Hallo! Mein Name ist Dmitry Shelamov und ich arbeite bei Vivid.Money als Backend-Entwickler in der Kundendienstabteilung. Unser Unternehmen ist ein europäisches Startup, das Internetbanking-Dienste für europäische Länder erstellt und entwickelt. Dies ist eine ehrgeizige Aufgabe, was bedeutet, dass für die technische Implementierung eine durchdachte Infrastruktur erforderlich ist, die hohen Belastungen standhält und den Geschäftsanforderungen entspricht.
Das Projekt basiert auf einer Microservice-Architektur, die Dutzende von Services in verschiedenen Sprachen umfasst. Dazu gehören Scala, Java, Kotlin, Python und Go. In letzterem schreibe ich den Code, daher verwenden die praktischen Beispiele in dieser Reihe hauptsächlich Go (und ein wenig Docker-Compose).
Die Arbeit mit Microservices hat ihre eigenen Merkmale, darunter die Organisation der Kommunikation zwischen Diensten. Das Interaktionsmodell in diesen Kommunikationen kann synchron oder asynchron sein und einen erheblichen Einfluss auf die Leistung und Fehlertoleranz des gesamten Systems haben.
Asynchrone Kommunikation
Stellen wir uns also vor, wir haben zwei Mikrodienste (A und B). Wir gehen davon aus, dass die Kommunikation zwischen ihnen über die API erfolgt und sie nichts über die interne Implementierung voneinander wissen, wie dies durch den Microservice-Ansatz vorgeschrieben ist. Das Format der zwischen ihnen übertragenen Daten ist im Voraus vereinbart.
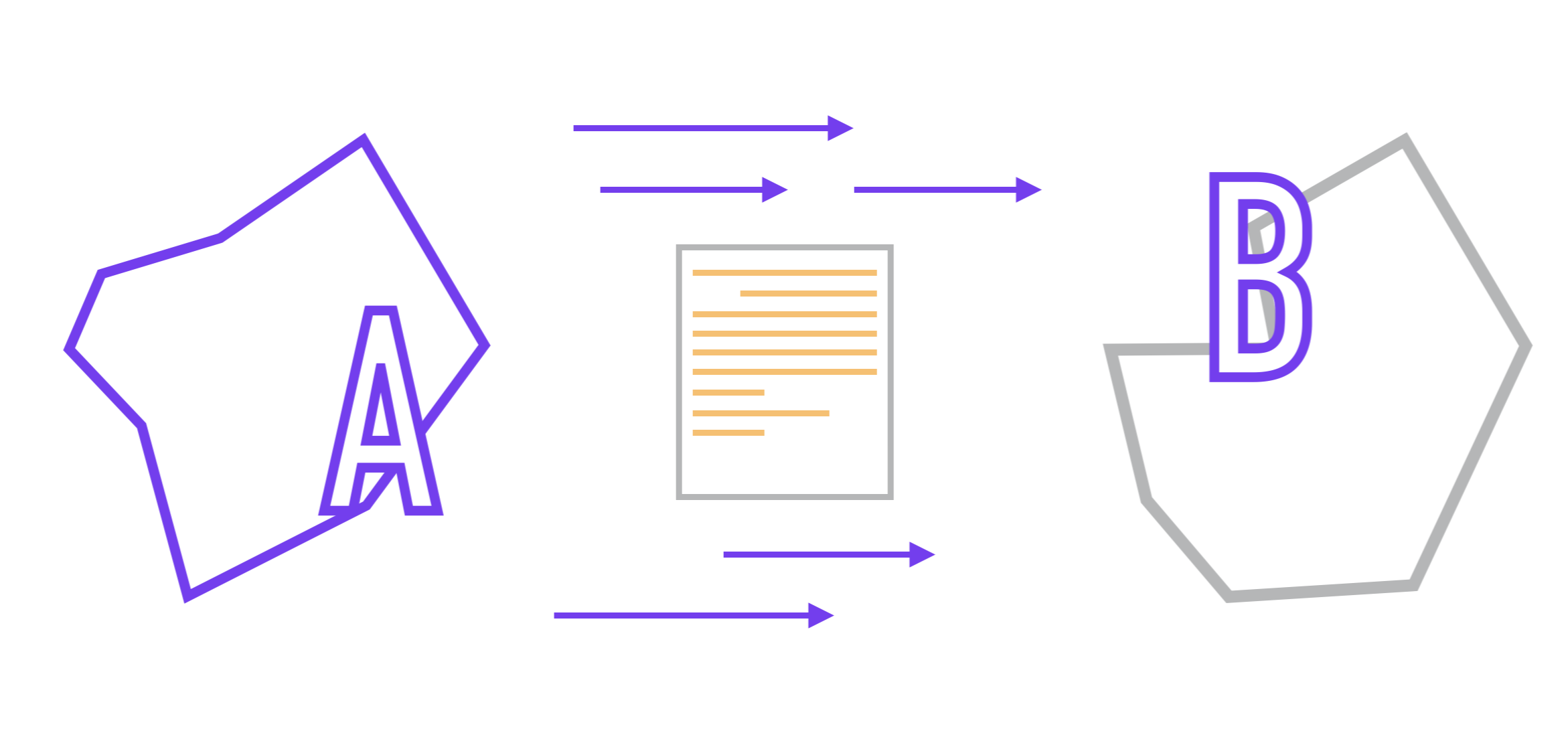
Die vor uns liegende Aufgabe lautet wie folgt: Wir müssen die Datenübertragung von einer Anwendung zur anderen und vorzugsweise mit minimalen Verzögerungen organisieren.
Im einfachsten Fall wird die Aufgabe durch synchrone Interaktion erreicht, wenn A eine Anforderung an Anwendung B sendet, wonach Dienst B sie verarbeitet und abhängig davon, ob die Anforderung erfolgreich verarbeitet wurde oder nicht, eine Antwort sendet Service A, der diese Antwort erwartet.
Wenn die Antwort auf die Anforderung nicht empfangen wurde (z. B. B die Verbindung vor dem Senden der Antwort unterbricht oder A durch eine Zeitüberschreitung abfällt), kann Dienst A seine Anforderung an B wiederholen.
Einerseits gibt ein solches Interaktionsmodell eine Sicherheit des Datenlieferungsstatus für jede Anforderung wenn der Absender sicher weiß, ob die Daten vom Empfänger empfangen wurden und welche weiteren Maßnahmen er je nach Antwort ergreifen muss.
Auf der anderen Seite wartet der zu zahlende Preis. Nach dem Senden einer Anforderung wird Dienst A (oder der Thread, in dem die Anforderung ausgeführt wird) blockiert, bis er eine Antwort empfängt oder die Anforderung gemäß seiner internen Logik als nicht erfolgreich betrachtet, wonach er weitere Maßnahmen ergreift.
Das Problem ist nicht nur, dass Wartezeiten und Ausfallzeiten auftreten, sondern dass Verzögerungen bei der Netzwerkkommunikation unvermeidlich sind. Das Hauptproblem ist die Unvorhersehbarkeit dieser Verzögerung. Kommunikationsteilnehmer im Microservice-Ansatz kennen die Details der Implementierung des anderen nicht, daher ist es für die anfragende Partei nicht immer offensichtlich, ob ihre Anforderung normal verarbeitet wird oder ob Daten erneut gesendet werden müssen.
Bei diesem Interaktionsmodell bleibt nur das Warten. Vielleicht eine Nanosekunde, vielleicht eine Stunde. Und diese Zahl ist ziemlich real, wenn B während der Datenverarbeitung schwere Operationen wie die Videoverarbeitung ausführt.
Vielleicht schien Ihnen das Problem nicht von Bedeutung zu sein - ein Stück Eisen wartet darauf, dass das andere antwortet. Ist der Verlust groß?
Angenommen, Dienst A ist eine Anwendung, die auf Ihrem Telefon ausgeführt wird, und während er auf eine Antwort von B wartet, wird auf dem Bildschirm eine Ladeanimation angezeigt. Sie können die Anwendung erst weiter verwenden, wenn Service B antwortet und Sie warten müssen. Unbekannte Zeit. Angesichts der Tatsache, dass Ihre Zeit viel wertvoller ist als die Laufzeit eines Codeteils.
Diese Rauheit wird wie folgt gelöst: Sie teilen die Interaktionsteilnehmer in zwei "Camps" auf: Einige können nicht schneller arbeiten, egal wie Sie sie optimieren (Videoverarbeitung), während andere nicht länger als eine bestimmte Zeit warten können (Anwendungsoberfläche auf Ihrem Telefon).
Dann ersetzen Sie die SynchronisierungDie Interaktion zwischen ihnen (wenn ein Teil gezwungen ist, auf den anderen zu warten, um sicherzustellen, dass die Daten vom Empfängerdienst übermittelt und verarbeitet wurden) wird asynchron , dh das Arbeitsmodell wird gesendet und vergessen. In diesem Fall setzt Dienst A seine Arbeit fort, ohne auf eine Antwort von zu warten B.
Aber wie können Sie sicherstellen, dass die Übertragung in diesem Fall erfolgreich ist? Sie können beispielsweise nach dem Hochladen eines Videos zu einem Video-Hosting-Dienst dem Benutzer keine Meldung anzeigen: "Ihr Video wird möglicherweise verarbeitet, aber möglicherweise nicht", da der Dienst, der das Video herunterlädt, keine Bestätigung vom Dienstprozessor erhalten hat, dass das Video erreicht wurde ihn ohne Zwischenfall.
Als eine der Lösungen für dieses Problem können wir eine Schicht zwischen den Diensten A und B hinzufügen, die als temporärer Speicher und Garant für die Datenlieferung in einem für Sender und Empfänger geeigneten Tempo fungiert. Auf diese Weise können wir Dienste entkoppeln , deren synchrone Interaktion möglicherweise problematisch sein könnte:
- Daten, die verloren gehen, wenn der empfangende Dienst abnormal beendet wird, können jetzt wieder aus dem Staging-Speicher abgerufen werden, während der sendende Dienst seine Arbeit fortsetzt. Somit erhalten wir einen Liefergarantiemechanismus ;
- Diese Schicht schützt die Empfänger auch vor Laststößen, da dem Empfänger Daten während der Verarbeitung und nicht beim Eintreffen gegeben werden.
- Anforderungen für Schwergewichtsvorgänge (z. B. Video-Rendering) können jetzt über diese Ebene weitergeleitet werden, wodurch die Konnektivität zwischen den schnellen und langsamen Teilen der Anwendung verringert wird.
Ein gewöhnliches DBMS ist für die oben genannten Anforderungen gut geeignet. Die darin enthaltenen Daten können lange Zeit gespeichert werden, ohne dass Sie sich Gedanken über den Verlust von Informationen machen müssen. Die Überlastung der Empfänger ist ebenfalls ausgeschlossen, da sie die Geschwindigkeit und das Volumen des Lesens der für sie bestimmten Datensätze frei wählen können. Die Bestätigung der Verarbeitung kann durch Markieren der gelesenen Datensätze in den entsprechenden Tabellen erfolgen.
Die Auswahl eines DBMS als Datenaustausch-Tool kann jedoch mit zunehmender Last zu Leistungsproblemen führen. Dies liegt daran, dass die meisten Datenbanken nicht für diesen Anwendungsfall ausgelegt sind. Außerdem fehlt vielen DBMS die Möglichkeit, verbundene Clients in Empfänger und Absender (Pub / Sub) zu trennen. In diesem Fall muss die Datenübermittlungslogik auf der Clientseite implementiert werden.
Wir brauchen wahrscheinlich etwas Spezialisierteres als eine Datenbank.
Nachrichtenbroker
Ein Nachrichtenbroker (Nachrichtenwarteschlange) ist ein separater Dienst, der für das Speichern und Übermitteln von Daten von Absenderdiensten an Empfängerdienste mithilfe des Pub / Sub-Modells verantwortlich ist.
Dieses Modell geht davon aus, dass die asynchrone Kommunikation der folgenden Logik zweier Rollen folgt:
- Publisher veröffentlichen neue Informationen als Nachrichten, die nach Attributen gruppiert sind.
- Abonnenten abonnieren Nachrichtenströme mit bestimmten Attributen und verarbeiten diese.
Das Nachrichtengruppierungsattribut ist die Warteschlange , die zum Trennen von Datenströmen benötigt wird, damit Empfänger nur die Nachrichtengruppen abonnieren können, die sie interessieren.
Ähnlich wie beim Abonnieren verschiedener Inhaltsplattformen können Sie durch Abonnieren eines bestimmten Autors Inhalte filtern, indem Sie nur diejenige anzeigen, die Sie interessiert.

Die Warteschlange kann als Kommunikationskanal betrachtet werden, der sich zwischen dem Schreiber und dem Leser erstreckt. Autoren stellen Nachrichten in eine Warteschlange. Anschließend werden sie an Leser weitergeleitet, die diese Warteschlange abonniert haben. Es erhält jeweils ein Leser eine Nachricht, nach der andere Leser nicht mehr darauf zugreifen können.
Eine Nachricht hingegen ist eine Dateneinheit, die normalerweise aus einem Nachrichtentext und Broker-Metadaten besteht.
Im Allgemeinen ist ein Body eine Sammlung von Bytes in einem bestimmten Format.
Der Empfänger muss dieses Format kennen, um seinen Körper nach dem Empfang einer Nachricht für die weitere Verarbeitung deserialisieren zu können.
Sie können jedes bequeme Format verwenden. Beachten Sie jedoch die Abwärtskompatibilität, die beispielsweise vom binären Protobuf und dem Apache Avro-Framework unterstützt wird.
Die meisten auf AMQP (Advanced Message Queuing Protocol) basierenden Nachrichtenbroker arbeiten nach diesem Prinzip, einem Protokoll, das einen Standard für fehlertolerantes Messaging über Warteschlangen beschreibt.
Dieser Ansatz bietet uns mehrere wichtige Vorteile:
- Schwacher Zusammenhalt. Dies wird durch asynchrone Nachrichtenübertragung erreicht: Das heißt, der Absender löscht die Daten und arbeitet weiter, ohne auf eine Antwort des Empfängers zu warten, und der Empfänger liest und verarbeitet Nachrichten, wenn es für ihn günstig ist, und nicht, wenn sie gesendet wurden. In diesem Fall kann die Warteschlange mit einem Postfach verglichen werden, in das der Postbote Ihre Briefe legt, und Sie holen sie ab, wenn es Ihnen passt.
- . , ( , ), - .
, . - . - . , , : , , , -, .
- . “at least once” “at most once”.
Die Wiederaufbereitung von Nachrichten wird höchstens sofort eliminiert, sie können jedoch verloren gehen. In diesem Fall übermittelt der Broker den Empfängern Nachrichten auf der Basis von "Senden und Vergessen". Wenn der Empfänger die Nachricht beim ersten Versuch aus irgendeinem Grund nicht verarbeiten konnte, sendet der Broker sie nicht erneut.
Mindestens einmal garantiert andererseits, dass der Empfänger die Nachricht empfängt, es besteht jedoch die Möglichkeit, dieselben Nachrichten erneut zu verarbeiten.
Oft wird diese Garantie mithilfe des Ack / Nack- Mechanismus (Bestätigung / negative Bestätigung) erreicht , der vorschreibt, eine Nachricht erneut zu senden, wenn der Empfänger sie aus irgendeinem Grund nicht verarbeiten konnte.
Daher gibt es für jede vom Broker gesendete (aber noch nicht verarbeitete) Nachricht drei Endzustände: Der Empfänger hat Ack zurückgegeben (erfolgreiche Verarbeitung), Nack zurückgegeben (nicht erfolgreiche Verarbeitung) oder die Verbindung getrennt. Die letzten beiden Szenarien führen zum erneuten Senden und erneuten Verarbeiten von Nachrichten.
Der Broker kann die Nachricht jedoch erneut senden, selbst wenn der Empfänger die Nachricht erfolgreich verarbeitet hat. Zum Beispiel, wenn der Empfänger die Nachricht verarbeitet, aber beendet hat, ohne ein Bestätigungssignal an den Broker zu senden .
In diesem Fall stellt der Broker die Nachricht wieder in die Warteschlange. Danach wird sie erneut verarbeitet. Dies kann zu Fehlern und Datenkorruption führen, wenn der Entwickler keinen Mechanismus zum Entfernen von Duplikaten auf der Empfängerseite bereitgestellt hat.
Es ist erwähnenswert, dass es eine weitere Liefergarantie gibt, die „genau einmal“ genannt wird . In verteilten Systemen ist dies schwierig zu erreichen, aber es ist auch am wünschenswertesten.
In dieser Hinsicht hebt sich Apache Kafka, über den wir später sprechen werden, vor dem Hintergrund vieler auf dem Markt verfügbarer Lösungen positiv hervor. Seit Version 0.11 bietet Kafka eine genau einmalige Liefergarantie innerhalb eines Clusters und von Transaktionen, während AMQP-Broker solche Garantien nicht bieten können. Transaktionen in Kafka sind ein Thema für eine separate Veröffentlichung. Heute lernen wir zunächst Apache Kafka kennen.
Apache Kafka
Es scheint mir nützlich zu sein, die Geschichte über Kafka mit einer schematischen Darstellung des Cluster-Geräts zu beginnen.
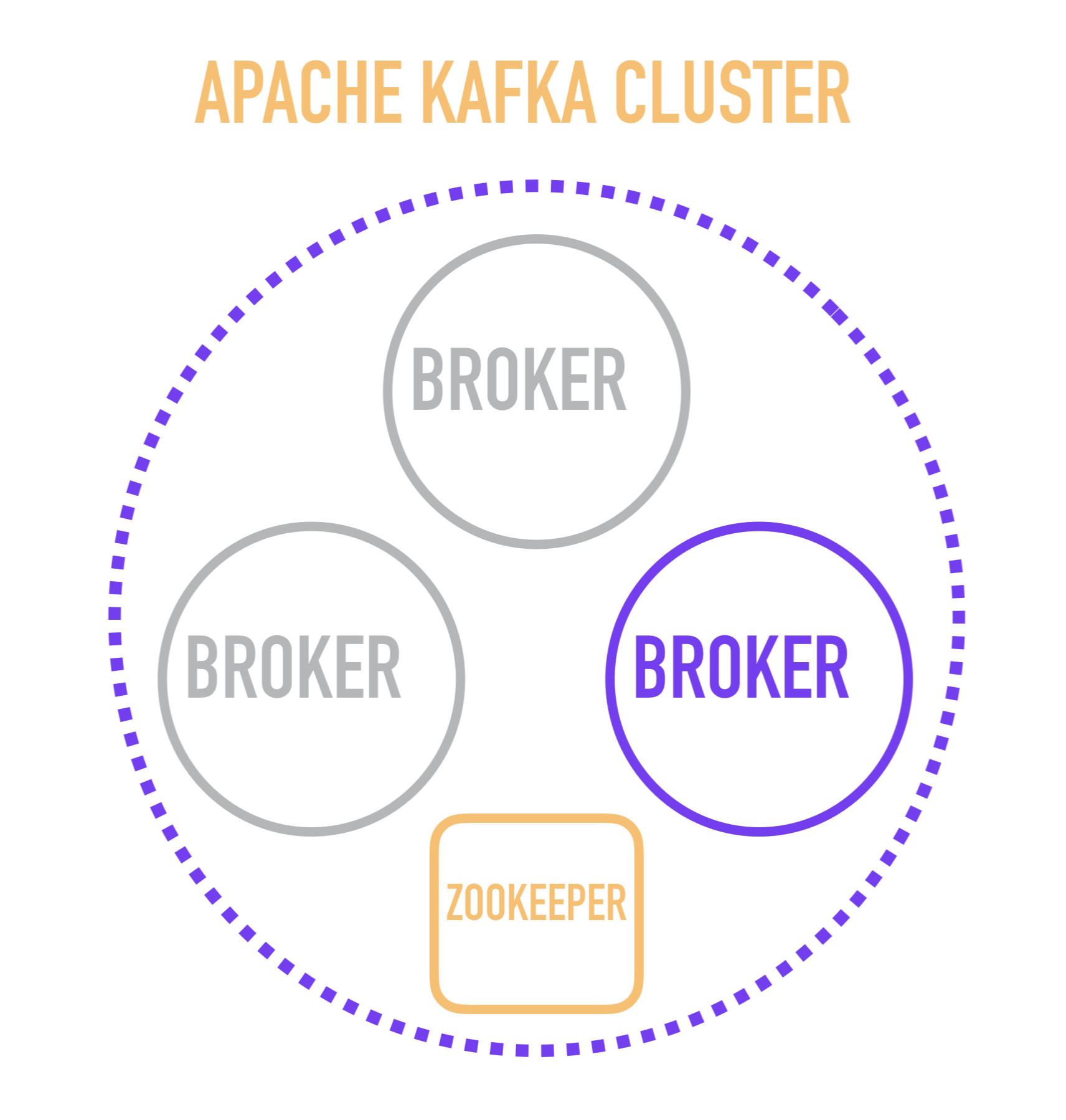
Ein separater Kafka-Server wird als Broker bezeichnet . Broker bilden einen Cluster, in dem einer dieser Broker als Controller fungiert, der einige der Verwaltungsvorgänge übernimmt (lila markiert).
Die Wahl eines Broker-Controllers liegt wiederum in der Verantwortung eines separaten Dienstes - ZooKeeper, der auch die Serviceerkennung von Brokern durchführt, Konfigurationen speichert und an der Verteilung neuer Leser unter Brokern teilnimmt und in den meisten Fällen Informationen über die zuletzt gelesene Nachricht für jeden der Leser speichert. Dies ist ein wichtiger Punkt, bei dessen Studium Sie eine Ebene tiefer gehen und überlegen müssen, wie ein einzelner Broker im Inneren arbeitet.
Protokoll festschreiben
Die Kafka zugrunde liegende Datenstruktur wird als Festschreibungsprotokoll oder Festschreibungsprotokoll bezeichnet.

Neue Elemente, die dem Festschreibungsprotokoll hinzugefügt wurden, werden streng am Ende platziert, und ihre Reihenfolge danach wird nicht geändert, sodass in jedem einzelnen Protokoll Elemente immer in der Reihenfolge aufgelistet werden, in der sie hinzugefügt wurden.
Die Reihenfolgeseigenschaft des Festschreibungsprotokolls ermöglicht es, es beispielsweise für die Replikation nach dem Prinzip der eventuellen Konsistenz zwischen Datenbankreplikaten zu verwenden: Sie speichern ein Protokoll der Änderungen, die an den Daten im Masterknoten vorgenommen wurden, deren sequentielle Anwendung auf den Slave-Knoten es Ihnen ermöglicht, die darin enthaltenen Daten zu dem mit dem Master vereinbarten zu bringen Verstand.
In Kafka werden diese Protokolle als Partitionen bezeichnet , und die darin gespeicherten Daten werden aufgerufen Nachrichten .
Was ist eine Nachricht? Es ist die grundlegende Dateneinheit in Kafka, bei der es sich lediglich um eine Sammlung von Bytes handelt, in denen Sie beliebige Informationen übergeben können. Inhalt und Struktur sind für Kafka irrelevant. Die Nachricht kann einen Schlüssel enthalten, der auch aus einer Reihe von Bytes besteht. Mit der Taste können Sie den Mechanismus zum Verteilen von Nachrichten an Partitionen besser steuern.
Partitionen und Themen
Warum könnte das wichtig sein? Tatsache ist, dass eine Partition nicht mit einer Warteschlange in Kafka vergleichbar ist, wie es auf den ersten Blick scheinen mag. Ich möchte Sie daran erinnern, dass eine Nachrichtenwarteschlange technisch gesehen ein Mittel zum Gruppieren und Verwalten von Nachrichtenflüssen ist, sodass bestimmte Leser nur bestimmte Datenströme abonnieren können.
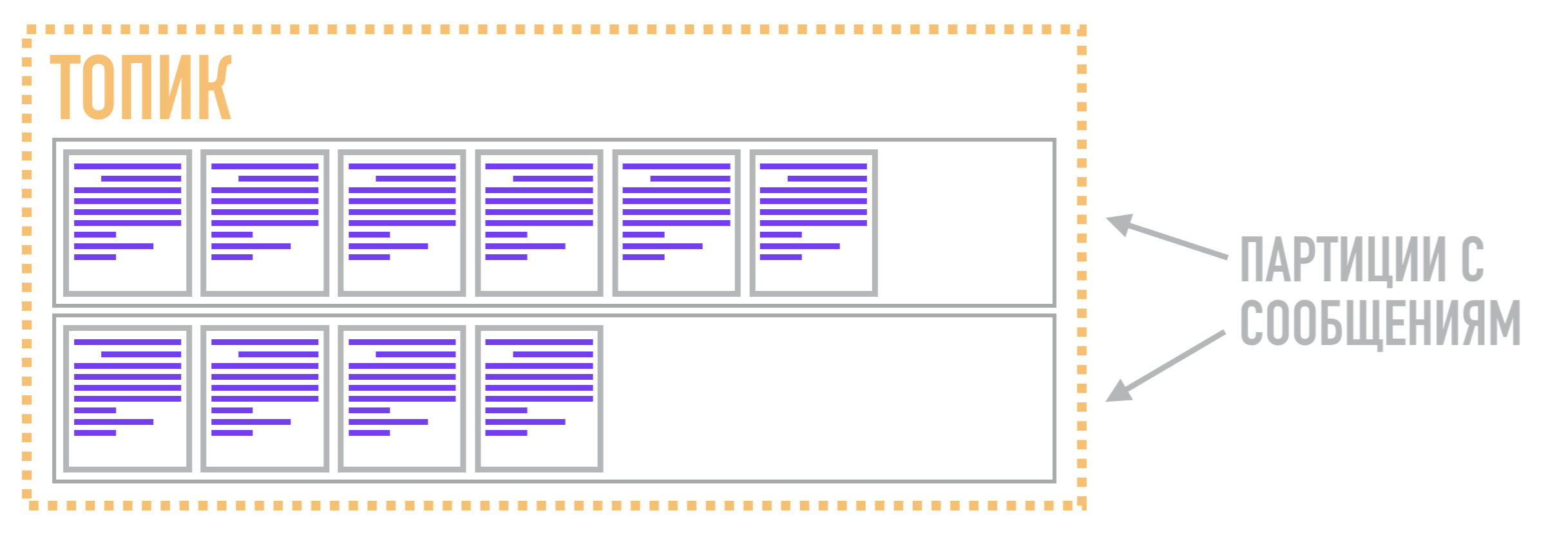
In Kafka wird die Funktion der Warteschlange also nicht von der Partition, sondern vom Thema ausgeführt . Es ist erforderlich, mehrere Partitionen zu einem gemeinsamen Stream zu kombinieren. Die Partitionen selbst speichern, wie bereits erwähnt, Nachrichten in einer geordneten Form gemäß der Datenstruktur des Festschreibungsprotokolls. Somit kann eine Nachricht zu einem Thema in zwei verschiedenen Partitionen gespeichert werden, von denen die Leser sie auf Anfrage abrufen können.
Daher ist die Parallelitätseinheit in Kafka kein Thema (oder eine Warteschlange in AMQP-Brokern), sondern eine Partition. Aus diesem Grund kann Kafka verschiedene Nachrichten, die sich auf dasselbe Thema beziehen, auf mehreren Brokern gleichzeitig verarbeiten und nicht das gesamte Thema als Ganzes, sondern nur einzelne Partitionen replizieren, was im Vergleich zu AMQP-Brokern zusätzliche Flexibilität und Skalierbarkeit bietet.
Ziehen und Drücken
Beachten Sie, dass ich das Wort "herausziehen" in Bezug auf den Leser nicht versehentlich verwendet habe.
Bei den zuvor beschriebenen Brokern wird die Nachrichtenübermittlung erreicht, indem sie ( Push- ) Empfänger über eine herkömmliche Rohrleitung geschoben werden.
Im Kafka-Übermittlungsprozess selbst ist dies nicht der Fall: Jeder Leser selbst ist dafür verantwortlich , Nachrichten von den Partitionen abzurufen, die er liest.
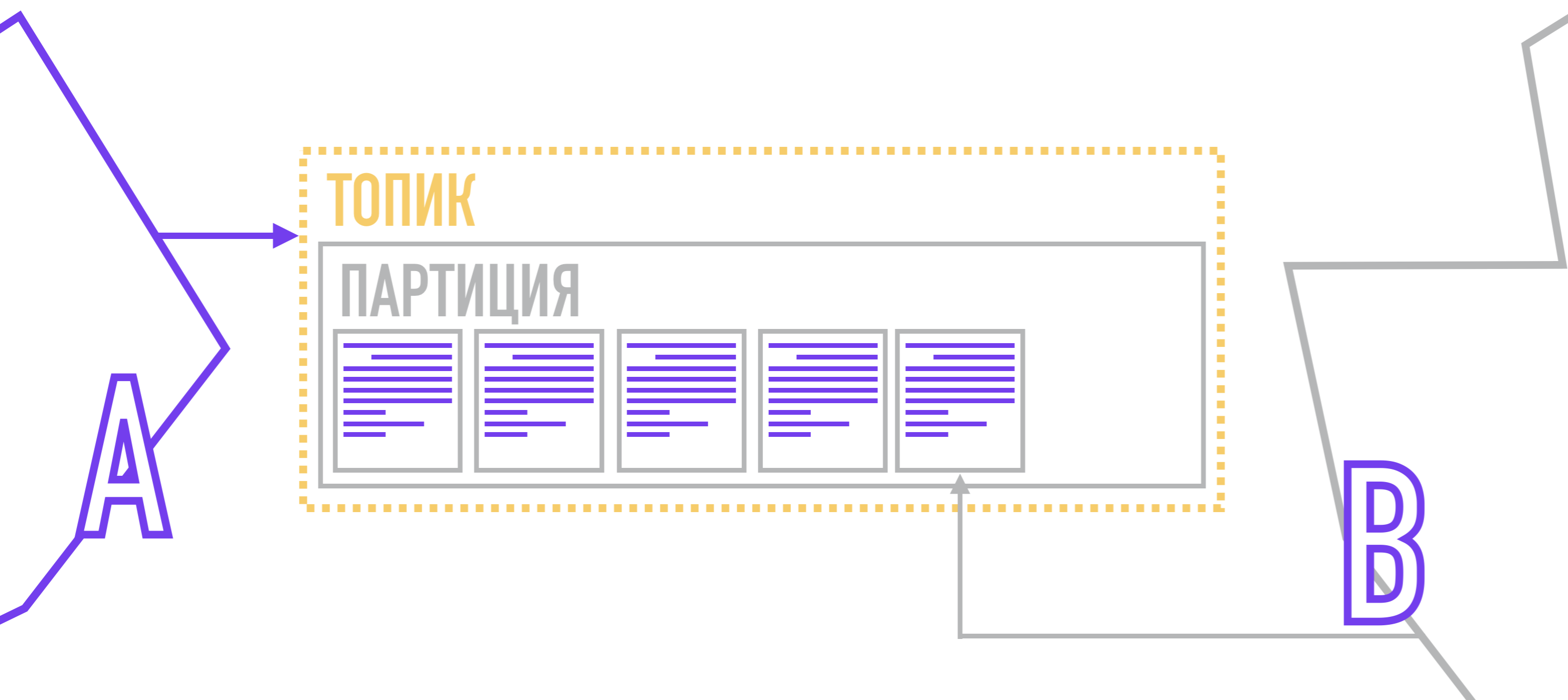
Hersteller, die Nachrichten bilden, fügen einen Schlüssel und eine Partitionsnummer hinzu. Die Partitionsnummer kann zufällig ausgewählt werden (Round-Robin), wenn die Nachricht keinen Schlüssel hat.
Wenn Sie mehr Kontrolle benötigen, können Sie der Nachricht einen Schlüssel hinzufügen und dann die Hash-Funktion verwenden oder einen eigenen Algorithmus schreiben, mit dem die Partition für die Nachricht ausgewählt wird. Nach der Gründung sendet der Produzent eine Nachricht an Kafka, die sie auf der Festplatte speichert und feststellt, zu welcher Partition er gehört.
Jeder Empfänger ist im gewünschten Thema einer bestimmten Partition (oder mehreren Partitionen) zugeordnet. Wenn eine neue Nachricht angezeigt wird, erhält er ein Signal zum Lesen des nächsten Elements im Festschreibungsprotokoll, während er die zuletzt gelesene Nachricht notiert. Wenn er sich wieder verbindet, weiß er, welche Nachricht als nächstes zu lesen ist.
Was sind die Vorteile dieses Ansatzes?
- . , , . , ( Retention Policy, ), .
- Message Replay. , . , , .
- . , ( ) – , .
- . (batch) , , . : (1 ), .
Die Nachteile dieses Ansatzes umfassen das Arbeiten mit Problemmeldungen. Im Gegensatz zu klassischen Brokern können fehlerhafte Nachrichten (die unter Berücksichtigung der vorhandenen Logik des Empfängers oder aufgrund von Problemen mit der Deserialisierung nicht verarbeitet werden können) nicht auf unbestimmte Zeit in die Warteschlange gestellt werden, bis der Empfänger lernt, sie korrekt zu verarbeiten.
In Kafka wird das Lesen von Nachrichten von der Partition standardmäßig beendet, wenn der Empfänger die fehlerhafte Nachricht erreicht. Lesen Sie die Partition weiter, bis sie übersprungen und zur weiteren Verarbeitung in die Warteschlange "Quarantäne" (auch als " Warteschlange für tote Buchstaben " bezeichnet) geworfen wird wird nicht funktionieren.
Auch in Kafka ist es (im Vergleich zu AMQP-Brokern) schwieriger, die Nachrichtenpriorität zu implementieren. Dies ergibt sich direkt aus der Tatsache, dass Nachrichten in Partitionen streng in der Reihenfolge gespeichert und gelesen werden, in der sie hinzugefügt wurden. Eine Möglichkeit, diese Einschränkung in Kafka zu umgehen, besteht darin, mehrere Themen für Nachrichten mit unterschiedlichen Prioritäten zu erstellen (die Themen unterscheiden sich nur in ihren Namen), z. B. events_low, events_medium, events_high , und anschließend die Logik des Prioritätslesens der aufgelisteten Themen auf der Seite der Consumer-Anwendung zu implementieren.
Ein weiterer Nachteil dieses Ansatzes hängt mit der Tatsache zusammen, dass es notwendig ist, Aufzeichnungen über die zuletzt gelesene Nachricht in der Partition von jedem der Leser zu führen. Aufgrund der Einfachheit der Struktur von Partitionen werden diese Informationen in Form eines aufgerufenen ganzzahligen Werts dargestellt Versatz (Versatz). Mit dem Versatz können Sie bestimmen, welche Nachricht gerade von jedem der Leser gelesen wird. Die dem Offset am nächsten liegende Analogie ist der Index eines Elements in einem Array, und der Lesevorgang ähnelt dem Durchlaufen eines Arrays in einer Schleife unter Verwendung eines Iterators als Index des Elements.
Dieser Nachteil wird jedoch dadurch ausgeglichen, dass Kafka ab Version 0.9 Offsets für jeden Benutzer in einem speziellen Thema __consumer_offsets speichert (vor Version 0.9 wurden Offsets in ZooKeeper gespeichert).
Darüber hinaus können Sie Offsets direkt auf der Empfängerseite verfolgen.

Die Skalierung wird auch komplizierter: Ich möchte Sie daran erinnern, dass Sie in AMQP-Brokern, um die Verarbeitung des Nachrichtenflusses zu beschleunigen, nur mehrere Instanzen des Reader-Dienstes hinzufügen und diese in einer Warteschlange abonnieren müssen und keine Änderungen an der Konfiguration des Brokers selbst vornehmen müssen.
Die Skalierung ist in Kafka jedoch etwas schwieriger als in AMQP-Brokern. Wenn Sie beispielsweise eine weitere Instanz des Readers hinzufügen und auf derselben Partition festlegen, erhalten Sie eine Effizienz von Null, da in diesem Fall beide Instanzen denselben Datensatz lesen.
Daher lautet die Grundregel für die Kafka-Skalierung, dass die Anzahl der wettbewerbsfähigen Leser (dh einer Gruppe von Diensten, die dieselbe Verarbeitungslogik (Replikate) implementieren) eines Themas die Anzahl der Partitionen in diesem Thema nicht überschreiten sollte, da sonst einige Leserpaare denselben Datensatz verarbeiten.
Verbrauchergruppe
Um die Situation beim Lesen einer Partition durch wettbewerbsfähige Leser zu vermeiden, ist es in Kafka üblich, mehrere Replikate eines Dienstes in einer Verbrauchergruppe zu kombinieren , in der Zookeeper einer Partition nicht mehr als einen Leser zuweist.
Da die Leser direkt an die Partition gebunden sind (während der Leser normalerweise nichts über die Anzahl der Partitionen im Thema weiß), verteilt ZooKeeper, wenn ein neuer Leser verbunden ist, die Mitglieder an die Verbrauchergruppe, sodass jede Partition nur einen Leser hat.
Der Leser bezeichnet seine Verbrauchergruppe, wenn er eine Verbindung zu Kafka herstellt.
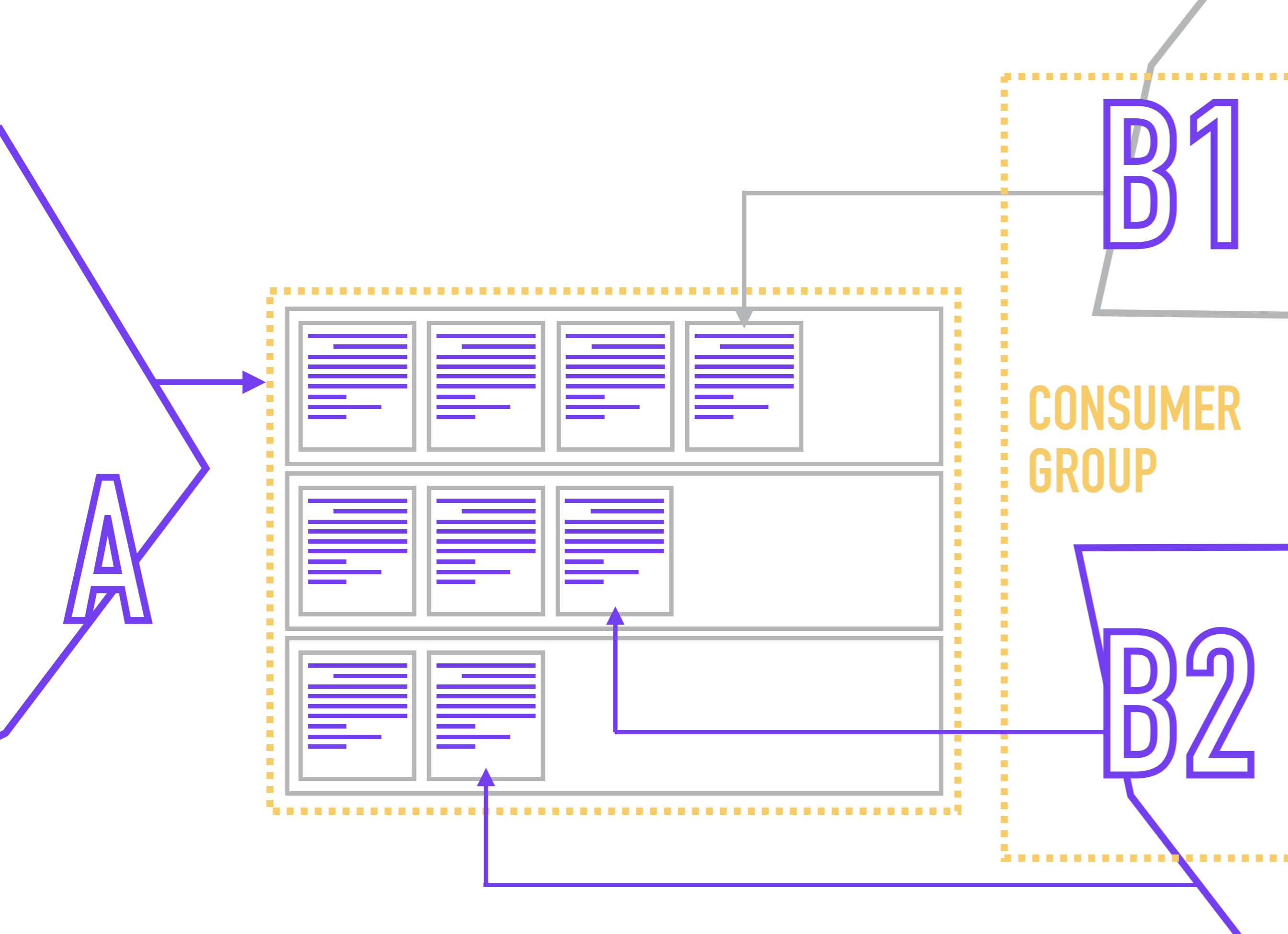
Gleichzeitig hindert Sie nichts daran, mehrere Lesegeräte mit unterschiedlicher Verarbeitungslogik an eine Partition zu hängen. Sie speichern beispielsweise in einem Thema eine Liste von Ereignissen nach Benutzeraktionen und möchten diese Ereignisse verwenden, um mehrere Ansichten derselben Daten zu generieren (z. B. für Geschäftsanalysten, Produktanalysten, Systemanalysten und das Yarovaya-Paket) und diese dann an die entsprechenden Speicher zu senden.
Aber hier können wir uns einem anderen Problem stellen, das durch die Tatsache verursacht wird, dass Kafka eine Struktur von Themen und Partitionen verwendet. Ich möchte Sie daran erinnern, dass Kafka die Reihenfolge von Nachrichten innerhalb eines Themas nicht garantiert, sondern nur innerhalb einer Partition. Dies kann beispielsweise beim Generieren von Berichten über Benutzeraktionen und beim Senden dieser Nachrichten an den Ist-Speicher von entscheidender Bedeutung sein.
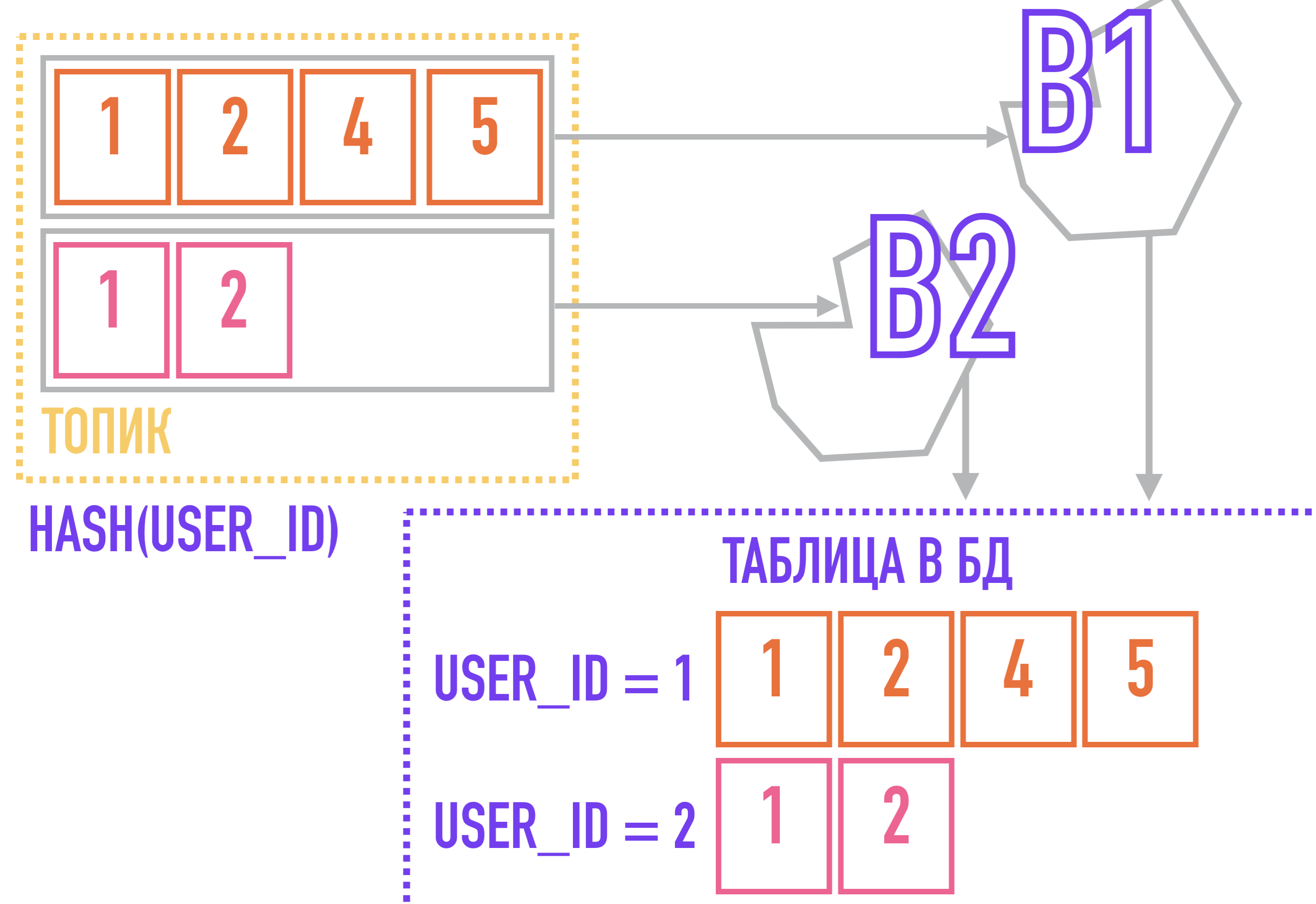
Um dieses Problem zu lösen, können wir vom Gegenteil ausgehen: Wenn alle Ereignisse, die sich auf eine Entität beziehen (z. B. alle Aktionen, die sich auf dieselbe Benutzer-ID beziehen), immer derselben Partition hinzugefügt werden, werden sie innerhalb des Themas einfach deshalb sortiert befinden sich in derselben Partition, deren Reihenfolge von Kafka garantiert wird.
Dazu benötigen wir einen Schlüssel für Nachrichten: Wenn wir beispielsweise einen Algorithmus verwenden, der den Hash aus dem Schlüssel berechnet, um die Partition auszuwählen, zu der die Nachricht hinzugefügt wird, fallen Nachrichten mit demselben Schlüssel garantiert in eine Partition und ziehen daher den Nachrichtenempfänger heraus mit demselben Schlüssel in der Reihenfolge, in der sie dem Thema hinzugefügt wurden.
In einem Fall mit einem Strom von Ereignissen über Benutzeraktionen kann der Partitionierungsschlüssel user_id sein.
Aufbewahrungsrichtlinie
Jetzt ist es Zeit, über Aufbewahrungsrichtlinien zu sprechen.
Dies ist eine Einstellung, die für das Löschen von Nachrichten von der Festplatte verantwortlich ist, wenn die Schwellenwerte für das Hinzufügen ( zeitbasierte Aufbewahrungsrichtlinie ) oder den auf der Festplatte belegten Speicherplatz ( größenbasierte Aufbewahrungsrichtlinie ) überschritten werden .
- Wenn Sie TBRP für 7 Tage konfigurieren, werden alle Nachrichten, die älter als 7 Tage sind, zum späteren Löschen markiert. Mit anderen Worten, diese Einstellung stellt sicher, dass Nachrichten unterhalb der Altersschwelle jederzeit lesbar sind. Kann in Stunden, Minuten und Millisekunden eingestellt werden.
- SBRP funktioniert auf ähnliche Weise: Wenn der Schwellenwert für den Speicherplatz überschritten wird, werden Nachrichten zum Löschen am Ende (älter) markiert. Es sollte beachtet werden: Da das Löschen von Nachrichten nicht sofort erfolgt, ist der belegte Speicherplatz immer etwas größer als in der Einstellung angegeben. In Bytes setzen.
Aufbewahrungsrichtlinien können sowohl für den gesamten Cluster als auch für einzelne Themen konfiguriert werden: Beispielsweise können Nachrichten in einem Thema zum Verfolgen von Benutzeraktionen mehrere Tage lang gespeichert werden, während Push-Benachrichtigungen mehrere Stunden lang gespeichert werden können. Durch das Löschen von Daten entsprechend ihrer Relevanz sparen wir Speicherplatz, was bei der Auswahl einer SSD als Hauptspeicher wichtig sein kann.
Verdichtungsrichtlinie
Eine andere Möglichkeit zur Optimierung des Speicherplatzes ist die Verwendung der Komprimierungsrichtlinie. Mit dieser Einstellung können Sie nur die letzte Nachricht für jeden Schlüssel speichern und alle vorherigen Nachrichten löschen. Dies kann nützlich sein, wenn wir nur an der neuesten Änderung interessiert sind.
Kafka-Anwendungsfälle
- . : . , , , (Clickhouse !) .
Customer Care Vivid.Money CRM. - . , . , - ( ) , , .
, ( ) . , , , , . - . , .
- (commit log). , - / .
, , «» .
Customer Care CRM- .
Kafka
- – , ;
- – (pull) , . (, ) Consumer Group, ZooKeeper, , , , ;
- . , , , . , () ;
- , , AMQP , – . , ;
- . , , --, – .