
Kann eine parallel ausgeführte Abfrage weniger CPU verbrauchen und schneller ausgeführt werden als eine nacheinander ausgeführte Abfrage?
Ja! Zur Demonstration werde ich zwei Tabellen mit einem Spaltentyp verwenden
integer.

Hinweis - Das TSQL-Skript in Form eines Textes befindet sich am Ende des Artikels.
Demo-Daten generieren
Wir
#BuildIntfügen 5.000 zufällige Ganzzahlen in die Tabelle ein (damit Sie dieselben Werte wie meine haben, verwende ich RAND mit Startwert und einer WHILE-Schleife). Fügen Sie 5.000.000 Datensätze in die

Tabelle ein
#Probe.

Ablaufplan
Schreiben wir nun eine Abfrage, um die Anzahl der Übereinstimmungen von Werten in diesen Tabellen zu zählen. Wir verwenden den MAXDOP 1-Hinweis, um sicherzustellen, dass die Abfrage nicht parallel ausgeführt wird.
Hier sind der Ausführungsplan und die Statistiken:

Diese Abfrage wird in 891 ms ausgeführt und verwendet 890 ms CPU.
Paralleler Plan
Lassen Sie uns nun dieselbe Abfrage mit MAXDOP 2 ausführen. Die

Abfrage dauert 221 ms und verwendet 436 ms CPU. Die Ausführungszeit hat sich viermal verkürzt und die CPU-Auslastung hat sich halbiert!
Magische Bitmap
Der Grund, warum die parallele Abfrageausführung viel effizienter ist, liegt am Bitmap-Operator.
Schauen wir uns den tatsächlichen Ausführungsplan für die parallele Abfrage genauer an:

Und vergleichen Sie ihn mit dem sequentiellen Plan:

Das Prinzip des Bitmap-Operators ist gut dokumentiert. Daher werde ich hier nur eine kurze Beschreibung mit Links zur Dokumentation am Ende des Artikels bereitstellen.
Hash Join
Die Hash-Verknüpfung erfolgt in zwei Schritten:
- Die Phase des "Bauens" (Englisch - bauen). Alle Zeilen einer der Tabellen werden gelesen und eine Hash-Tabelle für die Join-Schlüssel erstellt.
- Die Stufe der "Verifikation" (Englisch - Sonde). Alle Zeilen der zweiten Tabelle werden gelesen, der Hash wird von derselben Hash-Funktion mit denselben Verbindungsschlüsseln berechnet, und in der Hash-Tabelle befindet sich ein passender Bucket.
Aufgrund möglicher Hash-Kollisionen ist es natürlich weiterhin erforderlich, die tatsächlichen Werte der Schlüssel zu vergleichen.
Anmerkung des Übersetzers: Weitere Informationen zur Funktionsweise von Hash-Joins finden Sie im Artikel Visualisieren und Behandeln von Hash-Match- Joins
Bitmap in sequentiellen Plänen
Viele Leute wissen nicht, dass Hash Match selbst bei sequentiellen Anforderungen immer eine Bitmap verwendet. In einem solchen Plan wird er jedoch nicht explizit angezeigt, da er Teil der internen Implementierung des Hash Match-Operators ist.
HASH JOIN setzt beim Erstellen und Erstellen einer Hash-Tabelle ein (oder mehrere) Bits in die Bitmap. Sie können dann die Bitmap verwenden, um die Hash-Werte effizient abzugleichen, ohne den Aufwand für den Zugriff auf die Hash-Tabelle.
Bei einem sequentiellen Plan wird für jede Zeile der zweiten Tabelle ein Hash berechnet und mit einer Bitmap verglichen. Wenn die entsprechenden Bits in der Bitmap gesetzt sind, kann es zu einer Übereinstimmung in der Hash-Tabelle kommen, sodass die Hash-Tabelle als nächstes überprüft wird. Wenn umgekehrt keines der dem Hash-Wert entsprechenden Bits gesetzt ist, können wir sicher sein, dass die Hash-Tabelle keine Übereinstimmungen enthält, und die überprüfte Zeichenfolge sofort verwerfen.
Die relativ geringen Kosten für die Erstellung einer Bitmap werden durch die Zeitersparnis beim Nichtprüfen von Zeichenfolgen ausgeglichen, für die in der Hash-Tabelle definitiv keine Übereinstimmung vorhanden ist. Diese Optimierung ist häufig effektiv, da das Überprüfen der Bitmap viel schneller ist als das Überprüfen der Hash-Tabelle.
Bitmap in parallelen Plänen
In einem parallelen Plan wird die Bitmap als separate Bitmap-Anweisung angezeigt.
Beim Übergang von der Konstruktionsphase zur Überprüfungsphase wird die Bitmap von der Seite der zweiten (Sonden-) Tabelle an den HASH MATCH-Operator übergeben. Die Bitmap wird mindestens vor dem JOIN und dem Exchange-Operator an die Prüfseite übergeben (Parallelität).
Hier kann die Bitmap Zeichenfolgen ausschließen, die die Verknüpfungsbedingung nicht erfüllen, bevor sie an die Exchange-Anweisung übergeben werden.
Natürlich gibt es in sequentiellen Plänen keine Exchange-Anweisungen, sodass das Verschieben der Bitmap außerhalb von HASH JOIN keinen zusätzlichen Vorteil gegenüber der "eingebetteten" Bitmap in der HASH MATCH-Anweisung bietet.
In einigen Situationen (wenn auch nur in einem parallelen Plan) kann der Optimierer die Bitmap auf der Sondenseite der Verbindung weiter nach unten verschieben.
Die Idee dabei ist, dass je früher die Zeilen gefiltert werden, desto weniger Overhead erforderlich ist, um Daten zwischen Anweisungen zu verschieben, und es möglicherweise sogar möglich ist, einige Operationen zu eliminieren.
Außerdem versucht der Optimierer normalerweise, einfache Filter so nah wie möglich an den Blättern zu platzieren: Es ist am effizientesten, Zeilen so früh wie möglich zu filtern. Ich muss jedoch erwähnen, dass die Bitmap, über die wir sprechen, nach Abschluss der Optimierung hinzugefügt wird.
Die Entscheidung, diesen (statischen) Bitmap-Typ nach der Optimierung zum Plan hinzuzufügen, basiert auf der erwarteten Selektivität des Filters (daher sind genaue Statistiken wichtig).
Verschieben eines Bitmap-Filters
Kehren wir zum Konzept zurück, den Bitmap-Filter auf die Sondenseite der Verbindung zu verschieben.
In vielen Fällen kann der Bitmap-Filter in eine Scan- oder Seek-Anweisung verschoben werden. In diesem Fall sieht das Plan-Prädikat folgendermaßen aus:

Es gilt für alle Zeilen, die mit dem Suchprädikat (für Index-Suche) übereinstimmen, oder für alle Zeilen für Index-Scan oder Tabellenscan. Der obige Screenshot zeigt beispielsweise einen Bitmap-Filter, der auf den Tabellenscan für eine Heap-Tabelle angewendet wird.
Tiefer gehen ...
Wenn ein Bitmap-Filter auf einer einzelnen Ganzzahl- oder Bigint-Spalte oder einem Ausdruck basiert und auf eine einzelne Ganzzahl- oder Bigint-Spalte angewendet wird, kann der Bitmap-Operator noch weiter nach unten verschoben werden als die Such- oder Scan-Operatoren.
Das Prädikat wird weiterhin in den Scan- oder Seek-Anweisungen wie im obigen Beispiel angezeigt. Jetzt wird es jedoch mit dem INROW-Attribut markiert. Dies bedeutet, dass der Filter in die Storage Engine verschoben und beim Lesen auf Zeilen angewendet wird.
Bei dieser Optimierung werden Zeilen gefiltert, bevor der Abfrageprozessor die Zeile sieht. Von der Storage Engine werden nur die Zeichenfolgen gesendet, die mit dem HASH MATCH JOIN übereinstimmen.
Die Bedingungen, unter denen diese Optimierung angewendet wird, hängen von der Version von SQL Server ab. In SQL Server 2005 muss die Prüfspalte beispielsweise zusätzlich zu den zuvor angegebenen Bedingungen als NOT NULL definiert werden. Diese Einschränkung wurde in SQL Server 2008 gelockert.
Möglicherweise fragen Sie sich, wie sich INROW-Optimierungen auf die Leistung auswirken. Ist es so effizient wie möglich, den Bediener so nah wie möglich an Suchen oder Scannen zu bringen wie in der Storage Engine zu filtern? Ich werde diese interessante Frage in anderen Artikeln beantworten. Und hier schauen wir uns auch MERGE JOIN und NESTED LOOP JOIN an.
Andere JOIN-Optionen
Die Verwendung verschachtelter Schleifen ohne Indizes ist eine schlechte Idee. Wir müssen eine der Tabellen für jede Zeile der anderen Tabelle vollständig scannen - insgesamt 5 Milliarden Vergleiche. Diese Anfrage wird wahrscheinlich sehr lange dauern.
Zusammenführen Verbinden
Diese Art der physischen Verknüpfung erfordert eine sortierte Eingabe, sodass bei einer erzwungenen MERGE JOIN eine Sortierung vor der Verknüpfung vorhanden ist. Der sequentielle Plan sieht folgendermaßen aus:
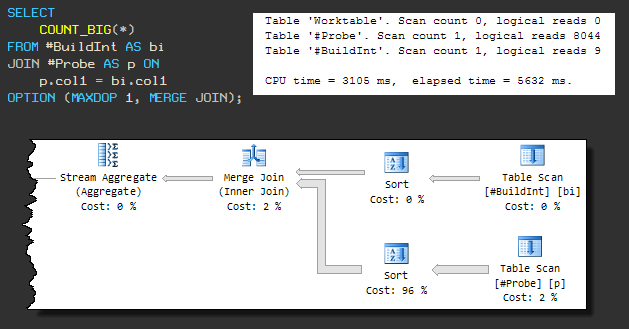
Die Abfrage verwendet jetzt 3105 ms CPU und die Gesamtausführungszeit beträgt 5632 ms .
Die Erhöhung der Gesamtausführungszeit ist auf die Tatsache zurückzuführen, dass eine der Sortiervorgänge tempdb verwendet (obwohl SQL Server über ausreichend Speicher für die Sortierung verfügt).
Das Leck in Tempdb tritt auf, weil der Standardalgorithmus für die Speichergewährung nicht genügend Speicher vorreserviert. Bis wir darauf achten, ist klar, dass die Anfrage nicht in weniger als 3105 ms abgeschlossen sein wird.
Lassen Sie uns weiterhin den MERGE JOIN erzwingen, aber Parallelität zulassen (MAXDOP 2):

Wie im parallelen HASH JOIN, den wir zuvor gesehen haben, befindet sich der Bitmap-Filter auf der anderen Seite des MERGE JOIN näher am Tabellenscan und wird mithilfe der INROW-Optimierung angewendet.
Mit einer CPU von 468 ms und einer verstrichenen Zeit von 240 ms ist ein MERGE JOIN mit zusätzlichen Sortierungen fast so schnell wie ein paralleler HASH JOIN ( 436 ms / 221 ms ).
Der parallele MERGE JOIN hat jedoch einen Nachteil: Er reserviert 330 KB Speicher basierend auf der erwarteten Anzahl der zu sortierenden Zeilen. Da diese Arten von Bitmaps nach der Kostenoptimierung verwendet werden, erfolgt keine Anpassung der Schätzung, obwohl nur 2488 Zeilen die untere Sortierung durchlaufen.
Eine Bitmap-Anweisung kann in einem Plan mit einem MERGE JOIN nur mit einer nachfolgenden Blockierungsanweisung (z. B. Sortieren) angezeigt werden. Der blockierende Operator muss alle erforderlichen Werte als Eingabe erhalten, bevor er die erste auszugebende Zeile generiert. Dadurch wird sichergestellt, dass die Bitmap vollständig gefüllt ist, bevor Zeilen aus der JOIN-Tabelle gelesen und mit ihr verglichen werden.
Es ist nicht erforderlich, dass sich die Blockierungsanweisung auf der anderen Seite von MERGE JOIN befindet, aber es ist wichtig, auf welcher Seite die Bitmap verwendet wird.
Mit Indizes
Wenn geeignete Indizes verfügbar sind, ist die Situation anders. Die Verteilung unserer "zufälligen" Daten ist so, dass
#BuildIntein eindeutiger Index für die Tabelle erstellt werden kann . Und die Tabelle #Probeenthält Duplikate, sodass Sie mit einem nicht eindeutigen Index auskommen müssen:

Diese Änderung wirkt sich nicht auf den HASH JOIN aus (sowohl seriell als auch parallel). HASH JOIN kann keine Indizes verwenden, daher bleiben Pläne und Leistung gleich.
Zusammenführen Verbinden
MERGE JOIN muss keine Viele-zu-Viele-Verknüpfungsoperation mehr ausführen und erfordert keinen Sortieroperator mehr für die Eingabe.
Das Fehlen eines blockierenden Sortieroperators bedeutet, dass Bitmap nicht verwendet werden kann.
Als Ergebnis sehen wir einen sequentiellen Plan, unabhängig vom MAXDOP-Parameter, und die Leistung ist schlechter als der parallele Plan vor dem Hinzufügen der Indizes: 702 ms CPU und 704 ms verstrichene Zeit: Es

gibt jedoch eine spürbare Verbesserung gegenüber dem ursprünglichen sequentiellen MERGE JOIN-Plan ( 3105 ms) / 5632 ms ). Dies ist auf die Eliminierung der Sortierung und eine bessere Eins-zu-Viele-Join-Leistung zurückzuführen.
Verschachtelte Schleifen verbinden
Wie zu erwarten ist, bietet NESTED LOOP eine deutlich bessere Leistung. Ähnlich wie beim MERGE JOIN entscheidet sich der Optimierer dafür, keine Parallelität zu verwenden:

Dies ist der bisher effizienteste Plan - nur 16 ms CPU und 16 ms Zeitaufwand.
Dies setzt natürlich voraus, dass sich die zum Abschließen der Anforderung erforderlichen Daten bereits im Speicher befinden. Andernfalls generiert jede Suche in der Sondentabelle zufällige E / A.
Auf meinem Laptop dauerte die Leistung des NESTED LOOP Cold Cache 78 ms CPU und 2152 ms verstrichene Zeit. Unter den gleichen Umständen verwendete MERGE JOIN 686 ms CPU und 1471 ms . HASH JOIN - 391 ms CPU und905 ms .
MERGE JOIN und HASH JOIN profitieren von großen, möglicherweise sequentiellen E / A-Vorgängen mit Vorauslesen.
Zusätzliche Ressourcen
Parallele Hash-Verknüpfung (Craig Freedman)
Bitmap-Filter für die Ausführung von Abfragen (SQL Server-Abfrageverarbeitungsteam)
Bitmaps in Microsoft SQL Server 2000 (MSDN-Artikel)
Interpretieren von Ausführungsplänen mit Bitmap-Filtern (SQL Server-Dokumentation)
Grundlegendes zu Hash-Verknüpfungen (SQL Server-Dokumentation)
Testskript
USE tempdb;
GO
CREATE TABLE #BuildInt
(
col1 INTEGER NOT NULL
);
GO
CREATE TABLE #Probe
(
col1 INTEGER NOT NULL
);
GO
-- Load 5,000 rows into the build table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #BuildInt
(col1)
VALUES
(CONVERT(INTEGER, RAND(1) * 2147483647));
WHILE @I < 5000
BEGIN
INSERT #BuildInt
(col1)
VALUES
(RAND() * 2147483647);
SET @I += 1;
END;
-- Load 5,000,000 rows into the probe table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND(2) * 2147483647));
BEGIN TRANSACTION;
WHILE @I < 5000000
BEGIN
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND() * 2147483647));
SET @I += 1;
IF @I % 25 = 0
BEGIN
COMMIT TRANSACTION;
BEGIN TRANSACTION;
END;
END;
COMMIT TRANSACTION;
GO
-- Demos
SET STATISTICS XML OFF;
SET STATISTICS IO, TIME ON;
-- Serial
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1);
-- Parallel
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 2);
SET STATISTICS IO, TIME OFF;
-- Indexes
CREATE UNIQUE CLUSTERED INDEX cuq ON #BuildInt (col1);
CREATE CLUSTERED INDEX cx ON #Probe (col1);
-- Vary the query hints to explore plan shapes
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1, MERGE JOIN);
GO
DROP TABLE #BuildInt, #Probe;
Weiterlesen: