Wenn auf einem der Tausenden von kontrollierten Servern ein abnormaler Ressourcenverbrauch (CPU, Speicher, Festplatte, Netzwerk usw.) auftritt, muss daher herausgefunden werden, "wer schuld ist und was zu tun ist".
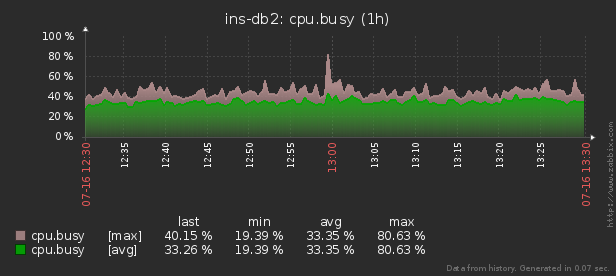
Es gibt ein pidstat-Dienstprogramm zur Echtzeitüberwachung der Ressourcennutzung des Linux-Servers "im Moment" . Das heißt, wenn die Lastspitzen periodisch sind, können sie direkt in der Konsole "schraffiert" werden. Wir möchten diese Daten jedoch nachträglich analysieren und versuchen, den Prozess zu finden, der die maximale Belastung der Ressourcen verursacht hat.
Das heißt, ich möchte in der Lage sein, zuvor gesammelte Daten in verschiedenen schönen Berichten mit Gruppierung und Detaillierung in einem Intervall wie diesem zu betrachten:
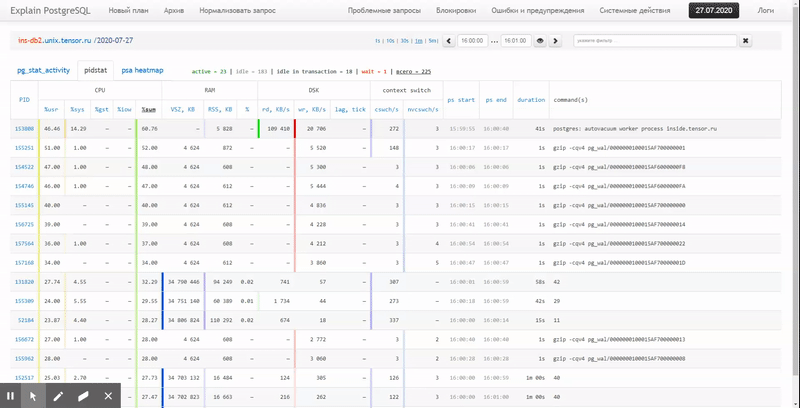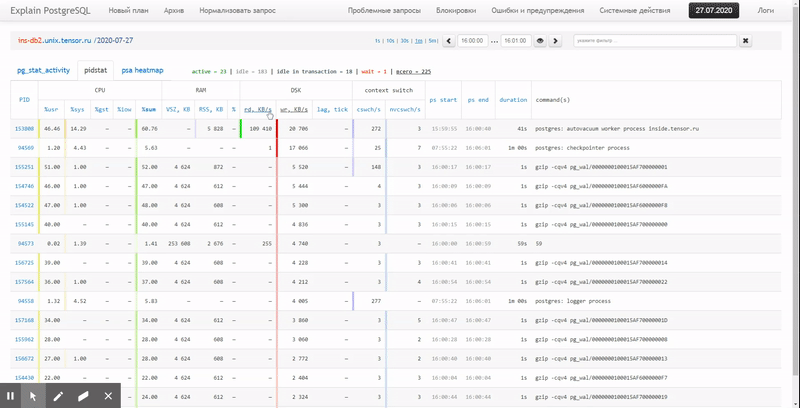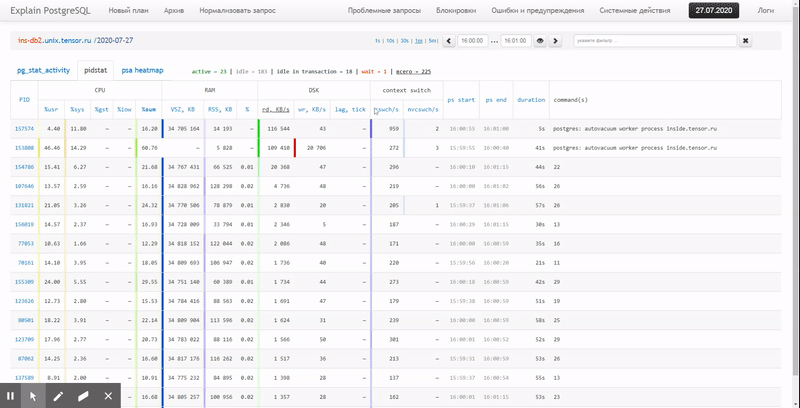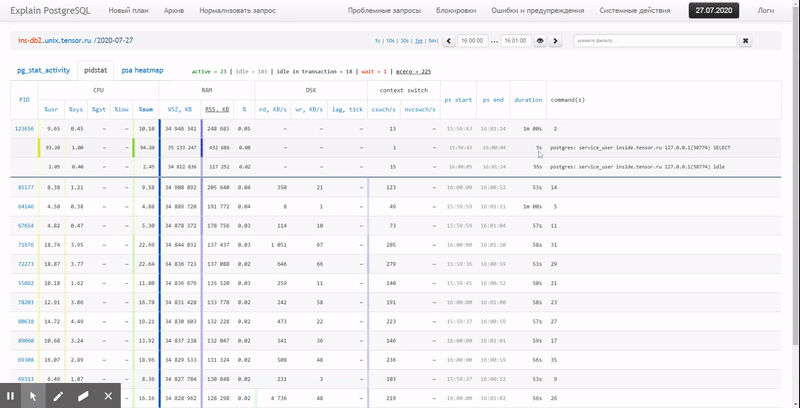
In diesem Artikel werden wir untersuchen, wie all dies wirtschaftlich in der Datenbank gespeichert werden kann und wie ein Bericht aus diesen Daten mithilfe von Fensterfunktionen und am effektivsten gesammelt werden kann GRUPPENSÄTZE .
Lassen Sie uns zunächst sehen, welche Art von Daten wir extrahieren können, wenn wir "alles maximal" nehmen:
pidstat -rudw -lh 1| Zeit | UID | PID | % usr | % System | % Gast | % ZENTRALPROZESSOR | Zentralprozessor | minflt / s | Majflt / s | VSZ | Rss | % MEM | kB_rd / s | kB_wr / s | kB_ccwr / s | cswch / s | nvcswch / s | Befehl |
| 1594893415 | 0 | 1 | 0,00 | 13.08 | 0,00 | 13.08 | 52 | 0,00 | 0,00 | 197312 | 8512 | 0,00 | 0,00 | 0,00 | 0,00 | 0,00 | 7.48 | / usr / lib / systemd / systemd --switched-root --system --deserialize 21 |
| 1594893415 | 0 | neun | 0,00 | 0,93 | 0,00 | 0,93 | 40 | 0,00 | 0,00 | 0 | 0 | 0,00 | 0,00 | 0,00 | 0,00 | 350,47 | 0,00 | rcu_sched |
| 1594893415 | 0 | dreizehn | 0,00 | 0,00 | 0,00 | 0,00 | 1 | 0,00 | 0,00 | 0 | 0 | 0,00 | 0,00 | 0,00 | 0,00 | 1,87 | 0,00 | Migration / 11.87 |
Alle diese Werte sind in mehrere Klassen unterteilt. Einige von ihnen ändern sich ständig (CPU- und Festplattenaktivität), andere selten (Speicherzuordnung), und Command ändert sich nicht nur selten innerhalb desselben Prozesses, sondern wiederholt sich auch regelmäßig auf verschiedenen PIDs.
Grundstruktur
Der Einfachheit halber beschränken wir uns auf eine Metrik für jede "Klasse", die wir speichern:% CPU, RSS und Command.
Da wir im Voraus wissen, dass der Befehl regelmäßig wiederholt wird, verschieben wir ihn einfach in ein separates Tabellenwörterbuch, in dem der MD5-Hash als UUID-Schlüssel fungiert:
CREATE TABLE diccmd(
cmd
uuid
PRIMARY KEY
, data
varchar
);Und für die Daten selbst ist eine Tabelle des folgenden Typs für uns geeignet:
CREATE TABLE pidstat(
host
uuid
, tm
integer
, pid
integer
, cpu
smallint
, rss
bigint
, cmd
uuid
);Lassen Sie mich Ihre Aufmerksamkeit auf die Tatsache lenken, dass% CPU immer mit einer Genauigkeit von 2 Dezimalstellen zu uns kommt und 100,00 sicherlich nicht überschreitet. Dann können wir es einfach mit 100 multiplizieren und eingeben
smallint. Dies erspart uns einerseits die Probleme der Abrechnungsgenauigkeit während des Betriebs, andererseits ist es immer noch besser, nur 2 Bytes im Vergleich zu 4 Bytes realoder 8 Bytes zu speichern double precision.
Weitere Informationen zum effizienten Packen von Datensätzen im PostgreSQL-Speicher finden Sie im Artikel "Sparen Sie einen schönen Cent bei großen Volumes" und zum Erhöhen des Datenbankdurchsatzes beim Schreiben - unter "Schreiben im Sublight: 1 Host, 1 Tag, 1 TB" .
"Freie" Speicherung von NULL-Werten
Um die Leistung des Festplattensubsystems unserer Datenbank und die Größe der Datenbank zu speichern, werden wir versuchen, so viele Daten wie möglich in Form von NULL darzustellen - ihr Speicher ist praktisch "frei", da er nur ein bisschen im Datensatzheader benötigt.
Weitere Informationen zur internen Mechanik der Darstellung von Datensätzen in PostgreSQL finden Sie in Nikolai Shaplovs Vortrag auf der PGConf.Russia 2016 "Was drin ist: Datenspeicherung auf niedriger Ebene . " Folie 16 ist dem NULL-Speicher gewidmet .Schauen wir uns die Arten unserer Daten genauer an:
- CPU / DSK
ändert sich ständig, wird aber sehr oft auf Null gesetzt. Daher ist es vorteilhaft, NULL anstelle von 0 in die Basis zu schreiben . - RSS / CMD Es
ändert sich ziemlich selten - daher schreiben wir NULL anstelle von Wiederholungen innerhalb derselben PID.
Es stellt sich ein Bild wie dieses heraus, wenn Sie es im Kontext einer bestimmten PID betrachten:

Es ist klar, dass, wenn unser Prozess beginnt, einen anderen Befehl auszuführen, der Wert des verwendeten Speichers wahrscheinlich auch anders sein wird als zuvor - daher sind wir uns einig, dass beim Ändern von CMD auch der Wert von RSS sein wird Fix unabhängig vom vorherigen Wert.
Das heißt , ein Eintrag mit einem gefüllten CMD-Wert hat auch einen RSS-Wert . Erinnern wir uns an diesen Moment, er wird uns immer noch nützlich sein.
Einen schönen Bericht zusammenstellen
Stellen wir nun eine Abfrage zusammen, die uns die Ressourcenkonsumenten eines bestimmten Hosts in einem bestimmten Zeitintervall anzeigt.
Aber machen wir es gleich mit minimalem Ressourcenverbrauch - ähnlich dem Artikel über SELF JOIN und Fensterfunktionen .
Eingehende Parameter verwenden
Um die Werte der Berichtsparameter (oder $ 1 / $ 2) während der SQL-Abfrage nicht an mehreren Stellen anzugeben, wählen wir den CTE aus dem einzigen json-Feld aus, in dem sich diese Parameter durch Schlüssel befinden:
--
WITH args AS (
SELECT
json_object(
ARRAY[
'dtb'
, extract('epoch' from '2020-07-16 10:00'::timestamp(0)) -- timestamp integer
, 'dte'
, extract('epoch' from '2020-07-16 10:01'::timestamp(0))
, 'host'
, 'e828a54d-7e8a-43dd-b213-30c3201a6d8e' -- uuid
]::text[]
)
)
Rohdaten abrufen
Da wir keine komplexen Aggregate erfunden haben, besteht die einzige Möglichkeit, die Daten zu analysieren, darin, sie zu lesen. Dafür brauchen wir einen offensichtlichen Index:
CREATE INDEX ON pidstat(host, tm);-- ""
, src AS (
SELECT
*
FROM
pidstat
WHERE
host = ((TABLE args) ->> 'host')::uuid AND
tm >= ((TABLE args) ->> 'dtb')::integer AND
tm < ((TABLE args) ->> 'dte')::integer
)
Gruppierung der Analyseschlüssel
Bestimmen Sie für jede gefundene PID das Intervall ihrer Aktivität und entnehmen Sie die CMD dem ersten Datensatz in diesem Intervall.
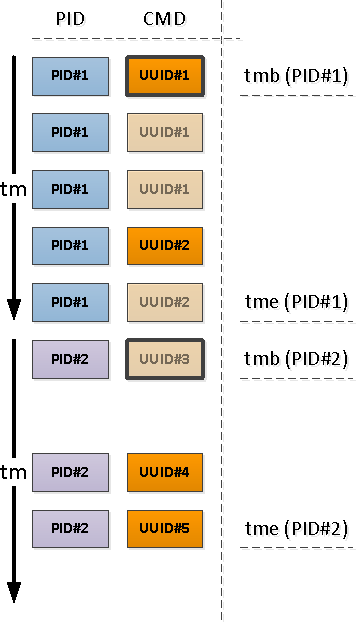
Zu diesem Zweck verwenden wir die
DISTINCT ONFunktionen " Uniqueization Through" und "Window":
--
, pidtm AS (
SELECT DISTINCT ON(pid)
host
, pid
, cmd
, min(tm) OVER(w) tmb --
, max(tm) OVER(w) tme --
FROM
src
WINDOW
w AS(PARTITION BY pid)
ORDER BY
pid
, tm
)
Prozessaktivitätsgrenzen
Beachten Sie, dass der erste Datensatz in Bezug auf den Beginn unseres Intervalls entweder ein Datensatz sein kann, der bereits ein gefülltes CMD-Feld enthält (PID Nr. 1 im obigen Bild), oder mit NULL, was die Fortsetzung des gefüllten Werts „oben“ in der Chronologie anzeigt (PID Nr. 2) ).
Diejenigen der PIDs, die aufgrund der vorherigen Operation ohne CMD belassen wurden, begannen früher als zu Beginn unseres Intervalls, was bedeutet, dass diese "Anfänge" gefunden werden müssen:

Da wir sicher wissen, dass das nächste Aktivitätssegment mit einem gefüllten CMD-Wert beginnt (und es gibt einen gefüllten RSS, was bedeutet ) hilft uns der bedingte Index hier:
CREATE INDEX ON pidstat(host, pid, tm DESC) WHERE cmd IS NOT NULL;-- ""
, precmd AS (
SELECT
t.host
, t.pid
, c.tm
, c.rss
, c.cmd
FROM
pidtm t
, LATERAL(
SELECT
*
FROM
pidstat -- , SELF JOIN
WHERE
(host, pid) = (t.host, t.pid) AND
tm < t.tmb AND
cmd IS NOT NULL --
ORDER BY
tm DESC
LIMIT 1
) c
WHERE
t.cmd IS NULL -- ""
)
Wenn wir die Endzeit der Segmentaktivität kennen wollen (und wollen), müssen wir für jede PID eine "Zwei-Wege-Methode" verwenden, um die Untergrenze zu bestimmen.
Wir haben bereits eine ähnliche Technik in PostgreSQL Antipatterns verwendet: Navigieren in der Registrierung .

--
, pstcmd AS (
SELECT
host
, pid
, c.tm
, NULL::bigint rss
, NULL::uuid cmd
FROM
pidtm t
, LATERAL(
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
tm < coalesce((
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
cmd IS NOT NULL
ORDER BY
tm
LIMIT 1
), x'7fffffff'::integer) -- MAX_INT4
ORDER BY
tm DESC
LIMIT 1
) c
)
JSON-Konvertierung von Postformaten
Beachten Sie, dass wir
precmd/pstcmdnur die Felder ausgewählt haben, die sich auf nachfolgende Zeilen auswirken, sowie alle CPU / DSKs, die sich ständig ändern - nein. Daher unterscheidet sich das Format der Datensätze in der Originaltabelle und diesen CTEs für uns. Kein Problem!
- row_to_json - verwandelt jeden Datensatz mit Feldern in ein json-Objekt
- array_agg - sammle alle Einträge in '{...}' :: json []
- array_to_json - Konvertiert Array-from-JSON in JSON-Array '[...]' :: json
- json_populate_recordset - Generiert eine Auswahl einer bestimmten Struktur aus einem JSON-Array
Hier verwenden wir einen einzelnen AnrufWir kleben die gefundenen "Anfänge" und "Enden" in einen gemeinsamen Haufen und ergänzen den ursprünglichen Datensatz:json_populate_recordsetanstelle eines mehrfachen Anrufsjson_populate_record, da dieser manchmal schneller kitschig ist.
--
, uni AS (
TABLE src
UNION ALL
SELECT
*
FROM
json_populate_recordset( --
NULL::pidstat
, (
SELECT
array_to_json(array_agg(row_to_json(t))) --
FROM
(
TABLE precmd
UNION ALL
TABLE pstcmd
) t
)
)
)
Lücken füllen
Verwenden wir das im Artikel "SQL HowTo: Erstellen von Ketten mit Fensterfunktionen" beschriebene Modell .Wählen wir zunächst die "Wiederholungs" -Gruppen aus:
--
, grp AS (
SELECT
*
, count(*) FILTER(WHERE cmd IS NOT NULL) OVER(w) grp -- CMD
, count(*) FILTER(WHERE rss IS NOT NULL) OVER(w) grpm -- RSS
FROM
uni
WINDOW
w AS(PARTITION BY pid ORDER BY tm)
)
Laut CMD und RSS sind die Gruppen außerdem unabhängig voneinander, sodass sie ungefähr so aussehen können:
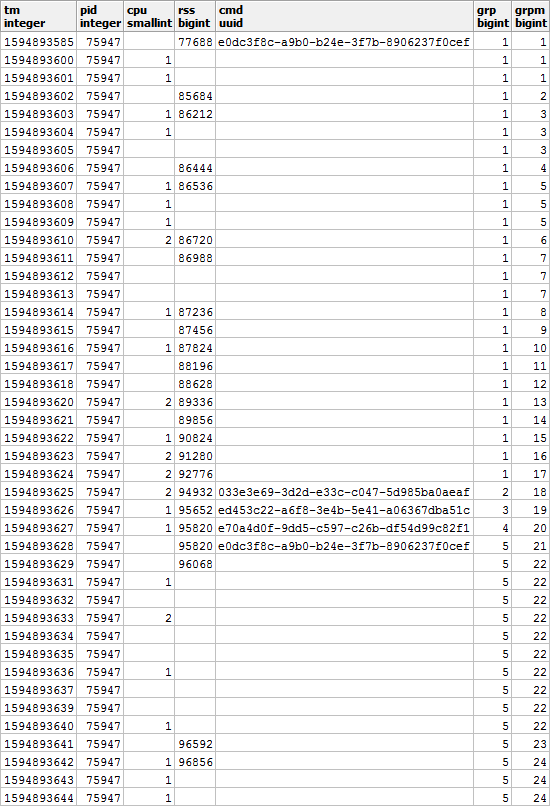
Füllen Sie die Lücken in RSS aus und berechnen Sie die Dauer jedes Segments, um die Lastverteilung über die Zeit korrekt zu berücksichtigen:
--
, rst AS (
SELECT
*
, CASE
WHEN least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) >= greatest(tm, ((TABLE args) ->> 'dtb')::integer) THEN
least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) - greatest(tm, ((TABLE args) ->> 'dtb')::integer) + 1
END gln --
, first_value(rss) OVER(PARTITION BY pid, grpm ORDER BY tm) _rss -- RSS
FROM
grp
WINDOW
w AS(PARTITION BY pid, grp ORDER BY tm)
)
Mehrfachgruppierung mit GRUPPENSÄTZEN
Da wir als Ergebnis sowohl zusammenfassende Informationen für den gesamten Prozess als auch deren Detaillierung nach verschiedenen Aktivitätssegmenten anzeigen möchten , verwenden wir die Gruppierung nach mehreren Schlüsselsätzen gleichzeitig mit GROUPING SETS :
--
, gs AS (
SELECT
pid
, grp
, max(grp) qty -- PID
, (array_agg(cmd ORDER BY tm) FILTER(WHERE cmd IS NOT NULL))[1] cmd -- " "
, sum(cpu) cpu
, avg(_rss)::bigint rss
, min(tm) tmb
, max(tm) tme
, sum(gln) gln
FROM
rst
GROUP BY
GROUPING SETS((pid, grp), pid)
)
Der Anwendungsfall (array_agg(... ORDER BY ..) FILTER(WHERE ...))[1]ermöglicht es uns, den ersten nicht leeren (auch wenn es nicht der allererste ist) Wert aus dem gesamten Satz direkt beim Gruppieren ohne zusätzliche Gesten abzurufen .Die Option, mehrere Abschnitte der Zielstichprobe gleichzeitig abzurufen, ist sehr praktisch, um verschiedene Berichte mit Detaillierung zu erstellen, sodass nicht alle Detaillierungsdaten neu erstellt werden müssen, sondern zusammen mit der Hauptstichprobe in der Benutzeroberfläche angezeigt werden.
Wörterbuch statt JOIN
Erstellen Sie ein CMD "Wörterbuch" für alle gefundenen Segmente:
Weitere Informationen zur "Mastering" -Technik finden Sie im Artikel "PostgreSQL Antipatterns: Lassen Sie uns mit einem Wörterbuch eine schwere Verbindung herstellen" .
-- CMD
, cmdhs AS (
SELECT
json_object(
array_agg(cmd)::text[]
, array_agg(data)
)
FROM
diccmd
WHERE
cmd = ANY(ARRAY(
SELECT DISTINCT
cmd
FROM
gs
WHERE
cmd IS NOT NULL
))
)
Und jetzt verwenden wir es stattdessen
JOIN, um die endgültigen "schönen" Daten zu erhalten:
SELECT
pid
, grp
, CASE
WHEN grp IS NOT NULL THEN -- ""
cmd
END cmd
, (nullif(cpu::numeric / gln, 0))::numeric(32,2) cpu -- CPU ""
, nullif(rss, 0) rss
, tmb --
, tme --
, gln --
, CASE
WHEN grp IS NULL THEN --
qty
END cnt
, CASE
WHEN grp IS NOT NULL THEN
(TABLE cmdhs) ->> cmd::text --
END command
FROM
gs
WHERE
grp IS NOT NULL OR -- ""
qty > 1 --
ORDER BY
pid DESC
, grp NULLS FIRST;

Stellen
wir abschließend sicher, dass sich unsere gesamte Abfrage bei der Ausführung als recht leicht herausstellte: [siehe EXPLAIN.tensor.ru] Es wurden nur 44 ms und 33 MB Daten gelesen!