
Wie aktualisiere ich den Attributwert für alle Datensätze in einer Tabelle? Wie füge ich einer Tabelle einen Primär- oder eindeutigen Schlüssel hinzu? Wie teile ich einen Tisch in zwei Teile? Wie ...
Wenn die Anwendung für Migrationen für einige Zeit nicht verfügbar ist, sind die Antworten auf diese Fragen nicht schwierig. Aber was ist, wenn Sie heiß migrieren müssen - ohne die Datenbank anzuhalten und ohne andere zu stören, damit zu arbeiten?
Wir werden versuchen, diese und andere Fragen, die während der Schema- und Datenmigration in PostgreSQL auftreten, in Form von praktischen Ratschlägen zu beantworten.
Dieser Artikel - Dekodierungsleistung bei der SmartDataConf-Konferenz ( hier finden Sie die Präsentation, das Video wird zu gegebener Zeit erscheinen). Es gab viel Text, daher wird das Material in zwei Artikel unterteilt:
- Grundmigrationen
- Ansätze zum Aktualisieren großer Tabellen.
Am Ende gibt es eine Zusammenfassung des gesamten Artikels in Form eines Pivot-Table-Spickzettel.
Inhalt
Der Kern des Problems
Hinzufügen einer Spalte
Hinzufügen einer Standardspalte
Löschen einer Spalte
Erstellen eines Index
Erstellen eines Index für eine partitionierte Tabelle
Erstellen einer NOT NULL-Einschränkung
Erstellen eines Fremdschlüssels
Erstellen einer eindeutigen Einschränkung
Erstellen eines Primärschlüssels Quick Migration Cheat Sheet
Das Wesentliche des Problems
Angenommen, wir haben eine Anwendung, die mit einer Datenbank arbeitet. In der minimalen Konfiguration kann es aus 2 Knoten bestehen - der Anwendung selbst bzw. der Datenbank.

Bei diesem Schema treten Anwendungsaktualisierungen häufig mit Ausfallzeiten auf. Gleichzeitig können Sie die Datenbank aktualisieren. In einer solchen Situation ist das Hauptkriterium die Zeit, dh Sie müssen die Migration so schnell wie möglich abschließen, um die Zeit der Nichtverfügbarkeit des Dienstes zu minimieren.
Wenn die Anwendung wächst und es erforderlich wird, Releases ohne Ausfallzeiten durchzuführen, verwenden wir mehrere Anwendungsserver. Es kann so viele davon geben, wie Sie möchten, und sie werden in verschiedenen Versionen vorliegen. In diesem Fall muss die Abwärtskompatibilität sichergestellt werden.

In der nächsten Wachstumsphase passen die Daten nicht mehr in eine Datenbank. Wir beginnen auch, die Datenbank zu skalieren - durch Sharding. Da es in der Praxis sehr schwierig ist, mehrere Datenbanken synchron zu migrieren, bedeutet dies, dass sie irgendwann unterschiedliche Datenschemata haben. Dementsprechend werden wir in einer heterogenen Umgebung arbeiten, in der Anwendungsserver möglicherweise unterschiedlichen Code und Datenbanken mit unterschiedlichen Datenschemata haben.
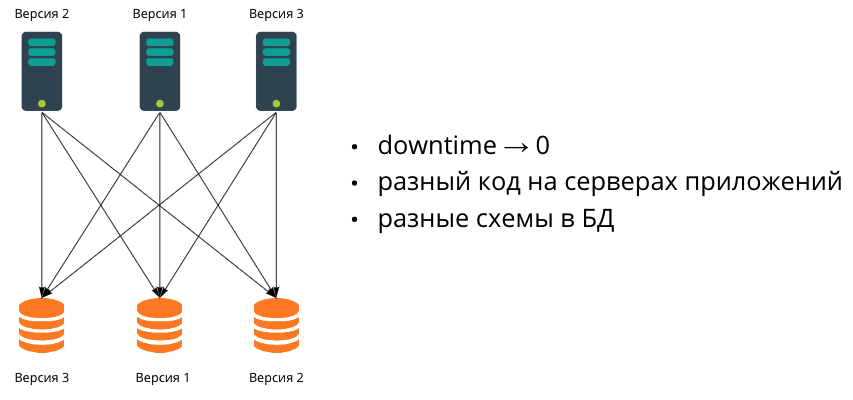
Es geht um diese Konfiguration, über die wir in diesem Artikel sprechen und die beliebtesten Migrationen betrachten, die Entwickler schreiben - von einfachen zu komplexeren.
Unser Ziel ist es, SQL-Migrationen mit minimalen Auswirkungen auf die Anwendungsleistung durchzuführen, d. H. Ändern Sie die Daten oder das Datenschema so, dass die Anwendung weiterhin ausgeführt wird und Benutzer es nicht bemerken.
Hinzufügen einer Spalte
ALTER TABLE my_table ADD COLUMN new_column INTEGER --
Wahrscheinlich hat jede Person, die mit der Datenbank arbeitet, eine ähnliche Migration geschrieben. Wenn wir über PostgreSQL sprechen, ist diese Migration sehr billig und sicher. Der Befehl selbst wird, obwohl er die Sperre der höchsten Ebene ( AccessExclusive ) erfasst , sehr schnell ausgeführt, da unter der Haube nur Metainformationen zu einer neuen Spalte hinzugefügt werden, ohne die Daten der Tabelle selbst neu zu schreiben. In den meisten Fällen geschieht dies unbemerkt. Probleme können jedoch auftreten, wenn zum Zeitpunkt der Migration lange Transaktionen mit dieser Tabelle ausgeführt werden. Um die Essenz des Problems zu verstehen, schauen wir uns ein kleines Beispiel an, wie Sperren in PostgreSQL auf vereinfachte Weise funktionieren. Dieser Aspekt wird sehr wichtig sein, wenn auch die meisten anderen Migrationen berücksichtigt werden.
Angenommen, wir haben eine große Tabelle und wählen alle Daten daraus aus. Abhängig von der Größe der Datenbank und der Tabelle selbst kann dies einige Sekunden oder sogar Minuten dauern.

Die schwächste AccessShare- Sperre , die vor Änderungen an der Tabellenstruktur schützt, wird während der Transaktion erworben .
In diesem Moment kommt eine andere Transaktion, die nur versucht, eine ALTER TABLE-Abfrage für diese Tabelle durchzuführen. Der Befehl ALTER TABLE erfasst , wie bereits erwähnt, eine AccessExclusive- Sperre , die mit keiner anderen Sperre kompatibel ist . Sie stellt sich an.
Diese Sperrwarteschlange wird in strenger Reihenfolge "geharkt". Selbst wenn andere Abfragen nach ALTER TABLE kommen (z. B. auch SELECTs), die für sich genommen nicht mit der ersten Abfrage in Konflikt stehen, stehen sie alle für ALTER TABLE an. Infolgedessen "steht" die Anwendung auf und wartet auf die Ausführung von ALTER TABLE.
Was tun in einer solchen Situation? Mit dem Befehl SET lock_timeout können Sie die Zeit zum Abrufen einer Sperre begrenzen . Wir führen diesen Befehl vor ALTER TABLE aus (das Schlüsselwort LOCAL bedeutet, dass die Einstellung nur innerhalb der aktuellen Transaktion gültig ist, andernfalls - innerhalb der aktuellen Sitzung):
SET LOCAL lock_timeout TO '100ms'
und wenn der Befehl in 100 Millisekunden die Sperre nicht abruft, schlägt er fehl. Dann starten wir es entweder erneut und erwarten, dass es erfolgreich ist, oder wir werden herausfinden, warum die Transaktion lange dauert, wenn dies nicht in unserer Anwendung enthalten sein sollte. In jedem Fall ist die Hauptsache, dass wir die Anwendung nicht zum Absturz gebracht haben.
Es sollte gesagt werden, dass das Festlegen einer Zeitüberschreitung vor jedem Befehl nützlich ist, der eine strikte Sperre ergreift.
Hinzufügen einer Spalte mit einem Standardwert
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42
Wenn dieser Befehl in einer älteren PostgreSQL-Version (unter 11) ausgeführt wird, werden alle Zeilen in der Tabelle überschrieben. Wenn der Tisch groß ist, kann dies natürlich lange dauern. Und da für die Ausführungszeit eine strikte Sperre ( AccessExclusive ) erfasst wird , werden auch alle Abfragen an die Tabelle blockiert.
Wenn PostgreSQL 11 oder neuer ist, ist diese Operation ziemlich billig. Tatsache ist, dass in der 11. Version eine Optimierung vorgenommen wurde, dank derer der Standardwert nicht neu geschrieben, sondern in einer speziellen Tabelle pg_attribute gespeichert wird. Später, wenn SELECT ausgeführt wird, werden alle leeren Werte dieser Spalte angezeigt im laufenden Betrieb durch diesen Wert ersetzt werden. In diesem Fall wird später, wenn die Zeilen in der Tabelle aufgrund anderer Änderungen überschrieben werden, der Wert in diese Zeilen geschrieben.
Darüber hinaus können Sie ab der 11. Version auch sofort eine neue Spalte erstellen und als NOT NULL markieren:
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42 NOT NULL
Was ist, wenn PostgreSQL älter als 11 Jahre ist?
Die Migration kann in mehreren Schritten erfolgen. Zunächst erstellen wir eine neue Spalte ohne Einschränkungen und Standardwerte. Wie bereits erwähnt, ist es billig und schnell. In derselben Transaktion ändern wir diese Spalte, indem wir einen Standardwert hinzufügen.
ALTER TABLE my_table ADD COLUMN new_column INTEGER;
ALTER TABLE my_table ALTER COLUMN new_column SET DEFAULT 42;
Diese Aufteilung eines Befehls in zwei mag etwas seltsam erscheinen, aber die Mechanik ist so, dass beim sofortigen Erstellen einer neuen Spalte mit einem Standardwert alle Datensätze in der Tabelle betroffen sind und der Wert für a festgelegt wird Die vorhandene Spalte (auch wenn nur das erstellt wird, was wie in unserem Fall erstellt wurde) wirkt sich nur auf neue Datensätze aus.
Nach dem Ausführen dieser Befehle müssen wir also die Werte aktualisieren, die bereits in der Tabelle enthalten waren. Grob gesagt müssen wir so etwas tun:
UPDATE my_table set new_column = 42 --
Ein solches UPDATE „frontal“ ist jedoch tatsächlich unmöglich, da beim Aktualisieren einer großen Tabelle die gesamte Tabelle für eine lange Zeit gesperrt wird. Im zweiten Artikel (hier wird es in Zukunft einen Link geben) werden wir uns ansehen, welche Strategien zum Aktualisieren großer Tabellen in PostgreSQL existieren, aber im Moment gehen wir davon aus, dass wir die Daten irgendwie aktualisiert haben, und jetzt sowohl die alten Daten als auch Der neue Wert wird standardmäßig mit dem erforderlichen Wert angegeben.
Eine Spalte entfernen
ALTER TABLE my_table DROP COLUMN new_column --
Hier ist die Logik dieselbe wie beim Hinzufügen einer Spalte: Die Tabellendaten werden nicht geändert, nur die Metainformationen werden geändert. In diesem Fall wird die Spalte als gelöscht markiert und ist für Abfragen nicht verfügbar. Dies erklärt die Tatsache, dass beim Löschen einer Spalte in PostgreSQL kein physischer Speicherplatz freigegeben wird (es sei denn, Sie führen ein VACUUM FULL aus), dh die Daten alter Datensätze verbleiben weiterhin in der Tabelle, sind jedoch beim Zugriff nicht verfügbar. Die Freigabe erfolgt schrittweise, wenn die Zeilen in der Tabelle überschrieben werden.
Somit ist die Migration selbst einfach, aber in der Regel treten manchmal Fehler auf der Backend-Seite auf. Vor dem Löschen einer Spalte müssen einige einfache vorbereitende Schritte ausgeführt werden.
- Zunächst müssen Sie alle Einschränkungen (NOT NULL, CHECK, ...) in dieser Spalte entfernen:
ALTER TABLE my_table ALTER COLUMN new_column DROP NOT NULL
- Der nächste Schritt besteht darin, die Backend-Kompatibilität sicherzustellen. Sie müssen sicherstellen, dass die Spalte nirgendwo verwendet wird. Im Ruhezustand müssen Sie beispielsweise ein Feld mit Anmerkungen markieren
@Transient
. In dem von uns verwendeten JOOQ wird das Feld mit einem Tag zu Ausnahmen hinzugefügt<excludes>
:
<excludes>my_table.new_column</excludes>
Sie müssen sich auch Abfragen genau ansehen"SELECT *"
- Frameworks können alle Spalten einer Struktur im Code zuordnen (und umgekehrt), und dementsprechend kann es erneut zu Problemen beim Zugriff auf eine nicht vorhandene Spalte kommen.
Nachdem die Änderungen auf allen Anwendungsservern veröffentlicht wurden, können Sie die Spalte löschen.
Indexerstellung
CREATE INDEX my_table_index ON my_table (name) -- ,
Diejenigen, die mit PostgreSQL arbeiten, wissen wahrscheinlich, dass dieser Befehl die gesamte Tabelle sperrt. Seit der sehr alten Version 8.2 gibt es jedoch das Schlüsselwort CONCURRENTLY , mit dem Sie einen Index in einem nicht blockierenden Modus erstellen können.
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name) --
Der Befehl ist langsamer, stört jedoch keine parallelen Anforderungen.
Dieses Team hat eine Einschränkung. Dies kann fehlschlagen, beispielsweise beim Erstellen eines eindeutigen Index für eine Tabelle, die doppelte Werte enthält. Der Index wird erstellt, aber als ungültig markiert und nicht in Abfragen verwendet. Der Indexstatus kann mit der folgenden Abfrage überprüft werden:
SELECT pg_index.indisvalid
FROM pg_class, pg_index
WHERE pg_index.indexrelid = pg_class.oid
AND pg_class.relname = 'my_table_index'
In einer solchen Situation müssen Sie den alten Index löschen, die Werte in der Tabelle korrigieren und dann neu erstellen.
DROP INDEX CONCURRENTLY my_table_index
UPDATE my_table ...
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name)
Es ist wichtig zu beachten, dass der Befehl REINDEX , der nur zum Neuerstellen des Index vorgesehen ist, nur im Blockierungsmodus bis Version 12 funktioniert, wodurch die Verwendung unmöglich wird. PostgreSQL 12 bietet KONKURRENTE Unterstützung und kann jetzt verwendet werden.
REINDEX INDEX CONCURRENTLY my_table_index -- PG 12
Erstellen eines Index für eine partitionierte Tabelle
Wir sollten auch das Erstellen von Indizes für partitionierte Tabellen diskutieren. In PostgreSQL gibt es zwei Arten der Partitionierung: durch Vererbung und deklarative Partitionierung, die in Version 10 veröffentlicht wurden. Schauen wir uns beide mit einem einfachen Beispiel an.
Angenommen, wir möchten eine Tabelle nach Datum partitionieren, und jede Partition enthält Daten für ein Jahr.
Bei der Partitionierung durch Vererbung haben wir ungefähr das folgende Schema.
Übergeordnete Tabelle:
CREATE TABLE my_table (
...
reg_date date not null
)
Kinderpartitionen für 2020 und 2021:
CREATE TABLE my_table_y2020 (
CHECK ( reg_date >= DATE '2020-01-01' AND reg_date < DATE '2021-01-01' ))
INHERITS (my_table);
CREATE TABLE my_table_y2021 (
CHECK ( reg_date >= DATE '2021-01-01' AND reg_date < DATE '2022-01-01' ))
INHERITS (my_table);
Indizes nach dem Partitionierungsfeld für jede der Partitionen:
CREATE INDEX ON my_table_y2020 (reg_date);
CREATE INDEX ON my_table_y2021 (reg_date);
Lassen wir die Erstellung eines Triggers / einer Regel zum Einfügen von Daten in eine Tabelle.
Das Wichtigste dabei ist, dass jede der Partitionen praktisch eine unabhängige Tabelle ist, die separat verwaltet wird. Daher erfolgt das Erstellen neuer Indizes auch wie bei normalen Tabellen:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name);
CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
Betrachten wir nun die deklarative Partitionierung.
CREATE TABLE my_table (...) PARTITION BY RANGE (reg_date);
CREATE TABLE my_table_y2020 PARTITION OF my_table FOR VALUES FROM ('2020-01-01') TO ('2020-12-31');
CREATE TABLE my_table_y2021 PARTITION OF my_table FOR VALUES FROM ('2021-01-01') TO ('2021-12-31');
Die Indexerstellung hängt von der PostgreSQL-Version ab. In Version 10 werden Indizes separat erstellt - genau wie im vorherigen Ansatz. Dementsprechend erfolgt das Erstellen neuer Indizes für eine vorhandene Tabelle auf die gleiche Weise.
In Version 11 wurde die deklarative Partitionierung verbessert und Tabellen werden jetzt zusammen bereitgestellt . Durch das Erstellen eines Index für die übergeordnete Tabelle werden automatisch Indizes für alle vorhandenen und neuen Partitionen erstellt, die in Zukunft erstellt werden:
-- PG 11 ()
CREATE INDEX ON my_table (reg_date)
Dies ist nützlich, wenn Sie eine partitionierte Tabelle erstellen, jedoch nicht, wenn Sie einen neuen Index für eine vorhandene Tabelle erstellen, da der Befehl beim Erstellen der Indizes eine starke Sperre aktiviert.
CREATE INDEX ON my_table (name) --
Leider unterstützt CREATE INDEX das Schlüsselwort CONCURRENTLY für partitionierte Tabellen nicht. Um die Einschränkung zu umgehen und ohne Blockierung zu migrieren, haben Sie folgende Möglichkeiten.
- Erstellen Sie einen Index für die übergeordnete Tabelle mit der Option NUR
CREATE INDEX my_table_index ON ONLY my_table (name)
Der Befehl erstellt einen leeren ungültigen Index, ohne Indizes für die Partitionen zu erstellen . - Erstellen Sie Indizes für jede der Partitionen:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name); CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
- Fügen Sie Partitionsindizes zum Index der übergeordneten Tabelle hinzu:
ALTER INDEX my_table_index ATTACH PARTITION my_table_y2020_index; ALTER INDEX my_table_index ATTACH PARTITION my_table_y2021_index;
Einschränkungen
Lassen Sie uns nun die Einschränkungen durchgehen: NICHT NULL, Fremd-, Eindeutigkeits- und Primärschlüssel.
Erstellen einer NOT NULL-Einschränkung
ALTER TABLE my_table ALTER COLUMN name SET NOT NULL --
Wenn Sie auf diese Weise eine Einschränkung erstellen, wird die gesamte Tabelle durchsucht. Alle Zeilen werden auf die Nicht-Null-Bedingung überprüft. Wenn die Tabelle groß ist, kann dies lange dauern. Der starke Block, den dieser Befehl erfasst, blockiert alle gleichzeitigen Anforderungen, bis er abgeschlossen ist.
Was kann getan werden? PostgreSQL hat eine andere Art von Einschränkung, CHECK , mit der das gewünschte Ergebnis erzielt werden kann. Diese Einschränkung testet alle booleschen Bedingungen, die aus Zeilenspalten bestehen. In unserem Fall ist die Bedingung trivial -
CHECK (name IS NOT NULL)
. Am wichtigsten ist jedoch, dass die CHECK-Einschränkung die Ungültigmachung (Schlüsselwort
NOT VALID
) unterstützt:
ALTER TABLE my_table ADD CONSTRAINT chk_name_not_null
CHECK (name IS NOT NULL) NOT VALID -- , PG 9.2
Die auf diese Weise erstellte Einschränkung gilt nur für neu hinzugefügte und geänderte Datensätze, und vorhandene Datensätze werden nicht überprüft, sodass die Tabelle nicht gescannt wird.
Um sicherzustellen, dass die vorhandenen Datensätze auch die Einschränkung erfüllen, muss sie validiert werden (natürlich indem zuerst die Daten in der Tabelle aktualisiert werden):
ALTER TABLE my_table VALIDATE CONSTRAINT chk_name_not_null
Der Befehl durchläuft die Zeilen der Tabelle und überprüft, ob alle Datensätze nicht null sind. Im Gegensatz zur üblichen NOT NULL-Einschränkung ist die in diesem Befehl erfasste Sperre jedoch nicht so stark (ShareUpdateExclusive) - sie blockiert keine Einfüge-, Aktualisierungs- und Löschvorgänge.
Erstellen eines Fremdschlüssels
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) --
Wenn ein Fremdschlüssel hinzugefügt wird, werden alle Datensätze in der untergeordneten Tabelle auf einen Wert im übergeordneten Element überprüft. Wenn die Tabelle groß ist, ist dieser Scan lang und die Sperre für beide Tabellen ist ebenfalls lang.
Glücklicherweise unterstützen Fremdschlüssel in PostgreSQL auch NOT VALID, was bedeutet, dass wir den gleichen Ansatz verwenden können, der zuvor mit CHECK beschrieben wurde. Erstellen wir einen ungültigen Fremdschlüssel:
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) NOT VALID
dann aktualisieren wir die Daten und führen eine Validierung durch:
ALTER TABLE my_table VALIDATE CONSTRAINT fk_group_id
Erstellen Sie eine eindeutige Einschränkung
ALTER TABLE my_table ADD CONSTRAINT uk_my_table UNIQUE (id) --
Wie bei den zuvor diskutierten Einschränkungen erfasst der Befehl eine strikte Sperre, bei der alle Zeilen in der Tabelle anhand der Einschränkung überprüft werden - in diesem Fall der Eindeutigkeit.
Es ist wichtig zu wissen, dass PostgreSQL unter der Haube eindeutige Einschränkungen mithilfe eindeutiger Indizes erzwingt. Mit anderen Worten, wenn eine Einschränkung erstellt wird, wird ein entsprechender eindeutiger Index mit demselben Namen erstellt, um diese Einschränkung zu erfüllen. Mit der folgenden Abfrage können Sie den Serving-Index der Einschränkung ermitteln:
SELECT conindid index_oid, conindid::regclass index_name
FROM pg_constraint
WHERE conname = 'uk_my_table_id'
Zur gleichen Zeit, die für die meisten Zeitbeschränkungen beim Erstellen derselben verwendet wird, gilt dies für den Index und seine anschließende Bindung, um sehr schnell zu begrenzen. Wenn Sie bereits einen eindeutigen Index erstellt haben, können Sie dies selbst tun, indem Sie einen Index mit den Schlüsselwörtern USING INDEX erstellen:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id UNIQUE
USING INDEX uk_my_table_id -- , PG 9.1
Daher ist die Idee einfach: Wir erstellen KONZURRENT einen eindeutigen Index, wie wir zuvor besprochen haben, und erstellen dann basierend darauf eine eindeutige Einschränkung.
An dieser Stelle kann sich die Frage stellen , warum überhaupt eine Einschränkung erstellt wird, wenn der Index genau das tut, was erforderlich ist. Dies garantiert die Eindeutigkeit der Werte. Wenn wir ausschließen Teilindizes aus dem Vergleich , dann aus einem funktionalen Standpunkt aus gesehen, ist das Ergebnis wirklich fast identisch. Der einzige Unterschied, den wir festgestellt haben, besteht darin, dass Einschränkungen aufschiebbar sein können, Indizes jedoch nicht. Die Dokumentation für ältere Versionen von PostgreSQL (bis einschließlich 9.4) enthielt eine Fußnotemit der Information, dass der bevorzugte Weg zum Erstellen einer Eindeutigkeitsbeschränkung darin besteht, explizit eine Einschränkung zu erstellen
ALTER TABLE ... ADD CONSTRAINT
, und die Verwendung von Indizes sollte als Implementierungsdetail betrachtet werden. In neueren Versionen wurde diese Fußnote jedoch entfernt.
Primärschlüssel erstellen
Der Primärschlüssel ist nicht nur eindeutig, sondern legt auch die Nicht-Null-Einschränkung fest. Wenn die Spalte ursprünglich eine solche Einschränkung hatte, wird es nicht schwierig sein, sie in einen Primärschlüssel "umzuwandeln" - wir erstellen auch KONKURRENT einen eindeutigen Index und dann den Primärschlüssel:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id PRIMARY KEY
USING INDEX uk_my_table_id -- id is NOT NULL
Es ist wichtig zu beachten, dass die Spalte eine "faire" NOT NULL-Einschränkung haben muss - der zuvor diskutierte CHECK-Ansatz funktioniert nicht.
Wenn es keine Begrenzung gibt, ist bis zur 11. Version von PostgreSQL nichts zu tun - es gibt keine Möglichkeit, einen Primärschlüssel ohne Sperren zu erstellen.
Wenn Sie über PostgreSQL 11 oder höher verfügen, können Sie dazu eine neue Spalte erstellen, die die vorhandene ersetzt. Also Schritt für Schritt.
Erstellen Sie eine neue Spalte, die standardmäßig nicht null ist und einen Standardwert hat:
ALTER TABLE my_table ADD COLUMN new_id INTEGER NOT NULL DEFAULT -1 -- PG 11
Wir richten die Synchronisation der Daten der alten und neuen Spalte mit einem Trigger ein:
CREATE FUNCTION on_insert_or_update() RETURNS TRIGGER AS
$$
BEGIN
NEW.new_id = NEW.id;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg BEFORE INSERT OR UPDATE ON my_table
FOR EACH ROW EXECUTE PROCEDURE on_insert_or_update();
Als Nächstes müssen Sie die Daten für Zeilen aktualisieren, die vom Auslöser nicht betroffen waren:
UPDATE my_table SET new_id = id WHERE new_id = -1 --
Die Anfrage mit dem obigen Update steht "auf der Stirn", auf einem großen Tisch lohnt es sich nicht, dies zu tun, weil es wird eine lange Blockierung geben. Wie bereits erwähnt, befasst sich der zweite Artikel mit Ansätzen zum Aktualisieren großer Tabellen. Nehmen wir zunächst an, dass die Daten aktualisiert werden und nur noch die Spalten ausgetauscht werden müssen.
ALTER TABLE my_table RENAME COLUMN id TO old_id;
ALTER TABLE my_table RENAME COLUMN new_id TO id;
ALTER TABLE my_table RENAME COLUMN old_id TO new_id;
In PostgreSQL sind DDL-Befehle transaktional. Dies bedeutet, dass Sie Spalten umbenennen, hinzufügen und löschen können. Gleichzeitig wird dies bei einer parallelen Transaktion im Verlauf ihrer Operationen nicht angezeigt.
Nach dem Ändern der Spalten bleibt es, einen Index zu erstellen und "aufzuräumen" - den Trigger, die Funktion und die alte Spalte zu löschen.
Ein kurzer Spickzettel mit Migrationen
Vor jedem Befehl, der starke Sperren erfasst (fast alle
ALTER TABLE ...
), wird empfohlen, Folgendes aufzurufen:
SET LOCAL lock_timeout TO '100ms'
| Migration | Empfohlener Ansatz |
|---|---|
| Hinzufügen einer Spalte | |
| Hinzufügen einer Spalte mit einem Standardwert [und NICHT NULL] | mit PostgreSQL 11:
vor PostgreSQL 11:
|
| Eine Spalte entfernen |
|
| Indexerstellung | Wenn es fehlschlägt:
|
| Erstellen eines Index für eine partitionierte Tabelle | Partitionierung über Vererbung + Deklarativ in PG 10:
Deklarative Partitionierung mit PG 11:
|
| Erstellen einer NOT NULL-Einschränkung |
|
| Erstellen eines Fremdschlüssels |
|
| Erstellen Sie eine eindeutige Einschränkung |
|
| Primärschlüssel erstellen | Wenn die Spalte NICHT NULL ist:
Wenn die Spalte mit PG 11 NULL ist:
|
Im nächsten Artikel werden Ansätze zum Aktualisieren großer Tabellen vorgestellt.
Einfache Migrationen für alle!