Teil 2
In diesem Artikel erfahren Sie:
- Über ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
- Über welche CNN-Architekturen gibt es:
- LeNet-5
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- Über welche Probleme mit neuen Netzwerkarchitekturen aufgetreten ist, wie sie durch nachfolgende gelöst wurden:
- verschwindendes Gradientenproblem
- explodierendes Gradientenproblem
ILSVRC
Die ImageNet Large Scale Visual Recognition Challenge ist ein jährlicher Wettbewerb, bei dem Forscher ihre Gitter zur Objekterkennung und -klassifizierung in Fotografien vergleichen.
Dieser Wettbewerb war der Anstoß für die Entwicklung von:
- Neuronalen Netzwerkarchitekturen
- persönlichen Methoden und Praktiken, die bis heute verwendet werden. Diese
Grafik zeigt, wie sich die Klassifizierungsalgorithmen im Laufe der Zeit entwickelt haben:
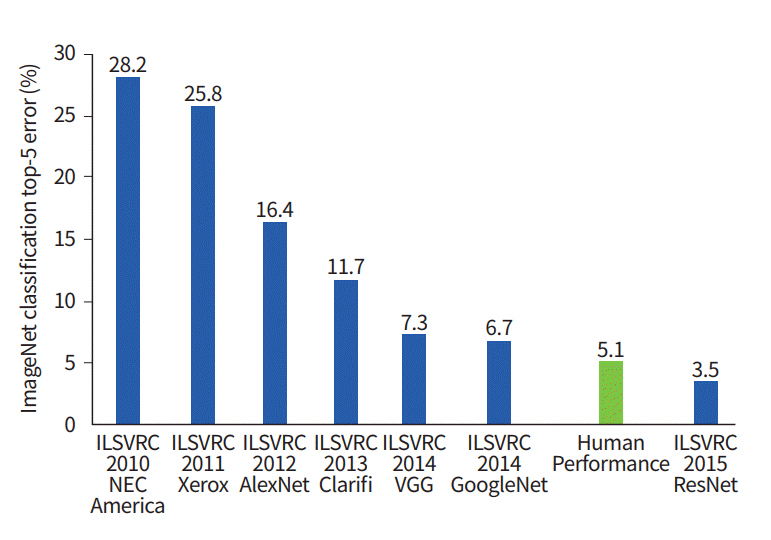
Auf der x-Achse - Jahre und Algorithmen (seit 2012 - Faltungsneural Netzwerk).
Die y-Achse ist der Prozentsatz der Fehler in der Stichprobe aus den Top-5-Fehlern.
Der Top-5-Fehler ist eine Methode zur Bewertung des Modells: Das Modell gibt eine bestimmte Wahrscheinlichkeitsverteilung zurück. Wenn unter den Top-5-Wahrscheinlichkeiten ein wahrer Wert (Klassenbezeichnung) der Klasse vorhanden ist, wird die Antwort des Modells als korrekt angesehen. Dementsprechend ist (1 - Top-1-Fehler) die bekannte Genauigkeit.
CNN-Architekturen
LeNet-5
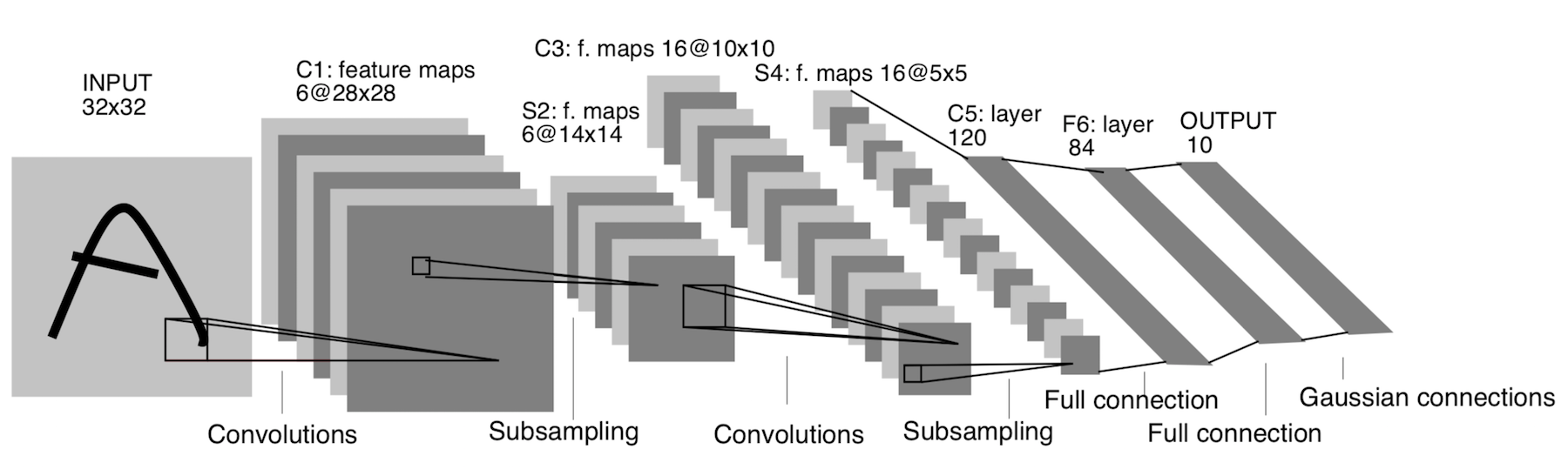
Es erschien bereits 1998! Es wurde entwickelt, um handgeschriebene Buchstaben und Zahlen zu erkennen. Unterabtastung bezieht sich hier auf die Pooling-Schicht.
Architektur:
CONV 5x5, Schritt = 1
POOL 2x2, Schritt = 2
CONV 5x5, Schritt = 1
POOL 5x5, Schritt = 2
FC (120, 84)
FC (84, 10)
Jetzt hat diese Architektur nur noch historische Bedeutung. Diese Architektur lässt sich in jedem modernen Deep-Learning-Framework einfach von Hand implementieren.
AlexNet

Das Bild wird nicht dupliziert. So wird die Architektur dargestellt, da die AlexNet-Architektur zu diesem Zeitpunkt nicht auf ein GPU-Gerät passte, sodass "die Hälfte" des Netzwerks auf einer GPU und die andere auf der anderen ausgeführt wurde.
Es erschien im Jahr 2012. Ein Durchbruch in diesem ILSVRC begann mit ihr - sie besiegte alle hochmodernen Modelle dieser Zeit. Danach wurde den Leuten klar, dass neuronale Netze wirklich funktionieren :)
Architektur genauer:

Wenn Sie sich die AlexNet-Architektur genau ansehen, können Sie feststellen, dass seit 14 Jahren (seit dem Erscheinen von LeNet-5) fast keine Änderungen vorgenommen wurden, mit Ausnahme der Anzahl der Ebenen.
Wichtig:
- Wir nehmen unser ursprüngliches 227x227x3-Bild und verringern seine Abmessung (in Höhe und Breite), erhöhen jedoch die Anzahl der Kanäle. Dieser Teil der Architektur "codiert" die ursprüngliche Darstellung des Objekts (Encoder).
- ReLU. ReLu .
- 60 .
- .
:
- Local Response Norm — , . batch-normalization.
- - , — - FLOPs, .
- FC 4096 , (Fully-connected) 4096 .
- Max Pool 3x3s2 , 3x3, = 2.
- Ein Datensatz wie Conv 11x11s4, 96 bedeutet, dass die Faltungsschicht einen 11x11xNc-Filter hat, Schritt = 4, die Anzahl solcher Filter ist 96. Jetzt ist die Anzahl solcher Filter die Anzahl der Kanäle für die nächste Schicht (der gleiche Nc). Wir nehmen an, dass das Ausgangsbild drei Kanäle hat (R, G und B).
VGGNet
Architektur:
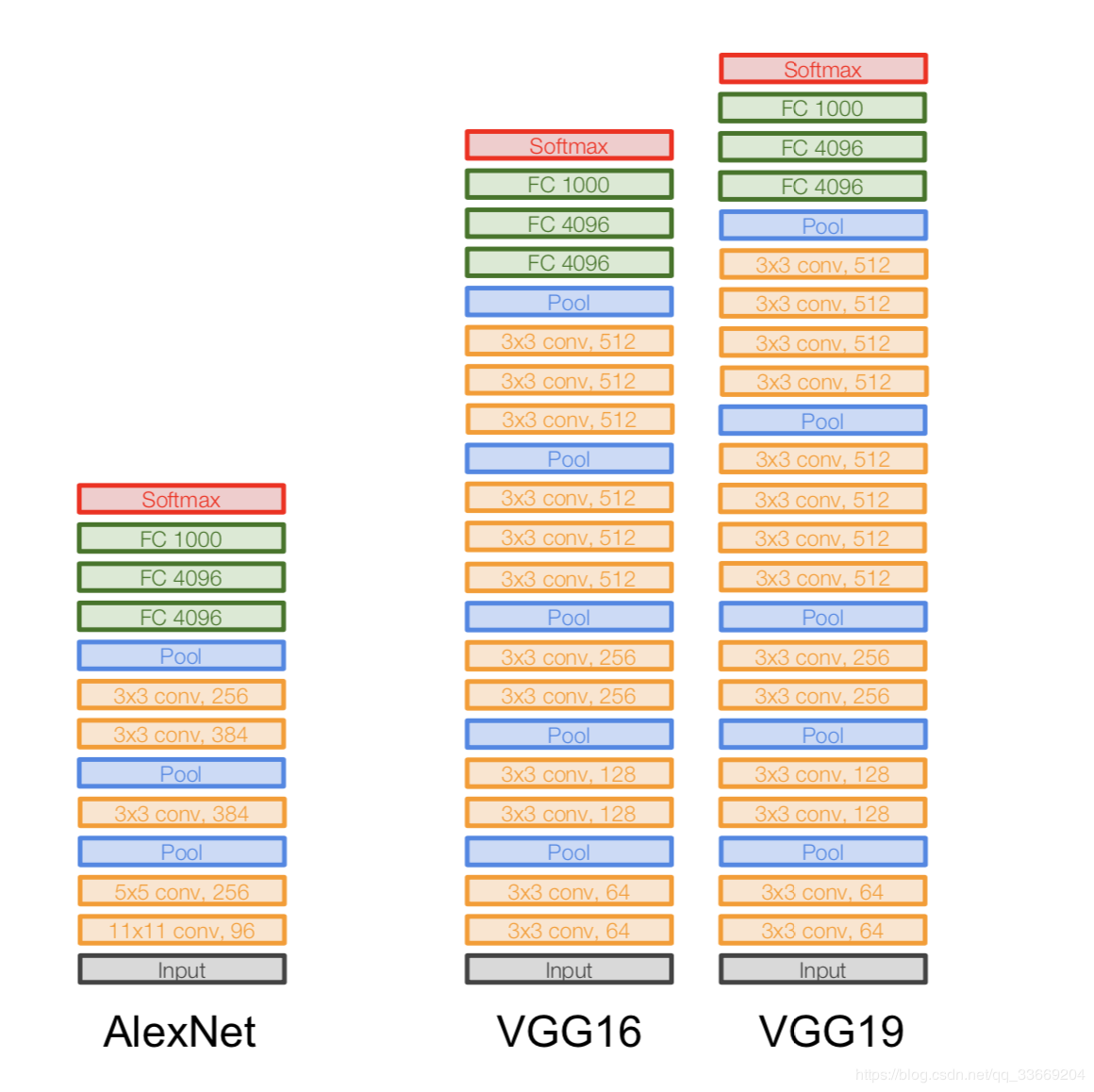
Eingeführt im Jahr 2014.
Zwei Versionen - VGG16 und VGG19. Die Hauptidee ist, kleine (3x3) anstelle von großen (11x11 und 5x5) zu verwenden. Die Intuition für die Verwendung großer Windungen ist einfach - wir möchten mehr Informationen von benachbarten Pixeln erhalten, aber es ist viel besser, kleine Filter häufiger zu verwenden .
Und deshalb:
- . , . .. , , .
- => .
- — , — , — , .
Wichtig:
- Beim Trainieren eines neuronalen Netzwerks für einen Fehler-Backpropagation-Algorithmus ist es wichtig, die Objektdarstellungen (für uns das Originalbild) in allen Phasen (Windungen, Pools) der Vorwärtsausbreitung beizubehalten (Vorwärtsdurchlauf ist, wenn wir das Bild der Eingabe zuführen und zur Ausgabe bewegen). zum Ergebnis). Diese Darstellung eines Objekts kann speicherintensiv sein. Schauen
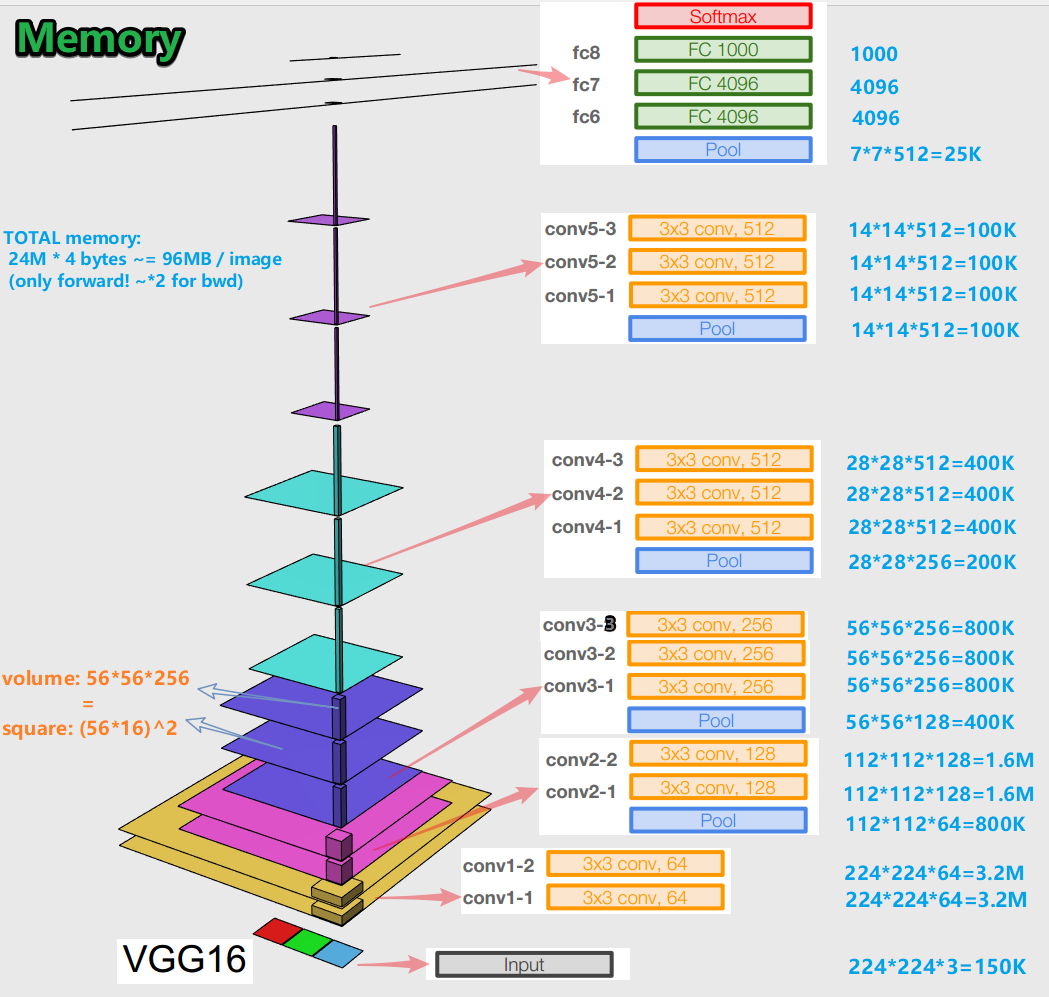
Sie mal rein: Es stellt sich heraus, dass es ungefähr 96 MB pro Bild sind - und das nur für den Vorwärtsdurchlauf. Für den Rückwärtsdurchlauf (bwd im Bild) - während der Berechnung der Gradienten - etwa doppelt so viel. Ein interessantes Bild ergibt sich: Die größte Anzahl trainierter Parameter befindet sich in vollständig verbundenen Schichten, und der größte Speicher wird von Objektdarstellungen nach Faltungs- und Poolschichten belegt . C - Synergie.
- Das Netzwerk verfügt über 138 Millionen Trainingsparameter in 16 Schichten und 143 Millionen Parameter in 19 Schichten.
GoogLeNet
Architektur:
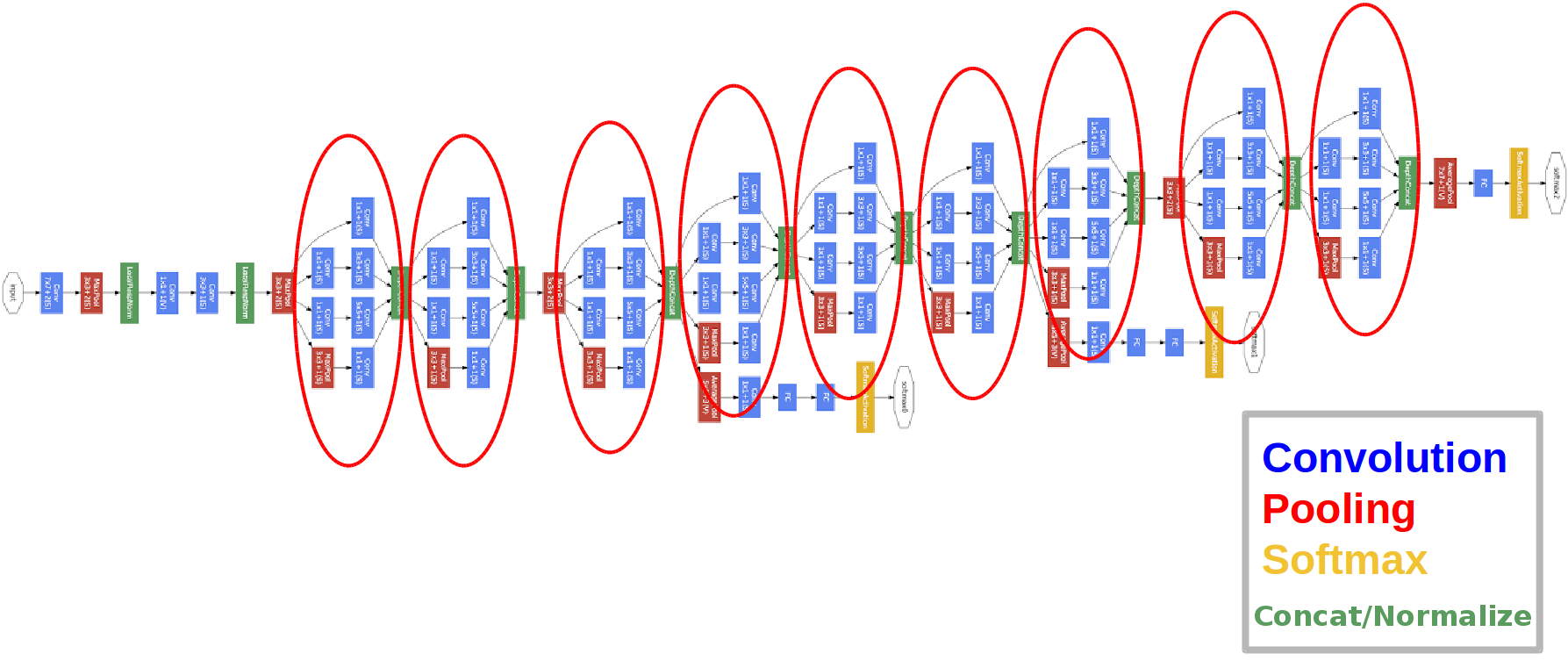
Eingeführt im Jahr 2014.
Die roten Kreise sind das sogenannte Inception-Modul.
Schauen wir uns das genauer an:
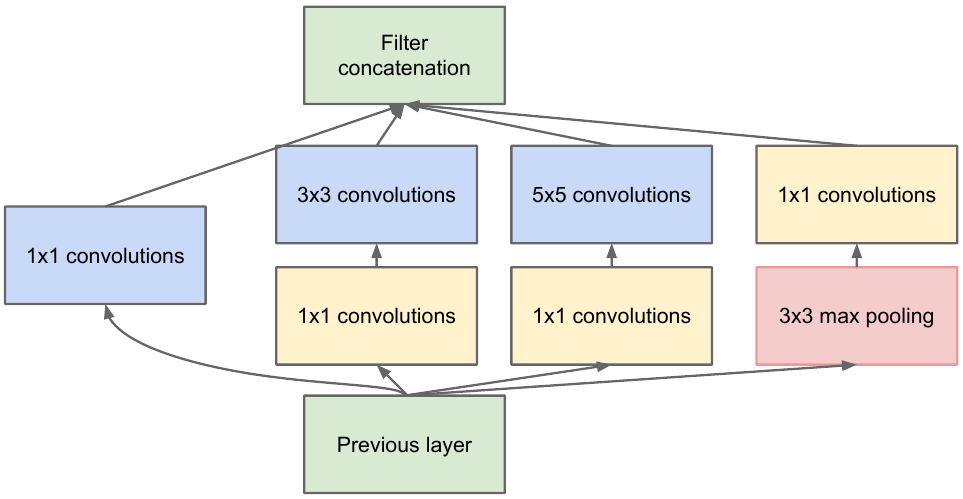
Wir nehmen eine Feature-Map aus dem vorherigen Layer, wenden eine Reihe von Windungen mit verschiedenen Filtern darauf an und verketten dann die resultierende. Die Intuition ist einfach: Wir möchten verschiedene Darstellungen unserer Feature-Map mit Filtern unterschiedlicher Größe erhalten. Die Faltungen 1x1 werden verwendet, um die Anzahl der Kanäle nach jedem solchen Anfangsblock nicht so stark zu erhöhen. Jene. Wenn die Feature-Map eine große Anzahl von Kanälen hat und diese Anzahl reduziert werden soll, ohne die Höhe und Breite der Feature-Map zu ändern, verwenden Sie die 1x1-Faltung.
Es gibt auch drei Klassifikatorblöcke im Netzwerk, so sieht einer von ihnen aus (der für uns rechts):

Bei dieser Konstruktion reicht der Gradient "besser" während der Rückausbreitung des Fehlers von den Ausgangsschichten zu den Eingangsschichten.
Warum benötigen wir zwei zusätzliche Netzwerkausgänge? Es geht um das sogenannte Problem des verschwindenden Gradienten :
Unter dem Strich tendiert der Gradient bei der Rückausbreitung eines Fehlers dazu, trivial gegen Null zu gehen. Je tiefer das Netzwerk ist, desto anfälliger ist es für dieses Phänomen. Warum passiert es? Wenn wir rückwärts gehen, gehen wir von Ausgabe zu Eingabe und berechnen die Gradienten komplexer Funktionen. Ableitung einer komplexen Funktion ( Kettenregel) Ist in der Tat Multiplikation. Wenn wir also einige Werte auf dem Weg von der Ausgabe zur Eingabe multiplizieren, treffen wir auf Zahlen nahe Null, und infolgedessen werden die Gewichte des neuronalen Netzwerks praktisch nicht aktualisiert. Dies ist teilweise ein Problem bei Sigmoid-Aktivierungsfunktionen, die einen festen Ausgabebereich haben. Nun, dieses Problem wird teilweise durch die Verwendung der ReLu-Aktivierungsfunktion gelöst. Warum teilweise? Weil niemand Garantien für die Werte der trainierten Parameter und die Darstellung des Eingabeobjekts in allen Feature-Maps gibt.
Wichtig:
- Das Netzwerk hat 22 Schichten (dies ist etwas mehr als das vorherige Netzwerk).
- Die Anzahl der trainierten Parameter beträgt fünf Millionen und ist damit um ein Vielfaches geringer als in den beiden vorherigen Netzwerken.
- Das Aussehen des 1x1-Bundles.
- Inception-Blöcke werden verwendet.
- Anstelle von vollständig verbundenen Ebenen werden jetzt 1x1-Windungen verwendet, die die Tiefe und damit die Dimension vollständig verbundener Ebenen und das sogenannte globale Avegare-Pooling verringern (mehr dazu hier ).
- Die Architektur hat 3 Ausgänge (die endgültige Antwort wird abgewogen).
ResNet
Architektur (ResNet-34-Variante): Eingeführt
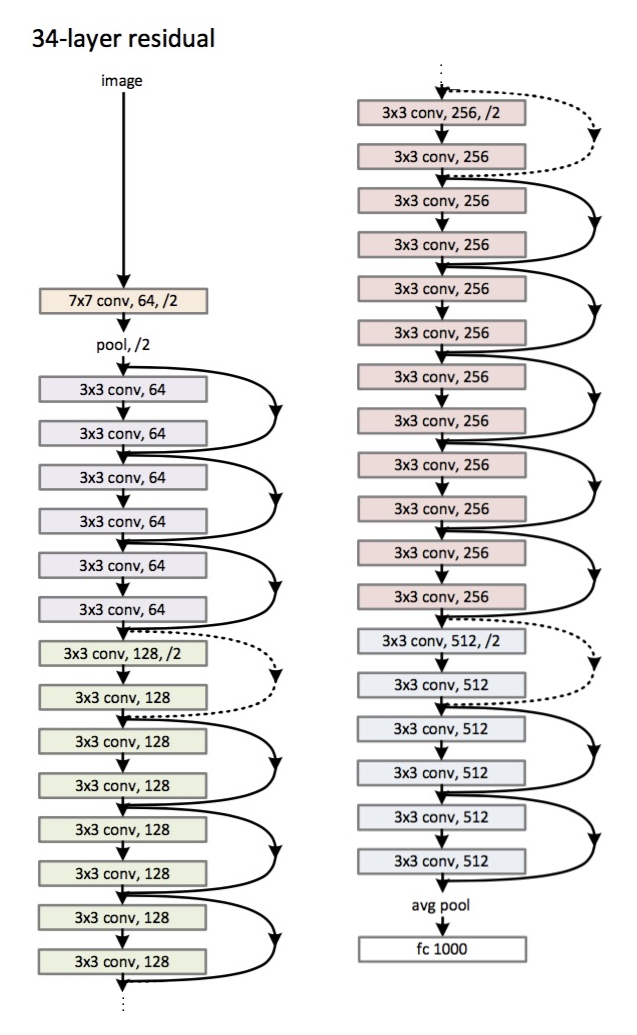
im Jahr 2015.
Die Hauptinnovation ist eine große Anzahl von Schichten und die sogenannten Restblöcke. Diese Blöcke werden verwendet, um das Problem des Fading-Gradienten zu bekämpfen. Die Verbindung zwischen solchen Restblöcken wird als Verknüpfung bezeichnet (Pfeile im Bild). Mit diesen Verknüpfungen erreicht der Gradient nun alle erforderlichen Parameter und trainiert so das Netzwerk :)
Wichtig:
- Anstelle von vollständig verbundenen Schichten - durchschnittliches globales Pooling.
- Restblöcke.
- Das Netzwerk hat die Menschen bei der Erkennung von Bildern im ImageNet-Datensatz übertroffen (Top-5-Fehler).
- Zum ersten Mal wurde eine Chargennormalisierung verwendet.
- Die Technik der Initialisierung von Gewichten wird verwendet (Intuition: Ab einer bestimmten Initialisierung von Gewichten konvergiert (lernt) das Netzwerk schneller und besser).
- Die maximale Tiefe beträgt 152 Schichten!
Ein kleiner Exkurs
Das Problem des Fading-Gradienten ist für alle tiefen neuronalen Netze relevant .
Es gibt auch seinen Antagonisten - das explodierende Gradientenproblem, das auch für alle tiefen neuronalen Netze relevant ist. Das Endergebnis ergibt sich aus dem Namen - der Gradient wird zu groß, was zu NaN führt (keine Zahl, unendlich). Die Lösung liegt auf der Hand - ansonsten den Wert des Gradienten zu begrenzen - seinen Wert zu verringern (normalisieren). Diese Technik wird als "Clipping" bezeichnet.
Fazit
Im Jahr 2019 erschien ein Artikel über eine neue Architekturfamilie - EfficientNet.
Ich empfehle den neuesten Trends in verschiedenen Aufgaben und Bereichen Maschinelles Lernen mit Bezug zu folgen hier . In dieser Ressource können Sie eine Aufgabe (z. B. Bildklassifizierung) und ein Dataset (z. B. ImageNet) auswählen und die Qualität bestimmter Architekturen sowie zusätzliche Informationen dazu anzeigen. Beispielsweise nimmt das FixEfficientNet-L2-Raster den ersten Platz bei der Bildklassifizierung im ImageNet-Dataset ein (Top-1-Genauigkeit).
In den nächsten Artikeln werden wir über Transferlernen, Objekterkennung und Segmentierung sprechen.