In meinem Vortrag teilte ich meine Erfahrungen mit Alembic, einem bewährten Tool zur Verwaltung von Migrationen. Warum Alembic wählen, wie man es verwendet, um Migrationen vorzubereiten, wie man sie ausführt (automatisch oder manuell), wie man die Probleme irreversibler Änderungen löst, warum Testmigrationen, welche Probleme die Tests aufdecken können und wie man sie implementiert - ich habe versucht, all diese Fragen zu beantworten. Gleichzeitig habe ich mehrere Life-Hacks geteilt, die die Arbeit mit Migrationen in Alembic einfach und angenehm machen.
Seit dem Tag des Berichts wurde der Code auf GitHub leicht aktualisiert, es gibt weitere Beispiele. Wenn Sie den Code genau so sehen möchten, wie er auf den Folien angezeigt wird, finden Sie hier einen Link zu einem Commit aus dieser Zeit.
- Hallo! Mein Name ist Alexander, ich arbeite in Edadil. Heute möchte ich Ihnen sagen, wie wir mit Migrationen leben und wie Sie mit ihnen leben könnten. Vielleicht hilft dir das, leichter zu leben.
Was sind Migrationen?
Bevor wir anfangen, sollten wir darüber sprechen, was Migrationen im Allgemeinen sind. Zum Beispiel haben Sie eine Anwendung und Sie erstellen ein paar Tablets, damit es funktioniert, geht zu ihnen. Dann rollen Sie eine neue Version aus, in der sich etwas geändert hat - die erste Platte hat sich geändert, die zweite nicht und die dritte war vorher nicht da, aber es erschien.

Dann erscheint eine neue Version der Anwendung, in der eine Platte gelöscht wird, dem Rest passiert nichts. Was ist das? Wir können sagen, dass dies der Zustand ist, der durch Migration beschrieben werden kann. Wenn wir von einem Zustand in einen anderen wechseln, ist dies ein Upgrade, wenn wir ein Downgrade durchführen möchten.
Was sind Migrationen?

Einerseits ist dies Code, der den Status der Datenbank ändert. Auf der anderen Seite ist dies der Prozess, den wir beginnen.

Welche Eigenschaften sollten Migrationen haben? Es ist wichtig, dass die Zustände, zwischen denen wir in Versionen der Anwendung wechseln, atomar sind. Wenn wir zum Beispiel zwei Tabellen haben möchten, aber nur eine angezeigt wird, kann dies zu nicht sehr guten Konsequenzen in der Produktion führen.
Es ist wichtig, dass wir unsere Änderungen rückgängig machen können, denn wenn Sie eine neue Version herausbringen, wird sie nicht gestartet und Sie können nicht zurückrollen, normalerweise endet alles schlecht.
Es ist auch wichtig, dass die Versionen bestellt werden, damit Sie die Art und Weise, wie sie rollen, verketten können.
Werkzeuge
Wie können wir diese Migrationen implementieren?
Die erste Idee, die mir in den Sinn kommt: Okay, Migration ist SQL. Warum nicht SQL-Dateien mit Abfragen erstellen? Es gibt mehrere weitere Module, die unser Leben erleichtern können.

Wenn wir uns ansehen, was intern vor sich geht, gibt es tatsächlich ein paar Anfragen. Es könnte CREATE TABLE sein, ALTER, alles andere. In der Datei downgrade_v1.sql brechen wir alles ab.

Warum solltest du das nicht tun? In erster Linie, weil Sie es mit Ihren Händen tun müssen. Vergessen Sie nicht, begin zu schreiben und dann Ihre Änderungen zu übernehmen. Wenn Sie Code schreiben, müssen Sie sich alle Abhängigkeiten merken und wissen, was in welcher Reihenfolge zu tun ist. Dies ist eine ziemlich routinemäßige, schwierige und zeitaufwändige Aufgabe.
Sie haben keinen Schutz vor versehentlichem Starten der falschen Datei. Sie müssen alle Dateien von Hand ausführen. Wenn Sie 15 Migrationen haben, ist es nicht einfach. Sie müssen 15 psql aufrufen, es wird nicht sehr cool sein.
Am wichtigsten ist, dass Sie nie wissen, in welchem Status sich Ihre Datenbank befindet. Sie müssen irgendwo aufschreiben - auf ein Blatt Papier, woanders - welche Dateien Sie heruntergeladen haben und welche nicht. Es klingt auch nicht sehr gut.

Es gibt ein Yoyo-Migrationsmodul . Es unterstützt die gängigsten Datenbanken und verwendet Rohabfragen.

Wenn wir uns ansehen, was er uns anbietet, sieht es so aus. Wir sehen das gleiche SQL. Auf der rechten Seite befindet sich bereits Python-Code, der die Yoyo-Bibliothek importiert.

Somit können wir Migrationen bereits genau automatisch starten. Mit anderen Worten, es gibt einen Befehl, der eine neue Migration erstellt und der Kette hinzufügt, in die wir unseren SQL-Code schreiben können. Mit Befehlen können Sie eine oder mehrere Migrationen anwenden, Sie können ein Rollback durchführen, dies ist bereits ein Fortschritt.

Das Plus ist, dass Sie nicht mehr auf ein Blatt Papier schreiben müssen, welche Anforderungen Sie an die Datenbank gestellt haben, welche Dateien Sie gestartet haben und wo Sie ein Rollback durchführen müssen, wenn etwas passiert. Sie haben eine Art narrensicheren Schutz: Sie können keine Migration mehr ausführen, die für etwas anderes ausgelegt ist, für den Übergang zwischen zwei anderen Zuständen der Datenbank. Ein sehr großes Plus: Dieses Ding führt jede Migration in einer separaten Transaktion durch. Dies gibt auch solche Garantien.

Die Nachteile liegen auf der Hand. Sie haben noch unformatiertes SQL. Wenn Sie beispielsweise in Python eine große Datenproduktion mit weitläufiger Logik haben, können Sie diese nicht verwenden, da Sie nur über SQL verfügen.
Außerdem finden Sie viele Routinearbeiten, die nicht automatisiert werden können. Es ist notwendig, alle Beziehungen zwischen den Tabellen im Auge zu behalten - was irgendwo geschrieben werden kann und was noch nicht möglich ist. Im Allgemeinen gibt es ganz offensichtliche Nachteile.
Ein weiteres Modul, das es wert ist, beachtet zu werden und für das heute der gesamte Vortrag gehalten wird, ist Alembic .

Es hat die gleichen Dinge wie Jojo und vieles mehr. Es überwacht nicht nur Ihre Migrationen und weiß, wie sie erstellt werden, sondern ermöglicht Ihnen auch, sehr komplexe Geschäftslogik zu schreiben, Ihre gesamte Datenproduktion zu verbinden und alle Funktionen in Python zu nutzen. Ziehen Sie die Daten und verarbeiten Sie sie intern, wenn Sie möchten. Wenn Sie nicht wollen, müssen Sie nicht.
In den meisten Fällen kann er automatisch Code für Sie schreiben. Natürlich nicht immer, aber es klingt nach einem guten Plus, nachdem Sie viel mit Ihren Händen schreiben mussten.
Er hat viele coole Sachen. Beispielsweise unterstützt SQLite ALTER TABLE nicht vollständig. Und Alembic verfügt über Funktionen , mit denen Sie dies in wenigen Zeilen leicht umgehen können, und Sie werden nicht einmal darüber nachdenken.
In den vorherigen Folien gab es ein Django-Migrationsmodul. Dies ist auch ein sehr gutes Modul für Migrationen. Sein Prinzip ist in der Funktionalität mit dem von Alembic vergleichbar. Der einzige Unterschied besteht darin, dass es an das Framework gebunden ist, Alembic jedoch nicht.
SQLAlchemy
Da Alembic auf SQLAlchemy basiert, empfehle ich, ein wenig durch SQLAlchemy zu laufen, um sich daran zu erinnern oder zu lernen, was es ist.

Bisher haben wir uns rohe Abfragen angesehen. Rohe Abfragen sind nicht schlecht. Das kann sehr gut sein. Wenn Sie eine hoch geladene Anwendung haben, ist dies möglicherweise genau das, was Sie benötigen. Sie müssen keine Zeit damit verschwenden, einige Objekte in Abfragen umzuwandeln.
Es sind keine zusätzlichen Bibliotheken erforderlich. Sie nehmen einfach den Fahrer und das wars, es funktioniert. Wenn Sie beispielsweise komplexe Abfragen schreiben, ist dies nicht so einfach: Nun, Sie können eine Konstante nehmen, sie aufrufen und einen großen mehrzeiligen Code schreiben. Wenn Sie jedoch 10 bis 20 solcher Anfragen haben, ist es bereits sehr schwer zu lesen. Dann können Sie sie in keiner Weise wiederverwenden. Sie haben viel Text und natürlich Funktionen zum Arbeiten mit Strings, F-Strings und all dem, aber das klingt schon nicht sehr gut. Sie sind schwer zu lesen.
Wenn Sie beispielsweise eine Klasse haben, in der Sie auch Abfragen und komplexe Strukturen haben möchten, ist das Einrücken ein wilder Schmerz. Wenn Sie eine Rohmigration durchführen möchten, können Sie nur mit grep herausfinden, wo Sie etwas verwenden. Und Sie haben auch kein dynamisches Tool für dynamische Abfragen.
Zum Beispiel eine super einfache Aufgabe. Sie haben eine Entität, sie hat 15 Felder in einer Platte. Sie möchten eine PATCH-Anfrage stellen. Es scheint super einfach zu sein. Versuchen Sie, dies auf Rohabfragen zu schreiben. Es wird nicht sehr hübsch aussehen und es ist unwahrscheinlich, dass die Pull-Anfrage genehmigt wird.

Es gibt eine Alternative dazu - den Abfrage-Generator. Es hat sicherlich Nachteile, da Sie Ihre Abfragen als Objekte in Python darstellen können.
Sie müssen für die Bequemlichkeit sowohl in der Zeit zum Generieren von Anforderungen als auch im Speicher bezahlen. Aber es gibt Pluspunkte. Wenn Sie große, komplexe Anwendungen schreiben, benötigen Sie Abstraktionen. Der Abfrage-Generator kann Ihnen diese Abstraktionen geben. Diese Abfragen können zerlegt werden. Wir werden sehen, wie dies etwas später gemacht wird. Sie können wiederverwendet, erweitert oder in Funktionen eingeschlossen werden, die bereits als Anzeigenamen für die Geschäftslogik bezeichnet werden.
Es ist sehr einfach, dynamische Abfragen zu erstellen. Wenn Sie etwas ändern müssen, schreiben Sie eine Migration. Eine statistische Analyse des Codes ist ausreichend. Es ist sehr bequem.
Warum ist SQLAlchemy überhaupt? Warum lohnt es sich, einen Zwischenstopp einzulegen?

Dies ist nicht nur eine Frage der Migration, sondern allgemein. Denn wenn wir Alembic haben, ist es sinnvoll, den gesamten Stack auf einmal zu verwenden, da SQLAlchemy nicht nur mit synchronen Treibern funktioniert. Das heißt, Django ist ein sehr cooles Werkzeug, aber Alchemie kann zum Beispiel mit Asyncpg und Aiopg verwendet werden . Mit Asyncpg können Sie, wie Selivanov sagte, eine Million Zeilen pro Sekunde lesen - aus der Datenbank lesen und an Python übertragen. Natürlich wird es mit SQLAlchemy etwas weniger geben, es wird etwas Overhead geben. Aber wie auch immer.
SQLAlchemy hat eine unglaubliche Anzahl von Treibern, mit denen es arbeiten kann. Es gibt Oracle und PostgreSQL und einfach alles für jeden Geschmack und jede Farbe. Außerdem sind sie bereits sofort einsatzbereit, und wenn Sie etwas Separates benötigen, dann gibt es, wie ich kürzlich nachgesehen habe, sogar Elasticsearch. Stimmt, nur zum Lesen, aber - verstehst du? - Elasticsearch in SQLAlchemy.
Es gibt eine sehr gute Dokumentation, eine große Community. Es gibt viele Bibliotheken. Und was wichtig ist, er diktiert Ihnen schließlich keine Frameworks und Bibliotheken. Wenn Sie eine enge Aufgabe erledigen, die gut erledigt werden muss, kann dies ein Werkzeug sein.
Woraus besteht es also?
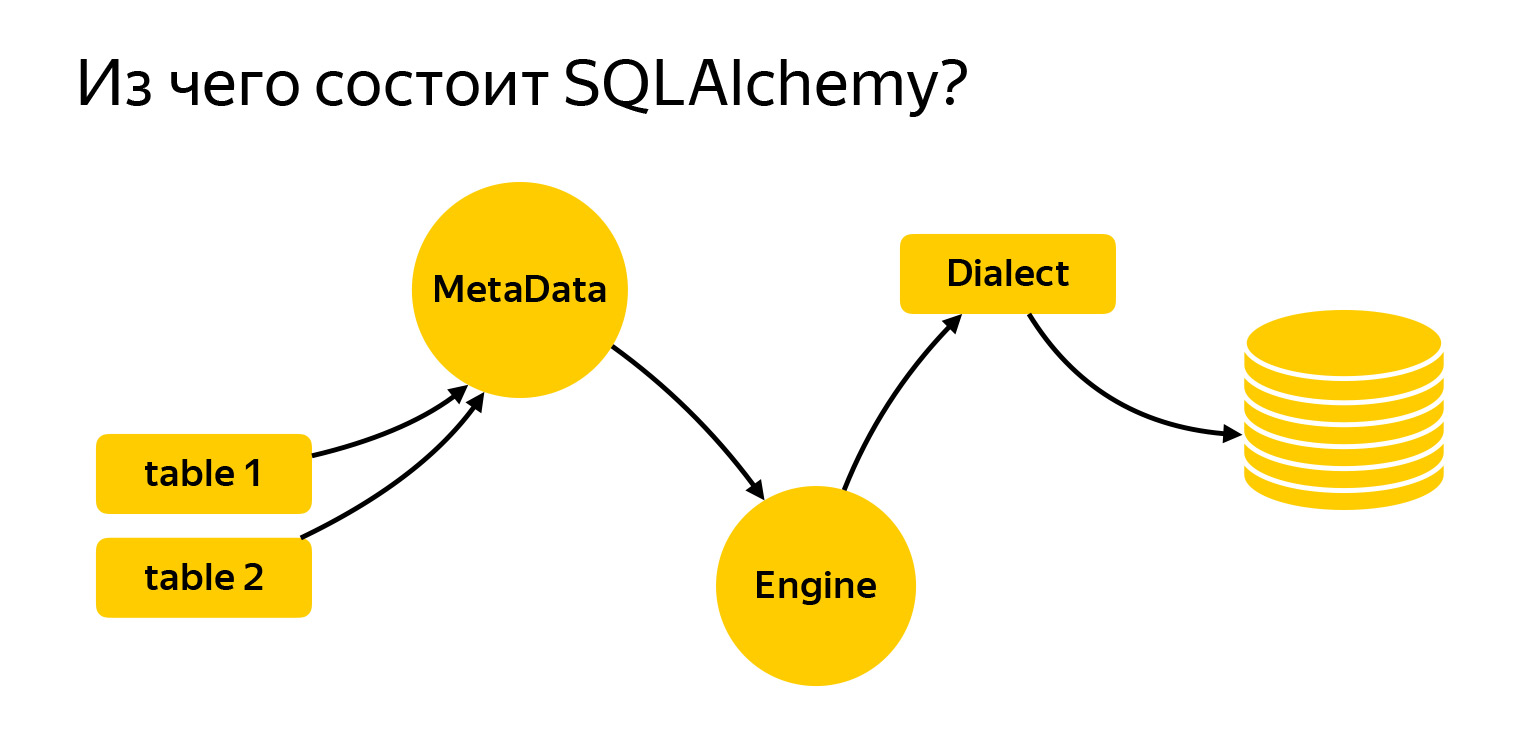
Ich habe die wichtigsten Einheiten hierher gebracht, mit denen wir heute arbeiten werden. Dies sind Tabellen. Um Anfragen zu schreiben, muss Alchemy gesagt werden, was es ist und womit wir arbeiten. Als nächstes folgt die MetaData-Registrierung. Engine ist eine Sache, die eine Verbindung zur Datenbank herstellt und über Dialect mit ihr kommuniziert.
Schauen wir uns genauer an, was es ist.

MetaData ist eine Art Objekt, ein Container, in den Sie Ihre Tabellen, Indizes und im Allgemeinen alle vorhandenen Entitäten einfügen. Dies ist ein Objekt, das einerseits widerspiegelt, wie Sie die Datenbank basierend auf Ihrem geschriebenen Code anzeigen möchten. Auf der anderen Seite kann MetaData in die Datenbank gehen, eine Momentaufnahme der tatsächlich vorhandenen Daten abrufen und dieses Objektmodell selbst erstellen.
Das MetaData-Objekt verfügt außerdem über eine sehr interessante Funktion. Hier können Sie eine Standardbenennungsvorlage für Indizes und Einschränkungen definieren. Dies ist sehr wichtig, wenn Sie Migrationen schreiben, da jede Datenbank - sei es PostgreSQL, MySQL, MariaDB - ihre eigene Vision hat, wie Indizes aufgerufen werden sollten.
Einige Entwickler haben auch ihre eigene Vision. Und mit SQLAlchemy können Sie ein für alle Mal einen Standard festlegen, wie es funktioniert. Ich musste ein Projekt entwickeln, das sowohl mit SQLite als auch mit PostgreSQL funktionieren musste. Es war sehr praktisch.

Es sieht folgendermaßen aus: Sie importieren ein MetaData-Objekt aus SQLAlchemy und geben beim Erstellen Vorlagen mit dem Parameter naming_convention an, dessen Schlüssel die Arten von Indizes und Einschränkungen angeben: ix ist ein regulärer Index, uq ist ein eindeutiger Index, fk ist ein Fremdschlüssel, pk ist Primärschlüssel.
In den Werten des Parameters naming_convention können Sie eine Vorlage angeben, die aus dem Indextyp / der Einschränkung (ix / uq / fk usw.) und dem Tabellennamen besteht, die durch Unterstriche getrennt sind. In einigen Vorlagen können Sie auch alle Spalten auflisten. Dies ist beispielsweise für den Primärschlüssel nicht erforderlich. Sie können einfach den Tabellennamen angeben.
Wenn Sie ein neues Projekt erstellen, fügen Sie ihm einmal Namensvorlagen hinzu und vergessen es. Seitdem wurden alle Migrationen mit denselben Indizes und Einschränkungen generiert.
Dies ist aus einem anderen Grund wichtig: Wenn Sie entscheiden, dass dieser Index in Ihrem Objektmodell nicht mehr benötigt wird, und ihn löschen, weiß Alembic, wie er heißt, und generiert die Migration korrekt. Dies ist bereits eine gewisse Garantie für die Zuverlässigkeit, dass alles so funktioniert, wie es sollte.
Eine weitere sehr wichtige Entität, auf die Sie stoßen müssen, ist eine Tabelle, ein Objekt, das beschreibt, was die Tabelle enthält.

Die Tabelle hat einen Namen, Spalten mit Datentypen und verweist notwendigerweise auf die MetaData-Registrierung, da MetaData eine Registrierung für alles ist, was Sie beschreiben. Und es gibt Spalten mit Datentypen.
Dank dem, was wir beschrieben haben, kann und weiß SQLAlchemy jetzt viel. Wenn wir hier einen Fremdschlüssel angeben würden, würde sie immer noch wissen, wie unsere Tabellen miteinander verbunden sind. Und sie würde die Reihenfolge kennen, in der etwas getan werden muss.

SQLAlchemy hat auch Engine. Wichtig: Was wir über Abfragen gesagt haben, kann separat verwendet werden, und Engine kann separat verwendet werden. Und Sie können alles zusammen verwenden, niemand verbietet. Das heißt, Engine weiß, wie man eine direkte Verbindung zum Server herstellt, und bietet Ihnen genau dieselbe Schnittstelle. Nein, natürlich versuchen verschiedene Treiber, DBAPI einzuhalten. In Python gibt es einen PEP, der Empfehlungen abgibt. Aber Engine bietet Ihnen genau die gleiche Schnittstelle für alle Datenbanken und ist sehr praktisch.

Der letzte wichtige Meilenstein ist der Dialekt. Auf diese Weise kommuniziert die Engine mit verschiedenen Datenbanken. Hier gibt es verschiedene Sprachen, verschiedene Menschen und verschiedene Dialekte.
Mal sehen, wofür das alles ist.

So sieht ein normaler Einsatz aus. Wenn wir eine neue Zeile hinzufügen möchten, die zuvor beschriebene Platte, in der sich eine ID und ein E-Mail-Feld befanden, geben wir hier die E-Mail an, führen Einfügen aus und erhalten sofort alles zurück, was wir eingefügt haben.
Was ist, wenn wir viele Zeilen hinzufügen möchten? Keine Probleme.

Hier können Sie einfach eine Liste von Diktaten übertragen. Sieht aus wie perfekter Code für einen supereinfachen Stift. Die Daten gingen ein, bestanden eine Art Validierung, ein JSON-Schema und alles wurde in die Datenbank aufgenommen. Super einfach.
Einige Abfragen sind recht komplex. Manchmal kann eine Anfrage sogar mit einem Ausdruck angezeigt werden, manchmal müssen Sie sie kompilieren. Das ist nicht schwer. Mit Alchemie können Sie all dies tun. In diesem Fall haben wir die Anfrage kompiliert, und Sie können sehen, was tatsächlich in die Datenbank fliegt.

Die Datenanforderung sieht recht einfach aus. Buchstäblich zwei Zeilen, Sie können sogar in einer schreiben.

Kehren wir zu unserer Frage zurück, wie beispielsweise eine PATCH-Anforderung für 15 Felder geschrieben werden kann. Hier sollten Sie nur den Namen des Feldes, seinen Schlüssel und Wert schreiben. Das ist alles was benötigt wird. Keine Dateien, kein Stringaufbau, überhaupt nichts. Klingt bequem.
Die vielleicht wichtigste Alchemie-Funktion, die ich jeden Tag in meiner Arbeit verwende, ist die Zerlegung und Erweiterung von Abfragen.

Angenommen, Sie schreiben eine Schnittstelle in PostgreSQL. Ihre Anwendung muss eine Person irgendwie autorisieren und sie in die Lage versetzen, CRUD auszuführen. Okay, es gibt nicht viel zu zersetzen.
Wenn Sie eine sehr komplexe Anwendung schreiben, die Datenversionierung, eine Reihe verschiedener Abstraktionen, verwendet, können die von Ihnen generierten Abfragen aus einer großen Anzahl von Unterabfragen bestehen. Unterabfragen werden mit Unterabfragen verknüpft. Es gibt verschiedene Aufgaben. Und manchmal hilft die Zerlegung von Abfragen sehr, sie ermöglicht eine gute Trennung von Logik und Code-Design.
Warum funktioniert das so? Wenn Sie beispielsweise die Methode users_table.select () aufrufen, wird ein Objekt zurückgegeben. Wenn Sie eine andere Methode für das resultierende Objekt aufrufen, z. B. where (), wird ein vollständig neues Objekt zurückgegeben. Alle Abfrageobjekte sind unveränderlich. Daher können Sie auf alles aufbauen, was Sie möchten.
Migrationen aus dem Destillierkolben
Wir haben uns also mit SQLAlchemy befasst und können nun endlich alembische Migrationen schreiben.

Der Einstieg in die Verwendung von Alembic ist überhaupt nicht schwierig, insbesondere wenn Sie Ihre Tabellen, wie bereits erwähnt, bereits beschrieben und ein MetaData-Objekt angegeben haben. Sie müssen nur alembic installieren, alembic init alembic aufrufen. alembic - der Name des Moduls, dies ist die Befehlszeile, Sie werden es haben. init ist ein Befehl. Das letzte Argument ist der Ordner, in dem es abgelegt werden soll.
Wenn Sie diesen Befehl aufrufen, haben Sie mehrere Dateien, die wir uns jetzt genauer ansehen werden.

Es wird eine allgemeine Konfiguration in alembic.ini geben. script_location ist genau dort, wo Sie es haben möchten. Als Nächstes erhalten Sie eine Vorlage für die Namen Ihrer Migrationen, die Sie generieren, sowie Informationen zum Herstellen einer Verbindung zur Datenbank.

Es gibt auch eine Vorlage für neue Migrationen. Sie sagen: "Ich möchte eine neue Migration", und Alembic erstellt sie gemäß einer bestimmten Vorlage. Sie können all dies anpassen, es ist sehr einfach. Sie gehen in diese Datei und bearbeiten alles, was Sie brauchen. Alle Variablen, die hier angegeben werden können, befinden sich in der Dokumentation. Dies ist der erste Teil. Oben befindet sich eine Art Kommentar, damit Sie bequem sehen können, was dort passiert. Dann gibt es eine Reihe von Variablen, die in jeder Migration enthalten sein sollten - Revision, Down_Revision. Wir werden heute mit ihnen arbeiten. Weiter - zusätzliche Meta-Informationen.

Die wichtigsten Methoden sind Upgrade und Downgrade. Alembic ersetzt hier den Unterschied, den das MetaData-Objekt zwischen Ihrer Schemabeschreibung und dem, was sich in der Datenbank befindet, findet.

env.py ist die interessanteste Datei in Alembic. Es steuert den Fortschritt der Befehlsausführung und ermöglicht es Ihnen, ihn selbst anzupassen. In dieser Datei verbinden Sie Ihr MetaData-Objekt. Wie bereits erwähnt, ist das MetaData-Objekt die Registrierung für alle Entitäten in Ihrer Datenbank.
Sie verbinden dieses MetaData-Objekt hier. Und von diesem Zeitpunkt an versteht Alembic, dass sie hier sind, meine Modelle, hier sind sie, meine Teller. Er versteht, womit er arbeitet. Als nächstes hat Alembic einen Code, der Alembic entweder offline oder online aufruft. Wir werden jetzt auch all dies berücksichtigen.
Dies ist genau die Zeile, in der Sie MetaData in Ihrem Projekt verbinden müssen. Mach dir keine Sorgen, wenn etwas nicht sehr klar ist, ich habe alles in einem Projekt gesammelt und auf GitHub gepostet . Sie können es klonen und alles sehen, fühlen.

Was ist der Online-Modus? Im Online-Modus stellt Alembic eine Verbindung zu der im Parameter sqlalchemy.url in der Datei alembic.ini angegebenen Datenbank her und beginnt mit der Ausführung von Migrationen.
Warum schauen wir uns diesen Code überhaupt an? Alembic kann sehr flexibel angepasst werden.
Stellen Sie sich vor, Sie haben eine Anwendung, die in verschiedenen Datenbankschemata leben muss. Sie möchten beispielsweise, dass viele Anwendungsinstanzen gleichzeitig ausgeführt werden und jede in einem eigenen Schema lebt. Es kann bequem und notwendig sein.
Es kostet dich überhaupt nichts. Nach dem Aufruf der Methode context.begin_transaction () können Sie den Befehl "SET search_path = SCHEMA" schreiben, der PostgreSQL anweist, ein anderes Standardschema zu verwenden. Und alle. Von nun an lebt Ihre Anwendung in einem völlig anderen Schema, Migrationen rollen in ein anderes Schema. Dies ist eine einzeilige Frage.

Es gibt auch einen Offline-Modus. Beachten Sie, dass Alembic hier keine Engine verwendet. Hier können Sie einfach einen Link zu ihm übergeben. Sie können die Engine natürlich auch übertragen, sie verbindet sich jedoch nirgendwo. Es werden nur Rohabfragen generiert, die Sie dann irgendwo ausführen können.

Sie haben also Alembic und einige MetaData mit Tabellen. Und Sie möchten endlich Migrationen für sich selbst generieren. Sie führen diesen Befehl aus und im Grunde ist es das. Alembic wird in die Datenbank gehen und sehen, was dort ist. Gibt es sein spezielles Label "alembic_versions", das Ihnen sagt, dass Migrationen bereits in dieser Datenbank eingeführt wurden? Wird sehen, welche Tabellen dort existieren. Wird sehen, welche Daten Sie in der Datenbank benötigen. Es wird all dies analysieren, eine neue Datei generieren, die nur auf dieser Vorlage basiert, und Sie werden eine Migration durchführen. Natürlich sollten Sie sich unbedingt ansehen, was bei der Migration generiert wurde, da Alembic nicht immer das generiert, was Sie möchten. Aber meistens funktioniert es.

Was haben wir generiert? Es gab ein Benutzerzeichen. Als wir die Migration generiert haben, habe ich die Anfangsnachricht angegeben. Die Migration heißt initial.py mit einer anderen Vorlage, die zuvor in alembic.ini angegeben wurde.
Es gibt auch Informationen darüber, welche ID diese Migration hat. down_revision = Keine - Dies ist die erste Migration.
Die nächste Folie ist der wichtigste Teil: Upgrade und Downgrade.

Im Upgrade sehen wir, dass eine Platte erstellt wird. Beim Downgrade wird dieses Zeichen entfernt. Alembic fügt solche Kommentare standardmäßig speziell hinzu, damit Sie dorthin gehen, sie bearbeiten und zumindest diese Kommentare löschen können. Und für alle Fälle haben wir die Migration überprüft und sichergestellt, dass alles zu Ihnen passt. Dies ist eine Frage eines Teams. Sie haben bereits eine Migration.

Danach möchten Sie diese Migration höchstwahrscheinlich anwenden. Einfacher geht es nicht. Sie müssen nur sagen: Alembic Upgrade-Kopf. Er wird absolut alles anwenden.
Wenn wir head sagen, wird versucht, auf die neueste Migration zu aktualisieren. Wenn wir eine bestimmte Migration benennen, wird diese aktualisiert.
Es gibt auch einen Downgrade-Befehl - falls Sie zum Beispiel Ihre Meinung ändern. All dies geschieht in Transaktionen und funktioniert ganz einfach.

Sie haben also Migrationen und wissen, wie Sie diese ausführen. Sie haben eine Anwendung und stellen beispielsweise folgende Frage: Ich habe CI, Tests werden ausgeführt, und ich weiß nicht einmal, ob ich beispielsweise Migrationen automatisch ausführen möchte. Vielleicht ist es besser, es mit deinen Händen zu tun?
Hier gibt es verschiedene Sichtweisen. Wahrscheinlich lohnt es sich, die Regel einzuhalten: Wenn Sie keinen einfachen Zugang haben, die Möglichkeit haben, mit einer Datenbank in ein Auto einzusteigen, ist es natürlich besser, dies automatisch zu tun.
Wenn Sie Zugriff haben, erstellen Sie einen Dienst, der in der Cloud funktioniert, und Sie können von einem Laptop, den Sie immer bei sich haben, dorthin gehen. Dann können Sie dies selbst tun und sich dadurch mehr Kontrolle geben.
Im Allgemeinen gibt es viele Tools, um dies automatisch zu tun. Zum Beispiel in den gleichen Kubernetes. Es gibt Init-Container, die dies können und in denen Sie diese Befehle ausführen können. Sie können Docker dazu direkt einen Startbefehl hinzufügen.
Sie müssen nur Folgendes berücksichtigen: Wenn Sie Migrationen automatisch anwenden, müssen Sie darüber nachdenken, was passiert, wenn Sie beispielsweise ein Rollback durchführen möchten, dies jedoch nicht können. Sie hatten beispielsweise eine 500-Gigabyte-Datenplatte. Sie dachten: Okay, diese Daten werden für die Geschäftslogik nicht mehr benötigt, Sie können sie wahrscheinlich löschen. Sie nahmen es und ließen es fallen. Oder Sie haben den Typ einer Spalte geändert, der sich mit Datenverlust geändert hat. Zum Beispiel gab es eine lange Schlange, aber sie wurde kurz. Oder etwas ist weg. Oder Sie haben eine Spalte gelöscht. Sie können nicht zurücksetzen, auch wenn Sie möchten.
Einmal habe ich Produkte für den lokalen Gebrauch hergestellt, die per Exe-Datei an Personen direkt an der Maschine gesendet werden. Sobald Sie verstanden haben: Ja, Sie haben die Migration geschrieben, sie ging in Produktion, die Leute haben sie bereits installiert. In den nächsten fünf Jahren könnte es laut SLA für sie funktionieren, und Sie möchten etwas ändern, etwas könnte besser sein. In diesem Moment überlegen Sie, wie Sie mit irreversiblen Veränderungen umgehen sollen.

Auch hier keine Raketenwissenschaft. Die Idee ist, dass Sie die Verwendung dieser Spalten oder Tabellen so weit wie möglich vermeiden können. Hör auf, sie zu kontaktieren. Sie können beispielsweise Felder mit einem speziellen Dekorator im ORM markieren. Er wird in den Protokollen sagen, dass Sie dieses Feld anscheinend nicht berühren wollten, aber Sie beziehen sich immer noch auf ihn. Fügen Sie einfach eine Aufgabe zum Backlog hinzu und löschen Sie sie eines Tages.
Wenn überhaupt, haben Sie Zeit, sich zurückzusetzen. Und wenn alles gut geht, werden Sie diese Aufgabe später im Backlog ruhig erledigen. Führen Sie eine weitere Migration durch, bei der tatsächlich alles gelöscht wird.
Nun zur wichtigsten Frage: Warum und wie werden Migrationen getestet?

Dies tun einige von denen, die ich gefragt habe. Aber es ist besser, es zu tun. Dies ist eine Regel, die in Schmerz, Blut und Schweiß geschrieben ist. Die Verwendung von Migration in der Produktion ist immer riskant. Sie wissen nie, wie es enden könnte. Selbst eine sehr gute Migration auf eine völlig normal funktionierende Produktion, wenn Sie CI konfiguriert haben, kann ruckeln.
Tatsache ist, dass Sie beim Testen von Migrationen sogar beispielsweise eine Phase oder einen Teil der Produktion herunterladen können. Die Produktion kann groß sein, Sie können sie nicht vollständig für Tests oder andere Aufgaben herunterladen. Entwicklungsbasen sind in der Regel keine wirklichen Produktionsbasen. Sie haben nicht viel von dem, was sich im Laufe der Jahre angesammelt haben könnte.

Dies können beschädigte Daten sein, wenn wir etwas migriert haben, oder alte Software, die die Daten inkonsistent gemacht hat. Es können auch implizite Abhängigkeiten sein - wenn jemand vergessen hat, einen Fremdschlüssel hinzuzufügen. Er glaubt, dass es verbunden ist, aber seine Kollegen wissen zum Beispiel nichts davon. Die Felder werden auch ganz zufällig genannt, es ist im Allgemeinen nicht klar, dass sie verbunden sind.
Dann entschied sich jemand, eine Art Index direkt zur Produktion hinzuzufügen, weil "es jetzt langsamer wird, aber was ist, wenn es schneller funktioniert?" Vielleicht übertreibe ich, aber die Leute ändern manchmal wirklich etwas richtig in den Datenbanken.
Es gibt natürlich Fehler in Tools und in der Schemamigration. Um ehrlich zu sein, bin ich nicht darauf gestoßen. Es gab normalerweise die ersten drei Probleme. Und vielleicht mehr Fehler bei den Annahmen darüber, wie Daten übertragen werden sollen.
Wenn Sie ein sehr großes Objektmodell haben, ist es schwierig, alles im Auge zu behalten. Es ist schwierig, ständig aktuelle Dokumentationen zu schreiben. Die aktuellste Dokumentation ist Ihr Code, und es gibt nicht immer eine vollständig geschriebene Geschäftslogik: Was und wie sollte funktionieren, wer hatte was im Sinn.

Was können wir überprüfen? Zumindest dass die Migration beginnt. Das ist schon toll. Und dass der Code keine dummen Tippfehler enthält. Wir können überprüfen, ob es eine gültige downgrade () -Methode gibt, dass die downgrade () -Methode alle von SQLAlchemy erstellten Datentypen löscht.
SQLAlchemy macht viele schöne Dinge. Wenn Sie beispielsweise eine Tabelle beschreiben und einen Aufzählungsspaltentyp angeben, erstellt SQLAlchemy automatisch den Datentyp für diese Aufzählung in PostgreSQL. Der Code zum Entfernen dieses Datentyps in der downgrade () -Methode wird jedoch nicht automatisch generiert.
Sie müssen dies beachten und überprüfen: Wenn Sie die Migration zurücksetzen und erneut anwenden möchten, wird beim Versuch, einen vorhandenen Datentyp in der upgrade () -Methode zu erstellen, eine Ausnahme ausgelöst. Und vor allem, wenn die Migration Daten ändert, müssen Sie überprüfen, ob sich die Daten beim Upgrade korrekt ändern. Und es ist sehr wichtig zu überprüfen, ob sie beim Downgrade ohne Nebenwirkungen korrekt zurückgesetzt werden.

Bevor wir mit den Tests selbst fortfahren, wollen wir uns ansehen, wie Sie sich am besten auf das Schreiben vorbereiten können. Ich habe viele Ansätze dafür gesehen. Einige Leute erstellen eine Basis, Platten, schreiben dann eine Vorrichtung, die alles aufräumt, und verwenden eine Art automatisch aufgebrachte Vorrichtungen . Der ideale Weg, um Sie zu 100% zu schützen und Tests in einem vollständig isolierten Raum durchzuführen, ist die Erstellung einer separaten Datenbank.
Es gibt ein fantastisches sqlalchemy_utils-Modul, mit dem Datenbanken erstellt und gelöscht werden können. In PostgreSQL prüft er außerdem: Wenn einer der Clients eingeschlafen ist und die Verbindung nicht getrennt hat, stürzt er nicht mit dem Fehler ab, dass "jemand die Datenbank verwendet, ich kann nichts damit anfangen, ich kann sie nicht löschen". Stattdessen wird er ruhig sehen, wer sich mit ihnen verbunden hat, diese Clients trennen und die Basis ruhig löschen.
Das Erstellen einer Datenbank und das Anwenden einer Migration auf jeden Test ist nicht immer ein schneller Prozess. Dies kann wie folgt gelöst werden: PostgreSQL unterstützt die Erstellung neuer Datenbanken aus einer Vorlage, sodass Sie die Datenbankvorbereitung in zwei Fixtures aufteilen können.
Das erste Fixture wird einmal ausgeführt, um alle Tests auszuführen (scope = session), erstellt eine Datenbank und wendet Migrationen darauf an. Das zweite Gerät (Umfang = Funktion) erstellt Basen direkt für jeden Test basierend auf der Basis des ersten Geräts.
Das Erstellen einer Datenbank aus einer Vorlage ist sehr schnell und spart Zeit beim Anwenden von Migrationen für jeden Test.

Wenn wir nur darüber sprechen, wie wir vorübergehend eine Datenbank erstellen können, können wir ein solches Gerät schreiben. Was ist hier los? Wir werden einen zufälligen Namen generieren. Wir fügen für alle Fälle das Ende des Pytests hinzu, damit wir verstehen können, was durch Tests erstellt wurde und was nicht, wenn wir über ein Postico zu localhost gehen.
Dann generieren wir aus dem Link Informationen über die Verbindung zur Datenbank, die die Person angezeigt hat, eine neue, bereits mit einer neuen Datenbank. Wir erstellen es und senden es einfach an Tests. Nachdem eine Person mit dieser Datenbank gearbeitet hat, löschen wir sie.

Wir können die Engine auch für die Verbindung mit dieser Datenbank vorbereiten. Das heißt, in diesem Gerät beziehen wir uns auf das vorherige Gerät, das als Abhängigkeit verwendet wurde. Wir erstellen eine Engine und senden sie an Tests.

Welche Tests können wir also schreiben? Der erste Test ist nur eine brillante Erfindung meines Kollegen. Ich glaube, ich habe die Probleme mit Migrationen vergessen.
Dies ist ein sehr einfacher Test. Sie fügen es Ihrem Projekt einmal hinzu. Es ist im Projekt auf GitHub... Sie können es einfach zu sich ziehen, vielleicht 80 Prozent der Probleme hinzufügen und vergessen.
Es macht eine sehr einfache Sache: Es ruft eine Liste aller Migrationen ab und beginnt, diese zu durchlaufen. Ruft Upgrade, Downgrade, Upgrade auf.

Zum Beispiel haben wir fünf Migrationen. Mal sehen, wie das funktioniert. Hier ist die erste Migration. Wir haben es erfüllt. Führen Sie ein Rollback der ersten Migration durch und führen Sie sie erneut aus. Was ist hier passiert? Tatsächlich haben wir hier gesehen, dass die Person die downgrade () -Methode korrekt implementiert hat, da es beispielsweise zweimal nicht möglich gewesen wäre, Tabellen zu erstellen.
Wir sehen, dass eine Person, die einige Datentypen erstellt hat, diese auch gelöscht hat, da es keine Tippfehler gibt und dies im Allgemeinen zumindest irgendwie funktioniert.
Dann geht der Test weiter. Er nimmt die zweite Migration, rennt sofort dorthin, rollt einen Schritt zurück und rennt wieder vorwärts. Und das passiert so oft, wie Sie Migrationen haben.
Der Zweck dieses Tests ist es, grundlegende Fehler und Probleme beim Ändern der Datenstruktur zu finden.
Die Treppe beginnt auf einer leeren Basis und ist normalerweise sehr schnell. Das heißt, bei diesem Test geht es mehr um die Datenstruktur. Hier geht es nicht darum, Daten bei Migrationen zu ändern. Aber insgesamt kann es Ihr Leben sehr gut retten.
Wenn Sie eine schnelle Lösung wünschen, ist dies das Richtige. Diese Regel ist. Als Faustregel gilt: Fügen Sie es in Ihr Projekt ein, und es wird für Sie einfacher.

Dieser Test sieht ungefähr so aus. Wir bekommen alle Revisionen, generieren die Alembic Konfiguration. Hier ist, was wir zuvor gesehen haben, die Datei alembic.ini, hier ist die Funktion get_alembic_config, sie liest diese Datei und fügt unsere temporäre Basis hinzu, da wir dort den Pfad zur Basis angegeben haben. Und danach können wir Alembic-Befehle verwenden.
Der zuvor ausgeführte Befehl - Alembic Upgrade Head - kann ebenfalls sicher importiert werden. Leider passt diese Folie nicht zu allen Importen, aber nehmen Sie mein Wort dafür. Es ist nur von alembic.com Import Upgrade. Dort übersetzen Sie die Konfiguration und geben an, wo das Upgrade durchgeführt werden soll. Dann sagen Sie: Downgrade.
Beim Downgrade wird die Migration auf down_revision, dh auf die vorherige Revision, oder auf "-1" zurückgesetzt.
"-1" ist eine alternative Methode, um Alembic anzuweisen, die aktuelle Migration zurückzusetzen. Es ist sehr relevant, wenn die erste Migration gestartet wird. Die down_revision lautet None, während die Alembic-API die Übergabe von None an den Downgrade-Befehl nicht zulässt.
Dann wird der Upgrade-Befehl erneut ausgeführt.
Lassen Sie uns nun darüber sprechen, wie Migrationen mit Daten getestet werden.

Datenmigrationen scheinen normalerweise sehr einfach zu sein, aber es tut am meisten weh. Es scheint, als würde man eine Auswahl schreiben, einfügen, Daten aus einer Tabelle entnehmen und in einem etwas anderen Format in eine andere übertragen - was könnte einfacher sein?
Zu diesem Test bleibt noch zu sagen, dass die Entwicklung im Gegensatz zum vorherigen sehr teuer ist. Bei großen Migrationen habe ich manchmal sechs Stunden gebraucht, um alle Invarianten zu betrachten. Es ist in Ordnung, alles zu beschreiben. Aber als ich diese Migrationen bereits rollte, war ich ruhig.

Wie funktioniert dieser Test? Die Idee ist, dass wir alle Migrationen bis zu der anwenden, die wir jetzt testen möchten. Wir fügen eine Reihe von Daten in die Datenbank ein, die sich ändern werden. Wir können darüber nachdenken, zusätzliche Daten einzufügen, die sich implizit ändern könnten. Dann aktualisieren wir. Wir überprüfen, ob die Daten korrekt geändert wurden, führen ein Downgrade durch und überprüfen, ob die Daten korrekt geändert wurden.

Der Code sieht ungefähr so aus. Das heißt, es gibt auch eine Parametrisierung durch Revision, es gibt eine Reihe von Parametern. Wir akzeptieren unsere Engine hier, akzeptieren die Migration, mit der wir mit dem Testen beginnen möchten.
Dann rev_head, was wir testen wollen. Und dann drei Rückrufe. Dies sind die Rückrufe, die wir irgendwo definieren, und sie werden aufgerufen, nachdem etwas getan wurde. Wir können überprüfen, was dort los ist.
Wo kann ich ein Beispiel sehen?
Ich habe alles in ein Beispiel auf GitHub gepackt . Es ist wirklich nicht viel Code enthalten, aber es ist schwierig, der Folie etwas hinzuzufügen. Ich habe versucht, das Grundlegendste zu ertragen. Sie können zu GitHub gehen und sehen, wie es im Projekt selbst funktioniert. Dies ist der einfachste Weg.
Was ist es noch wert, beachtet zu werden? Während des Startvorgangs sucht Alembic in dem Ordner, in dem sie gestartet wurde, nach der Konfigurationsdatei alembic.ini. Natürlich können Sie den Pfad mit der Umgebungsvariablen ALEMBIC_CONFIG angeben, dies ist jedoch nicht immer bequem und offensichtlich.
Ein weiteres Problem: Informationen zum Herstellen einer Verbindung zur Datenbank sind in alembic.ini angegeben. Oft müssen Sie jedoch in der Lage sein, nacheinander mit mehreren Datenbanken zu arbeiten. Rollen Sie beispielsweise Migrationen auf die Bühne und dann auf das Produkt. Im Allgemeinen können Sie Verbindungsinformationen in der Umgebungsvariablen SQLALCHEMY_URL angeben, dies ist jedoch für Endbenutzer Ihrer Software nicht sehr offensichtlich.
Für Endbenutzer ist es außerdem viel intuitiver, das Dienstprogramm "$ project $ -db" zu verwenden als "alembic".
Schauen Sie sich beim Betrachten der Beispiele im Projekt das Dienstprogramm staff-db an. Es ist eine dünne Hülle um Alembic und eine weitere Möglichkeit, Alembic für Sie anzupassen. Standardmäßig wird die Datei alembic.ini im Projekt relativ zu ihrem Speicherort gesucht. Aus jedem Ordner, den Benutzer sie nennen, findet sie selbst die Konfigurationsdatei. Außerdem fügt staff-db ein Argument --db-url hinzu, mit dem Sie Informationen angeben können, um eine Verbindung zur Datenbank herzustellen. Und, was wichtig ist, sehen Sie es, indem Sie die allgemein akzeptierte Option --help übergeben. Schließlich ist der Name des Dienstprogramms intuitiv.
Alle ausführbaren Projektbefehle beginnen mit dem Namen des Moduls "staff": staff-api, auf dem die REST-API ausgeführt wird, und staff-db, die den Basisstatus verwaltet. Wenn Sie dieses Muster verstehen, schreibt der Client den Namen Ihres Programms und kann alle verfügbaren Dienstprogramme durch Drücken der TAB-Taste anzeigen, auch wenn er den vollständigen Namen vergisst. Ich habe alles, danke.