
Aus architektonischer Sicht müssen für die IoT-Plattform die folgenden Aufgaben gelöst werden:
- Die Menge der empfangenen, empfangenen und verarbeiteten Daten erfordert eine hohe Bandbreite, Speicher- und Rechenleistung.
- Geräte können über ein weites geografisches Gebiet verteilt werden
- Unternehmen müssen ihre Architektur ständig weiterentwickeln, damit den Kunden neue Services angeboten werden können.
Eines der Merkmale der IoT-Plattform ist die Unabhängigkeit zwischen Objekten und Signalen, die parallele Berechnungen ermöglicht und die Produktivität erhöht.
Daten, die von Sensoren stammen, werden aus folgenden Quellen gesammelt: SPS, DCS, Mikrocontroller usw. und können im Zeitbereich gespeichert werden, um Datenverlust aufgrund von Verbindungsproblemen zu vermeiden. Daten können Zeitreihen (Ereignisse), halbstrukturierte Daten (Protokolle und Binärdateien) oder unstrukturierte Daten (Bilder) sein. Zeitreihendaten und Ereignisse werden häufig erfasst (von jeder Sekunde bis zu mehreren Minuten). Sie werden dann über das Netzwerk gesendet und in einem zentralen Datensee und einer Zeitreihendatenbank TSDB gespeichert. Data Lake kann ein Cloud-basiertes, lokales Rechenzentrum oder ein Speicher eines Drittanbieters sein.
Die Daten können sofort mithilfe einer Datenflussanalyse namens "Hot Path" mit einem Regelprüfungsmechanismus verarbeitet werden, der auf einem einfachen oder intelligenten Sollwert basiert. Erweiterte Analysen können digitale Zwillinge, maschinelles Lernen, Deep Learning oder physikbasierte Analysen umfassen. Ein solches System kann eine große Datenmenge (von zehn Minuten bis zu einem Monat) von verschiedenen Sensoren verarbeiten. Diese Daten werden im Zwischenspeicher gespeichert. Diese Analyse wird als "Cold Path" bezeichnet und normalerweise vom Scheduler gestartet oder wenn Daten verfügbar sind und viele Rechenressourcen erfordern. Fortgeschrittene Analysen benötigen häufig zusätzliche Informationen wie das überwachte Fahrzeugmodell und Betriebsattribute, die in der Anlagenregistrierung enthalten sind.Die Anlagenregistrierung enthält Informationen über die Art der Anlage, einschließlich Name, Seriennummer, symbolischer Name, Standort, Betriebsfähigkeiten, die Historie der Teile, aus denen sie besteht, und die Rolle, die sie im Herstellungsprozess spielt. In der Asset-Registrierung können wir eine Liste der Dimensionen jedes Assets, des logischen Namens, der Maßeinheit und des Grenzbereichs speichern. In der Industrie sind diese statischen Informationen für ein korrektes analytisches Modell unerlässlich.In der Industrie sind diese statischen Informationen für ein korrektes analytisches Modell unerlässlich.In der Industrie sind diese statischen Informationen für ein korrektes analytisches Modell unerlässlich.
Gründe für die Entwicklung einer benutzerdefinierten Plattform:
- Kapitalrendite: kleines Budget;
- Technologie: Einsatz von Technologie unabhängig vom Lieferanten;
- Vertraulichkeit der Daten;
- Integration: die Notwendigkeit, einen Integrationsgrad mit einer neuen oder veralteten Plattform zu entwickeln;
- Andere Einschränkungen.
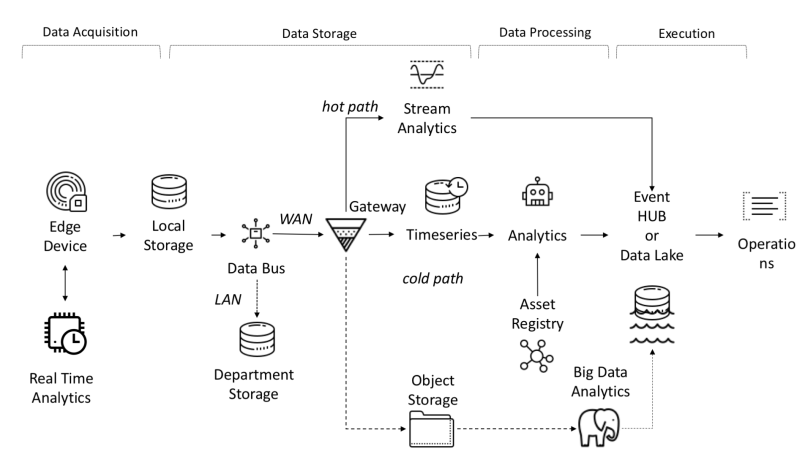
End-to-End-Datenfluss in I-IoT
Beispiel für eine benutzerdefinierte Implementierung der Edge-Plattform
Diese Abbildung zeigt die Implementierung der folgenden Plattformlinks:
- Datenquelle: Als Beispiel wird ein Simatic PLCSIM Advanced-Controllersimulator mit einem aktivierten OPC-Server ausgewählt, wie im vorherigen Artikel beschrieben.
- Als Border Gateway wurde die beliebte Node-Red-Plattform mit dem installierten Node-Red -Contrib-Opcua- Plugin ausgewählt .
- Der MQTT-Broker Mosquitto wird als Dispatcher für die Datenübertragung zwischen anderen Links im Stream verwendet.
- Apache Kafka wird als verteilte Streaming-Plattform verwendet, die als Hot-Path-Analyse mithilfe von Kafka-Streams dient.
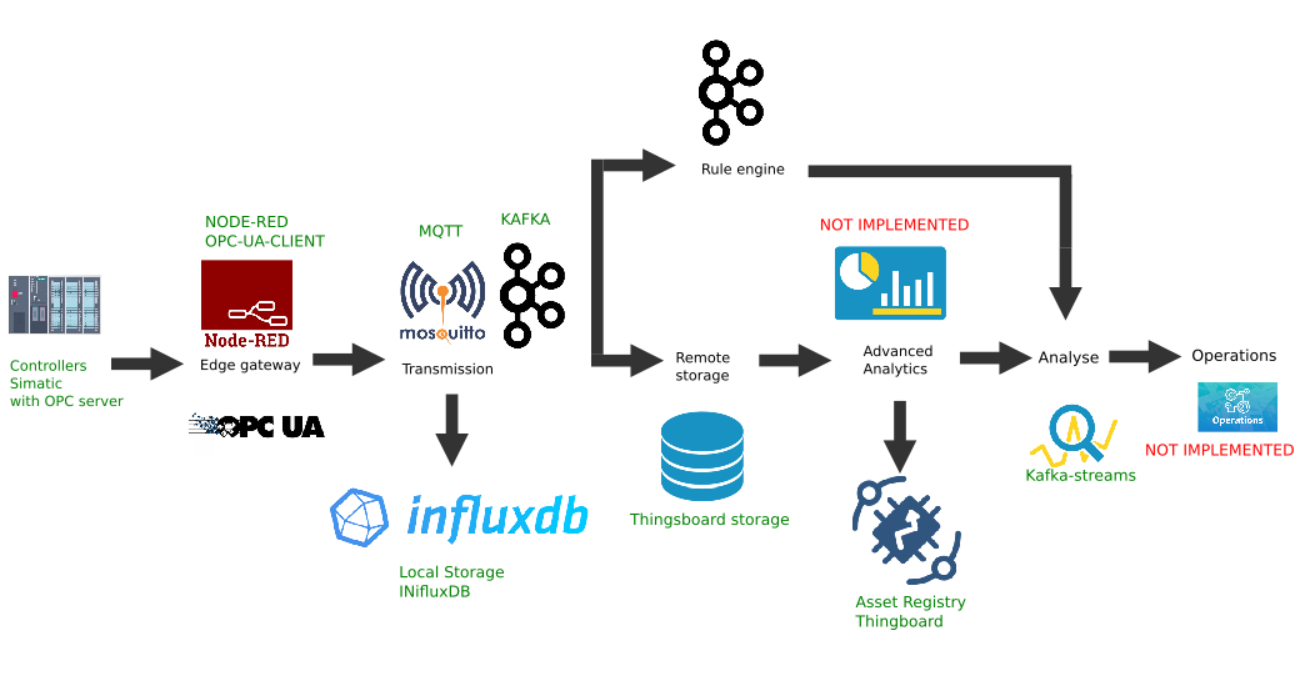
Knotenrotes Edge-Gateway
Als Edge-Computing-Gateway verwenden wir Node-Red, eine einfache benutzerdefinierte Plattform mit vielen verschiedenen Plugins. Die Rolle des Industrial-Adapters spielt das Node-Red-Contrib-Opcua-Plugin. Für die mehrfache Erfassung von Daten vom Controller durch die Abonnementmethode werden die Knoten verwendet: OpcUa-Browser und OpcUa-Client. Im OPC-Browserknoten werden die URL des OPC-Servers (Endpunkt) und das Thema konfiguriert, das den Namespace und den Namen des lesbaren Datenblocks angibt, z. B. ns = 3; s = "HMI_Alarms_Area". Im OPC-Clientknoten wird auch die URL des OPC-Servers angegeben, das ABONNIEREN und das Datenaktualisierungsintervall werden als Aktion festgelegt.
Knotenroter Hauptfluss
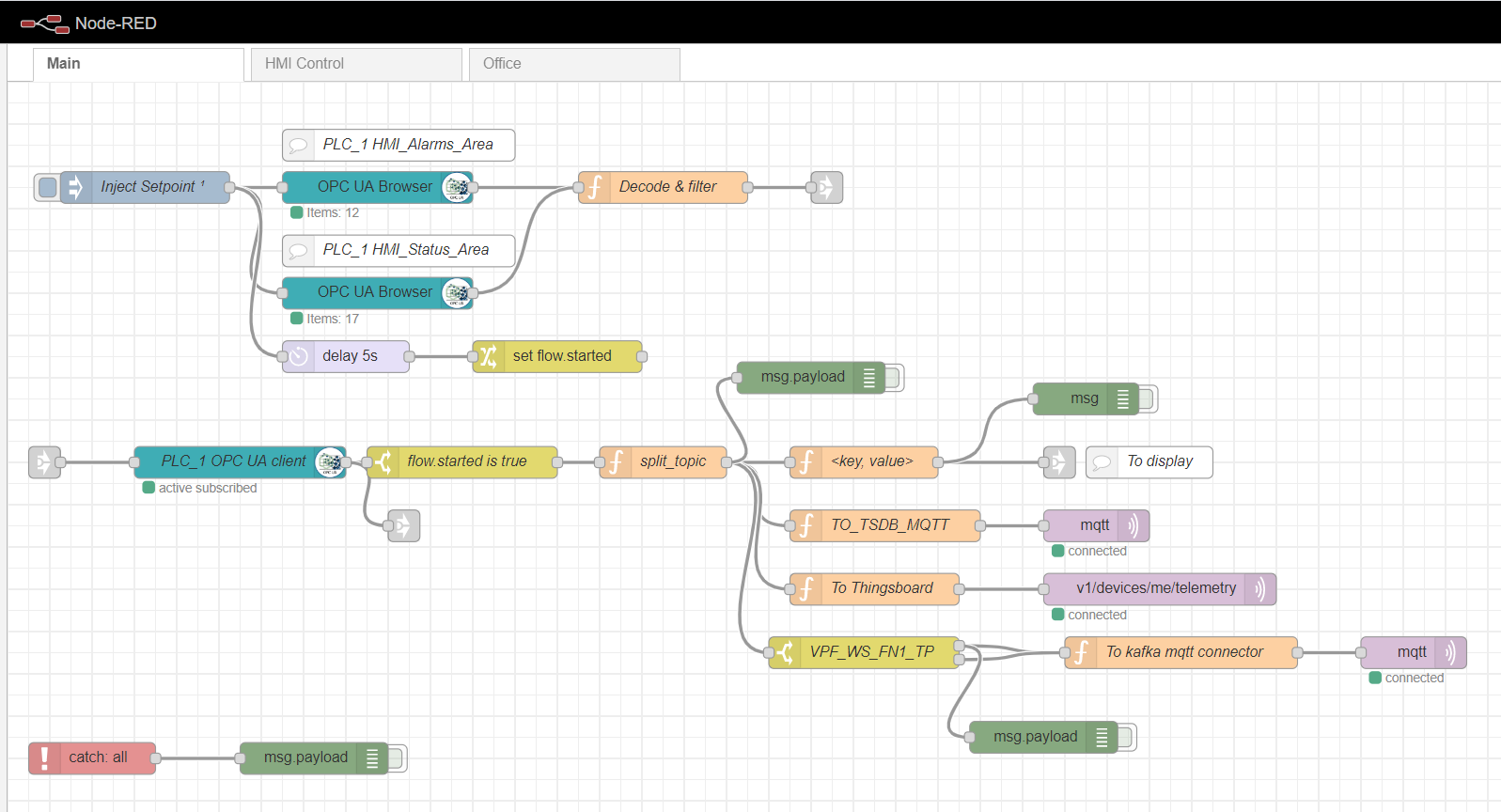
Einrichten des OPC-Browserknotens

OPC-client

Um das Lesen mehrerer Daten zu abonnieren, müssen Tags gemäß dem OPC-Protokoll vorbereitet und von der Steuerung heruntergeladen werden. Dazu wird zunächst ein Inject-Knoten mit dem nur einmaligen Kontrollkästchen verwendet, das ein einmaliges Lesen der in den OPC-Browserknoten angegebenen Datenblöcke auslöst. Die Daten werden dann von der Decode & Filter-Funktion verarbeitet. Danach abonniert und liest der OPC-Clientknoten die sich ändernden Daten von der Steuerung. Die weitere Verarbeitung des Streams hängt von der spezifischen Implementierung und den Anforderungen ab. In meinem Beispiel verarbeite ich die Daten, um sie weiter an den MQTT-Broker zu verschiedenen Themen zu senden.
Die Registerkarten HMI-Steuerung und Office sind eine einfache HMI-Implementierung, die auf Scadavis.io und einem knotenroten Dashboard basiert, wie weiter oben in diesem Artikel beschrieben .
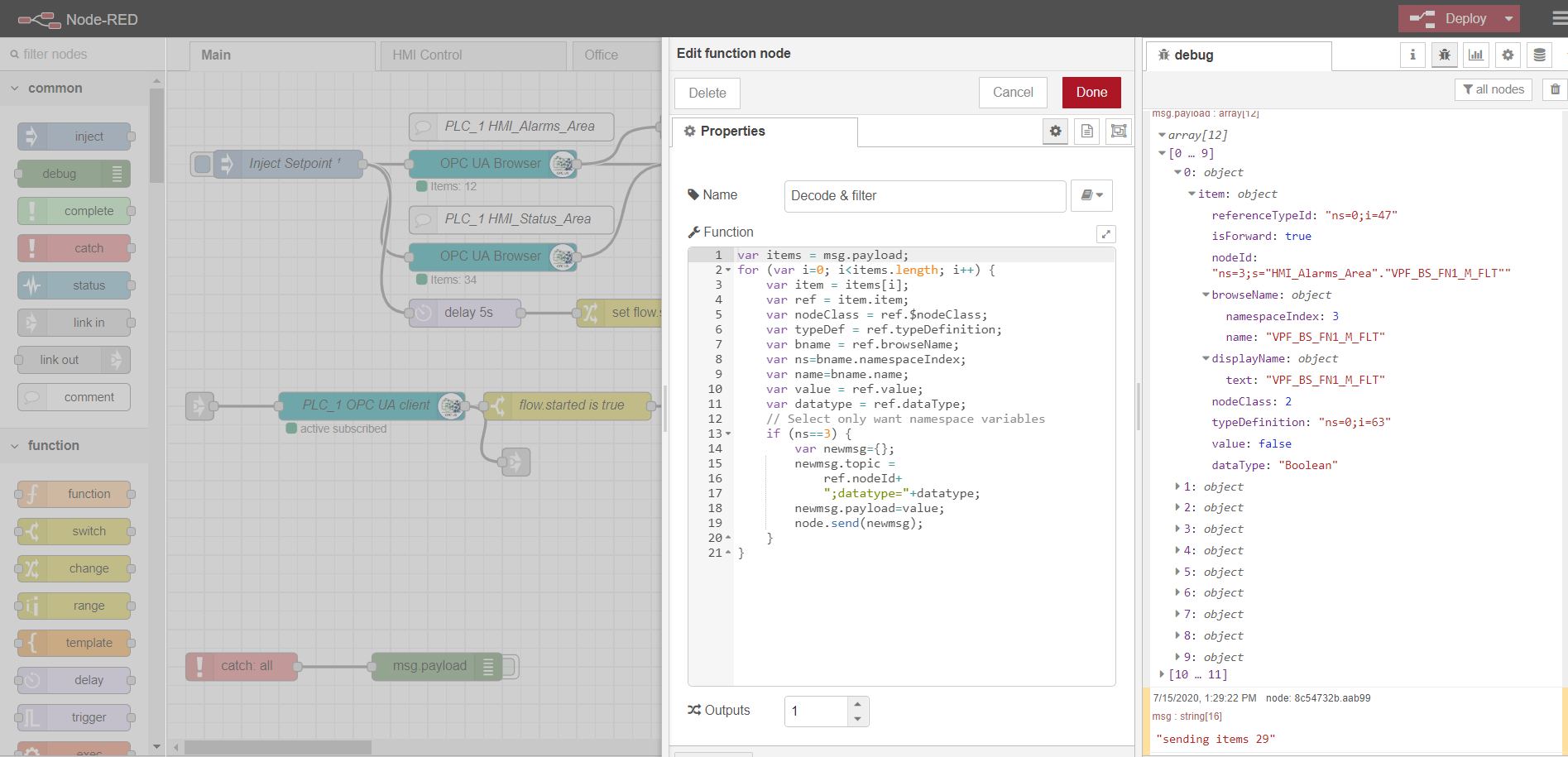
Ein Beispiel für das Parsen von Daten von einem OPC-Browserknoten:
var items = msg.payload;
for (var i=0; i<items.length; i++) {
var item = items[i];
var ref = item.item;
var nodeClass = ref.$nodeClass;
var typeDef = ref.typeDefinition;
var bname = ref.browseName;
var ns=bname.namespaceIndex;
var name=bname.name;
var value = ref.value;
var datatype = ref.dataType;
// Select only want namespace variables
if (ns==3) {
var newmsg={};
newmsg.topic =
ref.nodeId+
";datatype="+datatype;
newmsg.payload=value;
node.send(newmsg);
}
}
MQTT-Broker
Jede Implementierung kann als Broker verwendet werden. In meinem Fall ist der Mosquitto- Broker bereits installiert und konfiguriert . Der Broker übernimmt die Funktion des Transports von Daten zwischen dem Edge-Gateway und anderen Plattformteilnehmern. Es gibt Beispiele für Lastausgleich und verteilte Architektur ( wie hier ). In diesem Fall beschränken wir uns auf einen mqtt-Broker mit Datenübertragung ohne Verschlüsselung.
Lokale Speicherung von Zeitreihendaten
Es ist praktisch, Zeitreihendaten in der NoSql-Zeitreihendatenbank aufzuzeichnen und zu speichern. Der InfluxData-Stack funktioniert gut für unsere Zwecke . Wir benötigen vier Dienste von diesem Stapel:
InfluxDB ist eine Open-Source-Zeitreihendatenbank, die Teil des TICK-Stapels (Telegraf, InfluxDB, Chronograf, Kapacitor) ist. Entwickelt für die Datenverarbeitung mit hoher Last und bietet die SQL-ähnliche Abfragesprache InfluxQL für die Interaktion mit Daten.
Telegraf ist ein Agent zum Sammeln und Senden von Metriken und Ereignissen von externen IoT-Systemen, Sensoren usw. an InfluxDB. Es ist so konfiguriert, dass Daten aus mqtt-Themen erfasst werden.
Kapacitor ist eine integrierte Daten-Engine für InfluxDB 1.x und eine integrierte Komponente in der InfluxDB-Plattform. Dieser Dienst kann so konfiguriert werden, dass er verschiedene Sollwerte und Alarme überwacht und einen Handler zum Senden von Ereignissen an externe Systeme wie Kafka, E-Mail usw. installiert.
Chronograf ist die Benutzeroberfläche und Verwaltungskomponente der InfluxDB-Plattform. Wird verwendet, um schnell Dashboards mit Echtzeitvisualisierung zu erstellen.
Alle Komponenten des Stacks können lokal ausgeführt oder ein Docker-Container eingerichtet werden.
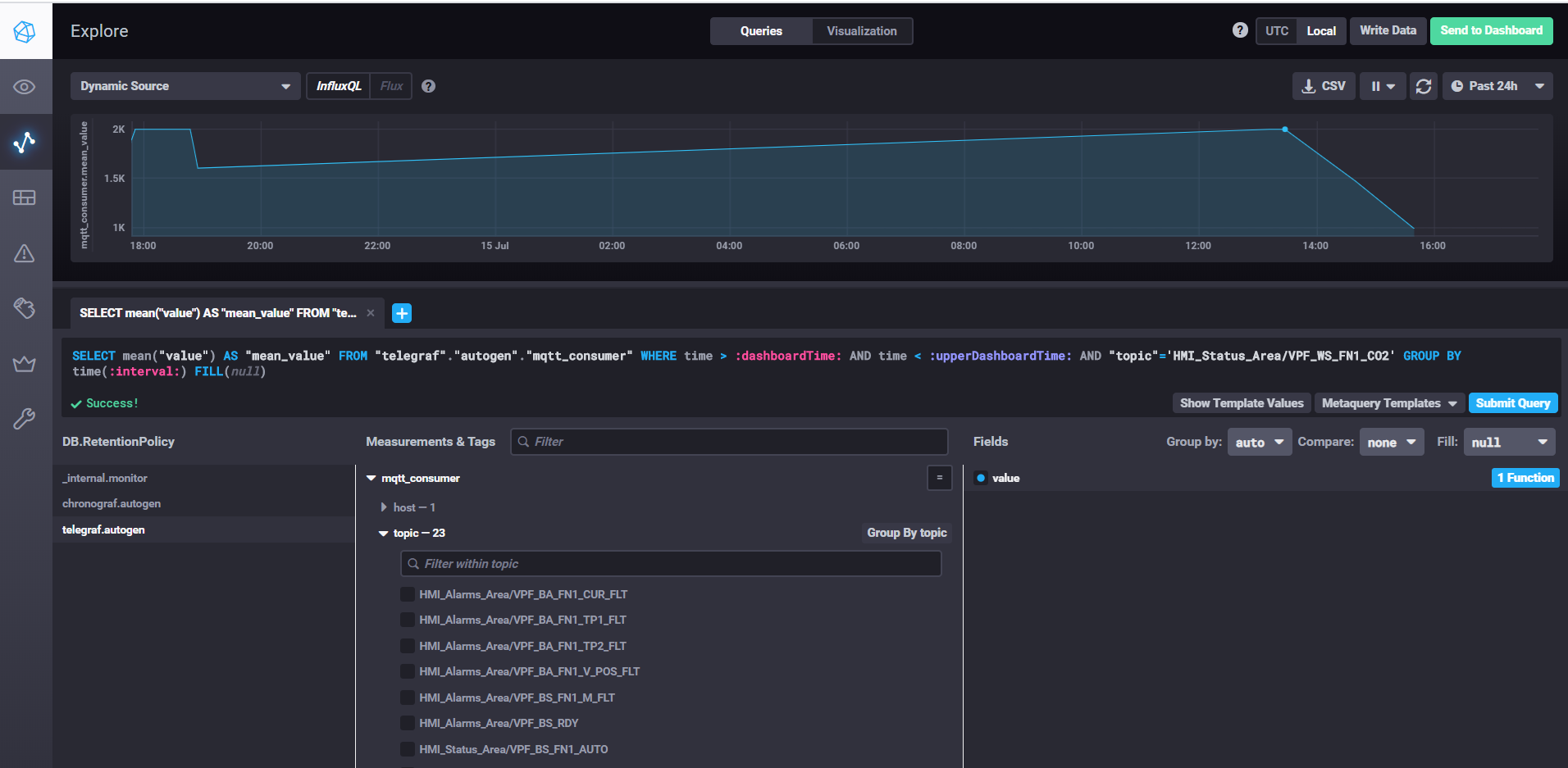
Abrufen von Daten und Anpassen von Dashboards mit Chronograf
Um InfluxDB zu starten, führen Sie einfach den Befehl influxd aus. In den Einstellungen von influxdb.conf können Sie den Speicherort und andere Eigenschaften angeben. Standardmäßig werden die Daten im Benutzerverzeichnis im Verzeichnis .influxdb gespeichert.
Um telegraf zu starten, müssen Sie den Befehl telegraf -config telegraf.conf ausführen, mit dem Sie die Quellen für Metriken und Ereignisse in den Einstellungen angeben können. In unserem Beispiel für mqtt sieht es folgendermaßen aus:
# # Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
servers = ["tcp://192.168.1.107:1883"]
qos = 0
topics = ["HMI_Status_Area/#", "HMI_Alarms_Area/#"]
data_format = "value"
data_type = "float"
In der Server-Eigenschaft geben wir die URL für den mqtt-Broker an. Qos kann 0 belassen, wenn es ausreicht, Daten ohne Bestätigung zu schreiben. Geben Sie in der Theme-Eigenschaft die mqtt-Masken der Themen an, aus denen Daten gelesen werden sollen. Zum Beispiel bedeutet HMI_Status_Area / #, dass wir alle Themen lesen, die das Präfix HMI_Status_Area haben. Auf diese Weise erstellt Telegraf für jedes Thema eine eigene Metrik in der Datenbank, in die Daten geschrieben werden.
Um kapacitor zu starten, müssen Sie den Befehl kapacitord -config kapacitor.conf ausführen. Die Eigenschaften können als Standard beibehalten werden und weitere Einstellungen können mit chronograf vorgenommen werden.
Um chronograf zu starten, führen Sie einfach den gleichnamigen Befehl chronograf aus. Das Webinterface wird localhost verfügbar sein : 8888 /
Um Einstellungen und Alarme mit Kapacitor zu konfigurieren, können Sie verwendenHandbuch . Kurz gesagt: Sie müssen in Chronograf zur Registerkarte "Warnung" gehen und eine neue Regel mit der Schaltfläche "Warnungsregel erstellen" erstellen. Die Benutzeroberfläche ist intuitiv und alles wird visuell ausgeführt. So richten Sie das Senden von Verarbeitungsergebnissen an kafka usw. ein Sie müssen im Abschnitt Bedingungen einen Handler hinzufügen
Kapacitor-Handler-Einstellungen
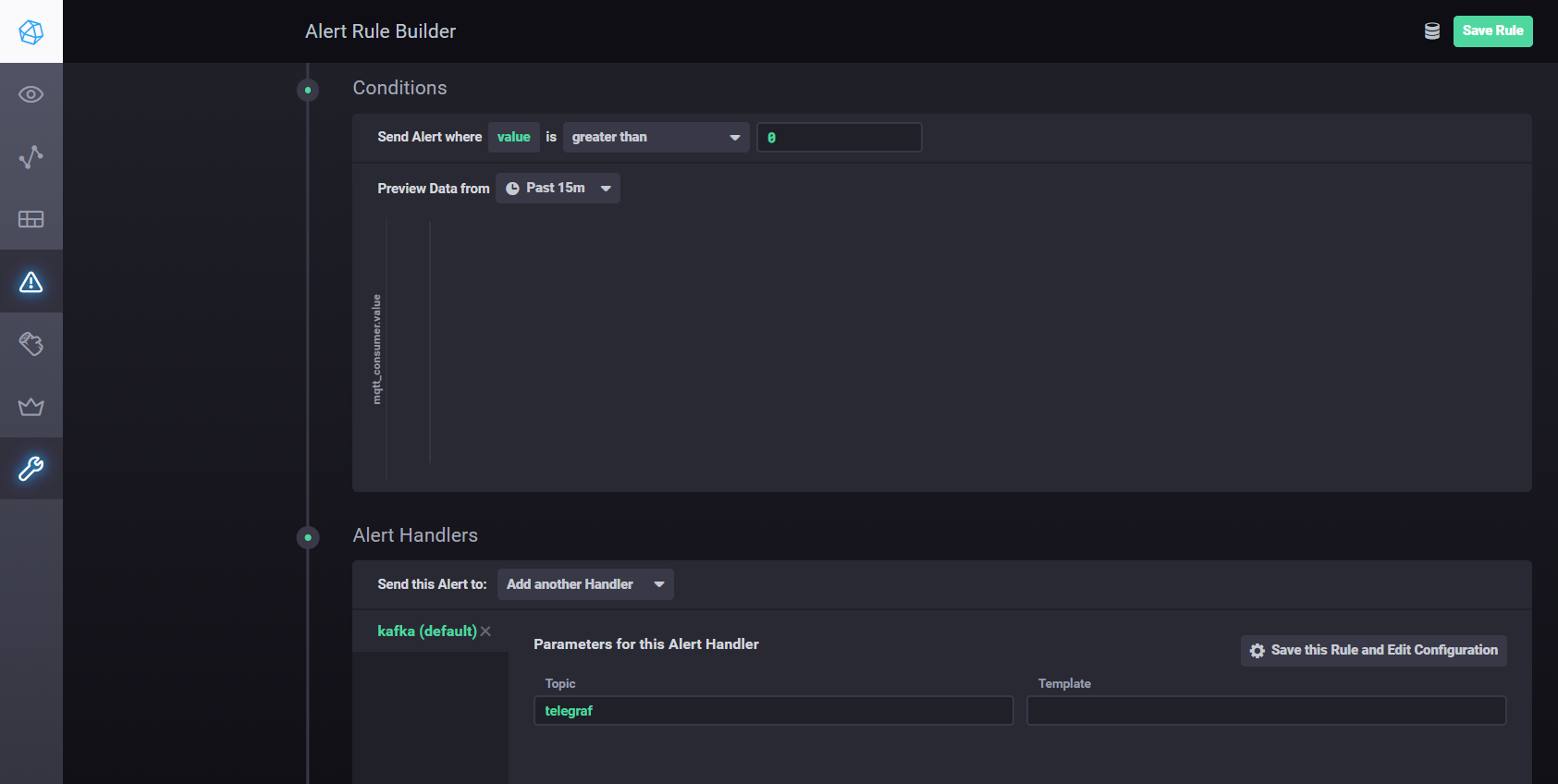
Verteiltes Streaming mit Apache Kafka
Für die vorgeschlagene Architektur ist es erforderlich, die Datenerfassung von der Verarbeitung zu trennen, um die Skalierbarkeit und die Schichtunabhängigkeit zu verbessern. Wir können eine Warteschlange verwenden, um dieses Ziel zu erreichen. Die Implementierung kann Java Message Service (JMS) oder Advanced Message Queuing Protocol (AMQP) sein. In diesem Fall verwenden wir jedoch Apache Kafka. Kafka wird von den meisten Analyseplattformen unterstützt, weist eine sehr hohe Leistung und Skalierbarkeit auf und verfügt über eine gute Kafka-Streams-Bibliothek.
Sie können das Plugin "Node-Red Node-Red-Contrib- Kafka -Manager" verwenden, um mit Kafka zu interagieren . Unter Berücksichtigung der Trennung von Sammlung und Datenverarbeitung werden wir jedoch das MQTT-Plugin installieren, das Mosquitto-Themen abonniert. Das MQTT-Plugin finden Sie hier .
Kopieren Sie zum Konfigurieren des Connectors die Bibliotheken kafka-connect-mqtt-1.1-SNAPSHOT.jar und org.eclipse.paho.client.mqttv3-1.0.2.jar (oder eine andere Version) in das Verzeichnis kafka / libs /. Anschließend müssen Sie im Verzeichnis / config eine Eigenschaftendatei mqtt.properties mit folgendem Inhalt erstellen:
name=mqtt
connector.class=com.evokly.kafka.connect.mqtt.MqttSourceConnector
tasks.max=1
kafka.topic=streams-measures
mqtt.client_id=mqtt-kafka-123456789
mqtt.clean_session=true
mqtt.connection_timeout=30
mqtt.keep_alive_interval=60
mqtt.server_uris=tcp://192.168.1.107:1883
mqtt.topic=mqtt
Nachdem wir zuvor zookeeper-server und kafka-server gestartet haben, können wir den Connector mit dem folgenden Befehl starten:
connect-standalone.bat …\config\connect-standalone.properties …\config\mqtt.properties
Aus dem mqtt-Thema (mqtt.topic = mqtt) werden Daten in das Kafka-Thema Streams-Measures (kafka.topic = Streams-Measures) geschrieben.
Als einfaches Beispiel können Sie ein Maven-Projekt mithilfe der Kafka-Streams-Bibliothek erstellen.
Mithilfe von Kafka-Streams können Sie verschiedene Dienste und Szenarien für Hot Analytics und Streaming-Datenverarbeitung implementieren.
Ein Beispiel für den Vergleich der aktuellen Temperatur mit dem Sollwert für den Zeitraum.
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-measures");
KStream<Windowed<String>, String> max = source
.selectKey((String key, String value) -> {
return getKey(key, value);
}
)
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)))
.reduce((String value1, String value2) -> {
double v1=getValue(value1);
double v2=getValue(value2);
if ( v1 > v2)
return value1;
else
return value2;
}
)
.toStream()
.filter((Windowed<String> key, String value) -> {
String measure = tagMapping.get(key.key());
double parsedValue = getValue(value);
if (measure!=null) {
Double threshold = excursion.get(measure);
if (threshold!=null) {
if(parsedValue > threshold) {
log.info(String.format("%s : %s; Threshold: %s", key.key(), parsedValue, threshold));
return true;
}
return false;
}
} else {
log.severe("UNKNOWN MEASURE! Did you mapped? : " + key.key());
}
return false;
}
);
final Serde<String> STRING_SERDE = Serdes.String();
final Serde<Windowed<String>> windowedSerde = Serdes.serdeFrom(
new TimeWindowedSerializer<>(STRING_SERDE.serializer()),
new TimeWindowedDeserializer<>(STRING_SERDE.deserializer(), TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)).size()));
// the output
max.to("excursion", Produced.with(windowedSerde, Serdes.String()));
Anlagenregistrierung
Die Asset-Registrierung ist in der Tat keine strukturelle Komponente der Edge-Plattform und Teil der Cloud-IoT-Umgebung. Dieses Beispiel zeigt jedoch, wie Edge und Cloud interagieren.
Als Asset-Registrierung verwenden wir die beliebte ThingsBoard IoT-Plattform, deren Benutzeroberfläche ebenfalls sehr intuitiv ist. Die Installation ist mit Demo-Daten möglich. Die Plattform kann lokal, im Docker oder in einer vorgefertigten Cloud-Umgebung installiert werden .
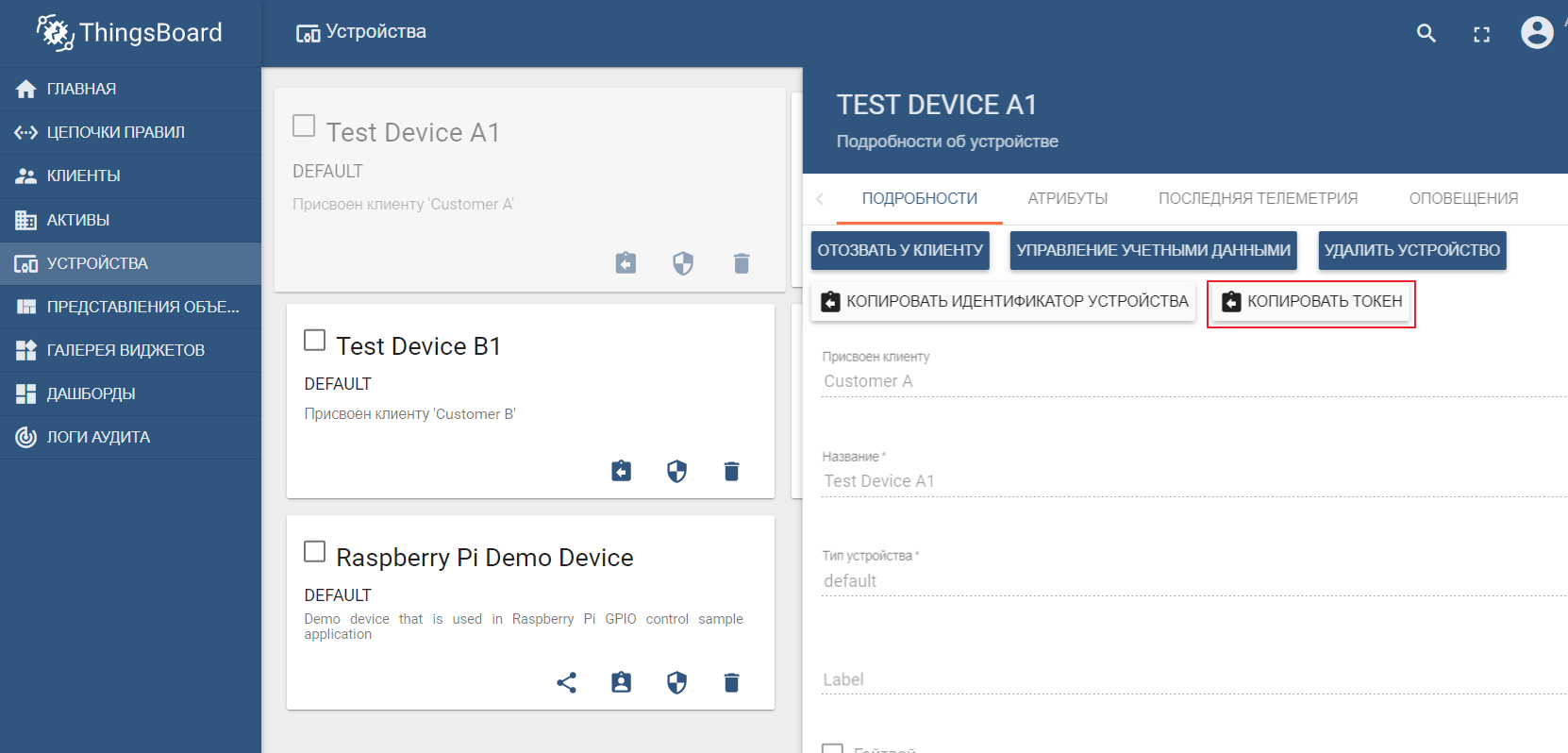
Das Demo-Dataset enthält Testgeräte (Sie können problemlos ein neues erstellen), an die Sie Werte senden können. Standardmäßig startet ThingsBoard mit einem eigenen mqtt-Broker, zu dem Sie eine Verbindung herstellen und Daten senden müssenim json Format. Angenommen, wir möchten Daten von TEST DEVICE A1 an ThingsBoard senden. Dazu müssen wir eine Verbindung zum ThingBoard-Broker unter localhost: 1883 herstellen und A1_TEST_TOKEN als Login verwenden, das aus den Geräteeinstellungen kopiert werden kann. Anschließend können wir Daten zum Thema v1 / Geräte / me / Telemetrie veröffentlichen: {„Temperatur“: 26}
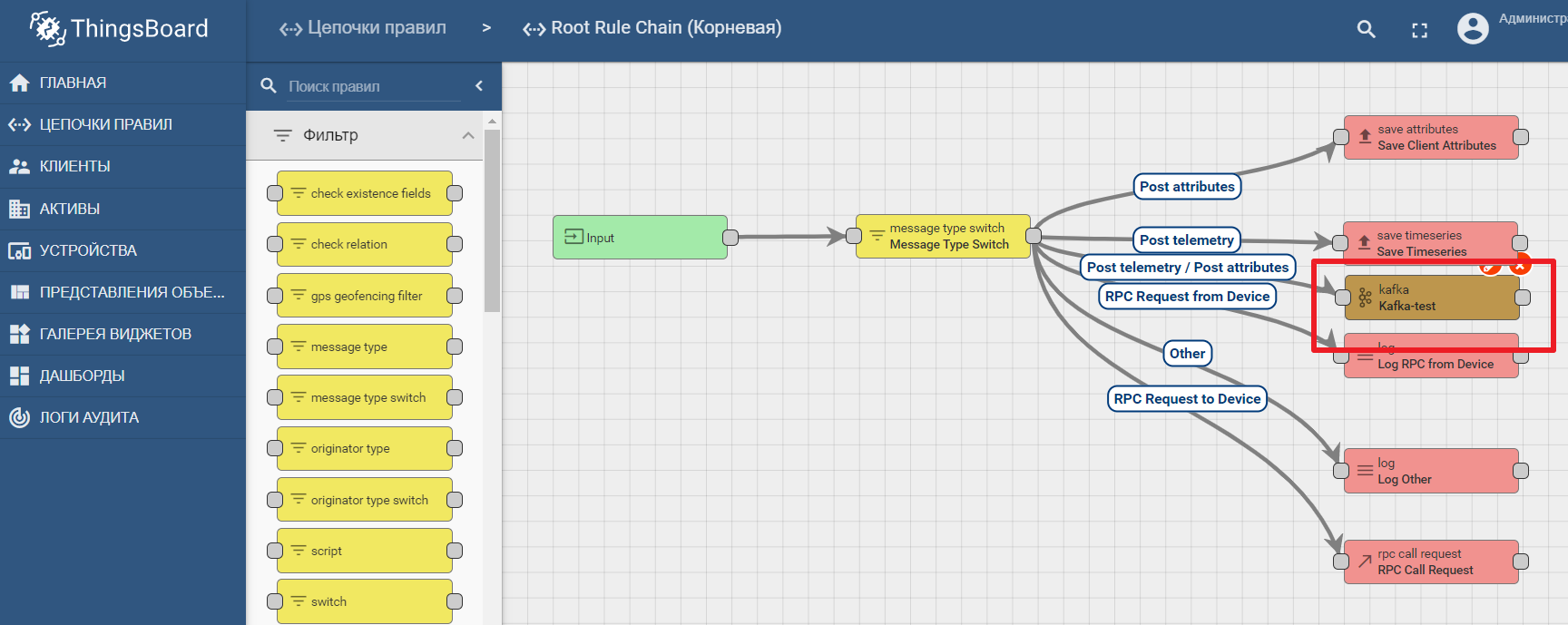
Die Plattformdokumentation enthält ein Handbuch zum Einrichten der Datenübertragungs- und -verarbeitungsanalyse in Kafka - IoT-Datenanalyse mit Kafka, Kafka Streams und ThingsBoard
Ein Beispiel für die Verwendung eines Kafka-Knotens in Thingsboard
Fazit
Moderne IT-Technologien und offene Protokolle ermöglichen das Entwerfen von Systemen beliebiger Komplexität. Die Edge-Plattform ist der Verbindungspunkt zwischen der industriellen Umgebung und der Cloud-basierten IoT-Plattform. Es kann in Makrokomponenten zerlegt werden, unter denen das Border Gateway eine Schlüsselrolle spielt und für die Übertragung von Daten von Geräten zum IoT-Datenhub verantwortlich ist. Offene Daten-Streaming-Tools ermöglichen effiziente Analysen und Edge-Computing.