
Der Datenfluss in dieser Tabelle ist etwas schwierig zu verfolgen. Hier ist eine äquivalente Tabelle, die die Tabelle als Grafik darstellt:

Rund um den El Farolito Super Vegi Burrito kosten 8 USD, also bei Lieferung Im Wert von 2 US-Dollar beträgt der Gesamtbetrag 20 US-Dollar.
Oh, ich habe es komplett vergessen! Einer meiner Freunde reicht nicht für einen Burrito, er braucht zwei. Also möchte ich wirklich drei bestellen. Bei einer Aktualisierung
Num Burritos
kann die naive Tabellenkalkulations-Engine das gesamte Dokument neu berechnen, indem sie zuerst die Zellen ohne Eingabe neu berechnet und dann jede Zelle mit der fertigen Eingabe neu berechnet, bis die Zellen leer sind. In diesem Fall berechnen wir zuerst den Burrito-Preis und die Burrito-Menge, dann den Versand-Burrito-Preis und dann einen neuen Gesamtbetrag von 30 USD.

Diese einfache Strategie zur Neuberechnung eines gesamten Dokuments mag verschwenderisch erscheinen, ist aber tatsächlich besser als VisiCalc, die ersten Tabellenkalkulationen in der Geschichte und die erste sogenannte Killer-App, die Apple II-Computer populär gemacht hat. VisiCalc berechnete die Zellen viele Male von links nach rechts und von oben nach unten neu und scannte sie immer wieder, obwohl sich keine von ihnen geändert hatte. Trotz dieses "interessanten" Algorithmus blieb VisiCalc vier Jahre lang die dominierende Tabellenkalkulationssoftware. Seine Regierungszeit endete 1983, als Lotus 1-2-3 den Markt für die Neuberechnung natürlicher Ordnung übernahm. So beschrieb ihn Tracy Robnett Licklider in der Zeitschrift Byte :
Lotus 1-2-3 verwendete die natürliche Reihenfolge, unterstützte jedoch auch den Zeilen- und Spaltenmodus von VisiCalc. Die natürliche Neuberechnung führte eine Liste von Zellabhängigkeiten und neu berechneten Zellen basierend auf Abhängigkeiten.
Lotus 1-2-3 implementierte die oben gezeigte Strategie zur Neuberechnung aller Strategien. Während des ersten Jahrzehnts der Tabellenkalkulationsentwicklung war dies der optimalste Ansatz. Ja, wir berechnen jede Zelle im Dokument neu, aber nur einmal.
Aber was ist mit dem Preis eines Liefer-Burritos?
Ja wirklich. In meinem Beispiel für drei Burritos gibt es keinen Grund, den Preis eines Burritos mit Lieferung neu zu berechnen, da eine Änderung der Burrito-Menge in der Bestellung den Preis des Burritos nicht beeinflussen kann. 1989 fand einer der Konkurrenten von Lotus dies heraus und entwickelte SuperCalc5, das vermutlich nach der Super-Burrito-Theorie hinter dem Algorithmus benannt wurde. SuperCalc5 berechnete "nur Zellen, die von den geänderten Zellen abhängen" neu. Die Aktualisierung der Burrito-Anzahl war also ungefähr so:
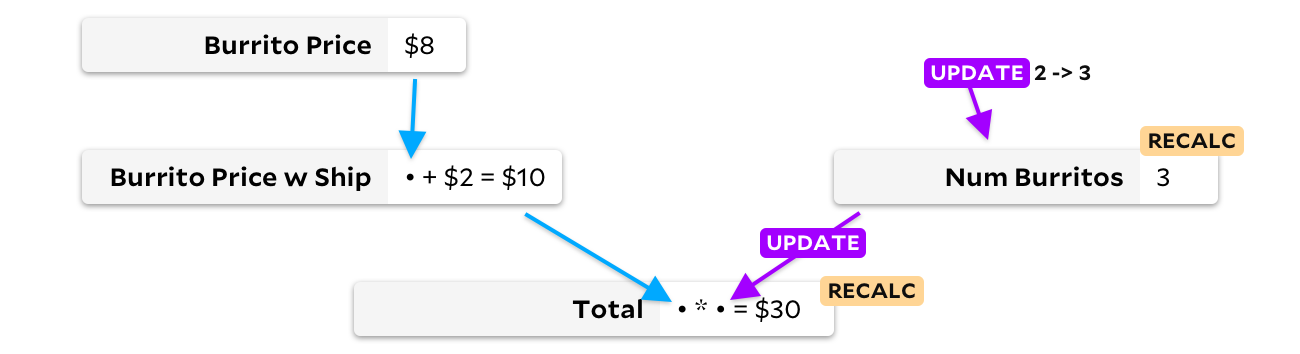
Indem wir die Zelle nur aktualisieren, wenn sich die Eingabedaten ändern, können wir vermeiden, den Preis des Burritos bei Lieferung neu zu berechnen. In diesem Fall sparen wir nur einen Zusatz, aber in großen Tabellen können die Einsparungen viel bedeutender sein! Leider haben wir jetzt ein anderes Problem. Nehmen wir an, meine Freunde wollen jetzt Fleischburritos, die einen Dollar teurer sind, und El Farolito fügt ihrer Bestellung 2 Dollar hinzu, unabhängig von der Anzahl der Burritos. Bevor wir etwas neu berechnen, schauen wir uns die Grafik an:
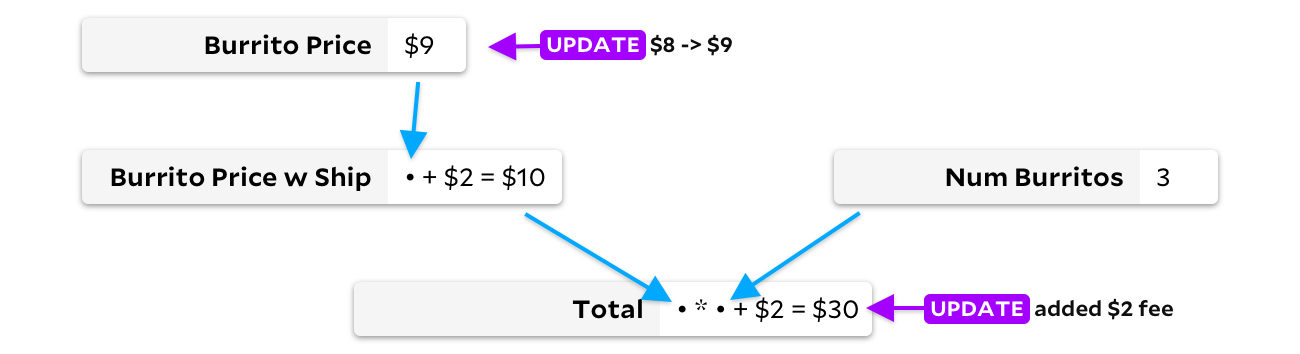
Da hier zwei Zellen aktualisiert werden, haben wir ein Problem. Sollten Sie zuerst den Preis eines Burritos oder den Gesamtbetrag neu berechnen? Im Idealfall berechnen wir zuerst den Burrito-Preis, bemerken die Änderung, berechnen dann den Versand-Burrito-Preis neu und berechnen schließlich den Gesamtbetrag neu. Wenn wir jedoch stattdessen zuerst die Gesamtsumme neu berechnen, müssten wir sie ein zweites Mal neu berechnen, sobald sich der neue Burrito-Preis von 9 USD auf die Zellen ausbreitet. Wenn wir die Zellen nicht in der richtigen Reihenfolge berechnen, ist dieser Algorithmus nicht besser als die Neuberechnung des gesamten Dokuments. In einigen Fällen so langsam wie VisiCalc!
Natürlich ist es für uns wichtig, die richtige Reihenfolge für die Aktualisierung der Zellen zu bestimmen. Im Allgemeinen gibt es zwei Lösungen für dieses Problem: Schmutzmarkierung und topologische Sortierung.
Die erste Lösung beinhaltet das Markieren aller Zellen stromabwärts der aktualisierten Zelle. Sie sind als schmutzig gekennzeichnet. Wenn wir beispielsweise den Preis eines Burritos aktualisieren, markieren wir die nachgeschalteten Zellen
Burrito Price w Ship
und
Total
bevor wir eine Neuberechnung durchführen:
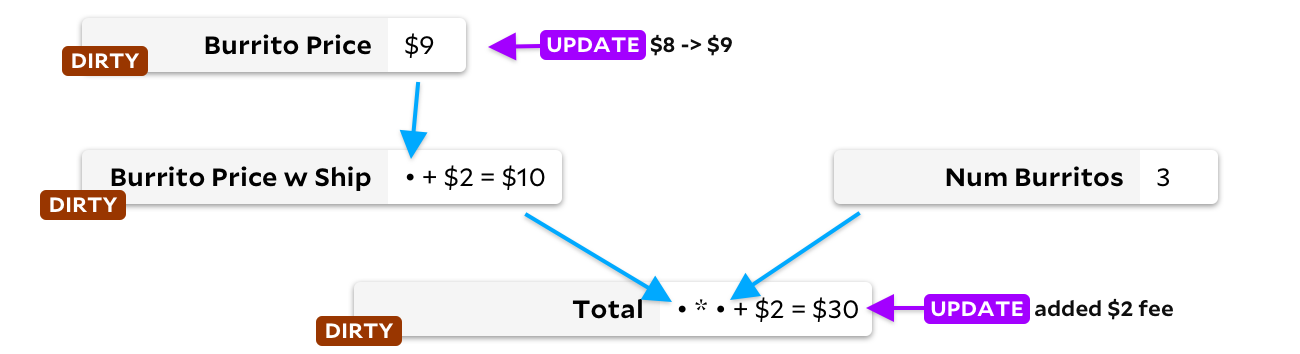
Dann finden wir in einer Schleife eine schmutzige Zelle ohne schmutzige Eingaben - und berechnen sie neu. Wenn keine schmutzigen Zellen mehr vorhanden sind, sind wir fertig! Dies löst unser Abhängigkeitsproblem. Es gibt jedoch einen Nachteil: Wenn die Zelle neu berechnet wird und wir feststellen, dass das neue Ergebnis das gleiche wie das vorherige ist, werden die untergeordneten Zellen immer noch neu berechnet! Ein wenig zusätzliche Logik hilft, das Problem zu vermeiden, aber leider verbringen wir immer noch Zeit damit, Zellen zu markieren und Markierungen zu entfernen.
Die zweite Lösung ist die topologische Sortierung. Wenn eine Zelle keine Eingabe hat, markieren wir ihre Höhe als 0. Wenn dies der Fall ist, markieren wir die Höhe als maximale Höhe der Eingabezellen plus eins. Dies stellt sicher, dass jede Zelle einen größeren Höhenwert als jede der eingehenden Zellen hat. Daher verfolgen wir einfach alle Zellen mit der geänderten Eingabe und wählen immer die Zelle mit der niedrigsten Höhe aus, die zuerst neu berechnet werden soll:
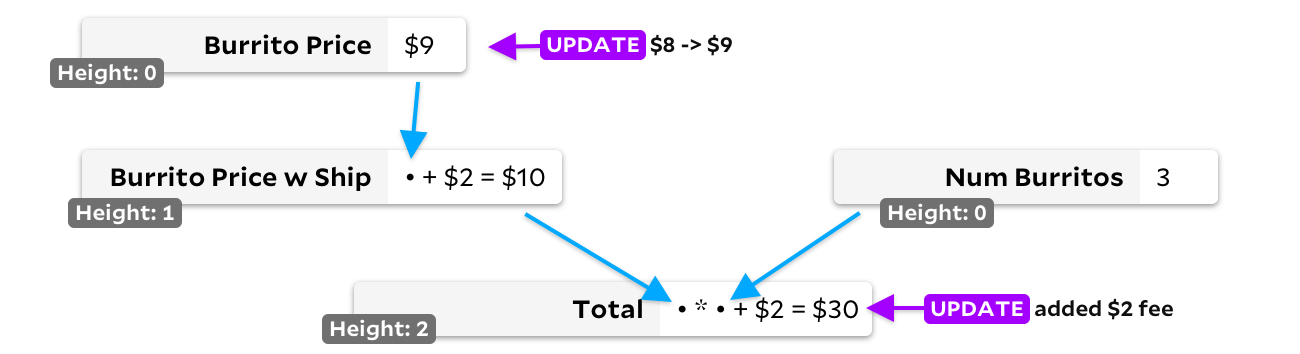
In unserem Beispiel für doppelte Aktualisierung den Preis für den Burrito und Der Gesamtbetrag wird zunächst zum Conversion-Heap hinzugefügt. Der Burrito-Preis ist niedriger und wird zuerst neu berechnet. Da sich das Ergebnis geändert hat, werden wir den Preis des Liefer-Burritos zum Neuberechnungshaufen hinzufügen, und da er auch eine kürzere Höhe als hat
Total
dann wird es neu berechnet, bevor wir endlich erzählen
Total
.
Dies ist viel besser als die erste Lösung: Keine Zelle wird als verschmutzt markiert, es sei denn, eine der eingehenden Zellen ändert sich wirklich. Dies erfordert jedoch das Speichern von Zellen in sortierter Reihenfolge bis zur Neuberechnung. Bei Verwendung auf dem Heap führt dies zu einer Verlangsamung
O(n log n)
, die im schlimmsten Fall asymptotisch langsamer ist als die neu berechnete Lotus 1-2-3-Strategie.
Modernes Excel verwendet eine Kombination aus Kontamination und topologischer Sortierung . Weitere Informationen finden Sie in der Dokumentation.
Faule Bewertung
Wir haben jetzt die Neuberechnungsalgorithmen in modernen Tabellenkalkulationen mehr oder weniger erreicht. Ich vermute, dass es im Prinzip leider keine geschäftliche Rechtfertigung für weitere Verbesserungen gibt. Die Leute haben bereits genug Excel-Formeln geschrieben, um eine Migration auf eine andere Plattform unmöglich zu machen. Glücklicherweise bin ich nicht geschäftstüchtig, daher werden wir trotzdem weitere Verbesserungen in Betracht ziehen.
Neben dem Caching besteht einer der interessanten Aspekte eines Berechnungsdiagramms im Tabellenkalkulationsstil darin, dass wir nur die Zellen berechnen können, an denen wir interessiert sind. Dies wird manchmal als verzögerte Bewertung oder bedarfsgesteuerte Berechnung bezeichnet. Als genaueres Beispiel sehen Sie hier ein leicht erweitertes Burrito-Tabellenkalkulationsdiagramm. Das Beispiel ist das gleiche wie zuvor, aber wir haben hinzugefügt, was am besten als "Salsa-Berechnung" beschrieben wird. Jeder Burrito enthält 40 Gramm Salsa und wir multiplizieren schnell, um herauszufinden, wie viel Salsa in der gesamten Bestellung enthalten ist. Da wir drei Burritos in unserer Bestellung haben, gibt es insgesamt 120 Gramm Salsa.

Anspruchsvolle Leser haben das Problem natürlich bereits bemerkt: Das Gesamtgewicht von Salsa in einer Bestellung ist eine ziemlich nutzlose Metrik. Wen interessiert es, wenn es 120 Gramm sind? Was soll ich mit diesen Informationen machen? Leider verbringt eine typische Tabelle Zyklen mit Salsa-Berechnungen, auch wenn wir diese Berechnungen die meiste Zeit nicht benötigen.
Hier kann eine faule Neuberechnung helfen. Wenn wir irgendwie darauf hinweisen, dass wir nur am Ergebnis interessiert sind
Total
, könnten wir diese Zelle und ihre Abhängigkeiten neu berechnen und die Salsa nicht berühren. Nennen wir es eine
Total
beobachtete Zelle, während wir versuchen, das Ergebnis zu betrachten. Wir können auch
Total
drei seiner Abhängigkeiten als notwendig bezeichnen.Zellen, da sie benötigt werden, um einige beobachtete Zellen zu berechnen.
Salsa In Order
und
Salsa Per Burrito
nenne es unnötig .
Um dieses Problem zu lösen, haben einige der Rust-Teamkollegen das Salsa- Framework erstellt und es explizit nach der unnötigen Salsa-Berechnung benannt, die ihre Computerzyklen verschwendet hat. Sicher können sie besser als ich erklären, wie es funktioniert. Sehr grob verwendet das Framework Revisionsnummern, um zu verfolgen, ob eine Zelle neu berechnet werden muss. Jede Mutation in einer Formel oder Eingabe erhöht die globale Revisionsnummer, und jede Zelle verfolgt zwei Revisionen:
verified_at
für die Revision, deren Ergebnis aktualisiert wurde, und
changed_at
für die Revision, deren Ergebnis tatsächlich geändert wurde.
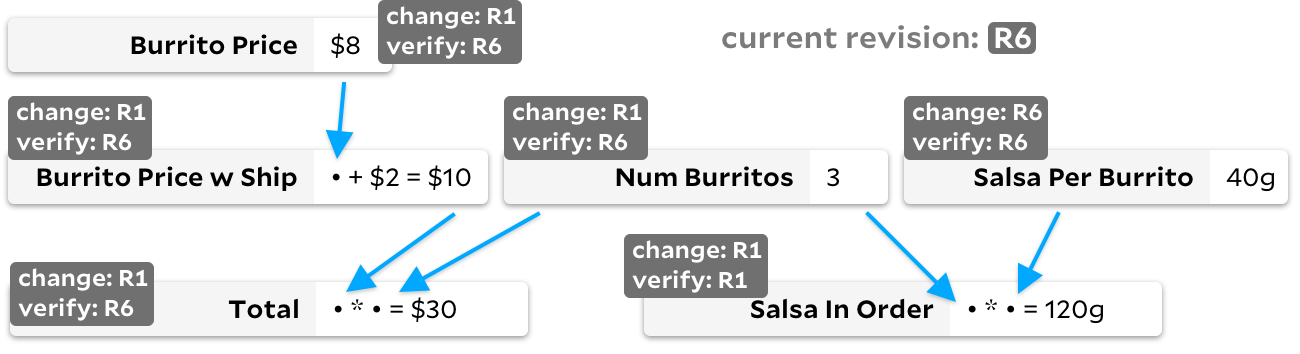
Wenn der Benutzer angibt, dass er einen neuen Wert
Total
benötigt
Total
, berechnen wir zunächst rekursiv alle dafür erforderlichen Zellen neu und überspringen die Zellen, bei denen die Revision
last_updated
der globalen Revision entspricht. Sobald die Abhängigkeiten
Total
aktualisiert wurden, führen wir die tatsächliche Formel
Total
nur dann erneut aus, wenn entweder Burrito Price w Ship oder eine
Num Burrito
Revision
changed_at
größer als die überprüfte Revision ist
Total
... Dies ist ideal für Salsa im Rostanalysator, bei dem Einfachheit wichtig ist und die Berechnung jeder Zelle zeitaufwändig ist. In der Grafik mit dem obigen Burrito können Sie jedoch die Nachteile feststellen. Wenn sich der Burrito
Salsa Per Burrito
ständig ändert, erhöht sich häufig unsere globale Versionsnummer. Infolgedessen
Total
würde jede Beobachtung das Durchlaufen von drei Zellen erfordern, selbst wenn sich keine von ihnen änderte. Es werden keine Formeln neu berechnet. Wenn der Graph jedoch groß ist, kann das Durchlaufen aller Zellabhängigkeiten kostspielig sein.
Schnellere Optionen für eine verzögerte Bewertung
Anstatt neue faule Algorithmen zu erfinden, probieren wir die beiden zuvor erwähnten klassischen Tabellenkalkulationsalgorithmen aus: Beschriftung und topologische Sortierung. Wie Sie sich vorstellen können, erschwert das faule Modell diese beiden Aufgaben, aber beide sind immer noch realisierbar.
Schauen wir uns zuerst die Markierungen an. Wenn wir nach wie vor die Formel einer Zelle ändern, markieren wir alle nachgeschalteten Zellen als verschmutzt. Beim Aktualisieren
Salsa Per Burrito
sieht es also ungefähr so aus:

Anstatt alle verschmutzten Zellen sofort neu zu berechnen , warten wir, bis der Benutzer die Zelle beobachtet. Dann führen wir den Salsa-Algorithmus darauf aus, anstatt die Abhängigkeiten mit veralteten Versionsnummern erneut zu überprüfen
verified_at
Wir überprüfen nur Zellen, die als verschmutzt markiert sind. Adapton verwendet diese Technik . In einer solchen Situation zeigt die Beobachtung der Zelle
Total
, dass sie nicht verschmutzt ist, und daher können wir den Diagrammdurchlauf überspringen, den Salsa durchgeführt hätte!
Wenn Sie es beobachten
Salsa In Order
, wird es als schmutzig markiert, und daher werden wir und und
Salsa Per Burrito
und erneut prüfen und neu berechnen
Salsa In Order
. Auch hier gibt es Vorteile gegenüber der Verwendung nur von Revisionsnummern, da wir rekursiv durch eine noch leere Zelle springen können
Num Burritos
.
Lazy Dirty Labeling funktioniert fantastisch, wenn es darum geht, die Zellen, die wir beobachten möchten, häufig zu ändern. Leider hat es die gleichen Nachteile wie der vorherige Algorithmus für schmutzige Markierungen. Wenn sich eine Zelle mit vielen nachgeschalteten Zellen ändert, verbringen wir viel Zeit damit, die Zellen zu kennzeichnen und zu entfernen, auch wenn sich die Eingabe bei der Neuberechnung nicht tatsächlich ändert. Im schlimmsten Fall führt jede Änderung dazu, dass wir den gesamten Graphen als verschmutzt markieren, was ungefähr die gleiche Leistungsreihenfolge wie der Salsa-Algorithmus ergibt.
Zusätzlich zur unordentlichen Kennzeichnung können wir auch die topologische Sortierung für eine verzögerte Bewertung anpassen. Diese Methode verwendet die inkrementelle Bibliothek von der Jane Street, und es braucht einige ernsthafte Tricks, um es richtig zum Laufen zu bringen. Vor der Implementierung der verzögerten Auswertung verwendete unser topologischer Sortieralgorithmus einen Heap, um zu bestimmen, welche Zelle als nächstes neu berechnet werden soll. Aber jetzt wollen wir nur die Zellen neu berechnen, die benötigt werden. Wie? Wir möchten nicht wie Adapton den gesamten Baum von den beobachteten Zellen aus laufen lassen, da ein vollständiger Spaziergang durch den Baum den gesamten Zweck der topologischen Sorte zerstört und uns ähnliche Leistungsmerkmale wie Adapton verleiht.
Stattdessen verwaltet Incremental eine Reihe von Zellen, die der Benutzer als überwacht markiert hat, sowie die Gruppe von Zellen, die für jede überwachte Zelle erforderlich sind. Immer wenn eine Zelle als beobachtbar oder nicht beobachtbar markiert ist, durchläuft Incremental die Abhängigkeiten dieser Zelle, um sicherzustellen, dass die erforderlichen Beschriftungen korrekt angewendet werden. Dann fügen wir dem Neuberechnungshaufen nur dann Zellen hinzu, wenn sie nach Bedarf markiert sind. In unserem Burrito-Diagramm führt
Total
die Änderung , solange sie Teil eines beobachtbaren Satzes ist, zu
Salsa in Order
keinem Durchgang durch das Diagramm, da nur die erforderlichen Zellen neu berechnet werden:

Dies löst unser Problem, ohne eifrig durch das Diagramm zu gehen, um Zellen als schmutzig zu markieren! Wir müssen uns noch daran erinnern, dass die Zelle
Salsa per Burrito
Es ist chaotisch, später bei Bedarf zu erzählen. Im Gegensatz zu Adaptons Algorithmus müssen wir dieses einzelne schmutzige Etikett jedoch nicht über das gesamte Diagramm verschieben.
Anker, eine Hybridlösung
Sowohl Adapton als auch Incremental durchlaufen den Graphen, auch wenn sie keine Zellen neu berechnen. Inkrementell geht das Diagramm nach oben, wenn sich die Menge der beobachteten Zellen ändert, und Adapton geht das Diagramm nach unten, wenn sich die Formel ändert. Bei kleinen Grafiken sind die hohen Kosten dieser Durchgänge möglicherweise nicht sofort ersichtlich. Wenn das Diagramm jedoch groß ist und die Zellen relativ billig zu berechnen sind - häufig ist dies bei Tabellenkalkulationen der Fall -, werden Sie feststellen, dass der größte Teil der Berechnung durch unnötiges Herumlaufen des Diagramms verschwendet wird! Wenn Zellen billig sind, kann das Markieren eines Teils auf einer Zelle ungefähr das gleiche kosten wie das einfache Neuberechnen einer Zelle von Grund auf neu. Wenn unser Algorithmus daher wesentlich schneller als eine einfache Berechnung sein soll, sollten wir daher im Idealfall vermeiden, dass Sie so weit wie möglich unnötig im Diagramm herumlaufen.
Je mehr ich über dieses Problem nachdachte, desto mehr wurde mir klar, dass sie Zeit damit verschwenden, das Diagramm in ungefähr entgegengesetzten Situationen zu durchlaufen. Stellen wir uns in unserem Burrito-Diagramm vor, dass sich die Zellformeln selten ändern, aber wir wechseln schnell und beobachten zuerst
Total
und dann
Salsa in Order
.
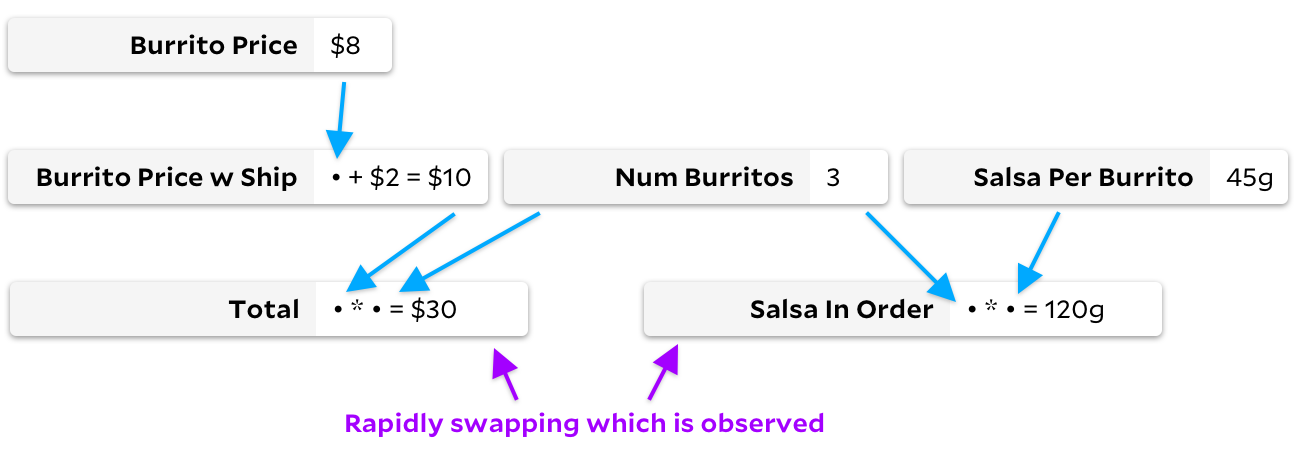
In diesem Fall geht Adapton nicht über den Baum. Keine der Eingabedaten ändert sich und daher müssen wir keine Zellen markieren. Da nichts markiert ist, ist jede Beobachtung billig, da wir den zwischengespeicherten Wert sofort aus einer leeren Zelle zurückgeben können. Incremental funktioniert in diesem Beispiel jedoch nicht gut. Obwohl keine Werte neu berechnet werden, markiert und deaktiviert Incremental wiederholt viele Zellen als erforderlich oder unnötig.
Stellen wir uns andernfalls ein Diagramm vor, in dem sich unsere Formeln schnell ändern, die Liste der beobachteten Zellen jedoch nicht. Zum Beispiel könnten wir uns vorstellen , sie gerade
Total
aus durch schnelles Ändern des Preises eines Burrito
4+4
zu
2*4
.
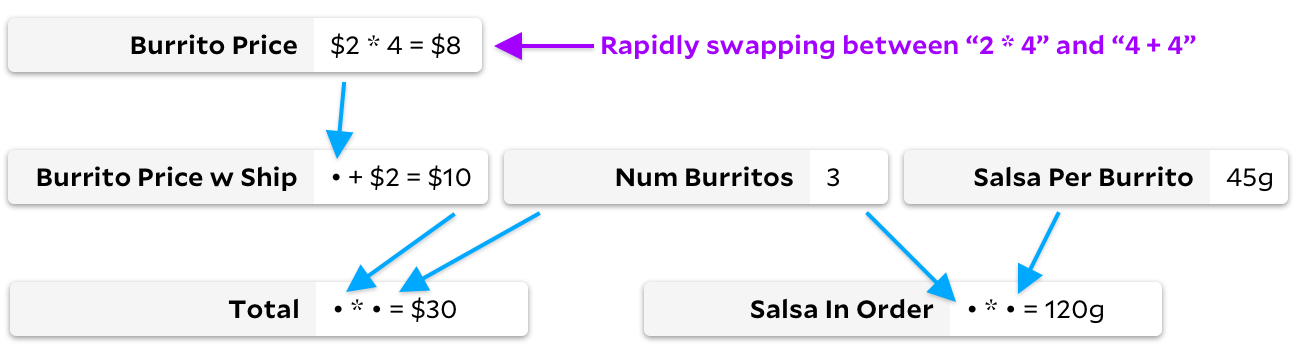
Wie im vorherigen Beispiel berechnen wir nicht viele Zellen neu:
4+4
und
2*4
gleich
8
Im Idealfall berechnen wir diese Arithmetik nur neu, wenn der Benutzer diese Änderung vornimmt. Im Gegensatz zum vorherigen Beispiel vermeidet Incremental jetzt das Gehen mit Bäumen. Mit Incremental haben wir die Tatsache zwischengespeichert, dass der Burrito-Preis eine notwendige Zelle ist. Wenn er sich ändert, können wir ihn neu berechnen, ohne das Diagramm durchzugehen. Mit Adapton verschwenden wir Zeit mit dem Markieren
Burrito Price w Ship
und
Total
wie chaotisch, auch wenn sich das Ergebnis
Burrito Price
nicht ändert.
Angesichts der Tatsache, dass jeder Algorithmus in den entarteten Fällen des anderen gut funktioniert, warum nicht idealerweise nur diese entarteten Fälle erkennen und zu einem schnelleren Algorithmus wechseln? Dies habe ich versucht, in meiner eigenen Bibliothek zu implementieren Anker . Es werden beide Algorithmen gleichzeitig auf demselben Diagramm ausgeführt! Wenn es verrückt, unnötig und zu kompliziert klingt, liegt es wahrscheinlich daran, dass es so ist.
In vielen Fällen folgen Anker genau dem inkrementellen Algorithmus, wodurch der obige entartete Adapton-Fall vermieden wird. Wenn Zellen jedoch als nicht beobachtbar markiert sind, unterscheidet sich ihr Verhalten geringfügig. Mal sehen, was los ist. Beginnen wir damit, es
Total
als beobachtete Zelle zu
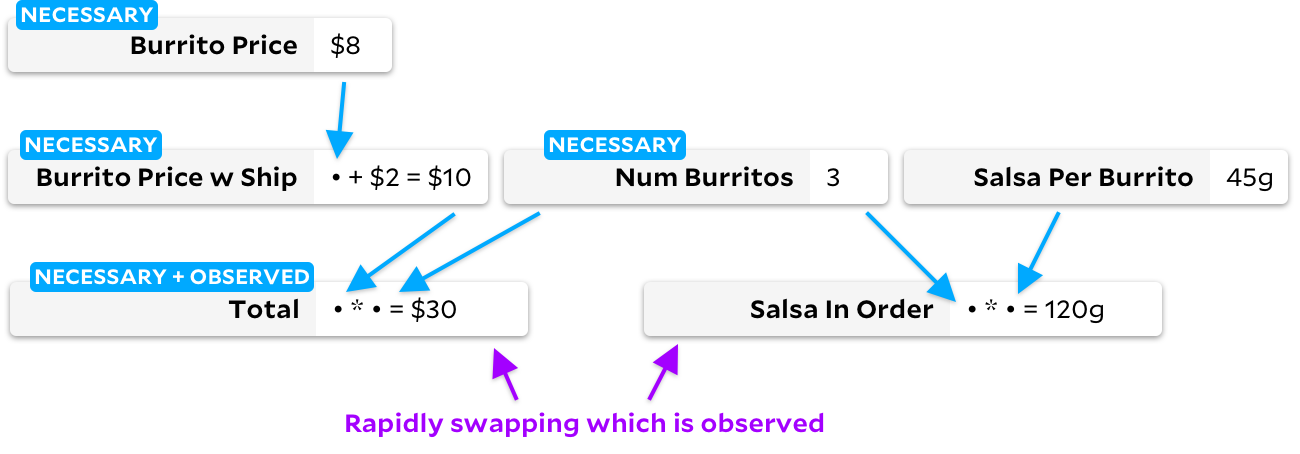
markieren : Wenn Sie es dann
Total
als nicht beobachtbare Zelle und
Salsa in Order
als beobachtbare Zelle markieren, ändert der traditionelle inkrementelle Algorithmus das Diagramm und durchläuft alle Zellen im Prozess:
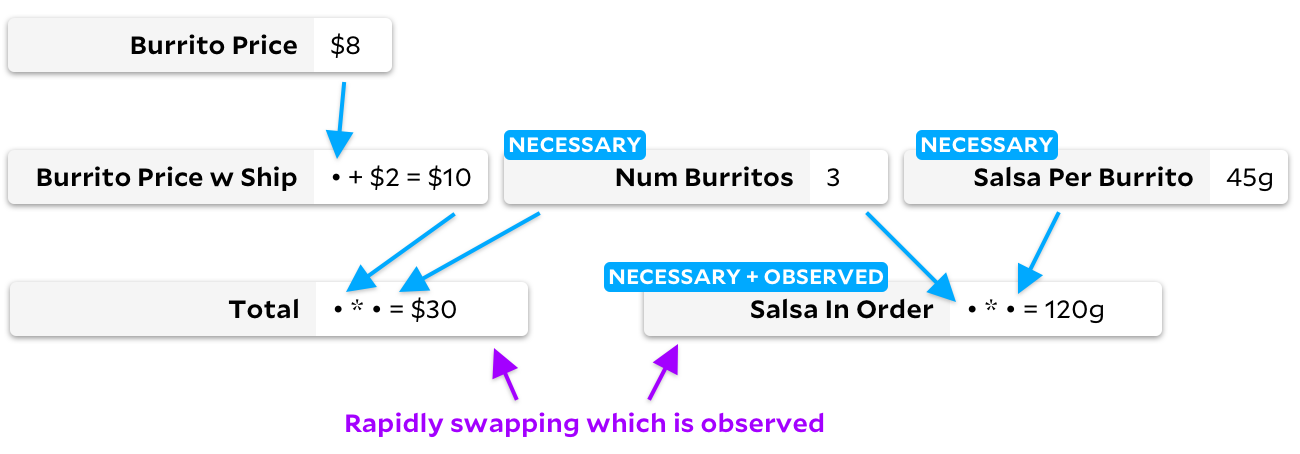
Anker für diese Änderung durchlaufen auch alle Zellen, erstellen jedoch ein anderes Diagramm:
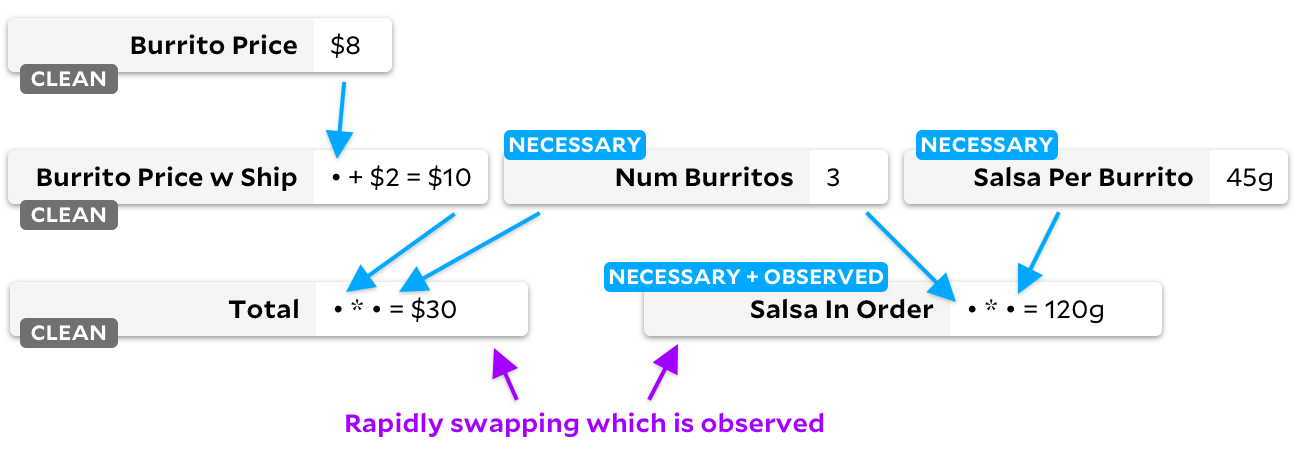
Achten Sie auf die Flaggen der "sauberen" Zellen! Wenn eine Zelle nicht mehr benötigt wird, markieren wir sie als leer. Mal sehen, was passiert, wenn wir von der Beobachtung
Salsa in Order
zu folgen
Total
:
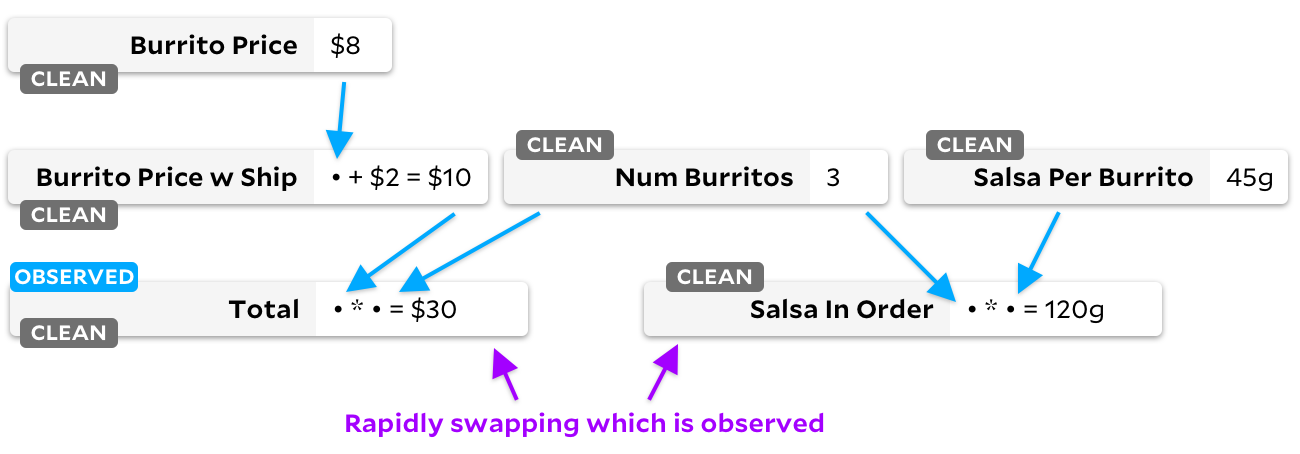
Richtig - unser Diagramm enthält jetzt keine "notwendigen" Zellen. Wenn eine Zelle ein "sauberes" Flag hat, markieren wir es niemals als beobachtbar. Unabhängig davon, welche Zelle wir als beobachtet oder unbeobachtet markieren, verschwenden Anker von nun an keine Zeit mehr damit, durch die Grafik zu gehen - sie weiß, dass sich keine der Eingaben geändert hat.
El Farolito hat anscheinend einen Rabatt angekündigt! Lassen Sie uns den Preis des Burritos um einen Dollar senken. Woher weiß Anchors, wie man den Betrag neu berechnet? Lassen Sie uns vor jeder Neuberechnung sehen, wie Anchors das Diagramm unmittelbar nach der Änderung des Burrito-Preises sieht:

Wenn die Zelle ein klares Flag aufweist, führen wir den traditionellen Adapton-Algorithmus darauf aus und markieren die nachgeschalteten Zellen bereitwillig als verschmutzt. Wenn wir später den inkrementellen Algorithmus ausführen, können wir schnell feststellen, dass es eine beobachtbare Zelle gibt, die als verschmutzt markiert ist, und wir wissen, dass wir ihre Abhängigkeiten neu berechnen müssen. Das endgültige Diagramm sieht folgendermaßen aus:
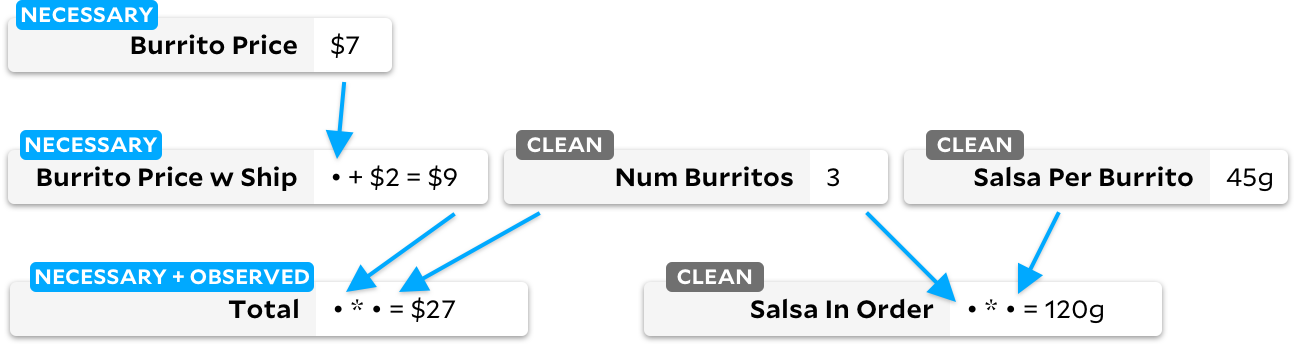
Wir berechnen Zellen nur bei Bedarf neu. Wenn wir also eine verschmutzte Zelle neu berechnen, markieren wir sie auch als erforderlich. Auf hoher Ebene können Sie sich diese drei Zustände von Zellen als eine zyklische Zustandsmaschine vorstellen:

Führen Sie auf den erforderlichen Zellen den inkrementellen topologischen Sortieralgorithmus aus. Im Übrigen führen wir den Adapton-Algorithmus aus.
Burrito-Syntax
Abschließend möchte ich die letzte Frage beantworten: Bisher haben wir viele Probleme diskutiert, die das Lazy-Modell für unsere Strategie zur Neuberechnung von Tabellen verursacht. Die Probleme liegen aber nicht nur im Algorithmus, sondern auch in syntaktischen Problemen. Stellen wir zum Beispiel eine Tabelle zusammen, um einen Emoji-Burrito für unseren Kunden auszuwählen. Wir möchten eine Erklärung schreiben ,
IF
in einer Tabelle wie folgt aus :

Da herkömmliche Tabellen nicht faul sind, können wir berechnen
B1
,
B2
und
B3
in beliebiger Reihenfolge, und berechnen dann die Zelle
IF
... Wenn wir jedoch in einer faulen Welt zuerst den Wert von B1 berechnen können, können wir anhand des Ergebnisses herausfinden, welcher Wert neu berechnet werden muss - B2 oder B3. Leider können herkömmliche Tabellenkalkulationen
IF
dies nicht ausdrücken!
Problem:
B2
Verweist gleichzeitig auf eine Zelle
B2
und ruft deren Wert ab. Die meisten der im Artikel erwähnten Lazy Libraries unterscheiden stattdessen explizit zwischen einem Verweis auf eine Zelle und dem Abrufen ihres tatsächlichen Werts. In Anchors bezeichnen wir diese Zellreferenz als Anker. Genau wie im wirklichen Leben wickelt ein Burrito eine Reihe von Zutaten zusammen, eine Art
Anchor<T>
Wraps
T
. Also ich denke unsere vegane Burritozelle wird
Anchor<Burrito>
, eine Art lächerlicher Burrito Burrito. Funktionen können unsere
Anchor<Burrito>
so viel übertragen, wie sie wollen. Wenn sie den Burrito jedoch tatsächlich auspacken, um auf das
Burrito
Innere zuzugreifen , erstellen wir eine Abhängigkeitskante in unserem Diagramm, die dem Neuberechnungsalgorithmus anzeigt, dass die Zelle möglicherweise benötigt wird und neu berechnet werden muss.
Der Ansatz von Salsa und Adapton besteht darin, Funktionsaufrufe und einen normalen Kontrollfluss zu verwenden, um diese Werte zu erweitern. In Adapton könnten wir beispielsweise die Burrito for Customer-Zelle wie folgt schreiben:
let burrito_for_customer = cell!({
if get!(is_vegetarian) {
get!(vegi_burrito)
} else {
get!(meat_burrito)
}
});
Durch die Unterscheidung zwischen einer Zellreferenz (hier
vegi_burrito
) und der Erweiterung ihres Werts (
get!
) kann Adapton auf Rust-Kontrollflussanweisungen wie z
if
. Dies ist eine großartige Lösung! Es erfordert jedoch ein wenig magischen globalen Status, um Anrufe beim Ändern ordnungsgemäß
get!
an Zellen zu
cell!
leiten
is_vegetarian
. Die inkrementell beeinflusste Anchors-Bibliothek verfolgt einen weniger magischen Ansatz. Wie bei async-pre / await
Future
ermöglicht Anchors das Starten von
Anchor<T>
Vorgängen wie
map
und
then
. Das obige Beispiel würde also ungefähr so aussehen:
let burrito_for_customer: Anchor<Burrito> = is_vegetarian.then(|is_vegetarian: bool| -> Anchor<Burrito> {
if is_vegetarian {
vegi_burrito
} else {
meat_burrito
}
});
Weiterführende Literatur
In diesem bereits langen und floriden Artikel war nicht genug Platz für so viele Themen. Hoffentlich können diese Ressourcen etwas mehr Licht in dieses sehr interessante Problem bringen.
- Sieben Implementierungen von Incremental , ein detaillierter Blick auf die Interna von Incremental sowie eine Reihe von Optimierungen wie ständig steigende Höhen, über die ich keine Zeit hatte zu sprechen, sowie clevere Methoden zum Umgang mit Zellen, die Abhängigkeiten ändern. Auch lesenswert von Ron Minsky: FRP Parsing .
- Video erklärt, wie Salsa funktioniert.
- Dies ist ein Salsa-Ticket, bei dem Matthew Hammer, der Erfinder von Adapton, einem zufälligen Passanten (mir), der keine Ahnung hat, wie sie funktionieren, geduldig die Grenzwerte erklärt.
- Rustlab . , « » «: DX CS» — .
- , « », Materialize. , . , (!) « », , . Noira .
- Adapton .
- Es stellt sich heraus, dass diese Denkweise auch für Build-Systeme gilt . Dies ist einer der ersten wissenschaftlichen Artikel über die Ähnlichkeiten zwischen Build-Systemen und Tabellenkalkulationen.
- Etwas inkrementelles Ray Tracing ist ein leicht inkrementeller Ray Tracer, der in Ocaml geschrieben wurde.
- Ich habe gerade "Teilzustand in materialisierten Ansichten basierend auf dem Datenfluss" betrachtet und es scheint relevant zu sein.
- Skip und Imp sehen auch sehr interessant aus.
Und natürlich können Sie jederzeit mein Anchors- Framework überprüfen .