- Kurz gesagt, welchen Plan werden wir haben? Zuerst werden wir darüber sprechen, warum wir Python lernen werden. Lassen Sie uns dann sehen, wie der CPython-Interpreter ausführlicher funktioniert, wie er den Speicher verwaltet, wie das Typsystem in Python funktioniert, Wörterbücher, Generatoren und Ausnahmen. Ich denke, es wird ungefähr eine Stunde dauern.
Warum Python?
* Insights.stackoverflow.com/survey/2019
** sehr subjektiv
*** Studieninterpretation
**** Studieninterpretation Beginnen
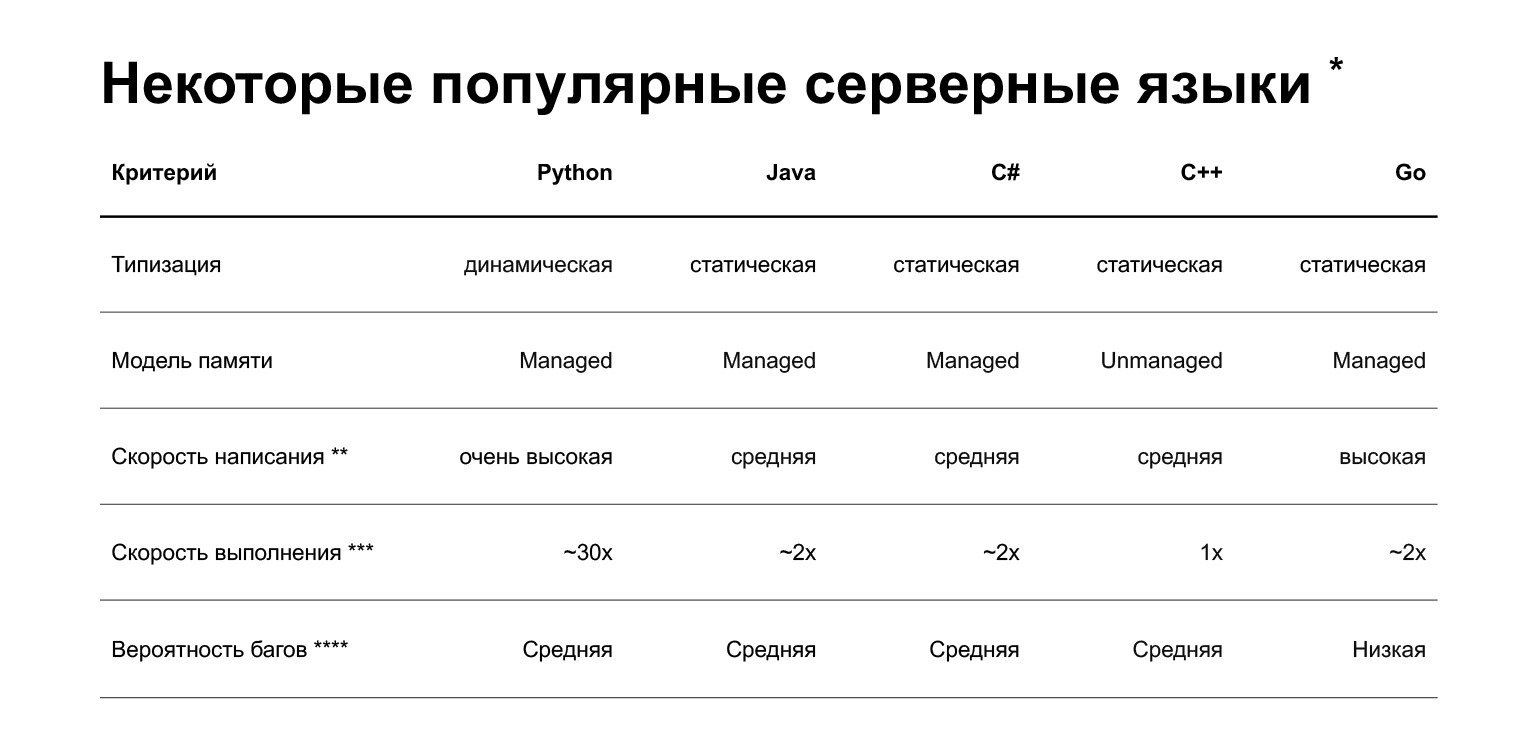
wir. Warum Python? Die Folie zeigt einen Vergleich mehrerer Sprachen, die derzeit in der Backend-Entwicklung verwendet werden. Aber kurz gesagt, was ist der Vorteil von Python? Sie können schnell Code darauf schreiben. Das ist natürlich sehr subjektiv - Leute, die cooles C ++ oder Go schreiben, können damit streiten. Im Durchschnitt ist das Schreiben in Python jedoch schneller.
Was sind die Nachteile? Der erste und wahrscheinlich größte Nachteil ist, dass Python langsamer ist. Es kann 30-mal langsamer sein als in anderen Sprachen. Hier ist eineStudiezu diesem Thema. Die Geschwindigkeit hängt jedoch von der Aufgabe ab. Es gibt zwei Klassen von Aufgaben:
- CPU-gebunden, CPU-gebundene Aufgaben, CPU-gebunden.
- E / A-gebunden, Aufgaben durch Eingabe / Ausgabe begrenzt: entweder über das Netzwerk oder in Datenbanken.
Wenn Sie das CPU-gebundene Problem lösen, ist Python langsamer. Wenn E / A gebunden ist und dies eine große Klasse von Aufgaben ist, müssen Sie Benchmarks ausführen, um die Ausführungsgeschwindigkeit zu verstehen. Und wenn Sie Python mit anderen Sprachen vergleichen, werden Sie vielleicht nicht einmal den Leistungsunterschied bemerken.
Darüber hinaus wird Python dynamisch typisiert: Der Interpreter überprüft beim Kompilieren keine Typen. In Version 3.5 wurden Typhinweise angezeigt, mit denen Sie Typen statisch angeben können, die jedoch nicht sehr streng sind. Das heißt, Sie werden einige Fehler bereits in der Produktion und nicht in der Kompilierungsphase feststellen. Andere beliebte Sprachen für das Backend - Java, C #, C ++, Go - haben eine statische Typisierung: Wenn Sie das falsche Objekt im Code übergeben, werden Sie vom Compiler darüber informiert.
Wie wird Python in der Taxi-Produktentwicklung eingesetzt? Wir bewegen uns in Richtung einer Microservice-Architektur. Wir haben bereits 160 Microservices, nämlich Lebensmittelgeschäfte - 35, davon 15 in Python, 20 - mit Pluspunkten. Das heißt, wir schreiben jetzt entweder nur in Python oder auf Pluspunkten.
Wie wählen wir die Sprache? Das erste sind die Ladeanforderungen, dh wir sehen, ob Python damit umgehen kann oder nicht. Wenn er zieht, dann schauen wir uns die Kompetenz der Teamentwickler an.
Jetzt möchte ich über den Dolmetscher sprechen. Wie funktioniert CPython?
Dolmetschergerät
Es kann sich die Frage stellen: Warum müssen wir wissen, wie der Dolmetscher funktioniert? Die Frage ist gültig. Sie können problemlos Dienste schreiben, ohne zu wissen, was sich unter der Haube befindet. Die Antworten können wie folgt lauten:
1. Optimierung für hohe Last. Stellen Sie sich vor, Sie haben einen Python-Dienst. Es funktioniert, die Last ist gering. Aber eines Tages kommt die Aufgabe zu Ihnen - einen Stift zu schreiben, der für eine schwere Last bereit ist. Sie können nicht davon loskommen, Sie können nicht den gesamten Dienst in C ++ neu schreiben. Sie müssen den Service also für hohe Auslastung optimieren. Das Verständnis der Funktionsweise des Dolmetschers kann dabei helfen.
2. Debuggen komplexer Fälle. Angenommen, der Dienst wird ausgeführt, aber der Speicher beginnt darin zu "lecken". Bei Yandex.Taxi hatten wir erst kürzlich einen solchen Fall. Der Dienst verbrauchte jede Stunde 8 GB Speicher und stürzte ab. Wir müssen es herausfinden. Es geht um die Sprache, Python. Kenntnisse über die Funktionsweise der Speicherverwaltung in Python sind erforderlich.
3. Dies ist nützlich, wenn Sie komplexe Bibliotheken oder komplexen Code schreiben möchten.
4. Und im Allgemeinen - es wird als eine gute Form angesehen, das Werkzeug zu kennen, mit dem Sie auf einer tieferen Ebene arbeiten, und nicht nur als Benutzer. Dies wird in Yandex geschätzt.
5. Sie stellen bei Interviews Fragen dazu, aber das ist nicht einmal der Punkt, sondern Ihre allgemeine IT-Perspektive.

Erinnern wir uns kurz an die Arten von Übersetzern. Wir haben Compiler und Interpreten. Wie Sie wahrscheinlich wissen, übersetzt der Compiler Ihren Quellcode direkt in Maschinencode. Vielmehr übersetzt der Interpreter zuerst in Bytecode und führt ihn dann aus. Python ist eine interpretierte Sprache.
Bytecode ist eine Art Zwischencode, der aus dem Original erhalten wird. Es ist nicht an die Plattform gebunden und läuft auf einer virtuellen Maschine. Warum virtuell? Dies ist kein echtes Auto, sondern eine Art Abstraktion.

Welche Arten von virtuellen Maschinen gibt es? Registrieren und stapeln. Aber hier müssen wir uns nicht daran erinnern, sondern daran, dass Python eine Stack-Maschine ist. Als nächstes werden wir sehen, wie der Stapel funktioniert.
Und noch eine Einschränkung: Hier werden wir nur über CPython sprechen. CPython ist eine Referenz-Python-Implementierung, die, wie Sie sich vorstellen können, in C geschrieben wurde. Wird als Synonym verwendet: Wenn wir über Python sprechen, sprechen wir normalerweise über CPython.
Es gibt aber auch andere Dolmetscher. Es gibt PyPy, das die JIT-Kompilierung verwendet und etwa fünfmal schneller ist. Es wird selten verwendet. Ich habe mich ehrlich gesagt nicht getroffen. Es gibt JPython, es gibt IronPython, das Bytecode für die Java Virtual Machine und für die Dotnet-Maschine übersetzt. Dies liegt außerhalb des Rahmens des heutigen Vortrags - um ehrlich zu sein, bin ich nicht darauf gestoßen. Schauen wir uns also CPython an.

Mal sehen was passiert. Sie haben eine Quelle, eine Zeile, die Sie ausführen möchten. Was macht der Dolmetscher? Eine Zeichenfolge ist nur eine Sammlung von Zeichen. Um etwas Sinnvolles daraus zu machen, übersetzen Sie zuerst den Code in Token. Ein Token ist ein gruppierter Satz von Zeichen, eine Kennung, eine Zahl oder eine Art Iteration. Tatsächlich übersetzt der Interpreter den Code in Token.

Ferner wird der abstrakte Syntaxbaum AST aus diesen Token erstellt. Machen Sie sich auch noch keine Sorgen, dies sind nur einige Bäume, in deren Knoten Sie Operationen haben. Nehmen wir an, in unserem Fall gibt es BinOp, eine binäre Operation. Operation - Potenzierung, Operanden: Die zu erhöhende Zahl und die zu erhöhende Kraft.
Außerdem können Sie mit diesen Bäumen bereits Code erstellen. Ich vermisse viele Schritte, es gibt einen Optimierungsschritt, andere Schritte. Dann werden diese Syntaxbäume in Bytecode übersetzt.
Lassen Sie uns hier genauer sehen. Ein Bytecode ist, wie der Name schon sagt, ein Code, der aus Bytes besteht. Und in Python besteht der Bytecode ab 3.6 aus zwei Bytes.

Das erste Byte ist der Operator selbst, der als Opcode bezeichnet wird. Das zweite Byte ist das Argument oparg. Es sieht so aus, als hätten wir von oben. Das heißt, eine Folge von Bytes. Aber Python hat ein Modul namens dis von Disassembler, mit dem wir eine besser lesbare Darstellung sehen können.
Wie sieht es aus? Es gibt eine Zeilennummer der Quelle - die ganz links. Die zweite Spalte ist die Adresse. Wie gesagt, der Bytecode in Python 3.6 benötigt zwei Bytes, daher sind alle Adressen gerade und wir sehen 0, 2, 4 ...
Load.name, Load.const sind bereits die Codeoptionen selbst, dh die Codes dieser Operationen, die Python sollte ausgeführt werden. 0, 0, 1, 1 sind oparg, dh die Argumente dieser Operationen. Mal sehen, wie sie als nächstes gemacht werden.
(...) Mal sehen, wie der Bytecode in Python ausgeführt wird, welche Strukturen dafür da sind.

Wenn Sie C nicht kennen, ist es okay. Fußnoten dienen dem allgemeinen Verständnis.
Python hat zwei Strukturen, mit denen wir Bytecode ausführen können. Das erste ist CodeObject, Sie können seine Zusammenfassung sehen. In der Tat ist die Struktur größer. Dies ist Code ohne Kontext. Dies bedeutet, dass diese Struktur tatsächlich den Bytecode enthält, den wir gerade gesehen haben. Es enthält die Namen der in dieser Funktion verwendeten Variablen, wenn die Funktion Verweise auf Konstanten, Namen von Konstanten usw. enthält.

Die nächste Struktur ist FrameObject. Dies ist bereits der Ausführungskontext, die Struktur, die bereits den Wert der Variablen enthält. Verweise auf globale Variablen; den Ausführungsstapel, über den wir etwas später sprechen werden, und viele andere Informationen. Angenommen, die Nummer der Befehlsausführung.
Beispiel: Wenn Sie eine Funktion mehrmals aufrufen möchten, haben Sie dasselbe CodeObject und für jeden Aufruf wird ein neues FrameObject erstellt. Es wird seine eigenen Argumente haben, seinen eigenen Stapel. Sie sind also miteinander verbunden.

Was ist die Hauptinterpreterschleife, wie wird der Bytecode ausgeführt? Sie haben gesehen, wir hatten eine Liste dieser Opcodes mit oparg. Wie wird das alles gemacht? Python hat wie jeder Interpreter eine Schleife, die diesen Bytecode ausführt. Das heißt, ein Frame tritt ein, und Python geht einfach den Bytecode der Reihe nach durch, prüft, um welche Art von Oparg es sich handelt, und geht mit einem riesigen Schalter zu seinem Handler. Hier wird zum Beispiel nur ein Opcode angezeigt. Zum Beispiel haben wir hier eine binäre Subtraktion, eine binäre Subtraktion, sagen wir, "AB" wird an dieser Stelle durchgeführt.
Lassen Sie uns erklären, wie das binäre Subtrahieren funktioniert. Sehr einfach, dies ist einer der einfachsten Codes. Die TOP-Funktion nimmt den obersten Wert aus dem Stapel, entfernt ihn vom obersten Wert, entfernt ihn nicht einfach vom Stapel und ruft dann die PyNumber_Subtract-Funktion auf. Ergebnis: Die Schrägstrich-Funktion SET_TOP wird auf den Stapel zurückgeschoben. Wenn der Stapel nicht klar ist, folgt ein Beispiel.

Ganz kurz über die GIL. Die GIL ist ein Mutex auf Prozessebene in Python, der diesen Mutex in der Hauptinterpreterschleife verwendet. Und erst danach wird der Bytecode ausgeführt. Dies geschieht so, dass jeweils nur ein Thread den Bytecode ausführt, um die interne Struktur des Interpreters zu schützen.
Nehmen wir an, dass alle Objekte in Python eine Reihe von Verweisen auf sie haben. Und wenn zwei Threads diese Anzahl von Links ändern, wird der Interpreter unterbrochen. Daher gibt es eine GIL.
Dies erfahren Sie in der Vorlesung über asynchrone Programmierung. Wie kann das für Sie wichtig sein? Multithreading wird nicht verwendet, da selbst wenn Sie mehrere Threads erstellen, im Allgemeinen nur einer davon ausgeführt wird und der Bytecode in einem der Threads ausgeführt wird. Verwenden Sie daher entweder Multiprocessing oder Sish Extension oder etwas anderes.

Ein kurzes Beispiel. Sie können diesen Frame sicher von Python aus erkunden. Es gibt ein sys-Modul mit einer Unterstrichfunktion get_frame. Sie können einen Frame erhalten und sehen, welche Variablen vorhanden sind. Es gibt eine Anweisung. Dies ist mehr für den Unterricht, im wirklichen Leben habe ich es nicht benutzt.
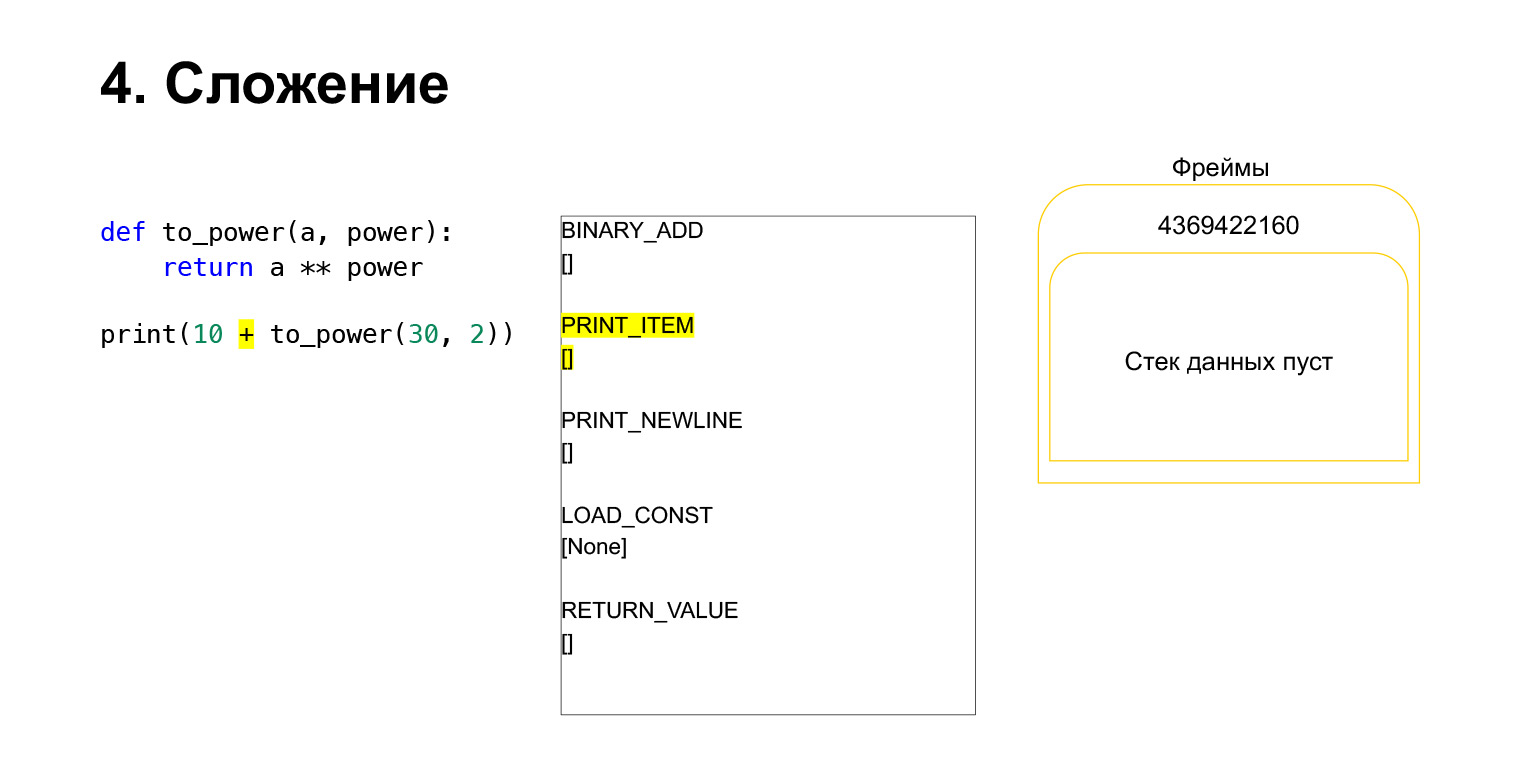
Lassen Sie uns versuchen zu sehen, wie der Stapel der virtuellen Python-Maschine zum Verständnis funktioniert. Wir haben einen ziemlich einfachen Code, der nicht versteht, was er tut.
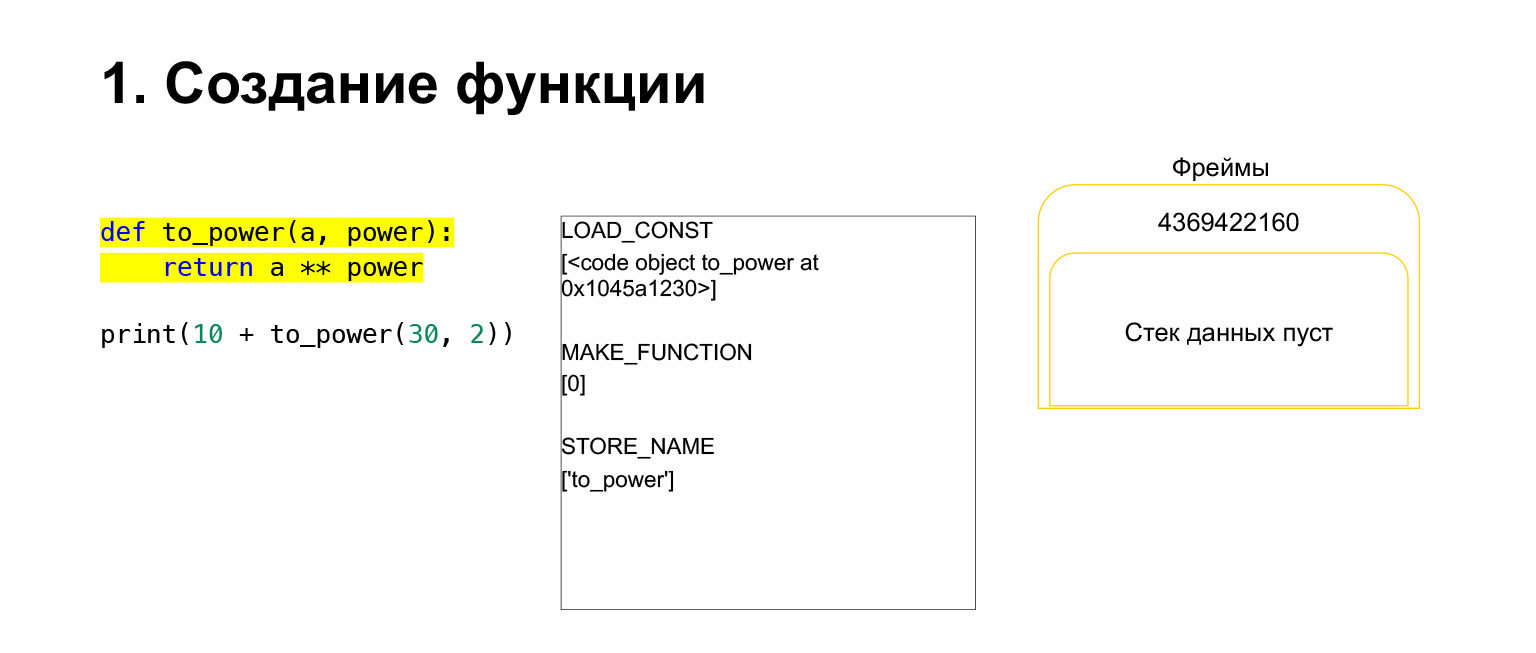
Links ist der Code. Der Teil, den wir jetzt untersuchen, ist gelb hervorgehoben. In der zweiten Spalte haben wir den Bytecode für dieses Stück. Die dritte Spalte enthält Frames mit Stapeln. Das heißt, jedes FrameObject hat seinen eigenen Ausführungsstapel.
Was macht Python? Es geht nur in der richtigen Reihenfolge, Bytecode, in der mittleren Spalte, wird ausgeführt und arbeitet mit dem Stapel.
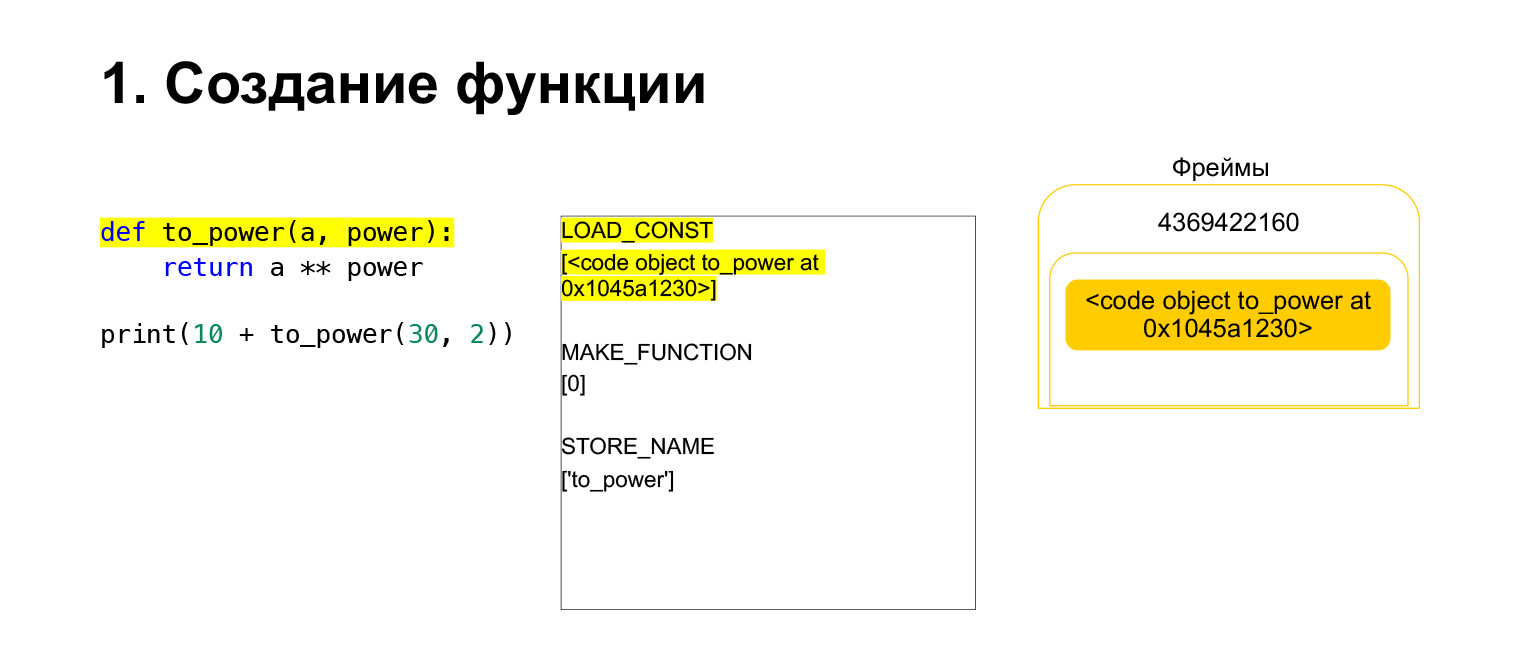
Wir haben den ersten Opcode namens LOAD_CONST ausgeführt. Es lädt eine Konstante. Wir haben den Teil übersprungen, dort wird ein CodeObject erstellt und wir hatten irgendwo in den Konstanten ein CodeObject. Python hat es mit LOAD_CONST auf den Stack geladen. Wir haben jetzt ein CodeObject auf dem Stapel in diesem Frame. Wir können weitermachen.
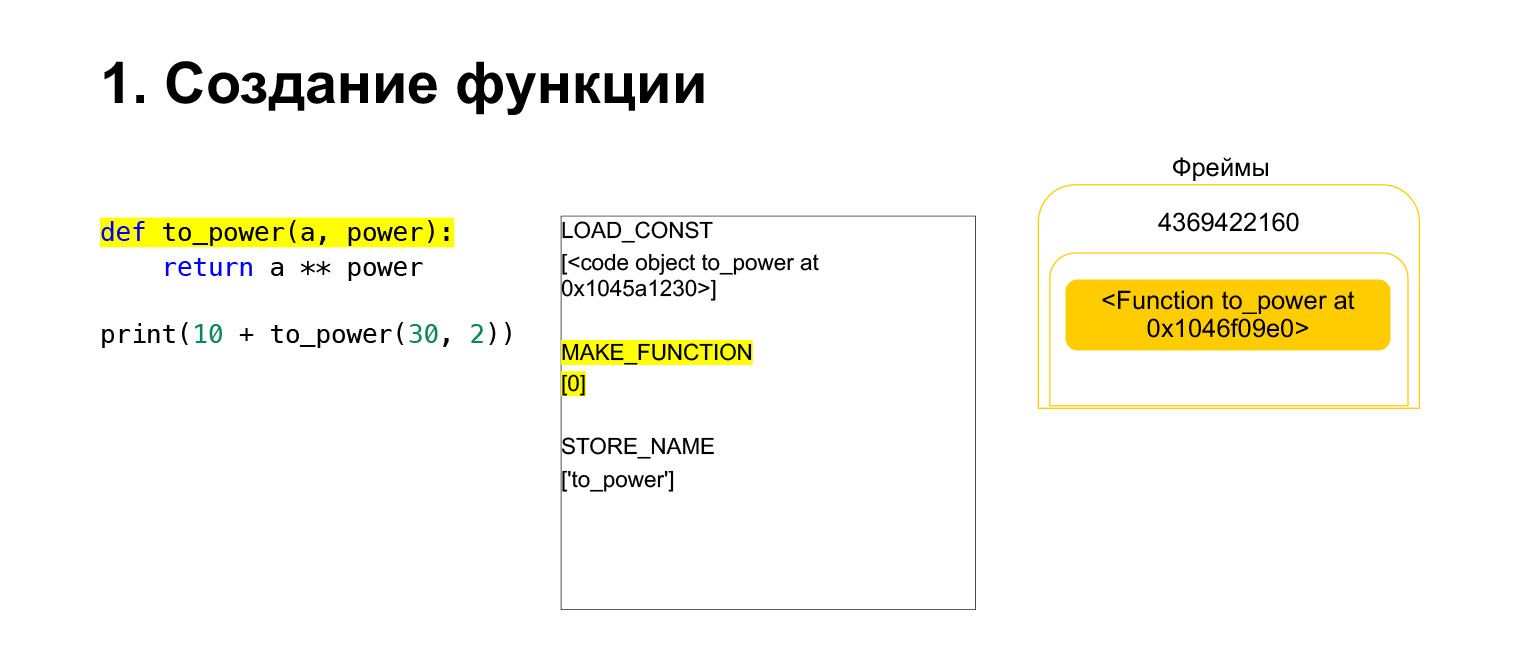
Dann führt Python den Opcode MAKE_FUNCTION aus. MAKE_FUNCTION macht offensichtlich eine Funktion. Es wird erwartet, dass Sie ein CodeObject auf dem Stapel hatten. Es führt eine Aktion aus, erstellt eine Funktion und schiebt die Funktion zurück auf den Stapel. Jetzt haben Sie FUNCTION anstelle von CodeObject, das sich auf dem Frame-Stack befand. Und jetzt muss diese Funktion in die Variable to_power eingefügt werden, damit Sie darauf verweisen können.
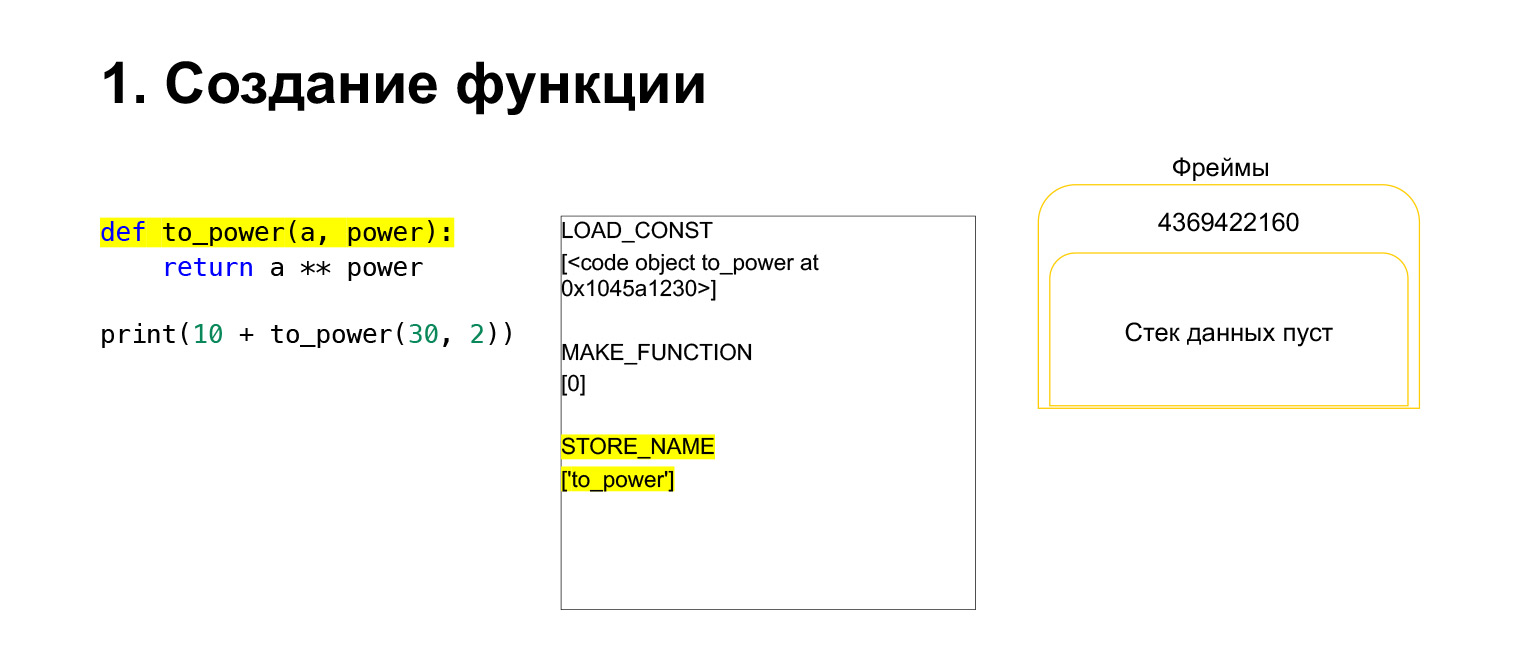
Der Opcode STORE_NAME wird ausgeführt und in die Variable to_power eingefügt. Wir hatten eine Funktion auf dem Stapel, jetzt ist es die to_power-Variable, auf die Sie verweisen können.
Als nächstes wollen wir 10 + den Wert dieser Funktion drucken.
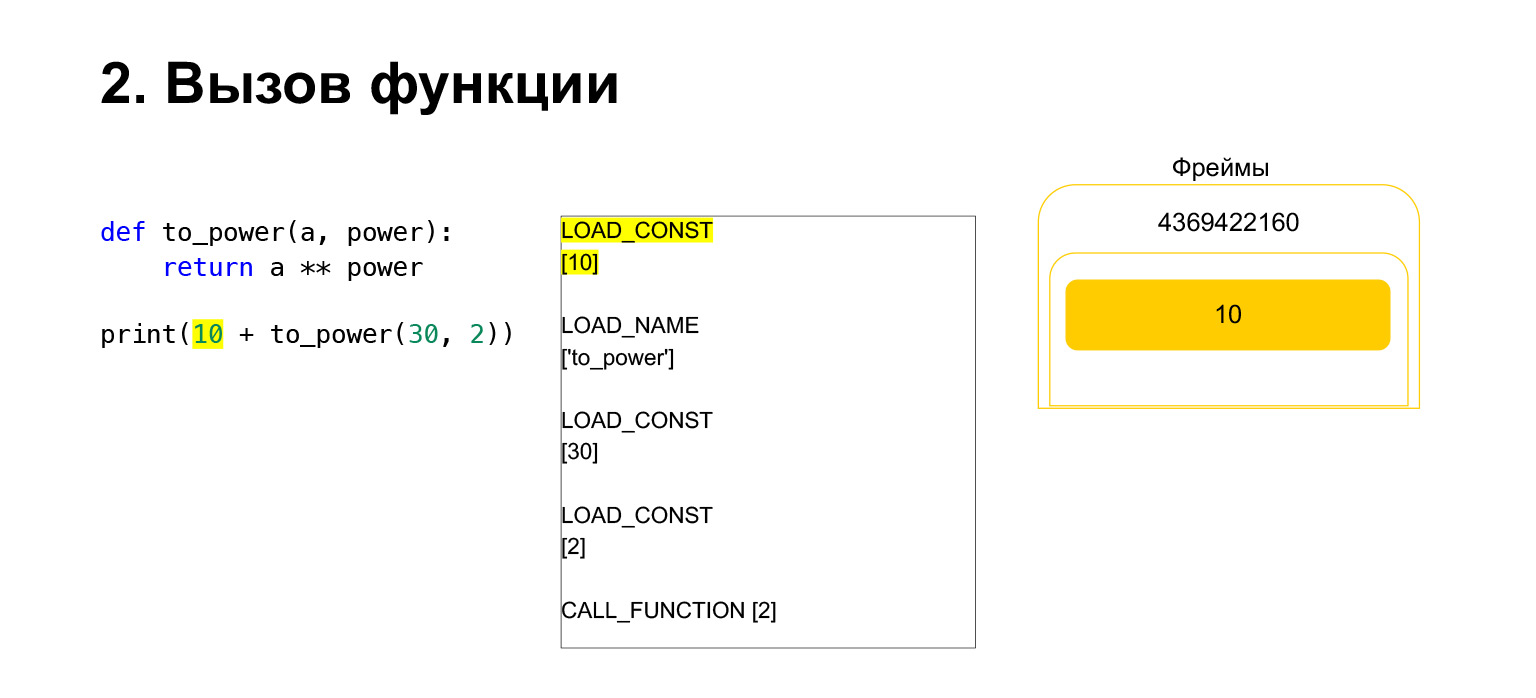
Was macht Python? Dies wurde in Bytecode konvertiert. Der erste Opcode, den wir haben, ist LOAD_CONST. Wir laden die Top Ten auf den Stapel. Ein Dutzend erschien auf dem Stapel. Jetzt müssen wir to_power ausführen.

Die Funktion wird wie folgt ausgeführt. Wenn es Positionsargumente hat - wir werden uns den Rest vorerst nicht ansehen -, legt Python zuerst die Funktion selbst auf den Stapel. Dann fügt es alle Argumente ein und ruft CALL_FUNCTION mit der Argumentnummer der Funktionsargumente auf.
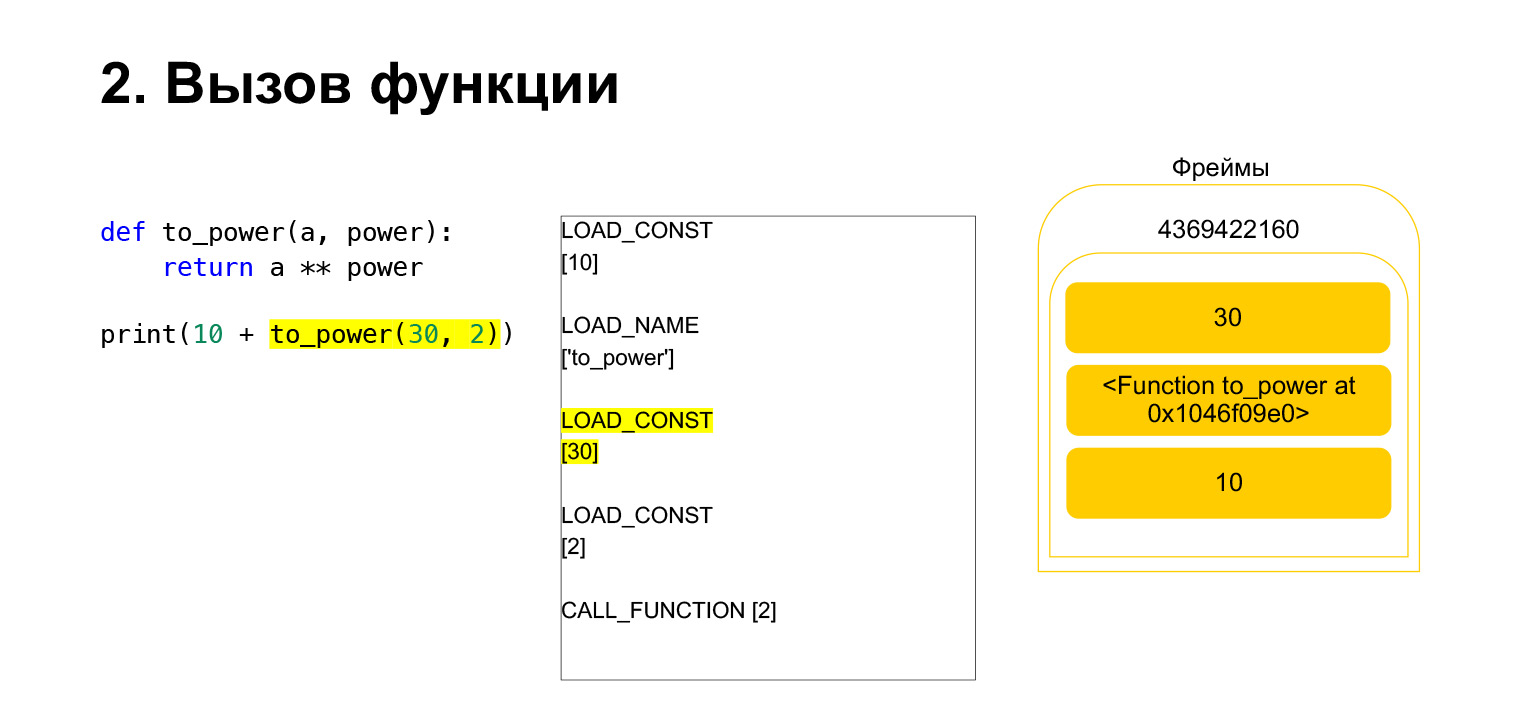
Wir haben das erste Argument auf den Stapel geladen, dies ist eine Funktion.
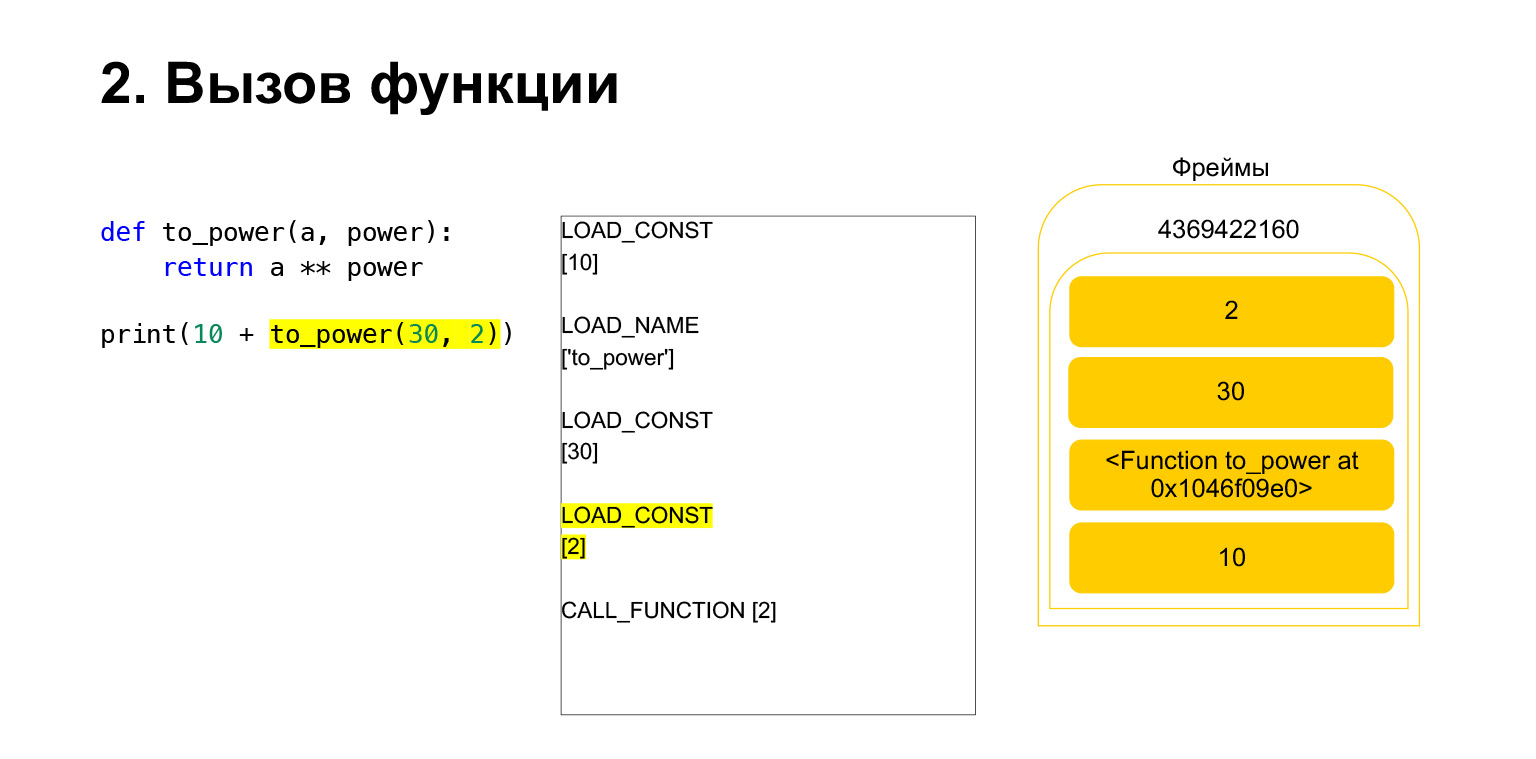
Wir haben zwei weitere Argumente auf den Stapel geladen - 30 und 2. Jetzt haben wir eine Funktion und zwei Argumente auf dem Stapel. Die Oberseite des Stapels befindet sich oben. CALL_FUNCTION wartet auf uns. Wir sagen: CALL_FUNCTION (2), das heißt, wir haben eine Funktion mit zwei Argumenten. CALL_FUNCTION erwartet zwei Argumente auf dem Stapel, gefolgt von einer Funktion. Wir haben es: 2, 30 und FUNCTION.
Opcode in Bearbeitung.
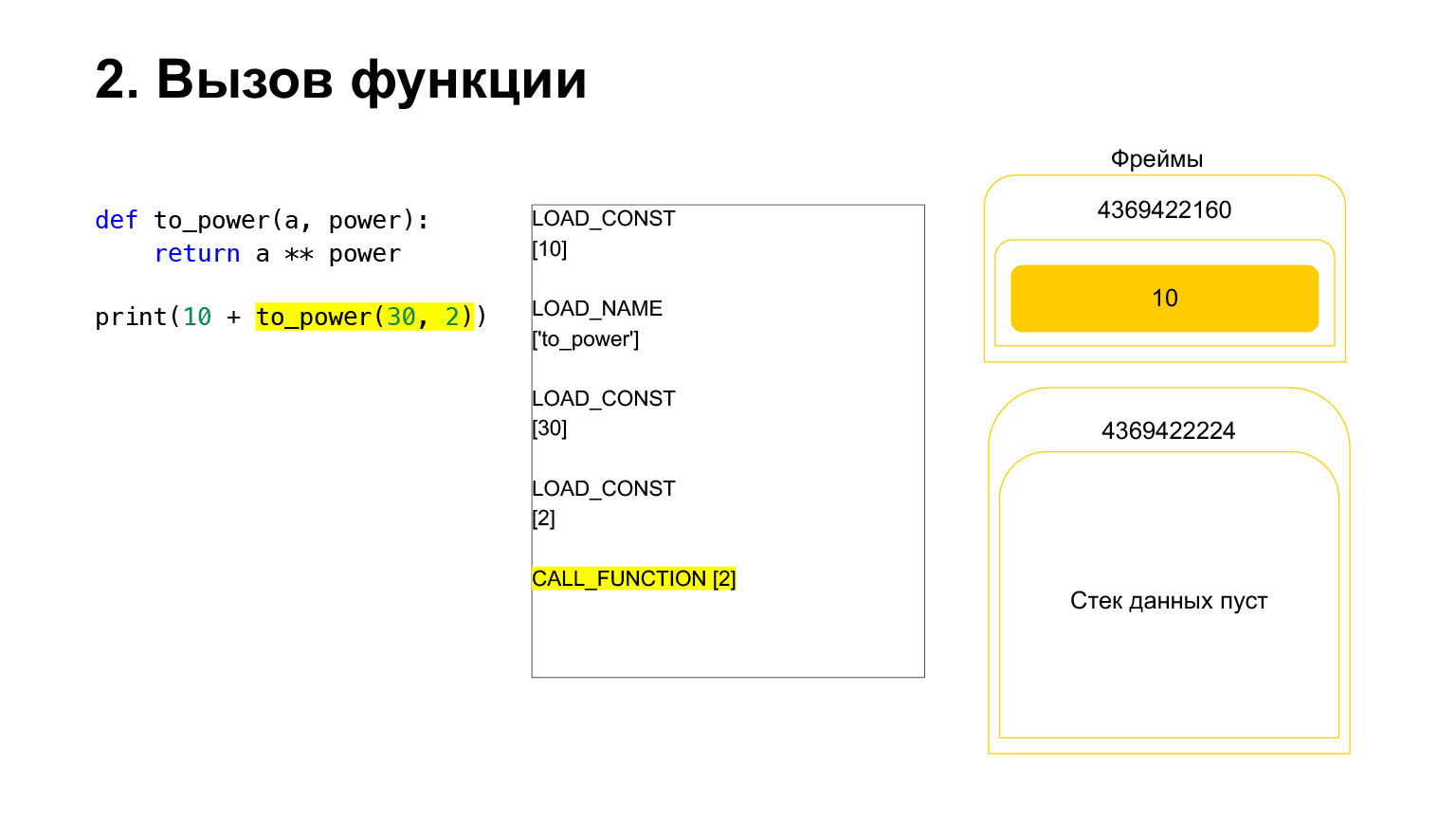
Für uns wird dementsprechend, wenn dieser Stapel verlässt, eine neue Funktion erstellt, in der die Ausführung nun stattfinden wird.
Der Rahmen hat einen eigenen Stapel. Für seine Funktion wurde ein neuer Rahmen erstellt. Es ist noch leer.
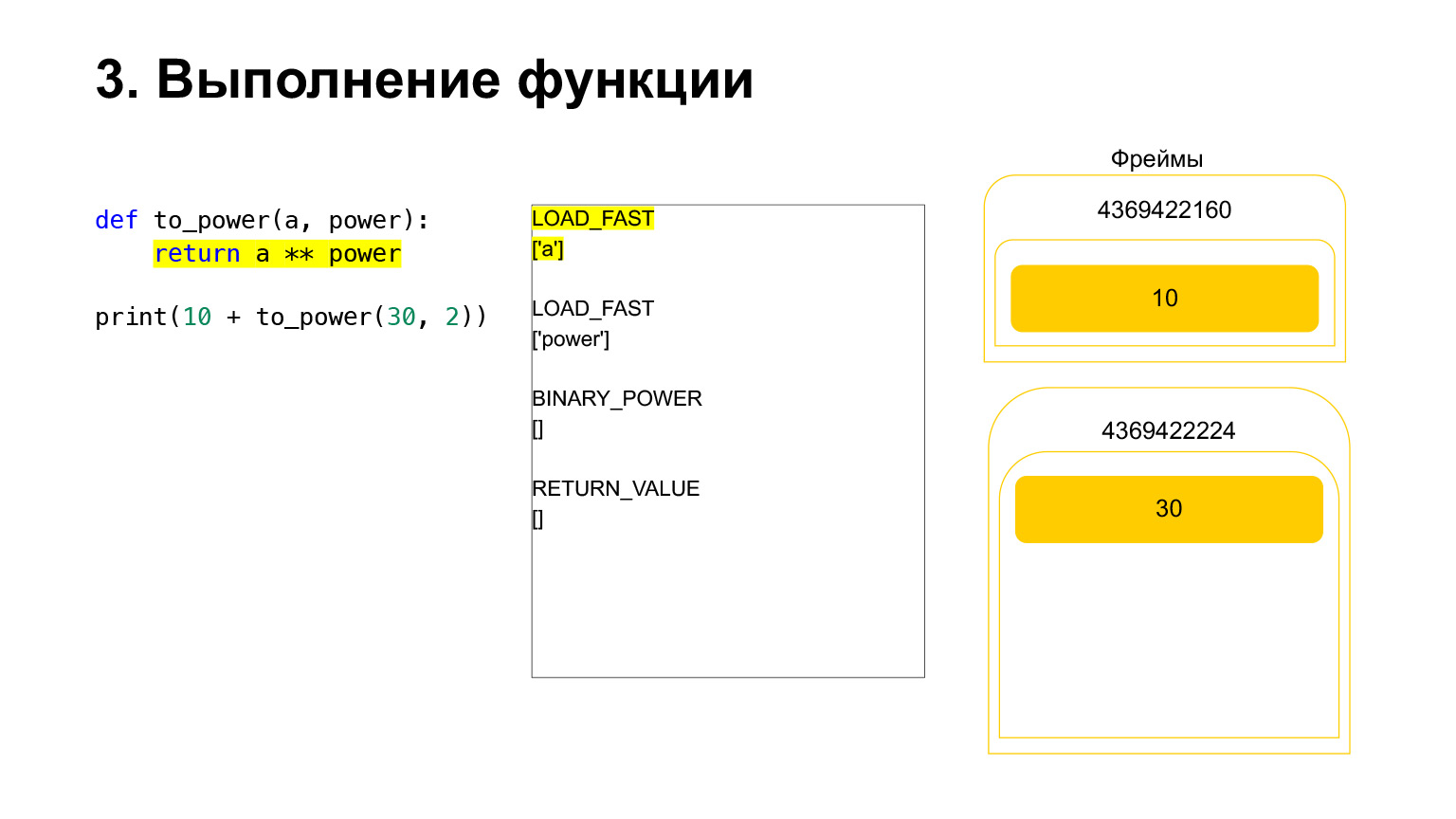
Die weitere Ausführung erfolgt. Hier ist es schon einfacher. Wir müssen A an die Macht bringen. Wir laden den Wert der Variablen A - 30 auf den Stapel. Der Wert der Variablen power - 2.
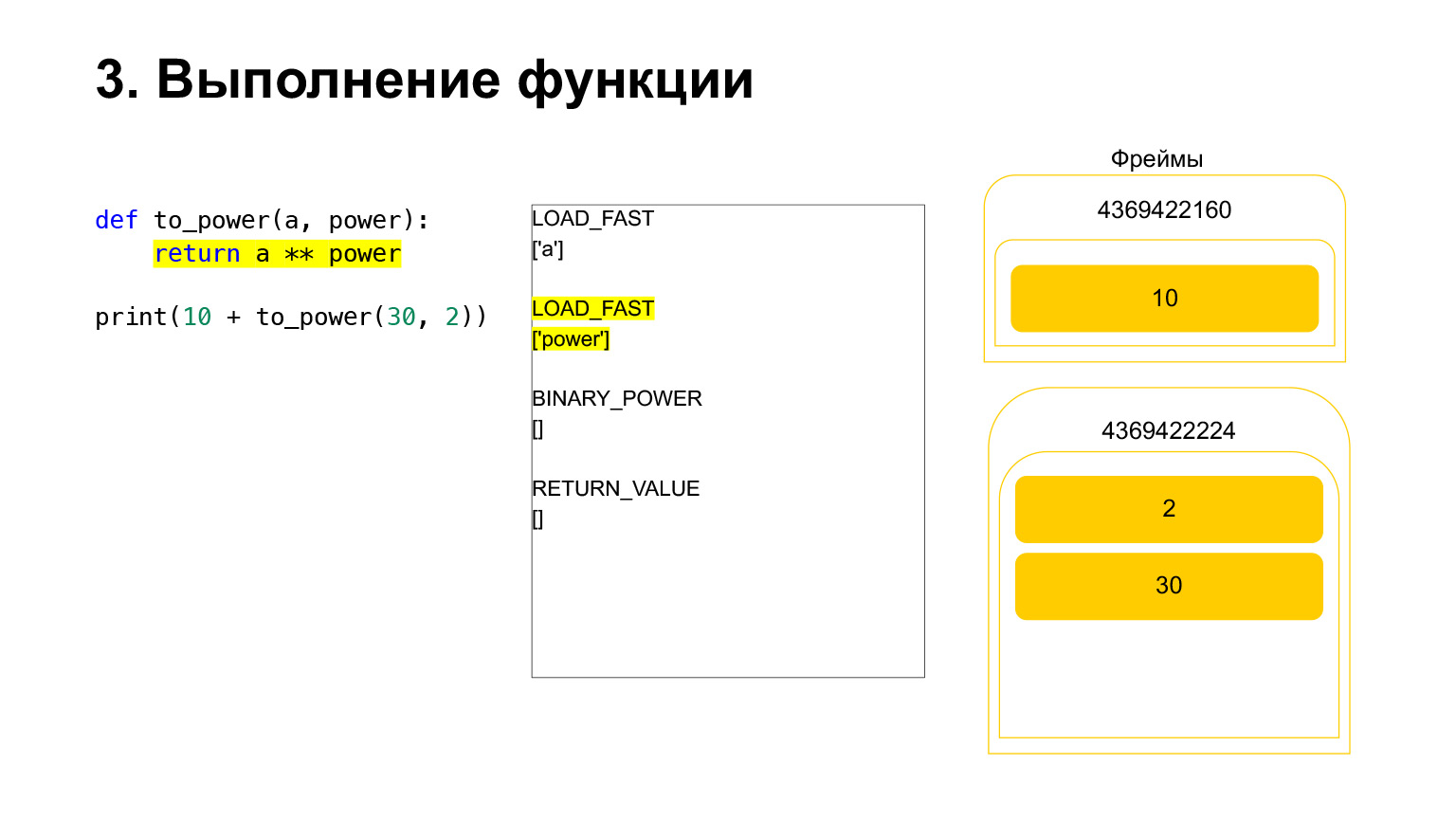
Und der Opcode BINARY_POWER wird ausgeführt.
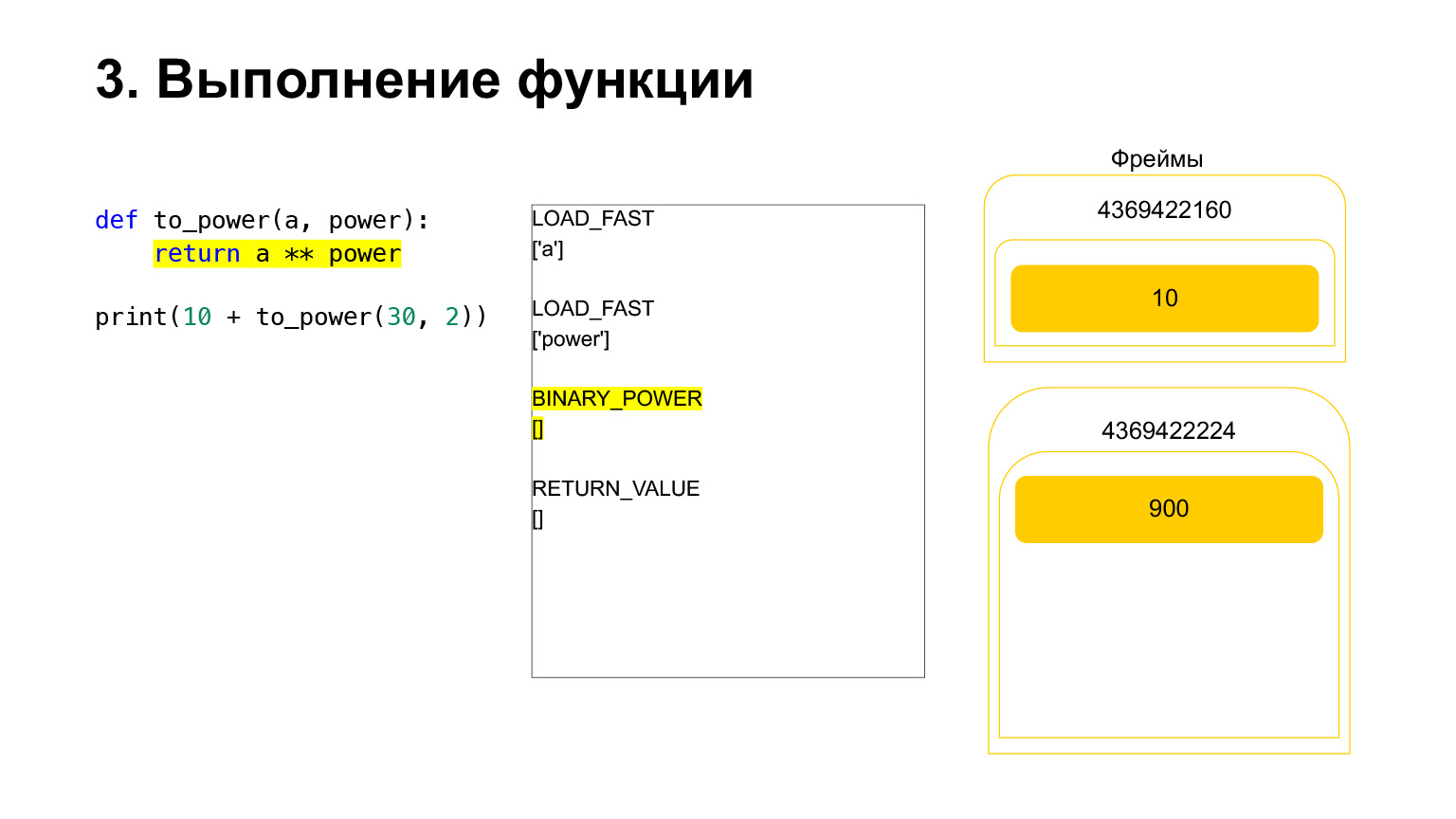
Wir erhöhen eine Zahl auf die Potenz einer anderen und legen sie wieder auf den Stapel. Es stellte sich 900 auf dem Funktionsstapel heraus.
Der nächste Opcode RETURN_VALUE gibt den Wert vom Stapel zum vorherigen Frame zurück.

So erfolgt die Ausführung. Wenn die Funktion abgeschlossen ist, wird der Frame höchstwahrscheinlich gelöscht, wenn er keine Referenzen enthält, und der Frame der vorherigen Funktion enthält zwei Zahlen.

Dann ist alles ungefähr gleich. Die Zugabe erfolgt.
(...) Sprechen wir über Typen und PyObject.
Tippen

Ein Objekt ist eine Sish-Struktur, in der es zwei Hauptfelder gibt: Das erste ist die Anzahl der Verweise auf dieses Objekt, das zweite ist der Typ des Objekts, natürlich ein Verweis auf den Typ des Objekts.
Andere Objekte erben von PyObject, indem sie es einschließen. Das heißt, wenn wir ein Float betrachten, eine Gleitkommazahl, die Struktur dort ist PyFloatObject, dann hat es einen HEAD, der eine PyObject-Struktur ist, und zusätzlich Daten, dh double ob_fval, in denen der Wert dieses Floats selbst gespeichert ist.

Und das ist die Art von Objekt. Wir haben uns gerade den Typ in PyObject angesehen, eine Struktur, die einen Typ bezeichnet. Tatsächlich ist dies auch eine C-Struktur, die Zeiger auf Funktionen enthält, die das Verhalten dieses Objekts implementieren. Das heißt, es gibt dort eine sehr große Struktur. Es sind Funktionen angegeben, die aufgerufen werden, wenn Sie beispielsweise zwei Objekte dieses Typs hinzufügen möchten. Oder Sie möchten dieses Objekt subtrahieren, aufrufen oder erstellen. Alles, was Sie mit Typen tun können, muss in dieser Struktur angegeben werden.

Schauen wir uns zum Beispiel int, Ganzzahlen in Python an. Auch eine sehr abgekürzte Version. Was könnte uns interessieren? Int hat tp_name. Sie können sehen, dass es tp_hash gibt, wir können Hash int bekommen. Wenn wir Hash auf int aufrufen, wird diese Funktion aufgerufen. tp_call wir haben null, nicht definiert, das heißt, wir können int nicht aufrufen. tp_str - String Cast nicht definiert. Python hat eine str-Funktion, die in einen String umgewandelt werden kann.
Es ist nicht auf die Folie gekommen, aber Sie alle wissen bereits, dass int noch gedruckt werden kann. Warum ist hier Null? Da es auch tp_repr gibt, verfügt Python über zwei Funktionen zum Übergeben von Zeichenfolgen: str und repr. Detaillierteres Casting zum String. Es ist tatsächlich definiert, es ist einfach nicht auf die Folie gekommen und es wird aufgerufen, wenn Sie tatsächlich zu einer Zeichenfolge führen.
Ganz am Ende sehen wir tp_new - eine Funktion, die beim Erstellen dieses Objekts aufgerufen wird. tp_init wir haben null. Wir alle wissen, dass int kein veränderlicher Typ ist, unveränderlich. Nach dem Erstellen macht es keinen Sinn, es zu ändern und zu initialisieren, daher gibt es eine Null.

Schauen wir uns zum Beispiel auch Bool an. Wie einige von Ihnen vielleicht wissen, erbt Bool in Python tatsächlich von int. Das heißt, Sie können Bool hinzufügen und miteinander teilen. Dies ist natürlich nicht möglich, aber es ist möglich.
Wir sehen, dass es eine tp_base gibt - einen Zeiger auf das Basisobjekt. Alles außer tp_base sind die einzigen Dinge, die überschrieben wurden. Das heißt, es hat einen eigenen Namen, eine eigene Präsentationsfunktion, bei der es sich nicht um eine geschriebene Zahl handelt, sondern um eine wahre oder falsche. Darstellung als Zahl, einige logische Funktionen werden dort überschrieben. Docstring ist seine eigene und seine Schöpfung. Alles andere kommt von int.

Ich werde Ihnen ganz kurz über Listen erzählen. In Python ist eine Liste ein dynamisches Array. Ein dynamisches Array ist ein Array, das folgendermaßen funktioniert: Sie initialisieren einen Speicherbereich im Voraus mit einer bestimmten Dimension. Fügen Sie dort Elemente hinzu. Sobald die Anzahl der Elemente diese Größe überschreitet, erweitern Sie sie um einen bestimmten Rand, dh nicht um eins, sondern um einen Wert von mehr als eins, sodass ein guter Asin-Punkt vorliegt.
In Python wächst die Größe mit 0, 4, 8, 16, 25, dh gemäß einer Formel, mit der wir die Einfügung für eine Konstante asymptotisch durchführen können. Und Sie können sehen, dass es einen Auszug aus der Einfügefunktion in der Liste gibt. Das heißt, wir ändern die Größe. Wenn wir keine Größenänderung haben, werfen wir einen Fehler und weisen das Element zu. In Python ist dies ein normales dynamisches Array, das in C implementiert ist.
(...) Lassen Sie uns kurz über Wörterbücher sprechen. Sie sind überall in Python.
Wörterbücher
Wir alle wissen, dass in Objekten die gesamte Zusammensetzung von Klassen in Wörterbüchern enthalten ist. Viele Dinge basieren auf ihnen. Wörterbücher in Python in einer Hash-Tabelle.
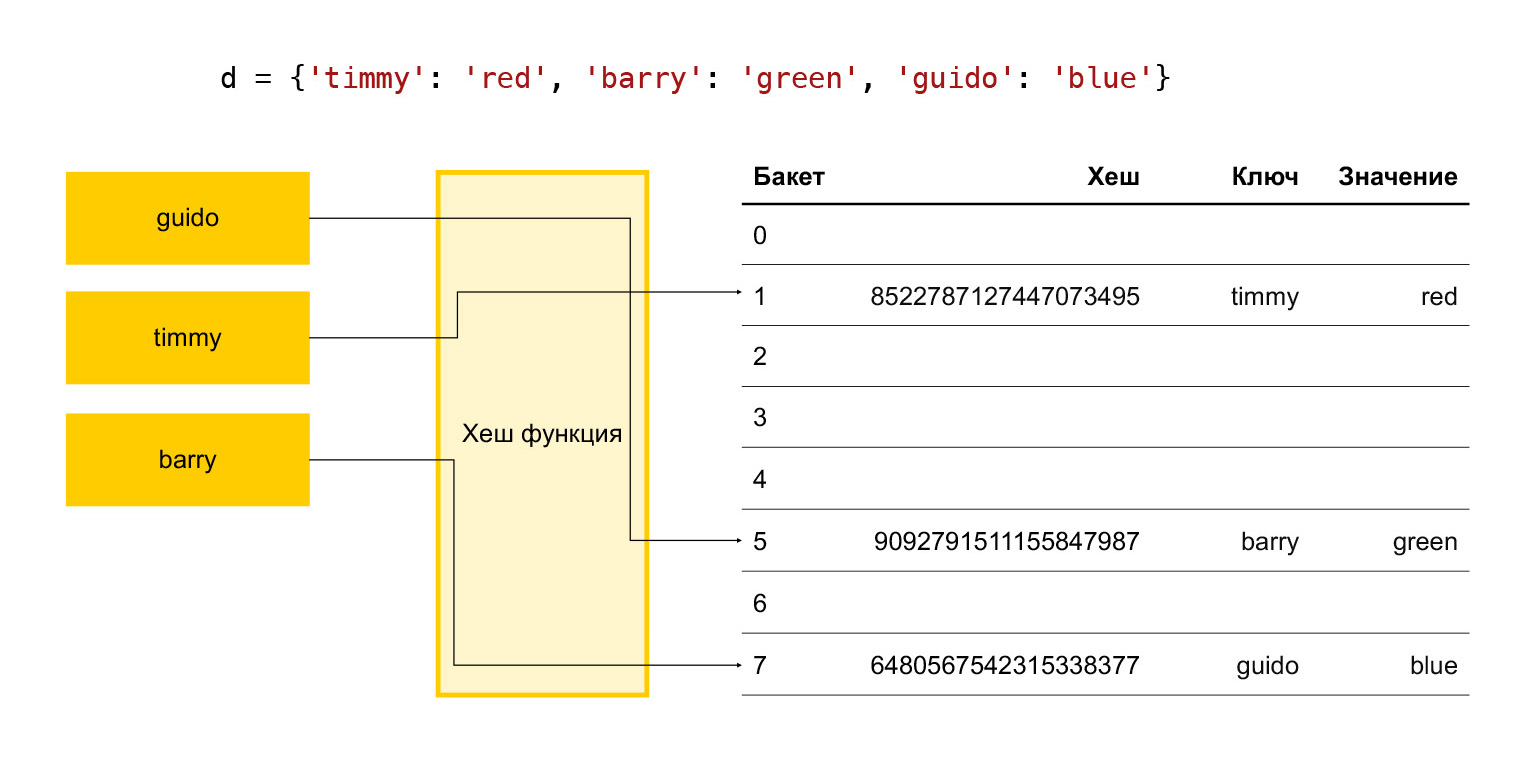
Kurz gesagt, wie funktioniert eine Hash-Tabelle? Es gibt einige Schlüssel: Timmy, Barry, Guido. Wir wollen sie in ein Wörterbuch aufnehmen, wir führen jeden Schlüssel durch eine Hash-Funktion. Es stellt sich heraus, ein Hash. Wir verwenden diesen Hash, um den Eimer zu finden. Ein Bucket ist einfach eine Zahl in einem Array von Elementen. Die endgültige Modulo-Teilung erfolgt. Wenn der Eimer leer ist, legen wir einfach den gewünschten Artikel hinein. Wenn es nicht leer ist und bereits ein Element vorhanden ist, handelt es sich um eine Kollision, und wir wählen den nächsten Bucket aus, um festzustellen, ob er frei ist oder nicht. Und so weiter, bis wir einen freien Eimer finden.
Damit der Addiervorgang in angemessener Zeit stattfinden kann, müssen wir daher ständig eine bestimmte Anzahl von Eimern frei halten. Wenn wir uns sonst der Größe dieses Arrays nähern, werden wir sehr lange nach einem freien Bucket suchen und alles wird langsamer.
Daher wird in Python empirisch angenommen, dass ein Drittel der Array-Elemente immer frei ist. Wenn ihre Anzahl mehr als zwei Drittel beträgt, wird das Array erweitert. Dies ist nicht gut, da ein Drittel der Elemente verschwendet wird und nichts Nützliches gespeichert wird.

Link von der Folie
Daher hat Python seit Version 3.6 so etwas getan. Links sehen Sie, wie es vorher war. Wir haben ein spärliches Array, in dem diese drei Elemente gespeichert sind. Seit 3.6 haben sie beschlossen, ein derart spärliches Array zu einem regulären Array zu machen, gleichzeitig aber die Indizes der Bucket-Elemente in separaten Array-Indizes zu speichern.
Wenn wir uns das Array von Indizes ansehen, dann haben wir im ersten Bucket None, im zweiten ein Element mit Index 1 aus diesem Array usw.
Dies ermöglichte es zum einen, die Speichernutzung zu reduzieren, und zum anderen haben wir es auch kostenlos aus der Box bekommen geordnetes Feld. Das heißt, wir fügen diesem Array bedingt Elemente mit dem üblichen sish-Anhang hinzu, und das Array wird automatisch sortiert.
Es gibt einige interessante Optimierungen, die Python verwendet. Damit diese Hash-Tabellen funktionieren, benötigen wir eine Elementvergleichsoperation. Stellen Sie sich vor, wir fügen ein Element in eine Hash-Tabelle ein und möchten dann ein Element übernehmen. Wir nehmen den Hasch, gehen zum Eimer. Wir sehen: Der Eimer ist voll, da ist etwas. Aber ist das das Element, das wir brauchen? Vielleicht gab es eine Kollision, als es platziert wurde und der Gegenstand tatsächlich in einen anderen Eimer passte. Daher müssen wir die Schlüssel vergleichen. Wenn der Schlüssel falsch ist, verwenden wir denselben Suchmechanismus für den nächsten Bucket, der für die Kollisionsauflösung verwendet wird. Und wir gehen weiter.

Link von der Folie
Daher benötigen wir eine Schlüsselvergleichsfunktion. Im Allgemeinen kann die Objektvergleichsfunktion sehr teuer sein. Daher wird eine solche Optimierung verwendet. Zuerst vergleichen wir die Artikel-IDs. ID in CPython ist, wie Sie wissen, eine Position im Speicher.
Wenn die IDs identisch sind, sind sie dieselben Objekte und natürlich gleich. Dann geben wir True zurück. Wenn nicht, schauen Sie sich die Hashes an. Der Hash sollte eine ziemlich schnelle Operation sein, wenn wir ihn nicht irgendwie neu definiert haben. Wir nehmen Hashes von diesen beiden Objekten und vergleichen sie. Wenn ihre Hashes nicht gleich sind, sind die Objekte definitiv nicht gleich, also geben wir False zurück.
Und nur in einem sehr unwahrscheinlichen Fall - wenn unsere Hashes gleich sind, wir aber nicht wissen, ob es sich um dasselbe Objekt handelt - vergleichen wir nur dann die Objekte selbst.
Eine interessante Kleinigkeit: Sie können während der Iteration nichts in Schlüssel einfügen. Das ist ein Fehler.

Unter der Haube hat das Wörterbuch eine Variable namens version, in der die Version des Wörterbuchs gespeichert ist. Wenn Sie das Wörterbuch ändern, ändert sich die Version, Python versteht dies und gibt einen Fehler aus.

Wofür können Wörterbücher in einem praktischeren Beispiel verwendet werden? In Taxi haben wir Bestellungen und Bestellungen haben Status, die sich ändern können. Wenn Sie den Status ändern, müssen Sie bestimmte Aktionen ausführen: SMS senden, Bestellungen aufzeichnen.
Diese Logik ist in Python geschrieben. Um kein großes "Wenn der Bestellstatus so und so ist, tun Sie dies" zu schreiben, gibt es ein bestimmtes Diktat, in dem der Schlüssel der Bestellstatus ist. Und zu VALUE gibt es ein Tupel, das alle Handler enthält, die beim Übergang in diesen Status ausgeführt werden müssen. Dies ist eine gängige Praxis, in der Tat ist es ein Ersatz für den Schalter.

Noch ein paar Dinge nach Typ. Ich erzähle dir von unveränderlichen. Dies sind unveränderliche Datentypen, und veränderbare sind veränderbare Datentypen: Diktate, Klassen, Klasseninstanzen, Blätter und möglicherweise etwas anderes. Fast alles andere sind Zeichenfolgen, gewöhnliche Zahlen - sie sind unveränderlich. Wofür sind veränderbare Typen? Erstens erleichtern sie das Verständnis des Codes. Das heißt, wenn Sie im Code sehen, dass etwas ein Tupel ist, verstehen Sie, dass es sich nicht weiter ändert, und dies erleichtert Ihnen das Lesen des Codes? Verstehe, was als nächstes passieren wird. In Tupel ds können Sie keine Elemente eingeben. Sie werden dies verstehen und es wird Ihnen helfen, Sie und alle Personen zu lesen, die den Code für Sie lesen werden.
Daher gibt es eine Regel: Wenn Sie etwas nicht ändern, ist es besser, unveränderliche Typen zu verwenden. Es führt auch zu schnellerer Arbeit. Es gibt zwei Konstanten, die Tupel verwendet: pit_tuple, tap_tuple, max und CC. Was ist der Sinn? Für alle Tupel mit einer Größe von bis zu 20 wird eine bestimmte Zuordnungsmethode verwendet, die diese Zuordnung beschleunigt. Und es kann bis zu zweitausend solcher Objekte von jedem Typ geben, viel. Dies ist viel schneller als Blätter. Wenn Sie also Tupel verwenden, sind Sie schneller.
Es gibt auch Laufzeitprüfungen. Wenn Sie versuchen, etwas in ein Objekt einzufügen, und diese Funktion nicht unterstützt wird, liegt natürlich ein Fehler vor, eine Art Verständnis dafür, dass Sie etwas falsch gemacht haben. Schlüssel in einem Diktat können nur Objekte sein, deren Hash sich während ihrer Lebensdauer nicht ändert. Nur unveränderliche Objekte erfüllen diese Definition. Nur sie können Diktierschlüssel sein.

Wie sieht es in C aus? Beispiel. Links ist ein Tupel, rechts ist eine reguläre Liste. Hier sind natürlich nicht alle Unterschiede sichtbar, sondern nur die, die ich zeigen wollte. In der Liste im Feld tp_hash haben wir NotImplemented, dh die Liste hat keinen Hash. In Tupel gibt es eine Funktion, die Ihnen tatsächlich einen Hash zurückgibt. Genau aus diesem Grund kann Tupel unter anderem ein Diktatschlüssel sein und eine Liste nicht.
Als nächstes wird die Elementzuweisungsfunktion sq_ass_item hervorgehoben. Es ist in der Liste, im Tupel ist es Null, das heißt, Sie können dem Tupel natürlich nichts zuweisen.

Eine Sache noch. Python kopiert nichts, bis wir danach fragen. Dies muss auch beachtet werden. Wenn Sie etwas kopieren möchten, verwenden Sie beispielsweise das Kopiermodul mit der Funktion copy.deepcopy. Was ist der Unterschied? copy kopiert das Objekt, wenn es sich um ein Containerobjekt handelt, z. B. eine Geschwisterliste. Alle Referenzen, die sich in diesem Objekt befanden, werden in das neue Objekt eingefügt. Deepcopy kopiert rekursiv alle Objekte in diesem Container und darüber hinaus.
Wenn Sie eine Liste schnell kopieren möchten, können Sie auch ein einzelnes Doppelpunkt-Slice verwenden. Sie erhalten eine Kopie, eine solche Verknüpfung ist einfach.
(...) Lassen Sie uns als nächstes über die Speicherverwaltung sprechen.
Speicherverwaltung

Nehmen wir unser sys-Modul. Es hat eine Funktion, mit der Sie sehen können, ob Speicher verwendet wird. Wenn Sie den Interpreter starten und die Statistiken der Speicheränderungen anzeigen, werden Sie feststellen, dass Sie viele Objekte erstellt haben, auch kleine. Und dies sind nur die Objekte, die derzeit erstellt werden.
Tatsächlich erstellt Python zur Laufzeit viele kleine Objekte. Und wenn wir die Standard-Malloc-Funktion verwenden würden, um sie zuzuweisen, würden wir uns sehr schnell in der Tatsache wiederfinden, dass unser Speicher fragmentiert ist und dementsprechend die Speicherzuweisung langsam ist.

Dies erfordert die Verwendung eines eigenen Speichermanagers. Kurz gesagt, wie funktioniert es? Python weist sich Speicherblöcke zu, die als Arena bezeichnet werden und jeweils 256 Kilobyte umfassen. Im Inneren schneidet er sich in Pools von vier Kilobyte, das ist die Größe einer Speicherseite. In den Pools befinden sich Blöcke unterschiedlicher Größe von 16 bis 512 Byte.
Wenn wir versuchen, einem Objekt weniger als 512 Bytes zuzuweisen, wählt Python auf seine Weise einen Block aus, der für dieses Objekt geeignet ist, und platziert das Objekt in diesem Block.
Wenn das Objekt freigegeben oder gelöscht wird, wird dieser Block als frei markiert. Es wird jedoch nicht an das Betriebssystem übergeben, und an der nächsten Stelle können wir dieses Objekt in denselben Block schreiben. Dies beschleunigt die Speicherzuweisung erheblich.

Speicher freigeben. Früher haben wir die PyObject-Struktur gesehen. Sie hat diese Referenznummer. Es funktioniert sehr einfach. Wenn Sie auf dieses Objekt verweisen, erhöht Python die Referenzanzahl. Sobald Sie ein Objekt haben, verschwindet die Referenz, und Sie geben die Referenzanzahl frei.
Was ist gelb hervorgehoben. Wenn refcnt nicht Null ist, dann machen wir dort etwas. Wenn refcnt Null ist, wird die Zuordnung des Objekts sofort aufgehoben. Wir warten nicht auf irgendeinen Müllsammler, nichts, aber in diesem Moment löschen wir die Erinnerung.
Wenn Sie auf die del-Methode stoßen, wird einfach die Bindung der Variablen an das Objekt entfernt. Die Methode __del__, die Sie in der Klasse definieren können, wird aufgerufen, wenn das Objekt tatsächlich aus dem Speicher entfernt wird. Sie rufen del für das Objekt auf, aber wenn es noch Referenzen hat, wird das Objekt nirgendwo gelöscht. Und sein Finalizer, __del__, wird nicht aufgerufen. Obwohl sie sehr ähnlich genannt werden.
Eine kurze Demo, wie Sie die Anzahl der Links sehen können. Es gibt unser Lieblings-sys-Modul, das eine getrefcount-Funktion hat. Sie können die Anzahl der Links zu einem Objekt sehen.

Ich werde dir mehr erzählen. Ein Objekt wird erstellt. Die Anzahl der Links wird daraus entnommen. Interessantes Detail: Variable A zeigt auf TaxiOrder. Wenn Sie die Anzahl der Links nehmen, erhalten Sie "2" gedruckt. Es scheint warum? Wir haben eine Objektreferenz. Wenn Sie jedoch getrefcount aufrufen, wird dieses Objekt um das Argument in der Funktion gewickelt. Daher haben Sie bereits zwei Verweise auf dieses Objekt: Der erste ist die Variable, der zweite ist das Funktionsargument. Daher wird "2" gedruckt.
Der Rest ist trivial. Wir weisen dem Objekt eine weitere Variable zu, wir erhalten 3. Dann entfernen wir diese Bindung, wir erhalten 2. Dann entfernen wir alle Verweise auf dieses Objekt und der Finalizer wird aufgerufen, der unsere Zeile druckt.

(...) Es gibt eine weitere interessante Funktion von CPython, auf der nicht aufgebaut werden kann, und es scheint, dass in den Dokumenten nirgendwo darüber gesprochen wird. Ganzzahlen werden häufig verwendet. Es wäre verschwenderisch, sie jedes Mal neu zu erstellen. Daher haben die Python-Entwickler als am häufigsten verwendete Zahlen den Bereich von –5 bis 255 gewählt, sie sind Singleton. Das heißt, sie werden einmal erstellt, liegen irgendwo im Interpreter, und wenn Sie versuchen, sie abzurufen, erhalten Sie einen Verweis auf dasselbe Objekt. Wir haben A und B genommen, sie gedruckt und ihre Adressen verglichen. Wurde wahr. Und wir haben zum Beispiel 105 Verweise auf dieses Objekt, einfach weil es jetzt so viele gibt.
Wenn wir eine größere Zahl nehmen - zum Beispiel 1408 - sind diese Objekte für uns nicht gleich und es gibt jeweils zwei Verweise darauf. In der Tat eine.
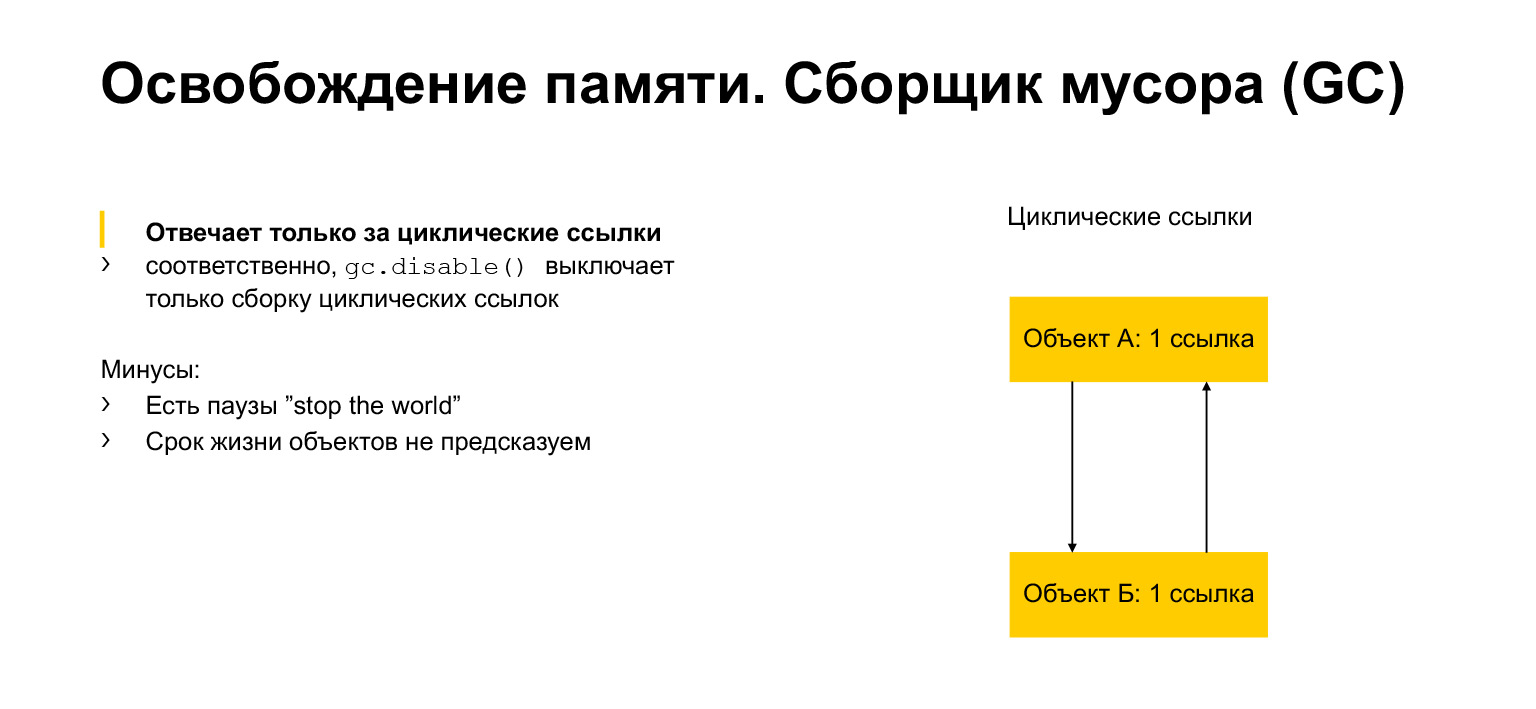
Wir haben ein wenig über Speicherzuweisung und Freigabe gesprochen. Sprechen wir jetzt über den Müllsammler. Wofür ist das? Es scheint, dass wir eine Reihe von Links haben. Sobald niemand auf das Objekt verwiesen hat, können wir es löschen. Aber wir können zirkuläre Links haben. Ein Objekt kann sich beispielsweise auf sich selbst beziehen. Oder wie im Beispiel können zwei Objekte vorhanden sein, die sich jeweils auf einen Nachbarn beziehen. Dies wird als Zyklus bezeichnet. Und dann können diese Objekte niemals einen Verweis auf ein anderes Objekt geben. Gleichzeitig sind sie beispielsweise in einem anderen Teil des Programms nicht erreichbar. Wir müssen sie löschen, weil sie nicht zugänglich und nutzlos sind, aber Links haben. Genau dafür ist das Garbage Collector-Modul gedacht. Es erkennt Zyklen und entfernt diese Objekte.
Wie arbeitet er? Zuerst werde ich kurz über Generationen und dann über den Algorithmus sprechen.
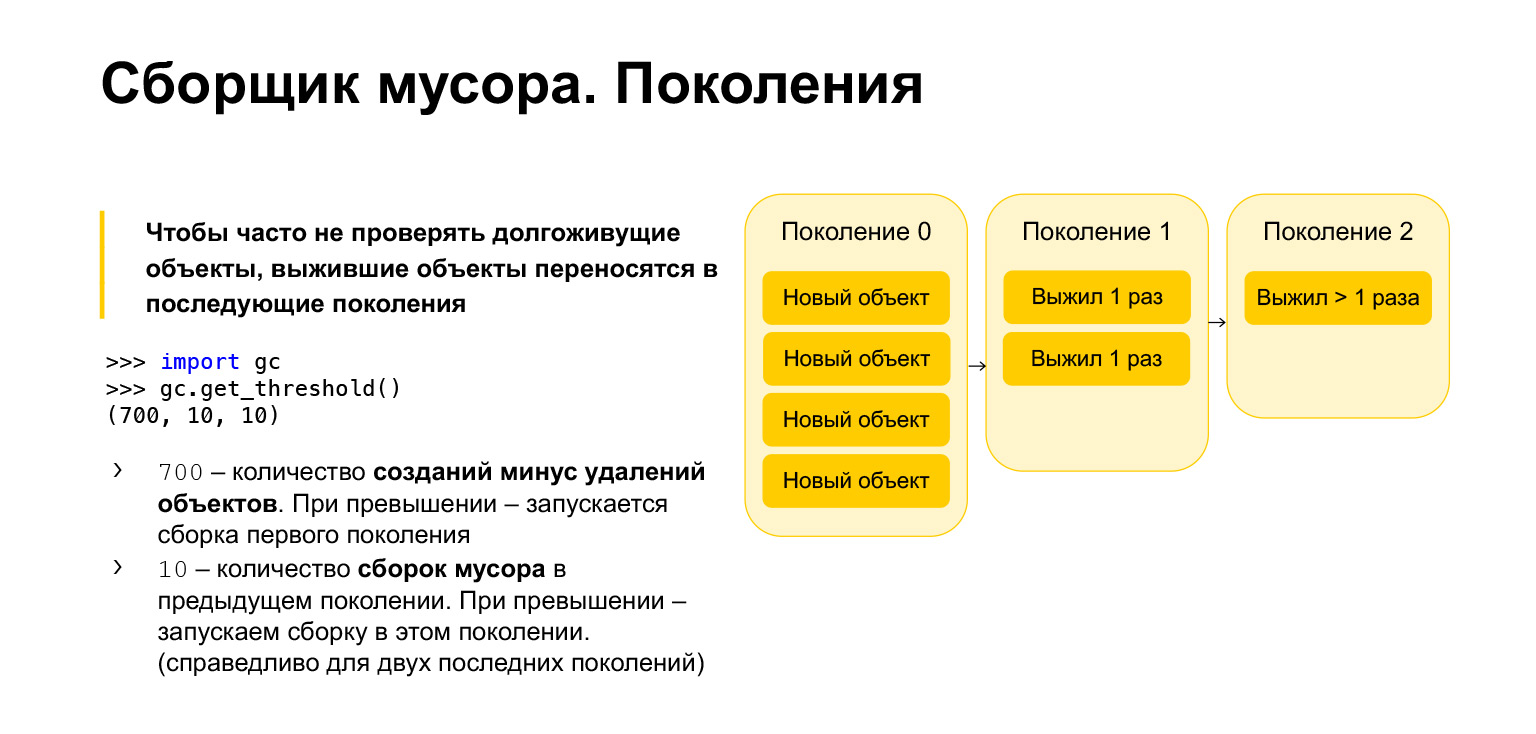
Um die Geschwindigkeit des Garbage Collectors in Python zu optimieren, ist es generationsübergreifend, dh es funktioniert mit Generationen. Es gibt drei Generationen. Wofür werden sie benötigt? Es ist klar, dass Objekte, die erst vor kurzem erstellt wurden, eher unnötig sind als langlebige Objekte. Angenommen, Sie erstellen im Laufe der Funktionen etwas. Höchstwahrscheinlich wird es beim Beenden der Funktion nicht benötigt. Das Gleiche gilt für Schleifen mit temporären Variablen. Alle diese Gegenstände müssen häufiger gereinigt werden als die, die es schon lange gibt.
Daher werden alle neuen Objekte in die Nullgenerierung eingefügt. Diese Generation wird regelmäßig gereinigt. Python hat drei Parameter. Jede Generation hat ihren eigenen Parameter. Sie können sie abrufen, den Garbage Collector importieren, die Funktion get_threshold aufrufen und diese Schwellenwerte abrufen.
Standardmäßig gibt es 700, 10, 10. Was ist 700? Dies ist die Anzahl der Objekterstellung abzüglich der Anzahl der Löschungen. Sobald 700 überschritten werden, wird eine Speicherbereinigung der neuen Generation gestartet. Und 10, 10 ist die Anzahl der Speicherbereinigungen in der vorherigen Generation. Danach müssen wir die Speicherbereinigung in der aktuellen Generation starten.
Das heißt, wenn wir die Nullgeneration zehnmal löschen, beginnen wir mit dem Build in der ersten Generation. Nachdem wir die erste Generation 10 Mal gereinigt haben, beginnen wir mit dem Build in der zweiten Generation. Dementsprechend bewegen sich Objekte von Generation zu Generation. Wenn sie überleben, wechseln sie in die erste Generation. Wenn sie eine Müllabfuhr in der ersten Generation überlebt haben, werden sie in die zweite verschoben. Ab der zweiten Generation bewegen sie sich nirgendwo mehr, sie bleiben für immer dort.
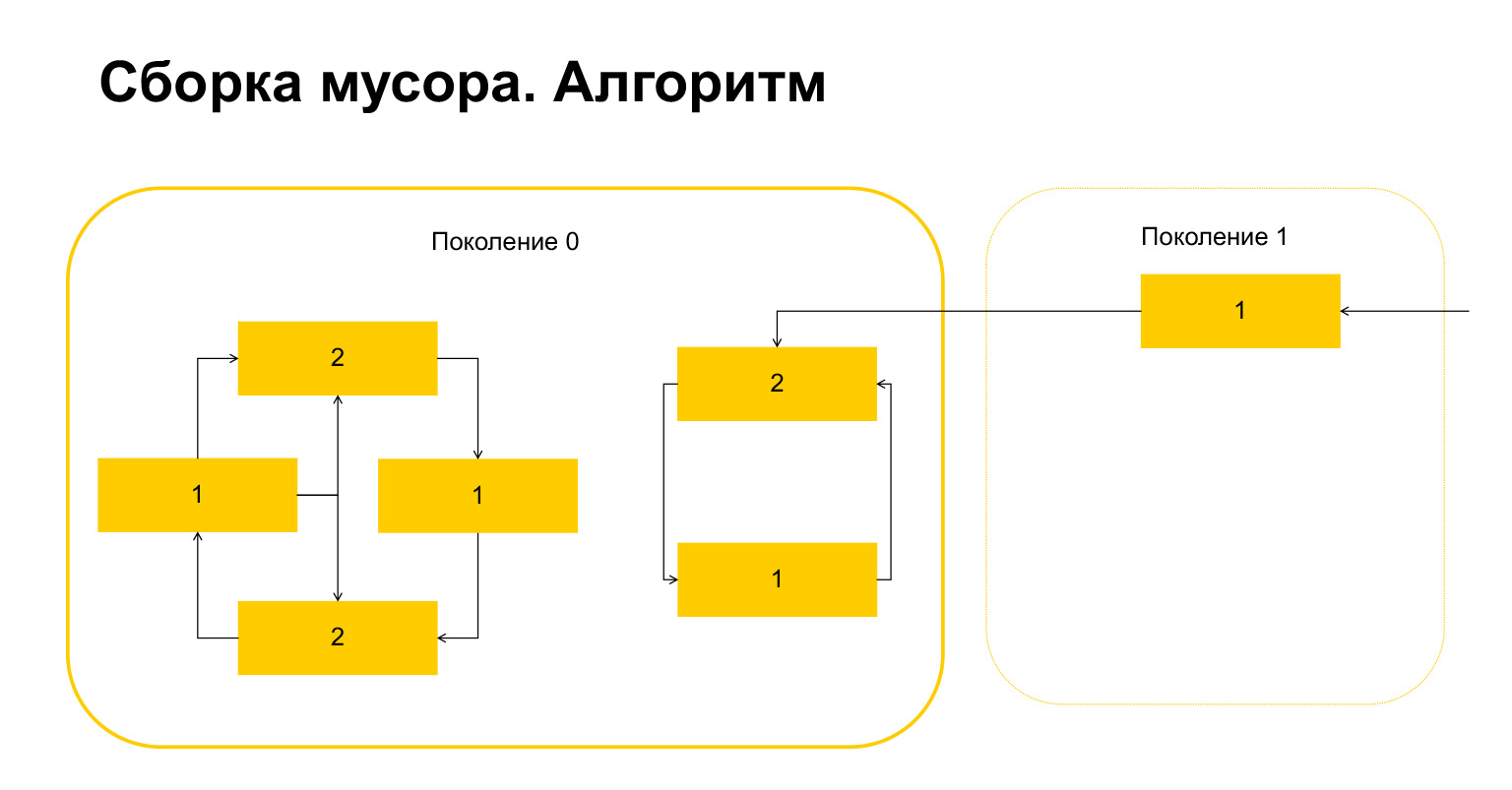
Wie funktioniert die Speicherbereinigung in Python? Nehmen wir an, wir starten die Speicherbereinigung in Generation 0. Wir haben einige Objekte, sie haben Zyklen. Links befindet sich eine Gruppe von Objekten, die sich aufeinander beziehen, und die Gruppe rechts bezieht sich auch aufeinander. Ein wichtiges Detail - sie werden auch ab Generation 1 referenziert. Wie erkennt Python Schleifen? Zunächst wird für jedes Objekt eine temporäre Variable erstellt und die Anzahl der Verweise auf dieses Objekt in das Objekt geschrieben. Dies spiegelt sich auf der Folie wider. Wir haben oben zwei Links zum Objekt. Aber ein Objekt aus Generation 1 wird von außen von jemandem referenziert. Python erinnert sich daran. Dann (wichtig!) Durchläuft es jedes Objekt innerhalb der Generation und löscht, dekrementiert den Zähler um die Anzahl der Referenzen innerhalb dieser Generation.
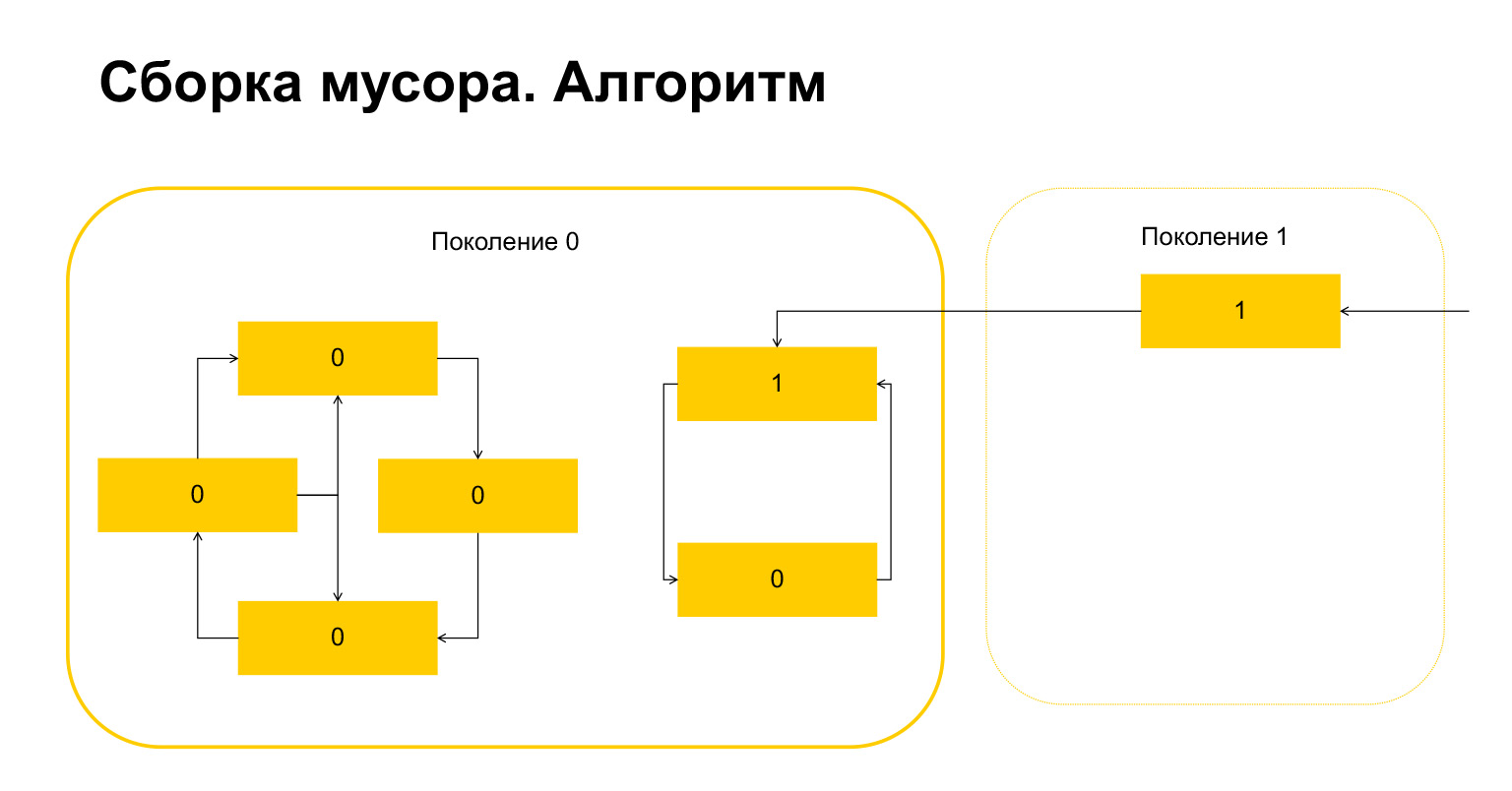
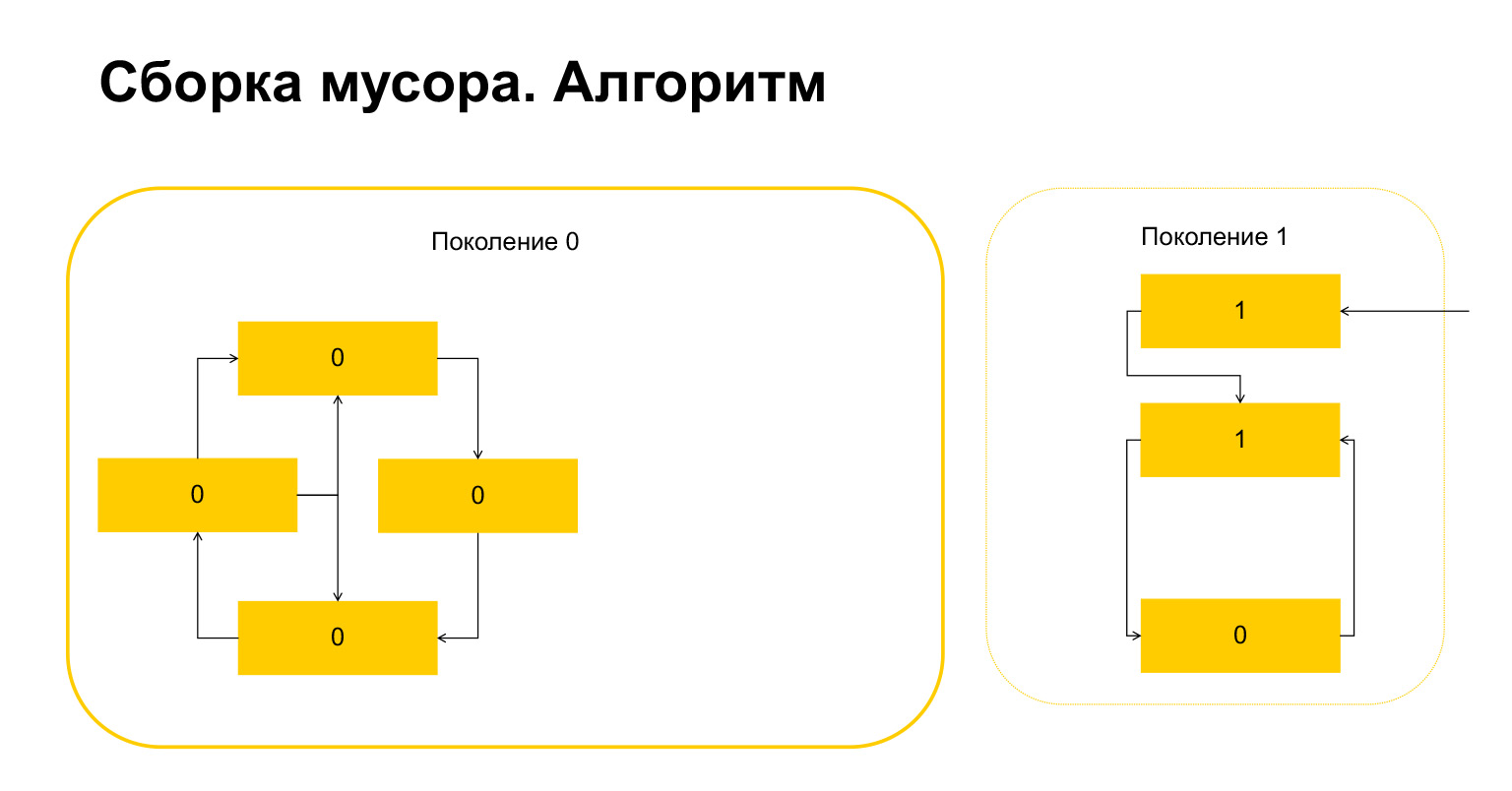
Folgendes ist passiert. Für Objekte, die nur innerhalb einer Generation aufeinander verweisen, ist diese Variable konstruktionsbedingt automatisch gleich Null geworden. Nur Objekte, auf die von außen verwiesen wird, haben eine Einheit.
Was macht Python als nächstes? Er, da es hier einen gibt, versteht, dass diese Objekte von außen referenziert werden. Und wir können weder dieses noch dieses Objekt löschen, da wir sonst in eine ungültige Situation geraten. Daher überträgt Python diese Objekte an Generation 1, und alles, was in Generation 0 übrig bleibt, wird gelöscht und bereinigt. Alles über Müllsammler.
(...) Mach weiter. Ich werde Ihnen ganz kurz über Generatoren erzählen.
Generatoren

Leider wird es hier keine Einführung in Generatoren geben, aber versuchen wir Ihnen zu sagen, was ein Generator ist. Dies ist eine relativ gesehen eine Art Funktion, die sich anhand des Wortes Ausbeute an den Kontext ihrer Ausführung erinnert. Zu diesem Zeitpunkt wird ein Wert zurückgegeben und der Kontext gespeichert. Sie können dann erneut darauf verweisen und den Wert erhalten, den es ausgibt.
Was kann man mit Generatoren machen? Sie können einen Generator liefern, der Ihnen Werte zurückgibt. Denken Sie an den Kontext. Sie können den Generator zurückgeben. In diesem Fall wird die StopIteration-Ausführung ausgelöst, der Wert, in dem sich der Wert befindet, in diesem Fall Y.
Weniger bekannte Tatsache: Sie können einige Werte an den Generator senden. Das heißt, Sie rufen die send-Methode für den Generator auf, und Z - siehe Beispiel - ist der Wert des Ertragsausdrucks, den der Generator aufruft. Wenn Sie den Generator steuern möchten, können Sie dort Werte übergeben.
Sie können dort auch Ausnahmen auslösen. Das Gleiche: Nimm ein Generatorobjekt, wirf es. Sie werfen dort einen Fehler. Anstelle der letzten Ausbeute wird ein Fehler angezeigt. Und schließen - Sie können den Generator schließen. Dann wird die GeneratorExit-Ausführung ausgelöst, und es wird erwartet, dass der Generator nichts anderes liefert.

Hier wollte ich nur darüber sprechen, wie es in CPython funktioniert. Sie haben tatsächlich einen Ausführungsrahmen in Ihrem Generator. Und wie wir uns erinnern, enthält FrameObject den gesamten Kontext. Daraus scheint klar zu sein, wie der Kontext erhalten bleibt. Das heißt, Sie haben nur einen Rahmen im Generator.

Woher weiß Python, wenn Sie eine Generatorfunktion ausführen, dass Sie sie nicht ausführen müssen, sondern einen Generator erstellen müssen? Das CodeObject, das wir uns angesehen haben, hat Flags. Und wenn Sie eine Funktion aufrufen, überprüft Python ihre Flags. Wenn das CO_GENERATOR-Flag vorhanden ist, versteht es, dass die Funktion nicht ausgeführt werden muss, sondern nur einen Generator erstellen muss. Und er schafft es. PyGen_NewWithQualName-Funktion.

Wie läuft die Hinrichtung? Von GENERATOR_FUNCTION ruft der Generator zuerst GENERATOR_Object auf. Dann können Sie GENERATOR_Object mit next aufrufen, um den nächsten Wert zu erhalten. Wie kommt es zum nächsten Anruf? Sein Frame wird vom Generator übernommen, in der Variablen F gespeichert und an die Hauptschleife des Interpreters EvalFrameEx gesendet. Sie werden wie bei einer normalen Funktion ausgeführt. Der YIELD_VALUE-Mapcode wird verwendet, um die Ausführung des Generators zurückzugeben und anzuhalten. Es merkt sich den gesamten Kontext im Frame und stoppt die Ausführung. Dies war das vorletzte Thema.
(...) Eine kurze Zusammenfassung der Ausnahmen und ihrer Verwendung in Python.
Ausnahmen

Ausnahmen sind eine Möglichkeit, mit Fehlersituationen umzugehen. Wir haben einen Versuchsblock. Wir können versuchen, Dinge zu versuchen, die Ausnahmen auslösen können. Nehmen wir an, wir können mit dem Wort Raise einen Fehler auslösen. Mit Hilfe von Except können wir bestimmte Arten von Ausnahmen abfangen, in diesem Fall SomeError. Mit Ausnahme erfassen wir alle Ausnahmen ohne Ausdruck. Der else-Block wird seltener verwendet, ist jedoch vorhanden und wird nur ausgeführt, wenn keine Ausnahmen ausgelöst wurden. Der finally-Block wird trotzdem ausgeführt.
Wie funktionieren Ausnahmen in CPython? Zusätzlich zum Ausführungsstapel hat jeder Rahmen auch einen Blockstapel. Es ist besser, ein Beispiel zu verwenden.


Ein Blockstapel ist ein Stapel, auf den Blöcke geschrieben werden. Jeder Block hat einen Typ, Handler, einen Handler. Handler ist die Bytecode-Adresse, zu der gesprungen werden muss, um diesen Block zu verarbeiten. Wie funktioniert es? Nehmen wir an, wir haben Code. Wir haben einen try-Block erstellt, wir haben einen Ausnahmeblock, in dem wir RuntimeError-Ausnahmen abfangen, und einen finally-Block, der auf jeden Fall sein sollte.
Dies alles degeneriert in diesen Bytecode. Ganz am Anfang des Bytecodes im try-Block sehen wir zwei Opcode SETUP_FINALLY mit den Argumenten 40 und 12. Dies sind die Adressen der Handler. Wenn SETUP_FINALLY ausgeführt wird, wird ein Block auf den Blockstapel gelegt, der besagt: Um mich zu verarbeiten, gehen Sie in einem Fall zur 40. Adresse, in dem anderen - zur 12 ..
12 unten im Stapel ist außer der Zeile, die den else RuntimeError enthält. Dies bedeutet, dass wir bei einer Ausnahme den Blockstapel auf der Suche nach einem Block mit dem Typ SETUP_FINALLY untersuchen. Suchen Sie den Block, in dem sich ein Übergang zur Adresse 12 befindet, und gehen Sie dorthin. Und dort haben wir einen Vergleich der Ausnahme mit dem Typ: Wir prüfen, ob der Typ der Ausnahme RuntimeError ist oder nicht. Wenn es gleich ist, führen wir es aus, wenn nicht, springen wir woanders hin.
ENDLICH ist der nächste Block im Blockstapel. Es wird für uns ausgeführt, wenn wir eine andere Ausnahme haben. Dann wird die Suche auf diesem Blockstapel fortgesetzt und wir kommen zum nächsten SETUP_FINALLY-Block. Es wird einen Handler geben, der uns zum Beispiel Adresse 40 mitteilt. Wir springen zu Adresse 40 - Sie können dem Code entnehmen, dass dies ein endgültiger Block ist.

Es funktioniert sehr einfach in CPython. Wir haben alle Funktionen, die Ausnahmen auslösen können, die einen Wertcode zurückgeben. Wenn alles in Ordnung ist, wird 0 zurückgegeben. Wenn es sich um einen Fehler handelt, wird je nach Funktionstyp -1 oder NULL zurückgegeben.
Nehmen Sie eine solche Seitenleiste bei C. Wir sehen, wie die Teilung erfolgt. Und es gibt eine Überprüfung, ob wir uns an die Ausnahme erinnern und NULL zurückgeben, wenn B gleich Null ist und wir nicht durch Null teilen wollen. Es bedeutet, dass ein Fehler aufgetreten ist. Daher sollten alle anderen Funktionen, die höher im Aufrufstapel sind, auch NULL ausgeben. Wir werden dies in der Hauptschleife des Interpreters sehen und hier springen.

Dies ist das Abwickeln des Stapels. Alles ist wie gesagt: Wir gehen den gesamten Blockstapel durch und überprüfen, ob sein Typ SETUP_FINALLY ist. Wenn ja, springen Sie über Handler, sehr einfach. Das ist in der Tat alles.
Links
Allgemeiner Interpreter:
docs.python.org/3/reference/executionmodel.html
github.com/python/cpython
leanpub.com/insidethepythonvirtualmachine/read
Speicherverwaltung:
arctrix.com/nas/python/gc
Rushter.com/blog/python -Speicher-managment
instagram-engineering.com/dismissing-python-garbage-collection-at-instagram-4dca40b29172
stackify.com/python-garbage-collection
Ausnahmen:
bugs.python.org/issue17611