Zu den Frameworks, die wir für die komplexe Datenverarbeitung in Java in Betracht ziehen, gehört Apache Flink. Wir möchten Ihnen eine Übersetzung eines guten Artikels aus dem Analytics Vidhya-Blog auf dem Medium-Portal anbieten, um das Interesse des Lesers einzuschätzen. Zögern Sie nicht abzustimmen!

In diesem Artikel sehen wir uns von unten an, wie Sie mit Flink optimieren können. Cloud-Dienste und andere Plattformen bieten Streaming-Lösungen (von denen einige Flink unter der Haube integriert haben). Wenn Sie dieses Thema von Grund auf verstehen wollten, haben Sie genau das gefunden, wonach Sie gesucht haben.
Unsere monolithische Lösung konnte das zunehmende Volumen eingehender Daten nicht bewältigen. Daher musste es weiterentwickelt werden. Es ist Zeit, in der Entwicklung unseres Produkts zu einer neuen Generation überzugehen. Es wurde beschlossen, Streaming-Verarbeitung zu verwenden. Dies ist ein neues Paradigma der Datenabsorption, das der herkömmlichen Stapelverarbeitung überlegen ist.
Apache Flink auf einen Blick
Apache Flink ist ein skalierbares Framework für verteiltes Threading, das für Operationen mit kontinuierlichen Datenströmen entwickelt wurde. In diesem Rahmen werden Konzepte wie Quellen, Stream-Transformationen, Parallelverarbeitung, Scheduling, Ressourcenzuweisung verwendet. Eine Vielzahl von Datenzielen wird unterstützt. Insbesondere kann Apache Flink eine Verbindung zu HDFS, Kafka, Amazon Kinesis, RabbitMQ und Cassandra herstellen.
Flink ist bekannt für seinen hohen Durchsatz und seine geringe Latenz, unterstützt eine konsistente, ausschließlich einmalige Verarbeitung (alle Daten werden einmal verarbeitet, keine Duplizierung) und eine hohe Verfügbarkeit. Wie jedes erfolgreiche Open Source-Produkt verfügt Flink über eine große Community, die die Funktionen dieses Frameworks erweitert und erweitert.
Flink kann Datenströme (Streamgröße ist undefiniert) oder Datasets (Datasetgröße ist spezifisch) verarbeiten. Dieser Artikel befasst sich speziell mit der Thread-Verarbeitung (Umgang mit Objekten
DataStream
).
Streaming und seine damit verbundenen Herausforderungen
Heutzutage kommen Daten aufgrund der Allgegenwart von IoT-Geräten und anderen Sensoren ständig aus vielen Quellen. Dieser endlose Datenstrom erfordert die Anpassung des traditionellen Batch-Computing an neue Bedingungen.
- Daten unbegrenzt streamen; Sie haben keinen Anfang und kein Ende.
- Neue Daten kommen in unregelmäßigen Abständen auf unvorhersehbare Weise an.
- Daten können ungeordnet mit unterschiedlichen Zeitstempeln eintreffen.
Mit solch einzigartigen Eigenschaften sind Datenverarbeitungs- und Abfrageaufgaben nicht trivial durchzuführen. Die Ergebnisse können sich schnell ändern, und es ist fast unmöglich, endgültige Schlussfolgerungen zu ziehen. Berechnungen können manchmal blockiert werden, wenn versucht wird, gültige Ergebnisse zu erhalten. Darüber hinaus sind die Ergebnisse nicht reproduzierbar, da sich die Daten während der Berechnungen weiter ändern. Schließlich sind Verzögerungen ein weiterer Faktor, der die Genauigkeit der Ergebnisse beeinflusst.
Mit Apache Flink können Sie solche Verarbeitungsprobleme bewältigen, da es sich auf die Zeitstempel konzentriert, mit denen die eingehenden Daten an der Quelle zurückgegeben werden. Flink verfügt über einen Mechanismus zum Akkumulieren von Ereignissen basierend auf Zeitstempeln, die auf diese gesetzt werden - und erst nach dem Akkumulieren fährt das System mit der Verarbeitung fort. In diesem Fall ist es möglich, auf die Verwendung von Mikropaketen zu verzichten, und auch in diesem Fall wird die Genauigkeit der Ergebnisse erhöht.
Flink implementiert eine konsistente, streng einmalige Verarbeitung, die die Genauigkeit der Berechnungen garantiert, und der Entwickler muss hierfür nichts Besonderes programmieren.
Woraus bestehen Flink-Pakete?
In der Regel absorbiert Flink Datenströme aus verschiedenen Quellen. Das Basisobjekt ist
DataStream<T>
ein Strom von Elementen desselben Typs. Der Elementtyp in einem solchen Stream wird zur Kompilierungszeit durch Festlegen eines generischen Typs bestimmt
T
(mehr dazu hier ).
Das Objekt
DataStream
enthält viele nützliche Methoden zum Transformieren, Trennen und Filtern von Daten. Für den Anfang wird es nützlich sein, eine Vorstellung davon zu haben, was sie tun
map
,
reduce
und
filter
; Dies sind die wichtigsten Transformationsmethoden:
Map
: ruft ein Objekt abT
und gibt als Ergebnis ein Objekt vom Typ zurückR
;MapFunction
streng einmal auf jedes Element des Objekts angewendetDataStream
.
SingleOutputStreamOperator<R> map(MapFunction<T,R> mapper)
Reduce
: ruft zwei aufeinanderfolgende Werte ab und gibt ein Objekt zurück, wobei sie zu einem Objekt desselben Typs kombiniert werden; Diese Methode führt alle Werte in der Gruppe aus, bis nur noch einer übrig bleibt.
T reduce(T value1, T value2)
Filter
: holt ein ObjektT
und gibt einen Strom von Objekten zurückT
; Diese Methode durchläuft alle ElementeDataStream
, gibt jedoch nur diejenigen zurück, für die die Funktion zurückgegeben wirdtrue
.
SingleOutputStreamOperator<T> filter(FilterFunction<T> filter)
Datenablauf
Eines der Hauptziele von Flink ist neben der Datentransformation die Steuerung der Flüsse und deren Weiterleitung an bestimmte Ziele. Diese Orte werden "Abflüsse" genannt. Flink verfügt über integrierte Zeichenfolgen (Text, CSV, Socket) sowie über sofort einsatzbereite Mechanismen für die Verbindung mit anderen Systemen, z. B. Apache Kafka .
Flink Event Tags
Bei der Verarbeitung von Datenströmen ist der Zeitfaktor äußerst wichtig. Es gibt drei Möglichkeiten, den Zeitstempel zu bestimmen:
- ( ): , ; , . - . , .
, , . , , , ; , .
// Processing Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
- : , , , Flink. , , Flink .
Flink , , , ; « » (watermark). ; Flink.
// Event Time streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);DataStream<String> dataStream = streamEnv.readFile(auditFormat, dataDir, FileProcessingMode.PROCESS_CONTINUOUSLY, 1000). assignTimestampsAndWatermarks( new TimestampExtractor());// ... ... // public class TimestampExtractor implements AssignerWithPeriodicWatermarks<String>{ @Override public Watermark getCurrentWatermark() { return new Watermark(System.currentTimeMillis()-maxTimeFrame); } @Override public long extractTimestamp(String str, long l) { return InputData.getDataObject(str).timestamp; } }
- Absorptionszeit: Dies ist der Zeitpunkt, zu dem das Ereignis in Flink eintritt. Wird zugewiesen, wenn sich das Ereignis an der Quelle befindet, und wird daher als stabiler angesehen als die Verarbeitungszeit, die zugewiesen wurde, wenn der Prozess gestartet wird.
Die Absorptionszeit ist nicht für die Behandlung von Ereignissen außerhalb der Reihenfolge oder verspäteten Daten geeignet, da der Zeitstempel der Zeitpunkt ist, an dem die Absorption beginnt. Dies unterscheidet sich von der Ereigniszeit, die die Möglichkeit bietet, ausstehende Ereignisse zu erkennen und zu verarbeiten, wobei auf den Wasserzeichenmechanismus zurückgegriffen wird.
// Ingestion Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
Weitere Informationen zu Zeitstempeln und deren Auswirkungen auf das Streaming finden Sie unter folgendem Link .
Fensteraufteilung
Der Strom ist per Definition endlos; Daher ist der Verarbeitungsmechanismus mit der Definition von Fragmenten (z. B. Periodenfenstern) verbunden. Somit wird der Strom in Chargen aufgeteilt, die für die Aggregation und Analyse geeignet sind. Eine Fensterdefinition ist eine Operation für ein DataStream-Objekt oder etwas anderes, das davon erbt.
Es gibt verschiedene Arten von zeitabhängigen Fenstern:
Tumbling-Fenster (Standardkonfiguration):
Der Stream ist in Fenster gleicher Größe unterteilt, die sich nicht überlappen. Während der Stream fließt, berechnet Flink kontinuierlich die Daten basierend auf diesem zeitlich festgelegten Storyboard.

Tumbling-Fenster
Implementierung im Code:
// ,
public AllWindowedStream<T,TimeWindow> timeWindowAll(Time size)
// ,
public WindowedStream<T,KEY,TimeWindow> timeWindow(Time size)
Schiebefenster
Solche Fenster können einander überlappen, und die Eigenschaften des Schiebefensters werden durch die Größe des Fensters und dem Rand festgelegt (wenn das nächste Fenster starten). In diesem Fall können Ereignisse, die sich auf mehr als ein Fenster beziehen, gleichzeitig verarbeitet werden.

Schiebefenster
Und so sieht es im Code aus:
// 1 30
dataStreamObject.timeWindow(Time.minutes(1), Time.seconds(30))
Sitzungsfenster
Beinhaltet alle Ereignisse innerhalb einer Sitzung. Die Sitzung endet, wenn keine Aktivität vorhanden ist oder wenn nach einem bestimmten Zeitraum keine Ereignisse erkannt werden. Dieser Zeitraum kann abhängig von den verarbeiteten Ereignissen fest oder dynamisch sein. Wenn das Intervall zwischen den Sitzungen kleiner als die Fenstergröße ist, wird die Sitzung theoretisch möglicherweise nie beendet.
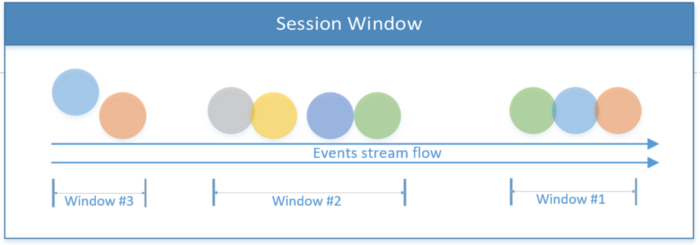
Sitzungsfenster
Das erste Codefragment unten zeigt eine Sitzung mit einem festen Zeitwert (2 Sekunden). Das zweite Beispiel implementiert ein dynamisches Sitzungsfenster basierend auf Thread-Ereignissen.
// 2
dataStreamObject.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)))
// ,
dataStreamObject.window(EventTimeSessionWindows.withDynamicGap((elem) -> {
// ,
}))
Globales Fenster
Das gesamte System wird als ein einziges Fenster behandelt.

Im globalen Fenster
Flink können Sie auch Ihre eigenen Fenster implementieren, deren Logik vom Benutzer festgelegt wird.
Neben zeitabhängigen Fenstern gibt es noch andere, z. B. das Kontofenster, in dem das Limit für die Anzahl der eingehenden Ereignisse festgelegt ist. Wenn der Schwellenwert X erreicht ist, verarbeitet Flink X Ereignisse.

Zählfenster für drei Ereignisse
Nach einer theoretischen Einführung wollen wir uns den Datenfluss aus praktischer Sicht genauer ansehen. Weitere Informationen zu Apache Flink und Threading finden Sie auf der offiziellen Website .
Stream-Beschreibung
Als Zusammenfassung des theoretischen Teils zeigt das folgende Blockdiagramm die wichtigsten Datenflüsse, die in den Codefragmenten dieses Artikels implementiert sind. Der folgende Stream beginnt an der Quelle (Dateien werden in das Verzeichnis geschrieben) und wird fortgesetzt, während Ereignisse verarbeitet werden, die in Objekte umgewandelt werden.
Die unten dargestellte Implementierung hat zwei Verarbeitungspfade. Der oben gezeigte teilt einen Stream in zwei Seitenströme auf und kombiniert sie dann, um einen Stream des dritten Typs zu erhalten. Das am unteren Rand des Diagramms gezeigte Skript beschreibt die Verarbeitung des Streams. Anschließend werden die Ergebnisse der Arbeit in die Senke übertragen.

Als nächstes werden wir versuchen, die praktische Umsetzung der obigen Theorie mit unseren Händen zu fühlen; Der gesamte unten diskutierte Quellcode wird auf GitHub veröffentlicht .
Grundlegende Stream-Verarbeitung (Beispiel 1)
Es ist einfacher, Flink-Konzepte zu verstehen, wenn Sie mit der einfachsten Anwendung beginnen. In dieser Anwendung schreibt der Produzent Dateien in ein Verzeichnis und simuliert so den Informationsfluss. Flink liest Dateien aus diesem Verzeichnis und schreibt zusammenfassende Informationen darüber in das Zielverzeichnis. Das ist die Aktie.
Schauen wir uns als nächstes genauer an, was während der Verarbeitung passiert:
Konvertieren von Rohdaten in ein Objekt:
// InputData;
DataStream<InputData> inputDataObjectStream
= dataStream
.map((MapFunction<String, InputData>) inputStr -> {
System.out.println("--- Received Record : " + inputStr);
return InputData.getDataObject(inputStr);
});
Das folgende Codefragment
InputData
konvertiert ein Stream-Objekt ( ) in einen String und ein Integer-Tupel. Es werden nur bestimmte Felder aus dem Objektstrom extrahiert und in Quanten von zwei Sekunden nach einem Feld gruppiert.
//
DataStream<Tuple2<String, Integer>> userCounts
= inputDataObjectStream
.map(new MapFunction<InputData,Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(InputData item) {
return new Tuple2<String,Integer>(item.getName() ,item.getScore() );
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0) // KeyedStream<T, Tuple> ( 'name')
//.timeWindowAll(Time.seconds(windowInterval)) // timeWindowAll
.timeWindow(Time.seconds(2)) // WindowedStream<T, KEY, TimeWindow>
.reduce((x,y) -> new Tuple2<String,Integer>( x.f0+"-"+y.f0, x.f1+y.f1));
Erstellen eines Ziels für einen Stream (Implementieren einer Datensenke):
//
DataStream<Tuple2<String,Integer>> inputCountSummary
= inputDataObjectStream
.map( item
-> new Tuple2<String,Integer>
(String.valueOf(System.currentTimeMillis()),1))
// (1)
.returns(Types.TUPLE(Types.STRING ,Types.INT))
.timeWindowAll(Time.seconds(windowInterval)) //
.reduce((x,y) -> // ,
(new Tuple2<String, Integer>(x.f0, x.f1 + y.f1)));
//
final StreamingFileSink<Tuple2<String,Integer>> countSink
= StreamingFileSink
.forRowFormat(new Path(outputDir),
new SimpleStringEncoder<Tuple2<String,Integer>>
("UTF-8"))
.build();
// DataStream; inputCountSummary countSink
inputCountSummary.addSink(countSink);
Beispielcode zum Erstellen einer Datensenke.
Streams teilen (Beispiel 2)
Dieses Beispiel zeigt, wie der Hauptstrom mithilfe von Nebenausgabestreams aufgeteilt wird. Flink bietet mehrere Seitenströme vom Hauptstrom
DataStream
. Der auf jeder Seite des Streams befindliche Datentyp kann sich vom Datentyp des Hauptstroms sowie vom Datentyp jedes Seitenstroms unterscheiden.
Mit einem Seitenausgabestream können Sie also zwei Fliegen mit einer Klappe schlagen: Teilen Sie den Stream und konvertieren Sie den Datentyp des Streams in viele Datentypen (sie können für jeden Seitenausgabestream eindeutig sein).
Das folgende Codefragment wird als
ProcessFunction
Aufteilen des Streams in zwei Seiten bezeichnet, abhängig von der Eingabeeigenschaft. Um das gleiche Ergebnis zu erzielen, müssten wir die Funktion wiederholt verwenden
filter
.
Funktion
ProcessFunction
sammelt bestimmte Objekte (basierend auf einem Kriterium) und sendet sie an den Hauptausgangskopf (liegt in
SingleOutputStreamOperator
), und der Rest der Ereignisse wird an die Seitenausgänge übertragen. Der Stream wird
DataStream
vertikal aufgeteilt und veröffentlicht für jeden Seitenstrom unterschiedliche Formate.
Beachten Sie, dass die Definition einer Nebenstromausgabe auf einem eindeutigen Ausgabe-Tag (Objekt
OutputTag
) basiert .
//
final OutputTag<Tuple2<String,String>> playerTag
= new OutputTag<Tuple2<String,String>>("player"){};
//
final OutputTag<Tuple2<String,Integer>> singerTag
= new OutputTag<Tuple2<String,Integer>>("singer"){};
// InputData .
SingleOutputStreamOperator<InputData> inputDataMain
= inputStream
.process(new ProcessFunction<String, InputData>() {
@Override
public void processElement(
String inputStr,
Context ctx,
Collector<InputData> collInputData) {
Utils.print(Utils.COLOR_CYAN, "Received record : " + inputStr);
// InputData
InputData inputData = InputData.getDataObject(inputStr);
switch (inputData.getType())
{
case "Singer":
//
ctx.output(singerTag,
new Tuple2<String,Integer>
(inputData.getName(), inputData.getScore()));
break;
case "Player":
// ;
// playerTag, (" ")
ctx.output(playerTag,
new Tuple2<String, String>
(inputData.getName(), inputData.getType()));
break;
default:
// InputData
collInputData.collect(inputData);
break;
}
}
});
Beispielcode zum Aufteilen eines Streams
Streams kombinieren (Beispiel 3)
Die letzte Operation, die in diesem Artikel behandelt wird, ist die Thread-Verkettung. Die Idee ist, zwei verschiedene Streams zu kombinieren, deren Datenformate sich unterscheiden können, um einen Stream mit einer einheitlichen Datenstruktur zu sammeln. Im Gegensatz zur Verknüpfungsoperation aus SQL, bei der Daten horizontal zusammengeführt werden, werden Streams vertikal zusammengeführt, da der Ereignisfluss fortgesetzt wird und nicht zeitlich begrenzt ist.
Das Verketten von Streams erfolgt durch Aufrufen der Verbindungsmethode und anschließendes Definieren einer Zuordnungsoperation für jedes Element in jedem einzelnen Stream. Das Ergebnis ist ein zusammengeführter Stream.
//
ConnectedStreams<Tuple2<String, Integer>, Tuple2<String, String>> mergedStream
= singerStream
.connect(playerStream);
DataStream<Tuple4<String, String, String, Integer>> combinedStream
= mergedStream.map(new CoMapFunction<
Tuple2<String, Integer>, // 1
Tuple2<String, String>, // 2
Tuple4<String, String, String, Integer> //
>() {
@Override
public Tuple4<String, String, String, Integer> // 1
map1(Tuple2<String, Integer> singer) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: singer stream", singer.f0, "", singer.f1);
}
@Override
public Tuple4<String, String, String, Integer>
// 2
map2(Tuple2<String, String> player) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: player stream", player.f0, player.f1, 0);
}
});
Auflistung, die zeigt, wie ein zusammengeführter Stream abgerufen wird
Ein Arbeitsprojekt erstellen
Um es noch einmal zusammenzufassen: Das Demo-Projekt wird auf GitHub hochgeladen. Es wird beschrieben, wie Sie es erstellen und kompilieren. Dies ist ein guter Ausgangspunkt, um mit Flink zu üben.
Schlussfolgerungen
Dieser Artikel beschreibt die grundlegenden Vorgänge zum Erstellen einer funktionierenden Flink-basierten Threading-Anwendung. Der Zweck der Anwendung besteht darin, einen Überblick über die kritischen Aufrufe des Streamings zu geben und den Grundstein für die anschließende Erstellung einer voll funktionsfähigen Flink-Anwendung zu legen.
Da Streaming viele Facetten und Komplexitäten aufweist, bleiben viele der Probleme in diesem Artikel ungelöst. Insbesondere Flink-Ausführung und Aufgabenverwaltung, Wasserzeichen beim Festlegen der Zeit für Streaming-Ereignisse, Einfügen von Status in Stream-Ereignisse, Ausführen von Stream-Iterationen, Ausführen von SQL-ähnlichen Abfragen in Streams und vieles mehr.
Wir hoffen, dieser Artikel hat ausgereicht, um Sie dazu zu bringen, Flink auszuprobieren.