, Textgeneratoren, einschließlich seq2seq, maskierte Modelle, NER- Modelle und Multifunktionsmodelle mit mehreren Ausgabeköpfen. Hauptmerkmale in der Tabelle:
Widget |
Kurze Beschreibung |
Beachtung |
Visualisierung des Aufmerksamkeitsmechanismus durch Aufmerksamkeitsschichten und Aufmerksamkeitsköpfe in Kombination. |
Verwirrung Matrix |
, , . |
Counterfactual Generator |
. |
Data Table |
. — 10k . |
Datapoint Editor |
. . |
Embeddings |
3D : UMAP PCA. . Data Table . , , , . |
Metrics Table |
— Accuracy Recall BLEU ROUGE. , . |
Predictions |
. . |
Salience Maps |
. . — local gradients, LIME. |
Scalar Plot |
2D . |
Slice Editor |
. |
— pip install .
pip Windows 10 GPU:
# :
conda create -n nlp python==3.7
conda activate nlp
# tensorflow-gpu pytorch:
conda install -c anaconda tensorflow-gpu
conda install -c pytorch pytorch
# pip tensorflow datasets, transformers LIT:
pip install transformers=2.11.0
pip install tfds-nightly
pip install lit-nlp
tensorflow datasets glue datasets, tfds . PyTorch , .
. 5432, PostgreSQL. netstat -ao. :
python -m lit_nlp.examples.quickstart_sst_demo —port=5433.
< >\anaconda3\envs\nlp\Lib\site-packages\lit_nlp\examples , quickstart_sst_demo windows. , , 5 GPU 20 CPU. ASCII- LIT .

git clone https://github.com/PAIR-code/lit.git ~/lit
#
cd ~/lit
conda env create -f environment.yml
conda activate lit-nlp
conda install cudnn cupti # , GPU
conda install -c pytorch pytorch
#
pushd lit_nlp; yarn && yarn build; popd
continuumio/anaconda3 WSL2. . environment.yml tensorflow-datasets tfds-nightly. gcc g++. yarn. yarn apt-get, yarn! — :
curl https://deb.nodesource.com/setup_12.x | bash
curl https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add -
echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list
apt-get update && apt-get install -y nodejs yarn postgresql-client
yarn && yarn build
NLP , , . «» LIT , quickstart_sst_demo, - .
:
Lenta.Ru, Kaggle. : , , . 70 150. 50k .
:
, BERT. . RuBert DeepPavlov , huggingface.co. 180 . . , 8 GPU. , . , max_seq_length, 128 , 64 .
LIT :
, , datasets/lenta.py, models/lenta_models.py examples/quickstart_lenta.py . — quickstart_sst_demo. . EDIT.
datasets/lenta.py: tfds, , .
models/lenta_models.py: «DeepPavlov/rubert-base-cased» : max_seq_length 64 , — 32 16.
examples/quickstart_lenta.py: , .
:
python -m lit_nlp.examples.quickstart_lenta —port=5433
RuBert – . . lenta_models num_epochs ( train). , . 50k 3000 . RTX2070 25 .
:

. , .

, 21 , , , .
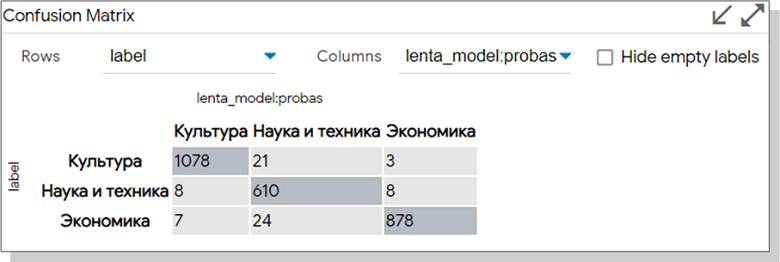
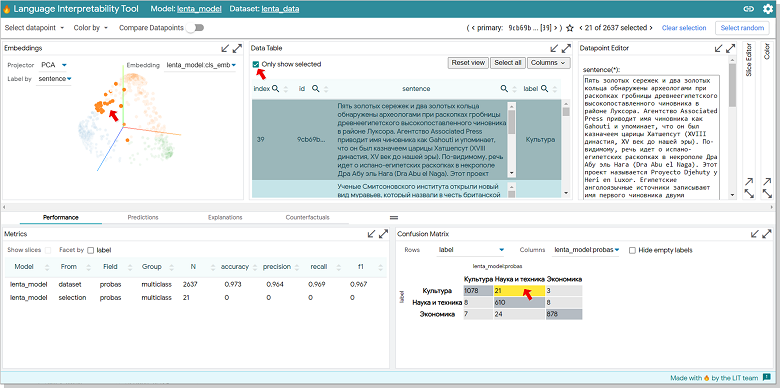
. Data Table «Only show selected». Embedding.
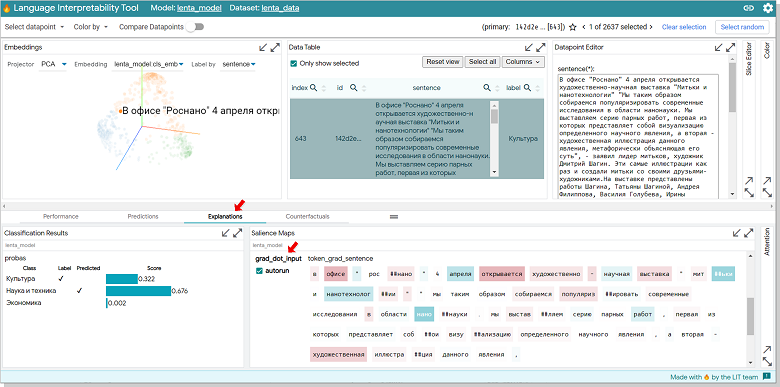
Data Table - Explanation. . 32% , 68, . Silence Maps grad_dot_input. , " " , — .
Datapoint Editor «-» , «Analyze new datapoint» ( ).
:

:

Scalar. , Y. , , ROUGE. .
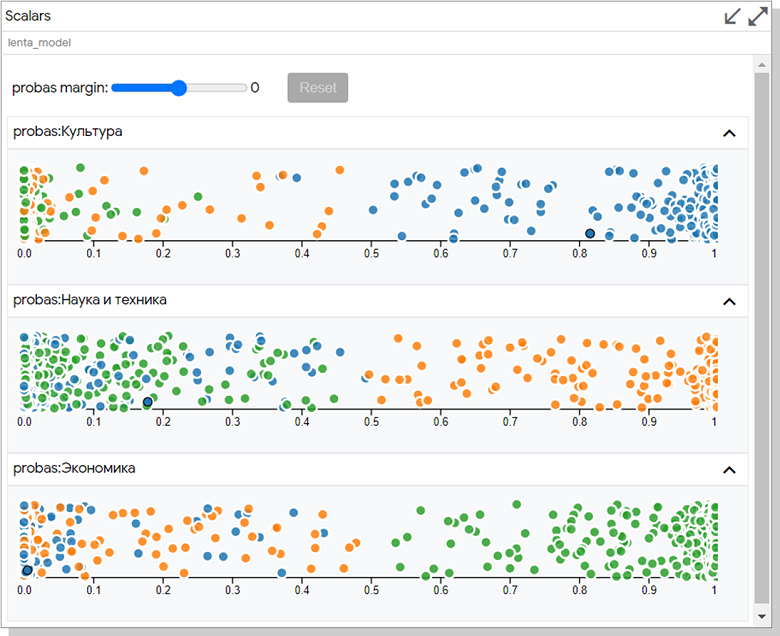
:
RuBert LIT , . , . . Slinece Maps Embeddings , - .
BERT füllt Textlücken
Text auf T5 generieren
Die Möglichkeit, die Wahrscheinlichkeit von Token abzuschätzen und beim Generieren von Text im letzten Beispiel Alternativen zu sehen, ist sehr nützlich. Ich habe ein solches Modell noch nicht lokal ausprobiert, aber ich kann nicht anders, als einen Screenshot aus der Demo zu teilen:
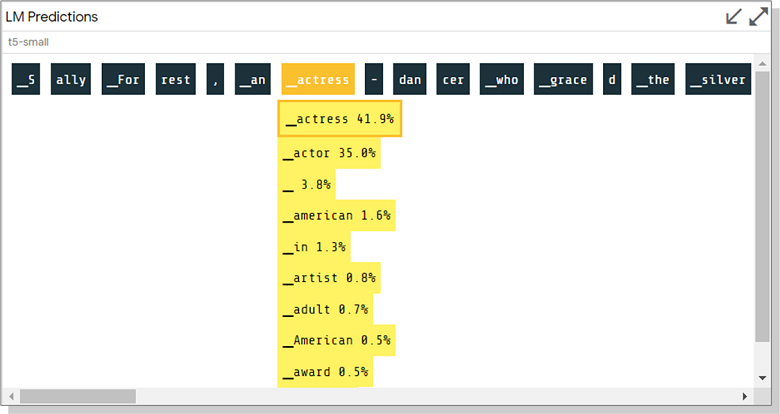
Ich wünsche Ihnen von Herzen alle interessanten Experimente mit LIT und etwas Geduld dabei!
Links
Veröffentlichung des Tools zur Sprachinterpretierbarkeit: Erweiterbare, interaktive Visualisierungen und Analysen für NLP-Modelle für EMNLP 2020
Forum auf Github mit Diskussion über Probleme und Fehler in LIT