
Selbstidentifikation
Mein Name ist Alexander, ich entwickle die Richtung der Daten- und Technologieanalyse für die Zwecke der internen Revision der Rosbank-Gruppe. Mein Team und ich verwenden maschinelles Lernen und neuronale Netze, um Risiken im Rahmen interner Audits zu identifizieren. Wir haben einen Server ~ 300 GB RAM und 4 Prozessoren mit 10 Kernen in unserem Arsenal. Für die algorithmische Programmierung oder Modellierung verwenden wir Python.
Einführung
Wir standen vor der Aufgabe, Fotos (Porträts) von Kunden zu analysieren, die von Bankangestellten bei der Registrierung eines Bankprodukts aufgenommen wurden. Unser Ziel ist es, zuvor aufgedeckte Risiken anhand dieser Fotos zu identifizieren. Um das Risiko zu identifizieren, erstellen und testen wir eine Reihe von Hypothesen. In diesem Artikel werde ich beschreiben, welche Hypothesen wir aufgestellt haben und wie wir sie getestet haben. Um die Wahrnehmung des Materials zu vereinfachen, werde ich die Mona Lisa verwenden - den Standard des Porträtgenres.

Prüfsumme
Zuerst haben wir einen Ansatz ohne maschinelles Lernen und Computer Vision gewählt und nur die Prüfsummen der Dateien verglichen. Um sie zu generieren, haben wir den weit verbreiteten md5-Algorithmus aus der Hash-Bibliothek übernommen.
Python * -Implementierung:
#
with open(file,'rb') as f:
#
for chunk in iter(lambda: f.read(4096),b''):
#
hash_md5.update(chunk)
Bei der Erstellung der Prüfsumme prüfen wir sofort mit einem Wörterbuch auf Duplikate.
#
for file in folder_scan(for_scan):
#
ch_sum = checksum(file)
#
if ch_sum in list_of_uniq.keys():
# , , dataframe
df = df.append({'id':list_of_uniq[chs],'same_checksum_with':[file]}, ignore_index = True)
Dieser Algorithmus ist in Bezug auf die Rechenlast unglaublich einfach: Auf unserem Server werden 1000 Bilder in nicht mehr als 3 Sekunden verarbeitet.
Dieser Algorithmus hat uns geholfen, doppelte Fotos in unseren Daten zu identifizieren und als Ergebnis Orte für eine mögliche Verbesserung des Geschäftsprozesses der Bank zu finden.
Wichtige Punkte (Computer Vision)
Trotz des positiven Ergebnisses der Prüfsummenmethode haben wir genau verstanden, dass sich die Prüfsumme radikal ändert, wenn mindestens ein Pixel im Bild geändert wird. Als logische Entwicklung der ersten Hypothese nahmen wir an, dass das Bild in der Bitstruktur geändert werden könnte: erneut speichern (dh JPG erneut komprimieren), die Größe ändern, zuschneiden oder drehen.
Lassen Sie uns zur Demonstration die Kanten entlang des roten Umrisses zuschneiden und die Mona Lisa um 90 Grad nach rechts drehen.

In diesem Fall müssen Duplikate nach dem visuellen Inhalt des Bildes gesucht werden. Zu diesem Zweck haben wir uns für die OpenCV-Bibliothek entschieden, eine Methode zum Erstellen von Schlüsselpunkten eines Bildes und zum Ermitteln des Abstands zwischen Schlüsselpunkten. In der Praxis können wichtige Punkte Ecken, Farbverläufe oder Oberflächenbewegungen sein. Für unsere Zwecke wurde eine der einfachsten Methoden entwickelt - Brute-Force-Matching. Um den Abstand zwischen den Schlüsselpunkten des Bildes zu messen, haben wir den Hamming-Abstand verwendet. Das folgende Bild zeigt das Ergebnis der Suche nach Schlüsselpunkten auf den Originalbildern und den geänderten Bildern (20 Schlüsselpunkte der Bilder, die in der Entfernung am nächsten liegen, werden gezeichnet).
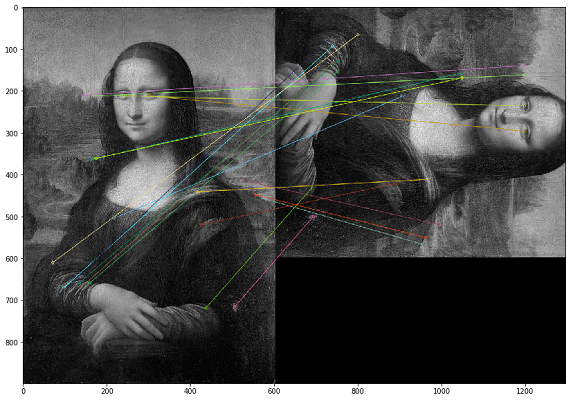
Es ist wichtig zu beachten, dass wir Bilder in einem Schwarzweißfilter analysieren, da dies die Laufzeit des Skripts optimiert und eine eindeutigere Interpretation der wichtigsten Punkte ermöglicht. Wenn ein Bild mit einem Sepia-Filter und das andere mit einem Farboriginal versehen ist, werden die wichtigsten Punkte unabhängig von der Farbverarbeitung und den Filtern identifiziert, wenn wir sie in einen Schwarzweißfilter konvertieren.
Beispielcode zum Vergleichen von zwei Bildern *
img1 = cv.imread('mona.jpg',cv.IMREAD_GRAYSCALE) #
img2 = cv.imread('mona_ch.jpg',cv.IMREAD_GRAYSCALE) #
# ORB
orb = cv.ORB_create()
# ORB
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# Brute-Force Matching
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)
# .
matches = bf.match(des1,des2)
# .
matches = sorted(matches, key = lambda x:x.distance)
# 20
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:20],None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.imshow(img3),plt.show()
Beim Testen der Ergebnisse haben wir festgestellt, dass sich im Fall eines Flip-Images die Reihenfolge der Pixel innerhalb des Schlüsselpunkts ändert und solche Bilder nicht als gleich identifiziert werden. Als Ausgleichsmaßnahme können Sie jedes Bild selbst spiegeln und das doppelte (oder sogar dreifache) Volumen analysieren, was im Hinblick auf die Rechenleistung viel teurer ist.
Dieser Algorithmus weist eine hohe Rechenkomplexität auf, und die größte Last wird durch die Berechnung des Abstands zwischen Punkten erzeugt. Da wir jedes Bild mit jedem vergleichen müssen, erfordert die Berechnung einer solchen kartesischen Menge, wie Sie verstehen, eine große Anzahl von Rechenzyklen. In einem Audit dauerte eine ähnliche Berechnung über einen Monat.
Ein weiteres Problem bei diesem Ansatz war die schlechte Interpretierbarkeit der Testergebnisse. Wir erhalten den Koeffizienten der Abstände zwischen den Schlüsselpunkten der Bilder, und es stellt sich die Frage: "Welcher Schwellenwert dieses Koeffizienten sollte ausreichend gewählt werden, um die duplizierten Bilder zu berücksichtigen?"
Mithilfe von Computer Vision konnten wir Fälle finden, die vom ersten Prüfsummentest nicht abgedeckt wurden. In der Praxis stellte sich heraus, dass es sich um übergespeicherte JPG-Dateien handelte. Wir haben keine komplexeren Fälle von Bildänderungen im analysierten Datensatz identifiziert.
Prüfsumme VS Schlüsselpunkte
Nachdem wir zwei radikal unterschiedliche Ansätze entwickelt hatten, um Duplikate zu finden und in mehreren Prüfungen wiederzuverwenden, kamen wir zu dem Schluss, dass die Prüfsumme für unsere Daten in kürzerer Zeit ein greifbareres Ergebnis liefert. Wenn wir also genügend Zeit haben, um dies zu überprüfen, führen wir einen Vergleich nach wichtigen Punkten durch.
Suchen Sie nach abnormalen Bildern
Nach der Analyse der Testergebnisse auf wichtige Punkte stellten wir fest, dass die von einem Mitarbeiter aufgenommenen Fotos ungefähr die gleiche Anzahl enger Schlüsselpunkte aufweisen. Und das ist logisch, denn wenn er an seinem Arbeitsplatz mit Kunden kommuniziert und im selben Raum fotografiert, ist der Hintergrund aller seiner Fotos der gleiche. Diese Beobachtung ließ uns glauben, dass wir möglicherweise Ausnahmefotos finden, die sich von anderen Fotos dieses Mitarbeiters unterscheiden, die möglicherweise außerhalb des Büros aufgenommen wurden.
Zurück zum Beispiel mit Mona Lisa: Es stellt sich heraus, dass andere Personen vor demselben Hintergrund auftreten. Leider haben wir solche Beispiele nicht gefunden. In diesem Abschnitt werden Datenmetriken ohne Beispiele angezeigt. Um die Berechnungsgeschwindigkeit im Rahmen des Testens dieser Hypothese zu erhöhen, haben wir beschlossen, wichtige Punkte aufzugeben und Histogramme zu verwenden.
Der erste Schritt besteht darin, das Bild in ein Objekt (Histogramm) zu übersetzen, das wir messen können, um die Bilder anhand des Abstands zwischen ihren Histogrammen zu vergleichen. Grundsätzlich ist ein Histogramm ein Diagramm, das einen Überblick über das Bild gibt. Dies ist ein Diagramm mit Pixelwerten auf der Abszissenachse (X-Achse) und der entsprechenden Anzahl von Pixeln im Bild entlang der Ordinatenachse (Y-Achse). Ein Histogramm ist eine einfache Möglichkeit, ein Bild zu interpretieren und zu analysieren. Mithilfe des Histogramms eines Bildes erhalten Sie eine intuitive Vorstellung von Kontrast, Helligkeit, Intensitätsverteilung usw.
Für jedes Bild erstellen wir ein Histogramm mit der Funktion calcHist von OpenCV.
histo = cv2.calcHist([picture],[0],None,[256],[0,256])
In den Beispielen für drei Bilder haben wir sie mit 256 Faktoren entlang der horizontalen Achse (alle Arten von Pixeln) beschrieben. Wir können die Pixel aber auch neu anordnen. Unser Team hat in diesem Teil nicht viele Tests durchgeführt, da das Ergebnis bei Verwendung von 256 Faktoren ziemlich gut war. Bei Bedarf können wir diesen Parameter direkt in der Funktion calcHist ändern.
Nachdem wir für jedes Bild Histogramme erstellt haben, können wir das DBSCAN-Modell einfach auf Bildern für jeden Mitarbeiter trainieren, der den Kunden fotografiert hat. Der technische Punkt hierbei ist die Auswahl der DBSCAN-Parameter (epsilon und min_samples) für unsere Aufgabe.
Nach der Verwendung von DBSCAN können wir Image-Clustering durchführen und dann die PCA-Methode anwenden, um die resultierenden Cluster zu visualisieren.

Wie aus der Verteilung der analysierten Bilder ersichtlich ist, haben wir zwei ausgeprägte blaue Cluster. Wie sich herausstellte, kann ein Mitarbeiter an verschiedenen Tagen in verschiedenen Büros arbeiten - Fotos, die in einem der Büros aufgenommen wurden, bilden einen separaten Cluster.
Während die grünen Punkte Ausnahmefotos sind, unterscheidet sich der Hintergrund von diesen Clustern.
Bei detaillierter Analyse der Fotos fanden wir viele falsch negative Fotos. Die häufigsten Fälle sind ausgeblasene Fotos oder Fotos, bei denen ein großer Teil der Fläche vom Gesicht des Kunden eingenommen wird. Es stellt sich heraus, dass diese Analysemethode ein obligatorisches Eingreifen des Menschen erfordert, um die Ergebnisse zu validieren.
Mit diesem Ansatz können Sie interessante Anomalien auf dem Foto finden, die manuelle Analyse der Ergebnisse erfordert jedoch einige Zeit. Aus diesen Gründen führen wir solche Tests im Rahmen unserer Audits selten durch.
Gibt es ein Gesicht auf dem Foto? (Gesichtserkennung)
Wir haben unseren Datensatz also bereits von verschiedenen Seiten getestet und gehen, um die Komplexität des Testens weiter zu entwickeln, zur nächsten Hypothese über: Gibt es auf dem Foto ein Gesicht des potenziellen Kunden? Unsere Aufgabe ist es zu lernen, wie man Gesichter in Bildern identifiziert, Funktionen für die Eingabe eines Bildes gibt und die Anzahl der Gesichter an der Ausgabe ermittelt.
Diese Art der Implementierung gibt es bereits und wir haben uns für MTCNN (Multitasking Cascade Convolutional Neural Network) für unsere Aufgabe aus dem FaceNet-Modul von Google entschieden.
FaceNet ist eine Deep Machine Learning-Architektur, die aus Faltungsschichten besteht. FaceNet gibt für jedes Gesicht einen 128-dimensionalen Vektor zurück. Tatsächlich besteht FaceNet aus mehreren neuronalen Netzen und einer Reihe von Algorithmen zur Vorbereitung und Verarbeitung von Zwischenergebnissen dieser Netze. Wir haben uns entschlossen, die Mechanismen der Gesichtssuche durch dieses neuronale Netzwerk genauer zu beschreiben, da es nicht so viele Materialien dazu gibt.
Schritt 1: Vorverarbeitung
Als erstes erstellt MTCNN mehrere Größen unseres Fotos.
MTCNN versucht, Gesichter innerhalb eines Quadrats mit fester Größe in jedem Foto zu erkennen. Wenn Sie diese Erkennung für dasselbe Foto in verschiedenen Größen verwenden, erhöhen sich unsere Chancen, alle Gesichter auf dem Foto korrekt zu erkennen.

Ein Gesicht wird möglicherweise nicht in einer normalen Bildgröße erkannt, aber es kann in einem Bild anderer Größe in einem Quadrat fester Größe erkannt werden. Dieser Schritt wird algorithmisch ohne ein neuronales Netzwerk ausgeführt.
Schritt 2: P-Net
Nachdem wir verschiedene Kopien unseres Fotos erstellt haben, kommt das erste neuronale Netzwerk, P-Net, ins Spiel. Dieses Netzwerk verwendet einen 12x12-Kernel (Block), der alle Fotos (Kopien desselben Fotos, aber unterschiedlicher Größe) ab der oberen linken Ecke scannt und sich mit einem 2-Pixel-Schritt entlang des Bildes bewegt.

Nach dem Scannen aller Bilder unterschiedlicher Größe standardisiert MTCNN jedes Foto erneut und berechnet die Blockkoordinaten neu.
Das P-Net gibt die Koordinaten der Blöcke und die Konfidenzniveaus (wie genau diese Fläche ist) relativ zu der Fläche an, die sie für jeden Block enthält. Mit dem Schwellenwertparameter können Sie Blöcke mit einem bestimmten Vertrauensniveau verlassen.
Gleichzeitig können wir nicht einfach die Blöcke mit dem maximalen Vertrauensniveau auswählen, da das Bild mehrere Gesichter enthalten kann.
Wenn ein Block einen anderen überlappt und fast denselben Bereich abdeckt, wird dieser Block entfernt. Dieser Parameter kann während der Netzwerkinitialisierung gesteuert werden.

In diesem Beispiel wird der gelbe Block entfernt. Grundsätzlich ist das Ergebnis des P-Net Blöcke mit geringer Genauigkeit. Das folgende Beispiel zeigt die tatsächlichen Ergebnisse von P-Net:

Schritt 3: R-Net
R-Net führt eine Auswahl der am besten geeigneten Blöcke durch, die als Ergebnis der Arbeit von P-Net gebildet wurden, bei dem es sich höchstwahrscheinlich um eine Person in der Gruppe handelt. R-Net hat eine ähnliche Architektur wie P-Net. In diesem Stadium werden vollständig verbundene Schichten gebildet. Die Ausgabe von R-Net ähnelt auch der Ausgabe von P-Net.

Schritt 4: O-Net
Das O-Net-Netzwerk ist der letzte Teil des MTCNN-Netzwerks. Zusätzlich zu den letzten beiden Netzwerken bildet es fünf Punkte für jedes Gesicht (Augen, Nase, Lippenwinkel). Wenn diese Punkte vollständig in den Block fallen, wird festgestellt, dass sie die Person am wahrscheinlichsten enthalten. Zusätzliche Punkte sind blau markiert:

Als Ergebnis erhalten wir einen letzten Block, der die Genauigkeit der Tatsache anzeigt, dass dies ein Gesicht ist. Wenn das Gesicht nicht gefunden wird, erhalten wir die Anzahl der Gesichtsblöcke auf Null.
Die Verarbeitung von 1000 Fotos durch ein solches Netzwerk auf unserem Server dauert durchschnittlich 6 Minuten.
Wir haben dieses neuronale Netzwerk wiederholt bei Überprüfungen verwendet und es hat uns geholfen, Anomalien auf den Fotos unserer Kunden automatisch zu identifizieren.
In Bezug auf die Verwendung von FaceNet möchte ich hinzufügen, dass, wenn Sie anstelle von Mona Lisa Rembrandts Leinwände analysieren, die Ergebnisse in etwa dem folgenden Bild entsprechen und Sie die gesamte Liste der identifizierten Personen analysieren müssen:

Fazit
Diese Hypothesen und Testansätze zeigen, dass Sie mit absolut jedem Datensatz interessante Tests durchführen und nach Anomalien suchen können. Heutzutage versuchen viele Auditoren, ähnliche Praktiken zu entwickeln, deshalb wollte ich praktische Beispiele für die Verwendung von Computer Vision und maschinellem Lernen zeigen.
Ich möchte auch hinzufügen, dass wir die Gesichtserkennung als nächste Hypothese für Tests angesehen haben, aber bisher bieten die Daten und Prozessspezifikationen keine vernünftige Grundlage für die Verwendung dieser Technologie in unseren Tests.
Im Allgemeinen ist dies alles, was ich Ihnen über unsere Art beim Testen von Fotos erzählen möchte.
Ich wünsche Ihnen gute Analysen und beschriftete Daten!
* Der Beispielcode stammt aus Open Source.