
AWS Fault Injection Simulator (FIS)- Ein Tool, mit dem Sie zuvor bekannte Szenarien eines internen Systemausfalls in AWS-Services implementieren können. Wozu? - damit die Teams Szenarien für ihre Beseitigung erarbeiten und im Allgemeinen das Verhalten ihres Produkts unter den vorgeschlagenen Bedingungen bewerten können. Das System bietet sofort mehrere Vorlagen mit Fehlerszenarien an, z. B. Verlangsamung der Server, deren Ausfall, Fehler beim Zugriff auf die Datenbank oder deren Absturz. Gleichzeitig stellt FIS sicher, dass das Experiment nicht zu weit geht. Wenn bestimmte Parameter erreicht sind, werden die Tests abgebrochen und das System kehrt zum Normalzustand zurück. Der Hauptslogan des neuen Produkts des Cloud-Riesen lautet "Steigerung der Ausfallsicherheit und Leistung mithilfe der Technologie des kontrollierten Chaos". Die Veröffentlichung des neuen Testsystems ist für 2021 geplant.
AWS bietet auch Tests und verteilte virtualisierte Systeme an, die weniger von einem einzelnen Host abhängig sind. Die Besonderheit eines Fehlers in einem verteilten System besteht darin, dass das Problem zyklisch sein und eine komplexere Struktur aufweisen kann. Mit der neuen AWS-Funktion können Sie nicht nur in der Infrastruktur von Monolithen, sondern auch in verteilten Systemen und Anwendungen nach Schwachstellen suchen.
Mal sehen, warum das wichtig und cool ist.
Chaos Engineering ist ein Simulationstestprozess, bei dem der Hauptschlag auf das System von innen kommt und sich auf die Projektinfrastruktur auswirkt. Das Team simuliert Situationen, in denen der Infrastrukturteil des Projekts mit technischen und anderen Problemen konfrontiert ist, z. B. mit einem Punkt oder einer systemischen Leistungsminderung in Instanzen. Dies kann auch Serverabstürze, API-Fehler und andere Albträume des Backends umfassen, denen das Team jederzeit oder, noch schlimmer, am Tag der Veröffentlichung der nächsten Version ausgesetzt sein kann.
Es gibt noch keine eindeutige Definition von Chaos Engineering, daher hier einige der beliebtesten und unserer Meinung nach genauesten Optionen. Chaos Engineering ist: "Ein Ansatz, bei dem mit einem Produktionssystem experimentiert wird, um sicherzustellen, dass es verschiedenen Störungen standhält, die während des Betriebs auftreten" und "ein Experiment, um die Auswirkungen von Fehlern zu mildern".
Warum AWS Fault Injection Simulator überhaupt benötigt wird
Die Entwickler des Tools führen mehrere Gründe an, warum FIS für Teams beim Testen und Vorbereiten ihrer Systeme nützlich sein wird.
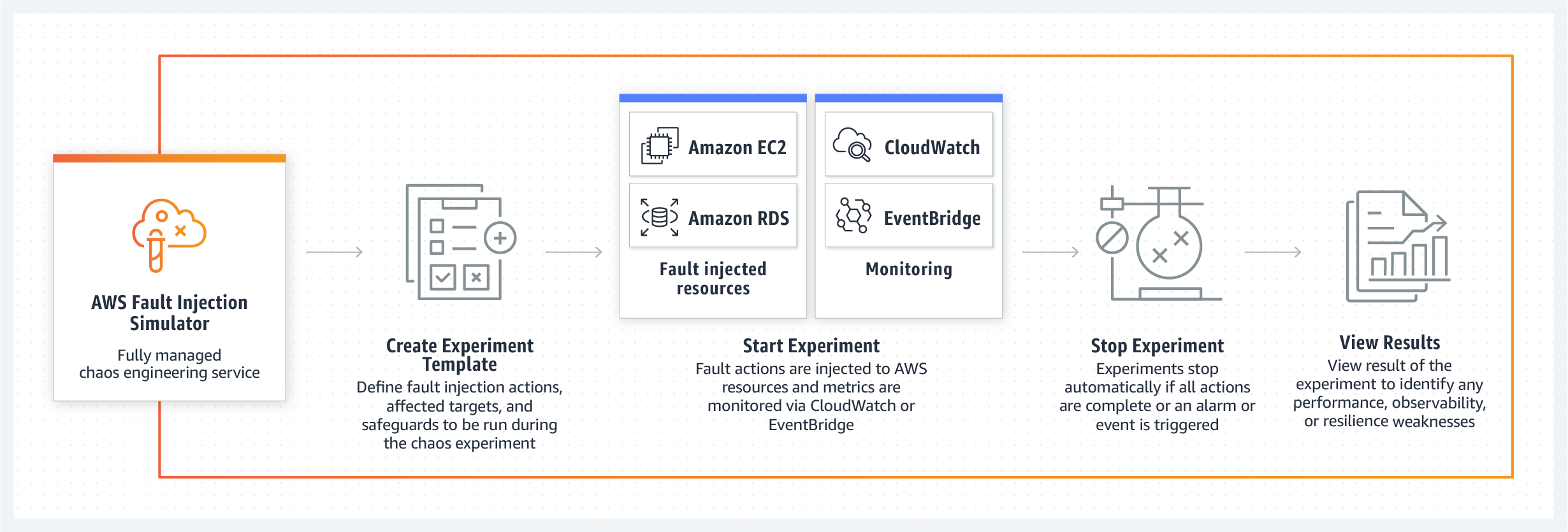
Systemleistung, Ausfallsicherheit und Transparenz sind eine der Kernbotschaften des AWS FIS-Teams.
AWS Fault Injection Simulator , , «» , .
Tatsächlich sind die üblichen Testmethoden in erster Linie eine Simulation der externen Belastung des Systems. Beispiel: Simulieren eines Habra-Effekts oder eines externen DDoS-Angriffs auf ein System oder einen Dienst. In den meisten Fällen sind alle Hauptüberwachungssysteme genau an diese Knoten gebunden, während die Verfolgung des Verhaltens der internen Infrastruktur häufig nur auf den Empfang von Daten im "Down / Down" -Stil oder die Belastung der CPU beschränkt ist. Gleichzeitig sind der größte Schaden und die stärksten Ausfälle der letzten Jahre genau mit internen Ausfällen oder Infrastrukturfehlern verbunden. Es genügt, sich an den CloudFlare-Absturz vom letzten Jahr zu erinnern, als Entwickler aufgrund einer Reihe von Fehlern und Irrtümern die Hälfte des Internets buchstäblich dazu zwangen, sich mit ihren eigenen Händen „hinzulegen“.
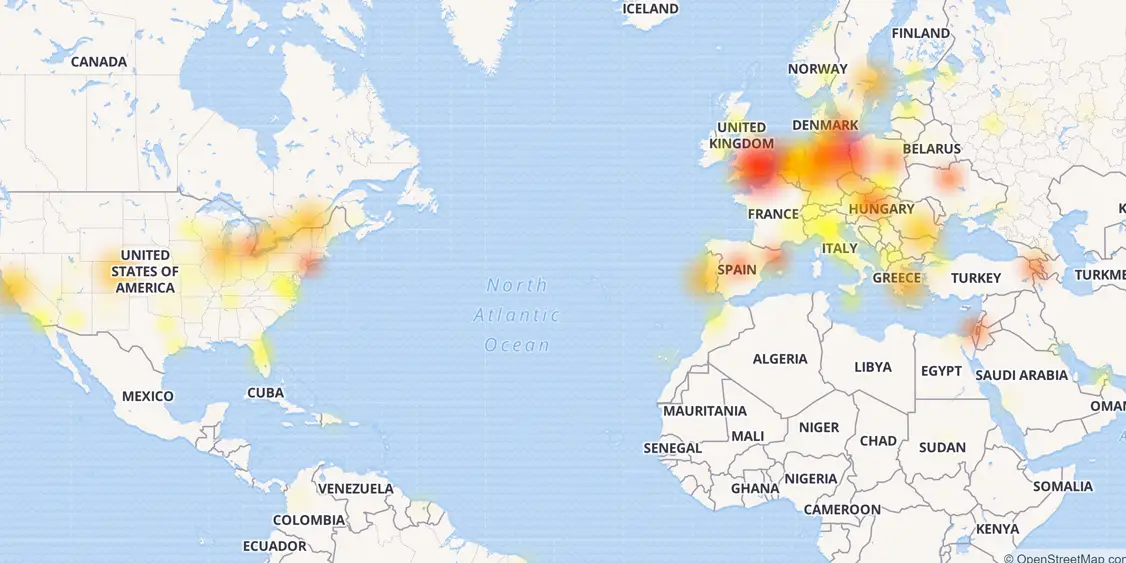
Karte dieses CloudFlare-Fehlers
Das neue Tool ist in der Lage, sowohl vorgefertigte Vorlagen für Szenarien mit Datenbankausfall, API oder Leistungseinbußen zu erarbeiten als auch zufällige „Blindtest“ -Bedingungen zu erstellen, bei denen Probleme in zufälliger Reihenfolge auf verschiedenen Knoten auftreten.
Eine weitere Stärke des neuen AWS-Toolkits ist die Steuerbarkeit des Chaos, das vom Team im System verursacht wird. Ingenieure versichern, dass Entwickler mithilfe ihres Control Panels ein kontrolliertes Fehlerszenario jederzeit stoppen und das System in den ursprünglichen Betriebszustand zurückversetzen können. Der Fault Injection Simulator unterstützt Amazon CloudWatch und Überwachungstools von Drittanbietern, die über Amazon EventBridge verbunden sind, sodass Entwickler ihre Metriken verwenden können, um kontrollierte Chaos-Experimente zu überwachen. Nun, und natürlich erhält der Administrator nach dem Stoppen des Tests einen vollständigen Bericht darüber, welche Systemknoten und in welcher Reihenfolge vom Fehler betroffen waren, was in Zukunft dazu beitragen wird, eine Reihe von Maßnahmen und Verfahren zur Lokalisierung und Beseitigung von Problemen zu entwickeln.
Wie die Lords of Chaos entstanden sind
Offensichtlich ist es am logischsten, solche Stresstests des Systems in der Vorabversion durchzuführen, um sicherzustellen, dass die vorhandene Infrastruktur in AWS dem neuen Patch standhält. In Wirklichkeit geht die Technik des Chaos Engineering jedoch auf ältere Praktiken zurück, deren Gründer Jesse Robbins, einer der Amazon-Manager in den 2000er Jahren, ist. Seine Position wurde offiziell "Master of Disaster" genannt, was in einer erbärmlichen Übersetzung mit "Lord of Disasters" verwechselt werden kann, und in einer kostenlosen Version klang seine Position wie "Master Lomaster".
 Es war Robbins, ein ehemaliger Feuerwehrmann-Retter, der
GameDay bei Amazon implementierte.... Das Ziel der Robbins-Initiative war äußerst einfach: Unter Ingenieurteams ein intuitives Verständnis für den Umgang mit Katastrophen zu entwickeln, so wie dieses Gefühl in Feuerwehren trainiert wird. Aus diesem Grund wurde die Methode der globalen Simulation des totalen Chaos gewählt: Alles bricht von allen Seiten gleichzeitig oder nacheinander zusammen, und jeder Versuch, mit dem Versagen fertig zu werden, führt zu neuen und neuen Problemen.
Es war Robbins, ein ehemaliger Feuerwehrmann-Retter, der
GameDay bei Amazon implementierte.... Das Ziel der Robbins-Initiative war äußerst einfach: Unter Ingenieurteams ein intuitives Verständnis für den Umgang mit Katastrophen zu entwickeln, so wie dieses Gefühl in Feuerwehren trainiert wird. Aus diesem Grund wurde die Methode der globalen Simulation des totalen Chaos gewählt: Alles bricht von allen Seiten gleichzeitig oder nacheinander zusammen, und jeder Versuch, mit dem Versagen fertig zu werden, führt zu neuen und neuen Problemen.
Wenn eine unvorbereitete Person mit dem Aufruhr der Elemente konfrontiert ist, gerät sie meistens in eine Betäubung oder Panik. Die meisten Entwickler und Ingenieure sind psychologisch nicht auf eine Situation vorbereitet, in der die Lösung eines Problems drei Tage dauern sollte und der Stress einfach außerhalb des Maßstabs liegt.
Robbins nennt das wichtigste Ergebnis von GameDay die psychologische Wirkung solcher Übungen: Sie entwickeln die Fähigkeit, die Tatsache zu akzeptieren, dass große Störungen auftreten . Es ist die Akzeptanz der Tatsache, dass alles um ihn herum brennt und zusammenbricht, er nennt es sehr wichtig für den Ingenieur, damit er seine Gedanken sammeln und endlich anfangen kann, "das Feuer zu löschen". Eine ungeschulte Person wird bestenfalls im Kreis laufen und "alles ist verloren" rufen.
Nach der Implementierung der GameDay-Praxis stellte sich heraus, dass solche Übungen Architekturprobleme und Engpässe perfekt identifizieren , die bei klassischen Tests und Verifizierungen nicht berücksichtigt werden.
Ein weiterer wesentlicher Unterschied zwischen GameDay und unseren üblichen "Training and Order" -Übungen besteht darin, dass nur wenige Menschen das spezifische Szenario kennen und wissen, was im Allgemeinen passieren wird. Informationen über die bevorstehenden "Spiele" werden sehr allgemein und vage gegeben, so dass sich die Teilnehmer nicht vollständig auf diese Veranstaltung vorbereiten konnten. Idealerweise nur das Datum des nächsten "Spieltages" ohne jegliche Klarstellung bekannt zu geben, damit die Teilnehmer es nicht für einen echten Unfall halten. Natürlich lässt sich diese Methode nicht auf ein großes Unternehmen skalieren. Beispielsweise kann GameDay nicht in ganz Yandex oder Microsoft gleichzeitig ausgeführt werden.
Infolgedessen wurde die Vorgehensweise auf den lokalen GameDay aktualisiert und in allen bestehenden großen IT-Unternehmen eingeführt, beispielsweise in Google, Flickr und vielen anderen. Es hat seine eigenen Master of Disasters (naja, oder Master-Lommasters, wie Sie möchten), die Trainingsfehler organisieren und dann die Ergebnisse analysieren, die bei bestimmten Projekten erzielt wurden.
Die Hauptschwierigkeit bei der Implementierung dieser Praxis liegt überall in zwei Aspekten: wie man sie organisiert und wie man Daten sammelt, damit GameDay nicht umsonst ist. Aus diesem Grund wurde diese Technik in kleineren Unternehmen bis vor kurzem (wenn überhaupt) nicht sehr häufig eingesetzt. Anstelle von GameDay und Katastrophensimulation konzentrierte sich das Geschäft mehr auf verschiedene Arten von Tests, CI / CD und andere Methoden für eine geordnete und sequentielle Entwicklung. Das heißt, was eine Katastrophe als solche verhindert.
Mit dem neuen AWS-Toolkit können Sie die andere Seite von Störungen angehen: Anstelle der Prävention, die zweifellos wichtig ist, ermöglicht FIS Ingenieurteams jeder Größe, effektiv in der Lösung globaler Infrastrukturstörungen zu trainieren. Die Hauptsache, die Robbins bemerkt, ist, dass Katastrophen sowieso passieren: Sie können nicht vermieden werden.